基于混合特征值的托攻击检测算法
2021-10-28雷梦宁丁爱玲王新美韩佳倩
雷梦宁,丁爱玲,王新美,韩佳倩,曹 苗
(长安大学 信息工程学院,陕西 西安 710061)
0 引 言
互联网时代的迅速发展,使“信息过载”现象愈发严重,寻找一种可以辨别有效信息的手段至关重要。随着用户对信息筛选的需求,搜索引擎应运而生,其通过在特定位置输入一些简单的关键词寻找与该关键词相关的信息。但其提供的海量信息仍需用户消耗大量时间精力去筛选。
推荐系统(recommender systems)[1-4]的出现有效缓解了信息过多带来的影响,其能够在海量的搜索结果中,依据用户的浏览记录、行为习惯、兴趣爱好等记录进行分析,为用户推荐最符合搜索预期的信息,从而缩短用户寻找有效信息的时间,为客户信息检索带来了极大的便利。其中,协同过滤(collaborative filtering,CF)作为推荐系统中最为有效的手段之一,广泛应用于生活中的各种领域,如Facebook、YouTube等。
推荐系统依靠其庞大的用户群体来为客户推荐较为准确的信息,一些商家利用该系统的开放性,通过注入大量攻击概貌[5]影响系统推荐结果,以此来提高或降低商品的系统推荐频率,从而谋取暴利。这种行为被称为托攻击(shilling attacks)[6-7]。其不正当的商业竞争行为造成系统推荐信息虚假或精确度不高等影响,偏离客户搜索预期。因此对托攻击进行防范检测具有重大的意义。
现有的托攻击检测方法对基本托攻击模型检测效果明显,文献[8-9]提出了一种基于特征分析的托攻击检测算法,可以针对不同类型的托攻击选取有效的检测指标,通过托攻击检测指标识别出攻击用户。但该方法不适合用在复杂的攻击模型下。文献[10]对推荐系统中现有的托攻击检测技术和鲁棒性能进行了分析,发现现有的检测算法大多是基于评分值差异提取的特征,容易造成误判率过高的问题。
