基于行走特征矢量图的步态识别方法
2021-09-23彭小波黄海娜杨辉跃刘俊宏
彭小波,黄海娜,杨辉跃,刘俊宏,黄 瑛
1)深圳大学机电与控制工程学院,深圳电磁控制重点实验室,广东深圳518060;2)深圳大学生命科学与海洋学院,深圳市海洋生物资源与生态环境科学重点实验室,广东省海洋藻类开发与应用工程重点实验室,广东深圳518071
步态指个体在走行过程中姿态的变化,是最重要的生物特征之一.随着深度学习技术的发展,基于步态的识别技术有了新的突破.利用神经网络进行有效的步态识别成为当前研究的热点[1].但是现有方法的识别准确性受视角、服饰、携带物和背景等多种因素的影响[2].近年来,国内外学者也在不断探究视角、服饰和携带物等协变量对步态识别性能的影响.针对这些影响,基于深度学习的步态识别技术可划分为生成式方法和判别式方法[3].生成式方法通常是将不同条件下的步态特征转化为相同条件下的步态特征以获得更好的匹配.YU等[4-5]实现在相同条件下图像序列的转化,在一定程度上处理了跨视角的问题.随后又提出基于多个堆叠自编码器(stacked progressive auto-encoders, SPAE)的方法,通过堆叠的多层自动编码器对输入的步态能量图使用渐进的方法来生成步态不变特征.TONG等[6]提出跨域传输网络以提高多视角步态识别的准确性.KHAN等[7]提取了步态时空特征以构造步态描述器来训练非线性深度神经网络.BEN等[8]提出了一种用于跨步态识别的通用张量表示框架,提取Gabor特征并将基于Gabor的表示体投影到一个公共子空间进行识别.判别式方法是通过学习判别子空间或矩阵来提高识别能力[3].该方法可以分为2类:一类是将步态轮廓图序列/步态模板输入到特征学习网络进行建模投影;另一类是学习样本间的相似度函数[9].SHIRAGA等[10]提出一个带有两层卷积层的网络结构,使用步态能量图作为输入,与训练对象的相似性作为输出.ZHANG等[11]采用DeepGait进行深度卷积特征的步态识别,并引入了联合贝叶斯模型对视图方差进行建模.THAPER等[12]使用视角分类器和3D卷积神经网络来确定步态,该研究对视角的正确预测有很大的依赖性.LIAO等[13]利用人体关键点的位置信息和时间信息,运用多分类交叉熵损失和二元损失处理服饰和携带物等协变量的问题.WU等[14]通过深度卷积神经网络(deep-convolutional neural network, deep-CNN)直接学习步态能量或步态序列之间的相似度,此方法对视角和步行条件变化具有鲁棒性.CHEN等[15]提出了使用CNN学习样本间的相似度,将得到的相似向量经过全连接层进行步态识别.
为提高多视角下的服饰改变和存在携带物等多协变量影响下的步态识别准确率,本研究提出一种基于人体姿态估计算法OpenPose的人体行走特征矢量图(walking feature vector diagram, WFVD)作为步态时空特征的描述,该特征描述既保留了步态时空信息,又避免了冗余信息,有利于步态特征的学习和训练;同时,设计了一种基于残差学习模块和长短时记忆网络的步态时空特征学习与分类网络,并验证了其有效性.
1 基于WFVD的步态识别方法
基于人体WFVD的步态识别方法,能处理多视角下的服饰和携带物改变的情况,处理过程如图1.首先,以行人视频图像序列作为输入,提取每一帧的人体部位关联场(part affinity field,PAF)[16].PAF是提供人体各部位的位置和方向信息的矩阵,它们成对出现:对于每一部位在x方向上有一个PAF,记为x-PAF; 在y方向上有一个PAF,记为y-PAF.将步态周期内连续帧的PAF堆叠成四阶张量组成WFVD.然后,先通过残差学习模块提取WFVD的步态空间特征图并做降维处理,再将得到的空间特征图输入到长短期记忆(long short-term memory, LSTM)网络进行步态时间特征的学习.最后,在网络的末端采用softmax分类器对特征进行识别.
