基于稀疏索引和哈希表的访问控制策略检索方法
2021-10-19王东升刘嘎琼
高 瑞,韩 斌,王东升,刘嘎琼
(江苏科技大学 计算机学院,镇江 212100)
访问控制是一种安全技术,用于规范主体对客体的访问,内容包括主体认证、控制策略实现和安全审计[1].其中控制策略被用于判断主体对客体的某些访问操作是否能够被执行,它依托于访问控制模型而存在.常见的访问控制模型有:自主访问控制模型(discretionary access control,DAC)[2],基本思想是系统中的主体可以完全自主地将其对客体的权限授予给其他主体,具有自主性强、灵活性高的特点;强制访问控制模型(mandatory access control,MAC)[3],基本思想是系统安全管理员为每个用户授予客体某一级别的访问许可证,具有安全性强的特点;基于角色的访问控制模型(role-based access control,RBAC)[4],基本思想是将用户与角色关联,角色与权限关联,用户通过角色获得访问权限,具有方便权限管理的特点.
随着大数据和云计算的快速发展,云计算环境下的数据安全访问问题变得日益突出,传统的访问控制模型如DAC、MAC和RBAC等无法完成对主体动态授权和对客体细粒度访问控制.针对上述问题,文献[5]提出基于属性的访问控制模型(attribute-based access control,ABAC),该模型通过引入实体属性概念,把主体属性、客体属性、环境属性进行搭配作为对主体进行动态授权的依据,通过制定策略对客体进行细粒度访问控制,因此在云计算环境下ABAC模型拥有更强的适应能力.
近年来研究人员对ABAC模型下的策略表示形式[6-8]和策略检索方法[9-11]进行了多方面的研究.文献[6]利用XML语言对策略进行表示,能够容易地表示复杂策略;文献[7]利用决策图表示策略,能够直观地展示策略内部属性的限制条件;文献[8]对策略进行了形式化描述,能够更好地反映属性和属性值之间的关系且有利于策略检索的实施;文献[9]通过对策略表进行冗余规则处理并利用基于语义树的策略索引来提高策略检索的效率;文献[10]通过对策略表实施规则精化,缩减策略规模并采用多种缓存机制来提高策略检索的性能.其中文献[9]和文献[10]针对的是用XML语言描述的策略且引用了第三方的策略评估引擎,所以在实施方面会受到平台和框架的限制.文献[11]提出了一种基于前缀标记的策略检索方法(下称,标记检索法),通过将访问请求与访问控制策略的前缀标记进行位运算,从而快速定位策略位置.文献[8]对文献[11]的方法进行了改善,提出了基于属性分组的访问控制策略检索方法(下称,分组检索法)将前缀标记中的主属性标记进行分组,从而缩小策略检索范围.文献[8]和文献[11]用前缀标记表示策略中的属性会对策略格式要求较高,具体表现在进行检索之前,策略中的属性要严格按照规定顺序排列好并且策略中没有被要求的属性也无法在策略中缺省,否则策略中的属性无法与前缀标记中的数值一一对应,这使得策略中的冗余属性较多,检索效率降低.并且没有考虑到在实际应用中访问局部性原理[12],会造成访问请求重复出现情况,从而进一步消耗策略的检索时间.
针对上述问题,文中使用形式化语言对策略进行描述并且提出了基于稀疏索引和哈希表的访问控制策略检索方法(下称,多级检索法)来解决策略检索效率较低的问题,利用策略表生成哈希缓存表、稀疏索引哈希表和稠密索引表来构建一个多层级的检索体系,缩小检索范围,提高检索效率.
