一种面向任务需求的群智感知任务分配模型*
2021-09-24廖祎玮赵国生谢宝文
王 鑫,廖祎玮,赵国生,王 健,谢宝文
(1.哈尔滨师范大学计算机科学与信息工程学院,黑龙江 哈尔滨 150025; 2.哈尔滨理工大学计算机科学与技术学院,黑龙江 哈尔滨 150080)
1 引言
移动群智感知是指利用移动设备来收集、分析和共享感知信息与数据。随着移动设备的普及,移动群智感知技术得到了越来越多的关注[1],并且已经广泛服务于各大应用领域,如交通状况监控[2]、环境监测[3]和移动社交推荐[4]等。在移动群智感知系统中,感知任务具有类型多、范围广和数量大等基本特性。面向不同的任务需求,将任务分配给合适的用户以提高任务与用户的匹配度,同时提高任务的分配效率成为群智感知任务分配的关键。
目前,国内外很多学者对群智感知任务分配问题展开了研究。Amintoosi等[5]针对社会感知中参与者复杂的、未知的社交关系提出一种参与者选择架构,根据参与者的适合性得分和参与者间的相互信任度选择合适的参与者。Xiao等[6]基于贪心算法提出了一种最大程度提高已招募用户的效率同时在截止时间内使感知支出最小的用户招募算法,该算法招募多个用户合作完成感知任务。韩俊樱等[7]提出了基于贪婪算法的分布式多任务分配方法,该方法划分任务和用户区域,动态定价并发任务组合构成的任务路径,根据感知用户的历史信誉度分配任务。上述任务分配机制主要以用户或平台为中心进行设计,没有考虑任务与用户的联系。为解决上述问题,Zhao等[8]提出一种每个任务最多由一个用户来完成的感知任务拍卖机制,该机制并没有考虑任务分配过程中用户可靠性的影响。Peng等[9]提出在任务分配时首先预测用户的期望任务完成质量来选择高可靠性的用户,并且为了使用户提交的数据质量更高,根据用户实际提交的数据质量来决定用户的报酬。刘媛妮等[10]以最大化用户效用为目的提出了一种基于拍卖模型的激励机制,该机制以任务为中心选择赢标用户且基于临界价格对赢标用户支付报酬,该机制中用户可将未完成任务转售他人。Han等[11]研究了一种用户根据感知时间和感知成本对平台发布的感知任务进行竞争的激励机制,感知平台在预算约束下支付报酬。Koutsopoulos[12]基于反向竞拍模型考虑到平台的预算条件约束,设计了一种最小化平台预算成本的激励机制,该机制结合用户贡献的数据量和数据质量进行用户选择与报酬支付。
群智感知中感知平台发布的任务是多类的,用户完成不同类别任务的效力也互不相同,上述研究均没有考虑到面向任务需求的用户分配问题,无法满足任务需求的复杂性。王涛春等[13]提出了从5个方面评估参与者信誉度的参与者信誉评估方案,包括参与者历史信誉度、提交数据的响应时间、距离、数据相关性和数据质量,通过建立信誉评估方程计算出参与者本次提交数据后的信誉度,新任务由群智感知网络根据更新后的信誉度选择合适的参与者来完成。Messaoud等[14]提出了在满足信息质量与能量约束的条件下,最大化信息质量和最小化能耗地选择合适的用户参与感知任务,该机制基于禁忌搜索算法且对能量和信息质量敏感。Li等[15]基于感知任务的实时性和异构性难题提出根据离线算法和在线算法来招募合适的参与者。