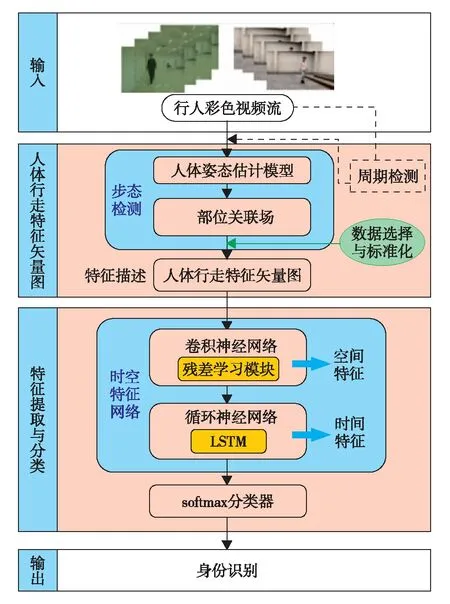
图1 基于WFVD的步态识别方法框架Fig.1 Framework of the gait recognition based on WFVD
1.1 WFVD的生成
WFVD的生成步骤为:① 使用轮廓高宽比方法对视频数据集进行步态周期检测,周期检测仅在模型训练之前的数据预处理阶段才需要,用来估计步态周期的长度;② 利用人体姿态估计系统OpenPose从视频图片序列中提取人体的PAF;③ 选择有效的关节数据并进行标准化;④ 利用周期检测的结果,由PAF装配形成WFVD.
1.1.1 步态周期检测
为减少计算量和冗余信息,考虑到步态周期之间的相似性,只取1个周期内的步态序列进行学习和识别.步态周期Tc从步态轮廓高宽比曲线中提取.图2为序号001的行人步态轮廓高宽比曲线.相邻2个波峰的距离为半个周期,所以,Tc=32-10=22帧.在本研究中,Tc通过对数据集中所有行人周期时间取平均值求得.
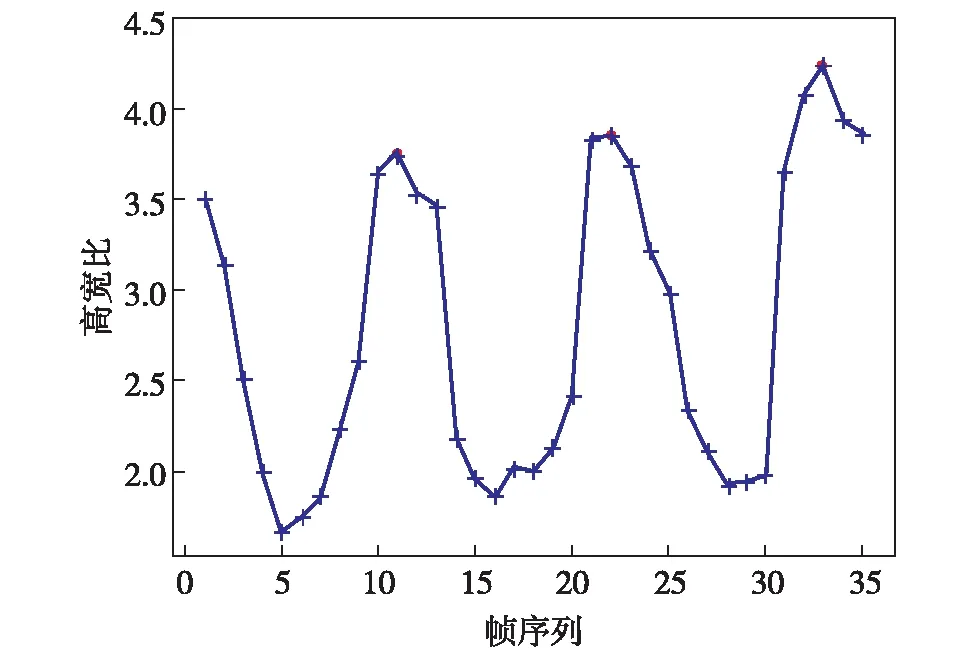
图2 步态周期检测Fig.2 Gait cycle time detection

图3 PAF提取Fig.3 PAF extraction
1.1.2 PAF提取
PAF是一个大小为W×H×C的3维矩阵, 其中,W为宽度;H为高度;C为层数.本研究中,W和H均为46,C为57,见图3.前18层为人体18个关键点的位置,第19层为背景,上述19层构成热图;后38层为PAF,其中,奇数层为x方向的x-PAF, 偶数层为y方向的y-PAF. 这38层构成了大小为46×46×38的PAF矩阵.
