一种基于聚类的交通轨迹差分隐私保护数据发布方法
2021-09-23赵书鹏
赵书鹏
(广东工业大学计算机学院,广州510006)
0 引言
随着物联网技术的飞速发展,越来越多的设备能够收集和分析用户个人的移动信息,并为用户提供定位、导航、兴趣点推荐等服务。导航应用程序可以根据用户当前的位置和目的地为其规划最快的移动路线,交通摄像头可以识别车辆车牌等特征信息并跟踪其位置。通过与第三方公司合作进行数据分析,企业和政府可以将这些信息应用到各种交通场景中。
但是,上述设备收集的位置信息可能包含个人隐私。例如,带有全球定位系统(GPS)的智能手机可能会记录敏感位置,例如家庭和工作地点。这些信息一旦泄露,个人的生命财产安全可能受到威胁。目前,数据的收集方往往只采用传统的k匿名、空间位置掩盖等方法来保护隐私数据。然而,这些方法都不能抵抗背景知识和再识别攻击。例如,攻击者可以通过一个人的性别、家庭和工作位置来识别出他的所有轨迹位置信息。因此,对于轨迹数据的发布,只采用传统的匿名方法是不够的。
差分隐私[1]是由Dwork于2006年提出的一种严格定义的隐私保护模型,能够概率地对查询或分析结果添加噪声,保护数据库中单条记录不被泄露。因其能够量化评估结果,在交通轨迹数据发布领域受到越来越多的关注。由于轨迹信息通常是二维甚至高维的,直接添加噪声容易使数据误差过大[2],因此研究人员通常会先对高维轨迹进行泛化操作。常用的泛化方法一般为采用网格模型或树形结构进行映射。此外,随着机器学习相关研究的深入,与差分隐私保护算法结合的研究也取得了一定的进展。
Hua等人[3]提出了一种K-means和指数机制结合的位置泛化方法。Li等人[4]扩展了这一方法,它首先用K-means离散每个时间戳n条轨迹的每个点并视作最优划分方式,再设计距离计算公式提取候选划分方式,通过指数机制选取该时间戳的聚类方式,以簇心作为该类点的映射位置。但由于K-means受初始值和离群点的影响,导致聚类结果不稳定且需要预设定簇的数量,因此会对轨迹点映射的准确性造成影响。
我们提出了一种新的基于聚类的交通轨迹差分隐私保护数据发布方法,结合AP聚类与欧氏几何的豪斯多夫距离进行轨迹点的区域划分和泛化映射,不需要提前定义聚类个数,更好地适应每个时间戳不同的轨迹点稀疏情况。
1 相关工作
早期大多数轨迹数据发布方法大都基于k-匿名[5],如果一个数据集满足k-匿名,那么该数据集中至少有k条记录具有相同的属性值。Nergiz等人[6]首先将k-匿名应用于轨迹数据集,在广义时空下抑制单个轨迹点或整条轨迹。Abul等人[7]提出了一种广义的k-匿名方法,即在一定地理距离范围内的点可以被认为是在相同的位置,并应用到轨迹集中[8]。Chen等人[9]对身份链接攻击和属性链接攻击进行了研究,首先提出了一种基于(K,C)L-privacy的支持局部和全局抑制的匿名化框架。虽然k-匿名方法被广泛应用,但k-匿名容易受到同质性攻击和背景知识攻击,也不能量化隐私泄露的概率。因此,它们不能为发布轨迹数据提供足够的隐私保护。
差分隐私[1]作为一种颇受关注的隐私保护技术,能够防止拥有任意背景知识的攻击者的攻击并提供有力的保护。其基本方法是对原始数据、原始数据的转换过程或者是对统计结果添加噪声实现隐私保护,并且对隐私保护的水平进行了严格的数学证明。目前,在轨迹序列数据发布中,差分隐私算法也被广泛应用。但由于轨迹数据普遍是高维且稀疏的,因此怎样聚合轨迹数据是目前主要的研究方向。我们根据不同的聚合方式将差分隐私保护轨迹数据发布的研究内容主要分为三类:基于树形结构的模型、基于网格结构的模型以及基于聚类的模型。
