图像描述生成研究进展
2021-09-13李志欣魏海洋张灿龙马慧芳史忠植
李志欣 魏海洋 张灿龙 马慧芳 史忠植
1(广西多源信息挖掘与安全重点实验室(广西师范大学) 广西桂林 541004) 2(西北师范大学计算机科学与工程学院 兰州 730070) 3(中国科学院智能信息处理重点实验室(中国科学院计算技术研究所) 北京 100190)
随着互联网与信息技术的发展,多媒体数据呈现爆炸性增长的趋势,从各种信息源(如网络、新闻、相机等)上可获得的图像数据越来越多.由于图像数据具有海量特性和非结构化特性,如何快速有效地组织、存储和检索图像,成为重要的研究课题,而完备的图像语义理解则是其中的关键问题[1].尽管从信息源上获取的大多数图像并没有对应的语义描述,但人类仍然能够在很大程度上理解它们.也就是说,人类很容易就能完成涉及复杂视觉识别以及场景理解的各种任务、涉及自然语言交流的各种任务以及2种模态之间的转换任务.例如,只需快速浏览图像就足以让人指出并描述关于视觉场景的大量细节,而这对于机器来说目前仍然是难以完成的任务.为了实现图像数据的结构化和半结构化,从语义上更完备地理解图像数据,从而进一步研究更符合人类感知的视觉智能,迫切需要机器能够为给定图像自动地生成自然语言描述.
计算机视觉研究如何理解图像和视频,而自然语言处理研究如何分析和生成文本.尽管这2个领域的研究都采用类似的人工智能和机器学习方法,但在很长一段时间里它们都是各自发展而很少交叉.近几年,结合视觉和语言的跨模态问题受到了广泛关注.事实上,许多日常生活中的任务都具有这种跨模态的特性.例如,看报纸时解释图片的上下文信息,听报告时为理解讲话而搭配图表,网页上提供大量结合视觉信息和自然语言的数据(带标签的照片、新闻里的图片视频、具有多模态性质的社交媒体)等.为完成结合视觉和语言的任务并充分利用多模态数据,计算机视觉和自然语言处理2个领域的联系越来越紧密.
在这个新的视觉和语言交叉的研究领域中,图像描述生成是个重要的任务,该任务包括获取图像信息、分析其视觉内容、生成文本描述以说明图像中的显著物体和行为等步骤[2-5].图1给出了4个根据图像内容生成描述语句的实例.

Fig.1 Examples of image captioning图1 图像描述生成实例
从计算机视觉的角度来看,图像描述生成是个重大的挑战,因为描述可能涉及图像的各个方面——可能是关于图像中的物体及其属性,也可能是关于场景的特性或者是场景中人和物体的交互行为.而更具挑战性的是,描述还可能指出图像中没有的物体(如等待中的火车)或提供不能直接从图像推出的背景知识(如画作中的蒙娜丽莎).总之,好的图像描述不仅需要有完备的图像理解,还需要综合而精炼的表达,因而图像描述生成任务对于计算机视觉系统是个良好的测试.传统的视觉任务(如物体检测[6]或图像自动标注[7])都是在有限个类别上测试检测器或分类器的精确率.相比之下,图像描述生成任务更具综合性.另一方面,从自然语言处理的角度来看,该任务是个自然语言生成的问题,需要将1个非语言的表示转换成1个可读的文本.一般来说,非语言表示是1个逻辑形式、1个数据库查询或是1串数字,而图像输入通常转换为1个中间表示向量(如深度特征表示),需要语言模型将之转换成1个语句.
图像描述生成任务结合了计算机视觉和自然语言处理2个研究领域,不仅要求完备的图像语义理解,还要求复杂的符合人类感知的自然语言表达,具备重要的理论意义和应用前景[2-5].在理论上,图像描述生成的研究将促进计算机视觉和自然语言处理领域的发展.通过构建新的计算模型与计算方法,提高计算机对非结构化信息的理解能力和对海量信息的处理效率,从而为人工智能和认知科学的发展作贡献.此外,图像描述生成还具有广阔的应用前景.首先,图像描述生成技术可以应用于自动图像索引,这对于提升图像检索的效果和效率具有重大意义,因而图像描述生成可以应用于图像检索的多个应用领域,包括医疗、商业、军事、教育、数字图书馆等;其次,图像描述生成技术可以帮助社交媒体平台(如Facebook,Twitter等)为图像生成自然语言描述,包括我们在哪里、穿什么和干什么等重要信息,可以直接帮助和指导我们的日常生活;最后,图像描述生成技术还可以在机器人交互、学前教育和视觉障碍辅助等应用领域起到关键的作用.
1 关键技术
图像描述生成的目标是:给定1幅图像,根据图像内容生成语法正确语义合理的语句.显然,图像描述生成涉及2个基本问题——视觉理解和语言处理.为了保证生成描述语句在语法和语义上的正确性和合理性,需要利用计算机视觉和自然语言处理技术分别处理不同模态的数据并做适当的集成.
近年来,深度学习技术得到迅速发展,并成功应用于计算机视觉和自然语言处理相关领域.图像描述生成的研究在经历了早期基于模板的方法和基于检索的方法之后,大多数方法都是基于深度学习技术构建,并在性能上取得了显著的提升[4].基于深度学习的图像描述生成方法涉及的关键技术主要包括整体架构、学习策略、特征映射、语言模型和注意机制5个方面,如图2所示:
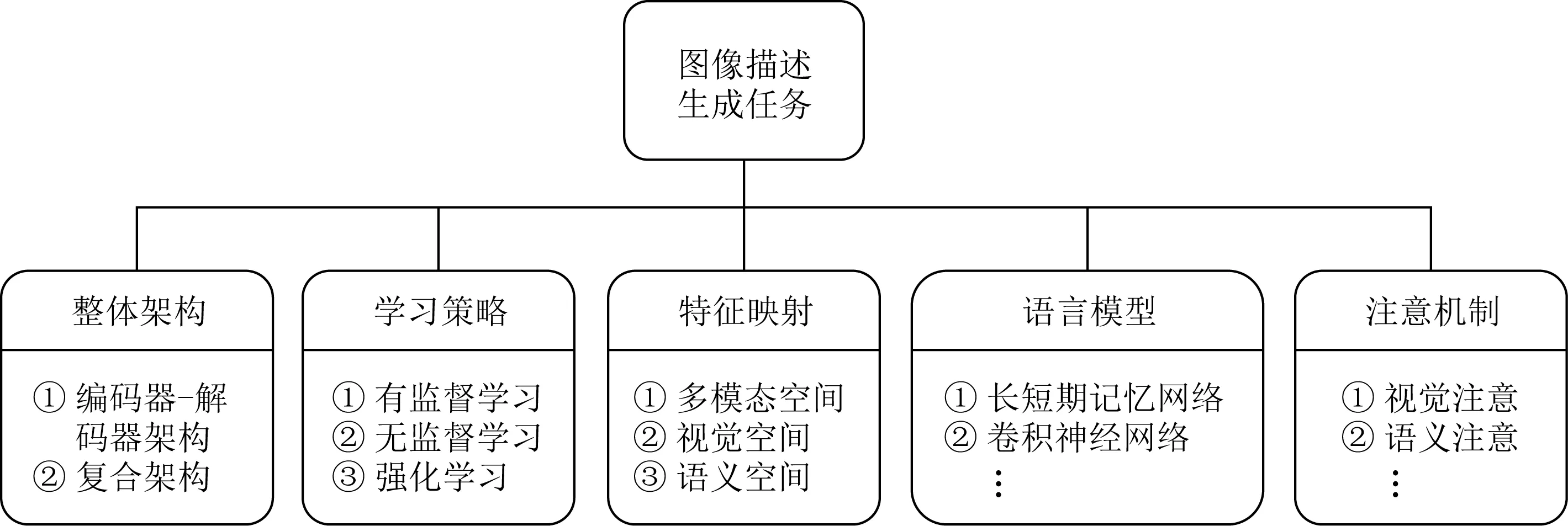
Fig.2 Key technologies of image captioning图2 图像描述生成关键技术
1.1 整体架构
从整体架构上看,当前主流的基于深度学习技术的图像描述生成方法大都基于编码器-解码器架构或复合架构来构建学习模型.
基于深度学习技术构建的图像描述生成方法大部分采用端到端的工作方式,这与基于编码器-解码器架构的神经机器翻译方法[8]非常相似.受到这个思路的启发,可以将图像描述生成看作一个序列到序列的翻译问题,输入是图像,而输出是自然语言,并利用编码器-解码器架构完成图像理解和语言生成的任务.这种架构在性能上取得了重要进展,成为当前图像描述生成方法的主流通用架构.在编码器-解码器架构中,编码器通常采用卷积神经网络(convolutional neural network,CNN)[9-10]提取图像特征,而解码器通常采用循环神经网络(recurrent neural network,RNN)[11]生成自然语言描述.
