面向水文模拟的大规模多级并行参数率定框架
2021-09-13全婷李强聂宁明田在荣
全婷 李强 聂宁明 田在荣
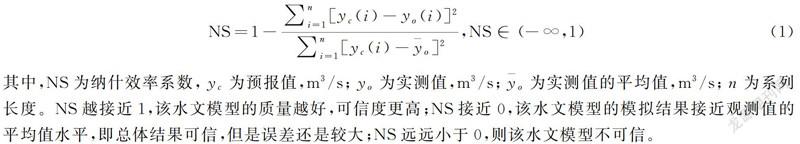

摘要:为了实现大尺度水文模拟中的参数率定,提出一种基于优化算法的大规模多级并行参数率定框架。首先利用MPI划分子通信域的技术,实现了多级并行处理框架,其次设计了基于对等模式的整体架构,以充分利用处理器资源,最后使用大量非阻塞式通信的方式优化了计算效率,减少了进程间等待。将该框架应用于HIMS水文模型的参数率定,试验结果表明,对等多级并行框架相对于主从并行框架具有更好的寻优效果,利用非阻塞式通信,在寻优效率上有所提升。该框架能够高效地利用大规模处理器且有效地缩短运行时间,提升了参数优化的整体效率,具有良好的扩展性。
关键词:水文模拟;大规模参数率定;对等式多级并行框架;非阻塞式通信;优化算法
中图分类号:TP338.6 文献标志码:A
文章编号:1006-1037(2021)03-0014-08
随着GIS/RS等高新技术的发展,分布式水文模型大量出现,如英国、丹麦和法国的水文工作者在1986年合作研發的MIKE-SHE模型[1]。此后,SWAT、IHDM等水文模型的出现,也验证了分布式大规模水文模拟实现的可行性。虽然国内水文模拟的发展起步较晚,但也涌现了HIMS(Hydroinformatic Modeling System)[2]、GBHM(Geomorphology-Based Hydrological Mode)[3]、新安江模型[4]以及EasyDHM(Easy Distributed Hydrological Model)[5]等分布式水文模型,在各流域模拟上展现了出色的模拟效果。分布式水文模型一般包含多个参数,其中大部分参数有明确的物理含义,能够根据实测的数据进行确定,但是在实际中仍然有很多参数需要通过率定获得。由于分布式水文模型需要率定的参数空间维度通常十几、二十维,高维参数空间搜索计算量巨大,传统搜索方式已经难以实施。20世纪80年代初兴起的启发式算法,包括遗传算法、模拟退火算法、粒子群算法和人工神经网络等,极大地推动了分布式水文模型中参数优化的发展。Wang[6]较早的将GA方法应用于径流模型的产流参数率定;Cheng等[7]将GA与模糊优选原理相结合,将其用于新安江三水源模型的参数率定;马海波等[8]将SCE-UA算法应用到TOPMODEL模型的参数率定;Thiemann等[9]以美国密西西比河Leaf流域(19 944 km2)为例,将贝叶斯回归参数估计算法应用于Nash-Cascade模型和Sacramento模型,验证了贝叶斯算法在参数优化方面有很好的效果。但是由于传统参数优化过程都是串行执行,运行时间较长。