基于文档的对话研究
2021-09-13孙润鑫马龙轩张伟男
孙润鑫 马龙轩 张伟男 刘 挺
(哈尔滨工业大学社会计算与信息检索研究中心 哈尔滨 150001)
近年来,随着大数据的发展以及深度学习技术的兴起,对话系统这一研究领域已经取得了长足的进步.由于Seq2Seq(sequence-to-sequence)模型[1]的出现,许多模型采用了端到端的方式并基于大规模的人类对话语料进行训练,已经收到了一定的效果.然而,这些模型的问题在于其总是倾向于生成较为通用的回复[2],这也是目前该领域面临的一大挑战.
事实上,通过引入外部知识使得模型生成信息更加丰富的回复,正逐渐成为这一问题可能且可行的方法之一.并且到目前为止,已经出现了一些富有建设性的成果.Ghazvininejad等人[3]是对一组候选事实进行检索,然后将其结果与对话信息相结合.Zhang等人[4]借助说话人的个人资料,使得模型可以生成一致性更好且更吸引人的对话.而Mem2Seq[5]则通过引入外部知识库的方式,以提升回复内容的丰富度.但是,这些工作大多是将现有的事实类知识整合到对话系统中,而此类知识的构建过程费时费力,且具有较大的局限性,从而在一定程度上制约了大规模数据的使用,以及现有系统的应用和落地.
基于文档的对话是一项在讨论特定文档的内容时,生成较自然对话回复的任务.与以往基于知识的对话不同,该任务采用文档作为知识源,因此能够使用较为广泛的知识,且无需对其预先进行构建.并且其与基于文档的问答也有所不同,相较于后者此时不仅需要考虑对话与文档之间的关系,同时还应考虑对话内部的联系以对其充分理解.针对这一任务,我们应主要从3个方面进行考虑:1)理解对话中各句之间的关系;2)理解对话与文档之间的关系;3)根据对话上下文,从文档中筛选有关信息以生成相应回复.
在本文中,我们提出了一种新颖的基于Trans-former[6]的模型,用于更好地构建对话上下文,并利用其进行信息筛选从而生成更有意义的回复.主要思想是将信息筛选分为利用历史和忽略历史2种情况进行讨论:当忽略历史时,只需以当前对话为依据,对文档信息进行相应筛选;而当考虑历史时,应先利用其对上下文进行重新建模,然后以所得结果为依据,进行文档信息的筛选.注意到对话历史事实上并不总是与语境相关,因此在完成上述过程后我们需要对其与当前对话的相关程度进行度量,并以此为依据进行语义向量的整合,以避免引入不相关的信息作为噪声.实验结果表明,与现有的基线模型相比,我们的模型能生成语义更加连贯、知识更为丰富的回复.
本文的主要贡献可总结为3点:
1)提出了一种辩证看待对话历史的方法,用于文档信息的筛选以及上下文信息的构建.在编码过程中,以分支的方式同时进行利用历史和忽略历史的信息筛选,并根据当前语境判断各分支的重要程度.
2)提出了一种新的信息汇总的方式,通过判断当前对话与历史之间的相关程度,来对各分支所得到的信息进行整合,以得到在解码过程中所使用的语义向量.
3)在CMU-DoG数据集[7]上进行了模型的验证,并取得了当前已知的最好效果.同时借助消融实验,也显示出模型各个部分在语义向量建模过程中的有效性.
1 相关工作
目前,基于文档的对话已被证明在解决通用回复、改善回复质量方面能够取得不错的效果[7-9].就现有工作而言,我们可以将其大致分为2类:基于抽取的方法和基于生成的方法.