基于复合架构的图像描述生成方法利用概念检测模型(如物体检测模型、图像自动标注模型等)获取图像中不同粒度的语义概念[12](包括物体名、标注、短语等形式),再利用并列语言模型或者分层语言模型代替解码器生成描述语句.这类方法通常由几个功能独立的部件组成,各个部件被集成到管道中,为输入图像生成自然语言描述.
1.2 学习策略
图像描述生成的学习策略包括有监督学习、无监督学习和强化学习.
在有监督学习中,使用的训练数据伴随着期望输出的标签,通常能够获得较高的精确率.由于图像描述生成的基准数据集中每幅图像都有对应的多条语句或多个语义标签,因而绝大多数图像描述生成方法都采用了有监督学习的方法进行训练.其中应用特别广泛的包括各种基于有监督学习的深度神经网络模型:CNN模型成功应用于图像分类等视觉任务,从AlexNet[13],VGG16[14]到ResNet[15]性能逐步提升;基于区域建议的物体检测模型能够自动提取原始图像中的候选区域,从R-CNN(region CNN)[16],Fast R-CNN[17],Faster R-CNN[18]到R-FCN(region-based fully convolutional networks)[19],在精确率和效率方面取得了很大的提升;RNN模型在自然语言生成方面取得成功,特别是经过改进的长短期记忆网络(long short-term memory,LSTM)[20]和门控循环单元(gated recurrent unit,GRU)[21]等.这些有监督学习方法都可以嵌入到当前主流的编码器-解码器的架构中,作为编码器或解码器的组成部分,完成图像描述生成过程中的基本功能.然而,由于图像内容的复杂性,精确地标注图像数据常常是不切实际的,因而难以获得成对的图像-语句训练数据.而无标签的图像数据日益增长,这就需要利用无监督学习与强化学习来辅助和改进图像描述生成方法.
在无监督学习中,训练数据的标签是未知的,需要通过学习算法揭示数据的内在性质和规律.无监督学习方法经常用于对图像或文本进行预处理,主要包括:各种聚类方法,如K均值聚类、高斯混合聚类等;各种降维方法,如主成分分析、多维缩放等;一些用于文档分析的概率模型,如概率潜在语义分析模型[22]和潜在狄利克雷分布(latent Dirichlet allo-cation,LDA)模型[23]等.此外,生成对抗网络(gen-erative adversarial network,GAN)[24]是在图像描述生成中应用最广泛的无监督学习技术.基于GAN的方法可以从无标签的数据中学习,通过在生成器和判别器之间的竞争过程来获得数据的深度特征表示.利用GAN也能对有限的数据集进行扩充,进而提升系统性能.然而,GAN的应用存在2个重要问题:首先,因为图像上像素值是连续的,GAN可以直接通过反向传播算法来进行训练.然而,文本处理是基于离散的数据,这种操作是不可微的,因此很难直接应用反向传播算法学习.其次,评估器在序列生成中面临着梯度消失和误差传播的问题.对于这些问题,一般需要借助强化学习方法来进行梯度传导.
强化学习[25]方法由智能体、状态、动作、奖励函数、策略和值等参数设计.智能体选择1个动作,接收奖励值,并移动到新状态.策略由动作定义,值由奖励函数定义.智能体试图选择具有最大长期回报的动作,它需要连续的状态和动作信息来提供奖励函数的保证.典型的基于强化学习的图像描述生成方法包含2个网络:策略网络和价值网络,分别被称为行动者和评论者.评论者(价值网络)可以用来估计预期的未来奖励,以训练行动者(策略网络).现有的图像描述生成方法存在“暴露偏差”[26]和评估指标不可微的问题.基于强化学习的训练方法一方面缓解了“暴露偏差”的问题,另一方面它直接在评估指标上优化语句的生成,从而使模型在训练目标和测试评估上也保持一致.因此,基于强化学习的模型优化是生成高质量图像描述的重要保证.
1.3 特征映射
对于图像描述生成任务而言,将图像或文本的内容映射到特征空间是最基本的问题.图像描述生成方法常用的特征空间包括多模态空间、视觉空间和语义空间,并在此基础上生成自然语言描述.将图像和文本的内容映射到多模态空间需要集成隐式的映射方法和语言模型,将图像内容映射到视觉空间通常基于显式的映射方法,而将图像内容映射到语义空间则通常需要在视觉空间的基础上加入概念检测的部件形成复合映射方法.
由于在图像描述数据集中包含图像和相应的描述文本,在基于多模态空间的方法中,编码器是同时从图像和描述文本中学习得到公共的多模态空间,然后将这个多模态表示传递给语言解码器.学习得到多模态空间的方法多种多样,比如可以直接通过加权融合视觉特征和文本特征,或者在融合的基础上进一步利用各种降维方法学习得到潜在的语义空间.
将图像内容映射到视觉空间是图像描述生成的主流方法.在基于视觉空间的方法中,图像特征和相应的描述文本分别独立地传递给语言解码器.早期的方法通常是先提取图像的各种关键手工特征(如颜色、纹理、空间关系等特征),然后再利用特征选择算法将多种手工特征融合为统一的视觉空间.而当前的方法普遍采用预训练的CNN模型或物体检测模型直接提取图像特征来构造视觉空间.
由于通常仅使用CNN模型提取图像特征构造视觉空间,所以只能从某个特定的角度描述图像内容,这使得输入图像的语义不能被全面理解,从而也限制了图像描述的性能.因此,另一种可选的方法是在获取视觉空间表示的基础上构建语义空间,全面描述图像中的物体、属性关系等各种语义要素,再将各个要素进行融合表示成语义属性向量输入解码器生成描述语句.
1.4 语言模型
一般来说,自然语言生成可以看作序列到序列的学习任务.为完成这个任务,研究者提出了多种神经语言模型,如RNN模型[11]、神经概率语言模型[27]和对数双线性模型[28]等.
RNN在各种序列学习任务中被广泛应用,但存在梯度消失和梯度爆炸的问题,且不能充分处理长期时序依赖问题.为此,LSTM[20]对RNN加以改进,可以解决RNN无法处理的长期时序依赖问题,也缓解了RNN容易出现的梯度消失问题.原始的RNN隐藏层只有1个单一的tanh层,输出1个状态h,它对于短期的输入非常敏感.LSTM在RNN的基础上增加了1个单元状态c,可以保存长期的状态.同时,LSTM使用了4个相互作用的层,其内部结构如图3所示:
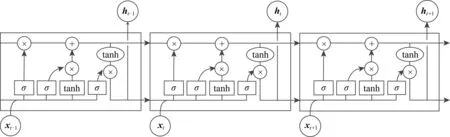
Fig.3 Basic structure of LSTM图3 LSTM基本结构
LSTM的关键在于穿越单元的数据传送线,它使得单元状态c的传输能够快速通过,从而实现长期的记忆保留.LSTM使用的3个门(遗忘门、输入门和输出门)结构可以选择性地让信息通过,从而实现信息的保护和控制.LSTM可用1组公式表示为:
it=σ(Wixxt+Wihht-1),
ft=σ(Wfxxt+Wfhht-1),
ot=σ(Woxxt+Wohht-1),
ct=ft⊙ct-1+it⊙tanh(Wcxxt+Wchht-1),
ht=ot⊙tanh(ct),
(1)
其中,σ是sigmoid函数;c是记忆单元,用于存储和更新记忆信息,由上一时刻保留的记忆和当前时刻纳入的记忆共同组成.f是遗忘门,它决定了上一时刻记忆单元中有多少信息可以保留到当前时刻;i是输入门,它决定了当前时刻的输入信息有多少可以纳入到记忆单元中;o是输出门,用来控制记忆单元在当前时刻的输出,即输出当前时刻的隐状态ht.3个控制门都是通过当前时刻输入的信息和上一时刻LSTM的隐状态来进行计算(这里为简单起见省略了偏置量).
在图像描述生成的任务中,LSTM占据压倒性的重要地位.它通常用作解码器,将编码器得到的中间向量解码为单词序列Y=(y1,y2,…,yT),其中yi∈D是预测生成的单词,D是包含所有单词的词典,T是语句的最大长度.单词由词嵌入向量表示,每个语句的开头用1个特殊的开始标记〈start〉,结尾用1个特殊的结束标记〈end〉.在模型解码过程中,上一时间步生成的单词会被反馈到LSTM中,结合注意机制,生成当前时间步LSTM的隐状态ht,然后根据ht预测生成当前单词yt.
