一种轻量级文本蕴含模型
2021-10-18孙成胜伍少梅李小俊
王 伟, 孙成胜, 伍少梅, 张 芮, 康 睿, 李小俊
(1.中国电子科技网络信息安全有限公司, 成都 610041; 2.四川大学计算机学院, 成都 610065;3. 卫士通信息产业股份有限公司, 成都 610041)
1 引 言
文本蕴含识别(Recognizing Textual Entailment, RTE)是自然语言理解研究中一项基本任务,对问答对话,阅读理解,文本摘要等任务有辅助作用.文本蕴含任务定义为给定一对文本,分别称为前提(Premise)和假设(Hypothesis),模型需要推理出这两段文本之间的关系,文本关系主要包括蕴含、中立和矛盾.
基于神经网络的文本蕴含模型取得较高的识别准确率.现有主流文本蕴含模型[1-2]通常使用双向LSTM网络编码文本,并采用注意力机制对两段文本交互,再用循环神经网络分析并推理交互特征从而判断文本关系.这些模型一个共同特点是采用多次循环神经网络编码和推理文本,并且近年来部分文本蕴含模型[3-4]为了进一步提升精度,模型整体趋势构建得越来越复杂,花费更多的参数,模型也需要花费更长的训练和推理时间.更高的训练代价使得模型难以快速微调和迭代,更长的推理时间使得模型不适于线上实际应用.
本文致力于探索高效的文本蕴含模型,采用并行架构,在保证模型精度情况下尽量精简模型结构,提高模型运行速度.本文提出轻量级文本蕴含模型(Lightweight Textual Entailment Model, LwTEM),模型采用改进的自注意力编码器分别编码前提和假设文本向量,捕捉文本长距离依赖,采用点积注意力机制深入比较两段文本语义,然后用卷积神经网络分别提取两段文本局部交互特征,模型可堆叠多个模块进一步强化推理效果,凝练高层语义信息.
2 相关工作
基于神经网络方法是文本蕴含任务的主流方法,主要分为两类.一类通过构建更好的文本编码器来独立编码两段文本,再采用神经网络分类器对两个文本向量分类.编码器主要包括循环神经网络[5],卷积神经网络[6],自注意力网络[7].一个好的文本编码器可适用于其他文本任务,但由于该方法没有两段文本的交互过程,分类器难以捕捉复杂的文本关系.另一类方法采用交互聚合框架来建模文本关系,在文本编码后采用注意力机制从语义上比较两段文本,再将文本交互特征聚合后进行推理.Chen等人[2]采用词级别注意力矩阵对齐交互文本,并使用双向LSTM网络编码和聚合文本特征.
在这种框架基础上,主要有4种方式被用于进一步提升文本蕴含性能.(1) 是采用手工提取文本特征来作为模型输入,Chen等[2]采用句法解析树得到句法特征,Tay等[1]和Gong等[8]使用词性特征,Kim等[4]和Gong等[8]手动提取字符匹配特征(2) 是采用复杂的文本对齐过程,Wang等[9]采用多视角匹配操作,Tan等[10]采用多种交互对齐方式;(3) 是构建复杂的后处理过程来处理文本交互结果,Tay等[1]使用因子分解层增强文本交互表示,Gong等[8]采用密集连接操作构建深度卷积网络从交互结果中抽取文本信息. Xiong等[11]使用门控机制处理句子级交互信息,结合单词级细粒度推理机制捕获全局语义;(4) 通过多次迭代推理或多层编码器来提取文本深层语义信息.Liu等[3]使用循环神经网络多次迭代推理文本交互特征.Kim等[4]堆叠编码层和交互对齐层,采用自动编码器处理大量特征空间.Tay等[12]采用多种层级的注意力强化推理结果,并用密集连接加强多层级注意力传播.
这些模型大多数都采用循环神经网络进行编码和推理,许多基于循环神经网络的文本任务[13-14]取得了成功, RNN网络的结构和串行数据处理方式,非常适用于文本数据,但该网络运行时间通常较慢,再加上近年来文本蕴含模型各种复杂的特征和组件的堆叠使得模型结构越来越复杂,参数越来越多,训练和推理时间也越来越长.
