人工智能算法与Logistic回归在肠道准备预测中的应用
2021-10-22邓少琦林丹丹刘鑫杰柴芳时陈杰桓
邓少琦,林丹丹,刘鑫杰,柴芳时,陈杰桓
肠镜检查前的肠道准备一直是内镜领域中一个受人关注的话题,良好的肠道准备能提高腺瘤检出率,减少漏诊,降低结直肠癌发生的风险[1]。国内外对于影响肠道准备因素的讨论非常多,其中包括以下各种人口学特征或临床特征:性别、年龄、体重指数、糖尿病病史、便秘病史、饮食习惯等[2-3],但这些研究尚未建立一个系统的预测模型。因此基于简单的人口学特征或临床资料,建立准确有效的风险预测模型,有助于筛查出肠道准备不足高危人群。近年来随着人工智能学科的风靡,与其相关的机器学习及深度学习的算法被带到包括医疗等各个领域[4]。我们尝试利用多种人工智能算法对肠道预测问题进行分析,并和经典的logistic回归算法进行对比,选出最佳的统计学模型,并从中探讨两类算法在临床研究中统计分析中的优缺点。
1 资料与方法
1.1 一般资料
选取2019年1月至2019年7月来我院区行结肠镜检查的门诊及住院患者作为训练集队列,2019年8月至2019年12月就诊的患者为验证集队列。纳入标准:年龄18~80岁,性别不限。排除标准:①患有肠道肿瘤、肠梗阻;②未严格执行本研究规定的肠道准备方案;③严重的心脑血管等基础疾病;④必要的信息资料不全。
1.2 肠道准备方法
检查前一天晚餐建议在20:00前进食完毕,20:00后禁食但可饮水,禁水时间为检查当天早上06:00。检查前天晚上21:30服用第一次泻药:和爽1包加水1 000 mL饮用,在1 h内喝完,饮完后可以继续饮水。服用泻药期间请多走动,顺时针按摩腹部,以促进排便。检查当天凌晨04:00左右再次服用泻药:和爽2包加水2 000 mL饮用,在1.5 h饮用完毕,饮完后继续饮水500~1 000 mL。检查当天早上06:00后禁水。
1.3 观察指标及判定标准
1.3 结局变量及预测变量的设定
结肠镜诊疗前,使用波士顿评分标准(boston bowel preparation scores,BBPS)[5]评估患者肠道准备质量。研究以波士顿评分为结局变量,总分≤6定义为肠道准备不佳,为准备不佳组;将7~9分定义为肠道准备充分,为准备充分组。本研究根据既往研究报道[6-8],尽可能地纳入更多影响肠道准备的预测因素,其中包括年龄、性别、BMI指数、有无便秘病史、服用泻药后不适症状等19个变量,其中便秘的等级分类依据来自于我国的2019年的《中国慢性便秘专家共识意见》[9];服泻药后不适症状定义为完全服用泻药1小时候后所出现的恶心、腹胀、呕吐三种由轻到重的症状,如果同时出现两种或以上症状,则分类编码取较严重者;检查间隔时间定义为最后一次排便至接受检查的时间间隔,根据我科既往的研究,将其分为四个时间段[10]。对患者的宣教方式则结合我科实际情况及既往的荟萃研究进行分类[11]。变量类型为二分类或有序多分类(表2)。资料的收集通过门诊病历系统回顾性收集或电话随访所得。