Luo等[16]提出了一个基于Stackelberg博弈的激励框架,该框架考虑了不同情况下平台和用户之间的交互关系以及任务之间的相互关系。Feng等[17]设计一种考虑用户和任务的位置关联的激励机制,该机制基于逆向竞拍框架,用户根据自身的位置信息响应感知任务并上报目标报酬,感知平台通过赢标价决策算法决定赢标价,以最小化预算成本。上述任务分配机制虽面向任务需求对用户进行选择,但未明确用户适合完成任务的类别,未考虑用户具有完成多类别任务的能力,且一旦有新任务推送会再次对用户信息进行处理,增加了机制的整体复杂性。因此,构建一种以任务为中心,筛选适合任务类别且满足任务其他需求的用户的高效任务分配模型有重要研究意义。
针对上述问题,本文提出了一种任务需求特征提取算法TRFEA(Task Requirement Feature Extraction Algorithm)和用户标签分类方法相结合的TREAULCM(Task Requirement Extraction Algorithm and User Label Classification Method)任务分配模型。利用任务需求特征提取算法提取感知任务的类别关键词,通过多线性神经网络训练得到数据集中各类数据的高层特征并利用径向基核函数将高层特征融合,通过多核学习训练得到分类器,利用分类器预测用户的类型标签。根据任务类别、空间位置信息和用户参与度选择满足任务需求的用户分发任务。本文主要贡献包括以下2点:
(1)本文通过用户标签分类方法得到适合用户的任务类别标签,根据任务需求选择合适的用户进行任务分发,实现用户优选。
(2)本文针对多线性神经网络2个全连接层提取到的特征,采用多核学习方法将它们在核空间中自适应融合,融合后的特征有更好的表现力和鲁棒性。
2 群智感知任务分配模型
群智感知的经典网络体系结构由任务发布者、感知平台和感知用户3部分组成。任务发布者向感知平台购买感知数据;感知平台根据感知任务需求和激励机制等选择合适的感知用户发布任务,并对用户提交的数据进行评估和支付报酬;感知用户可根据自身条件有选择性地参与任务。
2.1 模型描述
本文提出的任务分配模型如图1所示。该模型首先对感知任务进行处理,明确感知任务类别,然后通过用户标签分类方法对数据集进行训练,得到分类器,利用分类器得到适合用户处理的任务类别并给予用户该类标签。在任务分配过程中,感知平台选择符合任务类别且满足其他任务需求的用户执行任务,使任务分配更有针对性,任务完成后对用户的标签进行迭代预测。
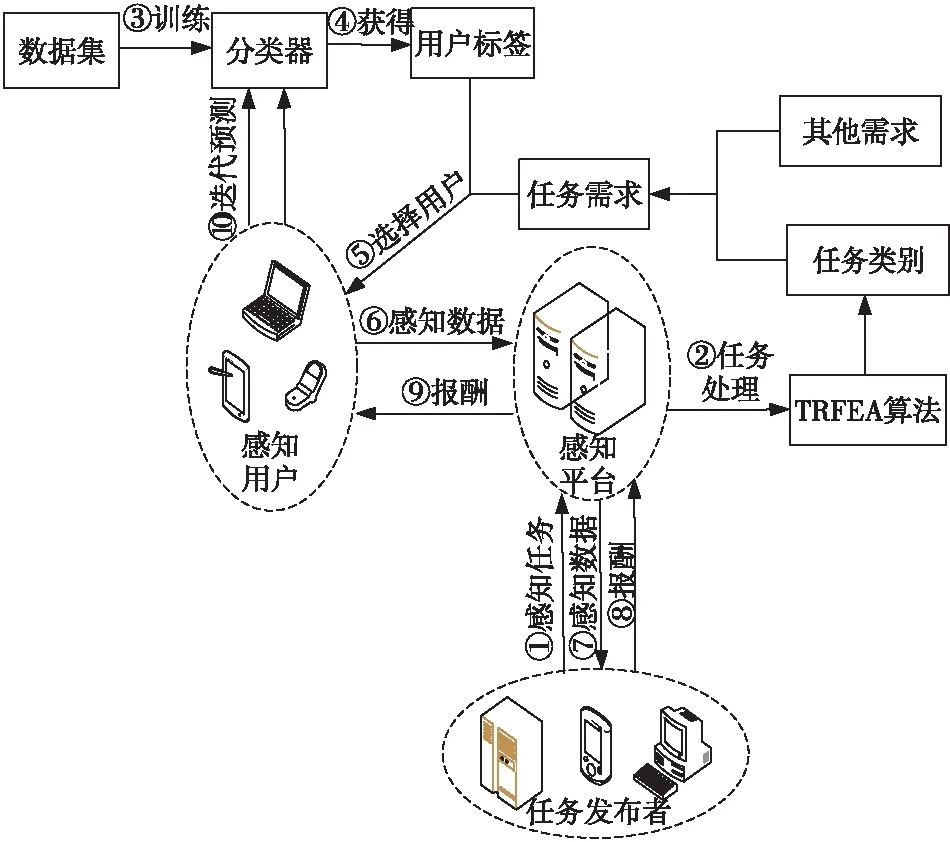
Figure 1 Model of task assignment图1 任务分配模型
2.2 问题描述
感知平台发布的不同类别的感知任务,意味着不同的任务需求。只有从任务需求的角度选择和感知任务需求匹配度更高的用户参与任务,才能最大限度保证任务的完成率和感知数据的可用性,使得资源利用最大化,减少感知平台工作量。本文提出任务需求特征提取算法TRFEA和用户标签分类方法,其中TRFEA用于提取感知任务类型的关键词;用户标签分类方法用于提取用户类型标签。
3 任务需求类型的提取
