基于轻量级深度哈希网络的细粒度图像检索
2021-10-28范业嘉
范业嘉,孙 涵
(南京航空航天大学 计算机科学与技术学院 模式分析与机器智能工业和信息化部重点实验室,
0 引 言
随着大数据时代的到来,对数据的有效存储和快速检索已经成为一个重要的研究课题。近年来,随着卷积神经网络在计算机视觉领域的成功应用,深度哈希方法利用端到端框架相互学习特征表示和哈希码,与传统的哈希方法相比,具有更好的检索性能。哈希的主要工作是将高维的原始数据转换为低维的二进制码,并使相似数据的哈希码之间的汉明距离小于异类数据哈希码之间的汉明距离。因此,哈希方法在保证检索精度的基础上,比其他检索方法提供更高的计算效率和更低的存储量。
但是,现有的深度哈希方法仍然有两个缺点:(1)现存的深度哈希方法大多是基于复杂的卷积神经网络。从AlexNet[1]到VGGNet[2],虽然识别精度不断上升,但是模型越来越大,计算速率越来越慢。(2)大多数现有的深度哈希方法使用的损失函数具有很高的时间复杂度。这些方法为了保留原始数据空间的相似性,都采用了适当的损失函数,比如成对相似性保留损失或三元组排序损失。然而,对于n个数据点,这些方法的时间复杂度是O(n!),这表明遍历所有数据计算损失是不切实际的。
为了解决上述问题,文中提出了基于轻量级深度哈希网络的细粒度图像检索算法。图1展示了文中模型的体系结构,其中主要分为三个部分:特征提取器、哈希编码层和分类层。对于上述问题一,文中将NTS-Net[24]特征提取器的主干网络ResNet-50[3]替换为PeleeNet[4]。并针对细粒度图像识别更加关注细节的特点,提出了跨层多尺度的Non-Local模块,将PeleeNet阶段2和阶段3输出的特征融合到阶段4输出的特征图上,使得最终的特征不仅包含低层的细节信息,还包含高层的语义信息。对于上述问题二,文中将哈希编码层置于分类层之前,用简单有效的分类损失来指导网络学习参数,这样不仅减少了时间复杂度,而且使哈希码保留了类别标签的语义信息。
简言之,文中的主要贡献为:
(1)设计了基于轻量级网络的深度哈希方法,提出了跨层的多尺度Non-Local模块,融合了低层与高层的特征,将局部特征与全局特征一起送入分类器;
(2)创新性地在细粒度图像检索中,将哈希编码层前置,放在分类层之前。在细粒度图像检索中,这里的哈希编码层更像是特征开关层,用于指导分类;
(3)在三个公开的细粒度图像数据集上做了广泛的实验分析。结果表明,该方法不仅提升了检索精度,而且节约了大量的存储空间,提升了检索速度。
