Spark平台下聚类挖掘的智能推荐系统
2021-11-11钟桂凤庞雄文孙道宗刘宇东
钟桂凤,庞雄文,孙道宗,刘宇东
(1.广州理工学院 计算机科学与工程学院,广东 广州 510540;2.华南师范大学 计算机学院,广东 广州 530631;3.华南农业大学 电子工程学院,广东 广州 510642)
互联网高速发展,网络数据量迅速增长,用户对网络的依赖程度及数据获取便捷度的需求明显提升,用户主动搜索获取服务的方式正逐渐改变[1],平台推荐服务方式被用户青睐。对于区块链和资源共享等网络服务平台来说,数据资源需要进行聚类归档,并根据用户在平台的访问和使用习惯[2],对用户进行类别评分,然后根据相似度计算获得用户和资源的相似关系,最后为用户推荐相似度最高的资源。这种基于数据聚类的智能推荐系统是当前网络推荐系统的主流模式,这种模式因为涉及到聚类运算,在类别较多且数据规模较大的情况下,推荐的准确率和效率均会受到影响,因此多类别聚类和大规模运算效率是该推荐模式需要重点解决的问题。
当前,基于聚类挖掘的智能推荐技术研究较多,Liu等[3]采用深度模型来实现K-means聚类挖掘,并用于在线学习资源推荐,能够根据用户短时间的学习习惯进行资源推荐,但是受模型限制,推荐的准确率并不高;Liu等[4]采用深度学习算法来提升K-means聚类的准确率,对网站在线用户提供广告推荐,具有一定的智能推荐效果,但也出现了轻度误判;Ming等[5]根据用户历史点歌情况,利用聚类挖掘算法实现了不同用户的歌单推荐,取得了良好效果,但其采用的方法处于封闭歌单库训练,导致适用度有一定局限。上述方法均在一定程度上提高了聚类的准确率,但是均没有效利用云计算平台来提升推荐效率。
狼群算法是近期提出的一种新型群体智能优化算法,能够解决全局寻优和局部极值问题。本文尝试引入狼群算法来对K-means聚类算法进行优化,以提高多类别聚类的准确率,同时引入Spark平台的多节点并行计算来提高聚类和推荐效率。
1 Spark结构
Spark作为大规模数据处理常用引擎,采用主-从节点管理模式共同完成数据处理任务,但是在功能结构上,主-从节点具有同等的运算能力,其主要结构[6,7],如图1所示。
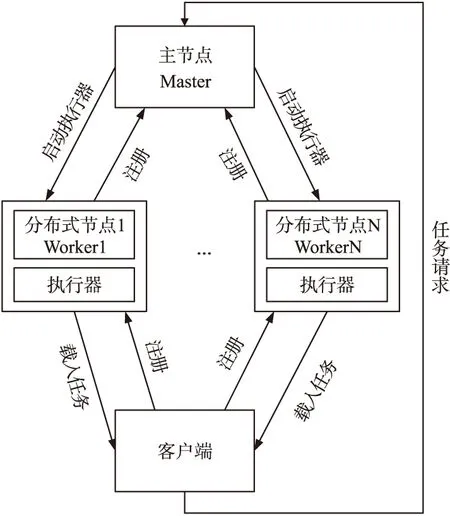
图1 Spark结构
除了这种主-从节点协同工作模式之外,Spark平台还有一个优点就是大部分数据运算都在其平台节点内存的弹性分布式数据集(Resilient distributed datasets,RDD)中完成,这种方式极大地提升了数据存取效率,完成大规模数据的聚类与推荐,解决了聚类中频繁迭代造成的运算效率不高问题,同时也解决了智能推荐的实时性问题。
2 基于狼群优化的K-means聚类挖掘的协同过滤推荐
2.1 K-means算法
聚类空间中任意两点i和j的距离Sij数学[8]表示
(1)
设中心点xi包含n个属性,表示方法为(xi1,xi2,…,xin)和待聚类点xj(xj1,xj2,…,xjn),xi与xj的距离为
