基于胶囊网络的对抗判别域适应算法
2021-09-13盛立杰苗启广
戴 宏 盛立杰 苗启广
(西安电子科技大学计算机科学与技术学院 西安 710071) (西安市大数据与视觉智能关键技术重点实验室(西安电子科技大学) 西安 710071)
近年来,随着卷积神经网络(convolutional neural networks,CNNs)的出现和不断发展,许多分类问题已经以极高的精确度被解决.这些基于深度学习的算法模型在大规模数据集上进行训练时,被期望能够学习到一类事物在不同任务中的通用表示,即事物的表征不变性(invariance of representation).但在实际应用中,卷积神经网络受限于训练用的数据集尺寸和样本的丰富性,很难提取到足够多的信息以构建样本的表征,因此,这些经过训练的模型往往无法精确指出同一事物在不同表现形式下的含义.
典型的解决方案是在基于特定任务的数据集上进一步微调这些卷积神经网络模型.然而,要获得足够多的标记数据来适当地微调这些卷积神经网络模型,所需要的成本往往是非常昂贵的.例如,手动进行新数据集的标记和对海量权重参数的调整等,都会花费大量的时间.为了解决这个问题,作为迁移学习的子研究领域,域适应方法通过将基于源域训练的模型迁移到与目标域相近的公共表示区域,以期用最小的代价和基于有限的数据样本完成从源域到目标域乃至开放域的机器学习任务.在机器学习的发展过程中,这一概念经由Donahue等人[1]引入到深度学习领域,并在Yosinski等人[2]的工作中得到了进一步的发展.
对抗判别域适应(adversarial discriminative domain adaptation,ADDA)[3]算法是这类方法中最为经典的算法之一.这种算法巧妙地利用了生成对抗网络(generative adversarial network,GAN)[4]的思想,通过对域判别器的对抗性训练来最小化域间差异距离(domain discrepancy distance)[5-6],以完成模型的域间迁移.
除此之外,近年来对神经网络可解释性的研究表明[7-8],提升卷积神经网络的特征提取能力,也能有效提高卷积神经网络在分类问题中的性能.在此基础上,受到胶囊网络(capsule network,Caps-Net)[8-9]在捕获样本的表征不变性上具有较强能力的启发,本文通过将ADDA与胶囊网络进行结合,提出一种基于胶囊网络的对抗判别域适应算法.
另一方面,现有研究表明,通过大量堆叠胶囊层以期提升胶囊网络特征提取性能的做法,会导致中间层的学习性能变差[10-11].这是由于当网络中存在大量胶囊结构时,层间权重系数过小,抑制梯度的传递过程和学习速率,并造成模型参数量的几何级膨胀,易发生过拟合现象.本文将残差网络与胶囊网络相结合,使其能够用于构建更深的网络结构,并能结合胶囊网络的特性,成对地捕获浅层特征.残差结构将改善单纯叠加网络层数所导致的梯度消失问题,而更深的网络有利于进一步提取样本的特征.
在对特征提取网络进行强化后,本文在ADDA算法的固有缺陷上亦做出了改进.就像大多数GAN的变体一样,ADDA所采用的域判别器仅受标注样本的引导,很少探索数据分布的内在结构.这将会导致ADDA中作为生成器的卷积基为了“欺骗”域判别器而产生错误的梯度,朝着既定的模式更新权重,引发模式崩塌(mode collapse)[12-13]问题,不利于模型的训练稳定性和总体性能表现.ADDA算法正是基于此类对抗性学习算法构建的,因此也间接引入了此类缺陷.
在引入胶囊网络作为特征提取网络的同时,应当注意到,胶囊网络还可以作为自编码器进行使用.受VAE-GAN[14]的启发,它结合了变分自编码器(variational auto-encoder,VAE)和GAN,利用源域和目标域内有限的样本特征拟合边缘分布,并提供强约束,稳定对抗性训练的过程.因此,本文基于改进的胶囊网络提出了一种类无关的自编码器网络,将其与GAN结合,使用重构损失作为强正则化项,约束单域特征提取网络,使其尽可能地从目标域捕获到事物的表征,而不是一味地朝着容易欺骗域判别器的梯度方向演化.进一步的研究显示,这种新的“编码-解码器”结构有能力提供可靠的梯度参数,使得判别网络能够在卷积基进行偏移微调时,保证判别器对源域与目标域内样本共性表征的敏感度.
本文的主要贡献有3个方面:
1)提出胶囊层的卷积算法CapConv2d,用于构建深层胶囊网络,并将其与残差网络相结合.
2)基于CapConv2d和残差机制提出了一种新的胶囊网络架构Res-CapsNet,用以改进ADDA算法.
3)利用胶囊网络可调整为自编码器的特性,通过引入重建网络R作为解码器,使用重建损失Lr作为强约束,并据此给定了新的损失函数,进一步提升了ADDA算法的性能.
为了验证其有效性,设计了与ADDA相同的一组无监督域适应实验,本文的算法使用更少的训练样本取得了更好的效果.对比其他技术路线的域适应算法,在从MNIST[15]到USPS[16]的域适应任务中取得了最先进的性能,并在其他域适应任务中取得了与最新研究成果相近的性能.同时,相比于ADDA算法,本文所提出的算法在ADDA所提供的各项标准任务中均提升了7%~17%的性能;其中,在从SVHN[17]到MNIST的域适应任务提升最为明显,达到17.7%.
1 相关工作
当源域和目标域的数据分布不同但2个任务的目标相同时,这种特殊的迁移学习叫作域适应.对于基于单域训练的模型,域适应算法是一类常见的用于提升模型泛化能力的算法.
之前有大量关于域适应的工作,如ADDA等.而最近的研究工作主要集中在如何利用深层卷积神经网络学习一种特征转换,使得在转换过后的特征空间上,源域和目标域数据分布的区分度最小.换言之,这些研究工作将用于特征提取的CNNs从有标注的源域数据集迁移到标记数据较为稀疏或无标记的目标域数据集上,并使其以相近的性能正常工作.
在这些研究工作中,对抗判别域适应算法展示了对抗性学习填补双域差异的有效性.然而,基于该算法的研究工作往往存在2个缺陷.首先,当前CNNs的能力并不能很好地提取到样本特征、保证多域内特征图的表征不变性.其次,这些算法基于对抗性训练算法框架,仅在域判别器的“真”“假”标签下进行域混淆或域映射,模型难以训练,存在性能不稳定、模式崩塌等风险.
针对第1个问题,Xu等人[18]提出了一种基于域混淆的域自适应算法(DM-ADA),该算法能在较为连续的潜藏层空间中保证域的不变性,并指导域判别器计算源域和目标域的差异;Tang等人[19]在相同的技术路线上亦做出了贡献.基于此类技术路线的算法在像素级别和特征级别进行域的联合混淆,提高了模型的健壮性,在多个域适应任务中获得了较好的性能.
同时,为了提升神经网络的特征提取能力,有研究表明更深的神经网络能够提取到更多潜藏信息.在构建深层卷积神经网络的过程中,面临的主要问题之一是梯度消失.当梯度信号从底层反向传播到顶层时,将会逐渐衰减,从而影响网络的学习速率和收敛结果.针对这个问题,ResNet[20]和Highway Network[21]通过层与层间的short-cut操作,直接将上一层的信号传递到下一层,以缓解深度学习中梯度消失的问题.为了进一步提升卷积神经网络的特征提取能力和可解释性,Hinton等人[8]和Sabour等人[9]提出了胶囊网络的概念,旨在建立一种具有空间感知能力的神经网络模型.胶囊网络的每个单元都存储一个向量,而不是传统神经网络中的标量,用来指示该神经元在更高的空间维度上提取到的特征信息,如旋转、宽度、组合等样本实例属性.凭借这种构思,给定一幅图像,胶囊网络能在不同胶囊层间提取到多尺度的图像实例的组件成分,进而推导出实例的部分与整体的组成方式.
