基于卷积神经网络的生菜多光谱图像分割与配准
2021-10-13黄林生卢宪菊郭新宇樊江川
黄林生 邵 松 卢宪菊 郭新宇 樊江川
(1.安徽大学农业生态大数据分析与应用技术国家地方联合工程研究中心, 合肥 230601;2.国家农业信息化工程技术研究中心, 北京 100097; 3.数字植物北京市重点实验室, 北京 100097)
0 引言
生菜是世界上广泛种植的一种重要的经济蔬菜作物,美国、欧洲和中国产量较高[1]。生菜富含维生素、类胡萝卜素、抗氧化剂和其他植物营养素[2],是常见的蔬菜之一。生菜叶片是生物量累积的主要器官,其在营养生长过程中可多次收获[3],因此如何无损地监测生菜生长状态和确定其采摘时期具有重要意义。
现阶段传感器技术和图像分析技术快速发展,在获取丰富数据的同时,可挖掘的图像信息也越来越丰富。拼接、配准、融合、语义分割和目标识别等技术是图像挖掘的基础。多光谱成像技术因其具有无损、快速、高效等优点,在对作物表型[4]以及生理状态的监测和分析中具有广阔的应用前景。其中,如何快速、精准地通过多光谱图像对作物进行感兴趣区域(ROI)提取是数据分析的前提,具有重要的意义。
光谱成像技术因其具备能够同时表征作物生长状态及生理生化信息的图像和光谱特征,近年来已被广泛应用于农业领域,如作物的品质检测、长势检测等领域。Pix4D软件、ENVI软件在处理离地面较近,如地面表型平台或者近地使用多光谱相机对作物进行拍摄分析表型(一般多光谱相机与地面距离1~3 m时),并不能解决5通道引起的相位差,导致在分析光谱时产生较大误差。根据已有的研究,常用的匹配算法可以归纳为:像素匹配[5]、区域匹配[6]、特征匹配[7-9]、相位相关匹配[10]等。但采用单一的匹配算法进行图像匹配,往往难以达到理想的匹配结果。Canny算法[11]是一种高效的边缘提取算法,对噪声具有较强的抗干扰能力,提取的边缘只有一个像素,准确度较高。因此使用Canny边缘提取算法与相位相关算法结合的方法对多光谱图像进行配准,可以大幅度降低图像配准时间。
从农业场景分割问题的大量研究成果来看,目前常用的一些图像分割算法主要可以分为4类:基于阈值的分割算法[12-13],基于聚类的分割算法[14-16],基于分类的分割算法[17-18],以及基于图论的分割算法[19-20]。传统分割算法大多基于人工提取图像的灰度、颜色、纹理和空间等特征,利用增强前景和背景区域的差异性来实现图像前景的分割,因此在图像处理过程中往往存在大量欠分割和过分割的情况。随着深度学习技术的发展,其在自然语言处理[21]、图像识别[22]、视频跟踪[23]等领域的应用和推广均超越了传统的机器学习算法。2015年美国笛卡尔实验室宣布开展深度学习在农业上的应用,此后卷积神经网络因其较强的图像特征提取能力开始广泛应用于农业领域,越来越多的学者开始将深度学习应用于作物表型信息获取分析[24]。文献[25]提出的全卷积神经网络(Fully convolutional neural networks,FCN)因其可以针对任意尺寸的输入图像并且实现端到端的像素分类,成为解决图像分割问题的重要方法。当前多数先进的语义分割框架均基于FCN实现且被应用于农业的各个领域。然而,FCN的分割精度并不能满足细粒度表型提取的要求。UNet是一种基于全卷积网络扩展的图像分割算法[26],其通过对图像进行下采样后再进行上采样,跨连接层实现上下文信息融合,从而拥有更加丰富的语义特征和更加精准的分割效果。VGG16[27]卷积神经网络是牛津大学视觉几何组提出的深层特征提取网络,增加网络深度能够提升网络的最终性能,在图像领域获得了广泛应用[28-29]。UNet语义分割模型因其网络结构在对图像进行分类时取得较好的效果得以在农业上广泛应用,但因其特征提取网络深度不够,无法提取图像更深层次的语义特征,不能满足精细化表型的提取要求。使用VGG16网络进行图像特征提取,加深网络深度,同时结合UNet语义分割模型网络结构可对多光谱生菜图像进行精细分割。