(2)
根据式(2)可以计算所有待聚类的样本点至中心点距离集,根据距离dij来判定xi与xj是否同类。然后根据距离集建立聚类目标函数,求解式(3)的最小值
(3)
xj∈N(xi)意思是:xj为N个样本点中除了中心点xi的剩余样本点,满足:∑j,xj∈N(xi)Sijxj=1,Sij≥0。
将式(3)进一步展开得[9]
(4)
最后得到目标函数为
minε
(5)
K均值聚类的效率取决于待聚类点的维度与样本数据量。一般而言,聚类的准确率和效率随着待聚类样本的数量及维度增加而降低。在处理大规模聚类精度问题和聚类时间问题仅采用K-means算法不够,因为,除了待聚类的数据量外,K均值聚类算法初始中心点的选择也很重要,它影响着聚类的效率,所以,有必要对K-means算法进行一定改进。
2.2 狼群算法
设狼群总量为N,数据维度为D,则第i只狼位置为Xi=(xi1,xi2,…,xid,…xiD),其中1≤i≤N,1≤d≤D。
xid=xmin+rand*(xmax-xmin)
(6)
式中:xmax和xmin分别表示d维空间的上下限。rand为[0,1]随机值。
根据适应度值最高的狼作为头狼,其周围的为探狼,数量为Tnum,其游走步长[10]为
StepG(d)=|maxd-mind|/S
(7)
式中:1≤d≤D,S为可设置的权重常量。
探狼位置更新
(8)
式中:i=1,2,…,Tnum,h为游走方向数。
狼群中剩余狼移动步长
StepB(d)=2×|maxd-mind|/S
(9)
位置更新为
式中:i=1,2,…,N-Tnum-1。si,d为d维空间中第i只狼与头狼距离,si,d∈Dd。
(10)
式中:ω为距离因子常量。
当狼群找到猎物,头狼号令围攻,运动步长和位置更新计算方式[11]为
StepW(d)=|maxd-mind|/(2×S)
(11)
(12)
式中:si,d∈Dd,i=1,2,…,N-1,λ∈[-1,1]随机值。
2.3 协同过滤推荐
通过狼群优化的K-means算法进行聚类后,可以获得用户对所有待推荐的资源或服务的评分,然后采用协同过滤算法进行有效推荐。
设推荐的用户集合为U={u1,u2,…,um},待推荐的资源集合为I={i1,i2,…,in},rm,n表示第m个用户对第n个资源的评分,那么用户a和b的相似关系[12]为
(13)
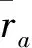
在协同过滤时,除了可以对用户之间的相似性进行分析之外,最重要的是需要求解用户对资源的评分,用户j对资源k的评分方法为
(14)
根据资源评分分数,为用户推荐评分高的资源,从而完成智能推荐。该算法的智能性体现在无需所有用户对所有资源进行评分,而是通过用户访问网络的习惯数据,采用狼群优化的K-means聚类来预测用户对资源的评分值。
2.4 聚类及推荐流程
