基于NLP技术后结构化处理的电子病历应用
2021-09-13程楠侯豪牛亚军唐浩杨旭张现辉
程楠,侯豪,牛亚军,唐浩,杨旭,张现辉
(1.河南省人民医院 网络信息中心,河南 郑州 450003;2.郑州市第一人民医院 信息科,河南 郑州 450004;3.郑州大学第三附属医院 信息科,河南 郑州 450052;4.郑州人民医院 信息科化建设和研发部,河南 郑州 450003;5.中牟县卫生健康委员会,河南 郑州 451400;6.河南省传染病医院 信息科,河南 郑州 450052)
《电子病历应用管理规范(试行)》指出:“电子病历是指医务人员在医疗活动过程中,使用信息系统生成的文字、符号、图表、图形、数字、影像等数字化信息,并能实现存储、管理、传输和重现的医疗记录,是病历的一种记录形式,包括门(急)诊病历和住院病历。”作为医院信息化建设核心的电子病历系统无疑是医院信息系统中最重要的数据采集和加工者。电子病历聚集了海量的医疗大数据,包括患者的个人信息、家族史和疾病诊疗信息等[1]。
数据的结构化存储是数据分析处理和利用的关键,但从临床角度来看,描述性语言是电子病历应用的首选方式。目前,结构化电子病历的采集方式病历文本中长期大量存在非结构化数据,如文本、图像、声音等,非结构化数据占比达85%以上[2],为计算机自动处理制造障碍。其次,各系统之间对数据编码和标准的使用不统一,数据录入有随意性,例如诊断编码、手术编码等的随意性,降低了数据的可信度、可操作性,影响了临床数据质量和信息的交换与共享。因此,对自然描述语言的结构化处理是电子病历深入发展的趋势。河南省人民医院在建设以电子病历为基础的医院信息集成平台过程中,将具有人工智能基因和梅奥(Mayo Clinic)知识内涵的临床决策支持系统(clinical decision support system,CDSS)与电子病历进行融合(见图1),利用基于深度学习算法的自然语言处理技术(natural language processing,NLP)在后台对自由输入或半结构化的病历文书进行关键单词界定、语意句意剖析解释、语言行为分析等智能化处理。本研究基于河南省人民医院电子病历数据,分析了基于深度学习技术的病历文本命名实体识别率情况。
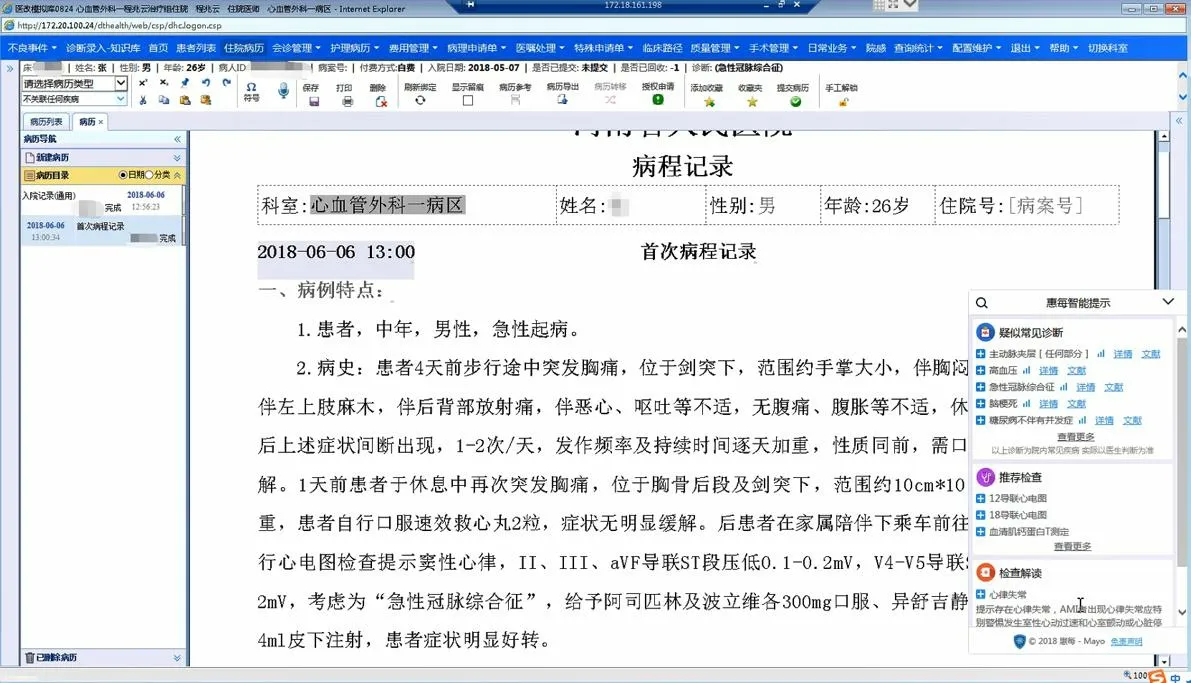
图1 人工智能系统无缝嵌入电子病历
1 对象与方法