1 相关知识
1.1 ABAC模型
ABAC是一个通过对系统中实体属性进行计算从而得出主体是否能对客体进行访问的访问控制模型.实体属性指的是ABAC中的主体属性(Subject)、客体属性(Object)、环境属性(Environment)和操作属性(Permission),所以通常用四元组(S,O,E,P)来描述ABAC模型.在ABAC模型下,主体访问客体的过程如图1.步骤1:主体对客体发起访问请求;步骤2:ABAC访问控制机制评估收集到的主体属性、客体属性、环境属性和策略通过计算进行决策;步骤3:根据决策结果判断主体能否访问客体.

图1 主体访问客体过程Fig.1 Process of subject access to object
步骤2中决策的过程其实就是利用收集到的主客体属性和环境属性到策略表中检索到对应的策略并且进行匹配的过程,所以策略检索是ABAC模型实施的重要环节,而策略检索的效率将直接影响到ABAC模型的实用性.
1.2 策略检索
访问控制策略是系统对访问请求属性和属性值的要求,通常描述访问控制策略的形式有3种:访问控制策略描述语言XACML;逻辑上的形式化;策略决策图.文中采用形式化的方式来描述策略.
策略在形式上是由多个键值对构成,键值对中的键是属性名称,值是属性名称的取值范围.为了区分不同类别的属性,主体属性以s为标识,客体属性以o为标识,环境属性以e为标识,操作属性以p为标识.对策略进行形式化定义[8].
定义1属性键值对.用avp表示:avp⟸(AttrName=Value).
定义2属性谓词值对.用apvp表示:apvp⟸(AttrName∝Value).其中:AttrName为属性名称,Value为属性的取值,∝为关系运算符,∝∈(≤,≥,<,>,=,≠).
定义3基于属性的访问请求.用request表示:request={avp1,avp2,…,avpn}.
定义4访问控制策略.用policy表示:policy=auth⟸{apvp1,apvp2,…apvpn}.其中:auth∈(grant,deny),grant表示这是一条正向授权策略,deny表示这是一条负向授权策略.
定义5属性匹配.当request的属性集合包含policy的集合,且在属性名相同的情况下,request的属性值符合policy属性取值范围的要求.
访问控制策略检索是系统在策略表中查找是否存在一条策略使得访问请求能够满足这条策略的属性及其属性值的全部要求.如果访问请求中的属性和属性值满足了策略表中的某条策略对属性和属性值的要求并且此条策略是正向授权策略,那么发起访问请求的主体就可以执行自己请求的操作.这里将策略分为正向授权策略和负向授权策略是为了缩减策略检索的范围,如果访问请求与负向授权策略匹配成功,则在策略表中立即停止检索,拒绝请求.
通过举例说明直接检索法,标记检索法,分组检索法在检索过程中的差异,其中:policyn表示策略表中的第n条策略,简写为pyn;name简写为n;auth简写为a;grant简写为g;deny简写为d;sq,eq,cq分别为环境,客体,操作属性变量,其中q为正整数;x为删除文件;r为读文件;w为写文件;m,n,i,j,c,b,k,y,f为字符患或常量.

表1 ABAC部分策略表
若request={s2=a, s8=f, e9=33,o1=1,p3=r,p4=w},直接检索法将request与策略表中策略进行逐条比较,首先s2=a不满足py1中SA中的要求,检索下一条py2,发现request不满足SA中s3=b的要求,继续检索下一条,发现request满足py3的所有属性及其对应的属性值的要求,匹配负向策略py3,但是py3中的auth值为deny,所以request被拒绝.直接检索法的不足之处在于每次都是将request和py的属性和属性值一起比较,因为大部分py属性与request属性都会匹配失败,所以在进行策略检索时会浪费很多比较属性值的时间.标记检索法改善了直接检索法的不足,将py属性先抽取出来与request的属性进行匹配,若属性匹配成功才会继续匹配属性值.这时将request的属性s2、s8、e9、o1、p3、p4与py1的属性s3、s7、e3、o1、o3、p2进行属性匹配,发现s2不满足py1的属性要求.检索下一条,发现py2要求s3=b,但request没有s3这个主体属性,所以继续检索下一条,发现request的属性s2、s8、e9、o1、p3、p4与py3的属性s8、p4匹配成功,这时继续比较值,发现属性值也匹配成功,匹配负向策略py3,访问请求被拒绝.标记检索法的不足之处在于每次检索时仍然和直接检索法一样对策略表进行逐条查找,所以系统想要检索的策略在策略表中的位置对检索效率影响较大.并且两种方法都没有对可能多次出现的访问请求做缓存处理.