由于每个浅层胶囊向深层胶囊进行信息传播时不再是标量到标量的映射,而是向量到向量的映射,因此胶囊网络存在更多需要训练的权重参数,并需要设计适配于向量计算的梯度传播算法.此类梯度传播算法被定义为“路由算法”,如Dynamic Routing[8-9],EM-routing[22],COF(clustering-like objective function)[23],Variational-Bayes Capsule Routing[24].
在胶囊网络的基础架构上,最近的一些研究工作也对此做出了相关改进,如HitNet[25],DeepCaps[10],Sovnet[11],Stacked Capsule Autoencoders[26],Proposed CapsNet[27].其中,HitNet使用了一种与Dropout[28]相仿的思路,依靠动态连接选择胶囊层,缓解胶囊网络由于参数量较大而带来的过拟合问题;DeepCaps提出了一种3维路由算法,同时改进了胶囊层间的传播算法,使得构建深层胶囊网络成为可能;Sovnet则通过跳接的方式,给出了一种新的胶囊网络架构和路由机制,基于此构建了深层胶囊网络;Stacked Capsule Autoencoders和Proposed CapsNet则将胶囊网络推广到无监督学习和人体动作识别问题上.
2 基于对抗判别网络的域适应算法
2.1 对抗判别域适应算法
在域适应任务中,受限于各种条件,例如无法在目标域内采集到足量标注数据,因此在目标域直接进行高质量的有监督学习是不可能的.所以,域适应算法主要通过无监督或半监督的方式使得模型可以在目标域上间接训练或进行自适应.
对于域适应任务,描述如下:对于K分类任务,假设源域数据是经过标注的优良数据集Xs,其标签为Ys.源域数据集符合分布ps,同样地,目标域数据集符合分布pt但未知其标签Yt.现在,任务的目标是得到一个模型Mt,能够正确地从目标域数据中提取特征信息,并将提取到的特征作为输入,经由分类器Ct正确地将目标域内的图像数据Xt判别为K个类别中的一个.
由于缺失Yt,因此在目标域上直接进行有监督训练得到Mt和Ct是不可能的,只能间接地进行训练.一个常见的思路是,在(Xs,Ys)上训练得到源特征提取模型Ms和分类器Cs,通过算法将其映射到Mt和Ct,然后使用Mt和Ct在目标域数据集Xt上进行域适应训练.域适应是迁移学习中的一种特例,其最大的特点是Cs和Ct有着相同的K个分类目标,且目标在ps及pt具有分布相关性.但这2种分布存在着一定的距离,即域间近似差异距离,如图1所示.显然,在这样的任务前提下,只要通过调整Ms和Mt缩小域间距离,得到双域的边缘分布,就可以消除另行训练目标域分类器Ct的需求,即在Ms≈Mt的情况下,对于域适应任务满足Cs≈Ct.这种思路巧妙地转化了任务目标,把对Ct的有监督训练转化为求Ms到Mt的映射方案.
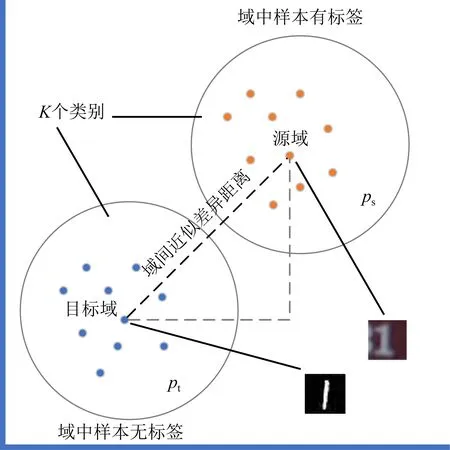
Fig.1 The illustration of domain discrepancy distance图1 域间近似差异距离示意图
ADDA是这类方法中的一种经典实现,该算法架构引入了一个域判别器D,用于鉴别一个特征提取模型M所提取的特征来自ps还是pt.ADDA试图通过对域判别器D的对抗性训练来最小化域间距离,当域判别器D无法分辨特征提取模型M所提取的特征来自ps还是pt时,就意味着Ms与Mt已经尽可能地靠近,ADDA的算法流程如图2所示.
该算法与GAN相似:GAN将2个子网络分别作为生成器G和判别器D相互竞争,在博弈中轮流、逐步提升2个网络的性能.不同的是,ADDA中没有生成器G,取而代之的是一个特征提取网络M,它被训练成一种能够按照一定规则,从服从某种分布p的数据中提取样本特征的网络,而域判别器D则试图分辨特征提取网络M从何种分布中提取样本特征.在对抗性域适应训练的过程中,当判别器损失LadvD保持不变,即判别器D的权重被冻结时,特征提取网络的损失LadvM满足:
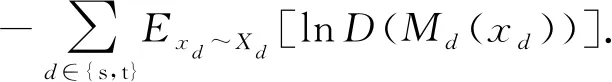
(1)
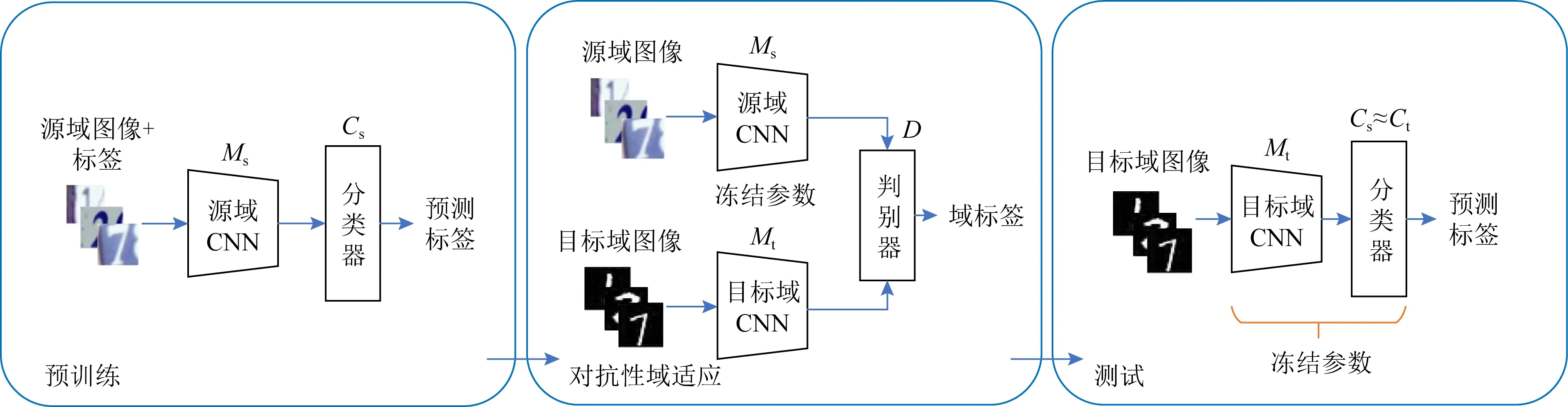
Fig.2 Overview of ADDA algorithm图2 ADDA算法流程图
对抗性训练中,最小化LadvM的同时也即最大化域判别器的损失LadvD,二者满足:
LadvM=-LadvD,
(2)
这非常类似GAN的极大值目标.然而,这样的优化目标容易导致域判别器在早期过快收敛.这是因为,在域适应中,需要对源域和目标域使用独立的特征映射,并且需要同时更新Ms和Mt的权重.而在GAN中,一个生成网络G试图模拟一个不变的分布,而不是如同域适应一样在2种真实存在的分布中寻找边缘分布.如果采用上述损失函数,当Ms和Mt都在变化时,将会发生剧烈的振荡.