Vaswani等[15]提出Transformer结构,摒弃了串行编码结构,采用自注意力和全连接网络作为基本架构,在多个文本任务上取得了较好的结果.自注意力可跨距离捕捉文本远距离依赖,良好的并行能力使得该结构在速度上很有优势,便于堆叠多层,可提取更准确的高层语义信息.Zhang等[16]把语义角色融合到自注意力机制应用于RTE任务.卷积神经网络擅长于局部特征建模,也被广泛使用文本任务中.Xu等[17]将上下文相关的概念特征整合到卷积神经网络中应用于短文本分类任务.卷积核及参数共享特点使得该网络在运行速度和参数数量上也要优于循环神经网络.
3 模 型
轻量级模型LwTEM包括嵌入层,编码层,交互层,特征提取层和输出层,整体架构如图1所示.其中编码层、交互层和特征提取层共同构成一个模块,如图1蓝色虚线部分,模型针对不同数据集特点可叠加多个模块,达到不同的推理效果.

图1 LwTEM模型架构Fig.1 Model architecture of LwTEM
3.1 嵌入层
由于编码层的自注意力网络无法捕捉文本的位置信息,因此本文在嵌入层将预训练词向量和位置编码拼接作为模型输入.位置编码采用Vaswani等[15]提出的相对位置编码.
PE(pos,2l)=sin(pos/10002l/dmodel)
(1)
PE(pos,2l+1)=cos(pos/10002l/dmodel)
(2)
式中,pos表示文本序列中当前词的位置;l表示位置向量中第l维;sin和cos分别表示奇数维度和偶数维度用的数学函数.该位置函数可以根据sin和cos函数的数学特性捕捉单词之间的相对位置关系.
3.2 编码层
本文编码层和Transformer编码器结构相似,由两个子模块组成:多头注意力和两层前馈神经网络,每个子模块通过残差和层归一化相连.
自注意力可无视距离交互远距离文本,但同时也会忽略文本序列信息.对于一句话,中心词附近的文本词的作用应该是高于远距离文本的,比如:“The man in a black shirt is standing next to black box”,句子中第一个“black”和第二个“black”对于“man”这个中心词来说重要程度是不一样的,而原始自注意力计算方式将这两个“black”同等对待.本文模型对自注意力结果增加参数约束,用于学习不同距离的词对中心词产生的不同效果.虽然嵌入层的位置编码也可缓解该问题,但实验显示增加参数约束后效果更好.改进后自注意力计算方式如图2所示.
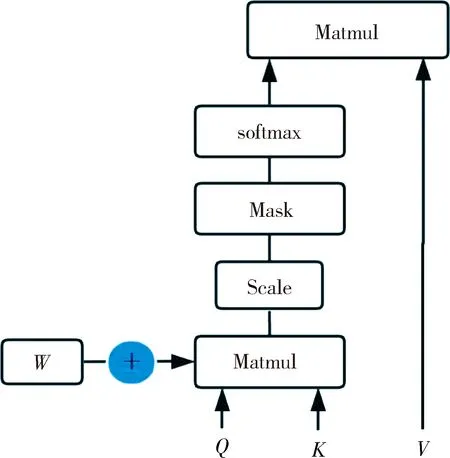
图2 模型自注意力方式Fig.2 Structure of self attention
计算方式如式(3)所示。
(3)
式中,Q,K,V为输入文本分别采用不同参数的线性映射得到;dk为多头自注意力的隐层.本文模型在原本的自注意力计算方式下增加参数W,W和自注意力矩阵大小相同,为可训练参数,用于改善不同距离词的自注意力效果.
多头自注意力计算结果通过拼接送入两层前馈神经网络中,如式(4)所示.
F(p)=W2(Relu(W1p+b1))+b2
(4)
式中,W1、W2和b1、b2分别为两层的前馈神经网络的权重和偏置;p为经过多头自注意力计算的前提文本向量,假设文本向量计算方式也同上.前馈神经网络将自注意力编码后的信息映射到高维空间,通过非线性激活函数Relu进一步选择有效的特征.
3.3 交互层
模型的交互方式采用简单高效的点积注意力,得到两段文本的词级相似度结果.