GRU[21]是与LSTM类似的语言模型,它不使用单独的存储单元,并且使用较少的门来控制信息流.从结构上看,GRU只有更新门和重置门2个门,把LSTM中的遗忘门和输入门用更新门来替代,并把单元状态和隐状态进行合并,在计算当前时刻新信息的方法和LSTM有所不同.从某些任务的表现上看,GRU与LSTM获得的性能大致相当,但计算效率更高.因此,GRU既保持了LSTM的效果,又具有更加简单的结构和更少的参数,也更容易收敛.但是,GRU并不能取代LSTM,因为LSTM在数据集很大的情况下表达效果更好.在图像描述生成的任务中,要处理的数据量日益增大,LSTM的应用还是要比GRU广泛得多.
此外,LSTM忽略了语句潜在的层次结构,并需要大量的存储空间.相比之下,CNN可以学习语句的内部层次结构,并且处理速度比LSTM快.因此,CNN也被用于序列学习任务,如条件图像生成[29]和机器翻译[30]等.
1.5 注意机制
视觉注意机制[31]是灵长类和人类视觉系统中的重要机制,本质上是个反馈过程.它有选择地将视觉皮层的早期表达映射到更突出中心的非拓扑表达,其中只包含场景中特定区域或物体的属性.这种选择性映射允许大脑在低层图像属性的指导下,将计算资源集中在某个物体上.机器注意机制也是模仿人类的这一能力最初在计算机视觉领域提出,后来被应用于机器翻译等任务,主要与编码器-解码器架构相结合来使用,目前已应用于人工智能的各个领域.
在最初应用于机器翻译的编码器-解码器架构中,编码器读取具有可变长度的序列输入,将其编码为隐状态,解码器根据编码器的最后1个隐状态来生成输出序列.但这个架构存在的潜在问题是大量的源信息可能无法通过固定长度的向量(即编码器最终的隐状态)来捕获,特别是在长语句的情况下,这个问题尤为严重.因此,Bahdanau等人[32]将注意机制与编码器-解码器架构结合,利用注意机制来对齐源信息和目标输出.源信息中保留了来自编码器所有时间步的隐状态信息,通过注意机制来计算目标输出当前所需的源信息,这样可以使模型能够“关注”源信息的特定部分,并更好地建立源信息与目标信息之间的联系.注意机制在图像描述生成的任务中也起着重要的作用.特别是,人们在描述图像的过程中并不需要一直关注整幅图像的所有信息,而是更倾向于讨论图像中语义上更显著的区域和物体.因此,引入注意机制可以将注意集中在图像的显著部分,同时生成相应的单词.
随着技术不断发展,出现了各种注意机制,但其本质思想都是对信息进行加权整合,以获取更重要的信息组成,从而将有限的信息处理资源分配到重要的部分.注意机制大致可以分为上下文注意机制和自注意机制,其主要计算过程可以表示为
α=softmax(f(Q,K)),
(2)
(3)
其中,Q表示查询(query),K表示键(key),V=(v1,v2,…,vn)表示值(value),通常都表示为矩阵形式,α为权重系数.函数f常见的形式包括对应元素相乘、相加以及通过感知机进行融合等.首先,式(2)通过函数f计算得到Q和K的关系,并通过softmax函数对其进行归一化,得到注意权重分布系数α;其次,式(3)根据权重系数α对信息V=(v1,v2,…,vn)的所有列向量进行加权计算得到整合后的向量vatt.
注意机制计算过程的核心思想是在输入序列上引入注意权重系数α,优先考虑存在相关信息的位置集,以生成下一个输出.将源端中的构成元素想象成是由一系列的数据对〈K,V〉构成,此时给定某个元素Q,通过计算Q和各个K的相似性或者相关性,得到每个K对应V的权重系数,然后对V进行加权求和,即得到了最终的输出.所以本质上注意机制是对源端中元素V进行加权求和,而Q和K用来计算对应的权重系数.不同的注意机制差异主要在于Q,K,V所表示的信息不同.在上下文注意机制中,K和V一般来自源端信息,Q一般来自目标端信息(如在图像描述生成任务中K和V一般表示编码端图像的空间特征,Q一般表示解码端的上下文信息),上下文注意机制通过计算当前目标端信息Q和源端信息K的关系,来对源端信息V进行整合得到输出.而在自注意机制中,Q,K,V都是来自源端信息,自注意机制计算了源端信息本身内部存在的依赖关系,从而可以将信息中的重要部分提取出来,得到关系化的特征表示.
无论是理论上还是实践上,注意机制在各种计算机视觉和自然语言处理任务中都起到了重要作用,在图像描述生成任务中也占据着重要地位,并显著提升了系统性能.
2 图像描述生成方法
图像描述生成经过多年的发展,研究者提出了大量的方法,对这些方法进行分类也存在多种标准.这里按照图像描述生成发展过程的时间线对这些方法进行划分,大致可分为四大类:基于模板的方法、基于检索的方法、基于编码器-解码器架构的方法和基于复合架构的方法.基于模板的方法和基于检索的方法是早期的方法[2].前者依赖于硬编码的语言结构,而后者则利用训练集中现成的描述语句,因此它们的共同缺点是不够灵活,在生成描述的表达上受到较大的限制.基于编码器-解码器架构的方法和基于复合架构的方法则是基于深度学习的方法[3-4],其中又以基于编码器-解码器架构的方法更为通用.在深度神经网络中,CNN等具有强大的图像特征提取能力,LSTM等具有良好的时间序列数据处理能力,这使得基于深度神经网络的方法能够在性能上取得突破,成为当前图像描述生成的主流方法.
2.1 基于模板的方法
基于模板的方法通过对语法和语义的约束过程来生成图像描述.通常,该方法先检测出图像中特定的一系列视觉概念,然后通过语句模板、特定的语法规则或组合优化算法等将这些概念进行连接以生成描述语句.
Yang等人[33]利用四元组〈名词,动词,场景,介词〉作为生成图像描述的语句模板.首先使用检测算法评估图像中的物体和场景,然后利用语言模型预测可能用于构成描述语句的动词、场景和介词,并利用隐Markov模型推理得到最佳的四元组,最后通过填充四元组给出的语句结构生成图像描述.Kulkarni等人[34]用图结点分别对应物体、属性及空间关系等,通过条件随机场确定需要呈现在图像描述中的图像内容,然后基于语句模板将推理的输出转换成图像描述.Li等人[35]首先使用视觉模型检测图像并提取物体、属性和空间关系等语义信息,然后定义三元组〈〈形容词1,物体1〉,介词,〈形容词2,物体2〉〉对识别的结果进行编码,并执行短语选择和短语融合,最终得到优化的短语集合作为图像描述.Mitchell等人[36]使用〈物体,动作,空间关系〉的三元组来表示图像,并根据视觉识别结果将图像描述视为1棵树的生成过程:首先通过对物体名词的聚类和排序,确定要描述的图像内容;然后为物体名词创建子树,并进一步创建完整的树;最后,利用Trigram语言模型从生成的完整树中选择字符串作为对应图像的描述.Lebret等人[37]提出了软模板的方法生成图像描述.该方法首先提取训练语句中的短语并进行统计,通过词向量表示方法将短语表示为高维向量,并使用CNN获取图像特征.随后训练1个双线性模型度量图像特征和短语特征之间的相似度,可以为给定图像推断出短语,并在上一阶段统计的基础上进一步生成描述语句.Lu等人[38]提出基于模板生成和填槽的图像描述生成方法,其主要思想是将生成语句的单词分为实体词与非实体词2个词表.语句模板由1个语言模型获得,其单词来自非实体词表.实体词则由物体检测方法直接从图像获得,用于填充语句模板中的空槽,形成1个语句.这种方法开创性地使用神经网络来提取语句模板,从而成功解决了传统的基于模板的方法缺乏多样性输入的问题.
基于模板的方法能够生成语法正确的语句,且与图像内容的相关性强.然而,因为这类方法依赖于视觉模型识别图像内容的精确性,所以生成的语句在广泛性、创造性和复杂性上有缺陷.此外,与人工描述相比,使用严格的模板作为语句结构使得生成的描述不够自然.
2.2 基于检索的方法
给定1幅查询图像,基于检索的方法通过从预先定义的语句集中利用相似度匹配的方法检索出1个或1组语句作为该图像的描述语句.生成的描述语句可以是1个现有的语句,也可以是1个由检索结果得到的多个语句组合而成的语句.