1 相关研究
1.1 基于哈希的图像检索算法
依据是否使用训练数据,可将现有的哈希方法分为与数据无关的算法[5-7]和与数据有关的算法[8-13]。与数据无关的哈希方法通常在不使用训练数据的情况下随机或手动生成哈希函数。相反,数据相关的哈希方法利用训练数据来弥补特征表示与输入数据无关的缺陷。文献[14]表明,较短的数据相关的哈希码比数据无关的哈希码具有更高的搜索精度。
此外,基于数据相关的哈希方法又可以分为监督哈希与无监督哈希。无监督哈希[8-10]依据的数据是没有标签信息的。尽管具有较少限制的无监督方法更加实用,但是它容易在原始数据和哈希码之间造成语义鸿沟。监督哈希方法[11-13]充分利用了类别标签等监督信息来学习哈希函数及生成哈希码,这些方法比无监督方法具有更高的准确性。基于内核的监督哈希(KSH)[11]是代表性的监督哈希方法之一,它在内核空间中生成非线性哈希函数。最小损失哈希(MLH)[12]基于具有潜在变量和类似铰链损失的结构化预测学习哈希函数。通过重新构造目标函数,监督离散哈希(SDH)[13]可以生成高质量的哈希码,而不会造成松弛。
近期,基于卷积神经网络(convolutional neural network,CNN)进行特征表示的方法取得了重大突破,一些将特征学习和哈希码生成相结合的端到端的深度哈希方法[15-18]被提出。卷积神经网络哈希(CNNH)[15]首次利用CNN提取的特征来学习哈希码。但是,CNNH是一种两阶段的方法,其中第一阶段使用成对标签学习近似的哈希码,第二阶段训练CNN学习特征表示和哈希函数。DNNH[16]提出了带有三元组排序损失的端到端的结构,它可以同时学习特征表示和哈希编码。HashNet[17]提出了一种新颖的方法,该方法通过迭代优化相似的平滑损失函数来解决原始的非平滑优化问题。文献[18]提出了一种监督哈希学习方法,它在分类层之前加入了紧凑的sigmoid层。尽管文献[18]和文中提出的网络框架类似,但是两者在分类层之前添加哈希编码层的含义和效果却大不相同。
1.2 细粒度图像检索