2 策略检索方法
针对直接检索法和标记检索法在策略检索范围缩减和重复的访问请求处理方面的不足,多级检索法构建了一个多层级的检索体系,缩减策略检索范围,并且对访问请求及其授权结果进行缓存.通过稀疏索引表来缩减策略表中需要检索的范围,采用哈希表作为缓存快速判断访问请求是否已被检索过,避免相同的访问请求重复检索造成时间浪费,提高检索效率.
2.1 生成稀疏索引表
生成稀疏索引表的过程如图2.

图2 稀疏索引表的生成过程
将策略表中每一条策略的所有属性及其对应的索引值抽取出来放到稠密索引表中,其中稠密索引表中listKey列中内容源于策略表中的policy列,policyIndex列与策略表中index列一一对应,attrNum列是对listKey列中的属性个数进行统计.将稠密索引表中index列和attrNum列的部分记录抽取出来,放到稀疏索引表中,其中稀疏索引表中sparseAttrNum列是稠密索引表中attrNum列去除了重复数值的集合,sparseIndex列是稠密索引表attrNum列中被抽取的记录所对应的index数值.在图2中,policyIndex简写为pI;index简写为i;attrNum简写为aN;sparseAttrNum简写为sA;sparseIndex简写为sI.
2.2 用哈希表优化策略检索过程
为了进一步提高策略检索效率,缩减策略检索范围,文中检索方法采用了两张哈希表,第一张将已经生成的稀疏索引表转换成哈希表,第二张将哈希表作为策略检索过程中的缓存来使用.图3是用哈希表存储稀疏索引表的数据,在查找时可以避免遍历整个稀疏索引表,利用哈希表中的attrNum_key直接获取index_value.在图3中,attrNum_key简写为ak;index_value简写为iv.
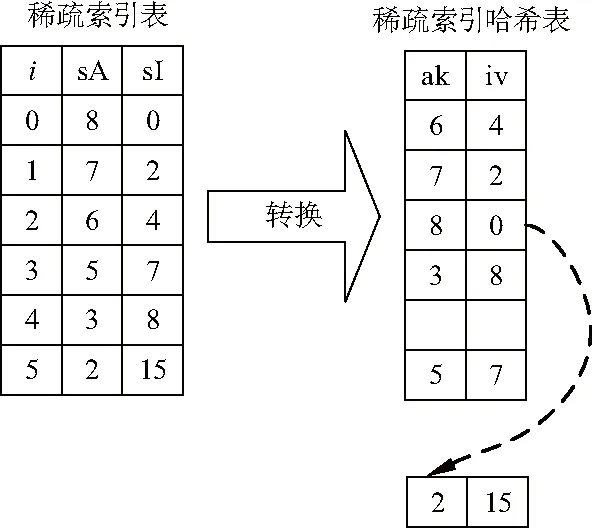
图3 稀疏索引哈希表的生成过程Fig.3 Process of generating sparse index hash table
图4是用哈希表作为所有访问请求的缓存表,其中hashKey存储的是requestn的内容,当访问请求满足了策略集中某一条策略的要求且此条策略是正向策略,则hashValue存储auth=grant,如果访问请求不能满足策略集中任一策略要求或此条策略是负向策略,则value存储auth=deny.

图4 哈希缓存表Fig.4 Hashcache table
2.3 基于稀疏索引和哈希表的策略检索举例
通过具体例子阐述多级检索法的检索过程,如图5,其中requestn简写为reqn.