Inter(pi,hj)=piT·hj
(5)
(6)
(7)
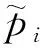
将交互特征向量和原编码向量通过以下方式进行融合.

(8)
(9)
(10)
(11)
式中,[;]表示连接符号;∘表示元素相乘,可表示原文本向量和交互向量之间的相似度,相减操作可表示找到向量之间的差异.假设文本的特征融合方式也同上.
3.4 特征提取层
特征提取层采用卷积神经网络提取融合的特征.由于编码层的自注意力网络可充分编码远距离文本信息,而卷积神经网络更关注局部特征,结合CNN网络的局部感知和自注意力编码的全局信息,可全面获取文本高层语义和蕴含特征.卷积计算方式如式(12)所示.
(12)

3.5 输出层
输出层采用最大池化操作将文本特征转为固定长度的向量.最后将前提和假设文本向量连接,采用两层前馈神经网络连接用于最后关系分类.

(13)
fk=xWk+bk,k∈{1,2}
(14)
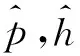
4 实验结果
4.1 数据集
本文LwTEM模型采用SNLI,SCITAIL, MultiNLI三个数据集进行验证.其中SNLI数据集[18]是由斯坦福在2015年发布的大型文本蕴含数据集,SCITAIL数据集[19]是根据科学类多选问答任务构造的科学类文本蕴含数据集.MultiNLI数据集[20]为SNLI扩展的文本蕴含数据集,在语料范围覆盖度和推理难度上都有一定加强.表1 展示了三个实验数据集详细信息.
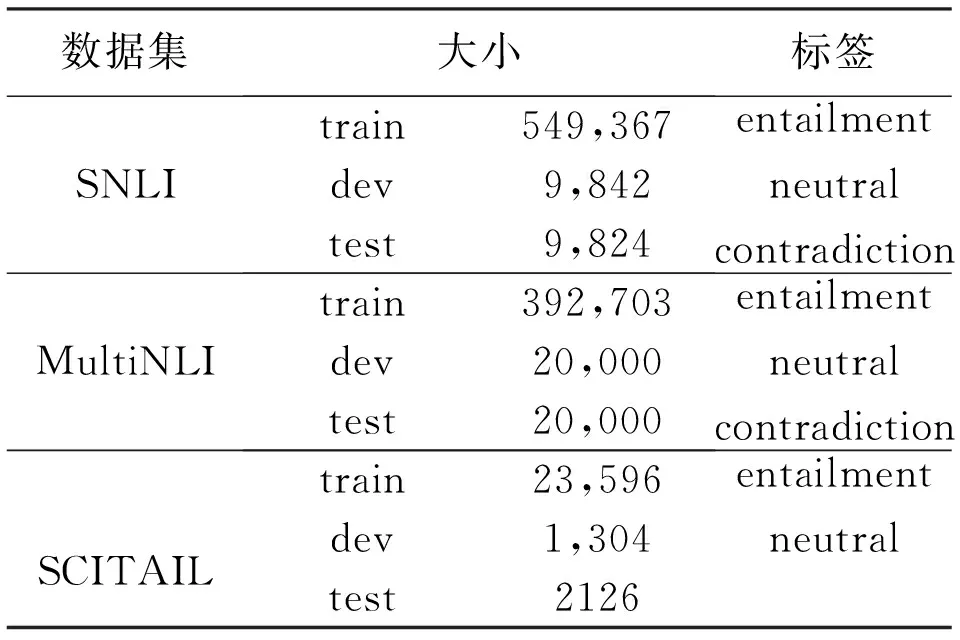
表1 3个实验数据集分布
表1中,Entailment表示蕴含;neutral表示中立;contradiction表示矛盾类别;文本蕴含评价指标为准确率(Accuracy,ACC).
4.2 实验结果
本文的模型是基于Tensorflow框架搭建,采用ADAM优化器[21]作为整个模型的优化函数.SCITAIL数据集的学习率为0.001,batch size大小为32,隐层维度为256,SNLI和MultiNLI数据集的学习率采用warm up策略,初始学习率为0.000 1,分别逐步上升到0.001和0.002之后开始下降,batch size为256,网络隐层维度为200.为防止过拟合,采用dropout[22]比率为0.2,CNN网络过滤器大小为3.输入为300维的Glove词嵌入[23]和50维的位置向量,对于词表外的单词,采用高斯分布随机初始化一个300维的向量,所有词向量在整个训练过程中不更新.