Chen等人[10]首先提出了一种基于树型结构的差分隐私保护轨迹数据发布模型SeqPT,该模型利用混合粒度的前缀树存储所有子序列的噪声计数,并发布差分隐私轨迹数据。Chen等人[11]用可变长度的NGram模型存储变长子序列,并将子序列与生成的轨迹进行组合。Khalil等人[12]提出了一种新的模型SafePath,该模型利用一种变高度、变度的分类树来降低生成空节点的概率,提高匹配位置和时间标签的速度。Li等人[13]对SafePath进行了扩展,通过一种增量的隐私分配机制和一种新的不需要分类树的前缀树结构来提高其有效性和效率。
由于轨迹数据固有的顺序性和高维性,前缀树在处理具有时间属性的轨迹数据时存在效率低、可用性低等问题。Mir等人[14]提出了满足不同隐私保护出行路线的WHERE[15]模型,命名为DP-WHERE。首先将轨迹点映射到均匀网格中,然后构建home position、movement length、work position、call times概率分布,生成新的轨迹。He等人[16]提出了一种分级参考系统DPT,该系统可以识别具有不同粒度的原始轨迹,并将其映射到具有相应粒度的参考系统中。Gursoy等人[17]提出了一种两层的自适应网格,通过第一层均匀网格内轨迹点的密度来计算推出第二层子网格的划分大小,以此生成的网格来对轨迹点进行映射。Ghane等人[18]以移动速度与对象最小停留时间为参数设计生成了一种均匀的网格结构来映射轨迹。
随着机器学习、神经网络相关研究的发展,现在越来越多的研究关注机器学习与差分隐私的融合技术。傅彦铭等人[19]提出了一种差分隐私保护Kmeans++聚类算法,在初始化选取中心点和迭代求均值中心点的过程中分别添加拉普拉斯噪声以满足差分隐私保护。胡闯等人[20]提出了一种新的基于差分隐私的DPk-means-up聚类算法来确定最佳K值的选择。黄保华等人[21]提出了一种结合三分法和等差数列的隐私预算分配方案,保证使用对K-means每次迭代更新质心的过程中引入的噪声不会引起质心变形。Hua等人[3]提出了一种利用K-means聚合点和指数机制提取点的位置泛化方法。文献[4]扩展了这一工作,它首先用K-means离散每个时间戳n条轨迹的每个点并视作最优划分方式,再设计距离计算公式提取候选划分方式,通过指数机制选取该时间戳的聚类方式,以簇心作为该类点的映射位置。但由于此类算法需要预设簇的数量,受初始值和离群点的影响,导致聚类结果不稳定,因此会对轨迹点聚合的准确性造成影响。
2 理论基础
2.1 AP聚类算法(Affinity Propagation Clustering Algorithm)
AP聚类算法又称吸引子传播算法,是基于数据点间的“信息传递”的一种聚类算法。AP聚类算法的基本思想是将全部样本映射成网络的节点,再通过网络中各边的消息传递计算出个样本的聚类中心。聚类过程中,有吸引度(responsibility)和归属度(avail⁃ability)两类消息在各节点间传递。AP聚类算法通过迭代来不断更新每个节点的吸引度和归属度,直到产生m个高质量的Exemplar(相当于质心),并将其余的数据节点分配到相应的聚类中。
设数据样本集为{x1,x2,…,xn},S为描述各轨迹点之间相似度的矩阵,当且仅当xi与xj的相似性程度要大于其与xk的相似性,S(i,j)>S(i,k)。
吸引信息矩阵R:r(i,k)描述了数据对象k适合作为数据对象i的聚类中心的程度,表示的是从i到k的消息。
迭代公式:

其中:

归属信息矩阵A:a()i,k描述了数据对象i选择数据对象k作为其据聚类中心的适合程度,表示从k到i的消息。
迭代公式:

其中:
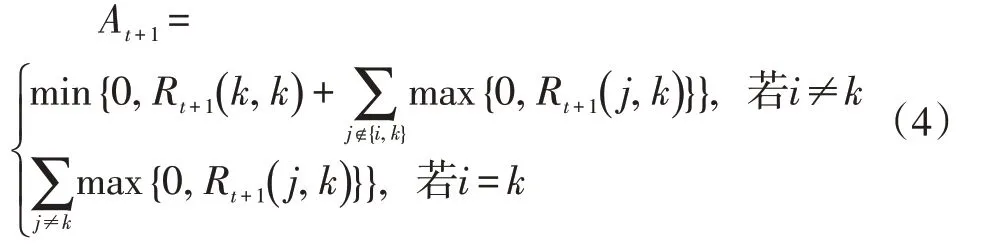
2.1 差分隐私
相邻数据集:对两个数据集D1、D2,如果存在一条轨迹T,使得D1=D2∪T或D2=D1∪T,则D1、D2互为相邻数据集。
差分隐私是一种概率隐私保护模型,对两个相邻数据集,经过差分隐私保护模型处理后,发布的两个数据集的不存在明显差异,即无法识别出数据集中的单条轨迹。因此,可以防止具有额外背景知识的攻击者的攻击,保护用户个人隐私。
ε-差分隐私:对相邻数据集D1、D2,一种随机算法A,Range(A)表示算法A所有可能的输出集合,S是Range(A)任一子集,即S⊆Range(A)。若对于所有的S,都有:
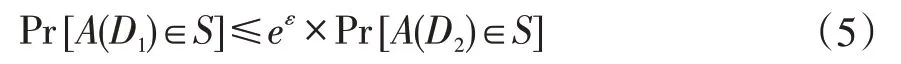
则随机算法A满足ε-差分隐私。其中,隐私预算参数ε控制隐私保护的级别,ε越小,隐私保护级别越高。
敏感度:对函数f:D1→Rm,输入为数据集D1,输出为m维向量。则f的敏感度为:

其中,D1、D2互为相邻数据集,||.||表示L1范式。
拉普拉斯机制是目前常用于对数值型数据实现差分隐私保护的方法,添加噪声的大小依赖于其敏感度。
拉普拉斯机制:对函数f:D→Rm,令表示添加的噪声,该噪声由平均值为0,由规模参数为

