基于特征贡献度与线性搜索的特征选择方法
2021-09-23郭文斌丘康平蔡惠坤
郭文斌,丘康平,蔡惠坤
(1.广东工业大学机电工程学院,广州510006;2.广州广日电梯工业有限公司,广州511447;3.中移互联网有限公司,广州510640)
0 引言
随着大数据时代来临,互联网、工业和制造等行业积累了大量的数据,基于数据驱动业务的研究成为国内外研究的热点方向。各种形式的数据处理技术的出现,使得数据挖掘和数据分析等效率更高,利用能被用于数据分析或者机器学习建模的数据往往特征空间庞大而且复杂,面对高维且特征空间巨大的数据,去除特征冗余,降低数据维度,提高建模计算空间,节省计算性能将成为数据处理相关的难题之一。在回归问题中,高维数据特征与目标特征之间往往呈现非线性的关系,数据特征空间中隐含的对目标结果不相关或者冗余的数据特征会影响数据建模的性能以及准确性,快速且有效的特征选择方法有助于简化学习模型学习空间。本文将某特种设备相关的高维预处理数据作为研究对象,使用基于特征参数的贡献度分析,结合参数的贡献度排序与分布,进行线性搜索,实现搜索路径上的最优解,并消除冗余特征,提高建模性能。
1 研究现状分析
特征选择问题最早于20世纪60年代被提出,最初用于研究统计学和信号处理领域,后逐步将特征选择延伸至机器学习、模式识别等领域[1]。按照特征选择和机器学习器的结合方式不同,可以将特征选择方式分为四种,分别为过滤式[2]、封装式[3]、嵌入式[4]和集成式,按照特征选择的搜索策略,可以分为全局最优搜索、随机搜索和启发式搜索等算法[5-6]。
基于特征排序是一种重要的特征选择方法,特征排序的评价标准有多种,可以分为Laplacian得分、Constraint得分、Fisher得分、Person相关系数等。传统特征搜索算法,采用穷举算法随着特征维度升高,特征子集的数目呈指数级增长,几乎不可能实现。基于特征排序,李光华等人提出了一种融合蚁群算法和随机森林的特征选择方法[7],武炜杰等人提出了三种随机森林多特征置换算法进行特征选择,但是此算法研究都针对分类领域的特征选择[8]。在特征选择相关的研究中,已经吸引了许多的研究学者在从事相关的研究工作,并综合了诸多算法与实现流程,发展近几十载,国内外相关文献已经有了近几千篇之多,但是诸多研究学者仍然不遗余力地进行相关地研究,其目标之一便是使用简单高效的方式实现特征选择的最优子集以便精简算法模型。
本文基于线性搜索的方法,与全局搜索策略不同,线性搜索具有更小的搜索空间;与随机搜索不同,随机搜索自定义搜索阈值可能使得特征子集仍然存在冗余。
2 相关理论
2.1 特征选择框架
特征选择的任务是从特征数据集中选择最有利于数据建模的子特征数据集,按照传统数据特征框架,该框架包含四个基本过程,如图1所示,主要为生产特征子集、评价特征子集、停止条件和验证结果[9]。

图1 传统的特征选择框架
2.2 特征排序计算方法
2.2.1 XGBoost算法
XGBoost(eXtreme Gradient Boosting)[10]是极端梯度提升树算法的简称,是基于GBDT算法上的改进,是基于弱学习器加权叠加形成强学习器的集成学习算法。XGBoost是结合了决策树、集成学习、广义加法模型、牛顿法等多种基础知识的算法,并在损失函数、正则化、切分查找算法、稀疏感知算法、并行化算法设计等多方面进行了改进,比较适合解决抽象数据分析方面的问题,在Kaggle比赛中也受到诸多青睐。
(1)定义目标函数:
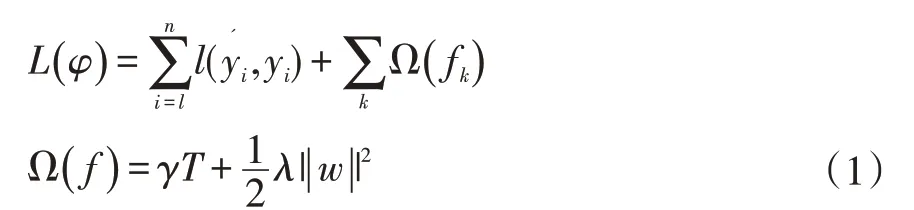
其中,n为训练样本,l为但样本损失,为预测值,yi为真实值,φ为模型参数,γ和λ为人工设定系数,w为叶子节点向量,T为叶子节点数,fk为映射函数。

(2)训练目标函数:yi、是常数,+ft(Xi)是损失函数的自变量。
(3)将目标函数按泰勒二阶展开:

其中,gi为损失函数的一阶导数:

hi为损失函数的二阶导数:

(4)去掉与ft(Xi)无关常数项:

(5)求出最优解:

(6)算法伪代码,如图2所示。

图2 XGBoost算法流程
2.2.2特征贡献度度量
贡献度即重要度,是衡量数据特征中每个特征对于目标特征的影响程度的评价指标。在XGBoost算法中,有三种全局特征的贡献度归因方法。三种贡献度算法是基于决策树的每次分割采用贪婪方式进行,即选择信息增益最大的特征用于树的分裂点。信息增益的计算方式如下:

(1)Weight。表示权重形式,指在所有树中,一个特征在分裂节点时被使用的次数。若一个特征作为分裂特征的次数越多,表明这个特征对于目标特征越重要。
(2)Cover。表示平均增益形式,指在所有树中,一个特征作为分裂节点存在时,带来的增益的平均值。
(3)Gain。表示平均覆盖度,指在所有树中,一个特征作为分裂节点存在时,覆盖的样本数据量的平均值。
2.3 线性搜索算法
线性搜索算法是在搜索空间下按照顺序搜索的方式寻找目标的最优值的算法,其搜索的次数一般为搜索空间的大小,当找到最优值或者达到搜索空间的尾端搜索步骤停止。
3 特征贡献度分析与特征选择
3.1 基于线性搜索的特征选择
结合特征贡献度的线性搜索算法的实现步骤如图3所示。

图3 算法流程图
(1)选用gain指数作为指标,按照XGBoost算法对数据进行特征贡献度分析,并对高维的数据按照得分进行特征排序。
(2)初始化搜索次数K=0,选用特征排序的得分最低点作为搜索起点。
(3)选用搜索空间位置的前向作为特征子集,并计算该子集的模型评价指标值。
(4)比较输出最优子集。
3.2 评价指标
在特征选择的回归数据子集中,衡量子集在数据模型上的表现好坏需要对子集建模的效果做出评价,决定系数将是很好的衡量指标。决定系数是反映预测目标的变异中可以通过自变量解释的所占的比例,它能够评判回归模型对于该数据的解释能力,其值越大说明自变量对因变量的解释程度越高,模型的表达能力越好,进而可以说明在该数据特征的子集下建模的效果越好。其公式如下:
定义一组数据集中包含y1,…,yn一共包含n个观察值,该同等观察值的参数下的模型预测值为f1,…,fn。
平均观察值:

总平方和:

回归平方和:

残差平方和:

决定系数:

4 案例分析与讨论
实验数据采用来自电梯设备相关的报价数据,其数据特征包含维度较低和维度较高的编号为NUM01、NUM02、NUM03三种设备型号的数据,该数据经过数据预处理的基本过程,使得数据能够直接利用在数据建模、数据分析和决策之中。实验数据描述如表1所示。

表1 测试数据描述
本次实验环境为采用统一的计算硬件环境和性能配置,并且使用统一的神经网络模型作为评价指标的计算工具,分别对三组数据进行测试与比较。其结果如图4-图6所示。

图4 NUM01实验结果

图5 NUM02实验结果

图6 NUM03实验结果
本次实验除了使用决定系数作为评价指标,还引入了MAE作为参考指标,方便对特征选择的搜索位置做出更精确定位,由图4-图6中,每个实验结果图中分别展示了两种颜色区分的折线图,红色折线图为在本文实现的算法中随着搜索路线中的搜索步长的递增,决策系数指标值的变化,蓝色折线图为随着搜索路线中的搜索补偿的递增,该搜索子集下的数据建模的损失值(Loss)。
在图4-图6的三个实验结果中,可以观察到随着搜索步数的不断增加,决定系数的值有平稳上升的趋势,说明冗余去除对模型的解释能力有所提升,同时MAE的值平稳下降,说明去除了冗余特征对总体数据的精确度有所提升。在决定系数上升到某个位置时,后续数据呈现震荡下降和不稳定的情况,说明去除了某些重要的特征之后,数据的解释能力忽然变差,模型不稳定因素变高。
5 结语
在数据驱动的时代,算法模型等分析和建模工具能够辅助科研工作者等做出快速的分析和决策,但是基于数据的处理始终是个棘手的难题,高维数据不仅增加了计算成本,增加了模型的复杂度,增加了计算空间,在次基础上,本文通过线性搜索的方式与特征贡献度结合,提出与分析了数据特征的选择方法,实验表明,可以缩减搜索空间的条件下找到搜索区域的较优子集,该方法对特征选择具有一定的参考价值。但是特征之间的关联度、特征编码方式的差异,以及特征降维之后该方法是否能够达到同样的效果还尚待挖掘。