为了解决这个问题,Tzeng等人[1,3]提出了域混淆的优化目标,在该目标下,对均匀分布的双域图像数据使用交叉熵损失函数进行训练:
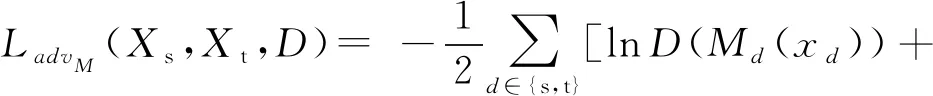
(3)
该损失函数确保了域判别器能以较为稳定的状态对域特征提取器进行偏移.
2.2 利用重建损失约束域间距离
ADDA算法虽然巧妙地利用对抗学习的方法避免了直接在源域数据集Xs上训练目标域特征提取模型Mt和目标域分类器Ct,但却因为使用了对抗性学习而引入了与GAN相同的缺陷.“模式崩塌”是此类缺陷中对ADDA算法影响最大的一种.当训练任务的目标是希望一组M应该能够尽可能地捕获到有用的特征,即经过训练的模型Ms或Mt应尽可能地靠近,以使得域判别器D难以区分二者.但考虑另一种情况,在交替进行对抗性学习的过程中,如果一个M开始向只能捕获到噪音的模式Mn倾斜,由于域判别器D只能给出“0”(源域)或“1”(目标域)的二值评价,那么接下来所有的M都会因为域判别器D的指导作用快速向Mn靠近;当模型收敛时,尽管此刻域判别器D无法准确分辨一组M,但并不意味着此次训练取得了预期的效果.
模式崩塌大部分时候是以一种随机的方式触发的,这通常使得GAN架构非常难以训练.特别是当模式崩塌只在部分参数中发生时,通常很难区分这组M有多少参数没有正确地训练,从而造成误判,间接影响到模型的实际性能.
本文借鉴了VAE-GAN的思想,通过融入一个自编码器来缓解模式崩塌问题,如图3所示:
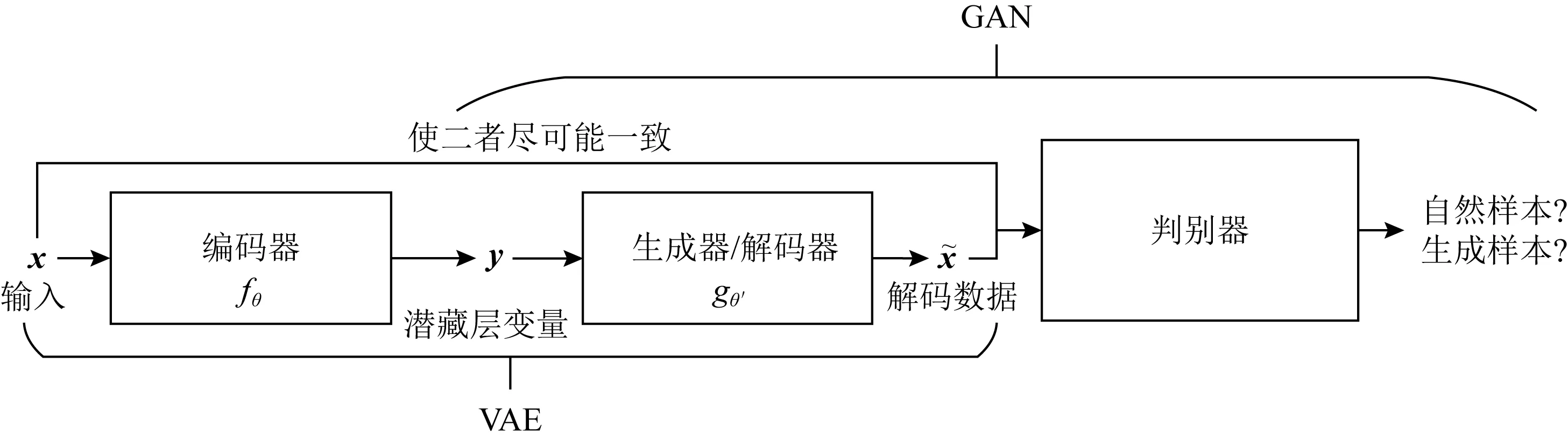
Fig.3 Overview of VAE-GAN图3 VAE-GAN架构图
编码器E在服从某种分布的样本域X中取样时,输入一个d维向量x,编码器E通过非线性函数y=fθ(x)=s(Wx+b)将其映射为一个d′维的潜藏层变量y.其中,参数项θ={W,b},W是一个d′×d的矩阵,b是偏置项,s为激活函数.
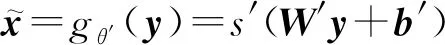
在训练这个自编码器的时候,对n个训练样本中的每项,最小化平均重建误差:
(4)
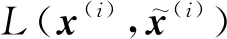

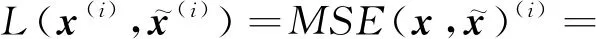
(5)
在进行训练时,域判别器D将会对从2个域特征提取网络得到的特征向量打分,给出“0”(源域)或“1”(目标域)的二值标签.此时,通过接入一个重建网络R作为解码器E,则判别距离为
DDA=1[D(Ms(Xs))=1]+
1[D(Mt(Xt))=0]+
α1×Exs~XsMSE(R(Ms(Xs)),Xs)+
α2×Ext~XtMSE(R(Mt(Xt)),Xt)
.
(6)
相比于直接使用二值标签作为判别距离,式(6)更能动态约束域特征提取网络,促使权重进行小幅度的稳定更新,保证潜藏层变量始终处于稳定的状态.本文中,对于胶囊网络而言,它的胶囊层在此处起到了编码器的作用,运作在无监督学习之下;而保证潜藏层变量的稳定,即可保证分类器的性能恒定.换言之,当Mt向着边缘分布移动时,使用重建网络的损失作为正则约束,将会更加平滑地进行权重更新;分类器C的性能得益于此,将始终以一个很高的指标,保持着直接在源域上进行有监督学习所能达到的分类效果.有关胶囊网络的内容将在第3节进行介绍.
2.3 使用重建网络改进的ADDA算法
首先,给定一个域适应任务T,在源域Xs和目标域Xt上具有相同的K个目标.需要说明的是,对于域适应问题,之前的研究工作都只在2个相似的空间中进行域适应,如CoGAN[29]和PixelGAN[30],这是因为,Xs和Xt应具有适当的域间距离,而不是非常相似或非常不同的2个域,这是域适应问题与广义迁移学习的主要区别.
本文所用算法的工作流程分为3个阶段:预训练阶段、对抗训练阶段和测试阶段,如图4~7所示.

