基于ENet的轻量级语义分割算法研究*
2021-09-24徐世杰吴思凡
徐世杰,杜 煜,鹿 鑫,吴思凡
(北京联合大学智慧城市学院,北京 100101)
1 引言
语义分割算法广泛应用于无人驾驶感知、医学图像识别和视频特效等领域,具有重要的研究价值。目前语义分割算法的研究重点在于降低算法参数量级,提升算法实时性[1]。Paszke 等人[2]提出的ENet(Efficient Net)算法是经典的轻量级语义分割算法,具有推理速度快、参数量少和精度较高的特点。但是,随着相关研究的深入,ENet简单的线性编码-解码结构无法满足更高的应用要求。ENet使用较为对称的编码-解码结构,采用传统的逐级下采样方式缓慢减小特征图尺度。然而浅层卷积结果虽具有丰富空间信息,但特征感受野较小、经过的非线性结构少,不能获得有效的语义信息。并且,空间信息传递损失会随着网络层数的加深而增加。Yu等人[3]认为浅层卷积进行了较多大尺寸矩阵运算,减少浅层卷积数量能有效降低计算量。ENet采用逐级上采样的解码方式恢复特征尺度,造成解码器过于庞大,也增加了大尺寸矩阵运算。此外,ENet在bottleneck2.0~3.0中穿插了大量空洞卷积[4]以提升算法感受野[5,6,7],过多的空洞卷积不仅增加了内存占用,其叠加结构还造成了网格效应[8],而文献[9]的实验表明感受野过大会造成过拟合现象。
针对以上问题,本文提出了改进的ENet算法 C-ENet+AM+RAM,首先对ENet编解码部分进行剪裁,以加快特征图采样过程并降低空洞卷积的使用率,然后引入通道注意力机制[10],并受其启发设计了空间注意力机制,将2种注意力机制结合设计了注意力模块AM(Attention Module),将浅层的空间特征与解码器的语义特征融合,最后利用金字塔结构[11]的扩张率叠加空洞卷积,设计感受野聚合模块RAM(Receptive field Aggregation Module)改善算法感受野。改进后的算法参数量降低了22%,在公开数据集Cityscapes[12]和BDD100K[13]上的实验结果超越了原有算法,推理速度提升了23%和17%,分割结果的平均交并比在2个数据集上分别提升了0.9%和0.5%。
2 ENet算法优化
2.1 结构剪裁
ENet算法的基本卷积结构为bottleneck结构,本文以此为最小裁剪单元。若输入数据尺寸为P×Q×3,有C个类别,则其原始结构与裁剪部分如表1所示,其中加粗部分为裁剪部分。网络结构名称为ENet的各个卷积结构,操作类型为此结构的主要卷积类型(空为普通卷积),输出尺寸是当前卷积结构的输出尺寸。

Table 1 ENet structure cutting表1 ENet结构剪裁
2.2 模块设计
本文不再依赖解码器提取浅层的空间信息,而是将空间信息直接传至解码器,通过设计的空间注意力模块SAM(Spatial Attention Module)与通道注意力模块CAM(Channel Attention Module)融合浅层的空间信息与深层的语义信息,降低空间信息的传递损失;通过对感受野模块的设计,改善算法的感受野,消除网格效应。