表2至表4分别显示了三个数据集的准确率结果,由于仅SNLI数据集中部分对比模型列出了模型参数数量,因此仅在SNLI数据集上对比模型参数数量结果,表5对比了部分模型的推理速度.
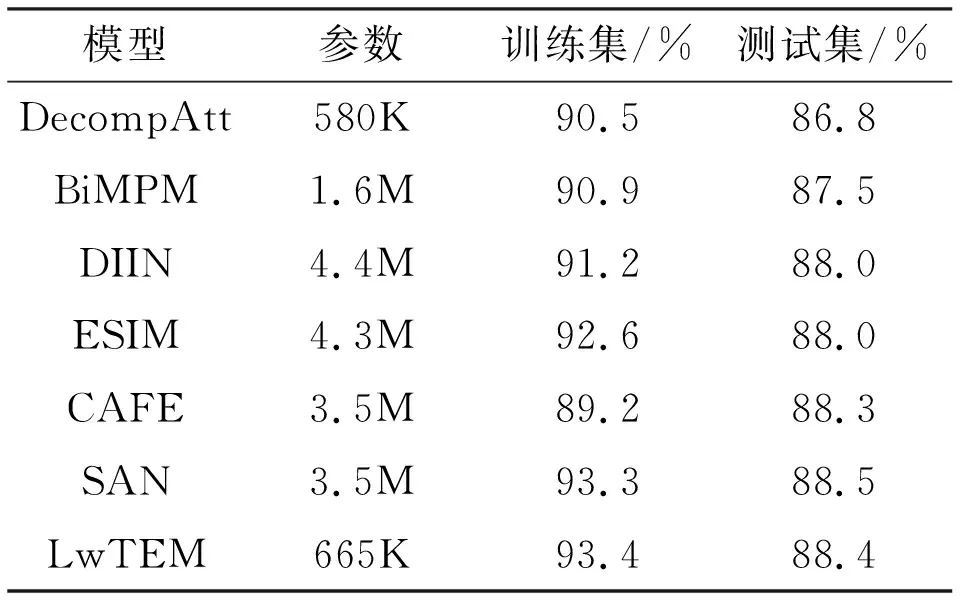
表2 SNLI数据集结果

表3 SCITAIL数据集结果
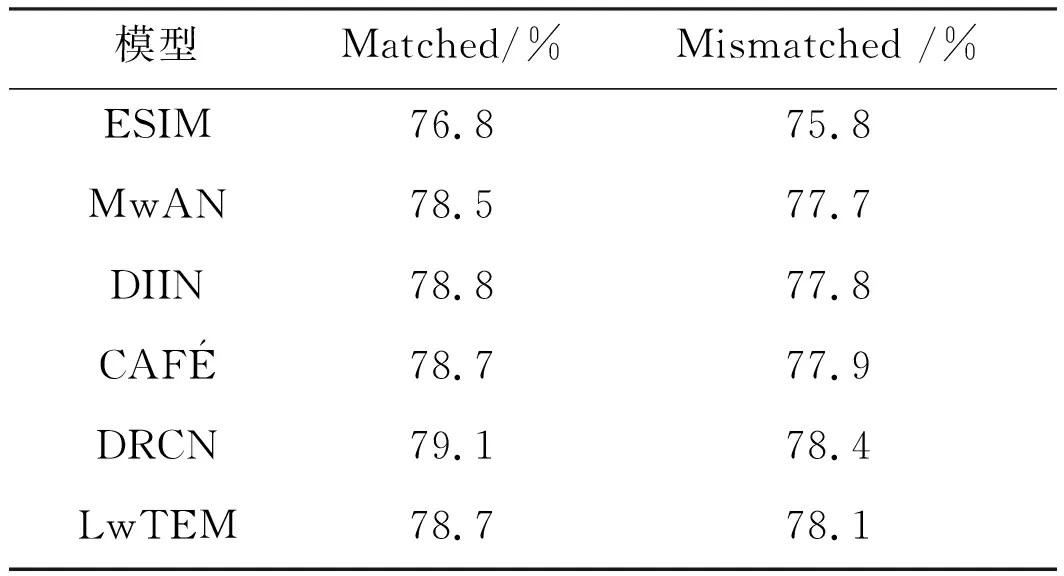
表4 MultiNLI数据集结果

表5 模型推理速度对比
表2为SNLI数据集的结果,LwTEM模型在SNLI测试集上达到了88.4%的准确率,模型参数数量却只有665 K,远低于其他主流模型参数量.
