改进免疫网络及其算法在配电网故障定位中的应用
2021-09-23孙飞洋龚涛
孙飞洋,龚涛
(东华大学信息科学与技术学院,上海201620)
0 引言
根据十四五规划和2035远景目标纲要,我国将大力发展新能源产业,提升新能源发电规模,坚持集中式和分布式并举[1],推动新能源革命。配电网自动化技术是提高配电网运行效率的重要手段,而由馈线终端单元(Feeder Terminal Unit,FTU)、数据采集与监视控制系统为基础构成的馈线自动化技术是其主要功能之一。其主要工作方式为,当FTU检测到配电网内的故障电流时,会将故障信息上传,通过有效的故障定位方法找到故障发生点并进行进一步处理[2-3]。
传统配电网故障定位方法在DG接入后不再适用[4-6],目前基于智能算法的配电网故障定位方法得到广泛研究[7-12]。本文针对含DG的复杂配电网提出了一种新的改进免疫算法,并且引入了一种新的分层模型,加快了故障定位速度,提高了定位准确率。
1 配电网故障定位基本原理
免疫算法是一种仿生物学智能算法,以生物的免疫机制为基础,通过抗体以及记忆细胞的变异操作,能够高效地搜寻全局最优解,良好适应配电网故障定位模型。
1.1 状态编码
抗体的编码形式为二进制,其编码的长度就是配电网的区段总数。抗体每位的取值对应着区段的状态,其状态编码只有两种情况,即出现故障时编码为1,正常时编码为0。抗体x的表现形式为(sx1,sx2,…,sxn),其中n为区段总数。
1.2 开关函数
开关函数是将状态编码转变为实际测量信息的重要途径。当配电网某区段发生故障时,FTU检测到故障电流并将信息上传,接收到的故障电流信息并不能直接显示故障区段。利用智能算法对故障电流信息进行故障定位时,需要使用开关函数将预测的故障状态编码转变为对应故障电流信息,再与实际信息对比。
在未接入分布式电源之前,传统的单电源开关函数如下[13]:

