基于卷积注意力的无人机多光谱遥感影像地膜农田识别
2021-10-13宁纪锋何宜家李龙飞赵志新张智韬
宁纪锋 倪 静 何宜家 李龙飞 赵志新 张智韬
(1.西北农林科技大学信息工程学院, 陕西杨凌 712100; 2.西北农林科技大学水利与建筑工程学院, 陕西杨凌 712100)
0 引言
地膜具有提高土壤温度、保持土壤水分、防止害虫侵袭和促进农作物生长等功能,已成为提高农作物产量的重要方法之一。随着农用地膜面积的快速增长[1],由此引发的环境问题也日益凸显。一方面,地膜覆盖地表抑制了水分蒸发,提高了水分利用率同时也改变了地表陆面参数,阻断了土壤与大气间的水分交换,从而可能会对区域气候产生一定的影响[2-4];另一方面,地膜在农田中的长期残留会降低土壤孔隙度和含水率,造成对土壤的污染[5-6]。因此迫切需要准确、及时地了解农田地膜的时空分布情况,为掌握农田地膜时空分布、开展农作物监测和残膜污染防控提供决策管理依据。
获取地膜覆盖信息传统方法需要进行实地调查,工作量大且效率低。由于卫星遥感具有大尺度监测[7]的优势,并且多光谱遥感影像具有多波段特点,含有丰富的地物特征,利用其进行农田地膜信息的监测取得了良好的进展[8-11]。而无人机遥感具有机动灵活和成像分辨率高等特点[12-13],近年来在农田级区域[14-15]的应用越来越广泛。同时,随着深度学习的发展,深度语义分割模型具有像素级分类的效果,其在效率和性能上相较于传统的分类方法具有明显的优势。文献[16]提出一种基于深度学习的大棚及地膜农田无人机航拍监测方法,通过构建全卷积神经网络(Fully convolutional network,FCN)[17]对采集到的赤峰市王爷府镇地区覆膜农田图像实现快速识别。文献[18]利用无人机获取内蒙古自治区2018年5月地膜覆盖的多光谱遥感影像,采用SegNet[19]深度语义分割方法且结合纹理特征和光谱特征实现对地膜的精确识别。
注意力机制[20-22]能够在进行视觉信息处理时选择性地关注部分信息,在语义分割中,利用其可将全局信息选择性地聚合到每个像素点上,使得不同类别的像素特征区分度更大,从而提高模型的识别精度。近年来,基于注意力机制的深度学习方法在农业中也逐渐得到应用[23]。
本文将注意力机制应用于地膜农田无人机多光谱遥感影像识别,并与可见光遥感图像的识别效果进行对比,考虑地膜表观变化对模型识别精度的影响,在训练数据中增加地膜农田表观变化的数据,提供多样化的训练数据。在DeepLabv3+[24]网络基础上加入注意力机制,以自适应学习地膜注意力,得到适应不同分布的大规模地膜农田空间分布信息监测模型,以期获得更为准确的地膜农田覆盖信息。
1 材料与方法
1.1 研究区域概况
实验区域为内蒙古自治区西部河套灌区沙壕渠灌域,地理坐标为40°52′~41°0′N,107°5′~107°10′E,海拔1 034~1 037 m,是内蒙古自治区河套灌区西北部解放闸灌域内部的一个独立区域。该灌溉区域总面积为52.4 km2,其形状为南窄北宽,地面较为平坦。主要种植的农作物有向日葵、小麦、玉米和西葫芦,其中向日葵的种植面积最大,约占47.9%。该地区夏季高温少雨,冬季寒冷干燥,属于典型的大陆性干旱半干旱气候,通过使用塑料地膜来提高农作物的产量。根据实地调研结果,选择地膜覆盖面积最大的4块实验田作为实验地,并依次编号为1、2、3、4号地,单块实验田面积在1.5×105~2.5×105m2之间,位置分布如图1所示。
1.2 数据获取与预处理
1.2.1数据采集