BiMAP网络[9]采用全匹配,最大匹配,平均匹配和注意力匹配多种对齐过程丰富文本匹配特征,CAFE网络[1],DIIN网络[8]在输入层构建多种文本输入特征,SAN网络[3]采用多次迭代推理凝练深层语义信息.这些网络除了DIIN模型外都是采用循环神经网络用于文本编码和推理,其中,SAN模型准确率高于本文模型0.1%,但参数数量却远多于本文模型.DecompAtt[24]采用自注意力和全连接网络为模型主要框架,没有复杂的推理过程和额外的特征,其参数数量略少于本文模型,但本文模型准确率高于该模型1.6%.通过分析可知,在综合考虑准确率和参数数量指标后,LwTEM模型性能要优于主流文本蕴含模型.
表3为SCITAIL数据集实验结果,由表2和3结合可知,LwTEM模型参数数量远少于上述大多数模型,并且在SCITAIL数据集上准确率也达到最好的效果.
表4显示了在MultiNLI数据集的实验结果.MultiNLI测试集分为Matched和Mismatched两个部分.LwTEM模型在Matched数据部分达到了78.7%的准确率,分别高于ESIM模型1.9%,MwAN模型0.2%,并且和DIIN,CAFE模型结果相当,在Mismatch数据上准确率为78.1%,优于表4中大部分模型结果.
表5显示了模型不同block的推理速度结果,推理过程中一个batch标准大小为8,最大句子长度设为20,Yang等[25]模型中设定完全相同,模型运行的处理器也相同,均为Inter Core i7,唯一的不同在于操作系统,本文模型运行操作系统为Windows10,表中其他模型运行系统为MacOS.CAFÉ[1],BiMAP[9],CSRAN[12]模型均是由单层或多层LSTM网络作为文本编码,并采用各种注意力匹配推理文本关系.RE2[25]结合CNN网络和注意力以及残差连接构建模型,DIIN[8]采用CNN网络,空间注意力以及密集连接构建的文本蕴含模型,但由于其复杂的交互特征处理过程,使得模型速度较慢.由表5中可知,本文模型1个模块的推理时间仅为0.015 s,优于其他所有模型推理速度,叠加到2个模块的模型推理时间为0.025 s,仍然好于其他模型,在叠加到3个模块后,模型推理速度为0.035 s.表5推理结果表明了本文模型LwTEM在推理速度上要比其他主流文本蕴含模型至少快1倍以上.
4.3 模型性能分析
4.3.1 结构消融分析 图3为LwTEM模型在SCITAIL验证集上模型结构消融结果,直观反应了不同模块的结果变化[26-27].由图3可知,本文轻量级模型(a)在SCITAIL验证集上最好效果为89.4%,在(b)去掉编码层注意力中参数w后准确率下降了0.3%,表明了改善后的自注意力优于原自注意力效果;在(c)去掉卷积结构后模型准确率大幅降低了2%,表明了在本文模型中CNN网络提取文本局部特征对文本对关系判断的重要性;在(d)去掉原特征融合方式而采用简单的拼接方式代替原本特征融合后,模型准确率也降低了1.5%.在这三个不同模块中,其作用最大的是CNN模块,其次是特征融合方式.图3表明了本章模型中各个模块的有效性和不可替代性.