1.1.3 数据选择
在步态视频中,由于人们的脸部图像通常不是很清晰,并且头部经常不规则地摇动,这使得头部PAF的提取变得困难且价值不大. 因此,本研究将与头部有关的PAF去除,忽略头部(鼻子、耳朵和眼睛)的步态特征信息,主要考虑四肢和躯干.从原始PAF中去除的14个头部相关PAF,即:18、19、26、27、28、29、20、21、32、33、34、35、36和37.PAF矩阵缩小为46×46×24,如图4.
1.1.4 WFVD的构造
每帧图像的PAF矩阵大小为46×46×24,取沿时间轴的视频序列长度为Tc, 则WFVD的大小为Tc×46×46×24,如图5.
1.2 特征提取与分类
设计时空网络对WFVD进行特征学习以及对行人身份进行预测,该网络结构如图6.
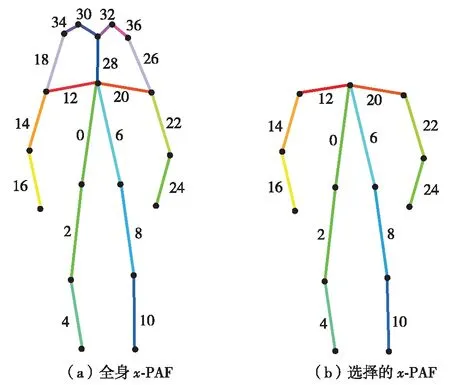
图4 x-PAF的选择Fig.4 Selection of x-PAF

图5 WFVD的构造Fig.5 Construction of the WFVD
2)残差学习模块:在基本残差模块的基础上修改了卷积数,并调整了批量归一化(batch normalization,BN)和线性整流函数(rectified linear unit,ReLU)的位置.在此输入维度和输出维度不一致.在基本的残差学习模组的右支进行一次卷积操作以调整输入的通道尺寸(图7).在3×3卷积层进行了两次降维,则输出的数据形状为(Tc, 12, 12, 512),参数流示意图如图8.