受此启发,文中针对用户选择评分项目方式的不同,提出了一种基于混合特征值的托攻击检测算法。该算法考虑到项目流行度和新颖度的特性,选择了五项特征检测指标构建特征模型对托攻击进行检测。最后,通过在MovieLens数据集上的实验,验证该特征模型可以有效检测出攻击用户。
1 相关工作
1.1 攻击概貌
攻击概貌由攻击者的所有评分构成,包括四个部分[7]:填充项目集、选择填充项目集、未评分项目填充集、目标项目集。填充项目是攻击者选取其他评分项目进行填充,填充项往往是随机的,可以掩护目标项目躲避检测。选择填充项目是特定的,由攻击者精心挑选,进行有效攻击。即攻击用户除对目标项目进行评分外,还对其他项目进行评分,使得攻击用户与正常用户更加接近,增加检测难度。攻击概貌的结构如表1所示。

表1 攻击概貌的结构
1.2 攻击类型
文献[11]提出了随机攻击和均值攻击,其为两种基本的标准攻击模型,文献[12-13]提出了流行攻击、分段攻击和love/hate攻击。Gunes等[14]在流行攻击基础上,讨论了逆流行攻击等混淆攻击。不同攻击模型对推荐系统评分集所需的先验知识不同。表2列出了4种常见攻击模型的生成策略,其中IS代表选择填充项目集,IF代表填充项目集,IT代表目标项目集。

表2 四种攻击模型
表中,rmax表示在评分时给予最高分,rmin表示给予最低分,rrandom表示随机评分,raverage表示均值评分。由表2可以观察到,不同攻击模式的主要区别在于对装填项目的评分方式不同。
根据攻击用户信息的生成策略可知,攻击用户与真实用户不同之处主要体现在3个方面:①目标项目的评分;②填充项目的评分;③由于所有的攻击用户信息采用同样的生成策略,致使攻击用户信息之间具有高度的相似性。文中利用以上数据差异生成统计特征,提出基于混合特征的攻击检测算法,以此区分正常用户与攻击用户。
1.3 托攻击检测指标
特征指标用于捕捉攻击用户与正常用户在评分方式上的差异。文献[15-16]中定义的9个统计量从不同角度反映了攻击用户概貌有别于真实用户概貌的特征。