目前应用于农业领域的语义分割模型多因细粒度程度不够且分割精度无法满足需求而难以实现生菜多光谱图像精细化表型信息提取。针对这些问题,本文提出基于VGG特征提取网络的UNet语义分割模型来对生菜多光谱进行精准分割,使用结合Canny边缘提取算法的相位相关算法对生菜多光谱图像进行精确配准,以期为后期分析多光谱图像,提取生菜表型和生理信息提供参考。
1 实验材料
1.1 生菜多光谱图像采集装置
实验在北京市农林科学院联合大温室进行。生菜种植区尺寸为10 m×40 m,生菜采用盆栽,共计种植271个材料,每个材料有4株生菜,按2×2摆放,正常水肥管理,具体种植示意图如图1a所示。
种植区内部署了冠层图像采集装置,如图1b所示。冠层图像采集系统包括:植物表型平台基础结构、表型平台控制机构、传感器数据采集模块、数据传输系统。图像采集系统布设在种植区冠层顶部4 m高处,成像高度可以在1~3 m范围内自由调节。图像采集是由远程控制端(移动端手机或者服务器端)发出图像收集指令。图像采集装置收到远程指令后按照设定好的路线和采集方式进行采集,采集到的图像可以通过无线路由端实时传输到服务器端。常用多镜头多光谱相机如图2所示,本研究采用MicaSense Altum 5通道多光谱相机,可以采集蓝(B)、绿(G)、红(R)、红边(Red edge)、近红外(NIR)5个通道的多光谱图像,Altum多光谱相机可以同时收集5个不连续的光谱波段,并且使用窄带滤光片提供针对单一波段图像大分辨率。相机参数见表1。

表1 MicaSense Altum相机参数Tab.1 MicaSense Altum parameters
1.2 多光谱图像获取及数据集构建
实验图像采集高度设定为1.5 m,图像采集装置移动速度设置为0.05 m/s,多光谱相机设定为4 s拍摄一次,拍摄完整各种植区共获得1 200幅多光谱图像。
经过筛选,剔除高重叠度图像(纵横重叠度在30%以上),共获得400幅有效多光谱图像,并形成原始图像数据集。为了减小图像尺寸、提高后期模型训练效率,将图像尺寸从2 064像素×1 544像素缩放为512像素×512像素。由于CNN卷积神经网络需要大量的训练数据以避免数据分析过程中出现过拟合现象,使用旋转、镜像、缩放、添加高斯噪声等方式进行标记样本数量扩充。最终数据集包含2 310幅图像,并以7∶3随机划分为训练集和测试集,因此共有1 617个训练样本输入UNet模型进行训练,其余693幅图像进行测试。
2 实验方法
多光谱图像配准与分割算法主要流程如图3所示,第1阶段对输入的多光谱图像使用Canny算法进行边缘提取,将得到的边缘提取图像使用相位相关算法得到各通道图像之间的平移参数,之后将各通道图像配准到相同位置。第2阶段将得到的配准后的生菜多光谱图像进行前景像素提取,利用UNet架构的优点,使用VGG16作为主特征提取网络,构造了生菜多光谱分割模型,将各通道的生菜多光谱图像从背景中精确分离出来。
2.1 改进相位相关算法对多光谱各通道图像配准
相位相关算法是将图像变换到频域,求得互功率谱,由峰值位置得到2幅图像的平移参数,由于需要估计整幅像素精度的平移参量,算法耗时较长。本文使用Canny算法对图像进行边缘特征提取,将得到的边缘图像作为后续算法的操作对象,可以大幅降低相位相关算法的图像配准时间。算法流程图和示意图如图4所示。
2.1.1Canny边缘检测算法
本文Canny边缘检测算法的处理流程可以分为以下4个步骤:
(1)噪声去除:由于边缘检测很容易受到噪声影响,所以首先使用5×5的高斯滤波器来平滑和去除噪声。
(2)计算图像梯度:对平滑后的图像使用Sobel算子计算水平方向和竖直方向的一阶导数(图像梯度Gx和Gy),根据得到的这2幅梯度图(Gx和Gy)找到边界的梯度和方向,公式为
(1)
(2)
式中 Edge_Gradient(G)——像素点的灰度函数
Angle(θ)——像素点的梯度函数
梯度的方向一般总是与边界垂直。梯度方向被归为4类:垂直、水平和2个对角线。