图5 多级检索过程Fig.5 Process ofmultilevel retrieval
给定4条不同类型的访问请求,如表2.

表2 访问请求表
request1检索过程如下:首先检查哈希缓存表中是否已经存储request1,此时哈希缓存表为空,所以没有存储,将request1作为hashKey存储到哈希缓存表中,hashValue默认存储auth=grant;然后计算出request1中不重复属性个数的值是7,查找稀疏索引哈希表中ak=7所对应的iv=2,直接定位到稠密索引表中的i=2的位置,检查request1中的属性是否满足listKey中属性要求,发现{s4,e1,e4,r3,p9,p20,p30}⊄{s1,s2,e1,e2,o1,o3,p1},所以不满足本条策略的要求,继续检索下一条策略,发现{s1,s2,e1,e2,o1,o3,p1}⊂{s1,s2,e1,e2,o1,o3,p1},满足要求,pI=0,则定位到策略表中i=0时对应的policy,发现request1中的属性值满足本条policy的要求且auth=grant,正向策略匹配成功,通过请求,不用更新hashValue值.
request2的检索过程与request1的检索过程基本一致,但request2所匹配policy的auth值是deny,负向策略匹配成功,拒绝请求.最后将auth=deny更新到哈希缓存表中request2所对应的hashValue中.
request3的检索过程如下:检索哈希缓存表中是否已经存储request3,发现request3就是request1,直接获取对应的hashValue值为auth=grant,正向策略匹配成功,请求通过.
request4的检索过程与request1的检索过程基本一致,但是检索到策略表发现request4中的o7=10不满足策略表中i=13所对应policy的o7≤0的要求,所以要回到稠密索引表中向下检索,发现request4不能满足下一条策略的属性要求,没有匹配成功,拒绝请求.将auth=deny更新到哈希缓存表中request4对应的hashValue中.
多级检索法的流程如图6.