特别在大尺度水文模拟的参数率定中,运行时间有可能长达几个小时到几个月不等,率定优化效率问题成为制约水文模型发展的重要问题。近些年,随着高性能计算技术的飞速发展,在科学研究的诸多领域,并行计算都显著地提高了大规模数据处理的效率,并且可以通过算法的设计来提高最终结果的可行性。因此,越来越多的科研工作者将此技术应用于水文模拟中。Kollet等[10]证明了将并行计算用于水文模拟正确性与可行性;Yalew等[11]还探索了将并行计算用于SWAT中的水文模拟过程;Li等[12]运用分解法和MasterSlave范式开发了动态并行水文模拟模型。通过水文模拟和高性能计算的结合,水文模型的计算效率有了相应的提高。但是这些研究都是针对水文模拟过程的加速,而花费时间最长的参数率定过程的求解加速并未直接涉及。当前针对参数率定优化加速方法的研究主要以优化算法的改进为主,如Huo等[13]将改进的多核并行人工蜂群优化算法应用于水文模拟参数优化过程中;阚光远等[14]对SCE-UA算法并行化;李强等[15]设计的基于克里金插值理论的对等式并行框架。而以参数率定并行框架为主的研究并不多见,如李强等[16]设计的应用于SWAT模型的参数敏感度分析的主从模式并行框架;申蒙蒙等[17]通过改进优化算法中的相关算子实现的双层主-从并行框架等。这些并行框架的加入虽然使得优化算法的搜索效率和运行效率相对串行有了很大的提升,但这些率定框架的并行扩展性还有待提高。在现有水文模拟参数率定并行实现中,参数率定主从模式并行框架可扩展规模的的数量级皆在百核数左右。这是由于主从模式中的主进程和从进程的频繁数据交换和大量从进程的请求会导致从进程等待,从而影响最终的运行效率和并行规模的扩大。如果想要实现万核数甚至数十万核数的大规模水文模拟参数率定,需要突破当前已有的率定框架设计思路,从应用本身所具有的特点出发,设计真正适用于水文模拟参数率定的大规模率定方法。针对以上问题,本文提出一套针对大规模水文模拟参数率定的基于非阻塞通信的对等式多级并行框架。通过划分子通信域的方法,将框架分成多级并行结构。由于框架的特殊性,在进行诸如粒子群优化的过程中,采用异步非阻塞通信技术,使得群体内部的信息能够得到分享,从而进一步提高框架的搜索效率。
1 参数率定
在采用水文模型进行径流模拟和预报时,关键在于寻求水文模型的最优参数值。水文模型的参数优化过程主要分为两部分:模型率定和模型校验,本文主要研究模型率定。在模型率定时,将实测降雨、蒸发、径流等资料输入到水文模型中,以模型的模拟流量和实测流量的误差最小为目标函数,采用优化算法来搜寻模型参数的最优值。选择NS效率系数[18]来验证水文模型模拟径流的精确度