1.4 样本量的估算
本研究为回顾性病例对照研究,采用的核心统计学方法是logistic回归建模。根据Courvoisier等[12]研究,采用基于最大似然估计(MLE,maximum likelihood estimate)的Wald方法时,结局事件需要在预测变量的10倍以上时,才可保证回归分析结果稳健。本研究纳入了19个预测变量,最后训练集队列纳入455例研究对象,其中准备不佳组有195例,准备充分组有260例;纳入验证集队列302例,其中准备不佳组有134例,准备充分组有166例。共纳入病例数757例。
1.5 统计学处理
所有数据的处理使用R3.4.3和SPSS24软件完成,主要用到的R包有‘glmnet’、‘dplyr’、‘caret’、‘neuralnet’[13]等,双侧检验P<0.05表示差异具有统计学意义。①统计描述及单因素分析:本研究所纳入的预测变量及结局变量均为二分类或有序多分类资料,在基线特征描述时采用卡方检验对比两组间差异。②构建logistic回归模型:在单因素分析中筛选出有意义的预测变量,建立向前逐步Logistic回归模型。用logistic回归后调整混杂后得出有意义的变量,以其β系数值最小的变量为基准,每个子得分是logistic回归模型的β系数除以此系数后,并四舍五入最接近的整数值,得出肠道准备预测评分系统。④人工智能算法建模:调用neuralnet、rpart、randomForest、e1071程序包,分别建立神经网络、分类树、随机森林、支持向量机模型。⑤对比分析Logistic回归模型和几个人工智能算法模型的AUC和NRI。R软件版本为3.4.3,神经网络设定中,考虑到纳入的特征变量有19个,训练集为455例,所以网络中权重矩阵中的系数不应大于455,否则权重系数难以训练。所以设置两层隐藏层,每层5个神经元,一个输出层,两个神经元对应二分类任务。输入层与第一层的权重系数矩阵为(19,5),第一层隐藏层与第二次隐藏层的权重系数矩阵为(5,5),第二层隐藏层与输出层的权重系数矩阵为(5,2),加上每层的偏置,共有142个系数。每层间的激活函数选用sigmoid函数,随机数种子设定为99。
2 结果
2.1 训练集队列与验证集队列
进入研究的患者分为455例训练集队列与302例验证集队列,患者变量特征所占比例如表1。
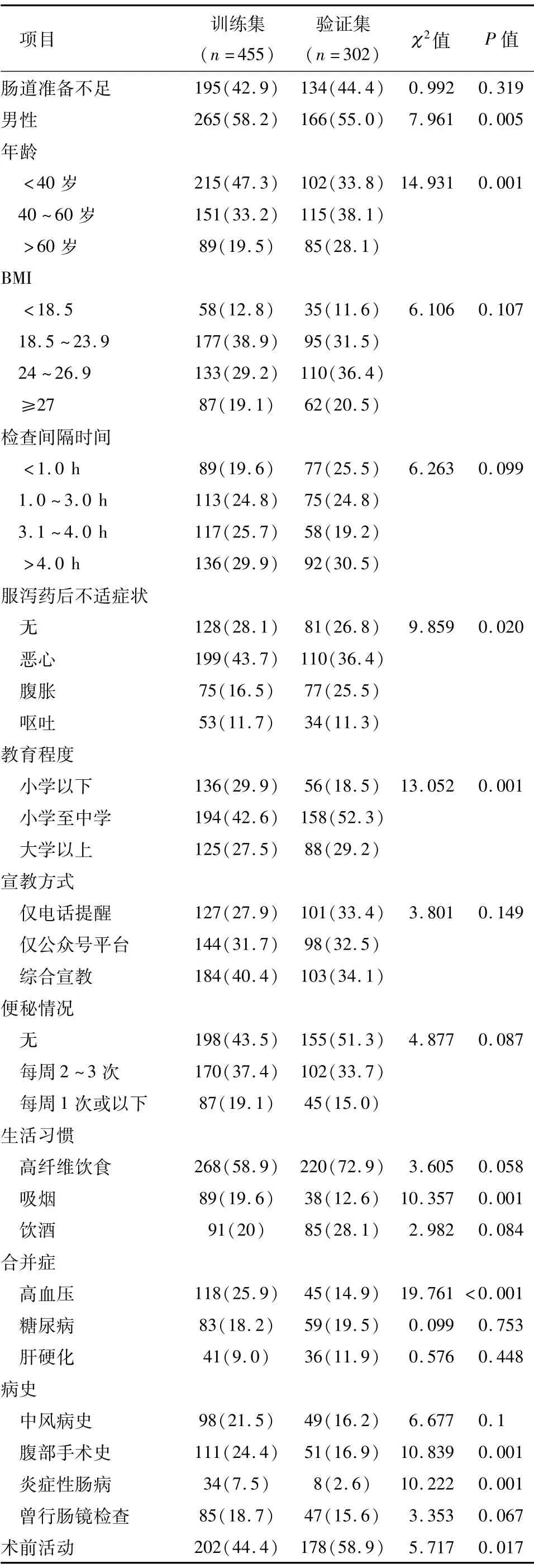
表1 训练集队列与验证集队列的变量特征[n(%)]