图3 模型结构消融结果柱状图
4.3.2 不同block实验结果 表6为LwTEM模型在叠加不同模块后在各个数据集的验证集上的准确率.在SNLI验证集上叠加2个模块比1个模块准确率提升了0.2%,当继续叠加到3个模块后,并没有发现明显的效果提升,说明本章模型在SNLI数据集上用2个模块堆叠的即可.而在MultiNLI数据集上叠加两个模块后,模型结果均提升了0.6%,而继续增加到3个模块,准确率进一步提升0.7%和0.4%.受硬件限制和模型复杂度影响,本文仅测试到三个模块.由表6结果可知,针对不同数据集的特点,叠加不同的模块有不同的效果.对于MultiNLI数据集,文本对较长,句式复杂,叠加多个模块模拟多次推理效果更好,而对于简单句的SNLI数据集,本章模型的1个模块即可达到较高的文本关系识别率.
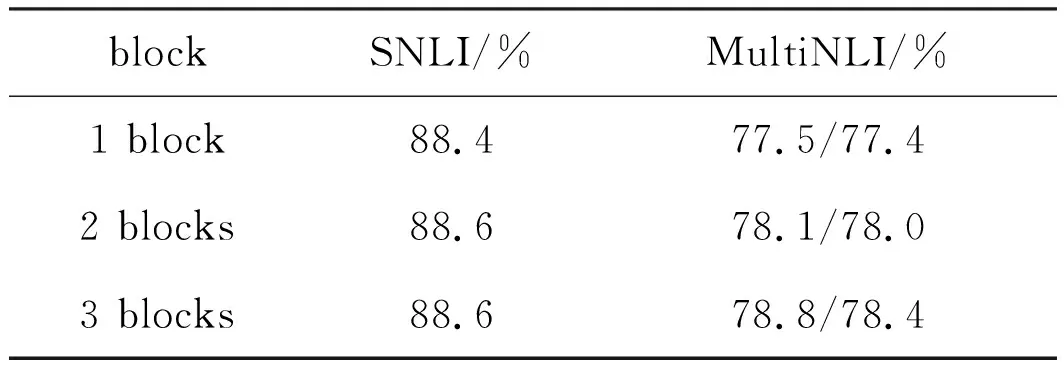
表6 模块不同block结果
4.3.3 注意力可视化和案例分析 本节通过可视化注意力结果分析模型内部学到的信息.LwTEM模型注意力模块得到的注意力热力图如4所示,纵轴表示前提文本,横轴表示假设文本,每个方块表示前提和假设文本中词两两对应的注意力可视化结果,颜色越深表示注意力值越大.
图4共包含4个样例,样例1为SNLI数据集中矛盾样例,样例2为SNLI数据集中蕴含样例,样例3为SCITAIL数据集的蕴含样例,样例4为SCITAIL数据集的中立样例.以下为4个样例详细分析结果.
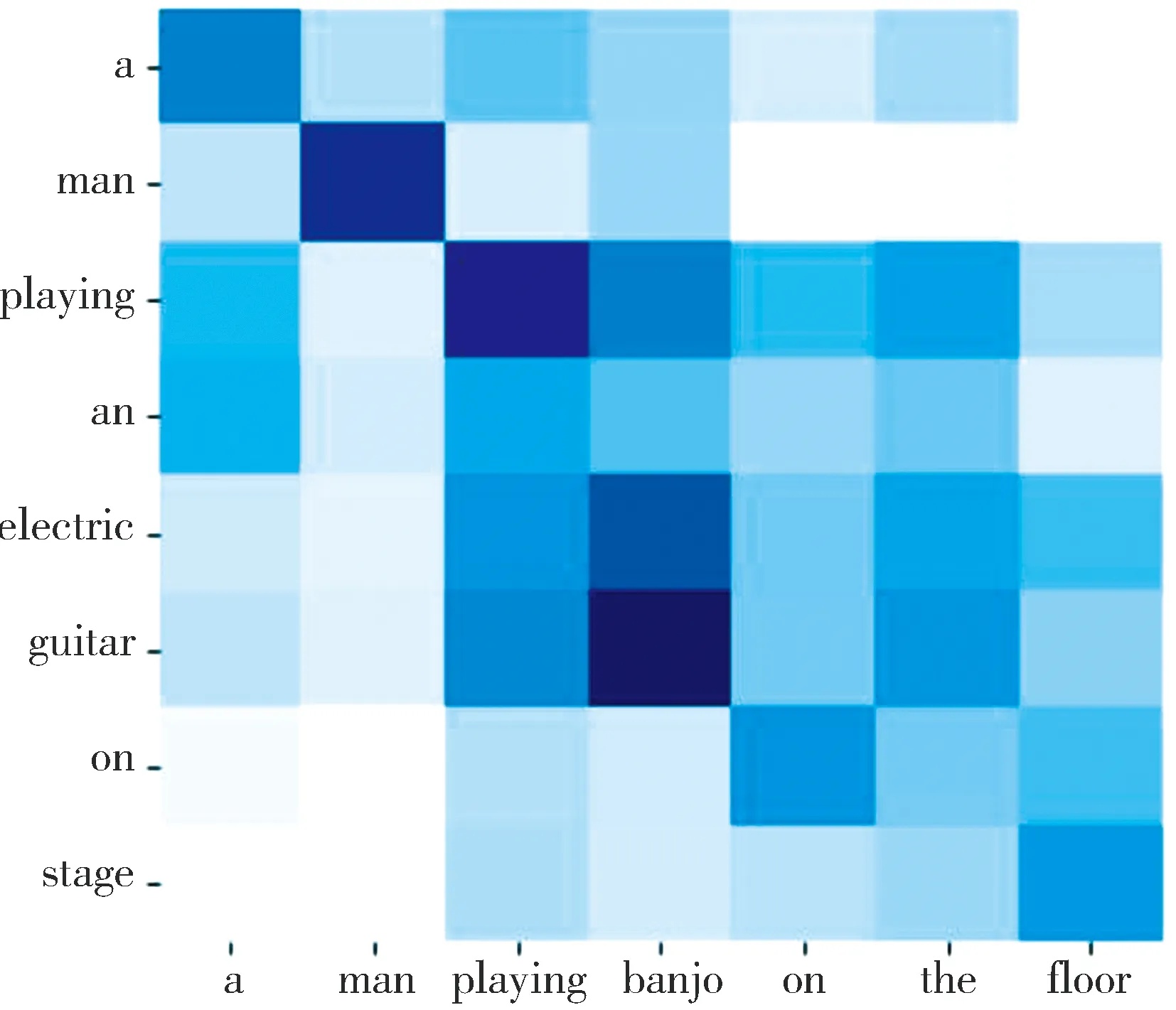
(a) 样例1
前提1:a man playing an electric guitar on stage.
假设1:a man playing banjo on the floor.
标签1:矛盾
在样例1中,模型可准确找到“guitar”和“banjo”这一对关键词,在主语“a man”,动词“playing”一一对应的情况下,模型定位到“guitar”和“banjo”的语义差异,从而识别出文本的矛盾关系.