其中,NS为纳什效率系数,yc为预报值,m3/s;yo为实测值,m3/s;o为实测值的平均值,m3/s;n为系列长度。NS越接近1,该水文模型的质量越好,可信度更高;NS接近0,该水文模型的模拟结果接近观测值的平均值水平,即总体结果可信,但是误差还是较大;NS远远小于0,则该水文模型不可信。
参数率定的主要计算过程是根据率定优化算法选取步长和方向,得到新的粒子点,每个粒子代表一组参数;本文中的水文模型写成了一个函数接口,通过一组参数来调用水文模型函数接口进行水循环模拟,得到径流量模拟值,最后使用式(1)得到NS效率系数。整个率定过程可以作为一个子任务,分配到多个进程中,利用多个进程并行计算,最终得到最优的NS效率系数。基于参数优化算法特点,如若想要更加均衡的使用更多的处理器来进一步提高搜索效率,则可以通过MPI划分子通信域的方式来加大计算规模。
2 多级并行参数率定框架
2.1 基于子通信域的多级并行框架
为了更好地提高计算效率,本文选择以进程级并行作为主要并行策略。MPI(Message Passing Interface)[19]是一个性能很好的并行程序接口。具有两种最基本的并行程序设计模式:对等模式和主从模式[20]。由于对结果的收集需要进行大量的规约和广播操作,同时参数率定过程可以独立为一个模块,本文并行设计模式采用的是对等模式,更好的适应大规模测试。对等模式设计如图1所示。本文程序的基础并行框架采用对等模式,但为了率定优化需要,逻辑上分为三级:主管理进程、子管理进程和计算进程。为了提高框架的并行效率,同时为了适应后续工作的异构结构特征设计,本文考虑划分子通信域。
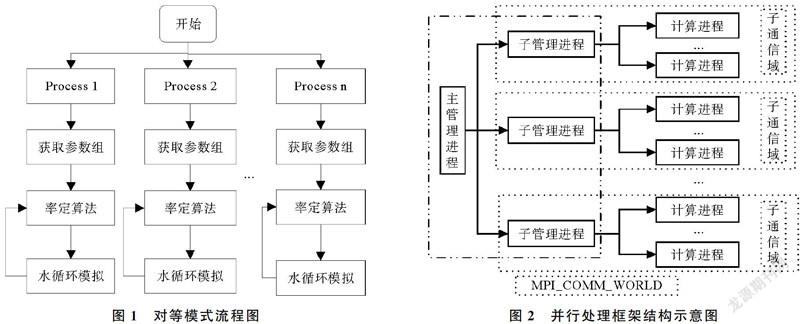
算法设计如下:将整个通信域MPI_COMM_WORLD中所有进程创建进程组MPI_GROUP_WORLD;排除主进程获取新的进程组newgrp;将新进程组newgrp创建为一个通信域newcomm;获取通信域newcomm中进程的进程号newrank和进程数newnum_procs;将通信域newcomm划分为subSpace个子通信域subcomm;将通信域MPI_COMM_WORLD的前subSpace+1个进程划为组group,将组group创建为通信域comm。其中,通信域comm中的0号进程为主管理进程,子通信域subcomm中的0号进程为子管理进程,子通信域subcomm中的其他进程为计算进程,至此框架的三级划分完成,如图2所示。
2.2 多级并行框架流程
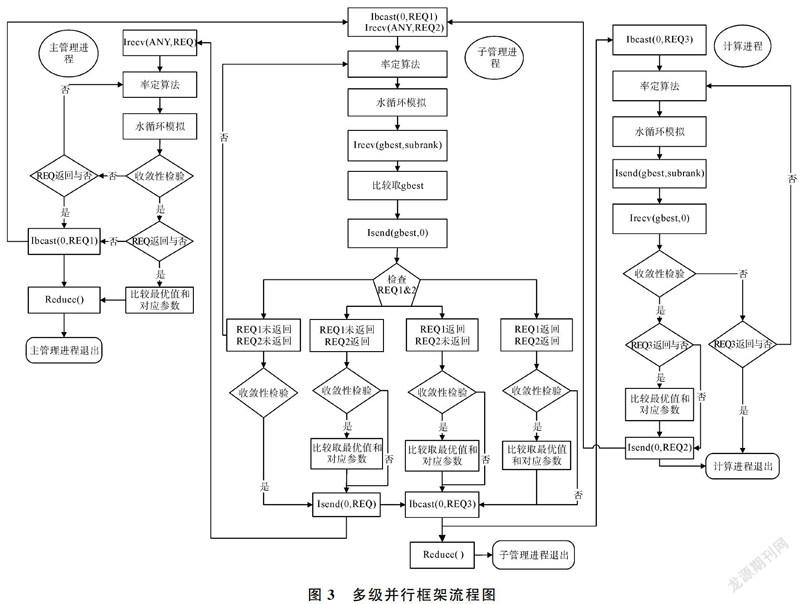