文献[8]针对流行攻击对统计量进行了研究,给出了有效检测指标排行,文中选择其前三项作为检测指标,如下所示:
(1)K近邻用户相似度(DegSim)。
在进行托攻击时,大量注入系统的攻击概貌往往具有相同的攻击模型,具有数量大,相似度高的特点,故攻击用户的此项特征值比真实用户高。DegSim的计算公式如下:
(1)

(2)均值方差(MeanVar)。
对用户评分项目进行均值方差运算,体现用户模型评分项目与所有评分项目平均值之间的二阶矩关系,第u个用户的MeanVar的计算公式如下:
(2)

(3)加权评分一致度(WDA)。
此特征值通过计算相应项目评分数目的逆向权重,以此衡量用户对项目的评分背离该项目评分均值的程度。第u个用户的加权评分一致度的计算公式如下:
(3)
其中,Nu表示用户u评价过的项目个数,NRi表示项目i被评价过的次数,ri表示项目i的评分均值,ru,i表示用户u对项目i的评分。
目前很多检测器通过计算出各个特征指标值,形成用户评分矩阵构建特征模型,以此作为属性对分类器进行训练,最终能够将真实用户和攻击用户进行分类。文中结合以上三个特征指标得到特征模型,绘制三维图,如图1所示,图中“+”代表攻击用户,即圆圈中的数据,“o”代表正常用户。由图可知该特征模型可以较好地区分真实用户和攻击用户,但部分攻击用户与正常用户数据重叠,存在一定误判率。
该特征模型在实际应用中准确率和召回率不够高,为进一步提高检测准确率,文中加入对项目流行度和新颖度的考量。考虑到项目流行度、项目新颖度以及攻击用户装填项目服从不同的概率分布,其所得到的用户平均流行度以及新颖度数值与正常用户的平均流行度以及新颖度数值始终具有差异,因此文中提出了两个新的特征检测指标,分别是检测项目与流行项目之间的卡方估计值(Chi-square of popular item,CHIP)和与新颖项目之间的卡方估计值(Chi-square of novel item,CHIN),通过这两个指标统计检测项目与所选的流行项目或新颖项目之间的相关程度。其中流行项目的选择依据项目流行度(item popularity,IPop),新颖项目的选择依据项目新颖度(item novelty,INov),其计算公式分别如下所示:
(4)
其中,Di表示所给数据库中所有真实用户的合集,rui表示用户u对任意一个项目i的评分。若rui=∅,则φ(rui)=0,若rui≠∅,则φ(rui)=1。
(5)
其中,|Dg|表示现在集合中的所有用户数目,Novu,i表示该用户对其任意一个项目的新颖程度,Nu表示用户u的项目评分数,也就是相似度。
流行项目以及新颖项目的卡方估计值通用公式如下:
CHI=|I|×
(6)
其中,I表示数据集中所有的项目,A表示既属于有评分项目又属于流行项目/新颖项目的个数,B表示属于有评分的项目但是不属于流行项目/新颖项目的个数,C表示虽然不属于有评分项目却属于流行项目/新颖项目的个数,D表示既不属于有评分项目的也不属于流行项目/新颖项目的个数。通过计算用户评分项目与新颖项目/流行项目之间的关联程度,得到特征矩阵。
2 K-means聚类算法
聚类作为统计数据分析中的一项重要技术,目前在各个领域得到广泛应用,如数据挖掘、机器学习等。它通过静态分类的方法,将更为相似的对象分到相同的组别,即该组别中的对象拥有较多相似的属性。
K-means聚类算法源于信号处理中的一种向量量化方法,其主要目的是将所给的样本数据聚类。其算法流程为:
(1)随机创建K个对象作为起始聚类中心;
(2)计算每个对象与K个聚类中心点之间的欧氏距离,将每个对象分到距聚类中心距离最短的类别中;
(3)重新对每一类中的对象进行计算,找到新的聚类中心点,重复(2)过程;
(4)直到聚类中心点的位置不再改变,样本聚类完成。
文中使用K-means聚类算法对攻击用户与真实用户集合进行初步分类。
3 基于混合特征值的托攻击检测算法