基于抽取的方法最初在机器阅读理解(machine reading comprehension,MRC)中被提出[10],其是在一篇给定的文档中抽取特定的片段,以回答所给问题的任务.Vinyals等人[11]提出了一种名为指针网络(pointer networks,Ptr-Nets)的结构,其使用注意力机制[12]从输入序列中选取元素作为输出.Seo等人[13]提出了BiDAF模型,其使用双向注意力流以获得问题感知的上下文表征.Wang等人[14]提出了R-Net模型,其使用一种自匹配注意力机制来对较长段落的表示进行完善.然而,这种方法实际上并不适合基于文档的对话.其原因主要有2点:1)在该任务中,事实上并没有一个明确的问题,这需要在充分理解对话内容的前提下,自行决定回复句的主题;2)由于方法本身的限制,只从原文中进行抽取使得对话的流利度难以得到保证[15].
至于基于生成的方法,目前绝大多数模型还是基于经典的Seq2Seq结构[1].Lian等人[16]利用后验知识来进一步指导知识的筛选过程.Liu等人[17]引入知识图谱作为又一知识源,从而与非结构化的文档相结合起到互为增强的效果.Li等人[18]提出了一种增量式Transformer编码器来对多轮对话及其相关文档进行联合建模,同时应用2阶段的推敲解码器以进一步增强对话的连贯性和信息的丰富性.
但是,之前的工作并没有深入研究对话历史与当前对话之间的关系.考虑真实的对话场景,由于对话过程中往往会出现主题的转换,且由于开放域对话的随意性,后续的主题并不一定总是与历史相关.在这种情况下,历史便成为了一种噪声,从而对知识的挑选以及后续对话的生成起到了负面作用.但当主题较为明晰、对话内容较为集中时,历史信息可以帮助我们更好地理解当前语境.由此便可生成内容更加丰富、语义更为连贯的回复.出于以上2点考虑,本文提出了一种辩证看待对话历史的方法,通过判断其与当前对话之间的相关程度,以更好地利用对话历史并避免引入不必要的噪声.
2 基于比较整合的Transformer模型
2.1 问题定义
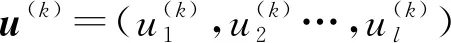
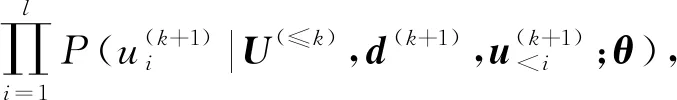
(1)
2.2 模型架构
模型基于经典的Transformer结构,各组成模块如图1所示.可以看出,其主要由3部分构成:
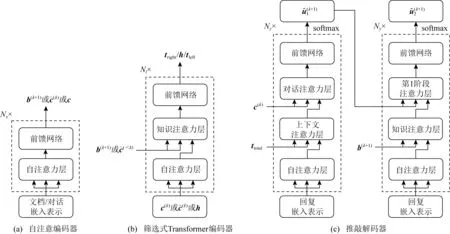
Fig.1 Composition modules of our model图1 本文模型的各构成模块
1)自注意编码器(self-attentive encoder,SA).SA是经典Transformer模型[6]中所使用的编码器,其负责将对话信息和文档信息分别预先进行编码.
2)筛选式Transformer编码器(selective transformer encoder,STE).STE是一种用于进行信息筛选的Transformer编码器,它通过注意力机制[6]对编码后的对话历史和文档信息分别进行筛选,以得到更为符合当前语境的向量表示,用于后续语义信息的构建.
3)推敲解码器(deliberation decoder,DD).DD是一个2阶段的Transformer解码器,用于生成语义更为连贯的回复[18].在第1阶段,其将经SA编码后的当前对话u(k)和整合后的语义向量作为输入,借助对话上下文来生成回复.而第2阶段则是将经SA编码后的前一阶段输出和相关文档d(k+1)作为输入,使用文档知识进一步完善回复.
接下来我们对模型中的各个环节进行详细介绍.