Fig.4 Pre-train a source encoder CNN and reconstruction-network using labeled source image examples图4 使用源域标记样本充分训练作为编码器的CNN和重建网络
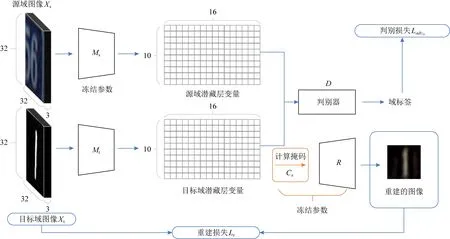
Fig.5 Training target encoder by adversarial domain adaptation图5 采用对抗性域适应训练目标域编码器
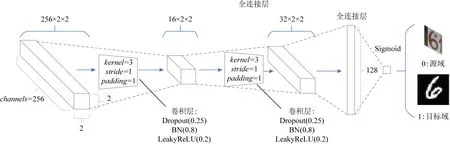
Fig.6 Overview of discriminator图6 判别器网络结构图

Fig.7 The illustration of testing图7 测试阶段的流程图
在第1阶段,使用来自源域的标注样本数据(Xs,Ys)预训练一个源域特征提取网络Ms和分类器Cs.在这个阶段,重建网络R也将被一同训练,如图4所示.其中,重建网络将使用均方误差作为损失函数:
Lr(Xs,Ms)=Exs~XsMSE(R(Ms(Xs)),Xs).
(7)
对于基于域混淆的域适应任务,显然满足Cs=C.在该阶段,对于分类任务,所使用的损失函数为
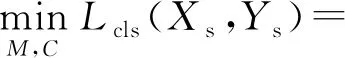
(8)
为了稳定网络和使得网络训练过程更加可控,添加一个超参数αs作为重建损失Lr的正则化权重.需要注意的是,由于目标域广泛缺乏可利用的标注数据,因此,如果在第1阶段没有进行合适的预训练,进行权值共享的目标域模型Mt将可能很快在对抗性学习过程中偏移到Mn,从而影响后续阶段的训练效果.
在第2阶段,如图5所示.先用Ms的权重初始化目标域特征提取网络Mt.将Ms的权重与Mt进行共享的好处是,一个域判别器D在初始时就不能很好地辨别经由特征提取网络M编码的图像特征输入是来自哪个数据分布域,避免在对抗学习初期过强的D所引发的训练不均衡问题.
在对Ms和Mt进行权值共享之后,将在多轮的对抗性学习过程中修正Mt的参数权重.Ms和Mt分别在源域Xs和目标域Xt提取特征,然后由域判别器D分辨这些编码后的特征来自哪个域,进而给出“0”“1”的标签,分别指示这些编码信息来自源域或目标域.本文所使用的判别器D是一个简单的CNN,其结构如图6所示.
图6所示的域判别器网络的结构参考了DCGAN[31]的设置,使用了批归一化层(batch norma-lization,BN).输入在经过2层卷积和Dropout+BN+LeakyReLU的组合层之后,最终使用一个尺寸为32×2×2的密集连接层输出二值标签.对于域判别器D,采用均匀分布的映射情况下的交叉熵损失函数进行训练:
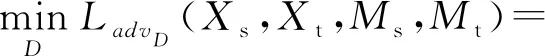
(9)
在该阶段,重建网络(解码器)R不再进行权重调整.目标域的重建损失Lr(Xt,Mt)为
Lr(Xt,Mt)=Ext~XtMSE(R(Mt(Xt)),Xt).
(10)
基于域判别器D给出的损失LadvM为
LadvM(Xs,Xt,Mt,D)=
-Ext~Xt[lnD(Mt(xt))].
(11)
Mt将根据式(12)的损失函数进行权重更新.由于初始化时采用了参数共享的原因,Mt会逐步向域间的边缘分布移动.C和R的参数在此阶段将被冻结,不再调整.
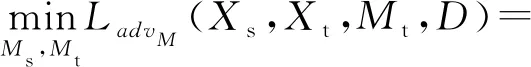
(12)
此外,为了训练过程更加平稳,在更新Ms的权重时添加一个权重衰减系数β,采用Adam[32]对该系数进行动态调整.这是因为:若使用预训练的Ms初始化Mt,初期采用一样的步长对Ms进行调整,容易让2个域特征提取网络提前趋同,导致其收敛于局部最优点.
在经过多轮对抗性训练后,就得到了一个非对称的特征映射Mt.这个映射将和Ms无法被区分,但拥有独立的权重,能够基于目标域和源域的边缘分布提取特征,并使这些特征可以被基于源域训练的分类器C所接受.
在第3阶段,即最后的阶段,使用模型Mt和分类器C进行分类性能测试,如图7所示.具体做法为:在目标域Xt上使用目标域特征提取网络Mt捕获特征,即将目标域内的样本数据Xt映射到共享的特征空间,并用预训练阶段得到的源域分类器Cs(等价于C)进行分类.为了检测实验效果,目标域的样本标签Yt仅在此时用于评估模型性能.
3 以深层胶囊网络为骨干网络
3.1 张量化的残差胶囊网络卷积层
在域适应任务中,数据集在源域与目标域内的识别任务目标是有着不同表示的同一事物.卷积神经网络如果能更好地捕获到目标对象的表征,那么,在域适应过程中就能更好地在目标域中正确识别目标.要想更好地捕获样本的表征,一个重要的途经是让神经网络能够理解事物的表征不变性(invari-ance)和同变性(equivariance).在广义上讲,不变性是指事物的表示形式不随变换而变化;而同变性是指事物的表示形式变换前后相等价.大部分现有的CNNs架构受限于2维的卷积架构和池化操作,在提取图像特征时无法很好地兼顾以上二者.为此,胶囊网络从神经科学中借用了一些想法,即认为人类的大脑被组织成叫作“胶囊”的模块,每个胶囊都是一个实例化模块,用于保存一个实体的一般属性,如尺寸、大小、颜色、边际轮廓等.
相较于CNNs中2维的特征图,在胶囊网络中,每个胶囊都包含由“胶囊向量”组成的张量,张量的每个维度都表示一种基本特征,即一个胶囊表示若干种基本特征的高维组合特征.在胶囊层间,使用路由算法逐层传递信息;在胶囊层内,每个胶囊通过1组绑定的2维卷积核来共享权重.胶囊网络的结构如图8所示.
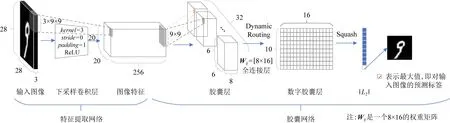
Fig.8 Overview of CapsNet图8 胶囊网络架构图
结合现有研究成果[10],构建更深的胶囊网络用于ADDA算法的特征提取网络,将会是改进ADDA算法的重要途径.
但是,在有关胶囊网络的诸多研究工作中,最近的研究表明[10-11],将全连接的胶囊层堆叠在一起,会导致中间层的性能降低较差并使得训练代价在一些数据集上几乎不可负担.
Hinton等人[8]所提出的标准形式的胶囊网络的主要缺点是,它只能以全连接的形式进行堆叠连接.因此,如果用这样的做法构建深层网络,相当于在MLP(multi-layer perception)模型中堆叠全连接层.大量的实验表明此类做法在模型性能的提升上作用甚微,且容易导致模型过拟合及收敛缓慢.考虑到ADDA算法并不需要一种非常强大的胶囊化深层特征分类器,本文使用一种近似于传统CNNs的特征提取网络,依靠胶囊层对该网络进行约束,使得其能够提取到域适应任务中所需的样本特征用以构建表征不变性信息.
基于这种思路,图9展示了本文所提出的CapConv2d的实现方案.对于k层的胶囊输入,为了维持特征图的尺寸,使用一组等通道的3×3卷积核进行stride=2,padding=1的卷积运算,卷积核采用LSUV[33]进行初始化.卷积结果按通道分别进行加和运算,得到k+1层的胶囊.