其中Ij(s)表示第j个开关的开关函数,si为第j个开关的下游区段i的区段状态,代表逻辑或运算。此开关函数表明,某一个开关的信息编码由其下游每一个区段状态决定。
但式(1)只适用于单电源供电的传统配电网。当DG接入配电网后,网络的整体结构变得复杂,传统的开关函数不能准确表达开关状态,因此需要使用新的开关函数来适应DG的接入。本文采用的开关函数如下[14]:
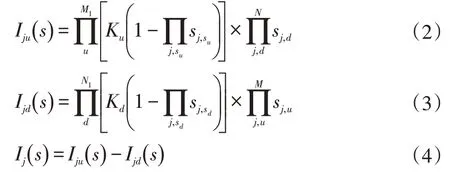
其中,Ij(s)由两个部分构成,是以开关j为中断点分割出来的上游线路开关函数Iju(s),以及下游线路开关函数Ijd(s)。式中,M、N分别表示为上游、下游线路的总区段数;M1、N1分别表示上游、下游电源总数;Ku、Kd分别表示为上游、下游线路的电源接入情况,如果电源接入则为1,反之则为0;sj,su、sj,sd分别表示从开关j到上游线路、下游线路电源中所经过的区段状态;sj,u、sj,d表示上游、下游线路的区段状态;代表逻辑或运算。
1.3 抗体评价
抗体是参与免疫计算的主要成员,对抗体进行评价,其结果将影响整个免疫过程。抗体评价主要分为两个部分,分别是抗体与抗原的亲和度指标和抗体之间的相似度指标。其中,亲和度指标用来表示抗体优良程度。相似度指标用来计算抗体的浓度,然后计算其期望繁殖率进行免疫操作。
1.3.1 抗体与抗原的匹配度
抗体与抗原的匹配度通过设定的适应度评价函数计算,因此评价函数会直接影响故障定位的准确性。在含DG的配电网故障定位过程中,故障诊断是建立在“最小集”理论上的,即在可能的结果中选取故障设备最少的解。评价函数有多种形式,本次实验选取评价函数如下[14-15]:
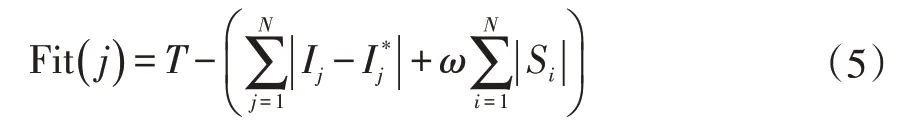
Fit(j)表示第j个抗体的适应度;N为区段节点数目;T为设定的数,其目的是将原本求取最小值的评价函数转化为求取最大值问题,一般取2N;Ij为节点状态信息,即FTU监测到的真实情况;Ij*为预测的期望值,是抗体通过开关函数计算得来的值;Si是第i个区段的故障状态,有故障则取1;ω为设定的系数,主要是为了防止特殊情况的误判,一般设定为0.5。