2.2.1 输入信息的编码
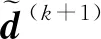
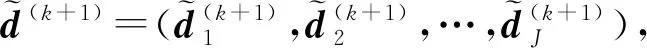
(2)
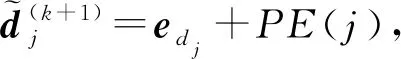
(3)

如图1(a)所示,自注意编码器由Nx个相同的层堆叠而成,每层都有2个子层.第1个子层是多头自注意力子层,而第2个子层则是简单的、位置完全连接的前馈网络(feed-forward network,FFN).同时每个子层也都采用了残差连接和标准化机制[6],因此子层的输出实际为LayerNorm(x+Sublayer(x)),其中Sublayer(x)是由子层本身所实现的功能,为了表述简洁这里故将其省略.下面给出该过程的公式表示:

(4)
D(1)=FFN(A(1)),
(5)
FFN(x)=max(0,xW1+b1)W2+b2,
(6)
其中,A(1)是经第1个自注意力子层计算出的隐层状态,而D(1)则是第1层最终得到的文档表示.对每层而言,重复这一过程,从而我们有:
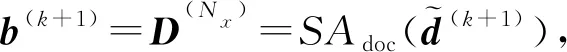
(7)
其中,b(k+1)是文档信息d(k+1)的最终表示,而SAdoc(·)表示上述编码的完整过程.
2.2.2 文档信息的筛选
为了借助注意力机制进行高效地信息筛选,我们使用了一种结构简单的筛选式Transformer编码器.由图1(b)可知,其与2.2.1节中叙述的结构最主要的区别就是增加了一个用于进行信息筛选的注意力子层.在这一子层,输入不再满足Q=K=V这一特征,而是令K=V且Q≠K,通过利用投影后Q与K之间的相似关系,来从V(也即是K)中进行信息的抽取.
出于辩证看待对话历史的考虑,在编码阶段,我们分利用历史和忽略历史2种情况讨论文档信息的筛选,整体结构如图2所示.先从忽略历史开始,容易想到,只需将编码后的当前对话c(k)作为下层输入,而将编码后的文档表示b(k+1)作为上层输入即可,公式表述为
tright=STEdoc(c(k),b(k+1),b(k+1)),
(8)
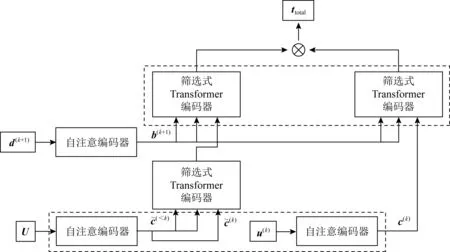
Fig.2 Overall architecture of the encoding part of our model图2 本文模型编码部分的整体架构
其中STEdoc是用于进行文档信息筛选的编码器.然后我们将tright,也即忽略历史进行信息筛选的输出作为右支最终的语义向量.

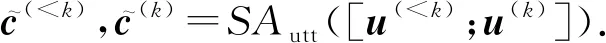
(9)
从而考虑对话历史的筛选过程可以表示为
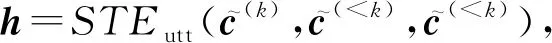
(10)
tleft=STEdoc(h,b(k+1),b(k+1)),
(11)
其中STEutt是用于进行对话信息筛选的编码器.同样地,我们将最终得到的结果作为左支也即借助历史的语义向量.
2.2.3 语义向量的整合
在得到了左右支的语义向量之后,一个关键的步骤便是如何将二者进行整合,以得到最终的语义表示.Sankar等人[19]指出,当前对话u(k)在回复生成的过程中起着决定性的作用.因此这里我们需要保留右支得到的信息,并根据对话历史与当前对话的相关程度,确定最终表示中是否包含左支信息及其所占的比重.
我们可以通过注意力机制[12]并结合最大池化(max pooling)的方式,来计算当前对话中的各词与对话历史之间的相关程度[20]:

(12)
α=sigmoid(maxcol(S)).
(13)
基于Zheng等人[21]所给出的形式进行左右支信息的整合:
ttotal=α⊙tleft+(1-α)⊙tright+tright,
(14)
此时ttotal即为最终用于进行回复生成的语义表示.