采用MPI划分子通信域实现的三级并行框架,其中的主管理进程、子管理进程和计算进程之间的关系如图3所示。主管理进程和子管理进程划分在一个通信域comm中,子管理进程和计算进程划分在多个子通信域subcomm中。首先主管理进程进行一个非阻塞式接收,用于接收来自子管理进程的收敛信号,子管理进程进行一个非阻塞式广播和非阻塞式接收,用于接收来自主管理进程的退出信号和计算进程的收敛信号,计算进程进行一个非阻塞式广播,用于接收来自子管理进程的退出信号。然后进入参数率定,获得各自最优解,同时对得到的最优解进行收敛性分析。主管理进程在进行收敛性分析时,若自身收敛或者子管理进程也收敛,则向所有其他子管理进程发送结束信号;若二者都未收敛,则回到参数率定过程,以此迭代,直至找到最优解。子管理进程在进行收敛性分析时,若自身收敛,则同时向主管理进行非阻塞式发送以及向计算进程进行非阻塞式广播,通知它们退出;考虑同时收到主管理进程和计算进程的收敛信号或者只收到其中一个收敛信号的可能性,进行最优解比较和非阻塞式通信,通知对应的进程退出;若本进程未收敛,同时也未收到收敛信号,则回到参数率定过程,以此迭代,直至找到最优解。计算进程在进行收敛性分析时,若自身收敛,检查是否收到子管理的收敛信号,若收到,则比较最优解,否则直接向子管理进程进行发送结束信号;若本进程未收敛,同时也未收到收敛信号,则回到参数率定过程,以此迭代,直至找到最优解。
2.3 面向并行框架的非阻塞通信优化
本文并行框架中采用自定义的规约操作,调用MPI_Reduce( )函数接口对主管理进程和子管理进程中的最优解进行收集和比较,使得框架整体所有进程搜索得到的最优解能够被迅速规约并将当前全局最优解分享到每一个进程。该框架可与率定算法紧密结合,框架中计算进程可以映射成率定算法的搜索粒子点,框架中子通信域可以映射成率定算法的种群,可以与粒子群算法、遗传算法等无缝结合。本文程序中主管理进程采用的率定算法为遗传算法[21],子管理进程和计算进程采用的率定算法为粒子群算法[22]。结合该特性,本文在每个子通信域中的子管理进程和计算进程之间加入了非阻塞式通信,计算进程异步地发送当前最优值和对应参数组到子管理进程,同时异步的接收子管理进程发送过来的整个子通信域的最优值和对应参数组,子管理进程异步的循环接收来自计算进程的最优值和对应参数,比较后,将该子通信域的最优值和对应参数发送给计算进程。由于非阻塞式通信主要用于计算和通信的重叠,通信操作全部后台运行,从而提高整个程序的执行效率。
3 数值试验
将本文的框架应用在HIMS水文模型参数率定模块的数值实验中,实验主要采用拉萨河流域数据针对HIMS模型的12个参数进行参数率定。通过比较和分析数值实验结果,来探讨框架效率以及并行性能。测试计算环境为中国科学院计算机网络信息中心超级计算机“元”和国产先进计算系统。
3.1 参数寻优效果的验证
首先利用HIMS水文模型对拉萨河流域进行参数率定优化的计算结果分析该并行框架的寻优效果和率定算法的正确性,寻优效果将从以下四个方面分析。