在求取最小值的适应度函数中,会设定亲和度为抗体适应度的倒数,其大小代表抗体与抗原匹配的好坏。在本次实验中,直接使用适应度代表其亲和度。
1.3.2 抗体间的相似度
免疫操作过程中,应该尽量保证抗体种群的多样性,借此提高算法的准确率和定位速度,避免陷入局部最优。抗体间的相似度Sx1,x2设定为:抗体x1、x2的相同位置上的相同编码数量占总体的比值,如果比值超过设定的阈值则认为两种抗体是相同类型。某类型抗体的抗体浓度用Cv表示,其计算方法如下:

式中,kx1,x2代表抗体x1、x2相同位置相同编码的数量;L代表抗体的长度,即总区段数;e是设定的相似度阈值;Hx1,x2代表两个抗体是否相同;N代表抗体种群大小。
1.3.3 抗体间的期望繁殖率
进行免疫操作时需要进行抗体的选择,其基本选择理念为抑制浓度较高的抗体,促进亲和度高的抗体。因此抗体的期望繁殖度受Pv以上两个因素影响,其计算方法为:

抗体亲浓度小且亲和度高的个体更容易被选择,通常使用轮盘赌法进行选择,每个抗体的被选择概率pv通过下式计算:

2 改进免疫算法原理
本次实验改进了传统免疫算法,通过粒子群算法并行计算,借此更新其记忆库。并且增加了记忆细胞的信息传递能力,使得更优秀的抗体能够将其内信息分享,从而避免陷入局部最优。
2.1 粒子群算法
粒子群算法是由一群粒子在空间内寻优移动,每个粒子通过全局最优、个体最优位置优化自身的运动方向以及速度。由于配电网故障定位的实例条件限制,二进制粒子群算法的速度、位置更新方式如下:
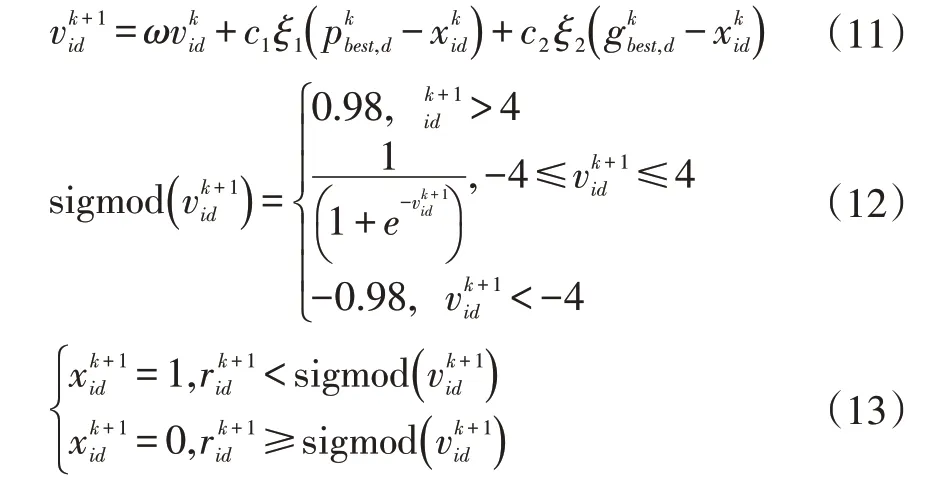
、表示第i个粒子在第k次迭代时第d维上的速度和位置;ω为惯性权重;c1为自身学习参数;c2为种群学习参数;ξ1、ξ2为区间[0,1]上的随机数;、表示第i个粒子在第k次迭代时第d维的个体最优位置和全局最优位置;为区间[0,1]上的随机数。本次实验将所有粒子速度限制在[-4,4]内。