Farhadi等人[39]提出基于三元组〈物体,行为,场景〉构建语义空间以连接图像和语句.给定1幅查询图像,该方法通过求解Markov随机场将给定图像映射到语义空间,并使用相应的相似度度量措施计算给定图像与现有语句的距离,将与给定图像最相似的语句作为相应的描述.Ordonez等人[40]首先提取给定查询图像的全局特征表示,从带有描述语句的图像集中检索出一系列图像;然后对检索得到图像的语句进行重新排序,将排位最靠前的语句作为给定图像的描述.Hodosh等人[41]利用核典型相关性分析技术将图像和文本投影到公共空间,使得训练图像与其相应的描述相关性最大.在这个公共空间中,通过计算图像和语句的余弦相似度来选择排位最靠前的语句作为给定图像的描述.
文献[39-41]直接使用检索得到的语句作为给定查询图像的描述,隐含的假设是总存在1个语句适合描述给定图像,然而现实中此假设未必正确.于是,另一些基于检索的方法利用检索得到的语句进行重新组合得到给定图像的新描述.Gupta等人[42]首先基于给定图像的全局特征执行检索,然后训练1个预测短语相关性的模型从检索到的图像中选择短语,最后根据选定的相关短语生成描述语句.Kuznetsova等人[43]提出了一种基于树的方法,利用Web图像来构建图像描述.在进行图像检索和短语提取后,将提取的短语作为树片段,将模型描述组合为约束优化问题,采用整数线性规划进行编码并求解.
随着深度学习技术的发展,利用深度神经网络提取图像特征逐步代替了早期使用的浅层模型和手工特征.Socher等人[44]使用深度神经网络从图像中提取特征,并利用最大化边缘目标函数将得到的多模态特征映射到公共空间,最后基于图像和语句在公共空间中的相似度进行语句检索.Karpathy等人[45]提出了将语句片段和图像片段嵌入公共空间,以便为给定查询图像的相关语句进行排序.该方法使用语句的依赖树关系作为语句片段,将区域CNN检测图像得到的结果作为图像片段,并设计了1个包括全局排序项和片段对齐项的最大化间隔目标的结构,将视觉和文本数据映射到公共空间.于是,图像和语句之间的相似度可以基于片段相似度来计算,使得语句排序可以在更细的层次上进行.Ma等人[46]提出了多模态CNN框架,包括3种组件:图像CNN用于编码视觉数据,匹配CNN用于视觉和文本数据的联合表示,多层感知机用于对视觉和文本数据的兼容性进行评分.该方法使用匹配CNN的各种变体来解释图像与单词、短语、语句的联合表示,最终基于多模态CNN的集成框架来确定图像和语句之间的匹配分数.
基于检索的方法能够为给定的查询图像传送格式良好的语句或短语,以生成图像描述.虽然生成的语句通常语法正确、流畅,但是将图像描述约束到已经存在的语句中并不能适应新的物体或场景的组合.在某些特殊情况下,生成的描述甚至可能与图像内容无关.此外,这类方法的性能依赖于大量带有描述语句的图像,也使其应用受到很大的限制.
2.3 基于编码器-解码器架构的方法
在编码器-解码器架构下,编码神经网络(通常采用CNN)首先将原始图像转换成中间表示(可以是多模态空间或视觉空间等表示形式),然后解码神经网络(通常采用LSTM)将中间表示作为输入,在注意机制的引导下,逐词生成描述语句.其一般过程如图4所示:

Fig.4 Image captioning based on encoder-decoder architecture图4 基于编码器-解码器架构的图像描述生成
按照各种图像描述生成方法所重点关注的关键技术的不同,基于编码器-解码器架构的方法可进一步分为基于多模态空间的方法、基于视觉空间的方法、基于语义空间的方法、基于注意机制的方法和基于模型优化的方法五大类.
2.3.1 基于多模态空间的方法
这类方法在编码时利用多个深度神经网络(如CNN和LSTM)同时处理训练图像的视觉模态和文本模态数据,生成公共空间,即得到训练图像的多模态空间表示,然后进行解码生成相应的图像描述.
Kiros等人[47]最早使用编码器-解码器架构完成图像描述生成任务.首先将图像文本联合嵌入模型和多模态神经语言模型相结合,使用CNN和LSTM分别对视觉和文本数据进行编码;然后通过最小化对偶排位损失,将编码的可视数据投影到由LSTM隐状态所覆盖的嵌入空间中,得到图像的多模态空间表示;最后利用内容结构化的神经语言模型对多模态空间表示进行解码,生成描述语句.Karpathy等人[48]提出了一种架构更简单的深度视觉语义对齐模型,其基本思想是假定语句的某些部分对应的是图像中特定的未知区域.该模型利用图像区域CNN、语句双向RNN和对齐2种模态的结构化目标来推断语句片段和图像区域之间的对齐.文本和图像区域被映射到公共的多模态嵌入空间中,然后利用多模态RNN推断出视觉和语义的对齐并生成新的描述语句.Mao等人[49]提出了多模态循环神经网络(multimodal RNN,m-RNN),包含2个子网:1个CNN子网处理图像和1个RNN子网生成语句.2个子网在多模态层中相互作用构成整个m-RNN模型,以图像和语句片段作为输入,计算生成描述语句下一个词的概率分布.Chen等人[50]提出了一种新的基于多模态空间的方法.一方面,可以从图像中生成新的描述,从给定的描述中计算视觉特征,即可以表示图像及其描述语句之间的双向映射.另一方面,可以从生成的单词中动态更新图像的视觉表示,还设计了1个附加的循环视觉隐藏层与RNN共同完成反向映射.
2.3.2 基于视觉空间的方法
这类方法在编码时通常利用CNN直接处理训练图像,即得到图像的视觉空间表示,或者经过预处理得到融合多个区域特征的视觉空间表示,然后进行解码生成相应的图像描述.
Vinyals等人[51]提出了神经图像描述生成(neural image caption generator,NIC)方法,使用CNN获取图像表示并使用LSTM生成图像描述.NIC的编码器CNN使用新方法进行批量归一化,并将CNN最后的隐藏层输出作为解码器LSTM的输入,且LSTM能够记录已经使用文本描述过的物体.在生成图像描述时,图像信息包含在LSTM的初始状态中,下一个词是根据当前时间步和上一个隐状态生成的,这个过程一直持续到描述语句的结束标记为止.由于图像信息只在处理过程的开始时输入,因此NIC可能面临消失梯度问题,而且在生成长语句时仍然存在问题,开始产生的单词作用会越来越弱.为此,Donahue等人[52]提出了长期循环卷积网络.与NIC的不同之处在于,该网络并不是只在初始阶段向系统输入图像特征,而是在LSTM的每个时间步都为序列模型同时提供图像特征和上下文词特征作为输入.此外,Jia等人[53]提出了一种LSTM的变体称为gLSTM,可以生成长语句.该方法将全局语义信息添加到LSTM的每个门和单元状态中,同时考虑了不同长度的规范化策略来控制描述语句的长度.由于单向LSTM是基于视觉上下文和所有之前生成的文本预测下一个单词,因而不能生成上下文构造良好的描述.为此,Wang等人[54]提出了基于深度双向LSTM的方法,其架构由1个CNN和2个独立的LSTM组成,可以利用过去和将来的上下文信息来学习长期的视觉语言交互,因此能够生成上下文信息和语义信息丰富的图像描述.
Mao等人[55]提出了一种特殊的图像描述生成方法,可以生成图像中特定物体或区域的描述,称为引用表达式.使用此表达式可以推断正在描述的物体或区域,因而该方法可以生成语义明确的描述语句,同时还考虑了场景中的显著物体.Gu等人[56]提出了逐步求精的学习思想,主要创新在于解码阶段使用了1个粗粒度的解码器和多个细粒度的解码器.其中粗粒度解码器接受图像特征作为输入,并获得粗粒度的描述结果,接下来在每个阶段都有1个细粒度解码器进行更精细的解码,其输入来自于上一阶段解码器的输出结果和图像特征,最终生成语义更完备的描述语句.Dai等人[57]探索图像的另一种视觉表示,即用2维特征图代替传统的单个向量表示潜在状态,并通过卷积将它们连接起来.这种空间结构对描述生成过程有显著影响,对潜在状态的编辑(例如抑制状态中的某些区域)可能生成不同的描述.由于这种变体表示能够保持空间局部性,因此可以加强视觉结构在描述生成过程中的作用.
2.3.3 基于语义空间的方法
随着图像描述生成技术的不断进步,单纯使用视觉特征向量表示图像已经很难提升系统性能,越来越多的研究工作尝试使用融合视觉特征和语义特征的方法表示图像.通常认为图像中的区域、物体和属性等包含丰富的语义信息,因而不少方法提出在视觉空间的基础上进一步获取复杂的语义空间表示,然后利用高级语义信息生成图像描述的思路.