图6 步态时空特征学习与分类网络结构图Fig.6 Spatiotemporal gait feature learning and classification network structure
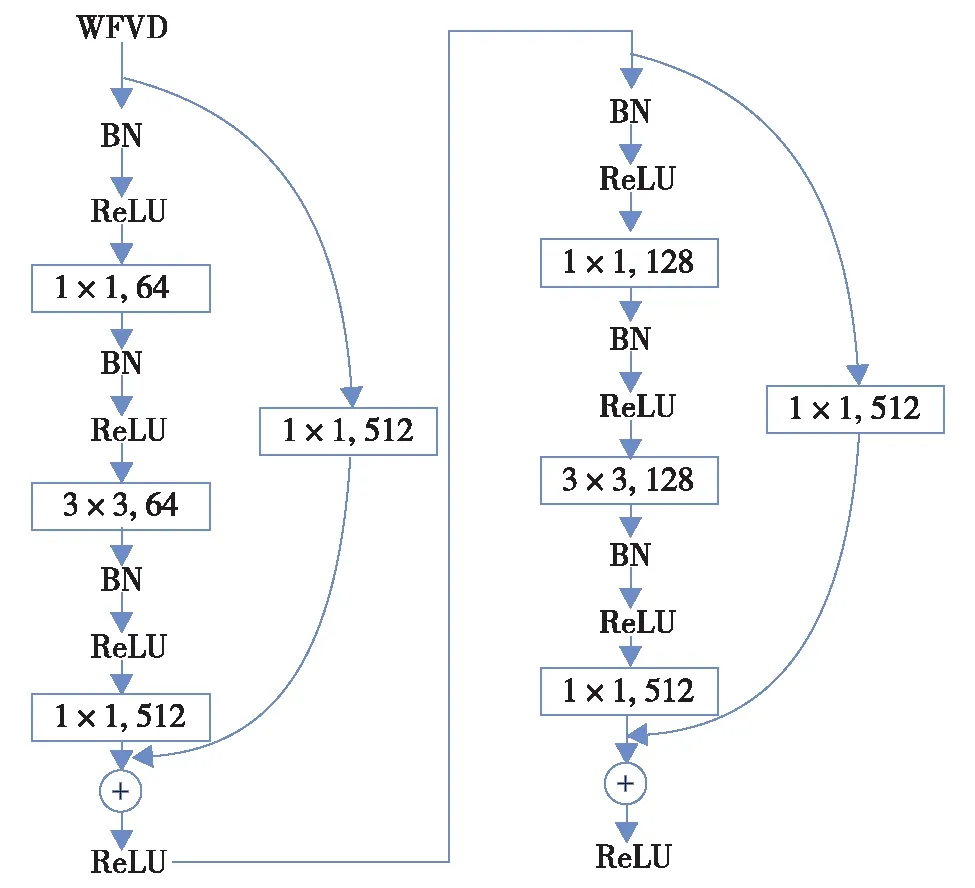
图7 残差学习模块Fig.7 Residual learning module
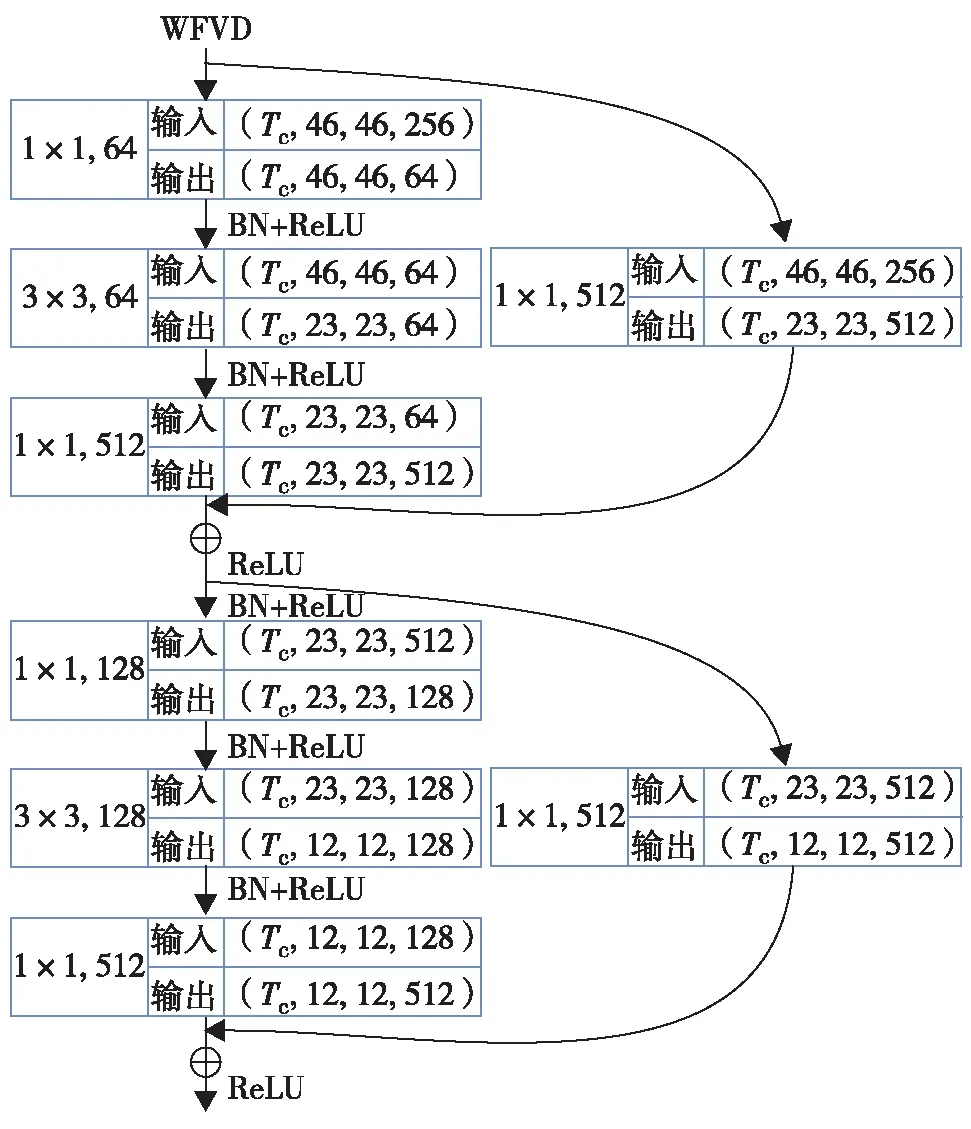
图8 残差学习模块的参数流Fig.8 The parameter flow of the residual learning module
3)LSTM网络:将第1个全连接的输出重塑为单层单向LSTM的输入形式.设LSTM网络的训练集样本数量为n, 隐藏层节点数为512,则其结构为(n,Tc,512), 输出为(n, 512).
4)softmax层:通过softmax层来计算交叉熵损失函数,将第2个全连接层的输出经过softmax回归函数转换为概率输出,模型预测的类别概率输出与真实类别的one-hot形式进行交叉熵损失函数的计算,利用计算的损失值对网络进行修正.网络训练和优化过程采用Adam算法,权值初始化采用xavier_initializer方法,为缓解过拟合问题,采用正规化函数L进行正则化.
(1)
其中,E为未包含正则化项的训练样本误差;ωi为第i个特征的权重系数;m为样本数;λ为可调整的正则化参数.
2 实验方法
2.1 实验数据
本研究采用中国科学院自动化研究所研发的CASIA-B数据集以及本课题组自建数据集(1 080像素)进行步态识别实验验证.