2.2 记忆细胞信息分化机制
通过对传统免疫算法的算例分析,发现有几种情况会使得故障定位过程陷入局部最优,如图1所示为部分单电源无支路配电网,假设故障区段为L5。

图1 单电源无支路配电网
(1)除了诊断出S5=1以外,还会出现在S1~S4内的故障点。是因为在这种情况下,额外的故障点对整体的故障状态编码影响较小,免疫算法不容易跳出局部最优点。
(2)最终结果可能是S5附近的开关节点,例如S4、S6。因为这种情况下离全局最优情况已经十分接近,不容易通过免疫操作找到全局最优。
针对这些陷入局部最优的情况,设计了一种记忆细胞信息分化机制。其基本原理为:在算法迭代陷入局部最优的情况下,将记忆细胞内每个可疑的故障点化为抗体参与免疫操作。具体实例假设算法陷入的局部最优状态为(1 ,0,0,1,1,0,…),那么信息分化机制将将其分化为如下几个抗体参与免疫操作:
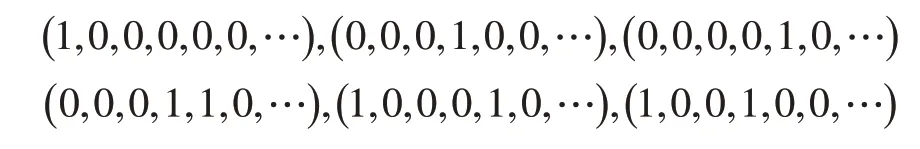
如果局部最优解只有一个故障点时,则会对这个故障点进行主动偏移,例如得到的解为(0,0,0,1,0,0,…)时,将会分化出( 0 ,0,1,0,0,0,…)、(0,0,0,0,1,0,…)两种抗体参与免疫寻优。
2.3 改进免疫算法的实现
本文改进的免疫算法采取粒子群算法并行运算方式,将初始化一样的两个种群分给粒子群算法以及免疫算法。之后的粒子群群体信息更新仅取决于自身的运算方式,免疫种群的信息更新不仅取决于传统免疫操作,还取决于记忆细胞的信息分化。记忆库的记忆细胞更新由两种算法共同决定,其具体流程如图2所示。
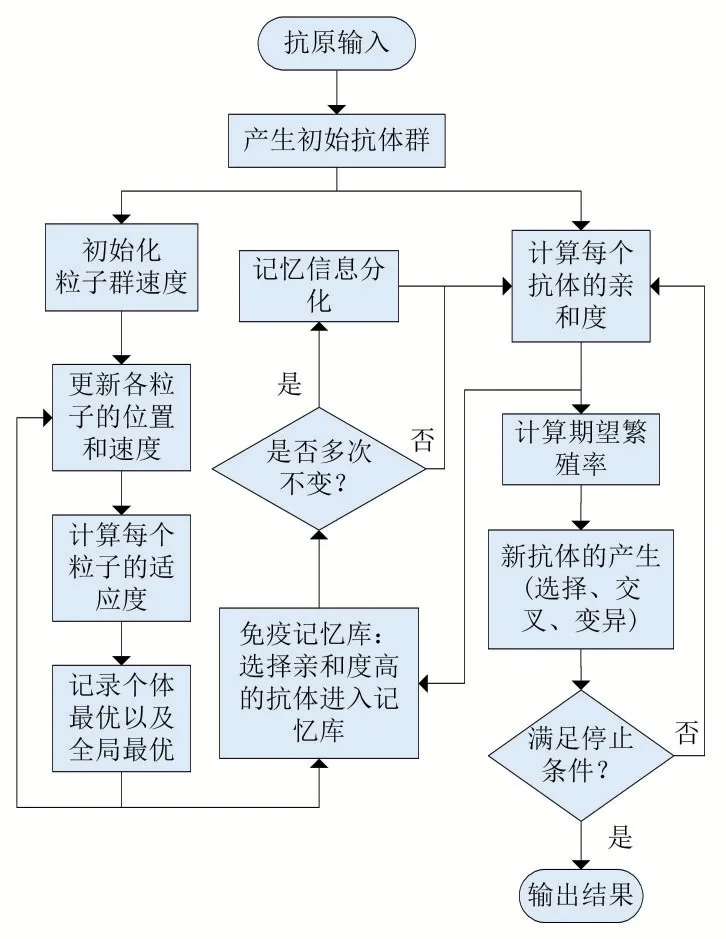
图2 改进免疫算法流程图
3 分层故障定位模型