与普通图像不同,由于类间差异小和类内差异大的特点,细粒度图像更加难以区分。细粒度图像检索(fine-grained image retrieval,FGIR)的现有方法可以分为两类:基于手工特征以及基于CNN提取特征的检索方法。FGIS[19]属于第一类,它首次提出细粒度图像检索的概念。SCDA[20]是使用CNN进行细粒度图像检索的首次尝试。SCDA使用粗略的显著性定位选择有用的深度描述符,然后聚合这些描述符并转换为低维特征向量。但是SCDA并不是深度学习方法,因为它只使用了预训练的CNN模型来定位显著区域。为了解决使用预训练模型进行无监督学习带来的局限性,CRL-WSL[21]可以联合学习显著区域和有意义的深度描述符。最近,DCL-NS[22]在几个基准数据集上获得了最先进的性能。DCL-NS首先将CNN提取的特征投影到超球面上,然后以新的排序损失最小化类内距离并最大化类间距离。FPH[23]将特征金字塔与哈希结合,利用低层特征和高层特征分别定位部件和主要目标区域。
2 文中方法
2.1 模型框架
如图1所示,文中的网络框架主要由特征提取器、哈希编码层和分类层三个部分构成。

图1 网络框架
2.2 特征提取器
(1)轻量级的Backbone网络。
文中的特征提取器是在NTS-Net[24]特征提取器上改进得到的,弥补了原始特征提取的缺点。如图1所示,特征提取器首先由一个CNN提取到全局特征图,然后NTS-Net利用一个RPN[25]和排序损失,自监督地得到局部特征,接着将这些局部特征分别传入CNN,最后将全局特征向量与局部特征向量拼接得到最终用于分类的特征向量。由此可见,图1中特征提取器的backbone卷积神经网络重复出现了四次,并随着局部特征增多而增多。在NTS-Net的实验中,CNN是ResNet-50,鸟类数据集的最优局部特征个数为三个,最终的模型大小可达116 MB。这样大的模型很难在移动端或者嵌入式设备上插入,所以文中用现如今识别效果可以与ResNet相媲美的轻量级网络PeleeNet代替。PeleeNet网络结构如图2所示。

图2 PeleeNet网络结构
(2)跨层多尺度的Non-Local模块。
最近,文献[26]提出了Non-Local模块,通过自注意力模块来形成注意力图,从而在一层中对远程依赖进行建模。对于每一个位置,Non-Local模块首先计算当前位置与所有位置之间的成对依赖关系,然后通过加权和汇总所有位置的特征,softmax操作之后的权重添加到每个位置上输出。文献[27-28]显示了Non-Local模块可以在图像识别方法带来出色的改进。然而,对于细粒度图像而言,因为目标物体的局部特征具有各种大小和形状,所以多尺度的特征至关重要。如果仅在同一卷积层对空间依赖进行建模,那么固定大小的感受野与目标物体的局部区域不匹配可能会破坏特征提取。