前提2:a woman with a green headscarf blue shirt and a very big grin.
假设2:the women is very happy.
标签2:蕴含
对于样例2文本对,模型注意力对齐了“very big grin”和“very happy”这一对关键词,可以推测出前提蕴含假设文本语义,从而找到文本对的蕴含关系.
前提3:This causes gases to become liquids and liquids to become solids as the temperature decreases
前提4:At high temperatures, the solid dye converts into a gas without ever becoming a liquid
假设3&4:Gases and liquids become solids at low temperatures
样例3和样例4的假设文本相同.前提3和假设为蕴含关系,前提4和假设为中立关系.通过注意力可视化分析,在样例3中,“gases”“become”liquids”和“liquids”“become”“solids”均有一一对应关系,“decrease”和“low”也可通过注意力推理出词义相同,在句子中谓语,宾语和多个不同主语均能一一对应情况下,可推断出文本为蕴含关系.对于样例4,为非蕴含关系,却有很多相同词,模型可对齐这些相同词的注意力,但是假设中关键词“liquids”到“solids”的关系,在前提中没有与之相应的关系,所以模型将其判断为非蕴含关系.
5 结 论
本文构建轻量级文本蕴含模型LwTEM,主要由自注意力编码,注意力交互,特征融合和CNN网络构成,堆叠多个模块可根据不同数据集特点得到相应的推理效果.本文在三个文本蕴含数据集上均做了实验,结果表明LwTEM模型在准确率和现主流模型相当情况下,参数数量和推理速度明显优于其他模型.未来可尝试将LwTEM模型应用于其他文本匹配任务.