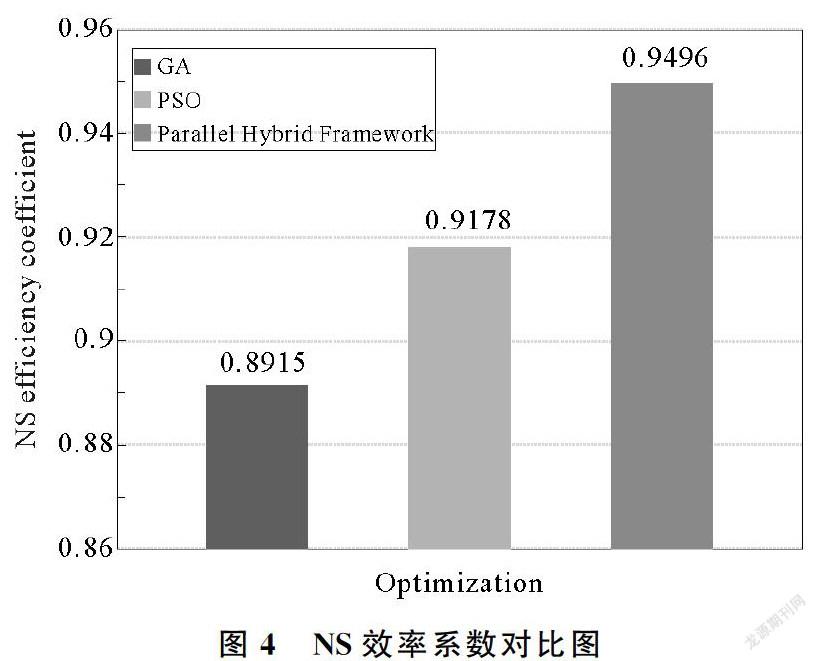
(1) 普通优化算法和并行混合算法框架的寻优效果对比。本次实验将HIMS水文模型中参数环境设置为粒子数20个,模拟500次,结果如图4所示。并行混合算法优化的NS效率系数在同样的迭代次数下大于其他单独的优化算法的计算结果,说明参数率定并行框架有相对突出的优化效果,达到了水文模型对流域进行参数率定优化的所需达到的基本要求。
(2) 主从模式和对等模式的寻优效果对比。在两种模式框架对比中,采用三种规模进行数值测试,分别为:小规模21核,粒子数200个;中规模201核,粒子数2 010个;大规模801核,粒子数8 010个。通过NS效率系数和运行时间对比两者的寻优效果,结果如图5所示。每种情况测试10次取均值。可以看出,在率定精确性方面,对等模式相对主从模式略占优势,对等模式比主从模式模拟的NS效率系数高0.01左右。但从计算效率来看,对等模式在大规模率定过程中的运行时间相对主从模式的运行时间要短很多,对等模式在大规模参数率定中发挥较好的效果。
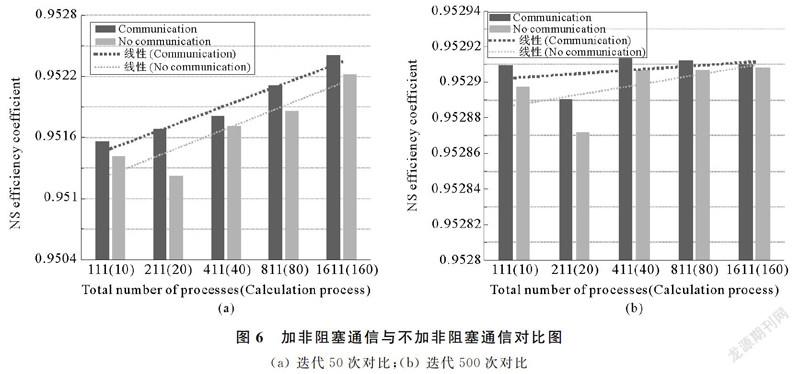
(3) 加非阻塞通信和不加非阻塞通信的寻优效果对比。对比加入非阻塞通信和不加入非阻塞通信的两种情况下的NS效率系数(图6),同时测试了迭代50次(图6(a))和迭代500次(图6(b))的情况。由图6(a)可知,在固定迭代50次后,加入非阻塞通信的NS效率系数比未加入非阻塞通信的NS效率系数高一些,同时随着进程数的增加,NS效率系数变高;由图6(b)可知,在固定迭代500次后,加入非阻塞通信的NS效率系数比未加入非阻塞通信的NS效率系数稍高一点,但总體上相差不大。以上分析说明在迭代次数较少的情况下,加入非阻塞通信的框架寻优效果较好,迭代次数增加后,两者之间差距缩小,说明加入非阻塞通信能够加快算法收敛,从而整体更快的贴近最优值。
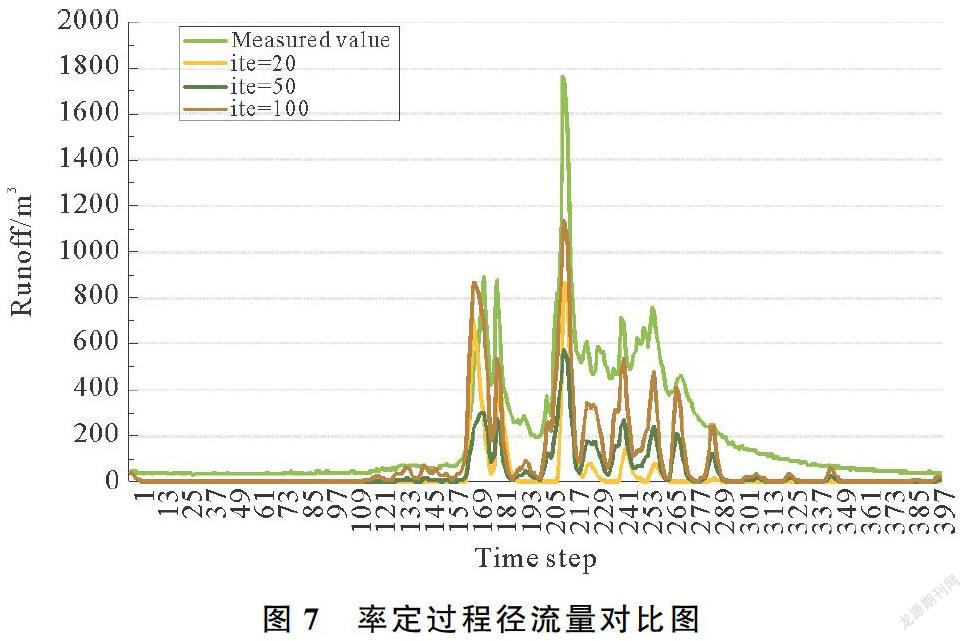
(4) 算法正确性验证。通过对比率定过程中的径流量和实测径流量来验证算法正确性,结果如图7所示。伴随着迭代次数的增加,水文模拟出来的径流量总体趋势上越来越贴近实际测量值,说明通过率定算法的参数集越来越靠近最优参数集,通过这组最优参数集水文模拟得到的径流量也会与实测值更加贴近吻合。
3.2 多级并行参数率定框架的扩展性测试
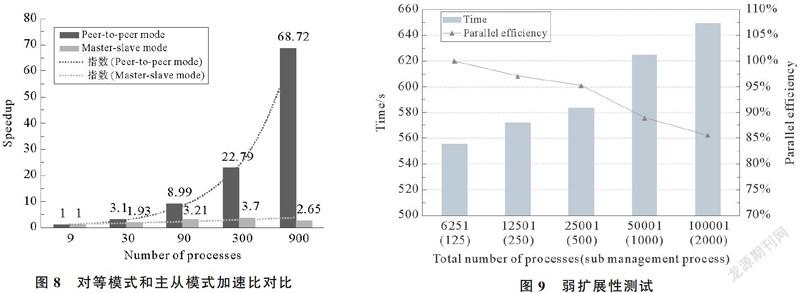
