基于同义词数据增强的汉越神经机器翻译方法*
2021-09-24尤丛丛高盛祥余正涛毛存礼潘润海
尤丛丛,高盛祥,余正涛,毛存礼,潘润海
(1.昆明理工大学信息工程与自动化学院,云南 昆明 650500;2.昆明理工大学云南省人工智能重点实验室,云南 昆明 650500)
1 引言
由于缺乏大型平行语料库训练神经机器翻译系统,导致低资源语言的机器翻译非常困难[1,2]。在计算机视觉领域,数据增强被广泛应用于增强模型的鲁棒性[3,4]。尽管数据增强已成为图像处理训练深层网络的标准技术,但它在机器翻译领域并不常见[5,6]。目前在机器翻译领域,主要的数据增强方法有2类,一类是词汇替换,一类是回译[7]。
词汇替换方法主要利用一定规模的双语平行语料,通过源语言和目标语言中的词进行替换获得扩展平行语料,是当前较为流行的增强方法。Fadaee等人[8]利用语言模型在目标语言端的句子中找到可以被低频词替换的高频词的位置并进行词汇替换,然后利用双语词典完成源语言端对应的词汇替换。通过这种简单的词汇替换,提高了训练语料中低频词的出现频次,从而增强神经机器翻译模型对低频词的翻译能力。作者在英法数据集上获得的实验结果的BLEU值比基准线高2.9,比回译高3.2。蔡子龙等人[9]提出了一个简单有效的增强方法。该方法首先利用源语言端句子中最相似的2个词进行相互替换形成新的句子,然后通过词对齐信息找到目标端对应的词汇并进行相互替换,进而形成新的平行句对。作者在藏汉语种上进行了实验,获得的BLEU值比基准线高4。
回译方法利用翻译引擎翻译句子并进行筛选获得新的平行语料,其广泛应用于提升神经机器翻译的性能。Yang等人[10]提出门增强型神经机器翻译模型。该模型通过将回译合成的平行语料数据和真正的平行语料数据分发到不同的通道,使模型能够根据输入序列的类型执行不同的转换。实验结果表明,该模型在汉英和英法数据集上的BLEU值比基准线分别提高了1.47和2.5。Zhang等人[11]提出基于自动编码器和回译的对抗学习方法。该方法通过对目标端词嵌入与原始的跨语言词映射进行回译,以学习最终的跨语言词映射。作者在3种语言对上的实验结果验证了该方法的有效性。
由于汉语-越南语属于低资源语言对,双语词典难以获得,但跨语言词替换方法需要一定规模的词典资源,因此难以实现,而汉语和越南语有大量的单语语料,通过单语语言训练获得单语环境下的词向量及相关词汇非常容易。因此,本文提出一种基于低频词的同义词替换的双语平行语料数据增强方法。该方法通过探索单语环境构建词向量,进而寻找低频词的同义词,再通过同义词替换获得扩展的平行语料。
2 基于同义词的数据增强方法
本文方法利用小规模的平行语料,通过单语词向量寻找一端语言低频词的同义词;然后对低频词进行同义词替换,再利用语言模型对替换后的句子进行筛选[12];最后将筛选后的句子与另一端语言中的句子进行匹配,从而获得扩展的平行语料。本文方法的实现主要分为以下几个方面:
(1)构建低频词词表VR(R表示低频词汇)。本文在训练语料源语言端范围内构建词汇表V,再将V中出现频率为N(1≤N<5)的词汇作为低频词加入到低频词列表中,从而构建低频词词表VR。单词vi为低频词的确定方法,如式(1)所示:
(1)
其中,1表示vi为低频词,0表示vi不是低频词,N表示vi(vi∈V)的词频,vi∈V为V中第i个词汇,0≤i≤30000。
(2)寻找同义词。由于在单语语义空间内,可以通过计算词汇间的距离来判断2个词汇的相似度。因此,本文利用Wikipedia 中文文本训练BERT(Birdirectional Encoder Representations for Transformers)模型[13]获得汉语端词向量,然后通过计算表征词汇的向量之间的余弦值判断2个词汇之间的相似度,进而寻找汉语端的低频词的同义词,以构建低频词的同义词列表。假设词汇A与词汇B的向量分别表征为a={wa1,wa2…,wan}与b={wb1,wb2…,wbn},词汇间语义相似度计算如式(2)所示:
(2)


Figure 1 Example of synonym replacement 图1 同义词替换示例

P(A1A2…An)=P(A1)P(A2|A1)…
P(An|A1A2…An-1)
(3)