(3)使用非极大值抑制(即寻找像素点的局部最大值,将非极大值所对应的像素点灰度设置为0)来消除边缘检测带来的杂散响应。
(4)滞后阈值:需要通过设定2个阈值来确定真正的边界,对于低于minVal阈值的像素点直接抛弃,高于maxVal阈值的像素点为真正的边界。如果处于阈值之间的像素点与真正的边界点相连便认为其也是边界点,否则抛弃。
如图5所示,D线段像素都处于minVal阈值外面,因此D直接抛弃;A是高于maxVal阈值的像素点,属于真正的边界点;B像素虽然处于2个阈值之间,但是没有与真正的边界点相连,所以也被抛弃;C像素与真正的边界点相连,因此也得以保留。因此选择合适的阈值点对于边缘检测非常重要。
本文中Canny算子的阈值设置minVal为0.2,maxVal为0.6,用来计算图像梯度的Sobel卷积核的大小设置为3,使用L2gradient参数作为求梯度大小的方程。通过Canny算法得到的边缘图像作为后续进行相位相关算法的操作对象。
2.1.2相位相关匹配算法
图像配准是图像处理的基本任务之一,其主要用于将不同时间、不同传感器、不同视角或者不同拍摄场景获取的关于同一目标或者场景或者多幅图像进行最主要几何意义上的匹配过程。本文中室内冠层采集装置使用MicaSense Altum多光谱相机进行多光谱数据采集,其采集到的数据是5幅不同波段的图像,5幅图像来自5个镜头拍摄,图像之间具有水平偏移。图像的平移运动可以通过傅里叶变换到频域中相位的变化表现出来,所以本文采用基于相位相关的模板匹配方法精确计算不同波段之间图像的相对平移量。
假设f1(x,y)和f2(x,y)为2幅图像的时域信号,其满足的关系(即f2(x,y)由f1(x,y)经过简单的平移得到)为
f2(x,y)=f1(x-x0,y-y0)
(3)
根据傅里叶变换的性质可得
F2(u,v)=F1(u,v)e-j(ux0+vy0)
(4)
式中F1(u,v)——f1(x,y)的傅里叶变换
F2(u,v)——f2(x,y)的傅里叶变换
其互功率谱为
(5)
e-j(ux0+vy0)的傅里叶反变换为一个二维脉冲函数δ(x-x0,y-y0)。求取式(4)的傅里叶反变换,然后找到最高峰的位置,最高位置的坐标即是平移参数x0、y0。
图6a~6c为多光谱3个通道图像,分别对B通道与R通道、G通道与R通道进行相位相关算法计算求得互功率谱,再对其求傅里叶反变换,得到2个二维脉冲函数,对其定位峰值可分别得到B通道与R通道、G通道与R通道的位移偏差。将其配准后进行叠加融合得到图6f的3通道真彩图像。图7为相位相关算法与本文算法在多光谱各通道上的匹配时间。
本文采用Canny算法与相位相关算法相结合对多光谱各通道图像进行配准,如图7所示,相较于传统相位相关算法在各通道配准时间上均有大幅度提高。
为验证本文算法,选取2个基于特征点匹配的经典算法SIFT(Scale-invariant feature transform)尺度不变特征变换算法和SURF(Speeded up robust features)加速文件特征算法作为对比,用单幅图像的配准时间和匹配准确率作为评价指标,结果如表2所示。
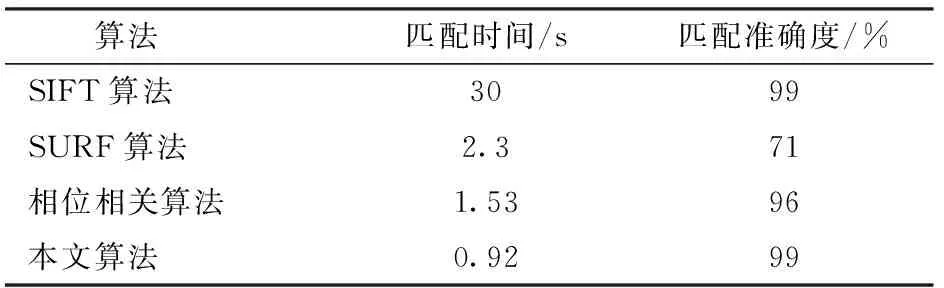
表2 算法测试结果Tab.2 Algorithm test result
由表2可以看到,基于特征点匹配的SIFT算法虽然匹配精度很高,但是匹配速度太慢,SURF算法精度不高,本文算法相对于传统单一相位相关算法在匹配精度上提升3个百分点,匹配时间上减少了0.61 s,效率提高了40%,本文算法在配准精度和速度上都有比较明显的优势。
2.2 基于UNet模型的生菜多光谱图像语义分割
2.2.1UNet网络结构