1.1 对象选取为评测人工智能系统后结构化数据处理的效果,开展面向电子病历的命名实体识别实验评测,即对于给定的一组电子病历文档,任务目标是识别并抽取出与医学临床相关的实体,并将它们归到预先定义好的类别,比如临床表现、检查、药品等。以住院病历中的首程病历记录作为本次命名实体识别和抽取的主要评测对象。入院首程记录包含了患者入院后经诊治医生通过问诊、查体、辅助检查等获得的相关资料,具体内容包括一般项目、主诉、现病史、既往史、个人史、家族史、体格检查、辅助检查、诊断等,尤其是现病史是住院病历的重点内容,应着重于了解患者本次疾病的发生、演变、诊疗经过中蕴含的更丰富的医疗信息。结合数据源“首程记录”的内容及特点,预定义类别聚焦在临床表现、诊断、时间、疾病趋势、检查项、指标、指标值、药品8个类别。此次选取的语料不限科室,挑选河南省人民医院1 000份住院病历的“首程记录”作为评测病历,并按照预定义类别的8个不同类别,对每个子类进行分开评测。
1.2 观察指标本评测采用精确率、召回率以及F1值作为评测指标。根据严格评测指标,计算各项指标。召回率为基于人工智能的CDSS系统正确识别的类别总数占医生人工标注的类别总数的百分比。精确率为基于人工智能的CDSS系统正确识别的类别总数占系统总抽取信息条数的百分比。F1值为F是精确率和召回率的调和均值。
1.3 处理方法利用实体识别技术系统完成临床信息抽取服务(见图2)。NLP技术首先将病历文本中的自然语言智能分割为长短不同的句子,定义识别句子中的概念、逻辑词、关系(包括医学关系、词相互间的位置和间隔等)。利用NLP技术特征提取,病历内容自然语言被切分成结构化的概念、逻辑关系,聚合为不同类别的命名实体。
由此,电子病历文本中的描述性自然语言,经过人工智能系统智能处理后转化为易处理的结构化数据表达,且识别结果按照预定义的实体类别,以一种标准化的、机器可读的结构化方式存贮(见图3)。临床表现、诊断实体识别结果自动映射临床医学系统术语,临床医学系统术语以恰当的颗粒度形式,规范临床信息的概念,从语义层面约束临床知识表达,并实现临床信息代码化,可以协调一致地在不同的学科、专业和医疗机构之间实现对于临床数据的标引、检索和聚合,减少临床照护和科学研究工作中数据采集、编码及使用方式的变异。同时,诊断实体识别结果符合国际疾病分类标准ICD-10,使得疾病名称标准化、格式化,有利医疗管理,为临床和科研提供有价值的数据支撑。
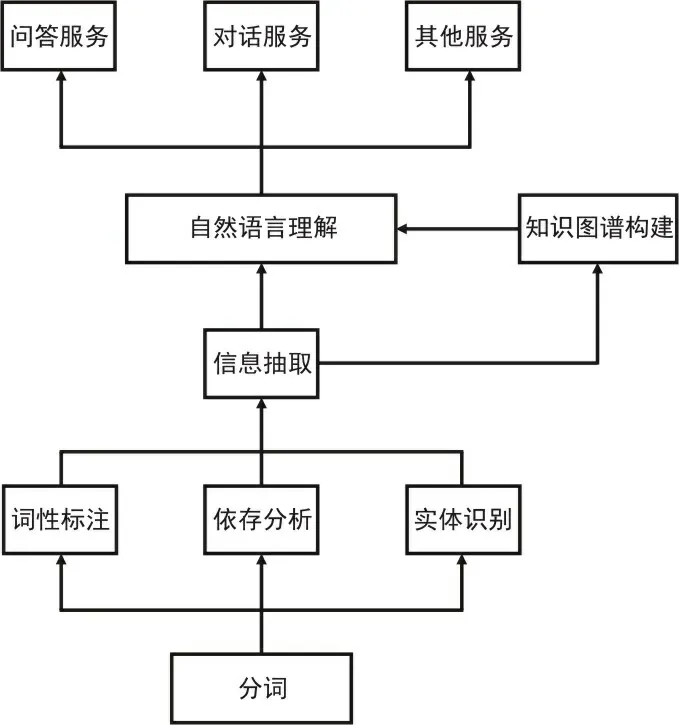
图2 自然语言处理逻辑图

图3 电子病历文本中的描述性自然语言处理过程
人工智能算法进行病历数据后结构化处理,一方面是遵循医疗原则,不影响临床医生自由书写病历,有利于患者信息录入的完整性。另一方面,人工智能系统支持诊断、检查等智能回填至电子病历,减轻了医生的文书压力。抽取后的结构化数据则通过机器的理解、处理和整合,可以极大降低获取数据的门槛,为信息检索和数据挖掘提供基础,并为医疗临床和管理决策提供支持。同时促进医院内部各系统之间、各医院之间的临床信息互联互通,将极大限度改善与解决我国医疗资源分配不均、信息孤岛等现象。