发布的感知任务可形式化地描述为任务属性向量task=(Tt,U,Lab,St,W,Par),其中,Tt代表任务的文字描述;U代表需要招募的感知用户数量;Lab代表任务要求的用户类型;St为感知任务的位置信息;W为任务要求的距离远近度;Par为任务要求的用户参与度。用矩阵Bg×e存放任务向量,其中g个任务用g行表示,任务的第e个属性用第e列表示。任务集可表示为Task={task1,task2,…,taskt}。
感知用户可形式化地描述为用户属性向量user=(X,Y,Su),其中,X为用户的数据集;Y为用户的标签集;Su为用户的位置信息。用矩阵Qx×f存放用户向量,其中x个用户用x行表示,用户的第f个属性用第f列表示。用户集可表示为User={user1,user2,…,useru}。为了方便理解,表1给出了本文部分符号标记及其对应的定义。

Table 1 Symbols and their definitions表1 符号及其定义
本文提出了TRFEA算法来提取感知任务的类别关键词。TRFEA算法用隶属度确定每个数据点属于某个聚类的程度并自适应地确定聚类中心个数。去除任务文字描述中无实际意义的虚词和代词,得到所有任务的词集Tx={T1,T2,…,Tnu},将其用空间向量模型表示,转换成高维空间中的向量,然后对这些向量聚类。Txi表示任务taski的词集,任一Txi可表示为以特征项的权重为分量的向量Ti,其中每个词或词组作为特征项,权重为词或词组出现的频数。
每个Ti到聚类中心Cj(j=1,2,…,q)的隶属度Fij的计算公式为:
(1)
其中,ψ是模糊指数,此处取ψ=2;‖Ti-Cj‖表示第i个任务的描述向量与第j个聚类中心之间的欧几里得距离,所有任务到每个聚类中心隶属度总和为1。
聚类中心的计算公式为:
(2)
设置目标函数JFK:
(3)
对于聚类算法得到的聚类中心集C={C1,C2,…,Cq}中任一聚类结果Cs,把构成Cs的每一个任务看作一个有v个不同单词的序列W=(w1,w2,…,wv),每一个wi到该类的主题词服从泊松分布,并把聚类中心集C中涉及的所有不同单词组成大集合Word。通过统计主题LDA(Latent Dirichlet Allocation)模型来识别潜藏的主题信息。TRFEA算法流程如算法1所示:
算法1TRFEA算法
输入:任务描述集Tx={T1,T2,…,Tnu}。
输出:各类任务的类别关键词集合Lab。
步骤1随机得到自适应q个模糊聚类中心Cj,并初始化,设迭代次数num=0;
步骤2通过式(1)计算每个Ti到聚类中心Cj的隶属度Fij;
步骤3通过式(2)计算聚类中心。根据Cj的变化,重新计算隶属度Fij;
步骤4通过式(3)计算目标函数JFK,如果目标函数不收敛,num=num+1,返回步骤3,否则得到聚类中心集C,转步骤5;
步骤5设置主题的参数α和词的参数δ,两者均随着训练和学习过程自动变化;
步骤6对于聚类结果Cs中每个词wi,根据其到各个主题发生的概率P(θ|α)得到主题分布θ,主题个数设为Tnum,并以概率P(Zs|θ)选择当前的主题Zs;
步骤7按照当前主题Zs下的多项分布概率P(topici|Zs,δ),选择一个单词topici,topici∈Word;