实验所用的采集设备为大疆创新科技有限公司生产的经纬M600型六旋翼无人机,搭载的多光谱传感器为美国Tetracam公司生产的Micro-MCA型多光谱相机(简称MCA),如图2所示。相机包含6个波段(3个可见光波段,3个近红外波段)的光谱采集通道,其中心波长分别为490 nm(蓝光)、550 nm(绿光)、680 nm(红光)、720 nm(红边)、800 nm(近红外)、900 nm(近红外),每个通道的宽度为35 nm,并且每个波段配备130万像素的CMOS传感器,图像分辨率均为1 280像素×1 024像素。
无人机遥感影像的采集过程分为2个时间段,分别为2018年5月3日和2019年5月14、16日。每次实验设定无人机的飞行高度为120 m,拍摄开始时间为13:00,平均飞行速度为9.2 m/s,影像的地面采样距离(Ground sample distance,GSD)为0.065 m。
无人机航拍的图像通过Pix4Dmapper软件进行拼接,利用地面控制点对其进行几何校正,生成最终的正射影像。拼接后的每块实验田遥感影像平均分辨率约为10 000像素×10 000像素,共有8幅,以TIFF格式存储。
1.2.2数据标注
根据地面调查,采集到的地膜数据主要有3种类型,分别为旱作黑膜、旱作透明膜和灌溉地膜,如图3所示。道路、裸地、作物农田、水渠等划为背景类。采用开源软件LabelMe对拼接后的图像进行手工标注。图4为地膜农田像素级标注示例。
1.3 数据集分析与构建
通过统计2年每块实验田的标签图像,对各类别的数据分布进行分析。由图5a可知,2018年地膜数据中旱作黑膜主要集中在2号地和3号地,旱作透明膜存在于2号地和4号地,灌溉地膜相对较少,且主要分布在3号地和4号地。由图5b可知,2019年地膜数据中旱作黑膜极少且只存在于3号地中,灌溉地膜分布在2号地、3号地和4号地,旱作透明膜居多且每块实验田都有分布。由此发现不同年份各块实验田地膜种类分布差距较大。从图5c可以看出,整体上2年的背景变化较小,相差不大。各地膜种类2018年中旱作透明膜居多,旱作黑膜次之,灌溉地膜最少,而2019年地膜种类中旱作透明膜最多,灌溉地膜次之,旱作黑膜最少。其中,2年的灌溉地膜差距最大,同时不同年份地膜也存在较大的表观变化。图6为2018年和2019年典型的旱作透明膜遥感图像,可以看出2018年的旱作透明膜特征明显,和图3b中旱作黑膜区分度较大。而2019年出现部分旱作透明膜的表观变化较大,与旱作黑膜相似的地膜特征容易被错误识别。
为了减少数据分布不均衡以及数据多样性问题对模型的训练与测试产生影响,在制作训练集时分别裁取各研究地块的遥感影像,并通过预处理裁剪生成每种类别数量大致相等的尺寸为256像素×256像素的训练图像。同时利用数据增强方法扩充数据集,主要包括随机旋转、加噪、缩放以及翻转等处理,并按照8∶2的比例划分为训练集和验证集,测试集为2019年的遥感数据。本次实验根据数据集的差异设计了2组实验,其中实验1用2018年的数据训练模型,共有图像15 500幅,测试集是2019年的数据。实验2是将2019年3号地裁剪分为2部分,其中一部分增加至训练集,共有图像18 000幅,测试集是2019年的1号地、2号地、3号地部分和4号地。
1.4 研究方法
1.4.1DeepLabv3+模型
DeepLabv3+是深度学习语义分割领域的一种代表性方法,包含编码器和解码器2部分。其中,编码器由带有空洞卷积的特征提取网络和空洞空间卷积池化金字塔(Atrous spatial pyramid pooling,ASPP)[25]结构组成,解码器融合低层特征并进行上采样,得到与输入图像尺寸相同的逐像素分类结果。在特征提取网络中,使用空洞卷积降低语义分割任务中存在的特征分辨率与感受野的矛盾,使得特征图的边界信息尽可能减少丢失,进一步提升分割效果。ASPP结构由3个3×3卷积和1个全局平均池化操作构成,其中3个3×3卷积操作的扩张率分别为6、12、18,该结构能够对特征图采用不同采样率的空洞卷积操作并行采样,增强对多尺度目标的适应性。在解码器部分,DeepLabv3+在特征图的恢复过程中融合低层特征,用双线性插值的方法恢复目标的边界信息,实现了较高的分类精度。