指数机制:设一得分函数q(D,R),输入为数据集D,输出为一实体集R,若对一随机算法A的任一输出r∈R,与e(εq(D,r))/(2∆q)成正比,则称随机算法A满足ε-差分隐私。
为了应对复杂的算法模型,我们可以设置具体的组合算法,来保证模型满足差分隐私保护。
组合属性:设A1,A2,…,An为n个随机算法,对每个i∈[1,n],Ai满足εi-差分隐私。则有:
顺 序 组 合:A1(D),A2(D),…,An(D)输 出 满 足-差分隐私。
平行组合:在D的不相交子集上应用每个算法,满足max(εi)-差分隐私。
后处理免疫性:对满足差分隐私保护的算法输出的结果进行二次处理,不会影响数据的隐私性。
3 算法框架和描述分析
本文提出的满足差分隐私保护的交通轨迹数据发布方法分为两个部分,轨迹点聚合泛化模块与轨迹生成发布模块。对原始轨迹集中每个时间戳的轨迹点使用AP聚类算法进行聚合,基于聚合结果,匹配选择豪斯多夫距离最短的φ种聚合方式作为候选划分方式,设计得分函数并使用指数机制选择最佳划分方式,再对聚合后的轨迹集合并泛化,对轨迹计数添加噪声,最后经后处理后生成发布轨迹数据集。该模型的创新之处在于,使用了AP聚类算法进行轨迹聚合,不需要指定最终聚类的划分个数,减少参数的干扰;将AP聚类与欧氏几何平面的豪斯多夫距离进行结合,更好地增强发布数据集的数据可用性。实验结果证明,该模型发布的轨迹数据集能够在满足差分隐私保护的同时,具有较高的数据可用性。
3.1 轨迹点聚合模块
算法1轨迹泛化整合
输入:原始轨迹集D,时间域Dt,候选划分方式数量φ,隐私预算ε1
输出:聚合后的轨迹集D1
1.Map=[]
2.For each timestamptiinDt:
3.Dti=[T[ti]forTinD]
4.apArea=AP(ti_points)//AP聚类
5.φAreas=φSubOptimal(apArea,hausdorffDis)
6.areaSelect=EM(φAreas,ε1)
7.Map[ti]=areaSelect
8.D1=map(Map,D)
9.While|D|-|D1|>0:
10.D1.add(Trajectory)//随机从D中选取
11.ReturnD1
算法1在每个时间戳下,先提取轨迹集D在该时间戳下所有轨迹点,使用AP聚类算法,对轨迹点进行聚类划分。再结合文献[4]中φSubOptimal方法,基于AP算法聚类划分与豪斯多夫距离,计算得出φ个最优的候选划分方式φAreas。然后使用指数机制对划分方式进行选取,期间,需要设计指数机制的得分函数。
设每一种划分方式为p,AP算法得出的划分方式为p',根据文献[4]中基于豪斯多夫距离设计的平均距离算法MeanDist,我们可以得到可靠性U的函数:

则对任意一中划分方式pi,我们可以得到得分函数为:

使用设计的指数机制选择该时间戳下的轨迹点划分结果,再以每个划分区域的簇心作为该区域点的映射位置,对数据集所有轨迹点进行映射,完成泛化操作。此外,为了达到与原轨迹相同的轨迹种类,需要随机选取|D|-|D1|条原轨迹加入到D1数据集中。
3.2 轨迹生成发布模块
算法2噪声添加与后处理
输入:映射数据集D1,每条轨迹的真实计数{tc1,tc2,...,tcN},隐私预算ε1
输出:发布的轨迹数据集D'
2.ForiinN:
3.nci=tci+lap(ε2,Δf)
4.NC={nc1,nc2,…,ncN}
5.SortNCand getS=
7.S'=
8.Forifrom 1 toN:
9.nci'=S'[i]
10.D2={(Ti',nci')|i=1,…,N}
11.D'=[forifrom 1 toN:randomly choose
12.Tbased onP(nci'/sum(S'))]
13.ReturnD'
轨迹生成发布模块分为噪声添加与后处理两个子模块。前半部分(1-3行)是噪声添加子模块,先计算出敏感度,由敏感度定义可知,这里的敏感度为1,然后根据隐私预算ε2,对不同轨迹的计数添加拉普拉斯噪声。后半部分(4-10行)为后处理子模块。为了更直观地进行后处理,我们以图的形式来映射生成的轨迹集,不同的节点表示不同时间戳的轨迹点位置。由实际经验可知,对于相邻的节点,时间戳小的节点计数一定大于时间戳大的;且如果对两个节点p、g,p的真实计数大于q,那么p的噪声计数也应大于q。因此,我们基于文献[4],设计了一种后处理方法:我们令mean[i,j]表示S的一条子轨迹Sij的平均数:

然后计算得:

该后处理方法使轨迹更加符合真实情况。最后再按照对应的计数比作为轨迹生成的概率,生成与原轨迹相同数量的数据集D',完成轨迹集D'的发布。
4 实验结果分析
4.1 实验设置
本文提出的算法基于Python实现,本节中所有实验的运行环境为双核Intel Core i5 3.1 GHz,内存为8 GB。采用微软提供的公开数据集T-Drive[24],内含北京10357辆出租车一周的出行轨迹。我们提取了其中850条轨迹,每条轨迹包含32个时间戳。详情如表1所示。作为对比,我们同样实现了文献[4]中的模型,通过设置不同的隐私预算、聚类数量,对比说明本文提出算法的先进性。