步骤8对于每类任务主题词的结果集Topic={topic1,topic2,…,topicTnum},返回步骤1进行聚类分析,直到结果集Topic不再变化,转步骤9;
步骤9Lab=Topic,并返回Lab。
4 用户标签的分类
明确任务需求基础上的用户选择问题实际上是筛选和任务需求更匹配的用户,本文提出了一种多线性神经网络结合多核学习的用户标签分类方法,如图2所示,其中MLSVM(Multi Label Support Vector Machine)表示多核支持向量机。该方法首先通过多线性神经网络训练数据集得到各类数据的高层特征并利用径向基核函数融合特征,根据已知的类别信息通过多核学习训练得到一个分类器,待预测用户的数据经过分类器可得到该用户的标签集。
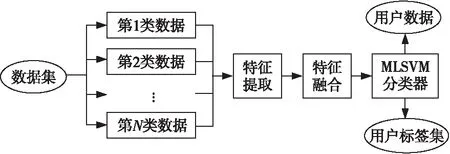
Figure 2 Framework of user label classification method 图2 用户标签分类方法框架
4.1 感知数据特征提取
对于数据集{(X1,Y1),(X2,Y2),…,(XHH,YHH)},数据集中数据信息表示为Xh={xh1,xh2,…,xhη},xh*∈χ,χ为数据空间,η为Xh中数据个数,Yh⊆Y为Xh的标签集Yh={yh1,yh2,…,yhλ},Y为标签空间,λ为Yh中包含的标签个数。对数据集中每类数据均随机抽取2/3并去掉标签组成训练集Tr,对于每类数据进行高层特征提取并得到核函数。
本文设计了一种卷积层-池化层循环的优化多线性神经网络结构,保持了网络良好的可区分性,缩短了计算时间。本文搭建多线性神经网络结构提取各类数据的高层特征,该网络结构的前5层每层由卷积层和池化层构成,用l1~l5表示。ac1和ac2表示第6层和第7层,第6层、第7层为全连接层,将第6层和第7层特征作为2种不同的高层特征。将训练集Tr输入到搭建好的网络中。首先计算每个神经元的输出值。
(1)卷积层。
(4)
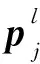
(2)池化层。
(5)

(3)全连接层。
(6)
其中,pl-1表示第l-1层所有特征图的加权结果。
其次,反向计算多线性神经网络整体损失函数。设任一带标签样本Ii(i=1,2,…,Nm),Nm表示训练集样本总个数,Ii的标签实际上是一对多标签。
(7)

(8)
损失函数E0的计算公式为:
(9)
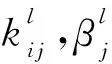
(10)
更新多线性神经网络的参数H,同时最小化损失函数E0:
(11)
其中,ω表示多线性神经网络的学习率,决定了每步调整的幅度;H(i)表示第i组更新的参数。
最后根据式(6),分别得到ac1、ac2层输出结果ac1-r、ac2-r,二者分别包含了ac1、ac2层计算得到的所有特征图,将其作为待融合的全连接层特征。
本文利用径向基核函数解决全连接层特征融合问题。进一步地,可以利用基于核的分类器得到用户的类型标签。
(12)