2.1.1 CASIA-B数据集
CASIA-B数据集包含124位行人(男93人,女31人)和3种步态模式:正常行走步态(nm)、穿外套行走步态(cl)和携包行走步态(bg).每种步态包含11个视角,对于每个视角下的每个行人,有6个正常步态视频(nm1—nm6)、2个穿外套步态视频(cl1—cl2)和2个背包行走步态视频(bg1—bg2).视频像素为320×240,速率为25帧/s.
2.1.2 自建数据集
为验证步态识别算法针对室外环境中的识别效果,使用类似CASIA-B的数据采集方法采集3个协变量条件nm、bg和cl的数据.实验共采集20个志愿者不同场景下16个视角3种步行状态的步态序列,每个视角都有20个视频(图9).
2.2 CASIA-B实验设置
CASIA-B实验被设计在0°视角下进行,测试所提出的模型处理服饰和携带物品协变量影响的能力.将第001~124号行人的nm1—nm4的第50~50+Tc帧作为训练集,行人001~124的nm5—nm6、cl1—cl2、bg1—bg2的第50~50+Tc帧作为测试集.其中,nm5—nm6测试集作为同步态状态的测试,cl1—cl2与bg1—bg2则为跨步态状态的测试.训练集和测试集中的视频序列数分别为124×4×11=5 456个和124×2=248个.
2.3 自建数据集实验设置
在自建数据集中设置多视角下的同步态和跨步态状态实验.同步态实验的训练集和测试集的场景相同,包括nm-nm、cl-cl和bg-bg.跨步态实验的训练集和测试集的场景不同,包括nm-cl和nm-bg,实验数据如表1.