You等人[58]提出了一种基于图像语义概念表示的方法,分别使用CNN和1组视觉属性检测器从输入图像中提取1个全局特征和1组语义属性,每个属性对应于所用词典的1个条目,要生成的单词和要检测的属性共享相同的词典.于是,解码过程可以在语义空间上进行,从而获得优越的性能.Wu等人[59]将视觉概念引入编码器-解码器框架,首先从训练语句中挖掘出1组语义属性,然后在基于区域的多标签分类框架下,针对每个属性训练1个基于CNN的语义属性分类器.该分类器可以将图像表示为1个预测向量,并给出每个属性在图像中出现的概率,然后再使用LSTM作为解码器生成描述图像内容的语句.Wang等人[60]提出了一种新型的解码器结构,由1个Skel-LSTM和1个Attr-LSTM联合构成.前者使用CNN提取图像特征生成主干语句及其属性,后者为每个主干语句的属性生成一系列的主干词,然后再将2部分内容合成最终的描述语句.
Yao等人[61]提出了改进的架构集成语义属性与图像表示,主要采用2组不同的框架结构:在第1组结构中,只向LSTM插入语义属性,或先向LSTM插入图像表示再向LSTM插入语义属性,反之亦然.在第2组结构中,可以控制LSTM的时间步长,决定图像表示和语义属性是一次性输入还是在每个时间步都输入.Li等人[62]提出了一种联合视觉和语义的LSTM模型.首先利用Faster R-CNN和CNN分别提取图像的低层视觉特征和高层语义特征;然后,在LSTM解码过程中,视觉单元利用视觉特征对图像中的物体进行定位,而语义单元则将定位后的物体与其语义属性进行集成,并据此生成相应的单词.为了揭示图像中难以直接表达的隐含信息,Huang等人[63]将从知识图谱中抽取出来的外部知识输入到LSTM语言生成器的单词生成阶段,以增加某些可能被用来描述图像内容的单词的概率,实现内部知识与外部知识的集成,从而能够生成新颖的图像描述.
Jiang等人[64]提出了循环融合网络(recurrent fusion network,RFNet),采用多个CNN作为编码器,并在编码器后插入1个循环融合过程,以获得更好的图像表示输入解码器.融合过程分为2个阶段:第1阶段利用来自多个CNN表示之间的交互来生成多组思维向量;第2阶段则融合生成的多组思维向量,并为解码器生成1组新的思维向量.Yao等人[65]提出结合图卷积网络(graph convolutional network,GCN)和LSTM的架构,将语义关系和空间物体关系集成到图像编码器中.该方法基于从图像中检测到物体的空间和语义关系来构建图,然后通过GCN利用图结构对物体上的推荐区域表示进行细化,基于细化的区域级视觉特征能够生成更准确的描述.Chen等人[66]提出了一种新的基于组的图像描述生成方案GroupCap,将组图像之间的结构相关性和多样性联合建模,以实现最佳的协同描述生成.首先提出视觉树解析器来构造单个图像中的结构化语义关联,然后利用树结构之间的关联来建模图像之间的相关性和多样性,最后将这些关联建模为约束并发送到基于LSTM的描述生成器中.
为了使现有的编码器-解码器架构具有人性化的推理能力,Yang等人[67]提出了一种新的学习框架称为配置神经模块(collocate neural module,CNM),用以生成连接视觉编码器和语言解码器的“内部模式”.CNM的编码器包含1个CNN和4个神经模块(分别对应物体、属性、关系和功能),用来生成不同的语义特征;解码器有1个模块控制器,可以将这些特征融合到1个特征向量中,以便解码器处理.此外,Yang等人[68]利用符号推理和端到端多模态特征映射2种方法的互补优势,将语言生成的归纳偏差引入到编码器-解码器架构中,使用场景图来缩减视觉感知和语言构成的鸿沟.场景图通过有向边连接物体(或实体)、物体的属性及物体在图像或语句中的关系.该方法将图结构嵌入到向量表示中,并无缝地集成到编码器-解码器框架,于是向量表示将归纳偏差从纯语言领域转移到视觉语言领域.Chen等人[69]提出基于抽象场景图的结构来表示用户在细粒度级别的意图,并控制描述的详细程度.抽象场景图由3种抽象节点(物体、属性、关系)组成,以没有任何具体语义标签的图像为基础.在此基础上实现的模型能够有效识别用户意图和图像中的语义信息,因而能够生成期望的描述语句.
2.3.4 基于注意机制的方法
2.3.1~2.3.3节讨论的一些方法在为图像生成描述时无法随着时间的推移分析图像,且通常将场景作为一个整体来考虑,而不考虑与描述语句部分相关的图像局部层面.基于人类的视觉注意机制[31],研究者提出了利用注意信号来引导图像描述生成,能够很好地缓解这个问题.这类方法的典型过程如图5所示:
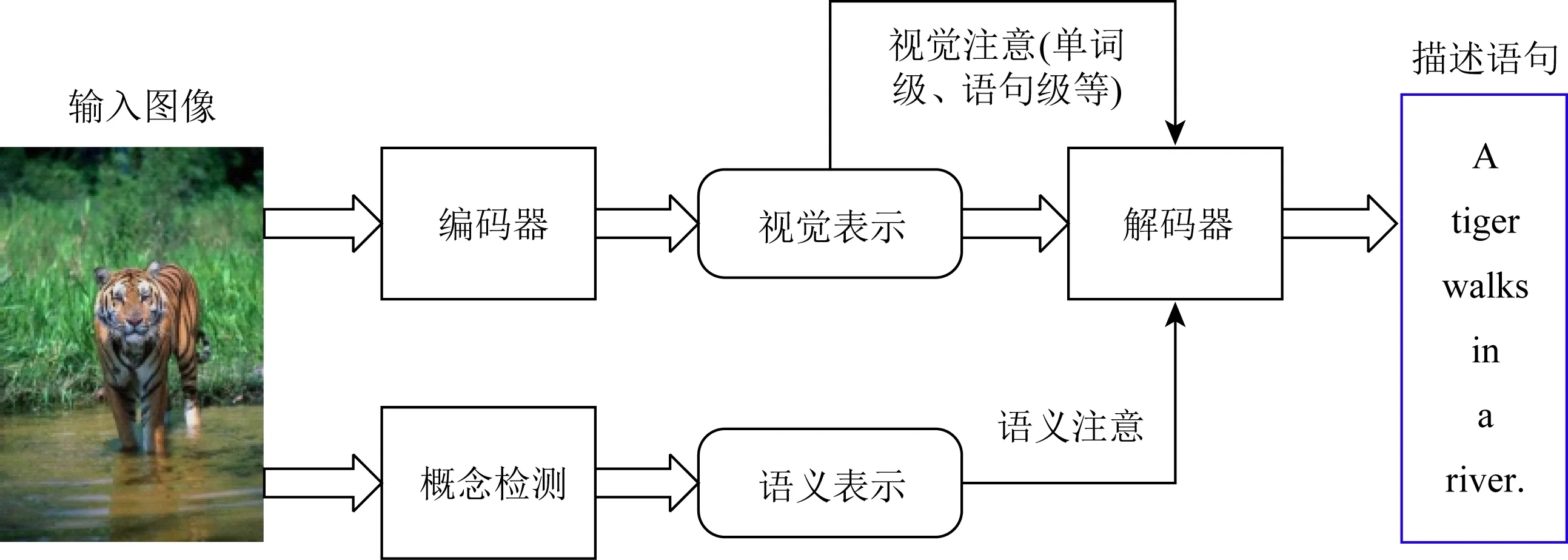
Fig.5 Image captioning guided by attention mechanism图5 注意机制引导的图像描述生成
由图5可见,通过将注意机制引入到编码器-解码器框架中,语句生成将以基于注意机制计算的隐状态为条件.这类方法中使用的注意信息大致可分为视觉注意和语义注意,其中视觉注意又可分为单词级注意和语句级注意等多个层级.如果希望同时利用多级注意信息,还需要提供协同机制以结合不同的注意.注意机制的重要性体现在,它可以在生成输出序列的同时动态聚焦于输入图像的各个局部层面,因而可以达成整体和局部的平衡.
Xu等人[70]最先在图像描述生成方法中引入注意机制,提出能够自动描述图像显著内容的方法.该方法首先用CNN将图像表示为N个向量,每个向量表示图像的部分区域,然后提出随机性硬注意机制和确定性软注意机制2种不同的方法来产生注意信号.在每个时间步中,随机性硬注意机制从N个位置中选择1个视觉特征作为上下文向量生成1个单词,而确定性软注意机制将所有N个位置的视觉特征结合起来,获取上下文向量生成1个单词.Yang等人[71]提出利用评论网络来强化编码器-解码器架构.该方法首先执行多个评论步骤,对编码器的隐状态应用注意机制,并在每个评论步骤后都输出1个思维向量;然后将这些思维向量作为解码器中注意机制的输入.