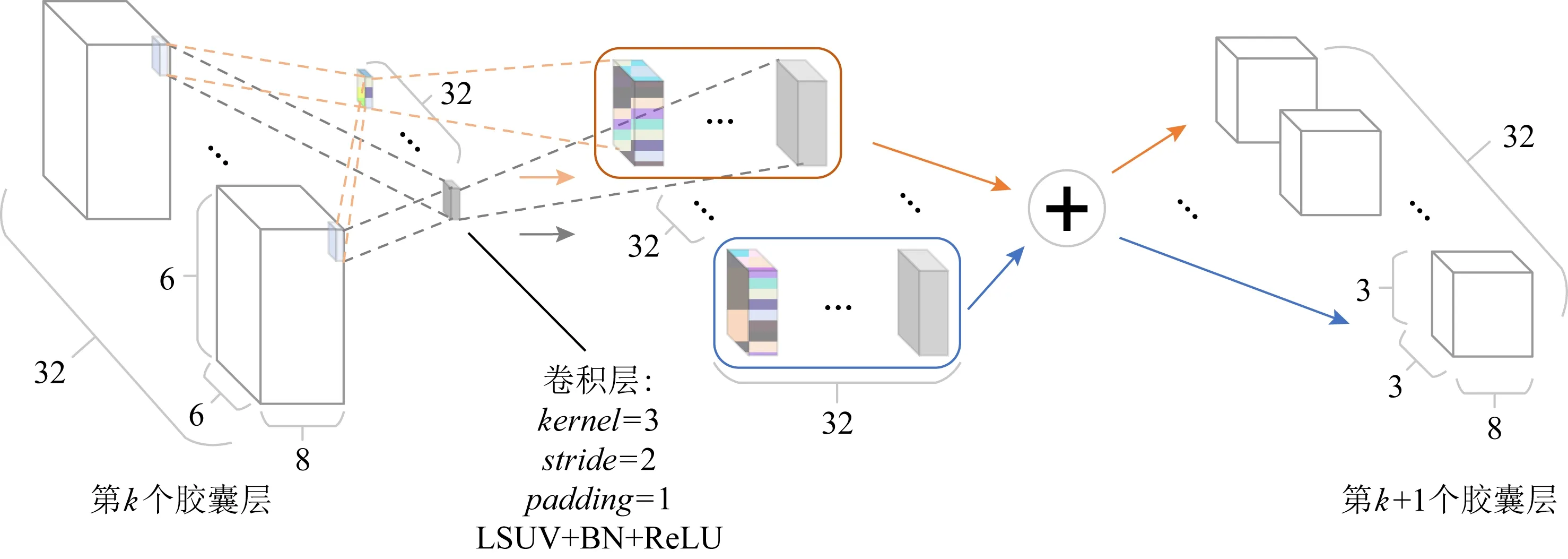
Fig.9 Pipeline of CapConv2d图9 CapConv2d的流程图
构建深层胶囊网络用于提取样本特征的另一个致命缺陷是梯度消失问题.当网络过深时,梯度会逐渐消失,进而影响模型的收敛.已有大量研究针对这个问题进行了实验[20-21,34],其中,ResNet和Highway Networks通过跳接各个层的信号,使得梯度能够保持传递的趋势.受到其启发,本文将采用胶囊机制构建骨干网络,并将其与残差结构相结合,调整胶囊网络中的卷积基.图10展示了ResCapConv2d的结构.
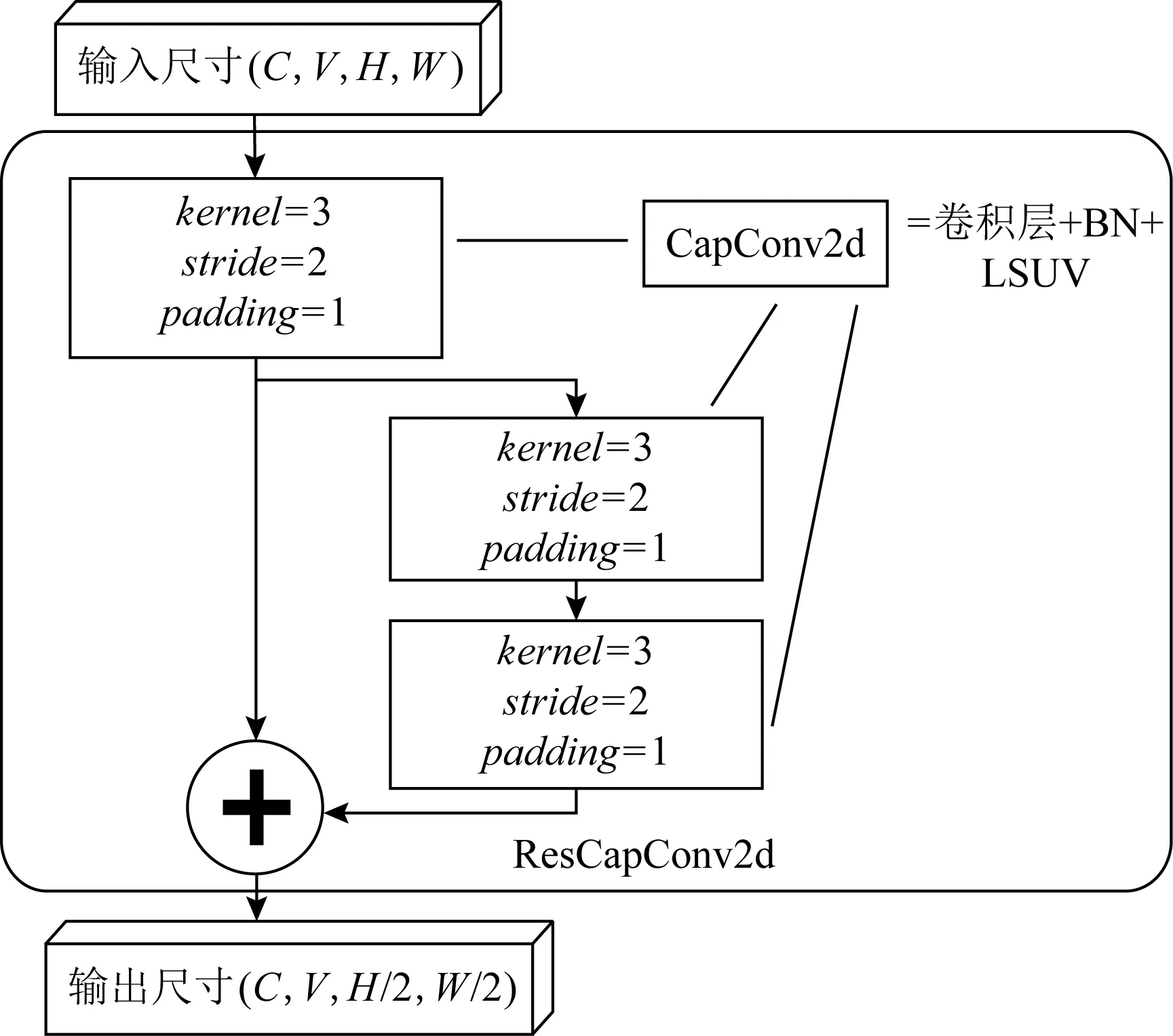
Fig.10 Overview of ResCapConv2d图10 残差块结构图
在该结构中,输入一个尺寸为(C,V,H,W)的胶囊特征,先经过一次卷积核为3×3,stride=2,padding=1的CapConv2d操作,下采样到(C,V,H/2,W/2),然后与2轮等尺寸输出的CapConv2d运算的结果进行加和输出.