首先,分析客户端的智能推荐任务需求,然后搭建Spark平台,部署合适规模的分布式节点,接着建立聚类运算模型,并通过狼群算法对初始聚类中心点进行优化,通过聚类结果获取用户-属性评分数据,最后采用协同过滤完成智能推荐。Spark平台下聚类挖掘的智能推荐流程主要如图2所示。
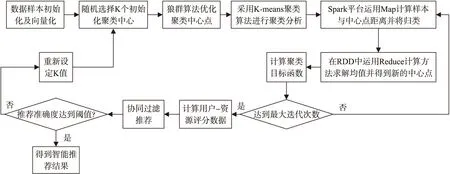
图2 Spark平台下智能推荐流程图
3 实例仿真
为了验证Spark平台下聚类挖掘的智能推荐性能,分别对公共数据集和自有数据集进行仿真,其中公共数据集为Movie Lens数据集,自有数据集为某在线教育平台。Movie Lens数据集作为推荐系统仿真的经典数据集,能够很好地验证聚类挖掘的推荐性能,而在线学习平台因为用户量众多和学习资源数据量大,很容易获得大规模数据样本,充分验证Spark平台的推荐优势。
Spark平台共包含1个Master节点和9个Work节点,所有节点具有相同的硬件性能。
3.1 Movie Lens数据集仿真
为了验证狼群优化的K-means聚类算法在Movie Lens数据集的智能推荐性能,采用狼群优化的K-means算法完成聚类,然后通过协同过滤完成影片推荐。

表1 Movie Lens实验数据集
3.1.1 不同聚类中心数的推荐性能
聚类中心个数K对影片评分矩阵影响敏感,从而影响影片协同过滤推荐的稳定性,因此差异化设置K,验证推荐准确率的RMSE值。
图3表明RMSE值随着K值的增加先减小后增大,当分类类别较小时,影片类别分类粒度大,因此推荐的影片与用户实际评分值偏差大,Data1和Data2在K=16时获得了最优RMSE,而Data3在K=18时获得了最优RMSE值。当继续增加K值后,RMSE逐渐增大,推荐稳定性变差。因此,选择在后续针对Movie Lens数据集仿真时,K取值范围设置为[16,18]。

图3 不同K值的推荐准确率RMSE值
3.1.2 基于公共数据集的推荐性能
设置K=16,采用狼群优化的K-means算法进行聚类挖掘,并采用协同过滤推荐算法对Movie Lens数据集训练,训练时共有10个节点组成Spark平台进行计算。
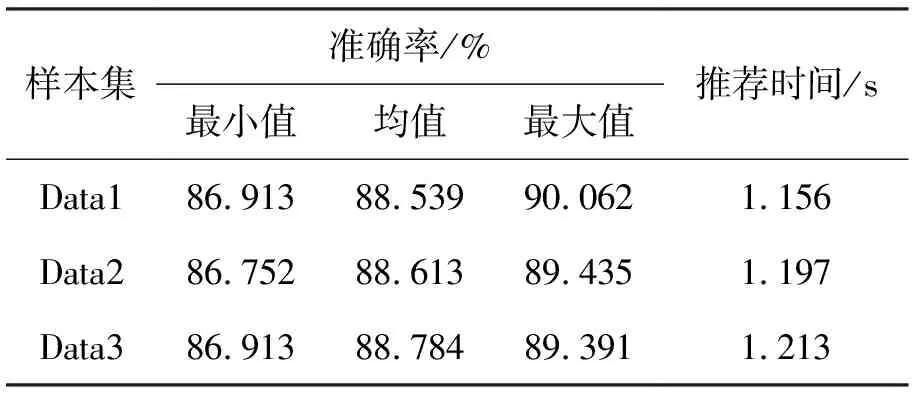
表2 推荐性能(Movie Lens数据集)
推荐时间性能方面,容量的差别在推荐时间上表现不明显,这主要是采取了Spark平台的作用,对于10个节点来说,因3个样本数据容量差异导致的推荐时间变化非常小。
3.2 在线学习平台数据集仿真
为了进一步验证本文算法和Spark平台结合的智能推荐性能,采用在线学习平台数据集进行仿真。分别选择了粤港澳大湾区某大型在线学习平台1个月的用户学习数据,组建成4个不同容量的样本:Data1(12.95MB),Data2(656.82MB),Data3(1.42GB),Data4(8.03GB)。
3.2.1 聚类结果可视化
将4种数据样本分别进行狼群优化K-means聚类。根据用户和资源的类别属性获得用户-资源评分数据,差异化设置K值,取推荐准确率最高K值作为聚类中心数;为了直观显示聚类结果,对聚类结果进行可视化,其中Data1的聚类结果如图4所示。