基于以上论点,文中提出了跨层多尺度的Non-Local模块,如图3所示。图中,1×1 Conv是指卷积核为1×1的卷积操作,⊗是矩阵乘法,⊕是逐元素加法。高层因具有大范围的感受野,所以对全局信息比较敏感,低层则相反。据此,文中将PeleeNet阶段2和阶段3输出的特征图作为低层细节特征,阶段4输出的特征图作为高层语义特征。通过这种方式,跨层的Non-Local模块将一个高层特征与多个低层特征相关联。因此,高层可以从之前的低层中学习更多的多尺度细节特征。所有相关层之间显式学习的相关性提高了网络的表示能力。

图3 跨层多尺度Non-Local模块
2.3 哈希编码层与分类层
传统深度哈希方法的哈希编码层是对特征进行编码的输出层。与笔者的工作类似的文献[18]则在分类层之前添加了哈希编码层,以进行特征映射和生成紧凑的哈希码。但是,文献[18]未使用特征中包含的语义信息。文中框架中的哈希编码层,每个神经元作为特征开关控制某个特征的存在或不存在。由于哈希码是二进制的,因此“1”表示类别具有某种特征,而“0”表示其缺乏某种特征。图4是语义哈希编码层的示意图,实线表示具有某种特征,虚线表示缺少某种特征。
值得一提的是,只有细粒度特征提取器后面的哈希编码层才可以被视为特征开关层。众所周知,与粗粒度图像不同,细粒度图像具有相似的特征。以CUB200-2011[29]为例,其类别均为具有喙,羽毛等特征的鸟类。但是,在粗粒度图像数据集CIFAR-10[30]中,只有汽车和卡车才具有轮胎的特征,而其他类别(如鸟类和轮船)则没有此特征。由于粗粒度图像特征的复杂性,为粗粒度图像设计的文献[18]的哈希编码层无法控制某些特征的存在或不存在。
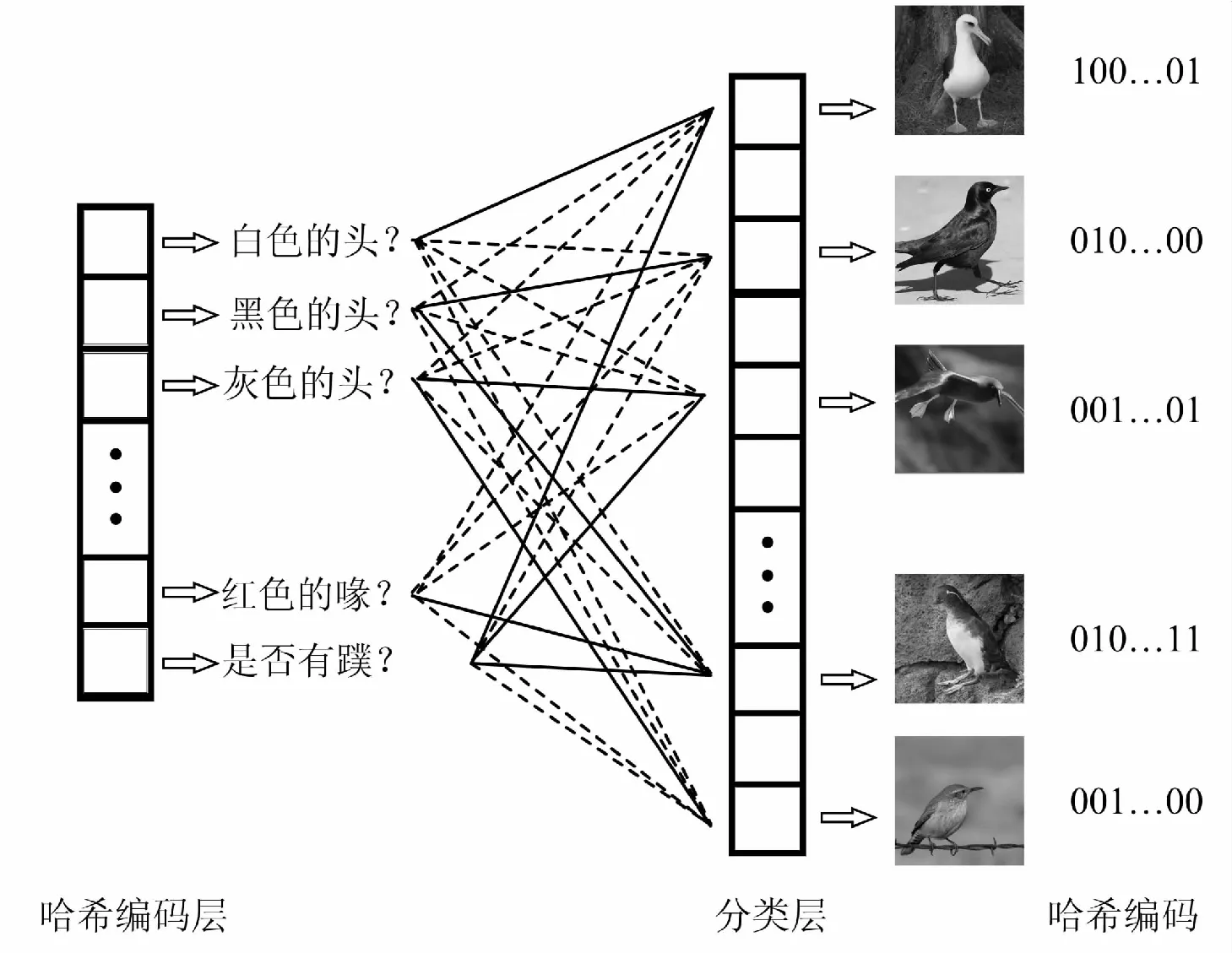
图4 哈希编码层指导分类层分类的示意图
3 实验结果与分析
3.1 实验平台及超参设置
本节做了广泛的实验以验证文中方法的有效性,所有的实验均在深度学习框架Pytorch上操作,实验机器的CPU为Intel Xeon E5-2609,GPU是两张NVIDIA TITAN XP(12 GB内存),操作系统是Ubuntu 16.04。在训练阶段,使用小批量随机梯度下降方法进行优化,初始学习率为0.001,权重衰减率为0.000 1,动量为0.9。此外,第60个和100个epoch,学习率下降为之前的0.1倍。
3.2 对比实验