DeepLabv3+中带空洞卷积操作的特征提取网络用来解决感受野增大时特征分辨率降低的问题,ASPP结构中不同的扩张率(6、12、18)能够并行处理输入的特征图,用来提取多尺度的目标信息。但过大的扩张率会使网络无法较好地提取图像边缘目标特征,同时也会影响大尺度目标局部特征之间的关联,从而产生大尺度目标语义分割空洞现象。对于无人机遥感影像中的大面积地膜分割时这种现象尤为明显,从而会影响模型的分割精度。
1.4.2基于卷积注意力机制的DeepLabv3+语义分割模型
卷积注意力机制[26]将基于注意力的特征细化应用于通道和空间2个不同的模块,在不显著增加计算量和参数量的前提下提升网络模型的特征提取能力,在深度学习的多个领域已有成功应用。DeepLabv3+是通用的语义分割模型,在对无人机遥感影像地膜农田进行分类时,需进行迁移学习,以克服原始模型和具体应用的域不一致问题。
本文将注意力机制与DeepLabv3+模型融合,学习面向地膜语义分割的通道注意力和空间注意力特征,提出一种改进的DeepLabv3+深度语义分割模型,增强对地膜农田的识别性能。在DeepLabv3+骨干网络之后、ASPP结构之前增加卷积注意力模块,基于骨干网络提取的特征图,依次经过通道和空间2个注意力模块学习地膜注意力图,并将其与输入特征图点乘以进行自适应特征优化,提高不同种类地膜像素特征之间的判别性。
图7a为注意力模块网络结构,图7b为改进的基于注意力的DeepLabv3+网络结构。首先,多光谱遥感图像经过骨干网络处理后得到特征图F。接着,特征图先经过通道注意力模块得到通道注意力Attc,并与特征图F融合得到Fc,再经过空间注意力模块得到空间注意力Atts,并与Fc融合得到最终的注意力特征图Fs,计算公式为
Fc=Attc(F)⊗F(F∈RC×H×W,Fc∈RC×1×1)
(1)
Fs=Atts(Fc)⊗Fc(Fs∈R1×H×W)
(2)
式中 ⊗——逐元素相乘
Fc——卷积注意力机制的一维通道注意力图
通道注意力模块中使用最大池化和平均池化来聚合特征映射的空间信息,在空间注意力模块中使用2个池化操作来聚合特征映射的通道信息。当特征图经过整个卷积注意力模块时能够有效增强和压缩提取中间特征,并且保持了小的参数开销。
2 结果与分析
2.1 模型训练
实验的硬件环境为英特尔Intel(R) Core(TM) i7-7700K CPU,NVIDIA 1080Ti GPU,16 GB内存,操作系统为Ubuntu 16.04 LTS,深度学习框架为Tensorflow1.4[27],编程语言及版本为Python 3.6.5。
使用在ImageNet[28]上预训练的ResNet模型初始化骨干网络权重,输入的图像分辨率为256像素×256像素,使用交叉熵损失函数以及动量梯度下降算法对模型进行优化。迭代次数为30 000次,批处理大小为6,初始学习率为0.007,结束学习率为1×10-6,权重衰减以及动量参数分别为0.000 5和0.9。本文所有模型在2组实验数据集上的训练集和测试集均保持一致。
2.2 评价指标
平均像素精度(Mean pixel accuracy,MPA)[29]作为衡量语义分割算法精度的一个指标,能够计算每个类内被正确分类像素的比例,之后求所有类的平均。
2.3 结果分析