文中构建了一种新的特征模型,该特征模型由两部分组成:①由特征指标Degsim、MeanVar、WDA组成特征模型的第一层;②由特征指标CHIP和CHIN组成特征模型的第二层。在该特征模型的基础上提出了一种基于混合特征值的托攻击检测算法,将其命名为T-Kmeans算法。该算法的具体步骤如下:
步骤一:向用户评分矩阵注入攻击概貌,得到混合数据集;对其提取特征Degsim、MeanVar、WDA、CHIP、CHIN,并按列排序,得到用户特征向量矩阵V。
步骤二:提取特征向量矩阵V的前三列,即DegSim、MeanVar、WDA三个特征值,通过K-means聚类算法将用户初步聚成两类,称为第一真实用户集合和第一攻击用户集合。
步骤三:对特征矩阵V的后两列进行阈值判断操作;将大于阈值的标记为真实用户,小于阈值的标记为攻击用户,称其为第二真实用户集合和第二攻击用户集合;其中阈值的选择根据经验选择[17]。
步骤四:将步骤二、步骤三中得到的第一攻击用户集合和第二攻击用户集合做交集,得到最终检测结果,即攻击用户集合,剩余的用户则为真实用户集合。
算法流程如图2所示。
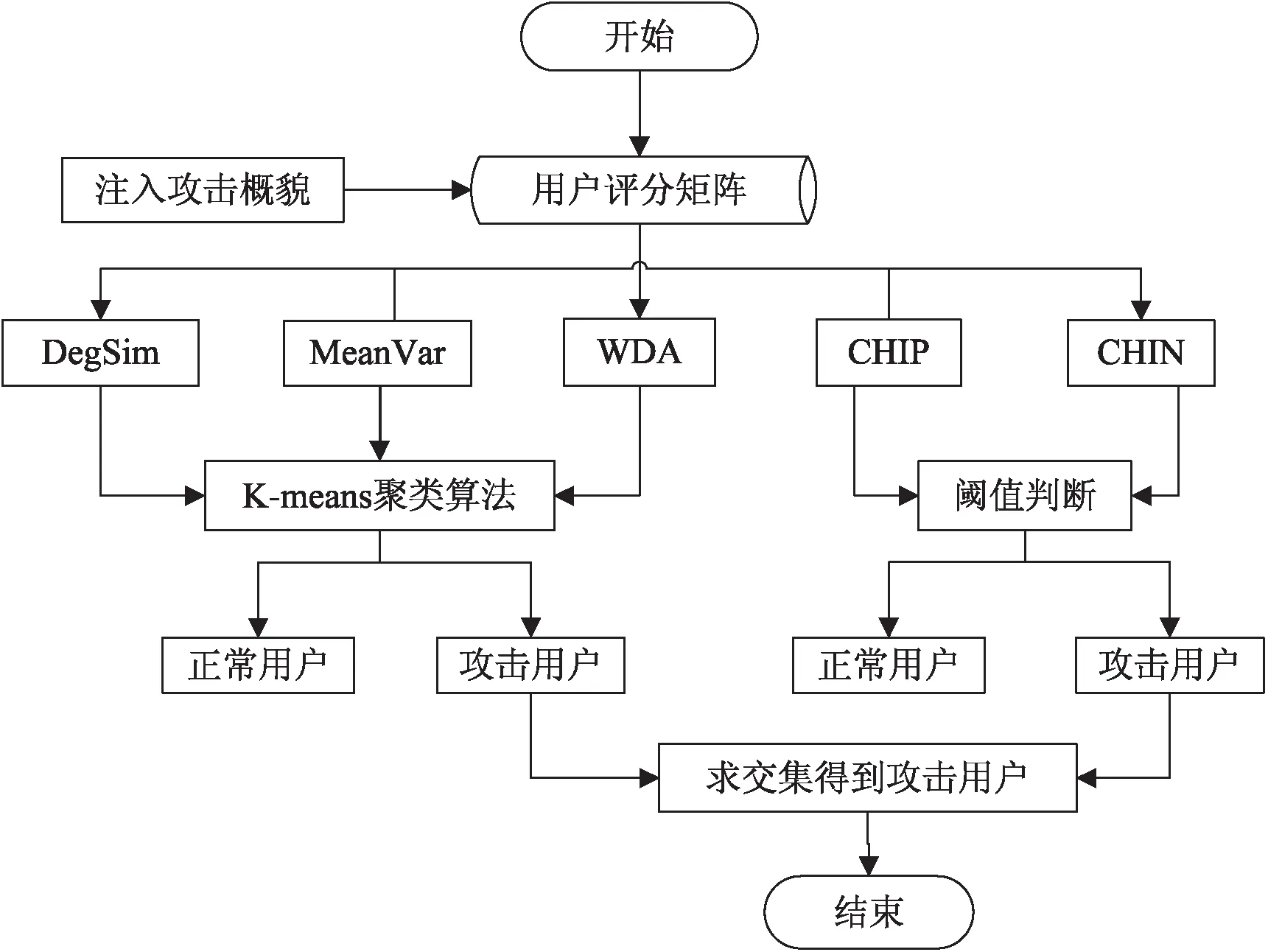
图2 T-Kmeans算法流程
4 仿真实验
文中实验采用Movielens数据集,包括943个观众对1 682部电影的随机评价,共计100 000条评分,采取5分制,即最高分记5分,最低分记1分,未评分的记为0。
实验选取的攻击模型为流行攻击,攻击目的为推攻击。分别在攻击规模为3%,5%,8%,10%,12%,填充规模为3%,5%,8%,10%的条件下进行实验。
4.1 算法评估标准
文中通过计算准确率(precision)和召回率(recall),与主成分分析(principal components analysis,PCA)检测方法进行对比,以此评估T-Kmeans检测算法的有效性与准确率。其计算公式如下:
(7)
(8)