Figure 1 Structure overview of improved ENet图1 改进的ENet结构总览
改进的ENet算法的模块结构图如图1所示。其中,⊕为通道相加以形成残差结构;⊗为相乘加权以实现注意力机制;M(Mean)为通道求平均操作。首先,以bottleneck1.2与bottleneck4.0的输出作为输入,2个输入分别包含了浅层的空间信息与深层的语义信息,通过将输入信息进行通道串联聚合2种信息,将聚合信息嵌入其中的感受野聚合模块,提升特征图的感受野并进行初步融合;然后,再利用注意力机制对信息进行通道维与空间维加权,进一步融合聚合信息;最后,对特征图进行2倍上采样恢复至输入图像尺寸并进行像素分类。
2.2.1 感受野聚合模块
ENet算法在bottleneck2.1~3.7部分循环了2次扩张率为2,4,8,16的空洞卷积。但是,根据混合空洞卷积理论HDC(Hybrid Dilated Convolution),这种扩张率的组合会造成网格效应。
HDC提出了连续串联空洞卷积的3个设计原则:
(1)多层空洞卷积的扩张率不能有大于1的公约数。
(2)连续的空洞卷积的扩张率应设计成锯齿状结构。
(3)每层空洞卷积的扩张率应满足式(1):
Mi=max[Mi+1-2di,Mi+1-2(Mi+1-di),di]
(1)
其中,Mi是第i层的最大扩张率(默认Mi=di,di是第i层的扩张率)。通过调整卷积的扩张率满足上述3个设计原则以避免网格效应。在ENet算法中,每层的扩张率设计如表1中的操作类型所示,除去dilatedn表示扩张率为n的卷积操作外,其余卷积结构的扩张率均为1。
在bottleneck结构中,1×1卷积不影响感受野,而尺度为5的非对称卷积对感受野的影响等同于5×5卷积。因此,bottleneck3.2可看做扩张率为1的普通卷积,bottleneck3.3可看作扩张率为4的空洞卷积,不满足HDC第3个设计原则,会造成网格效应,并且后续结构会加重这种效应。
本文采用并联结构设计空洞卷积,避免了HDC严格的设计要求。将扩张率D为1,2,4,8的空洞卷积进行通道并联(取消了扩张率为16的操作),这种扩张率递增的并联结构能够避免网格效应的产生,缓解感受野过大造成的过拟合现象和减少大扩张率造成的内存占用问题。感受野聚合模块细节如图2所示,若设bottleneck1.2与bottleneck4.0的输出为x1,x2,则RAM的输入f可表示为式(2)所示:
f=conv(cat(x1,x2))
(2)
其中,cat是通道串联操作,conv是卷积操作。则RAM的输出FRAM可表示为式(3)所示:
FRAM=conv[cat(D1,D2,D4,D8)]
(3)
其中,Dn表示对f进行扩张率为n的空洞卷积后的输出。

Figure 2 Receptive field aggregation module图2 感受野聚合模块
扩张率为1的卷积保证了特征点近距离感受野的完整性,扩张率为2,4,8的空洞卷积并联用于提升特征点感受野,并联方式不会产生感受野的重叠,并且叠加后的空洞卷积核的权重分布为放射状,即特征点更加重视近距离信息,更符合信息的处理原则。
一个特征点分别经过bottleneck3.0~3.7与感受野聚合模块后,对输入信息的感受野可视化如图3所示。其中图3a为bottleneck的感受野可视化图,可以看出特征点的感受野有严重的网格效应,特征点忽视了近距离信息,却包含了丰富的远距离信息。图3b为感受野聚合模块的感受野可视化图,没有网格效应,包含了更丰富的近处信息,感受野强度由近及远变化均匀,可减少信息传递损失和信息位置偏差。

Figure 3 Receptive field visualization图3 感受野可视化
并联结构的感受野增大速率比串联结构的感受野增大速率慢,因此由图2可以看出,感受野聚合模块最终输出的感受野不能达到原结构输出的感受野的大小,但本文认为远距离的信息并不一定对特征点的正确分类起增益效果,且大于图像尺寸的感受野不合理,即感受野并不是越大越好,分析如下:
卷积神经网络每层感受野大小可使用式(4)计算:
(4)
其中,lk是第k层特征的感受野,fk和dk是第k层卷积核的尺寸与扩张率,si是第i层的卷积步长。由于1×1卷积与上采样不影响感受野,则原算法与改进后算法的感受野变化趋势如图4所示。图4的横坐标为使感受野增加的有效卷积层数,纵坐标为特征点对应输入图像的感受野大小,链状曲线为ENet算法感受野增长曲线,实线为剪裁后算法的感受野增长曲线,点状曲线显式了剪裁后算法增加本文设计模块后的感受野变化。

Figure 4 Receptive field growth curve图4 感受野增长曲线
ENet算法最终感受野大小为1 265,剪裁后的最终感受野大小为625,增添所设计模块后的感受野大小增长到801。感受野大于输入图像尺寸时,会造成过拟合,导致准确率降低,对于常见的图像尺寸,如512×1024, 720×1280或者1080×1920,改进后算法的感受野更加合适。
2.2.2 注意力模块
注意力模块包含通道注意力和空间注意力2个部分,本文分别对输入数据进行通道维和空间维的加权,将传入的空间信息与语义信息进行进一步融合。本文引入通道压缩理论[10]设计了通道注意力机制。
通道注意力的实现如图5所示,输入为感受野聚合模块的输出FRAM。对输入数据每个通道进行全局平均池化GAP(Global Average Pooling)得到特征图每个通道的平均值,再经过2层全连接FC(Fully Connected)层得到通道维权重,对特征通道维进行加权。