对于无人机多光谱遥感影像的地膜农田识别结果,基于设计的2组实验,从3方面进行分析讨论。首先,对比分析多光谱与可见光遥感图像对地膜农田的识别效果。其次,基于2组实验结果,对比不同的数据集差异,分析地膜农田表观变化对识别精度的影响。最后,将嵌入注意力模块的DeepLabv3+网络和原网络的识别效果进行比较,分析改进效果。在实时性方面,对于分辨率为1 000像素×1 000像素的图像,SegNet模型的预测时间为32.6 s,DeepLabv3+模型的预测时间为46.7 s,本文提出的基于注意力机制的DeepLabv3+模型的预测时间为47.5 s,相对于原网络仅增加0.8 s,满足语义分割算法的实时性要求。表1、2分别为可见光与多光谱遥感影像的识别结果。

表1 可见光遥感图像3种深度语义分割模型对4块实验田的平均像素精度识别结果Tab.1 Recognition accuracy of four experimental fields of visible remote sensing image by three deep semantic segmentation models %
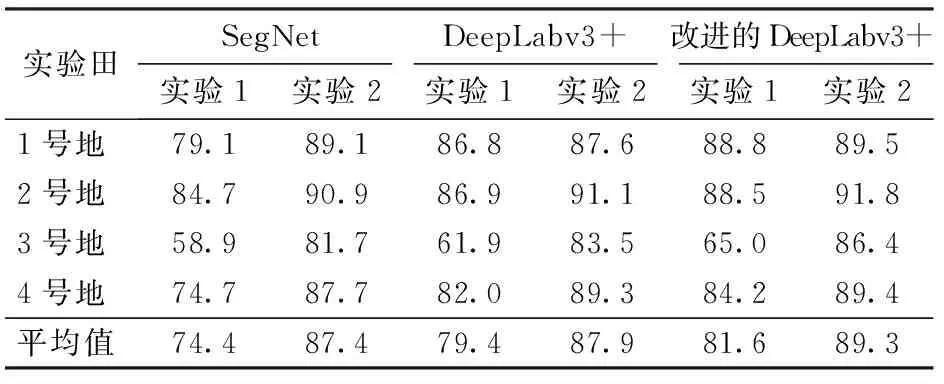
表2 多光谱遥感图像3种深度语义分割模型对4块实验田的平均像素精度识别结果Tab.2 Recognition accuracy of four experimental fields of multispectral remote sensing image by three deep semantic segmentation models %
2.3.1可见光与多光谱识别结果分析
可见光遥感图像只包含3个波段的信息,而无人机多光谱图像不仅包含纹理特征并且具有丰富的光谱信息,可以把地物波谱的微弱差异区分并记录下来,得到各类别地膜的光谱信息,从而对地膜农田的分辨能力较强。对比表1和表2可以看出,对于4块实验田的识别效果,整体上3种模型方法均为多光谱的识别精度优于可见光。其中,在实验1数据集上,DeepLabv3+和改进的DeepLabv3+模型对多光谱遥感图像的平均像素精度均比可见光高7.1个百分点。在实验2数据集上,DeepLabv3+模型多光谱的平均像素精度超出可见光11.3个百分点。这表明丰富的光谱信息相对于可见光,有助于将地膜农田从各种复杂的背景中较好地识别。
以实验1数据集上2号实验田部分为例,图8展示3种模型的多光谱与可见光图像的预测结果。从图8a可以看出,在可见光数据集上3种模型对地膜特征明显的部分识别效果较好,对灌溉地膜和旱作透明膜的识别效果不佳。而多光谱图像的识别效果如图8b所示,3种模型均能不同程度地对地膜特征微弱的灌溉地膜和旱作透明膜进行识别。
2.3.2地膜农田表观变化对识别结果的影响
由于种植作物和气象的变化,实验田2年的地膜农田表观有一定的差异。实验1为在2019年4块地上测试模型的泛化性能。实验2针对第2年地膜农田表观的变化,在第1年数据集的基础上,将第2年反映地膜农田表观变化的一部分样本数据增加至训练集中,在2019年剩余的数据上进行测试,以提高模型的分类精度。
增加数据集后,训练集地膜农田样本类型更丰富,表2中实验2的结果表明,SegNet、DeepLabv3+和改进的DeepLabv3+模型在4块实验田上的地膜识别分割精度相对于实验1都有提高。其中,SegNet、DeepLabv3+和改进的DeepLabv3+在4块大田的平均分类精度分别提升13、8.5、7.7个百分点,SegNet提升精度最高。特别地,2019年3号实验田地膜表观相对于2018年有明显变化,而上一年的训练集没有该类样本,导致实验田3种分割模型的识别精度都比较低。当实验2训练集中增加了相应的地膜样本后,分类精度均有显著提升。