改进免疫算法使用混合算法并行方式,这种方式虽然可以提高故障定位的准确度,但是也会降低迭代速度。基于这种情况,本次实验设计了一种分层网络结构,通过两次分层实现整体复杂网络的有效简化,达到运算数据降维,提高迭代速度的效果。
3.1 有源分支与无源分支
根据配电网各支路有无DG的情况,可以将支路分为有源支路、无源支路两种类型。有源支路包含了所有的电源,当配电网发生故障时,由各电源产生的故障电流会对有源支路上所有节点造成影响。当此故障未发生在无源支路上时,各电源所产生的故障电流并不会对无源支路上的开关产生影响,在这种情况下无源支路可以不参与故障定位运算,从而降低维度。
如图3所示,该配电网共有38个区段、1个主电源和三个DG。很明显,29至32区段所形成的支路和21至28区段形成的支路是两条无源支路,其他的开关在所有情况下都会受到故障电流的影响。假设此时故障出现在有源支路上,无源支路上的开关均不受故障电流影响,可以很容易将其剔除,在本例中网络结构将从38维降低到26维。
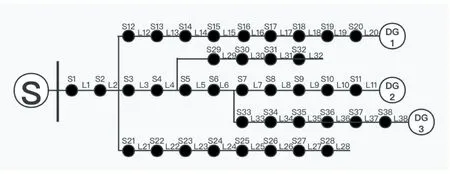
图3 含DG配电网
3.2 等效节点模型
由于DG的存在,使得大型配电网的结构变得更加复杂,也提高了故障定位的难度。为了降低网络的维度从而提高准确率和运算速度,实验使用了等效节点模型来简化模型结构。根据将每个分支点作为划分点的方法,将两个划分点内的分支区段等效成一个点,从而先对降维后的等效节点模型进行定位,找到故障发生的分支区段。
通过开关函数公式(4)可知,当故障发生时,在故障点所在的分支区段中,靠近主电源一侧的第一个开关节点的状态是确定的。在此分支区段上其他位置的开关则不能确定其状态,它们的状态由故障点的具体位置而决定。
以图3为例,假设只有一个故障点,且出现在L7~L11内任何一个位置,可知:

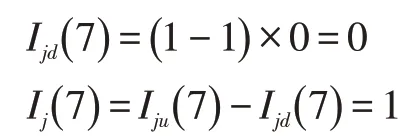
此时Iju(8)~Iju(11)的状态并不能确定,其状态受故障点具体位置影响。