由于注意信号主要集中在RNN每个时间步的图像上,但有些单词或短语存在不必要的注意视觉信号,那么这些不必要的视觉信号就可能会影响生成描述的总体性能.因此,Lu等人[72]提出了基于视觉哨兵的自适应注意方法,可以确定什么时候关注图像区域,什么时候关注语言生成模型.该方法引入新的空间注意方法,可以从图像中计算出空间特征,然后在自适应注意方法中引入1个扩展的LSTM,能够产生1个额外的视觉哨兵,为解码器提供1个回退选项.此外,还有1个哨兵门用以控制解码器从图像中获得信息的多少.Chen等人[73]提出SCA-CNN(spatial and channel-wise attention CNN),在CNN中融合了空间注意和通道注意.在生成图像描述的过程中,SCA-CNN在多层特征图中动态地调整多层特征图和生成语句的上下文,对视觉注意的位置(即多层特征图中关注的空间位置)和内容(即关注的通道)进行编码.Fu等人[74]提出了在图像和文本之间采用平行结构的新方法,在图像的多个尺度上引入了多个可视区域,能够根据视觉信息与文本信息之间的语义关系提取抽象语义流,还可以通过引入特定场景的上下文来获取更高级的语义信息.
基于注意的方法在生成单词或短语时会寻找图像的不同区域,但这些方法生成的注意图并不总是对应于图像的某个适当的区域,这也会影响描述生成系统的性能.为此,Liu等人[75]提出了新的神经图像描述生成方法,可以在每个时间步对注意图进行评估和校正.该方法引入了1个定量的评估指标来计算注意图,并提出监督注意模型,包含了对齐标注的强监督和语义标签的弱监督2种监督信息.Pedersoli等人[76]提出了基于区域注意的图像描述方法,将图像区域与给定RNN状态的描述词相关联,可以预测RNN的每个时间步的下一个词和对应的图像区域.该方法将新的注意机制与空间变换网络相结合,可以生成高质量的图像描述.
多数图像描述方法采用自顶向下的方法构建视觉注意图,通常从CNN的输出中获得一些选择性区域作为图像特征.You等人[58]在获取图像视觉概念的基础上提出了新的语义注意模型,可以同时利用自底向上和自顶向下的方法并互补不足.在编码器-解码器框架下,全局视觉特征仅在编码阶段的初始步骤发送给CNN,而在解码阶段则使用1个输出注意函数利用获取的语义级概念指导LSTM生成对应的图像描述.Anderson等人[77]提出了结合自底向上和自顶向下的注意机制,其中自底向上的注意机制基于Faster R-CNN推荐图像区域,使用与推荐区域相关联的特征向量,而自顶向下的注意机制则确定特征权重.因此,该方法既适用于物体级区域,也适用于其他图像级显著区域.Cornia等人[78]提出的图像描述生成框架既能基于图像的区域获取特征,又允许对这些区域序列进行控制.给定图像区域序列或集合形式的控制信号,该方法通过1个循环架构生成相应的描述.这个循环架构能够显式地预测基于区域的各个文本块,并根据给定控制信号的约束生成多样化的描述语句.Huang等人[79]提出了“注意上的注意”(attention on attention,AoA)模块,扩展了传统的注意机制来确定注意结果和查询之间的相关性.AoA首先利用注意结果和当前上下文生成“信息向量”和“注意门”,然后通过对它们进行对应元素相乘操作来加上另一个注意,得到最后的“注意信息”,即期望的有用知识.该方法将AoA模块同时应用于图像描述生成架构的编码器和解码器,因而称为AoA网络.
注意机制大致分为上下文注意机制和自注意机制,在此基础上可以引入单词级注意、语句级注意和语义级注意等多个层级.结合多级注意机制获取更好的图像描述性能是个值得研究的课题.Wei等人[80]在图像描述生成方法中引入自注意机制,用以提取图像的语句级注意信息.并在此基础上进一步提出了双注意模型,通过结合语句级注意和单词级注意生成图像描述.由于该方法能够结合图像的全局和局部信息,因而生成的描述表达更准确且语义更丰富.Guo等人[81]对自注意机制进行改进:首先,提出了规范自注意模块,对自注意重新参数化,有益于自注意内部的规范化;其次,提出了几何感知自注意模块,使自注意能够明确有效地考虑图像中物体之间的相对几何关系,从而弥补Transformer模型[30]无法对输入物体的几何结构进行建模的局限性.Li等人[82]探讨上下文感知组描述的新任务,其目的是以另外1组相关参考图像作为上下文生成1组目标图像的描述.为此,提出了将自注意机制与对比特征构建相结合的框架,既能捕捉每个组图像之间的区分信息,同时也能有效地总结每个组的共同信息.Liu等人[83]提出的方法在生成过程中使用融合网络集成视觉注意和语义注意.在生成描述语句的每个时间步,解码器根据生成的上下文自适应地将提取的语义主题信息和图像中的视觉注意信息合并,从而能够有效地将视觉信息和语义信息结合起来.Ke等人[84]提出反射解码网络以增强解码器中单词的长序列依赖性和位置感知能力.该网络能学习协同关注视觉和文本特征,同时感知每个单词在语句中的相对位置,以最大化生成语句中传递的信息.李志欣等人[85]提出了结合视觉注意和语义注意的图像描述方法,首先对现有的视觉注意模型进行改进以获取更准确的图像视觉信息,然后利用LDA模型与多层感知机提取出一系列主题词来表示图像场景语义信息,最后基于注意机制来确定模型在解码的每一时刻所关注的图像视觉信息和场景语义信息,并将它们结合起来共同指导模型生成更准确的描述语句.
2.3.5 基于模型优化的方法
由于图像内容的复杂性,精确地标注图像数据常常是不切实际的,因而如何充分利用无标签图像数据成为重要问题.于是,利用强化学习与无监督学习方法进行模型优化成为自然的思路,也已经在图像描述生成的任务中获得了良好的效果.
基于强化学习的图像描述生成主要针对评估指标进行优化,能够提高模型的整体评估得分.其过程通常分为2步:首先,构建结合CNN和RNN的“策略网络”用于控制解码器生成图像描述;其次,构建结合CNN和RNN的“价值网络”用于评估当前生成的部分描述语句,将奖励信息反馈给第一个网络,并调整动作以生成高质量的描述语句.这类方法的典型过程如图6所示:
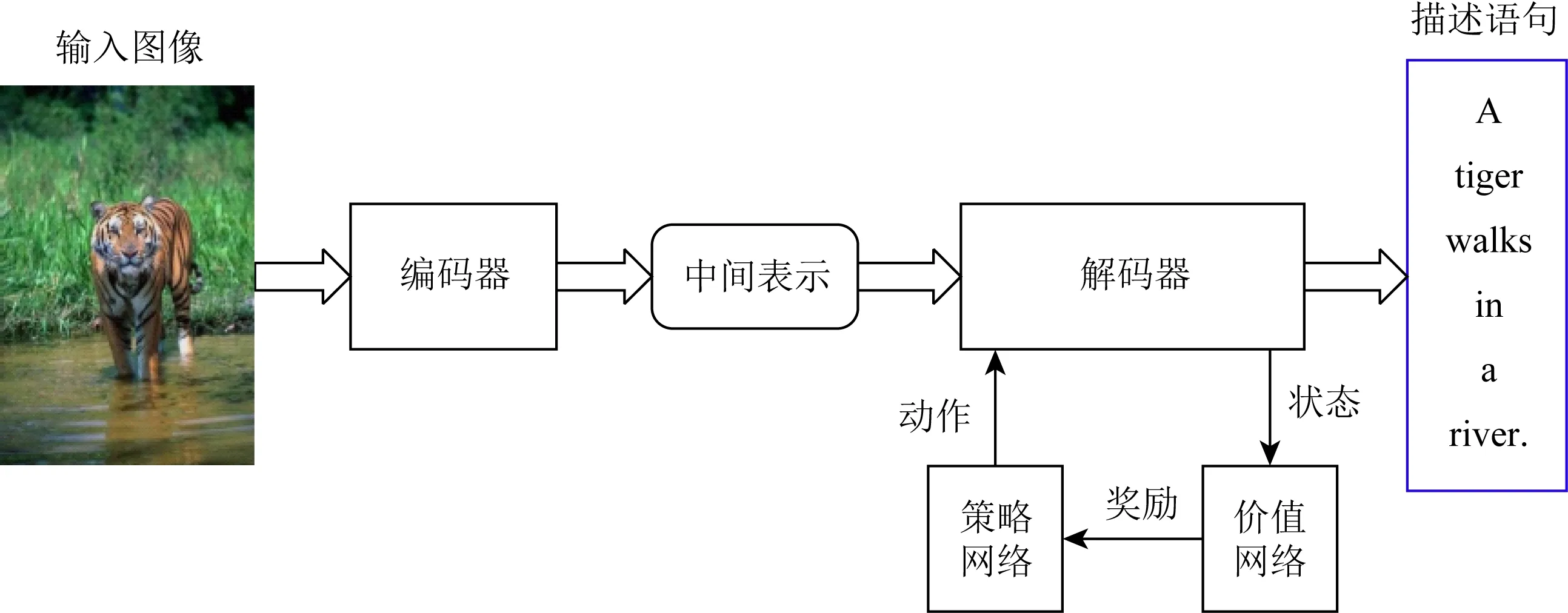
Fig.6 Image captioning based on reinforcement learning图6 基于强化学习的图像描述生成