表1 数据集的基本统计信息
4.2 结果评估指标
4.2.1 计数查询误差
在对轨迹数据集进行统计分析时,数据分析人员通常会对一个区域内的人员情况进行统计查询。我们规定,计数查询方法Q(D):在地图上任取一点为圆心,以半径为r作圆,计算数据集D中经过该圆的轨迹数。则查询相对误差为:

其中b为原轨迹集中轨迹数目的0.1%。为了防止概率性误差,评估时会进行100次实验,结果取平均值。
4.2.2 豪斯多夫距离
豪斯多夫距离是在度量空间中任意两个集合之间定义的一种距离,是一种常用的欧氏几何度量方式。我们用豪斯多夫距离作为数据集有效性的评价指标之一。

其中:

豪斯多夫距离越小,说明两个数据集越相似。
4.2.3 结果分析
基于T-Drive数据集,我们在不同的隐私预算下,对比文献[4]提出的模型进行实验,分析评估指标的差异。由于对比文献[4]提出的模型是基于K-means算法的,聚类数量需要提前设定,因此我们分别对聚类数为10,20,30,…,100的模型进行了实验。
图1、图2分别为隐私预算为1下,本文提出的方法与文献[4]提出的模型(聚类K值分别为10,20,30,…,100)计数查询误差的对比图与豪斯多夫距离的对比图。由图1可以看出,我们提出的方法具有更低的计数查询误差,说明在位置准确度上,我们的方法能更好地拟合原始轨迹的稀疏性,更大地保存数据信息。由图2可以看出,我们提出的方法对比大部分K值下的文献[4]模型结果,具有更低的豪斯多夫距离,得到的数据集可用性较高。

图1 同一隐私预算下计数查询误差结果对比

图2 同一隐私预算下豪斯多夫距离结果对比
图3、图4分别为不同隐私预算下,本文提出的方法与文献[4]提出的模型(划分数分别为10、70、100)计数查询误差的对比图与豪斯多夫距离的对比图。由图3可以看出,不同隐私预算下,我们提出的方法依然具有最佳的计数查询误差。由图4可以看出,我们提出的方法也接近文献[4]模型的最佳豪斯多夫距离。且从两个图中都可看出,随着差分隐私预算的增加,计数查询误差与豪斯多夫距离都越来越低,效果越来越好,符合差分隐私的定义。

图3 不同隐私预算下计数查询误差结果对比

图4 不同隐私预算下豪斯多夫距离结果对比
综上,由于我们提出的方法可以不需要提前指定轨迹点划分区域数量,且将AP算法与豪斯多夫距离计算相结合,能够不受数据集稀疏、范围的变化影响,能更好地对轨迹点进行聚合泛化,发布具有更好数据可用性且满足差分隐私保护的数据集。
5 结语
本文提出的基于聚类的交通轨迹差分隐私保护数据发布方法,目的是为了提高发布数据的可用性同时保证用户的隐私。本文的算法通过改变每个时间戳轨迹点聚合的方式,使用AP聚类算法进行轨迹点聚合,基于聚类结果结合豪斯多夫距离计算生成候选划分方式,设计新的指数机制进行选取。对比常用的K-means聚类方法,我们提出的方法不需要事先指定聚类的数量,聚类的结果不会变化,也更适用于稀疏的轨迹集。在T-Drive数据集上的实验结果也表明,该方法能够在保护发布轨迹数据集隐私的同时,极大保留数据集的可用性。下一步将拓展差分隐私算法在轨迹数据发布领域与新兴领域的结合,尝试结合使用神经网络相关算法,以提高数据可用性。