3.1 训练集队列一般基线资料
在单因素分析中(表2),BMI指数、最后一次排便至开始检查的候诊时间、服泻药后不适症状、患者教育程度、宣教方式、饮酒习惯、术前有无高纤维饮食、糖尿病、肝硬化、中风病史病史、腹部手术史、便秘情况、术前有无活动13个预测变量与肠道准备不足相关(P<0.05)。
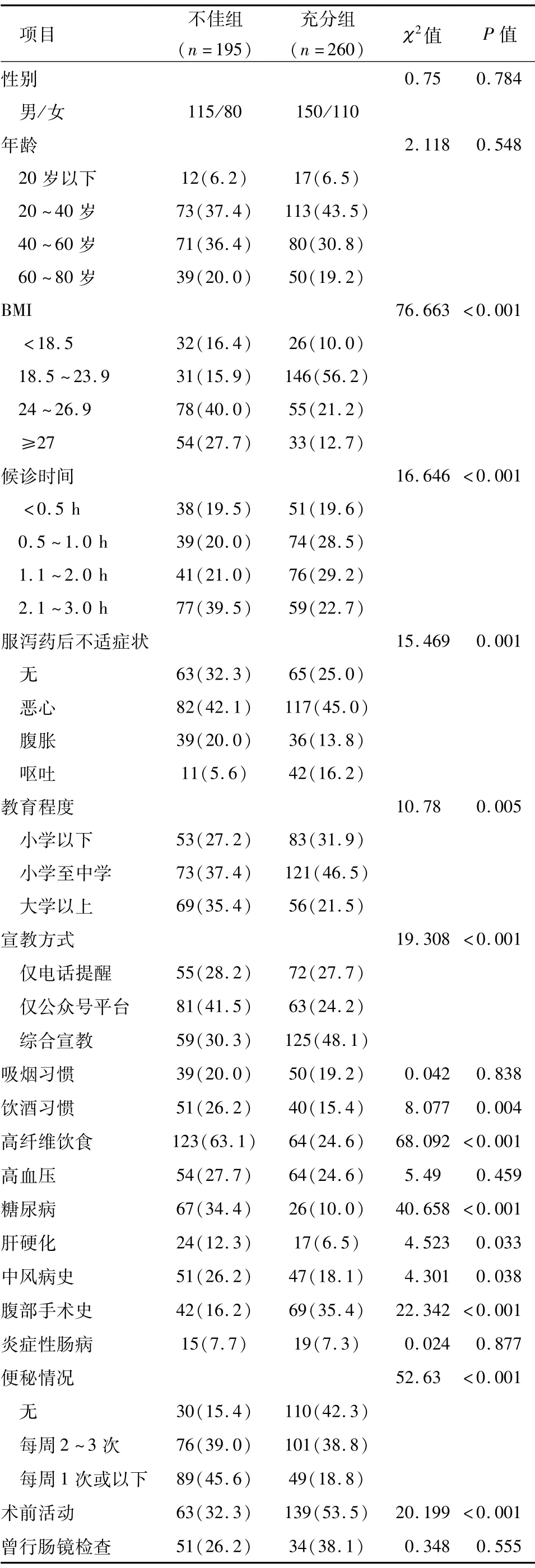
表2 训练集队列基线资料
3.2 训练集的多因素分析
经logistic回归进行混杂因素的调整后,发现BMI、服泻药后不适症状、宣教方式、便秘情况、术前是否高纤维饮食、糖尿病病史、术前积极活动7个预测变量为影响肠道准备的独立因素,其中术前高纤维饮食与积极活动是保护性因素。根据BMI为24~26.9的系数值(β=0.81)为基准,每个独立危险因素的子得分是logistic回归模型的β系数除以此系数后,并四舍五入最接近的整数值,得出肠道准备风险评分表。(表3)
3.4 评分与肠道准备质量
根据logistic回归模型的公式定义,可得出每个分值所对应的肠道准备不佳的概率。评分系统的范围为0~12分,可分为低分险组(0~3分),其准备不佳的概率在10%以下;中风险组(4~6分)为21.3%~66.9%;高风险组(7~12分)为77.5%~99.6%。当评分≥9分时,肠道准备不佳的概率已接近100%(图1)。
3.3 各模型比较
在几个模型中,神经网络的表现最佳,其验证集AUC值0.885,其次是随机森林,Logistic回归居第三。随机森林模型相比Logistic回归的NRI为0.08(P>0.05),两者AUC间差异无显著统计学意义。神经网络NRI为0.18,且P<0.05,具有统计学显著性,提示神经网络的预测能力优于Logistic回归模型,正确分类的比例提高了18%。见表4。

表4 人工智能算法与Logistic回归模型的预测性能比较
3 讨论
目前国内外对于预测结肠镜检查前影响肠道准备危险因素的研究虽然比较多,但很多方面尚存争议。造成这个问题的原因,除了有研究设计的因素也有统计学层面的因素。影响肠道准备的危险因素数量众多,彼此间相互联系,很可能存在共线性问题。多重共线性(Multicollinearity)是指回归模型
中的解释变量之间由于存在较精确相关关系或高度相关关系而使模型估计失真或难以估计准确。譬如年龄、便秘、糖尿病几个因素间在现实情况下就存在共线性,老年人更容易出现便秘或糖尿病。