其中,k(Xn) 表示第n类数据的核函数;za表示Xn中第a个数据在多核某一尺度下ac1层的特征向量ac1-r;zb表示Xn中第b个数据在多核某一尺度下ac2层的特征向量ac2-r,μ表示带宽参数。
4.2 多标签分类器
在群智感知任务分配中一个用户可完成多类任务,故而用户的数据样本分布特征存在差异性,如果数据采用同一种高维映射方式,会忽略不同任务类别的差异性。因此,本文采用多核学习方法通过融合不同权系数的核函数使分类的灵活性和准确性更高。
根据得到的每类数据的核函数和训练集数据的类别信息,采用SimpleMKL工具箱训练得到一个MLSVM分类器hy并得到权系数βn(1≤n≤N),完成多核融合过程,如图3所示。
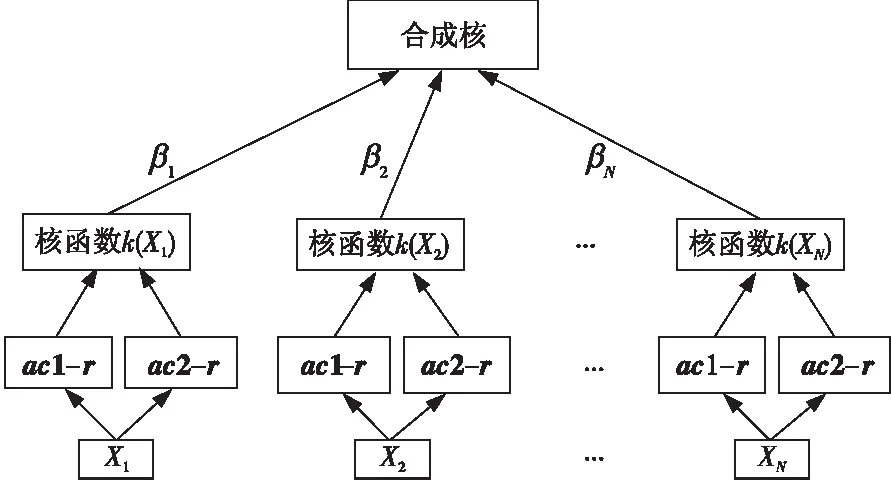
Figure 3 Multi-kernel fusion process图3 多核融合过程
(13)
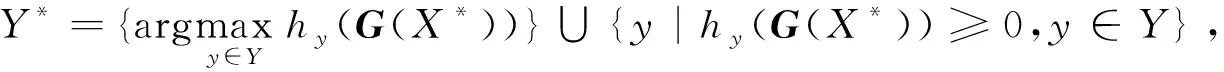
5 TREAULCM任务分配模型
本文根据任务的需求类别、距离远近度和用户参与度3种因素共同决定感知用户的选择,实现满足任务需求的任务分配。
在实际的群智感知任务分配问题中,感知平台希望选择距离较近的感知用户参与感知任务以减少报酬支出,感知用户也会偏向于参与离自身位置较近的任务,为了最大化用户的参与意愿,最小化平台支出,本文考虑到任务与用户的空间位置信息,提出距离远近度W作为任务分配的决定性因素之一,计算公式如下:
Wij=1-min[logodis(Sti,Suj),1],Wij∈[0,1]
(14)
其中,Wij为任务taski和用户userj的距离远近度,Wij越接近1,则无论从感知平台还是从用户角度考虑,双方的开销都越小;o为感知平台设置的任务区域半径,即在该半径内选择用户参与任务;dis(Sti,Suj)表示任务taski的位置Sti到用户userj的位置Suj的欧几里得距离。
为了选择更活跃的用户参与任务以保证已分配任务的完成情况,且调动用户的参与积极性,本文提出以用户参与度作为用户选择的决定性因素之一。在本文模型中,用户参与度由其之前在其他感知任务中的表现共同决定。
设frj是用户userj对所分配任务的执行总次数,fej是用户userj对所分配任务的未执行总次数,用户userj在过去任务中积累的执行情况为:
(15)
感知平台对用户提供的数据进行评分,评分值在[1,5],结合用户执行任务的情况,可计算用户userj的参与度:
(16)
其中,num为用户完成任务的总个数;s(i)为用户完成任务taski后平台的评分;min(i)和max(i)为对完成任务taski的所有用户,平台评分最低值和最高值。
TREAULCM任务分配模型详细描述如下:
(1)对于任务集Task={task1,task2,…,taskt},通过算法1得到任务taski的类别关键词Labi。
(2)对于用户集User={user1,user2,…,useru},将数据通过用户标签分类方法训练好的MLSVM分类器得到用户userj的类型标签集YLabj。
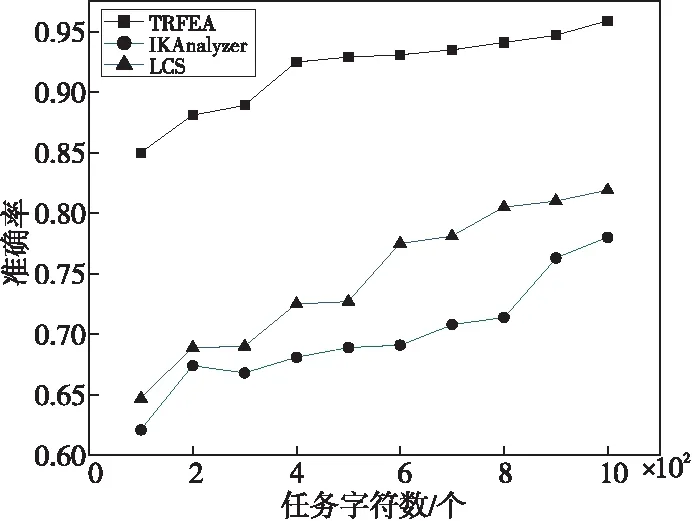
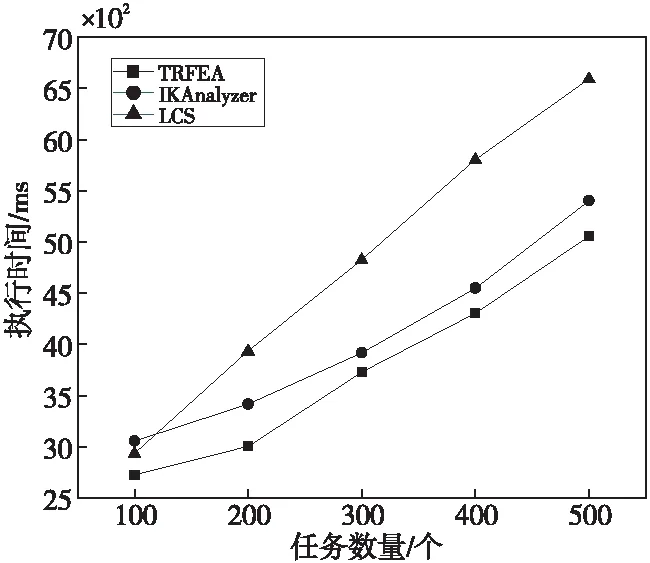