2.2.4 解码与回复生成
受现实世界中人类认知过程的启发,Li等人[18]设计了一种2阶段的推敲解码器,以提高知识的相关性和上下文的连贯性,这里我们同样使用这一结构.在第1阶段,其将编码后的当前对话c(k)和整合后的语义向量ttotal作为输入,以学习生成上下文连贯的回复.而第2阶段则是将编码后的前一阶段输出和相关文档b(k+1)作为输入,试图将文档知识进一步注入到生成回复中.
如图1(c)所示,推敲解码器由第1和第2阶段解码器构成.2个解码器具有相同的架构,但子层的输入不同.同样地,其也由Ny个相同的层堆叠而成,每层都有4个子层.这里仅以第1阶段为例,对相应流程进行详细说明.首先第1个子层同样是多头自注意力子层:

(15)
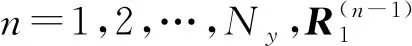

(16)
其中ttotal即为式(14)所得的整合后的语义表示.第3个子层是多头对话注意力层:
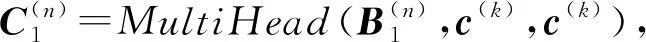
(17)
其中c(k)即为编码后的当前对话.值得一提的是,式(16)(17)分别将文档信息和对话信息融入到生成回复中,以求在生成信息更加丰富的回复时,不失其连贯性.第4个子层是全连接的前馈网络:
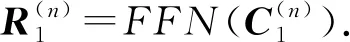
(18)
在Ny层之后,我们使用softmax函数获得第1阶段解码出的单词的概率分布:

(19)
2.3 优化目标
按照Li等人[18]所给出的方法,这里我们摒弃了原始推敲解码器所采用的较为复杂的训练算法,其是一种基于蒙特卡洛思想的联合学习框架[22].而是出于连贯性的考虑,选择对解码器的2个阶段分别计算损失,并采用加和的方式同时进行训练[23],其公式为
Lmle=Lmle1+Lmle2,
(20)

(21)
(22)
其中N是参与训练的样本总数,而I是参考回复的长度.
3 实验设置
3.1 数据集
我们使用基于文档的对话数据集(CMU-DoG)[7]来进行模型的评估.该数据集共包含基于120篇文档的4 112段对话,平均每段对话的轮数为21.43.文档内容取自维基百科中有关热门电影的文章,而对话内容不仅可以基于文档,也可以是随意闲聊的.需要注意的是,这里我们将同一个人的连续对话视为一整句,并忽略每段对话起始部分的问候语.每个样例包含一段与回复相关的、平均词数为200的文档,最近3句作为上下文的对话和1句参考回复.数据集的统计信息详见表1,更多细节请查阅文献[7],在此不再赘述.

Table 1 Statistics of CMU-DoG Dataset表1 CMU-DoG数据集的统计信息
3.2 基线模型
我们将所提出的模型与以下2类基线模型进行比较:基于RNN的模型和基于Transformer的模型.
1)基于RNN的模型
① S2S(Seq2Seq).S2S是一种经典的编码器-解码器模型[1].根据Zhou等人[7]给出的方法,这里我们将编码得到的文档知识,与上一时刻生成的词拼接起来作为解码器的输入,以向生成回复中添加文档信息.
② S2SIF(S2S with input feeding).S2SIF是一种Seq2Seq模型的变体[24].其是利用注意力机制来对编码结果进行动态汇总,并将其输入到下一时刻的解码过程.这里我们对编码得到的文档表示进行这一操作.
2)基于Transformer的模型
① T-MemNet(transformer memory network).T-MemNet是一种将Transformer与Memory Network相结合的模型[9].首先利用注意力机制对知识进行预筛选,然后将其与对话信息拼接后送入编码器中进行二次编码.在这里由于相关知识已经给定,故省去筛选步骤.