既往大部分研究[14-15]都认为便秘是影响肠道准备质量的重要因素,但也有研究持相反意见[16]。Yadlapati等[3]也认为便秘不是危险因素,而较低的经济水平(OR,1.11;95%CI,1.04~1.22)、服用鸦片类药物或三环抗抑郁药(OR,1.55;95%CI,0.98~2.46)、在下午行结肠镜检查(OR,1.66;95%CI,1.07~2.59)是影响肠道准备差的危险因素。与许多文献的结论一样[17],我们的研究也认为便秘是影响肠道准备的关键因素,相比没有便秘既往史的患者,每周排便1次或更少的患者其OR为8.508(95%CI:3.047~23.915)。
我们也发现糖尿病和术前活动不充分与肠道不足密切相关(OR:5.233;95%CI:2.458~16.488)。这可能是糖尿病增加了细胞氧化、凋亡,使肠道运动神经元受损,导致胃肠道运动功能下降,最终导致便秘[18]。糖尿病患者的便秘既有慢传输型便秘,肠道本身蠕动能力削弱而引起的便秘,患者腹胀、便秘、缺乏便意;又有出口梗阻型便秘,在排便时肛门不能正常松弛,患者有排便感觉,但大便费力、排不出[19]。另一方面,活动不充分的患者一般年老体弱,合并便秘和其他基础疾病。
与其他研究不同的是,我们认为便秘作为胃肠动力障碍的一种表现,可能与多种因素相关,例如长期使用阿片类药物、抗胆碱能药物,合并中风、糖尿病、年龄等。也就是说便秘这个危险因素可能和多个因素有交互作用,当研究把这些因素都纳入分析时,可能会均摊降低了便秘的作用,从而低估了便秘的风险。我们的研究并没有纳入影响便秘的药物服用史,因而便秘的OR值其他研究高。
根据一项荟萃研究分析认为[20],比起高剂量的肠道清洁方案,患者对于低剂量或分次剂量的肠道清洁方案的依从性或完成率更高(RR,1.06;95% CI:1.02~1.10),耐受性也更好(RR,1.39;95% CI:1.12~1.74)更好,这可能是患者在使用低剂量或分次剂量的肠道清洁方案时更不容易出现呕吐等不适症状。我们的研究发现患者服用泻药后出现呕吐的不适症状会影响肠道准备质量(OR:3.058;95%CI:1.725~7.122),这可能是出现呕吐症状会严重影响患者的依从性及服用的泻药剂量,从而最终导致患者肠道准备不足。
为了进一步量化评估各独立因素对肠道准备质量的影响,我们建立了基于logistic回归的评分系统,其AUC为0.823,其预测性能良好。同时我们也建立了多个人工智能算法模型与logistic回归模型比较,分析各自优点与缺点。人工智能的概念很宽泛,机器学习是人工智能的一部分,而深度学习又是人工智能的一部分。而统计学则是和这三者有较大的区别。诺奖得主萨金特和任正非都有过类似的观点:人工智能就是统计学,只不过套用了华丽的辞藻[21]:如果一个程序可以在某个任务上,随着经验的增加,效果也可以随之增加,则称这个程序可以从经验中学习。logistic回归这种广义线性模型是根据数据分布进行曲线拟合[22],而神经网络等人工智能算法更像一个黑箱,通过验证集反馈修改建模细节,建立与前者截然不同的非线性模型[23]。