(3)根据任务要求的用户类型筛选用户。如果YLabj中某一元素是Labi中的元素,那么userj进入候选用户集Usercd={user1,user2,…,userc}(1 (4)计算候选用户集中所有用户到任务taski的距离远近度,形成以距离远近度降序排列的新候选用户序列Usercd1。 (5)对于Usercd1中用户,以用户参与度降序排列得到用户序列Usercd2。 (6)根据任务需要招募的感知用户数量,从前往后选取Usercd2中需求用户数量×120%个用户组成最终的待分发任务用户集。 为了验证本文的TRFEA算法在任务需求特征提取方面的效率和准确性,将TRFEA算法与IKAnalyzer算法[18]和传统的最长子串LCS(Longest Common Subsequence)算法进行对比。其中,IKAnalyzer算法[18]是一种中文文本的分词技术,它根据给定的字符而不是依赖于字符数量来分词,该算法扫描文本,遇到预先定义的字符才会进行分词;LCS算法具有语种独立性,适用处理中文文本,该算法不需要对文本内容进行语言预处理,并且对提取出的公共子字符串的长度没有限制。 为了验证本文模型在任务分配中的高效性和准确性,在相同实验环境下,将本文模型与采用余弦相似度计算方法的用户选择激励模型TRIM(Task Requirement-oriented user selection Incentive Mechanism)[19]和基于逻辑回归LR(Logistic Regression)方法的任务分配模型[20]进行比较。 实验基于Python 3.5以及TensorFlow 2.0实现,并在Linux环境下运行。本文数据集由公用数据集MSRC-v2[21]中的数据组成,MSRC-v2[21]数据集包含23类的591幅图像,每幅图像大小为320×213左右,其中很多图像同时属于多类。在数据集上每类数据均随机选取2/3的样本组成训练集,剩余样本用作测试。根据数据集MSRC-v2[21]随机生成由23种类别信息和其他文字组成的任务文字描述,每个任务描述大于100字符数,作为实验中的感知平台发布的任务信息,并对包含类别信息的词或词组进行标记,同时随机生成其他任务需求;由MSRC-v2[21]数据集中591幅图像数据组成用户的历史感知数据,并随机生成其他用户信息,构造100个感知用户。 根据数据集设置主题数目Tnum=23,聚类中心个数q=23,参数α=50/Tnum,参数δ=0.01,多线性神经网络中初始学习率ω=0.001,带宽参数μ=0.05,核函数的总个数N=23,在[0,1]随机选择用户参与度。 6.2.1 任务类别关键词提取准确率 TRFEA算法着重于提高任务类别关键词提取的准确率,任务类别关键词提取的准确率与任务文本的长度具有相关性,通过式(17)计算任务类别关键词的提取准确率Tra,如图4所示。 (17) 其中,CHd表示其有标记的关键词的字符数;fqb表示其有标记的关键词在文本中出现的频数;CH表示提取出的所有关键词的字符数;fq表示其提取出的关键词在文本中出现的频数。 