Figure 5 Channel attention mechanism图5 通道注意力机制
通道注意力模块的输出FCAM可表示为式(5)所示:
FCAM=FC2(FC1(GAP(FRAM)))
(5)
其中,FC为全连接操作,第1个全连接操作(FC1)压缩通道降低计算量,激活函数为RuLU,第2个全连接操作(FC2)恢复通道数生成对应通道数的权重,激活函数为Sigmod。由于通道注意力机制处于解码部分,特征图的通道数仅有128,将第1次全连接操作FC1的通道压缩率设置为2(原最佳压缩率为16),取得了计算量与精度上的较好平衡。
其中全局平均池化操作如式(6)所示:
(6)
其中,FRAMx为输入特征的第x个通道的特征图,FRAMx(i,j)为输入特征第x通道在位置(i,j)处的值,通过当前通道特征权重平均值衡量其在所有通道中的重要性,若输入特征维度为H×W×N,则得到N个特征平均值,之后通过2次全连接层得到N个通道维权重,再对输入特征的每个通道进行加权突出重要特征通道,实现通道维的注意力机制。
空间注意力的实现如图6所示,输入为通道注意力模块的输出FCAM。受通道注意力机制的启发,本文通过对每个空间位置的所有通道求平均获取对应空间位置的特征强度,利用空间的特征强度设计了空间注意力机制。首先,对输入特征矩阵的每个位置的所有通道求平均,获得包含每个空间位置均值的单通道矩阵,再通过2次3×3卷积层得到空间权重矩阵,然后,将空间权重矩阵在通道维进行复制使得特征维度与输入特征维度对齐,最后利用权重矩阵对输入特征进行加权。

Figure 6 Spatial attention mechanism图6 空间注意力机制
则空间注意力模块的输出FSAM可表示为式(7)所示:
FSAM=conv(conv(M(FCAM(i,j))))
(7)
(8)
其中,FCAMk(i,j)为输入特征第k个通道在位置(i,j)处的值,通过对当前位置所有通道求平均获得此位置空间均值,之后通过2次3×3卷积获得对应空间位置权重,激活函数均为ReLU。若输入特征维度为H×W×N,则得到维度为H×W×1的空间权重图,最后进行通道复制,将其维度扩充到H×W×N,与输入特征进行加权突出重要特征空间位置,实现空间维的注意力机制。
3 实验
在同一软件框架与硬件水平下(Keras深度学习框架;AMD Ryzen 5 3600X处理器;GTX1080ti显卡)和大型公开数据集Cityscapes和BDD100K上进行实验,以验证本文提出的结构剪裁方法和轻量级注意力机制的正确性(所有数据进行2倍缩小,未进行数据增强)。
3.1 参数分析
对ENet、裁剪后的ENet C-ENet和及C-ENet+AM+RAM进行浮点量与参数量统计,结果如表2与表3所示。
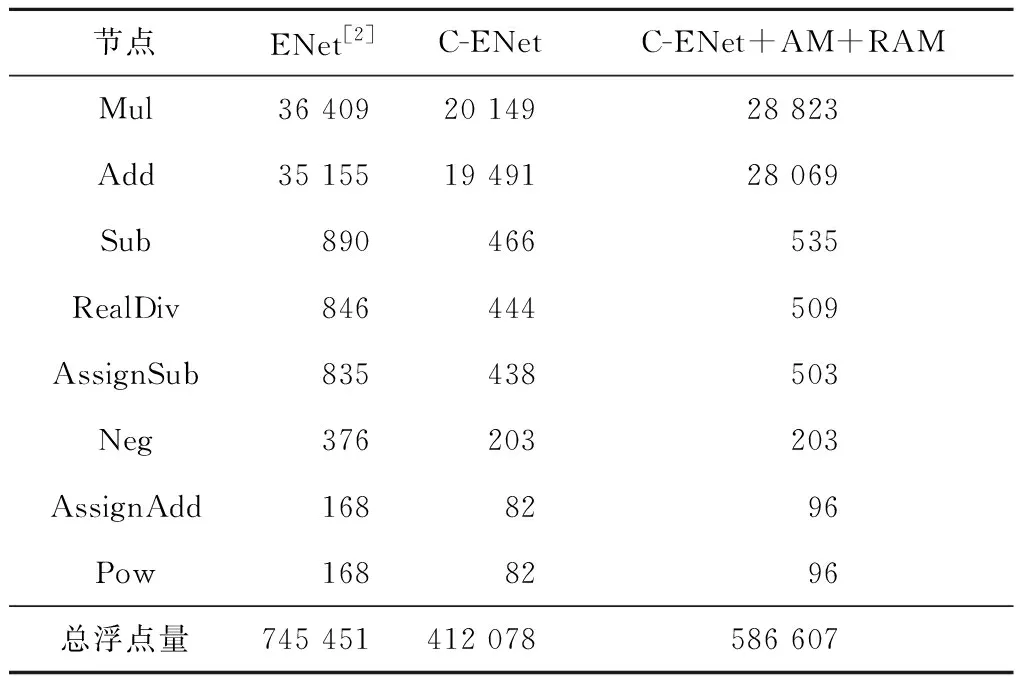
Table 2 Calculation volume statistics表2 计算量统计 Flops