3.2.1 主从模式和对等模式可扩展性对比 针对主从模式框架和对等模式框架在强扩展性方面进行测试。模拟总粒子数为9 000粒子,随着进程的增加,每个进程中的粒子数减少。其中,由于主从框架的特性,在数据整理时,总进程中去除了前四个只进行优化算法的固定进程。两者对应的加速比对比如图8所示。可以看出,随着进程数的增加,对等模式框架的加速比呈指数上涨,呈现较好的扩展性,而主从模式框架的加速比在90个进程之后几乎没有变化,甚至在900进程处呈下降趋势。可见,对等模式框架在大规模率定中的扩展性远远好于主从框架。
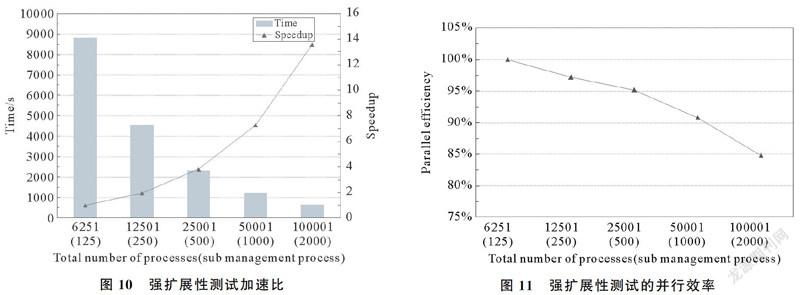
3.2.2 对等模式在大规模方面的扩展性测试 (1) 弱扩展性测试。在多级并行参数率定框架的并行弱扩展测试中,在保持每个进程所分到的计算量基本一致的情况下,通过增加进程数来测试程序的并行性能。测试以6 251核为基准,每种情况测试10次取均值,迭代次数为500次。所有算例均设置每个子通信域50个进程,每个进程1 600个粒子,保证每个进程分到的任务量基本一致。测试的运行时间和并行效率如图9所示。从测试结果可以看到,以6 251核为基准,到十万核时并行效率还保持在86%,整个框架始终运行在较高的效率之上,扩展性较好。
(2) 强扩展性测试。参数率定框架的强扩展测试实验中,在保证问题计算规模一定的情况下,测试程序随着核数增多而导致程序性能的变化情况。本文测试以6 251核为基准,将核数翻倍,总粒子数在1.6亿左右,迭代次数500次。测试的运行时间和加速比如图10所示,测试的并行效率如图11所示。可以看出,强扩展性测试具有较为理想的加速比与并行效率,在十万核之内保持85%的并行效率,说明划分平衡度较好,且非阻塞式通信使得通信与计算重叠,由于通信产生的核间等待很少。总体扩展性良好。
4 结论
本文采用了MPI中的非阻塞式通信实现了一个多级并行框架,同时将多种优化算法相结合,用于水文模型中的参数优化模块。分析HIMS模型的参数优化实验结果可知,此框架求出的NS效率系数有明显的提高,并较大幅度减少了运行时间。并行框架具有良好的可扩展性,在大规模水文模拟中有较好的发挥。下一步的工作主要是考虑并行框架在异构众核架构上的加速,同时探讨其他的优化算法与该并行框架的结合,使得在参数率定过程中进一步提高并行度。
参考文献
[1]ABBOTT M B, BATHURST J C, CUNGE J A, et al. An introduction to the European Hydrological System-Systeme Hydrologique Europeen, “SHE”, 1: History and philosophy of a physically-based, distributed modelling system[J]. Journal of Hydrology, 1986, 87(1): 45-59.