② ITE-DD.ITE-DD是一种使用增量式Trans-former编码器和2阶段推敲解码器的模型[18].增量式编码器使用多头注意力机制,将文档信息和对话上下文合并到每句对话的编码过程中.而推敲解码器采用2阶段的方式,分别利用对话上下文生成回复主干以及将文档知识进一步注入回复之中.
3.3 实验设置
我们使用OpenNMT-py[25]作为代码框架.对于所有模型,隐层规模均设置为300.对基于RNN的模型,按照文献[7]中的描述,我们使用2层的双向LSTM作为编码器,并使用1层单向的LSTM作为解码器.对基于Transformer的模型,编码器和解码器的层数均设置为3.多头注意力层中的注意力头数为6,过滤器(filter)的规模为1 200.我们使用预训练的词向量,即在Google News语料库上借助Word2Vec训练得到的300维词向量[26]对嵌入矩阵进行初始化.并且这一表示会被文档、对话和回复所共享.我们使用Adam优化器[27]来对模型进行优化.在解码阶段,集束规模(beam size)被设置为5.
3.4 评价指标
1)自动评价.我们使用BLEU,ROUGE-1,ROUGE-2,ROUGE-L作为生成回复的自动评价指标.Zheng等人[21]指出,由于文档中真正有意义的词往往出现频率较小,较低的困惑度(perplexity,PPL)反而会使得模型倾向于生成通用回复,因此这里我们没有使用这一指标.BLEU主要度量生成回复和参考回复之间的n元组(n-gram)重叠,而ROUGE则从召回角度来评测回复的语义完整度.
2)人工评价.我们随机选取了100个测试样例并邀请了4位评委,在给定之前3句对话和文档信息的条件下,从3个方面对回复质量进行评判:①连贯性(coherence),回复是否符合当前语境,语义逻辑是否连贯;②信息性(informativeness),回复是否包含有用信息,是否与所给文档相关而非通用回复;③自然性(naturalness),回复语义是否通顺,是否符合语法规定和人类表述习惯.所有指标均被划分为3个等级:0代表较差;1代表中等;2代表较好.
4 结果分析
4.1 实验结果
表2列出了所有模型在第3节设置下的自动评价和人工评价结果.

Table 2 Experimental Results of All Models on CMU-DoG Dataset表2 所有模型在CMU-DoG数据集上的实验结果
在自动评价方面,我们的模型(CITE-DD)在所有的指标上都优于基线模型.其中在BLEU指标上模型取得了约30%(即(1.31-1.01)/1.01≐30%)的性能提升,这也在一定程度上体现了其结果与参考回复具有更高的重合度,从而表明其能够生成更有意义的回复.不仅如此,模型在ROUGE指标上也有不小的进步,由此便可以看出其结果对参考回复具有更高的覆盖度,也即更为全面地表达了参考回复的内容.综合来看,模型相较于基线模型,能够生成质量更高的回复,其结构的有效性也得到了较为显著的体现.
而在人工评价方面,我们的模型同样表现不错.值得一提的是,模型在信息性这一指标上相较于基线模型有着较为显著的提升.从而可以反映出其能够更好地筛选和利用文档信息,而这也是基于文档的对话任务中的一大关键.另外对于连贯性和自然性而言,模型也显现出了一定的效果.不过在连贯性上,模型与ITE-DD相比区别不大,考虑主要是因为推敲解码器已经大幅提升了生成回复的连贯性,若要在此基础上取得新的进展,需要对其有针对性的改进,但本文的重点并不在于此.