Figure 4 Extraction accuracy of task category keywords 图4 任务类别关键词提取准确率 从图4可以看出,TRFEA算法的任务类别关键词提取准确率明显高于IKAnalyzer算法和传统的LCS算法的,准确率在85%以上,且随着任务字符数的增多呈上升趋势。这是因为TRFEA算法采用了自适应聚类方法,该方法用隶属度确定聚类中心,对任务需求进行聚类预处理,该方法提取出的词或词组不会由于截取而失去其原本的含义,并且能够自适应调整聚类中心,不断优化任务类别关键词与任务的契合性。又因为TRFEA算法用LDA模型将文本信息转化成易于建模的数字信息,所以其与文本描述的任务需求类别更为贴近,模型会随着信息的增多更加完善,使TRFEA算法提取关键词的准确率更高。IKAnalyzer算法虽然分词较为准确,但是由于并不具有关键词提取的功能,仅通过给定字符分词,缺乏自主性和能动性,使得提取准确率较低。综上,TRFEA算法的任务类别关键词提取准确率较高。 6.2.2 任务类别关键词提取时间 任务类别关键词提取时间会随着测试文本长度的增加而增加,本文选取了100个任务文本来测试算法的执行时间,并求取平均值,结果如图5所示。 Figure 5 Relationship of execution time and the number of task characters图5 执行时间与任务字符数的关系 从图5可以看出,TRFEA算法提取任务类别所需时间少于传统的LCS算法的,略多于IKAnalyzer算法的。因为TRFEA算法在进行词或词组提取时需对文本进行聚类提取,而传统的LCS算法对提取出的公共子字符串的长度没有限制,该算法的空间复杂度会随着文本分句长度的增长呈平方倍增长。TRFEA算法将文本信息转化成数字信息进而识别关键词,降低了空间复杂度,因此效率高于传统的LCS算法。IKAnalyzer算法需要扫描文本寻找指定的字符进行分词,因此耗时与TRFEA算法相近。但是,TRFEA算法使用的聚类方法适合处理批量任务,随着任务数量的增加,总的任务需求提取时间少于IKAnalyzer算法和传统的LCS算法的,如图6所示,此处选用的任务文本长度在[200,400]。 Figure 6 Relationship of execution time and the number of tasks图6 执行时间与任务数量的关系 综上分析,本文的TRFEA算法适用于任务需求的提取,准确率高于IKAnalyzer算法和传统的LCS算法的,处理多个任务的效率也优于两者。 6.2.3 任务分发效率 在相同时间内对TRIM模型、LR模型和本文TREAULCM模型进行任务分发率(Tdr)对比,结果如图7所示。通过式(18)计算Tdr: (18) 其中,Tdrp表示单位时间内成功分发的任务个数;Tdrs表示单位时间内待分发任务的总数。假设每小时待分发的任务数为500个,任务分发率越高,模型效率越高。 从图7可以看出,在相同时间内TREAULCM的任务分发率明显大于LR模型的,略大于TRIM模型的。这是由于随着任务数量的增加,多线性神经网络训练模型不断最小化损失函数,并更新网络中各个参数使任务分配模型不断完善。