表1 基于自建数据集的实验设置
3 结果与分析
3.1 CASIA-B实验结果及分析
CASIA-B的实验结果如表2,算法速度约为10帧/s,平均识别准确率为96.24%,表明所提出的网络可以较好解决服饰和携带物等协变量对步态识别的影响.此外,本实验的平均识别准确率都高于基于牛津大学视觉几何组(visual geometry group, VGG)网络和基于步态能量图像(gait energy image, GEI)+泊松方程+Gabor小波的方法[17-18],表明本研究提出的方法在0°视角具有较强的鲁棒性和有效性.

图9 自建数据集采集Fig.9 Acquisition of the self-built dataset

表2 正确识别准确率对比
为验证Tc是否是合适的视频序列长度,测试了Tc、Tc+5和Tc-5共3个序列长度的平均识别准确率.Tc=25帧是从001~124号行人的视频中提取的步态周期长度.从表3可见,与Tc+5和Tc-5 相比,当视频序列长度等于Tc时,泛化是最好的.
3.2 自建数据集实验结果分析
3.2.1 同步态状态
同步态状态实验的识别准确率结果表4,由表4可见,同步态状态nm-nm、cl-cl和bg-bg的各视角总平均识别准确率分别为99.69%、99.72%和99.69%,说明本研究网络提取的时空特征能很好地反映步态,解决多视角下同步态状态的步态识别问题.因为人体行走特征矢量图是经过归一化的且大小都是固定的25×46×46×24,识别算法时间成本与视频分辨率无关,识别速度约为10帧/s,能满足实时识别的要求.
3.2.2 跨步态状态
为验证网络的泛化能力,利用nm步态数据集训练得到的模型对不同类型的测试集进行识别实验.实验中16个视角的nm-cl和nm-bg实验的识别准确率如表5.
图10为服饰和携带物的识别结果.由图10可见,虽然身体被遮挡,但仍能获得正确的识别.该模型良好的泛化性能还体现在它能处理诸如手提包之类的规则摆动的携带物.
在nm-bg实验中,16个视角的平均识别准确率为65.125%,其在0°和180°视角下的识别准确率最高,都超过80%.在0°和180°视角时,尽管空间特征不明显,但此时可以利用时间特征来弥补,如图11(a).90°和270°时的识别准确率仅次于0°和180°;在90°及270°视角下,人体不仅被自身遮挡的部位较多且也受到携带物的影响,但由于该视角下步态的空间特征最鲜明,因此,该视角下的识别准确率相对较高,如图11(b).在精度相对较低的视角下,人体主要部分被携带物阻挡,从而影响了WFVD的获取.
nm-bg和nm-cl的实验结果表明,由nm步态序列训练的网络具有良好的泛化能力,较好地解决了在多个视角下服饰和携带物体的协变量问题.

表4 同步态状态的平均识别准确率Table 4 Average recognition accuracies in the identical gait states %

表5 跨步态状态的平均识别准确率Table 5 Average recognition accuracies in the crossing gait states %

图10 服饰和携带物的识别结果Fig.10 Recognition results of clothes and carrying objects

图11 180°及90°视角下的识别结果Fig.11 Recognition results at viewing angles of 180° and 90°
结 语
基于深度学习方法,提出基于人体WFVD的步态识别方法,并针对CASIA-B部分数据集和自建数据集进行了实验.由于OpenPose对外形不敏感,在一定程度上能处理遮挡和噪声,因此,本算法能处理多视角下的步态特征.由于本研究提出的时空网络是基于WFVD进行特征学习,当遮挡物规律性的运动导致基于残差学习模块学习“错误”的步态空间特征时,依靠基于LSTN网络学习步态时间特征,可学习出这种有规律的“错误”.研究结果表明,所提方法能有效提升算法的识别准确率和鲁棒性.
目前,本方法仅能完成单人在数据集已有视角下不同服饰、不同携带物等综合环境下的身份识别,未涉及到多人在跨视角、不同步行速度等情况下的识别工作,所采用的网络结构也有待改进.如何在复杂环境下解决多人跟踪与识别、跨视角问题、不同步行速度下的识别问题,以及如何利用更好的网络结构比如双层双向LSTM来提高识别准确率,将是下一步研究的方向.此外,需要采用更多样本数量进一步验证算法的有效性.