UNet是目前比较流行的用于语义分割的深度学习模型,它是在全卷积网络(FCN)的基础上做了改进,提高了传统的CNN模型用于像素级图像分类的性能。UNet的主要结构由卷积编码单元和卷积解码单元组成。重复的卷积运算在网络的2个部分被一个矫正的线性单元执行。在编码单元中,执行2×2的最大池化操作,将输入的样本降为2倍下采样。在每个降采样相位之后,特征数增加1倍以补偿分辨率的损失。解码单元由上采样块组成,通过使用卷积对输入进行上采样后,将上采样的特征映射与编码单元提取的相应特征映射连接起来,使网络在下采样过程中最大限度地保留最基本的特征信息。重复上采样块,直到网络的输出与输入图像的尺寸匹配。一般情况下,编码单元主要用于捕获图像中的上下文信息,解码单元用于精确定位需要分割的部分。UNet模型在语义分割方面有几个关键优势:首先,它结合了低层细节信息和高层语义信息,允许网络在大空间尺度上利用信息,而不会丢失有用的本地信息。其次,它只需要少量的训练样本就可以获得更好的分割性能。最后,端到端网络处理整个图像并直接产生分割图像。
2.2.2VGG16特征提取网络
目前研究人员开始应用UNet模型分割多通道遥感数据并提供了有效的解决方案。在本研究中,根据UNet模型的特点,采用VGG16作为主干特征提取网络。结构如图8所示,本文采用Imagenet上的预训练权重进行迁移学习,来提高模型的泛化性。
当输入的图像尺寸为512×512×1时,VGG16网络的具体参数配置如表3所示。

表3 特征提取网络结构参数配置Tab.3 Configuration of network structure parameters for feature extraction
2.2.3整体网络结构
本文使用的UNet网络结构主要由主干特征提取网络(VGG16)和加强特征提取网络构成,其形状可以看作U型。利用VGG16主干特征提取网络可以获得5个初步的特征层,在加强特征提取网络里,利用这5个初步有效特征层进行特征融合,特征融合的方式就是对特征层进行上采样并且进行堆叠。为了方便网络的构建和更好的通透性,在加强特征提取网络里,在进行上采样时直接进行2倍上采样再进行特征融合,这样最终获得的特征层和输入图像的宽高相同。具体示意图如图9所示。
2.2.4模型训练
采用非线性函数ReLU作为模型隐藏层的激活函数,如图10所示,ReLU由于非负区间的梯度为常数,因此不存在梯度消失问题(Vanishing gradient problem),使得模型的收敛速度维持在一个稳定状态。
(6)
使用UNet全卷积神经网络进行图像分割,目的是为了输出一个分割精度较高,尺寸与输入图像相当的分割结果,本文所使用的损失函数主要由Cross Entropy Loss和Dice Loss组成。模型最终输出一个二分类图像,使用Softmax对像素点进行分类时使用Cross Entropy Loss 作为Loss损失函数。交叉熵主要是用来表达神经网络输入输出的结果差异,一般来说,交叉熵越小,输入和输出的结果就越接近。分类的交叉熵损失函数为
(7)
式中x——输入向量
C——当前样本类别对应索引
x[C]——当前样本预测函数输出
x[j]——预测函数第j个输出
Dice Loss将语义分割的评价指标作为Loss,Dice系数是一种集合相似度度量函数,通常用于计算2个样本的相似度,取值范围为[0,1]。越大表示预测结果和真实结果重合度越大,所以Dice系数越大越好,而Loss则越小越好,计算公式为
(8)
式中 Dice_Loss——损失函数
X——预测值像素点集
Y——真实值像素点集
模型训练过程就是对损失函数进行优化的过程。本文模型训练采用适应性矩估计优化算法(Adaptive torque estimation optimization algorithm,Adam),和一般传统的随机梯度下降不同。Adam作为一阶优化算法可以在迭代训练数据时更新神经网络权重,并且其实现方式更直接,可以解决大规模数据和参数的优化问题,计算高效且所需内存少。
2.2.5评价指标
为了量化本文语义分割方法对生菜冠层多光谱图像的分割效果以及对比不同方法的分割性能,在此引入平均像素准确率[30](Mean pixel accuracy,MPA)、平均交并比(Mean intersection over union, MIoU)、召回率(Recall)、精确率(Precesions)和F1值(F1-Score)来进行评价。