Table 3 Parameter statistics表3 参数统计
从表2中可以看出,浮点量的差距主要产生在Mul节点和Add节点,分别对应卷积计算中的乘法和加法运算。原算法浮点计算量为745 451,参数量为3.7×106B。通过算法剪裁后,计算量与参数量降至412 078与2.1×106B,精简算法并增加本文设计模块后计算量与参数量为586 607与2.9×106B。
改进后的算法计算量降低了21.3%,参数量降低了21.6%。
3.2 消融实验
对算法与各模块在Cityscapes与BDD100K上进行消融实验,使用平均交并比MIoU(Mean Intersection over Union)与每秒分割图像数FPS(Frames Per Second)作为评价指标,结果如表4和表5所示。
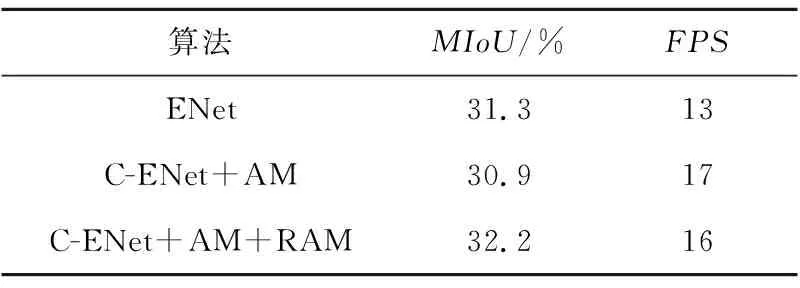
Table 4 Performance of algorithms on Cityscapes表4 算法在Cityscapes上的表现

Table 5 Performance of algorithms on BDD100K表5 算法在BDD100K上的表现
图7a和图7b为本文改进后算法(C-ENet+AM+RAM)与原算法ENet在Cityscapes与BDD100K数据集上部分分割结果可视化,图7中从左至右、从上至下分别为原图、标签、ENet分割结果和本文算法分割结果。

Figure 7 Visualization of partial segmentation results of ours and ENet on Cityscapes and BDD100K datasets图7 本文算法和ENet在Cityscapes 与BDD100K上的部分分割结果可视化
3.3 对比实验
实验还将本文算法(C-ENet+AM+RAM)与当今主流语义分割算法进行了实验对比。具体结果如表6所示(最优结果使用方框黑体标注,次优结果使用黑体标注)。
表6中,FCN8S、UNet和SegNet都是经典的语义分割算法。FCN8S最大进行了8倍下采样,采用跨通道相加的方法增强信息传递性;UNet精度较高,常用于医学图像处理,算法结构为U型结构,对相同尺度的编解码使用加法进行信息融合;SegNet算法的结构类似FCN,不同之处在于编码部分采用了VGG-16结构的前13层,解码部分的上采样操作使用了空间的索引信息(在编码时的pooling操作记录了相应的索引信息)。

Table 6 Result comparisons of various algorithms表6 各算法实验对比结果
在Keras(TensorFlow)深度学习框架和GTX1080ti显卡计算下,各算法在Cityscapes上的性能对比如图8所示。
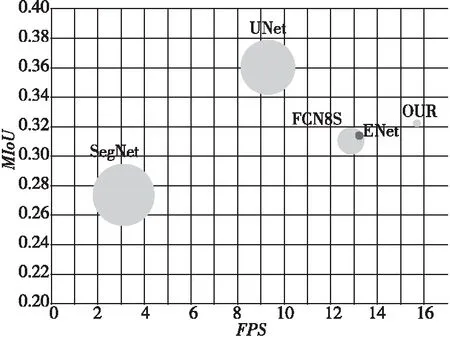
Figure 8 Performance comparison of various algorithms图8 各算法性能对比
图8中,纵坐标为分割精度指标——平均交并比(MIoU),横坐标为每秒钟分割图像的数量(FPS),坐标轴上的实心圆对应各个算法,实心圆的直径大小与算法参数量成正比。可见本文算法在众多算法中,参数量最少,推理速度最快,并且精度达到了第2的高水平(越靠近右上方性能越好)。
4 结束语
本文通过对轻量级语义分割算法ENet进行改进,提出了一种优化基于编码-解码结构的语义分割算法的思路,通过注意力机制与空洞卷积理论,创新性地设计了2种计算复杂度较小的网络模块,提升了算法的精度与推理速度。本文所提出的算法对于需要实时分割的应用场景,如无人驾驶场景有较大价值。