图4 Data1聚类结果可视化
狼群优化的K-means聚类算法在三维空间内将Data1数据集分为5类。根据分类结果,可以获得样本所有用户和资源属性的评分,然后再进行协同过滤计算获得推荐结果。
3.2.2 推荐性能仿真
差异化设置聚类中心数,对不同K值下的推荐性能进行仿真,取最优K值完成5个样本的狼群优化K-means和协同过滤智能推荐。
从表3可以看出,推荐的准确率保持在91%以上,准确率受样本容量的影响较小,而推荐时间随着样本容量在增加,虽然Data3和Data4样本容量量级变大,推荐时间并未有快速增长,这主要是Spark平台多节点运算的原因。
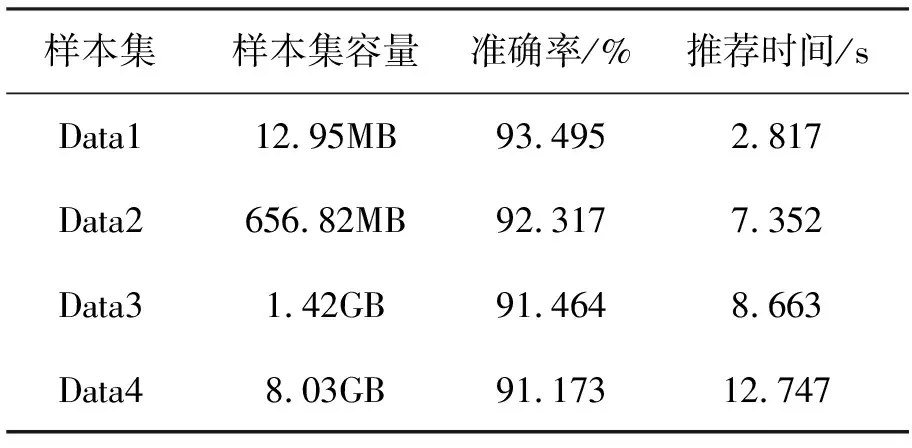
表3 推荐性能(在线学习平台数据集)
3.2.3 Spark平台的加速性能仿真
为了验证Spark平台对智能推荐速度的影响,求解Spark推荐相对于单机推荐的加速比:
(15)
Ta与Ts为单机和Spark多节点的各自推荐时间。
从表4可以看出,当Worker节点数量增加,Spark加速效果明显,样本容量越大,Worker节点数对加速比影响越显著。Data1的样本容量为12.95 MB,Worker节点达到10时,加密比只比单机增加了0.001,而当样本容量为8.03 GB时,加速比相对于单机增加了42.907,因此Spark平台提高了大容量样本的推荐效率,特别适合大规模聚类挖掘及推荐。
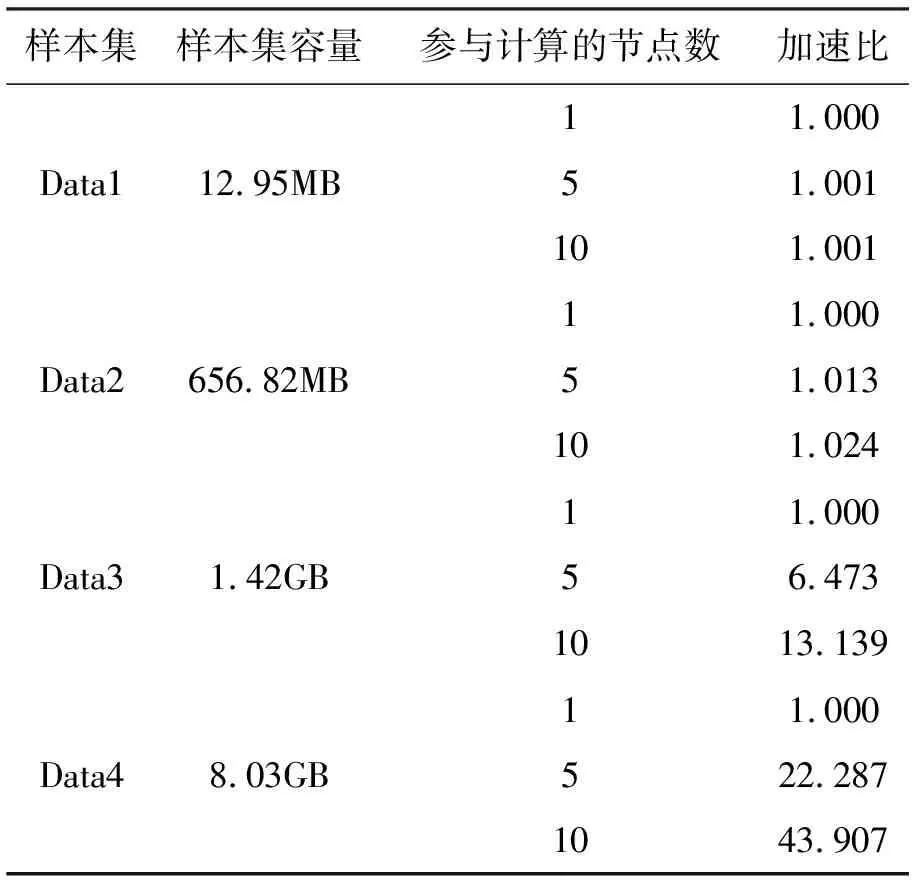
表4 Spark加速性能
3.3 不同推荐算法性能仿真
为了继续验证本文算法在智能推荐系统中的性能,分别从在线学习平台的4个数据集中各抽取500个样本组建成新的数据集Data5,将SVM算法[13]、深度神经网络(DNN)[14]、XGBoost算法[15]和本文算法分别进行仿真。
如图5所示,4种不同算法的推荐准确率在初期时均随着迭代次数的增加而不断提升,然后趋于稳定。推荐性能包括两个方面:准确率和收敛速度,可从这2个方面综合分析。首先,在推荐准确率方面,算法稳定即收敛后,本文算法和XGBoost算法最优,均超过了0.9,而SVM算法最差,仅约为0.7;其次,在收敛速度方面,SVM表现最优为190次,本文算法次之,约为230次,XGBoost算法最差。根据4种算法的综合推荐性能对比来看,本文算法在准确率和收敛速度2个方面均排名靠前,这说明其对在线学习样本的综合推荐性能最佳。

图5 不同算法的推荐性能
4 结束语
本文采用狼群优化的K-means算法完成聚类挖掘,并采用协同过滤算法完成智能推荐,推荐准确率高;为了解决大规模数据的推荐问题,引入Spark平台多节点共同完成聚类和推荐,提高了智能推荐效率。后续研究将进一步优化聚类参数及Spark节点的自适应加入,以提高智能推荐准确率,同时节省节点计算资源。