其中,TP表示被正确识别的攻击用户的数目,FP表示被误判的真实用户的数目,FN表示未被识别出来的攻击用户的数目。
4.2 实验结果与对比
4.2.1 准确率对比
将文中提出的检测方法的准确率与PCA检测算法的准确率进行对比,得到的实验结果如图3(a)~(d)所示。
如图3所示,在填充规模分别为3%、5%、8%、10%的情况下,随着攻击规模的增大,PCA检测算法和 T-Kmeans检测算法的准确率都在持续增加,但T-Kmeans检测算法准确率一直比PCA检测算法准确率高,且最高时候可达到98%,这说明在小规模攻击情况下T-Kmeans检测算法在准确率方面比PCA检测算法效果好。
4.2.2 召回率对比
将文中检测方法的召回率与PCA检测算法的召回率进行对比,得到的实验结果如图4(a)~(d)所示。
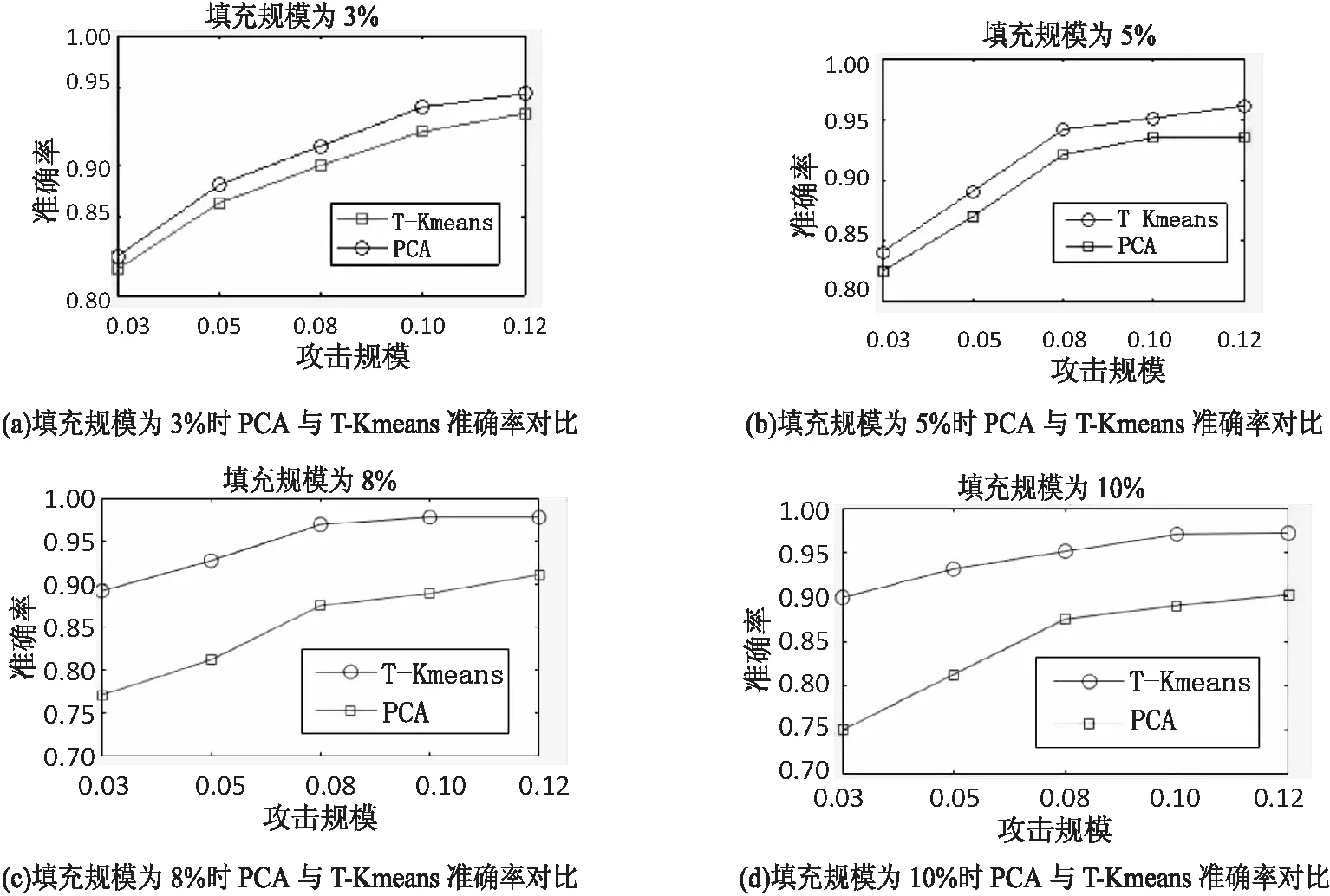
图3 T-Kmeans与PCA准确率对比
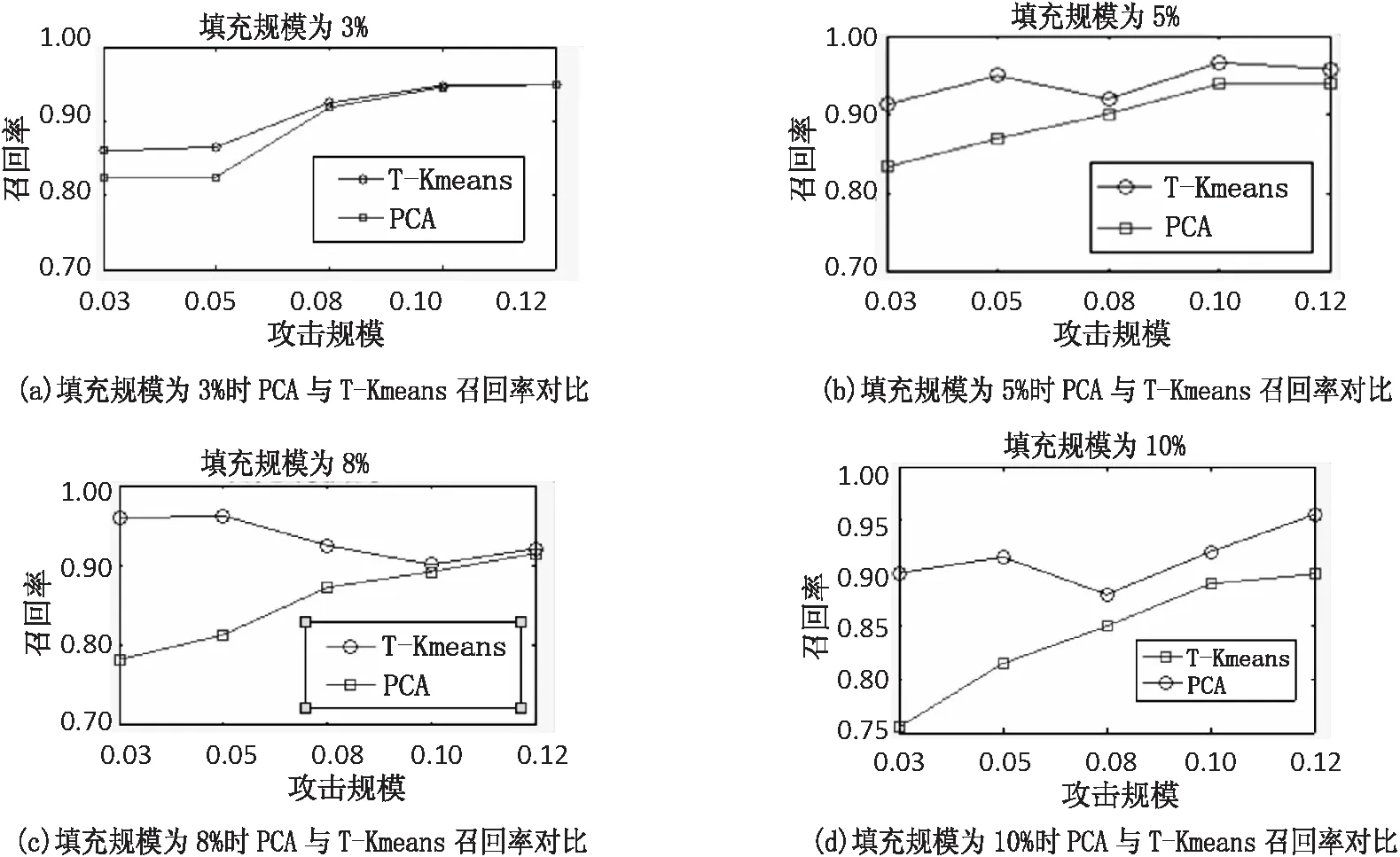
图4 T-Kmeans与PCA召回率对比
如图4所示,在填充规模分别为3%、5%、8%、10%的情况下,随着攻击规模的增大,T-Kmeans检测算法的召回率变动较大,但其一直比PCA检测算法的召回率高,且最高时候可达到97%,这说明T-Kmeans检测算法在召回率方面比PCA检测算法的检测效果好。
5 结束语
文中提出了一种基于混合特征值的托攻击检测算法。该算法构建了一种新的特征模型,在传统Degsim、MeanVar、WDA这三个特征检测指标基础上,考虑到项目与流行项目、项目与新颖项目之间的关联程度,引入CHIP,CHIN检测指标,构成特征模型。通过对Degsim、MeanVar、WDA形成的特征矩阵进行K-means聚类,以及对CHIP、CHIN形成的特征矩阵进行阈值判断,并进行求交集操作,得到最终检测出的攻击用户集合。实验结果表明,该算法提高了检测准确度,具有一定的优越性。