基于CapConv2d和ResCapConv2d,将能够以类似搭建CNN的方式构建深层胶囊网络.由此,通过堆叠ResCapConv2d构成胶囊层(primary capsules layer),本文得到了一种新的胶囊网络结构Res-CapsNet,如图11所示.
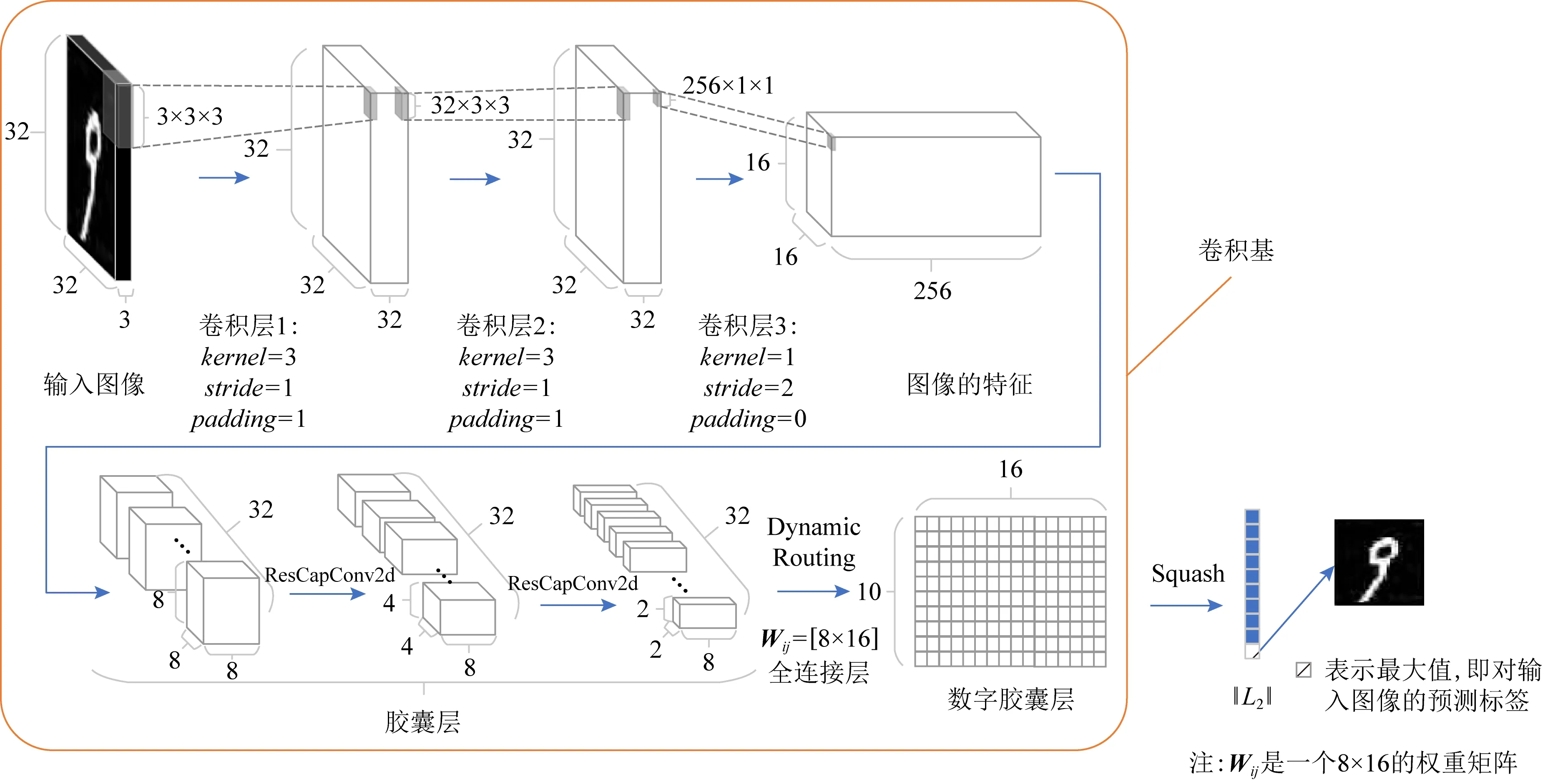
Fig.11 Overview of Res-CapsNet图11 Res-CapsNet的网络结构
该网络结构在保证胶囊网络使用向量表示样本特征的同时,改进了其作为编码器时的卷积基结构,使得其有能力构建更深的胶囊神经网络.
对比Hinton的胶囊网络,Res-CapsNet首先改进了其仅有1层卷积的特征提取网络.Res-CapsNet通过bottle-neck[35]的形式,先进行了2次3×3的卷积,将3通道的图像输入转为32通道的特征图,然后通过1×1的卷积进行下采样,将特征图的尺寸降到16×16、将特征图的通道提升到256.通过这种方式提升特征图的通道数有助于捕获到更多的样本特征,并保证整个网络的待训练参数相对较少.
接着,将256×16×16的特征图进行胶囊化编码,并利用ResCapConv2d进行下采样,转为32个8×8×8的胶囊(capsules),再经过2次ResCapConv2d,最终得到32个8×2×2的胶囊,随后进行层间路由,以一种近似全连接的方式(即Dynamic Routing)映射到10×16的空间.本模型的参数量为655 360,相比于Hinton模型的1 474 560,参数量减少了55%.
在10分类的手写数字识别问题中,Dynamic Routing算法将胶囊特征映射到10×16的空间,即每个类对应1个16维的特征.Hinton使用非线性映射(即Squash)将其压缩成1个10维的向量,取L2范式的最大值作为最终的预测值标签.
3.2 胶囊层间的路由算法
在标准形式的胶囊网络中,对于MNIST的识别问题,Hinton等人用1个16维的向量来表示1个手写数字在潜藏层空间的高维特征vj.由于vj又可以被用来表示1个浅层特征属性组合,因此可以被看作是1个特殊的编码器输出值,可以利用解码器R进行图像的重建.
在胶囊i到胶囊j的前向传播过程中,使用Squash来将前1个胶囊的输入ui映射到[0,1]向量空间:
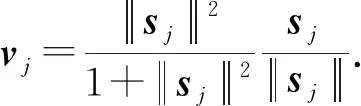
(13)
在第l层的所有胶囊向量ui到l+1层的胶囊连接中,vj为第j个胶囊的输出,sj是前一层所有胶囊向量输入的加权和,满足:
(14)
其中,Wij是一个可训练的权重矩阵,通过梯度的逆向传播进行训练.cij为一个加权系数,通过Softmax函数进行计算:
(15)
其中,bij是一个历史先验概率,给出了胶囊i到胶囊j的可能性,bij和cij在路由过程中进行动态调整,不参与梯度的逆向传播过程.胶囊间的连接采用Dynamic Routing算法,见算法1.对第k个类的特征属性组合vk,使用L2范式来描述输入样本x是第k个类的可能性.在计算分类误差Lk时,采用边缘损失(margin loss):
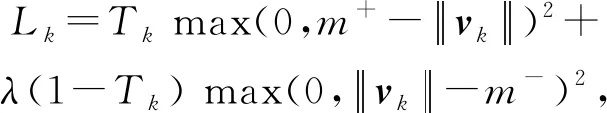
(16)
其中,在10分类的手写数字识别问题中,m+=0.9,m-=0.1,λ=0.5,vk为第k个数字胶囊(digit capsules)的输出.当且仅当输入样本x属于第k个类时Tk=1,否则Tk=0.