4.2 消融实验
为了验证模型各部分的有效性,我们还设计并进行了消融实验,结果如表3所示:
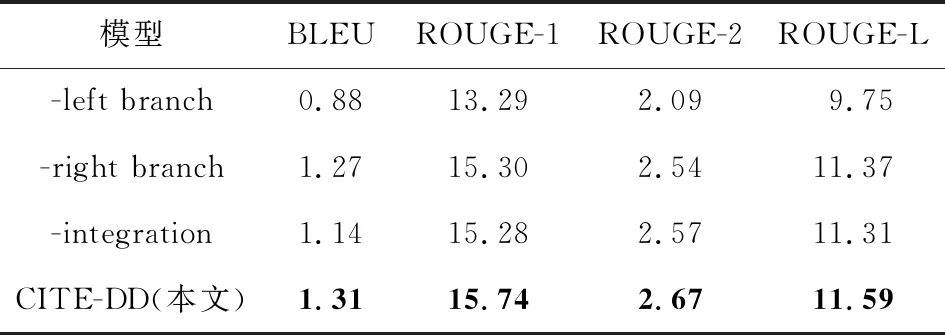
Table 3 Experimental Results of Ablation Study表3 消融实验的结果
在这里,-left branch表示将编码部分的左支(式(10)(11)),也即利用历史的部分去掉,此时模型便退化为基于文档的单轮对话.显然,完全忽略对话历史会对回复的生成有着极大的影响,这也较为明显地在表3指标中得以体现.考虑主要有2个原因:1)其包含了丰富的语义信息,利用其进行文档信息的筛选可以得到更多、更准确的结果;2)其亦可对更好地理解当前对话起到一定的帮助作用.当然上面2点都建立在历史信息与当前对话具有较强相关性的基础之上.而-right branch则表示将编码部分的右支,也即忽略历史的部分去掉,此时模型便仅能从利用历史的角度进行文档信息的筛选以及语义信息的建模.可以看出,回复生成的质量也受到了部分影响,这也在一定程度上说明了当历史信息与当前对话不相关时,忽略历史的方法使得模型避免了不必要噪声的引入,从而可以更为准确地理解当前对话和构建对话上下文.
另外,-integration表示将语义向量的整合部分去掉,这里采用直接加和的方式进行替换,此时模型便失去了辩证看待对话历史的能力.注意在这种情况下,模型的性能反倒比只用左支时要差,由此便进一步印证了本文所提方法的有效性与合理性.
4.3 权重可视化
如图3所示,这里我们将注意力矩阵进行可视化处理,并以此说明整合方式的合理性.在该例中,历史信息为“i did!she really delivered a knockout in mean girls.what was your favorite scene in mean girls?i personally like the scene where cady met the plastics.〈SEP〉 i love the revenge plot the best i think”,而当前对话为“oh yeah!the plan of revenge against regina?that was awesome!did you know that mean girls was partially based on a book?”.
根据图3中的结果,可以看出模型认为当前对话标出的部分与历史信息较为相关,而事实也同样如此.显然,2段文字具有高度的重合性,这时左支得到的信息才可视为右支对应位置的补充而非噪声.由此便可说明模型最终的效果与我们的预期相吻合,从而进一步印证了本文方法的有效性.

Fig.3 Visualization results of the attention matrix图3 注意力矩阵的可视化结果
4.4 样例分析
我们从测试集中选取了一个例子,以较为直观地说明所提模型的有效性,内容详如表4所示.可以看出,对话是一段典型的基于电影知识的闲聊:其没有明确的问题引出下句,当前对话与历史之间的关系也并不密切.在这种情况下,历史信息如果不加筛选反而会成为一种噪声,从而在一定程度上分散了回复句主题的确定.此时,已有的基线方法就不能很好地理解对话信息并从文档中提取出相关知识,从而倾向于生成通用回复.然而,我们的模型却可以很好地做到这一点,并利用文档信息生成了正确且自然的回复,使得当前对话可以顺利地延续下去.由此便可体现出辨证看待对话历史的重要性.