图9为2019年3号实验田3种分割模型的实验1和实验2部分识别结果。在实验1中,对于训练集中未见过的表观变化较大的旱作透明膜,SegNet、DeepLabv3+以及改进的DeepLabv3+模型均不同程度地将其识别成旱作黑膜,其中SegNet分类错误最为明显。在实验2中,当训练数据经扩充更具代表性后,3种分割模型对这类旱作透明膜的分割精度显著提高,分类错误明显降低。
通过对比实验1和实验2数据集上的识别效果,可以明显看出由于外界因素导致的地膜表观出现较大变化,扩充其数据能够有效提升该类别地膜的识别精度,这表明增加地膜农田数据的多样性有助于建立一个从复杂场景中识别各类地膜的鲁棒模型。
2.3.3基于注意力机制的改进DeepLabv3+分类性能分析
DeepLabv3+网络的ASPP结构中过大的扩张率,对地膜农田遥感影像识别时,容易造成目标边缘分割不连续和分割结果出现空洞。本文通过在DeepLabv3+中增加注意力机制,以抑制这种现象,从而提高分类精度。表2表明,在实验1和实验2中,改进的基于卷积注意力机制的DeepLabv3+模型相对于原始的DeepLabv3+模型,在4块实验田上均有提升,并且平均像素精度优于SegNet和DeepLabv3+。改进后的DeepLabv3+模型在1号、2号、3号和4号地的分类平均像素精度分别提升0.7、3.3、21.4、5.2个百分点,实验1的平均像素精度比原网络高2.2个百分点,实验2的平均像素精度比DeepLabv3+提高1.4个百分点。表明添加注意力机制后的DeepLabv3+网络模型相对于原网络,识别性能有效提高,验证了提出模型的适用性。
基于注意力机制的DeepLabv3+网络,能够实现自适应学习地膜特征,分割效果见图10。从图10c的1号地和4号地可以看出,DeepLabv3+分割结果的地膜边缘不准确,存在明显错分的现象。而卷积注意力模块能够利用不同通道的相关地膜农田类别特征间的联系,会对不同地膜农田特征类别进行特征强化,突出相互联系的特征图并使特定的地膜语义特征得以促进,从而较好地分割出目标。图10d中1号地和4号地为改进后网络的分割结果图,可看出该块区域旱作透明膜边缘分割像素错分问题得到明显改善,分割效果更好。从图10c的2号地和3号地可看出,地膜分割时都不同程度地出现尺寸不一的空洞,而加入的卷积注意力模块能够获取丰富的全局特征的上下文信息,增强不同位置同类地膜农田特征,从而减少大面积地膜农田分割出现的空洞问题,图10d的2号地和3号地显示了改进后的DeepLabv3+网络对抑制空洞现象的有效性。
3 结论
(1)在3种深度语义分割模型上,基于多光谱遥感影像的识别效果均优于可见光,表明相较于基于可见光遥感影像,多光谱遥感影像更多的光谱信息有助于提升复杂场景中地膜农田的识别精度。
(2)将地膜农田表观变化的数据增加至样本训练数据集时,SegNet、DeepLabv3+及改进的基于卷积注意力机制的DeepLabv3+语义分割模型,对于旱作透明膜、旱作黑膜以及灌溉地膜的识别精度均有所提升。这表明训练样本更丰富的地膜农田数据能提升模型对于无人机多光谱遥感影像地膜农田的分类精度。
(3)基于卷积注意力模块的改进DeepLabv3+网络模型,相比于原始的DeepLabv3+,在2组实验的每块实验田上均表现出稳定的提升效果,表明注意力机制能够有效减少遥感影像中大尺度目标分割存在的空洞现象,并且利用通道和空间像素特征信息能够较好地推断出大面积地膜覆盖的边缘特征位置,有效克服原始DeepLabv3+模型应用于无人机遥感影像中,对地膜农田分割不准确的问题。