值得说明的是,在胶囊网络中,路由算法是可模组化的.因此,在整体架构一定的情况下,可以较为方便地更换其他更好的路由算法,而这将可能极大地提升整个网络的分类性能[8-9,22-24,26].但本文的研究重点不在于提出一种新的路由算法或验证何种路由算法更加有效.因此,为了和Hinton首次提出的胶囊网络作比较,在本文中依旧采用与其相同的路由算法,即Dynamic Routing算法.在不更换路由算法和使用数据增广的情况下,该架构相较于Hinton的方案,使用了45%的待训练参数的同时取得了更好或近似的成绩.
算法1.Dynamic Routing算法.
输出:l+1层第j个胶囊的胶囊向量vj.
① 初始化所有历史先验概率bij=0;
② forr∈{1,2,…,rs} do
③ fori∈{1,2,…,ql} do
④ci=softmax(bi);
⑤ end for
⑥ forj∈{1,2,…,ql+1} do
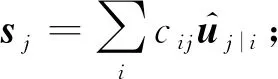
⑧vj=Squash(sj);
⑨ end for
⑩ fori∈{1,2,…,ql} do
3.3 自动编码器架构
从胶囊网络意图构建实例化参数向量的角度出发,可以把一个胶囊网络视为一个编码器.在本文的实验中,使用了与Hinton等人相同的参数设置,即使用一个16维的向量来表示一个手写字符.类似地,这些实例化参数将分别或共同定义手写字符的某个属性,如笔画粗细、曲度和长度等.在本文所设计的实验中,要识别的对象为10个手写阿拉伯数字,因此将构建10个数字胶囊,每个数字胶囊拥有16个实例化参数.给定一个解码器,将通过这些实例化参数重建图像.重建损失将作为正则项参与整个网络的训练,约束数字胶囊层能够捕获到最能代表一个手写数字各项表征的参数组合和权重.
为了给此类模型在手写数据集上寻得合适的重构损失函数,Jayasundara等人[36]研究了不同的重构损失函数对图像重构质量的影响.为验证所提出的架构的有效性,本文采用Hinton论文中所使用的最小均方误差作为重构损失函数.
在Res-CapsNet架构的编码过程中,使用卷积基作为特征提取网络M,M(X)是图像经过特征提取后的特征张量.数字胶囊层将作为编码器,使用Dynamic Routing算法将特征张量映射为一个10×16维的张量,每个16维的向量将作为一个独立的胶囊向量,共有10个胶囊与10个手写数字实例一一对应.
本文所采用的重建网络R参考了DCGAN,由4层转置卷积层构成,如图12所示.

Fig.12 Overview of reconstruction network which using masked capsule vectors图12 基于胶囊向量输入的重建网络R的结构图
首先,10×16的特征张量会经过一个掩码层,按照正确的标签进行掩码计算[8],筛选得到一个16维的向量y;掩码计算指使用样本标签或L2值最大的标签,从10个向量中选取表示当前类的16维向量.选中的向量输入一个使用线性整流函数(rectified linear unit,ReLU)激活的8×8×16的密集连接层,再使用BN进行归一化后得到一个1 024维的向量.该1 024维的向量即为潜藏层变量,经过4层转置卷积层,最终输出为一个3×32×32的张量,完成图像的重建.
3.4 将深层胶囊网络与ADDA相结合
图11中,框选标注的卷积基将被作为特征提取网络M使用,数字胶囊层将被用作分类器C,其输出将被输入重建网络R,完成图像的重建工作.判别器网络D和重建网络R的架构分别如图6和图12所示.C中数字胶囊层的传播过程参见算法1.结合式(16),式(8)所示的分类损失函数为
(17)
结合第2节内容,本文所提出的“基于胶囊网络的对抗判别域适应算法”如算法2所示.
算法2.基于胶囊网络的对抗判别域适应算法.

① 使用LSUV初始化Ms和Cs的权重;
② for(Xs,Ys)中的批样本xs,ysdo
③ 根据式(7)计算源域重建损失Lr;
④ 根据式(17)计算分类任务的损失Lcls;
⑤ 基于损失Lcls更新Ms,Cs,R的权重;
⑥ end for
⑦ 将Ms和Cs的权重复制到Mt和Ct;
⑧ 使用LSUV初始化D的权重;
⑨ 冻结R,Ms,Cs,Ct的权重;
⑩ for(Xs,Xt)中的批样本xs,xtdo

4 实验结果
4.1 MNIST,USPS,SVHN数据集
为了验证本文所提出算法的有效性,在MNIST,USPS,SVHN这3个标准数字手写数据集上进行了实验.图13显示了来自这3个数据集的示例图像.

Fig.13 Overview of digits-datasets图13 3个数据集概览
MNIST由60 000个训练样本和10 000个测试样本构成,每个样本是单通道28×28的灰度图,包含手写数字0~9的图像,共计10个类别.USPS由10 000个训练样本和1 000个测试样本构成,每个样本是单通道16×16的灰度图,共计10个类别.SVHN由73 257个训练样本和26 032个测试样本构成,每个样本是3通道32×32的彩色图像,共计10个类别.以上3个数据集在10个类别上都有均衡的样本分布,也具有相同的10个分类目标,但数据集间存在尺寸差异、数据分布差异,是研究无监督域适应任务的标准实验数据集.
本文在域适应任务的相关实验中,所有在目标域上的训练都是在无监督的情况下进行的,目标域的样本标签仅在测试时被使用.在数据集采样上,遵从ADDA设置,从MNIST中随机抽取2 000张图片,从USPS中随机抽取1 800张图片;而不同于ADDA的实验设置的是,在进行SVHN→MNIST域适应实验时,仅使用了30%~50%的MNIST数据用于域适应时的无监督学习,而ADDA则使用了MNIST全集.
为了使数据更加规整,将MNIST,USPS,SVHN的所有图像尺寸都调整为32×32;对于单通道的MNIST和USPS,仅将灰度图通过复制的方式增广到3通道,而没有进行其他图像处理.在读取数据集时,不同于其他研究工作中所设置的实验参数[3,18]的是,本文所做的所有实验中均没有使用任何数据增强方法.
首先,为了验证本文所提出的Res-CapsNet的有效性,直接在MNIST,USPS,SVHN数据集上进行了有监督分类任务测试,并与几种使用Dynamic Routing算法的胶囊网络结构进行了性能比对,实验结果如表1所示.接着,仿照ADDA中的实验设置,进行了3个方向的域适应任务实验:MNIST→USPS,USPS→MNIST,SVHN→MNIST,并与其他几种最新的域适应算法进行了比对,结果如表2所示.