如何筛选出真正影响结局的因素、变量,在传统的临床研究中可以通过单因素及多因素配合的方法,选定p值的阈值,并结合专业理解,从而筛选出独立的影响因素。这个过程在涉及机器学习、深度学习算法的领域中,则称之为“特征选择”。常见的特征选择方法大致分为三类:过滤法(filter)、包裹法(wrapper)和嵌入法(embedding)[24]。过滤法是按照特征的发散性或者相关性指标对各个特征进行评分,文中通过结合P值的假设检验就是其中一种[25]。包裹法是根据目标函数,通常是预测效果评分,每次选择部分特征,或者排除部分特征[26]。通俗地说,就是哪些预测变量的预测准确率高,就选择哪些预测变量。本研究的几个人工智能算法模型都采用了包裹法进行特征选择,多个模型在纳入全部19个变量时有着最好的预测效果,证明它们能更好地提取数据内容,处理多重共线性问题更有优势。嵌入法则使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据权值系数从大到小来选择特征[27]。目前在临床研究中较常见的Lasso回归是其中之一。
在本研究中,神经网络能同时纳入19个变量,模型的预测性能较logistic回归稍好,证明其能更好地提取数据内容,处理多重共线性问题更有优势。然而它不能提供具体的模型细节,为结局事件及各影响因素提供具体的参数。相比之下,logistic回归建模过程较简单,而且能提供详细的模型参数,为临床提供有价值的指导意见[28]。但它在建模前需要一定的数据预处理,譬如要用合理的方法筛选进入模型的变量、处理好连续性变量及分类变量间的关系等。另一方面,logistic回归在处理多重共线性和交互作用问题上不如神经网络。在临床研究中,涉及的数据多为结构化的数据结构表格,更适合传统的统计建模方法,人工智能算法优势并不明显。而在工业领域,譬如计算机视觉识别模型或自然语言处理方面,所涉及的数据多为矩阵结构,数据量庞大,且以预测效果为向导,神经网络等模型能发挥更大的价值[29]。
综上所述,我们建立的logistic回归模型能提供各变量间的参数细节,为肠道准备预测提供详细的评分,可用于临床推广。对比之下,神经网络模型预测效果更好,可为我们目前正在进行的以图像为研究数据的肠道准备视觉识别模型提供理论依据。本研究也存在一定的不足,例如在神经网络建模时,没有对隐藏层、激活函数、损失函数等超参数做更细致地处理。另外,本研究为单中心研究,纳入的研究对象有来自门诊和住院的患者,影响了研究结论的外推性。本研究最为回顾性对照研究,预测变量的测量来自于肠镜检查后的问卷或电话随访调查,不可避免造成一定的回忆偏倚。