Ranzato等人[86]提出基于RNN的策略梯度序列模型,利用强化学习方法直接在评估指标上优化模型,从而得到更好的描述生成结果.Liu等人[87]通过优化评估指标及其线性组合确保描述语句在语法上的流畅性以及描述语句在语义上与图像相符合.该方法使用蒙特卡洛模拟方法代替了最大似然估计训练与策略梯度混合的方法,比原来的混合方法更容易优化并获得了更好的结果.Ren等人[88]提出的方法整体架构包含2个网络,在每个时间步联合计算最佳的下一个单词.“策略网络”作为局部指导,有助于根据当前状态预测下一个单词;“价值网络”作为全局指导,对考虑到当前状态所有可能扩展得到的奖励值进行评估.该方法能够在正确预测单词的同时调整网络,因而最后生成与原始描述相匹配的描述语句.Rennie等人[89]提出了自批评序列训练(self-critical sequence training,SCST)的强化学习方法,不是通过估计一个“基线”来规范化奖励和减少方差,而是利用自己的测试时间推理算法的输出来对奖励信号进行规范化.这种训练方法可以避免估计奖励信号和规范化的过程,同时可以根据其测试时间推理过程来协调模型.Zhang等人[90]提出了基于行动者-评论者强化学习的方法,可直接对评估指标不可微的问题进行优化.行动者将整个任务视为序列决策问题,并可以预测序列的下一个标签;评论者的工作是预测奖励值,如果预测的奖励值符合预期,行动者将继续根据其概率分布抽样得到输出.此外,由于现有大多数基于强化学习的图像描述生成方法只关注语言策略,而不关注视觉策略(如视觉注意),因此无法捕捉对合成推理至关重要的视觉上下文.于是,Liu等人[91]提出了上下文感知视觉策略网络(context-aware visual policy network,CAVP)以生成序列级的图像描述,将视觉上下文集成到序列视觉推理中.CAVP在每一个时间步都将先前的视觉注意作为上下文进行显式的解释,然后根据当前的视觉注意判断上下文是否有助于当前单词的生成.与传统的每一步只确定1个图像区域的视觉注意相比,CAVP可以随着时间的推移处理复杂的视觉合成.CAVP及其后续的语言策略网络可以使用行动者-评论者策略梯度方法对任何评估指标进行端到端的高效优化.
基于无监督学习的方法可以充分利用无标签图像数据,增强现有的训练数据并进一步优化模型.对抗学习是一类重要的无监督学习方法.与传统的方法相比,基于对抗学习的图像描述生成方法可以生成更多样化的图像描述,并能与强化学习策略相结合以提升描述语句质量.Dai等人[92]提出了新的基于条件GAN[93]的学习框架,在给定图像和评估器(评估描述与视觉内容的匹配程度)的条件下,通过联合学习得到生成器(生成图像描述).在训练序列生成器的过程中,该方法通过策略梯度算法优化模型,允许生成器沿着通道接收早期反馈.Shetty等人[94]采用对抗训练与近似Gumbel采样器[95]相结合,试图将模型生成的分布与人类感知分布相匹配.该方法不仅在描述的正确性方面与当前先进方法相当,而且能够生成多样化的描述,偏向性显著降低并且更符合人类感知.Chen等人[96]提出了跨域图像描述生成器,使用新的对抗训练方法来利用目标域中的未配对数据,可以在不需要目标域成对图像-语句训练数据的情况下,从源域到目标域自适应语句样式.该方法引入了2个评论者网络来指导图像描述生成器:领域评论者评估生成的语句能否与目标域中的语句区分;多模态评论者评估图像及其生成的语句是否有效成对.Dognin等人[97]研究基于条件GAN训练图像描述生成模型,提出了基于上下文感知的LSTM描述生成器和协同注意判别器,实现了图像和描述语句之间的语义对齐.该工作还讨论了图像描述生成模型的自动评估问题,提出了1个新的语义评分方法,并证明了它与人类判断的相关性.Feng等人[98]提出了无监督图像描述生成模型,由图像编码器、语句生成器和判别器组成.CNN将给定的图像编码成1个特征表示,生成器根据这个特征表示输出1个语句来描述图像,判别器用于区分描述是由模型生成的还是从语句语料库生成.生成器和判别器以不同的顺序耦合以执行图像和语句的重构.该模型通过策略梯度联合引入对抗性奖励、概念奖励和图像重构奖励对生成器进行训练.Gu等人[99]提出了基于场景图的无配对图像描述生成方法,其架构包括图像场景图生成器、语句场景图生成器、场景图编码器和语句解码器.该方法利用文本模态数据训练场景图编码器和语句解码器,并将场景图特征从图像模态映射到语句模态,从而实现图像和语句之间的场景图对齐.
综上所述,基于编码器-解码器架构的方法通常采用端到端的方式将图像中的内容转换为描述语句,是当前图像描述生成的主流方法.这类方法的参数可以联合训练,具有简洁有效的特点,但有时难于识别复杂图像中的细节,从而影响描述语句的质量.
2.4 基于复合架构的方法
在复合架构下,首先使用图像理解部件来检测输入图像中的视觉概念;然后,将检测到的视觉概念发送到文本生成部件以生成多个候选描述语句;最后,使用一个多模态相似度模型对候选描述语句进行后处理,选择其中的高质量语句作为输入图像的描述.其一般过程如图7所示:
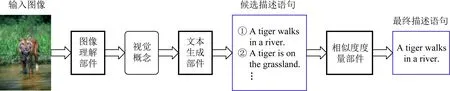
Fig.7 Image captioning based on compositional architecture图7 基于复合架构的图像描述生成
Fang等人[100]提出的图像描述生成方法由视觉检测器、语言模型和多模态相似度模型组成,先找出训练语句中最常见的单词,再通过CNN提取视觉特征,使用多示例学习方法训练对应于每个单词的视觉检测器.给定1幅图像,根据图像中检测到的单词,采用最大熵语言模型生成候选描述语句.最后,利用深度多模态相似度模型将图像和文本片段映射到公共空间并进行相似度度量,对候选描述语句进行重新排序.在这个工作的基础上,Tran等人[101]提出了开放领域图像描述系统,使用基于ResNet的视觉模型来检测广泛的视觉概念,同样使用最大熵语言模型生成候选描述,并使用深度多模态语义模型进行描述语句排序.该系统增加了对地标和名人的检测,及用于处理描述复杂图像的信心模型.
为了对图像内容进行详细的描述,Ma等人[102]提出了使用结构词进行图像描述生成,分为结构词识别和语句翻译2个阶段.该方法首先使用多层优化方法生成分层次的概念,将图像表示为四元组〈物体,属性,行为,场景〉,也就是所谓的结构词.然后再利用基于LSTM的编码器-解码器翻译模型,将结构词翻译成描述语句.Wang等人[103]提出了并行融合RNN和LSTM的架构,利用RNN和LSTM的互补性提高图像描述生成的性能.该方法首先将输入通过RNN单元和LSTM单元并行映射到隐状态,然后将这2个网络中的隐状态与单词预测的某些比率合并以生成图像描述.此外,Gan等人[104]在图像描述生成中引入语义合成网络,其中语义概念向量由图像中所有可能的概念合成,比视觉特征向量和场景向量具有更大的潜力,可以生成覆盖图像整体意义的描述.
尽管基于深度学习的图像描述生成方法取得了很好的效果,但它们在很大程度上依赖于大量成对的图像-语句数据集.而且这些方法只能在上下文中生成物体的描述,难于生成有新意的描述语句.发现新物体的方法试图在生成的描述语句中出现不包含在训练集的图像-语句对中的物体,因此这类方法大多基于复合架构设计.Hendricks等人[105]提出了深度合成描述方法,利用大型物体识别数据集和外部文本语料库,并通过在语义相似的概念之间传递知识来生成图像语句数据集中不存在的新物体描述.Yao等人[106]在CNN和RNN的架构中引入复制机制来生成新物体的描述,首先使用自由获取的物体识别数据集来为新物体开发分类器,然后将RNN逐词生成的标准语句与复制机制结合起来,可以在输出语句的适当位置选择有关新物体的单词.Venugopalan等人[107]提出的方法试图发现图像中的新物体,能够充分利用外部知识来源,包括来自物体识别数据集的有标签图像,以及从无标签文本中提取的语义知识.该方法提出了最小化联合目标的训练方法,可以从不同的数据源中学习,并利用分布式语义嵌入,使得模型能够概括和描述在数据集之外的新物体.