Table 1 The Results on Classification Accuracy表1 分类准确率对比
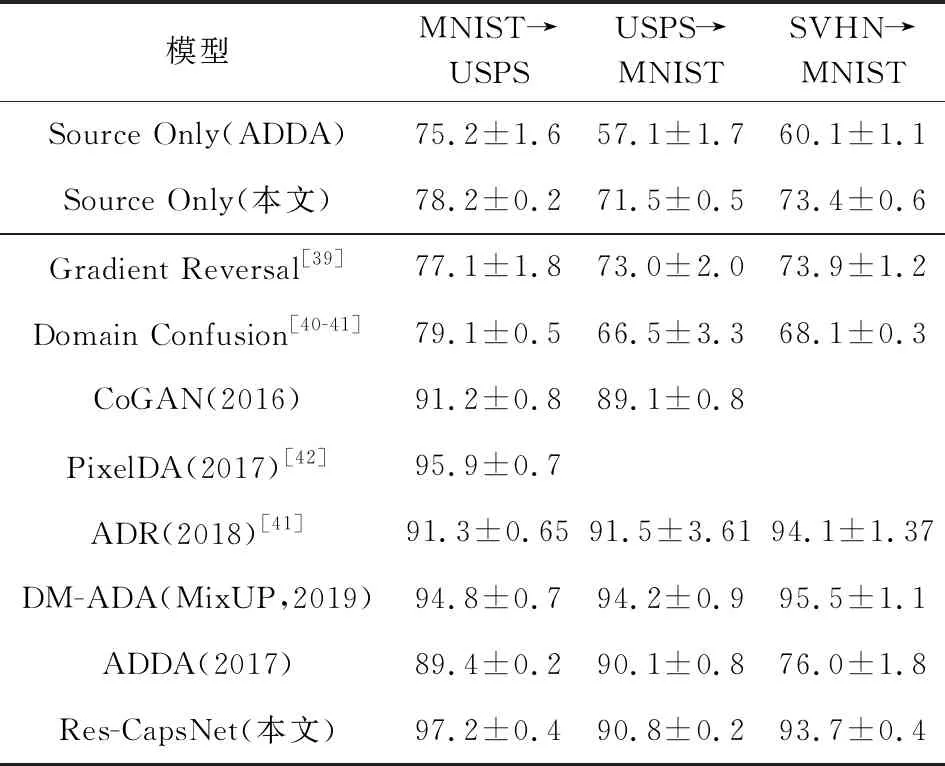
Table 2 The Results on Classification Accuracy in Domain Adaptation Tasks表2 域适应方法的分类准确率对比 %
4.2 Res-CapsNet网络的分类性能
首先,为了测试Res-CapsNet的性能,将其与2种流行的CNN和几种胶囊网络进行了比较.表1展示了模型在各个测试数据集上的分类正确率.
受限于网络深度,在CIFAR-10数据集上,几种胶囊网络的性能都仍不及具有更高深度的ResNet-56等.但尽管如此,CapsNet在MNIST手写数据集和SVHN上仍可以取得近似的性能表现.
表1中,在进行数据增强和集成了7组CapsNet(baseline)之后得到的结果被记为CapsNet(DA).
由表1可知,在不进行数据增强和集成学习的情况下,尽管本文所提出的Res-CapsNet的分类正确率略低于或与最先进的胶囊网络相关研究成果持平,但Res-CapsNet的网络结构相较于同样基于Dynamic Routing算法的baseline胶囊网络,能够支撑尺寸更大的数据集且便于扩展.需要注意的是,在不经过数据增强和fine-tune的前提下,本文所提出的Res-CapsNet胶囊网络模型几乎可以取得SOTA(state-of-the-art),但本文的研究重点不在于获取能够直接达到目前最优性能的分类器.
在兼顾分类器性能的同时,还需要考虑将其作为自编码器的架构稳定性和易扩展性.例如,HitNet通过添加Hit-or-Miss层的做法提升了胶囊网络的性能,于同等条件下,在MNIST数据集的分类任务上达到了与Res-CapsNet相近的水平,但却破坏了层间绑定权重的特性,使得其在进行域迁移时无法保证独立同分布,最终会受到域判别器的影响,大幅度调整Ms的参数权值,以一定的概率随机向Mn塌缩,并在一定轮次后导致网络无法捕获到任何目标域内样本的特征.换言之,该网络如同CoGAN一样,在一些特殊的复杂情况下无法绑定双域的特征捕获网络M,只能独立朝着某个随机方向发生变化,而不是使二者趋近.
4.3 域适应任务性能
本文在域适应实验中采取了与表2内大多数算法相近似的实验设计.
首先,仅在源域上训练Ms和Cs并直接将其在目标域上进行测试.ADDA算法中所使用的卷积网络是1个标准的LeNet,属于传统CNNs,而本文的方案采用的是基于Res-CapsNet的卷积基.“Source Only”表示模型仅在源域上进行充分训练而未在目标域上进行域适应训练,但直接被用在目标域上进行分类测试所得到的结果.通过对比ADDA和本文的方法,由表2可知,对于MNIST→USPS域适应任务,提升了约3.0%;对于USPS→MNIST域适应任务,提升了约14.4%;对于SVHN→MNIST域适应任务,提升了约13.3%,进一步验证了本文关于胶囊网络能更好地捕获样本表征的猜想.
接着,对于域适应任务,先在源域上训练Ms和Cs,然后基于本文所提出的Res-CapsNet与重建网络相结合的算法架构,通过对抗性学习得到Mt.相较于作为基线(baseline)的ADDA算法中相同实验设置下的分类正确率指标,对于MNIST→USPS域适应任务,提升了7.8%;对于USPS→MNIST域适应任务,提升了0.7%;对于SVHN→MNIST域适应任务,提升了17.7%.
最后,需要注意的是,在特征更为复杂的SVHN→MNIST域适应任务中,本文所用方法仅使用了30%的目标域数据用于无监督训练,便取得了更好的成绩,且远超ADDA的性能;另外,该任务中,域适应前后,相较于Source Only(ADDA)到ADDA的提升,本文算法所训练的域适应模型的分类正确率提升了20.3%,而ADDA算法仅提升了15.9%.在SVHN→MNIST域适应任务上的大幅提升,表明本文所提出的算法具有推广到复杂情况的潜力.其他方面,在MNIST→USPS的域适应任务中,对比最新的相关研究成果[18],本文所提出的算法取得了SOTA.
除此之外,本文还和其他几种最新的相关研究成果进行了比对,本文所提出的算法在使用更少的参数量的情况下,取得了超过或与它们相近的成绩.尽管在USPS→MNIST和SVHN→MNIST任务中,本文没有取得SOTA,但是,包括ADDA在内,其他相关研究工作普遍使用了更复杂的网络结构或采用了数据增强等其他技术手段,并在此基础上取得了当前的性能表现.相比之下,本文的研究工作主要着力于改进ADDA的2个缺陷——特征提取能力和模式崩塌问题,而不是组合、使用其他技巧来取得新的SOTA.因此,虽然没有在所有标准任务中达到SOTA,但抛开其他网络训练技巧,本文的工作依旧取得了较好的成果,更具有说服性和启发性的意义.
5 总结与展望
针对数据分布不同但任务相同的域适应任务,本文通过对抗性学习得到一种特征转换方案,使得在转换过后的特征空间上源域和目标域分布的区分度达到最小,以此绕过在标签稀疏或缺失的目标域上无法进行有监督学习的障碍,并利用源域的标注数据提高模型整体的训练质量,提升模型在目标域上进行无监督迁移学习的性能表现.
简而言之,从ADDA的固有缺陷着手,受到了胶囊网络的启发,本文对胶囊网络的架构进行了一定改进,提出了Res-CapsNet架构并与ADDA算法相结合,极大地提升了ADDA算法的性能表现.为了使得基于对抗性学习方案的ADDA算法更加稳定、有效地最小化域间距离,本文融入VAE-GAN的思想,将Res-CapsNet调整为自编码器混入网络中.最后,在多个复杂程度不同的域适应任务中,通过实验验证了本文所提算法的有效性.
今后的研究工作及展望是尝试探究胶囊网络所使用的路由算法对性能的影响,以期提高算法的整体稳定度和样本特征提取性能.