考虑到实际使用中需要处理高通量的冠层图像数据,本文利用平均处理时间来说明不同方法的时间性能。平均处理时间定义为某个分割方法对单幅图像分割所需时间的平均值。
3 结果与分析
3.1 实验参数设置及训练过程分析
在软件环境为Windows 10系统,开发语言环境为anaconda 3和Python 3.6,硬件环境为Intel(R)Xeon(R) CPU E5-2697处理器和NVIDIA GTX1070 Ti GPU的计算机上进行实验,深度学习开发框架为Tensorflow_Keras。
本文模型训练将初始学习率设置为1×10-4,衰减率设置为0.9,将训练集的1 617个训练样本每2幅图像作为一个批次(batch)输入到模型中进行训练,训练一共进行300个epoch迭代循环。为了加快训练速度和训练初期防止权值被破坏,本文在训练的前10个epoch冻结一部分神经网络进行训练,之后把所有神经网络进行解冻训练,同时将学习率调整为1×10-5,衰减率依然设置为0.9。
3.2 不同模型和网络结构精度比较
为了测试和对比本文所提出模型的性能,对测试集693幅生菜多光谱冠层图像采用传统的UNet方法、本文方法UNet_VGG、一种编码解码语义分割网络方法SegNet[31](A deep convolutional encoder-decoder architecture for image segmentation)、基于VGG特征提取网络的SegNet方法、金字塔场景解析网络方法PSPNet[32](Pyramid scene parsing network)以及基于VGG特征提取网络的PSPNet方法进行语义分割并分析。
对比6个模型的精确率曲线和损失值曲线可以看出(图11),UNet模型比SegNet模型的收敛速度更快,并且分割的精度也更高。用VGG作为特征提取网络的模型要比传统语义分割模型的分割精度更高,随着迭代次数的增加,模型分割精度不断上升并趋于稳定,当迭代到300个epoch时,损失函数值基本收敛,表明模型达到了比较好的训练效果。
表4显示了本文所提出的模型UNet_VGG与其他语义分割模型在测试集上的性能对比,可以看到,相较于传统的UNet模型,UNet_VGG的平均像素准确率和F1值得分均有不同程度的提高。其中PSPNet模型在测试集上的表现最差,表明在处理二分类分割问题时,UNet模型分割相较于其他语义分割模型具有很大的优势。相较于原有模型,在使用VGG作为下采样进行特征提取时,模型精度均有不同程度提高。本文模型UNet_VGG与其他模型的分割效果对比如图12所示。
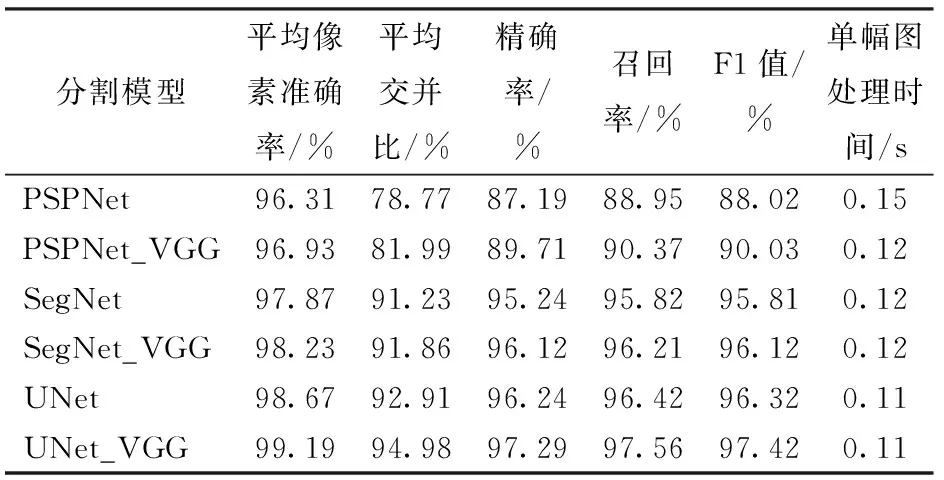
表4 不同分割方法测试集分类结果对比Tab.4 Comparison of classification results of samples for validation by different segmentation algorithms
4 结论
(1)针对多镜头多光谱相机在近距离拍摄时各通道图像存在位移偏差,采用Canny算法与相位相关算法结合的方法对多光谱各通道图像进行配准,结果表明结合算法有更高的配准精度,且相对于单一算法图像配准时间减少0.61 s,效率提高了40%。
(2)为满足对作物精确表型提取的需求,以配准后的生菜多光谱图像构建图像数据集。在UNet模型基础上,特征提取网络部分使用VGG网络,构建了本文模型。该模型在测试集上的平均分割准确率为99.19%,平均交并比为94.98%,相较于传统UNet模型分别提高0.52个百分点和2.07个百分点。本文方法单幅图像平均处理时间为0.11 s,可以满足对植物表型图像实时分割的要求。
(3)实验结果表明,本文方法可以对多光谱图像进行精确配准和生菜前景的精确提取。