此时其上游节点S(1)~S(6)的期望节点状态可得:
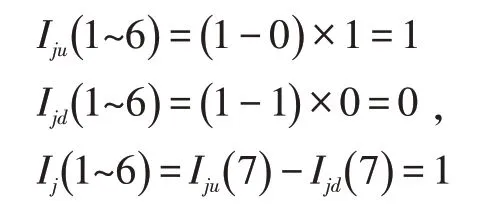
而当故障点出现在其上游区段,此分支区段内无故障点时:
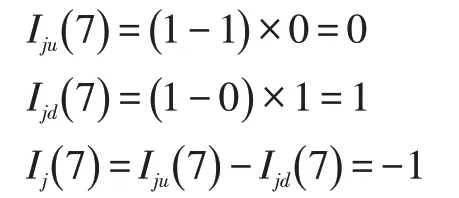
同理此时Iju(7)~Iju(11)的值相同。
通过对各个分支区段分析易知,当故障发生在某分支区段内,此分支区段内的第一个开关状态是能够确定的,并且具有代表性;此故障点对其他区段的等效节点所带来的影响是固定的,具体影响可以根据上下游关系判断;此故障点对故障区段内的其他节点状态的影响不确定,要根据具体位置具体分析,但不影响等效节点的工作。
通过等效节点模型,可将图3所示结构简化为如图4,将原本38个节点的故障定位转换为先对8个节点进行故障定位。
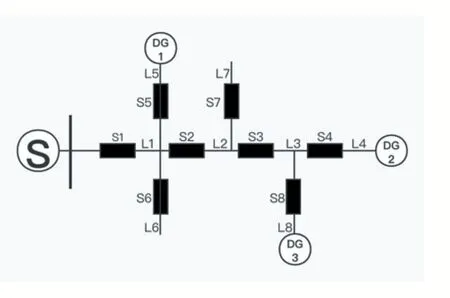
图4 含DG配电网等效节点模型
3.3 分层模型实现方式
本次实验使用先降维,再等效的方法对配电网模型进行分层运算。具体步骤为:
(1)将配电网划分有源分支和无源分支,根据检测到的真实节点状态对无源分支进行筛查。如果判断无源分支上并没有故障电流,则认为无源分支上没有故障点,在网络模型中去除无源分支。
(2)对去除无源分支后的网络进行等效节点简化,同时对简化后的模型进行改进免疫算法的寻优,得到故障点所在的区段。
(3)利用改进算法对步骤(2)所找到的区段进行定点故障定位。
4 算例分析
本次实验使用图3所示配电网模型进行算例分析,分别对传统免疫算法、改进免疫算法、改进免疫网络及其算法3种方式进行故障定位实验。实验共预设了3种DG接入情况,分别是[1,1,1]、[1,0,1]、[0,1,0],其中1代表DG接入,位置与DG编号相对应。对3种DG接入情况下设计了5种故障状态,分别是:①L9故障;②L18、L34故障;③L10、L16、L31故障;④L18、L27故障,S22信号畸变为0,S36信号畸变为1;⑤L25、L31、L36故障,S3信号畸变为0,S11信号畸变为1,S17信号畸变为1。