文中在三个公开的细粒度图像识别的数据集上做了实验,分别是CUB200-2011[29],Stanford Dogs[31], Stanford Cars[32]。表1展示了最近的深度哈希方法与文中的检索方法的mAP比较,其中16位,32位,64位表示哈希码的长度。由表1可见,文中方法优于其他方法。无论数据集或哈希码的维数如何,文中方法都是最优的,并且在很大程度上超过了第二位。造成巨大差异的原因是文中方法是专为细粒度图像检索而设计的。其他深度哈希方法随着哈希码长度减少一半,其检索的mAP大大降低,而文中方法则不会。因此,文中方法擅长使用低维哈希码进行检索。
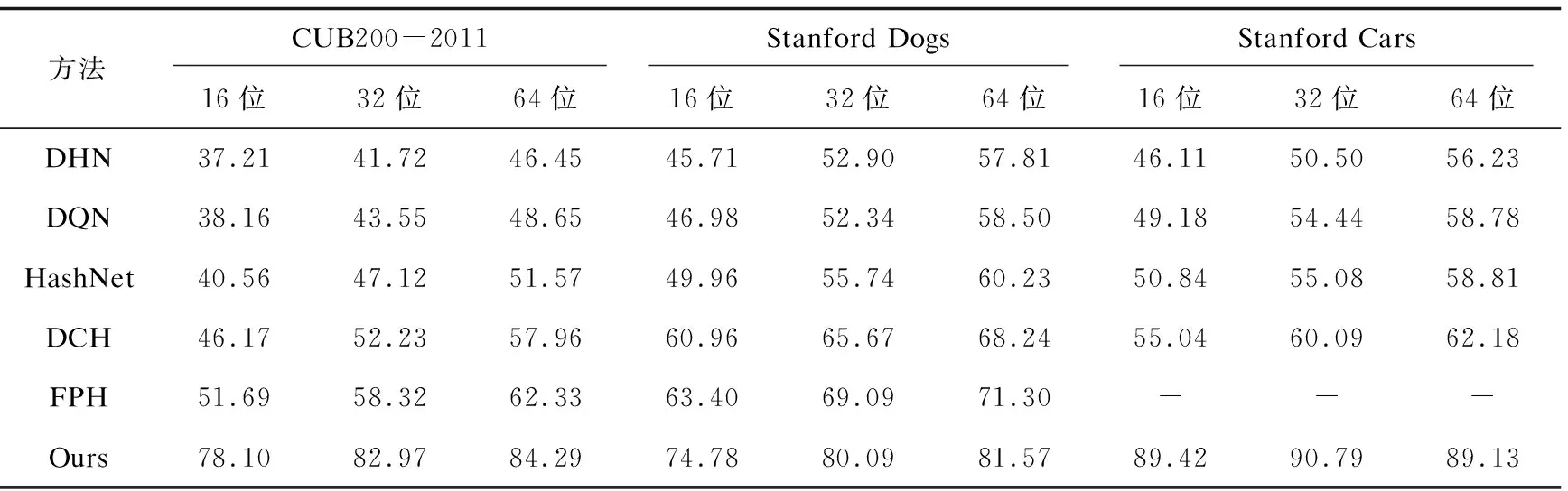
表1 各数据集上不同长度哈希码的mAP结果 %
此外,为了验证文中方法的优越性,表2记录了以上算法的网络模型大小和检索速度。由表2可见,文中方法不论在模型大小,还是检索速度上,都占有明显的优势。结合表1和表2,可以得到以下结论,在细粒度图像检索中,文中方法比其他深度哈希方法性能更佳,性价比更高。
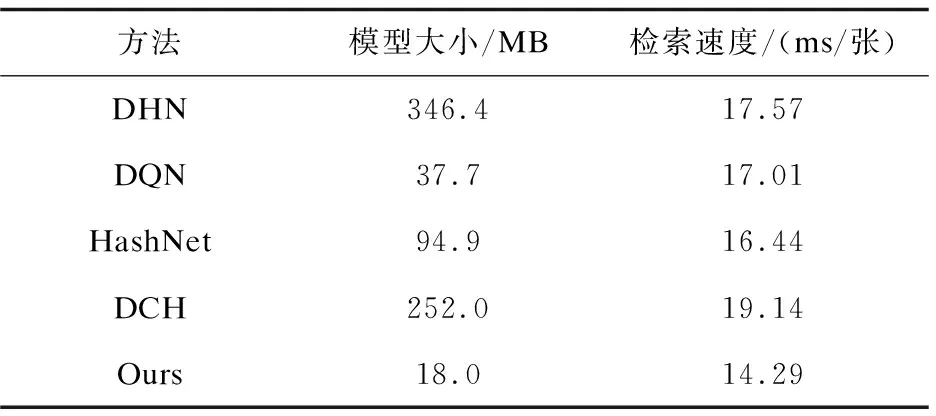
表2 深度哈希方法模型大小和检索速度比较
3.3 消融实验
针对文中的三个创新点,即(1)将复杂基础网络替换成轻量级网络;(2)跨层的多尺度Non-Local进行高低层特征融合;(3)哈希编码层前置,用简单有效的交叉熵损失指导参数更新,本小节在CUB200-2011数据集上,做了各个创新模块的消融实验,以验证每个模块的有效性,如表3所示。值得一提的是,表格第一行未添加任何子模块的网络即为NTS-Net,mAP为top1识别精度。实验中哈希编码长度为128位。

表3 各个模块的消融实验
4 结束语
文中提出了一种简单而有效的细粒度图像检索方法。模型由三个部分组成:特征提取器,哈希编码层和分类层。首先文中的基础网络替换成轻量级网络,并辅以跨层的多尺度Non-Local模块,不仅提升了细粒度图像检索精度,而且节约了大量的存储空间,以及提升了检索速度。其次,在分类层之前添加哈希编码层作为特征开关层,以指导最终分类。同时,保留交叉熵损失,而不是使用传统的具有高时间复杂度的成对或三元组相似性保留损失。所提出的检索模型的性能在三个公开数据集上进行了评估。实验结果表明,与其他先进的图像检索算法相比,文中方法在检索性能上具有明显的优势。接下来的主要工作将考虑将少样本学习与细粒度图像检索相结合,以便在现实中从部分可见类检索未见类。