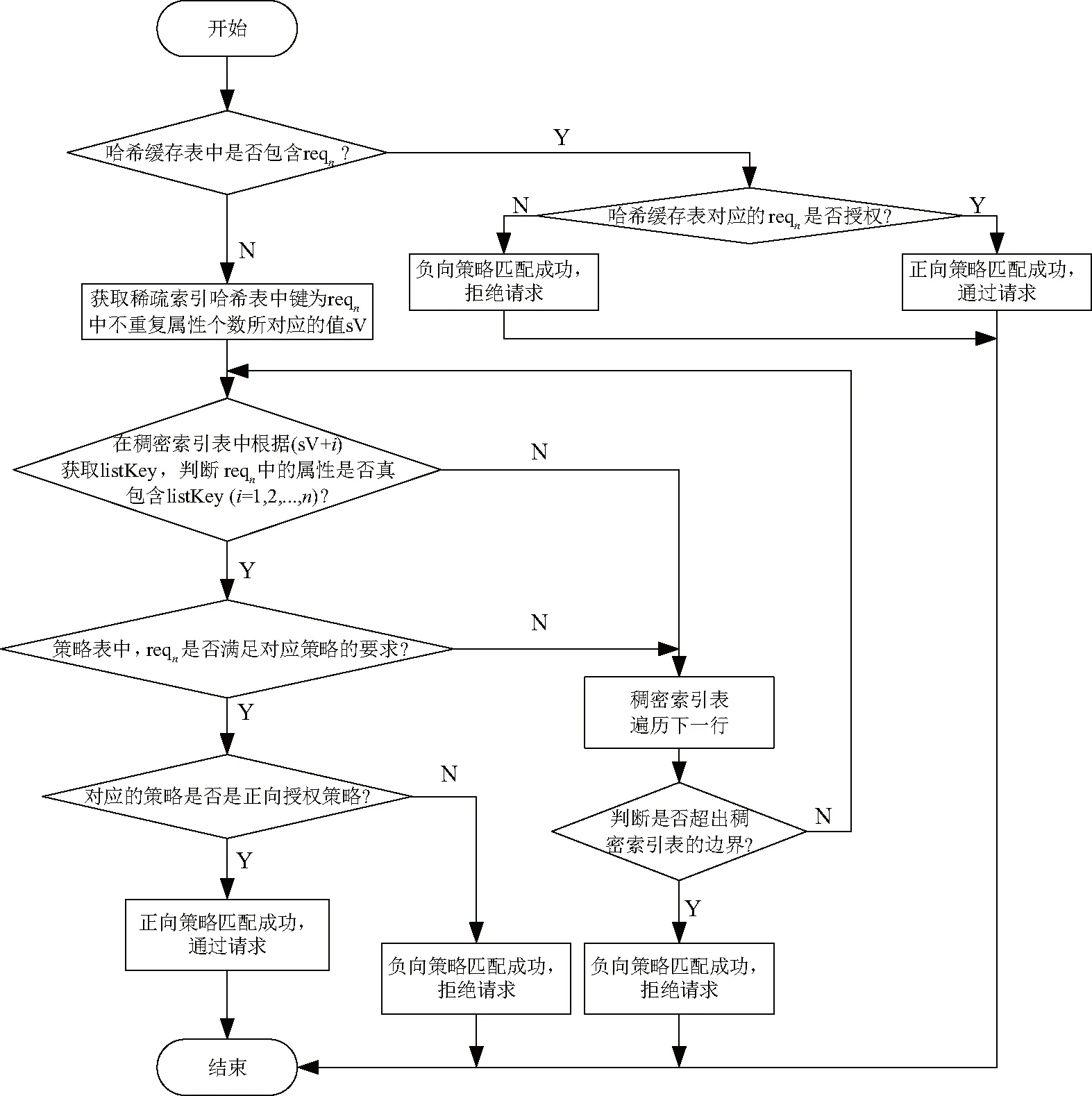
图6 多级检索法流程Fig.6 Flow chat ofmultilevel retrieval
由图6可知,文中提出的多级检索法,对于访问请求request1和request4只需检索一次哈希缓存表、一次稀疏索引哈希表、两次稠密索引表和一次策略表即可得出结果.request2只需检索一次哈希缓存表、一次稀疏索引哈希表、一次稠密索引表和一次策略表即可得出结果.request3只需检索一次哈希缓存表.
3 仿真实验及性能分析
为了验证多级检索法的检索效率,需要分别测试直接检索法、标记检索法以及多级检索法,测试所用计算机的CPU型号是英特尔i7-6770HQ,内存大小为16GB,操作系统是Windows10,集成开发环境是IntellijI DEA,编程语言是Java.其中直接检索法和标记检索法实现了文献[11]中的相关算法的描述,文献[11]中的直接检索法是标记检索法的对比方法.
3.1 空间消耗比较
空间消耗是指Java程序在运行时所要占据的物理内存空间,空间消耗过大会触发Java虚拟机JVM进行垃圾回收,严重影响程序性能.采用JDK工具集中jconsole程序对Java集成开发环境Intellij IDEA进程进行监控,记录Intellij IDEA在运行不同检索方法程序时的堆内存空间大小.记录前需要手动触发JVM的垃圾回收器,将JVM的垃圾回收机制在程序运行时对程序的空间消耗的影响降到最低.
针对3种检索方法在策略数量分别为10 000、20 000、30 000、40 000、50 000的环境中进行测试.实验结果如图7,多级检索法、标记检索法和直接检索法的平均内存消耗分别为100.72;88.19和83.96 MB.

图7 空间消耗比较Fig.7 Comparison of space consumption
这表明多级检索法相较于标记检索法和直接检索法由于3张中间表缓存的存在需要消耗更多的堆内存空间.标记检索法运行时平均堆内存空间比直接检索法大是因为标记检索法比直接检索法多了1张中间表缓存.而直接检索法没有任何缓存,所以运行时平均堆内存空间最小.