对以上每种故障状态进行2次实验,即对每种算法共进行30次实验,部分实验结果如下。
表1的数据是DG接入情况为[1,1,1]时,采取传统免疫算法的实验数据。表2内数据是30次实验的平均数据。其中,抗体数量N0=20,记忆细胞数量Nm=4,相似度阈值e=0.9,交叉概率Pc=0.8,变异概率Pm=0.08,共迭代400次。
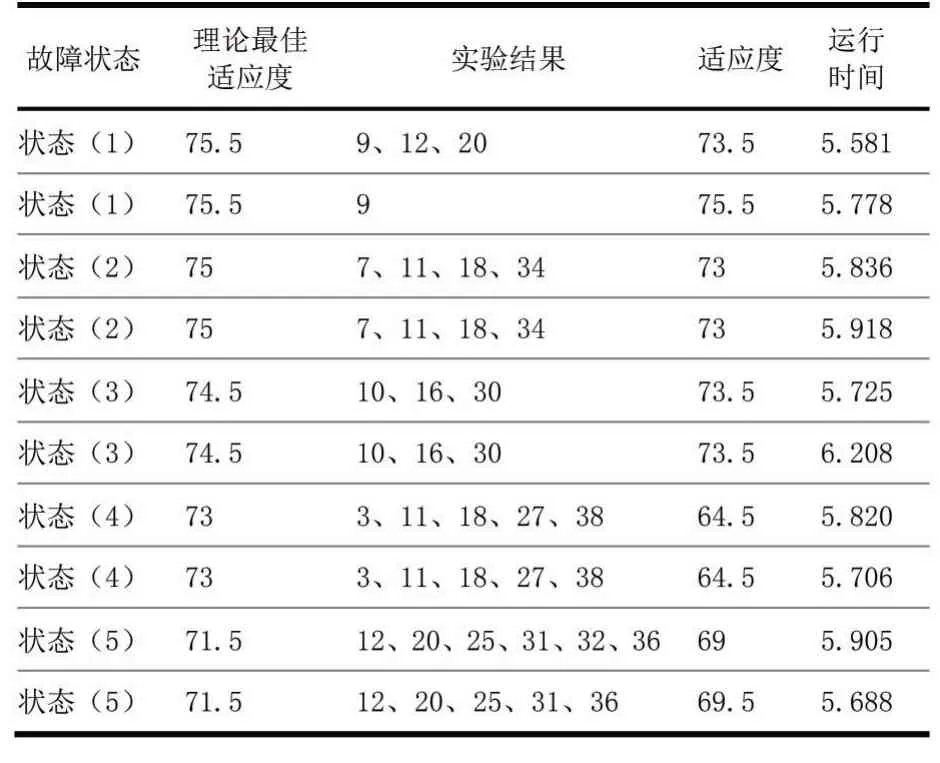
表1 传统免疫算法部分仿真结果

表2 传统免疫算法平均数据
表3和表4内是使用改进免疫算法的部分实验数据。其中,抗体数量N0=20,记忆细胞数量Nm=4,粒子群种群数量Np=24,相似度阈值e=0.9,交叉概率Pc=0.8,变异概率Pm=0.08,共迭代400次。
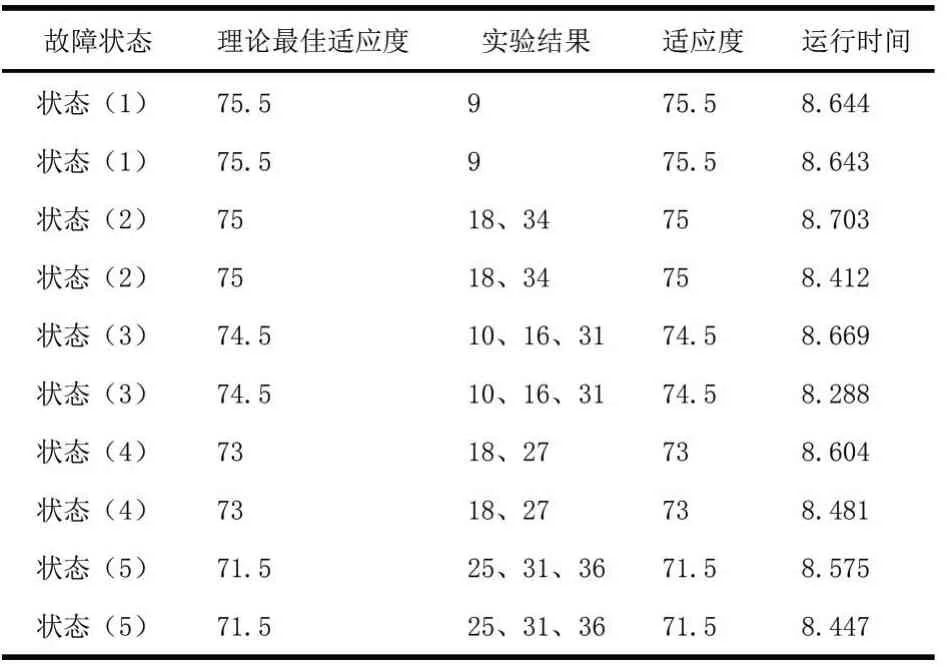
表3 改进免疫算法部分仿真结果

表4 改进免疫算法平均数据
表5和表6内是使用改进免疫网络及其算法的部分实验数据。由于采用分层网络模型,在新的模型中算法会进行两次迭代寻优,因此每次寻优迭代200次,其余参数与之前相同。
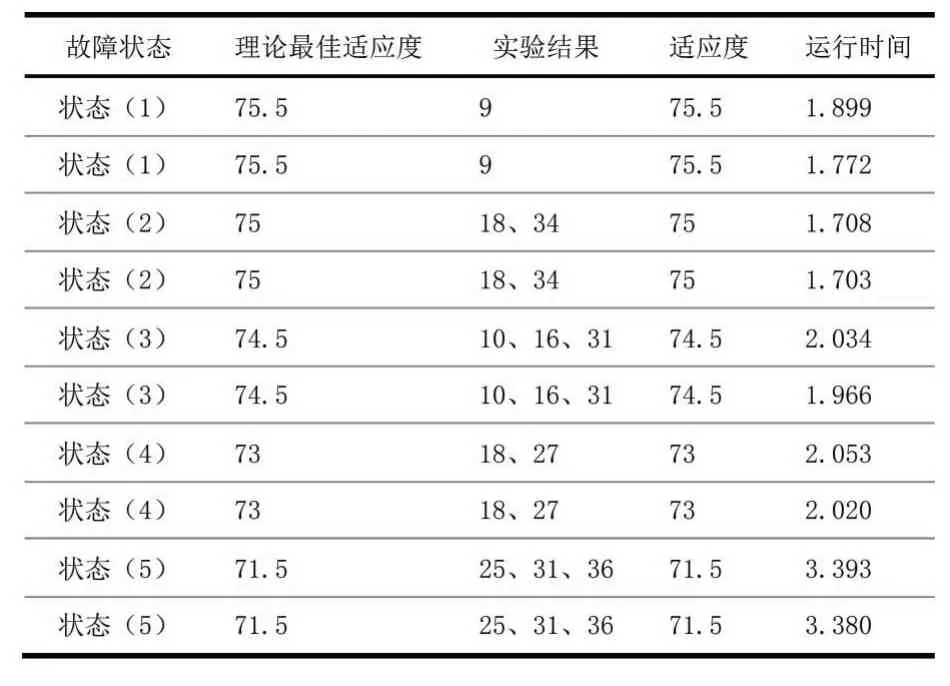
表5 改进免疫网络及其算法部分仿真结果

表6 改进免疫网络及其算法平均数据
通过实验数据表明,新的改进免疫算法能够很好地应用于含DG的配电网故障定位。该算法与传统免疫算法相比,能够大幅提高定位准确性。并且针对各类情况,例如多重故障、多重信息畸变等,都能表现出特别优秀的准确性。改进免疫算法因其复杂的运算方式使得运算时间有所增,但分层模型的引入能够显著降低运算复杂度从而降低运算时间。因此应用于分层模型的改进免疫算法能够优秀地实现故障定位功能。