因此,TREAULCM的任务分发率更高。 Figure 7 Comparison of task distribution rate图7 任务分发率对比 6.2.4 感知任务与用户的匹配度 为了验证文本模型对任务与用户匹配的准确性,本文选择了基于空间权值向量的余弦度量法计算任务-用户匹配度。将任务的类别关键词和用户标签抽象为词语向量,余弦度量法通过计算两者的夹角余弦值得到任务-用户匹配度。具体过程如下: 假设Wd={wd1,wd2,…,wdε}是任务taski的描述Ti和用户userj的类型标签YLabj的所有词集合。taski的类别关键词Labi在Wd中的出现次数为c1i(1≤i≤ε);用户userj的类型标签在Wd中的出现次数为c2i(1≤i≤ε),分别可以表示为向量Mi=(c11,c12,…,c1ε)和Nj=(c21,c22,…,c2ε)。任务-用户匹配度计算如下所示: (19) 表2为根据式(19)计算TRIM模型、LR模型和TREAULCM对MSRC-v2数据集上不同类别的平均任务-用户匹配度。从表2可以看出,TREAULCM模型对不同类别任务的识别度更高,这表明TREAULCM模型具有准确性高的优点。 任务-用户匹配度越大,表明用户完成该类别任务的优势越大。图8表明随着任务数量的增加,TREAULCM的平均任务-用户匹配度略高于TRIM模型的,明显高于LR模型的。这是因为无论采用余弦相似度计算方法的用户选择激励模型TRIM还是基于逻辑回归(LR)方法的任务分配模型,在用户选择上依赖固定的设置,缺乏灵活性;而本文的用户标签分类方法不断调整分类器的最优参数,随着任务数量和迭代次数的增加,用户标签不断更新,使任务与用户的匹配有更高的准确性。因此,本文模型在用户选择方面有较大的优势。 Figure 8 Relationship of number of tasks and average task-user matching图8 任务数量与平均任务-用户匹配度的关系 本文针对群智感知中的任务分配问题,提出了一种面向任务需求的任务分配模型。由于任务需求具有多元性,本文首先通过TRFEA算法提取感知任务的类别关键词;然后通过用户标签分类方法得到用户类型标签,根据任务类别、空间位置信息和用户参与度选择满足任务需求的用户分发任务。仿真结果表明,与其他模型相比,本文提出的模型能以较少的时间开销相对准确地选择合适的用户执行任务,能够批量处理用户数据,适合大宗任务分发。然而现实中任务平台和用户任务交互过程复杂且受到的随机干扰因素众多,可能会影响用户类型标签的预测。本文模型对随机因素的考虑还不够全面,针对这个问题进行改进是下一步研究的重点。 Table 2 Average task-user matching degree of different task types in three models表2 3种模型对不同任务类别的平均任务-用户匹配度6 仿真分析
6.1 仿真环境
6.2 实验分析

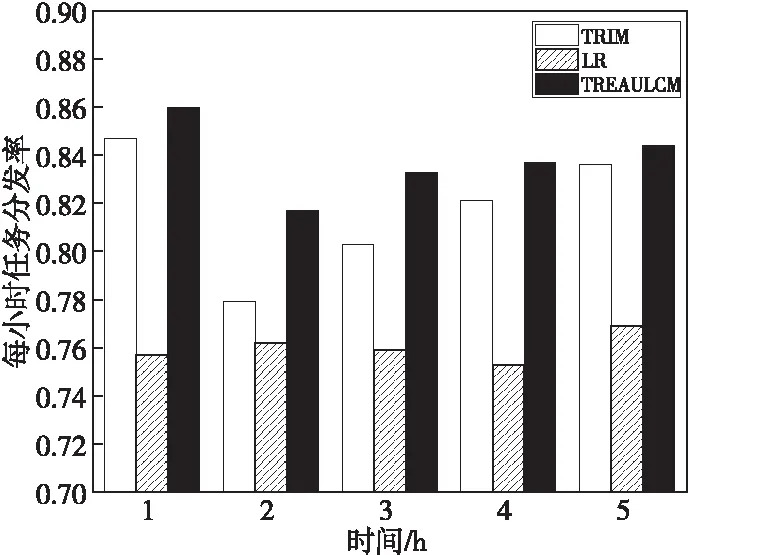
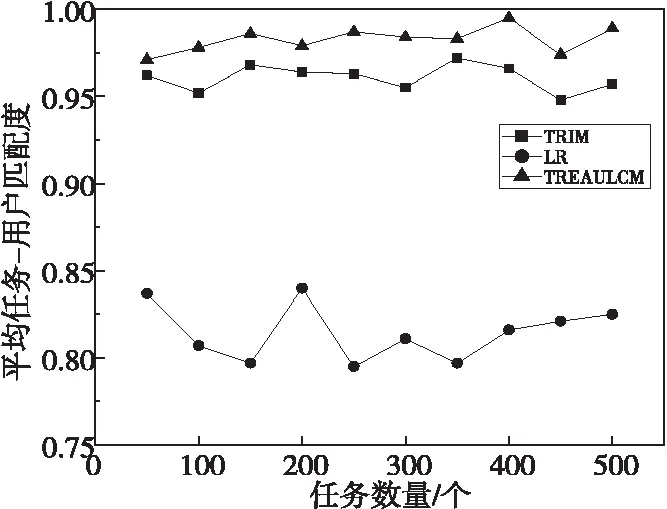
7 结束语