3.2 时间消耗比较
3种方法在检索时间方面的消耗主要比较两个方面:最坏情况下的检索时间,以及一般情况下的检索时间.
直接检索法和标记检索法都是在策略表中从上到下逐条检索,所以最好的情况是访问请求匹配成功策略表的第一条;最坏的情况是访问请求匹配成功策略表的最后一条.多级检索法最好的情况是访问请求已经在哈希缓存表中,可以直接获取检索结果;最坏的情况是访问请求属性的个数与策略表中策略属性个数的最大值相等并且匹配成功的是策略表中策略属性个数的最小值所对应的策略,这要求访问请求必须添加大量冗余属性键值对使得检索策略时程序在稀疏索引表和策略表中来回跳跃检索,降低了检索效率.
根据策略的形式化描述编写程序生成5份策略表,每份策略表中的策略数量分别为10 000,20 000,30 000,40 000,50 000.在这5份策略表中分别检索能够造成最坏情况的request所对应的policy,检索10次,取平均时间.3种方法在最坏情况的时间消耗,如图8,标记检索法相比直接检索法能够减少平均26.48%检索时间,多级检索法相比直接检索法能够减少平均17.11%检索时间.因为多级检索法和标记检索法都属于先检索属性,属性匹配后才检索属性值,所以两种方法检索效率接近.而直接检索法是直接检索属性键值对,没有分级检索,所以在检索效率上不如标记检索法和多级检索法.

图8 最坏情况下的时间消耗Fig.8 Time consumption of the worst situation
图8是3种方法在最坏情况下的性能表现,但这种极端情况在实际系统中难以出现,所以文中仍然使用之前选取的5份访问请求样本作为普通情况下访问请求的样本,策略表中的策略数量仍为10 000条,每份样本中的比例构成不变.
实验结果如图9,与直接检索法相比,多级检索法能够减少平均67.49%的检索时间,与标记检索法相比,多级检索法能够减少平均58.49%的检索时间.随着样本中访问请求数量的增加,多级检索法与直接检索法和标记检索法的差距会逐渐扩大,这表明在实际应用中,系统访问请求并发数越大,重复的访问请求越多,多级检索法的检索效率越高.

图9 一般情况下的时间消耗Fig.9 Time consumption of general situation
3.3 算法分析和综合性能比较
根据3种算法在空间和时间上的开销比较,可以看出多级检索法在算法设计时运用了以空间换时间的设计思想,通过运行时堆内存空间的增加换取策略检索时间消耗的减少.从理论上分析这3种算法,设策略集中有n条策略,每条策略中有m个属性约束,request中有k个属性键值对,根据上述对3种算法的描述可得直接检索法算法时间复杂度为O(nmk),标记检索法的时间复杂度为O(nm+mk),多级检索法的时间复杂度为O(cm+mk),其中c的值在一般情况下远小于n.所以多级检索法在一般情况下的时间消耗要少于标记检索法和直接检索法.
表3是多级检索法与其他方法在普通情况下的综合性能比较,比较的维度有访问控制模型、平均内存消耗、平均时间消耗、需维护的表数目.

表3 与其他几种方法的综合性能比较
4 结论
访问控制是实现系统安全的重要手段,而ABAC模型是一种能够较好实现细粒度授权的访问控制模型,其中实现细粒度控制的关键技术是策略检索,策略检索的性能优劣将直接影响到系统的实用性.文中提出一种基于稀疏索引和哈希表的访问控制策略检索方法,对基于前缀标记运算的策略检索方法和基于属性分组的访问控制策略检索方法中的策略表预处理和分级检索思想进行吸取和改善,引入三张中间表,构建了一个多层级的检索体系,缩减策略检索范围,提高策略检索效率.实验结果表明,多级检索法在ABAC模型中的有着比直接检索法和标记检索法更高的检索效率.