其中,P(A1A2…An-1)>0,P(A1)表示第1个词A1出现的概率,P(A2|A1)是已知第1个词Ai的前提下,第2个词A2出现的概率,以此类推,词An出现的概率取决于它前面所有的词。
(5)目标句选择。对于平行句对(S,T),由于本文对源语言端S进行的是同义词替换操作,所以源句S与增强句S′为同义句。很大概率上,(S′,T)也是平行句对。因此,本文对目标语言端不进行变动。将(S′,T)句对直接加入到训练集中参与模型训练。如图2所示为目标句匹配示意图。
Figure 2 Target sentence matching diagram
图2 目标句匹配示意图

(6)采样。本文对增强后的语料库进行多次循环,以确保每个低频词的词频最多被增强至5。
3 实验与结果分析
3.1 实验数据设置
本文收集20万个汉越平行句对作为数据增强前的训练数据。验证集与测试集分别由2 000个汉越平行句对组成。实验数据如表1所示。
3.2 实验设置
本文设置机器翻译实验来比较同义词数据增强前后的结果,以检验数据增强的效果。本文使用
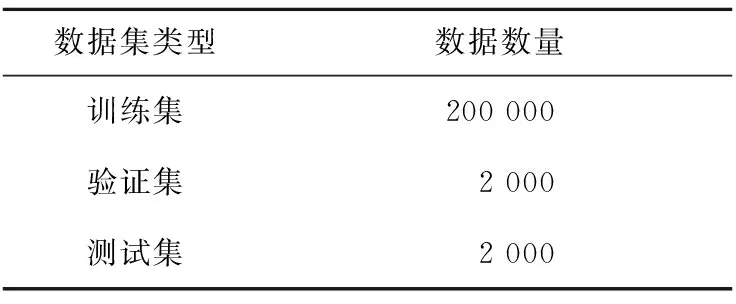
Table 1 Experimental data表1 实验数据
transformer[15]作为神经机器翻译模型。模型的隐藏层大小为512维,批次大小为64,训练轮次为20。在所有实验中,神经机器翻译模型词汇量被限制在汉越2种语言中最常见的30 000个单词中。注意,数据增强不会将新词汇引入词汇表。本文使用5 GB大小的来自Wikipedia的中文文本训练kenLM语言模型。KenLM语言模型属于n-gram语言模型,本文将n设置为3。
3.3 结果及分析
为了验证所提方法的有效性,本文设计了3组实验,通过BLEU值进行评价。
实验1为使得本文增强方法效果达到最佳,以对源语言端进行同义词替换,匹配目标语言端为例进行实验参数选择的对比,以评估采用不同方法构建低频词的同义词列表,以及低频词的同义词个数K对神经机器翻译模型的影响。采用方法分别为:(1)使用Synonyms工具包[16]构建源语言端低频词的同义词列表。(2)使用中文BERT模型生成源语言端词汇的词向量,通过计算和比较词表V与低频词词表VR中词汇间的余弦相似度,由高到低构建源语言端低频词的同义词列表[17]。实验将低频词的同义词个数K设置为1~5,将每个低频词词频通过本文方法增加至5。注意,低频词的同义词个数的不同并不会对语料库的大小产生不同的影响,增强后的汉越平行句对均为310 000。实验结果如图3所示。
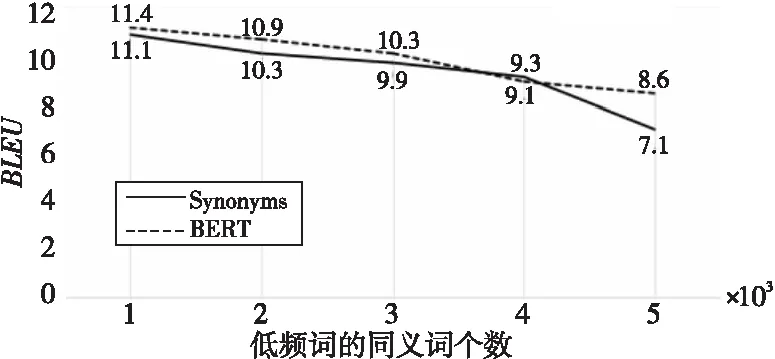
Figure 3 Comparison of Chinese-Vietnamese translation performance with different parameters图3 不同参数汉语-越南语的翻译性能比较
图3中,实线为采用Synonyms构建源语言端低频词的同义词列表;虚线为采用BERT构建源语言端低频词的同义词列表;横坐标为源语言端低频词的同义词个数;纵坐标为翻译模型对应的BLEU值。
图3显示,采用BERT构建源语言端低频词的同义词列表的模型比采用Synonyms构建获得了较高的BLEU值。这是因为Synonyms采用的基本技术是word2vect[18]。BERT相比于word2vect考虑了上下文信息。所以,采用BERT构建源语言端低频词的同义词列表,在进行低频词替换后更容易产生平行度较高的汉越句对。因此,本文方法采用BERT构建源语言端低频词的同义词列表。
图3中虚线显示,当源语言端低频词的同义词个数K=1时,翻译模型性能达到最高值,取得的BLEU值为11.4。随着低频词的同义词个数的增加,翻译模型的BLEU值随之下降,当低频词的同义词个数K=5时,取得了最低BLEU值8.6。这是因为本文方法在构建源语言端低频词的同义词列表时是按照词汇间的余弦相似度由高到低进行构建,所以位置越偏后的同义词与其低频词的相似度越低,在进行同义词替换后生成的增强句S′与源句S的句子相似度越低,经过语言模型筛选,目标句匹配后生成句对(S′,T)的平行度越低。由于翻译模型训练语料噪声增加,BLEU值随之降低。因此,本文方法取低频词的同义词个数K=1。