[2]LIU C M, WANG Z G, ZHENG H X, et al. Development of hydro-informatic modelling system and its application[J]. Science in China Series E: Technological Sciences, 2008, 51(4): 456-466
[3]ALAM Z, RAHMAN M, ISLAM A. Assessment of climate change impact on the Meghna River Basin using geomorphology based hydrological model (GBHM)[C]// 3rd International Conference on Water and Flood Management (ICWFM-2011). Dhaka, 2011.
[4]赵人俊, 王佩兰. 新安江模型参数的分析[J]. 水文, 1988(6): 2-9.
[5]雷晓辉, 廖卫红, 蒋云钟, 等. 分布式水文模型EasyDHM模型[J]. 水利信息化, 2010, (3): 31-37.
[6]WANG Q. The genetic algorithm and its application to calibrating conceptual rainfall-runoff models[J]. Water Resources Research, 1991, 27(9): 2467-2471.
[7]CHENG C, OU C, CHAU K. Combining a fuzzy optimal model with a genetic algorithm to solve multi-objective rainfall-runoff model calibration[J]. Journal of Hydrology, 2002, 268(1): 72-86
[8]馬海波, 董增川, 张文明, 等. SCE-UA算法在TOPMODEL参数优化中的应用[J]. 河海大学学报,2006, 34(4): 361-365.
[9]THIEMANN M, TROSSET M, GUPTA H, et al. Bayesian recursive parameter estimation for hydrologic models[J]. Water Resources Research, 2001, 37(10): 2521-2535.
[10] KOLLET S J, MAXWELL R M, WOODWARD C S, et al. Proof of concept of regional scale hydrologic simulations at hydrologic resolution utilizing massively parallel computer resources[J]. Water Resources Research, 2010, 46(4): W04201.1-W04201.7.
[11] YALEW S G, VAN GRIENSVEN A, KOKOSZKIEWICZ L. Parallel computing of a large scale spatially distributed model using the Soil and Water Assessment Tool (SWAT) [C]// 2010 International Congress on Environmental Modelling and Software Modelling for Environment′s Sake, Fifth Biennial Meeting. Ottawa, 2010:1182-1189.
[12] LI T J, WANG G Q, CHEN J, et al. Dynamic parallelization of hydrological model simulations[J]. Environmental Modelling & Software, 2011, 26(12): 1736-1746.
[13] HUO J Y, LIU L Q, ZHANG Y N. An improved multi-cores parallel artificial Bee colony optimization algorithm for parameters calibration of hydrological model[J]. Future Generation Computer Systems, 2018, 81: 492-504.
[14] 闞光远, 洪阳, 梁珂, 等. 基于GPU加速的水文模型参数率定[J]. 人民长江, 2019, 50(5): 65-69,75.
[15] 李强, 陆忠华, 王彦棡, 等. 基于克里金插值的SWAT参数率定大规模并行方法[J]. 计算机应用研究, 2016,33(1): 60-63.
[16] 李强, 陆忠华, 王彦棡, 等. 基于高性能计算的SWAT参数敏感度分析并行框架[J]. 计算机应用研究, 2015, 32(1): 41-44+70
[17] 申蒙蒙, 陆忠华, 王彦棡. 水文模拟中并行参数优化算法[J]. 计算机工程与设计, 2017, 38(4): 1002-1007.
[18] NASH J E, SUTCLIFFE J V. River flow forecasting through conceptual models part I—A discussion of principles[J]. Journal of Hydrology, 1970, 10(3): 282-290.
[19] GROPP W, LUSK E, DOSS N, et al. A high-performance, portable implementation of the MPI message passing interface standard[J]. Parallel Computing, 1996, 22(6): 789-828
[20] 王亚茹, 王鹏, 王德志. 基于MPI的多核并行模式的性能测试与分析[J]. 成都信息工程大学学报, 2018, 33(6): 617-623.
[21] MAN K F, TANG K S, KWONG S. Genetic algorithms: concepts and designs[M]. Berlin: Springer Science & Business Media, 2012.
[22] 王蓉, 刘遵仁, 高阳. 基于粒子群优化和邻域粗糙集的快速约简算法[J]. 青岛大学学报(自然科学版), 2017, 30(3):51-54.