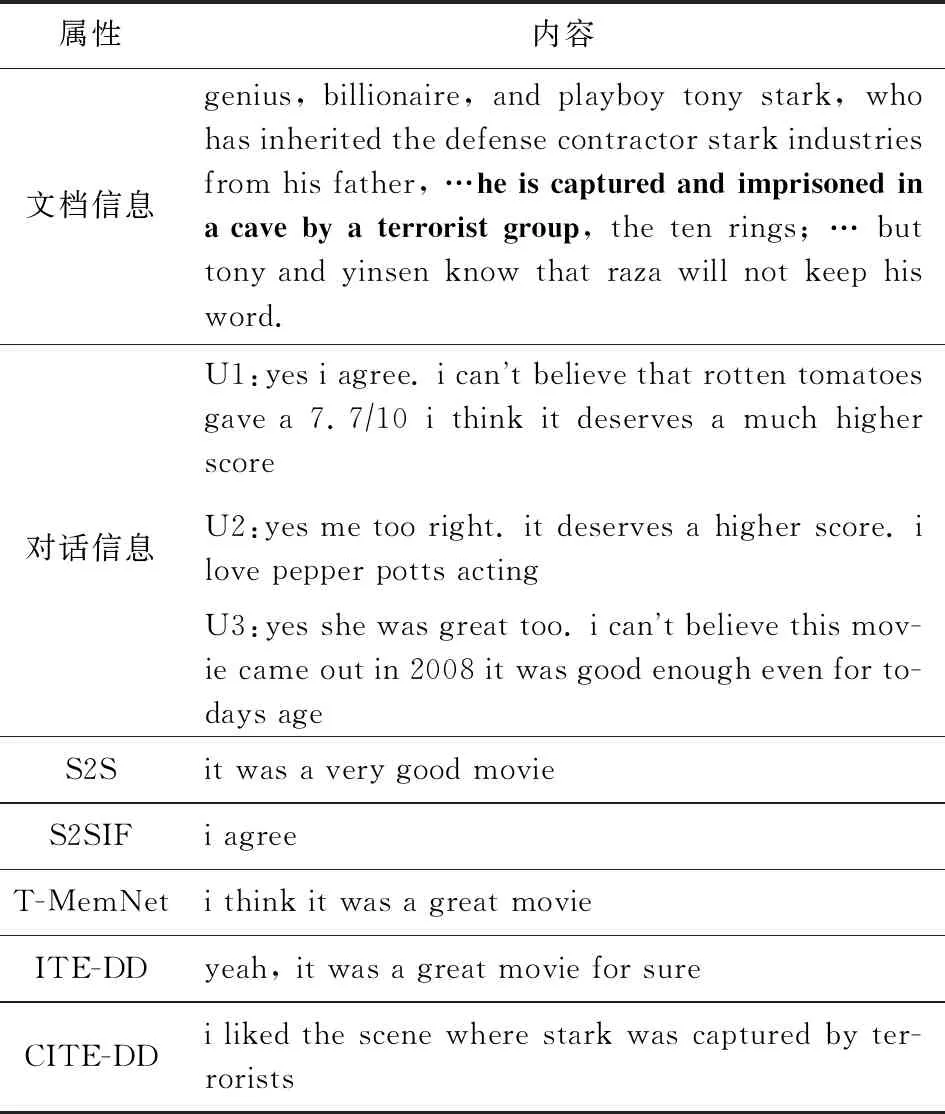
Table 4 A Sample in the Test Set and Responses Generated by Each Model表4 测试集中的样例及各模型的生成回复
5 总结与展望
本文提出了一种新颖的基于Transformer的模型,以辩证的观点来看待对话历史,同时充分发挥当前对话在上下文构建和信息筛选中的指导作用,以应用到基于文档的对话任务.模型分为利用历史和忽略历史2种情况进行文档信息的筛选,然后根据当前对话与历史之间的相关程度,来决定最终是否包含利用历史的信息及其所占的比重.在公开数据集上的实验结果表明,与现有的基线模型相比,其可以更好地理解对话中的主题转移,从而生成在相关性和信息性上质量更高的回复.
至于后续的研究方向,考虑到目前并没有一种较好的方式,能够在长文档上对相关知识进行更为准确和精细的抽取.因此考虑文档本身的结构信息,同时引入粒度的概念可能是一个有效的改进思路.