实验2为使本文模型效果达到最佳,本文在汉语到越南语以及越南语到汉语的不同翻译方向上,分别对源语言端进行词替换,对目标语言端进行词替换,以及对2个语言端一起进行词替换进行相关实验,结果如表2所示。在进行越南语端词汇替换时,使用Grave等人[19]在Common Crawl和Wikipedia上训练的fasttext 模型获得越南语端的词向量,以进行低频词的同义词列表构建,取低频词的同义词个数K=1,将越南语低频词词频在原语料基础上增加至5,词汇替换细节请参照第2节。
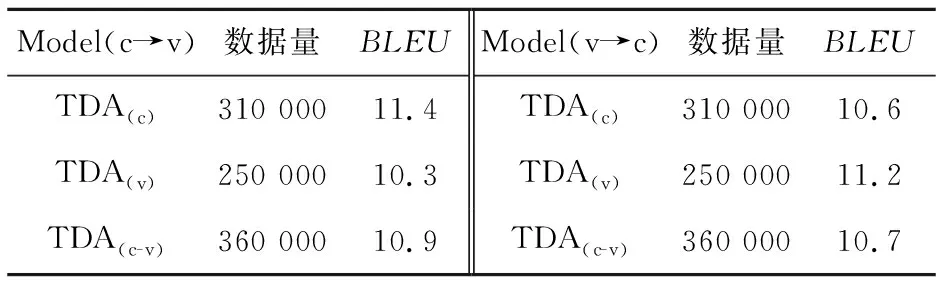
Table 2 Effect of word substitution in different languages on translation performance表2 不同语言端进行词替换对翻译性能的影响
表2中,Model(c→v)表示汉语为源语言端,越南语为目标语言端;Model(v→c)表示越南语为源语言端,汉语为目标语言端;TDA(c)表示对汉语端进行词汇替换;TDA(v)表示对越南语端进行词汇替换;TDA(c-v)表示同时使用TDA(c)和TDA(v)2种方法。
表2数据显示,在将低频词词频增加至5的前提下,TDA(c)和TDA(v)在原语料基础上分别增加了110 000和50 000。这是因为在原语料库中汉语端词表规模是越南语端词表规模的2倍。因此TDA(c-v)在原语料基础上增加了160 000。分析表2数据可得:Model(c→v)下的TDA(c)比Model(v→c)下的TDA(c)的BLEU值高0.8;Model(c→v)下的TDA(v)比Model(v→c)下的TDA(v)BLEU值低0.9。这是因为翻译的质量取决于译出语言的水平而不是源语言的水平。目标语言必须是真句子,才能使翻译结果更加流畅和准确。因此,Model(c→v)下的TDA(c-v)中通过TDA(v)所得到的50 000语料在一定程度上可以理解为噪声语料,所以尽管Model(c→v)下的TDA(c-v)语料规模大于Model(c→v)下的TDA(c)的,前者却比后者的BLEU值低0.5。因此,本文方法采用Model(c→v)下的TDA(c)作为增强方法。
实验3为证明本文方法的最优性,将本文方法与基准线和回译进行比较,基准线模型采用的数据为表1的实验数据。回译方法和本文方法均在表1数据的基础上将数据增加到310 000,然后使用这3组数据对同一transformer模型进行训练,并比较翻译的性能(BLEU值)。众所周知,训练语料的大小直接影响翻译模型的质量,为了在同一水平线上将本文方法与回译方法进行比较,本文将回译增强后的语料大小设置为310 000。由于汉语-越南语属于低资源语言对,若使用个人训练的翻译模型进行回译,显然会降低增强后语料的质量。基于此原因,本文借助谷歌翻译进行回译。为了不在数据增强后引入新的词汇,本文基于训练语料进行回译。首先借助谷歌翻译将训练语料从目标端译为源语言端,构建汉越平行语料库,然后从中随机抽取110 000的汉越平行句对加入训练语料参与模型训练。实验结果如表3所示。

Table 3 Comparison of Chinese-Vietnamese translation performance with different methods表3 不同方法汉语-越南语的翻译性能比较
表3数据显示,本文提出的方法和回译方法有效地改善了翻译质量,相比基准线的BLEU值分别提高了1.8和0.7。本文方法获得最佳BLEU值的原因在于:TDA(c)方法可以帮助汉越神经机器翻译模型对源语言端低频词进行更好的识别,从而提高翻译质量。
上述3组对比实验表明,本文方法采用BERT构建源语言端低频词的同义词列表,取低频词的同义词个数K=1时,本文方法效果达到最优,说明该方法在提高汉越神经机器翻译性能上是可行的。
4 结束语
本文提出了一种有效的用于改善汉越神经机器翻译性能的数据增强方法。该方法利用单语词向量寻找低频词的同义词,然后通过同义词替换获得扩展的汉越平行语料。汉越神经机器翻译的对比实验验证了本文方法的有效性。进一步研究将着眼于对词汇替换后的语料进行质量评估。