2 结果
基于深度学习算法的信息抽取,最终结果见表1。

表1 基于人工智能的CDSS病历文本识别结果
3 结论
医院的信息化建设要重视数据的标准化采集、储存,然后才能进行分析展示乃至决策支持。在当前大数据研究浪潮下,电子病历信息抽取和文本挖掘越来越吸引人们的目光,人工智能、自然语言处理等技术创新发展将有效提高大数据挖掘和分析能力,这些研究也将为临床智能支持、循证医学研究和疾病监控等提供支持,从而提高医疗服务质量。
本研究结果显示,人工智能系统中文病历文本命名实体识别效果最好的是药品。可能原因是电子病历中的药品信息多为术语表达,本身的专业性、规范性较高。临床表现是命名实体识别最为复杂和最难的,因为临床表现表达方式多样,不同医生有不同的习惯说法、简称、缩写等,书写通常不规范、不标准,识别起来较为困难。本次评测系统共抽取了15 390个临床表现,准确率为85.24%,召回率为84.88%,F1值为85.60%。相关研究中,龚凡等[3]基于CRF模型识别电子病历症状实体研究中,准确率为89.46%,召回率为81.70%,F值为85.40%。但该研究只针对患者首程记录的西医症状进行抽取,语言规模较小。叶枫等[4]采用条件随机模型对疾病、临床症状、手术操作3类中文病历中常见的命名实体进行智能识别,该研究是首次在中文电子病历中进行命名实体识别研究,其最佳F1值为95.06%。该研究同样存在对实体类型的定义不完整,语料规模较小且语料只包含了现病史和既往史等。
本次评测抽取了1 000份入院记录,并针对检查、临床表现、药品等8个实体类别进行分类抽取,预料规模较大,实验取得了较好的识别效果。基于深度学习的方法可以利用更多的特征,可以帮助临床进行更好的数据抽取服务。
电子病历文本的自然语言处理研究属于生物医学领域的研究,在生物医学领域的其他实体识别研究中,F值一般为70%~85%[5]。但对于中文电子病历识别研究,我们起步较晚,加之中文电子病历因有其独特的语言特性,如:医疗行业习惯用语大量出现,包含一些以数字和单位表示的检查结果和英文缩写词,句子语法结构不完整,模式化较强等,造成中文病历实体总体识别难度较大。
随着我国电子病历系统的广泛实施,中文电子病历数量急剧增长,中文电子病历实体和实体关系识别研究势在必行。鉴于此,我们应该根据中文电子病历文本明显的子语言特点,一是加强中文电子病历标注语料库的构建,二是逐步改善 “拷贝、粘贴”这种易导致数据质量低下的输入模式,提升电子病历智能层级,创造高效、高质的信息抽取环境,提高大数据利用价值。