基于复合架构的方法一般专注于识别复杂图像中的细节,期望生成高质量的图像描述,但这类方法通常包含多个独立部件,训练过程比较复杂.
除了以上方法之外,与图像描述生成领域相关的还有一些其他研究方向和实现方法.除了发现新物体的描述方法和多样化描述方法之外,风格化描述方法[108-109]希望生成的描述语句能模仿人类的独特风格,而故事生成方法[110]试图将生成的描述语句进一步组成段落故事,等等.也就是说,图像描述生成的研究空间还非常广,有待研究者进一步开展新的研究和改进现有方法.
3 实验评估与性能比较
本节介绍图像描述生成研究中常用的数据集和评估措施,并给出若干典型方法在2个基准数据集上获得的性能评估指标数值.
3.1 数据集
在图像描述生成的研究过程中,研究者构建了多个不同的数据集.本节介绍最常用的5个基准数据集,即MS COCO[111],Flickr8K[41],Flickr30K[112],Visual Genome[113],IAPR TC-12[114].
3.1.1 MS COCO数据集
MS COCO数据集[111]是一个用于图像描述生成、物体识别、语义分割任务的大型数据集,通过在自然环境中收集日常复杂场景和常见物体的图像而创建,包含用于识别和分割等任务的多种特征.该数据集规模在不断地扩充,目前图像数量已超过300 000幅图像,每幅图像包含至少5个人工标注的参考描述语句,共有91个分类,其中82个分类每个都超过5 000个实例物体.由于该数据集的规模大、图像内容复杂,已成为图像描述生成任务中最常用的数据集.
3.1.2 Flickr8K数据集
Flickr8K数据集[41]包含从Flickr提取的8 000幅图像,主要内容包括人类和动物,每幅图像都包含来自于亚马逊众包服务的5条描述语句.在图像标注过程中,工作人员要求专注于图像本身并描述其内容,而不考虑图像中拍摄的文本.Flickr8K数据集中共有8 000幅图片,其中训练集6 000幅,验证集和测试集各有1 000幅.
3.1.3 Flickr30K数据集
Flickr30K数据集[112]从Flickr8K数据集扩展而来,是一个用于图像描述生成和语言理解的数据集.该数据集包含了31 783幅图像,每幅图像包含5条描述语句.图像内容主要涉及人的日常生活和运动等,且不为训练、测试和验证提供任何固定的划分.该数据集还包含公共物体检测器、颜色分类器,并有选择较大物体的偏向.
3.1.4 Visual Genome数据集
图像描述生成不仅需要识别图像的可视物体,还需要推理它们之间的相互作用和属性.与前面数据集的描述语句针对整个场景不同,Visual Genome数据集[113]针对图像中的多个区域有单独的描述语句.该数据集有7个主要部分:区域描述、物体、属性、关系、区域图、场景图和问答对.数据集包含的图像数量超过108 000幅,每幅图像平均包含35个物体、26个属性和21个物体之间的成对关系.
3.1.5 IAPR TC-12数据集
IAPR TC-12数据集[114]收集了运动、相册、动物、风景等自然场景图像共20 000幅,图像中通常包含多个物体,每幅图像都包含多种语言(包括英语、德语等)的描述语句.该数据集用于图像自动标注任务时,通常经过预处理后保留其中19 627幅,共包含291个语义标签,平均每幅图像4.7个标签,划分为17 665幅训练图像和1 962幅测试图像.
3.2 评估措施
由于图像描述生成系统输出的自然语言描述的复杂性,评估其性能非常困难.为了评估生成的语句在语言质量和语义正确性方面是否与人类感知一致,研究者设计了多种度量指标来评估生成语句的质量,包括BLEU(bilingual evaluation understudy)[115],ROUGE(recall-oriented understudy for gisting evaluation)[116],METEOR(metric for evaluation of translation with explicit ordering)[117],CIDEr(con-sensus-based image description evaluation)[118],SPICE(semantic propositional image caption eval-uation)[119]等.其中BLEU和METEOR来源于机器翻译,ROUGE来源于文本摘要,而CIDEr和SPICE是专门为评估图像描述语句提出的.
3.2.1 BLEU
BLEU[115]是用于评估机器生成文本质量的度量指标,用候选语句的可变短语长度来匹配参考语句,通过计算精确率以衡量它们的接近程度.换言之,BLEU度量是通过n-gram模型比较候选语句和参考语句来确定的,使用unigram将候选语句与参考语句进行比较计算BLEU-1,使用bigram将候选语句与参考语句进行匹配计算BLEU-2,以此类推.根据经验,确定最大值为4的序列,以获得与人类判断最佳的相关性.对于BLEU指标,unigram分数用于解释语句相似度,而较高的n-gram分数用于解释语句流畅性.但是,BLEU度量不考虑语法正确性,且受到生成文本大小的影响,在生成的文本很短时BLEU分数通常较高.因而在某些情况下,BLEU分数高并不意味着生成了高质量的文本.
3.2.2 ROUGE
ROUGE[116]通过计算召回率来衡量文本摘要质量,将单词序列、单词对和n-gram与人类创建的参考摘要进行比较.根据计算方法的不同,ROUGE又可分为ROUGE-N,ROUGE-L,ROUGE-W,ROUGE-S这4种类型,不同类型的ROUGE指标用于不同的任务.其中ROUGE-L旨在评估机器翻译的充分性和灵活性,该度量指标采用候选语句和参考语句之间的最长子序列来度量它们在语句层次上的相似性.由于该度量指标自动包含序列中最长的公共n-gram,因而可以自然地捕获语句级结构.
3.2.3 METEOR
METEOR[117]是用于评估自动机器翻译的度量指标,它首先在候选语句和人类标注的参考语句之间进行广义unigram匹配,然后根据匹配结果计算得分.计算涉及到匹配词的精确率、召回率和对齐率.在多个参考语句的情况下,所有独立计算出的参考语句中的最佳分数作为候选的最终评价结果.该度量指标的引入是为了弥补BLEU度量的不足,因为BLEU度量仅基于n-gram匹配的精确率得到.
3.2.4 CIDEr
CIDEr[118]是评估图像描述质量的自动一致性度量指标,衡量图像描述语句与人类标注的参考语句的相似度.该指标将候选语句中的n-gram出现在参考语句中的频率进行编码,并使用TF-IDF(term frequency-inverse document frequency)对每个n-gram进行加权来计算相似度,从而能够体现生成的图像描述与人类感知的一致性.这个度量指标的目的是从语法性、显著性、重要性和准确性等方面对生成的描述语句进行评估.
3.2.5 SPICE
SPICE[119]是基于语义命题内容的图像描述度量指标,它将候选语句和参考语句都转换为场景图表示,通过场景图计算指标得分来评估描述语句质量.场景图对图像描述中的物体、属性和关系进行了显式编码,并在编码过程中抽象出自然语言的大部分词汇和句法特征.
综上所述,各个性能度量指标都有各自的适用范围和优缺点,表1对此作了总结和比较.

Table 1 Comparison of Advantages and Disadvantages of Performance Metrics表1 性能度量指标优缺点比较
3.3 典型方法性能比较
本节以最常用的MS COCO和Flickr30K数据集为基准,报告了一些典型方法在这2个数据集上得到的性能指标数据,并做简要分析.
3.3.1 MS COCO数据集上的性能比较
MS COCO数据集是目前图像描述生成领域应用最广的基准数据集,大多数方法都报告了在该数据集上的实验结果.由于基于模板的方法和基于检索的方法性能普遍较低,而且大部分都没有使用基准数据集和评估措施进行实验,因此这里选取进行性能比较的典型方法都是基于深度学习的方法.所选方法包括:基于多模态空间的方法BRNN[48]和m-RNN[49];基于视觉空间的方法NIC[51],gLSTM[53],Stack-Cap[56];基于语义空间的方法ATT-FCN[58],Att-CNN+LSTM[59],RFNet[64],SGAE[68];基于注意机制的方法Soft-Attention[70],Adaptive[72],SCA-CNN[73],RA+SS[74],Up-Down[77],AoANet[79],VASS[85];基于模型优化的方法SCST[89]和G-GAN[92];基于复合架构的方法SCN-LSTM[104].所选19种典型方法在MS COCO数据集上的实验结果如表2所示:
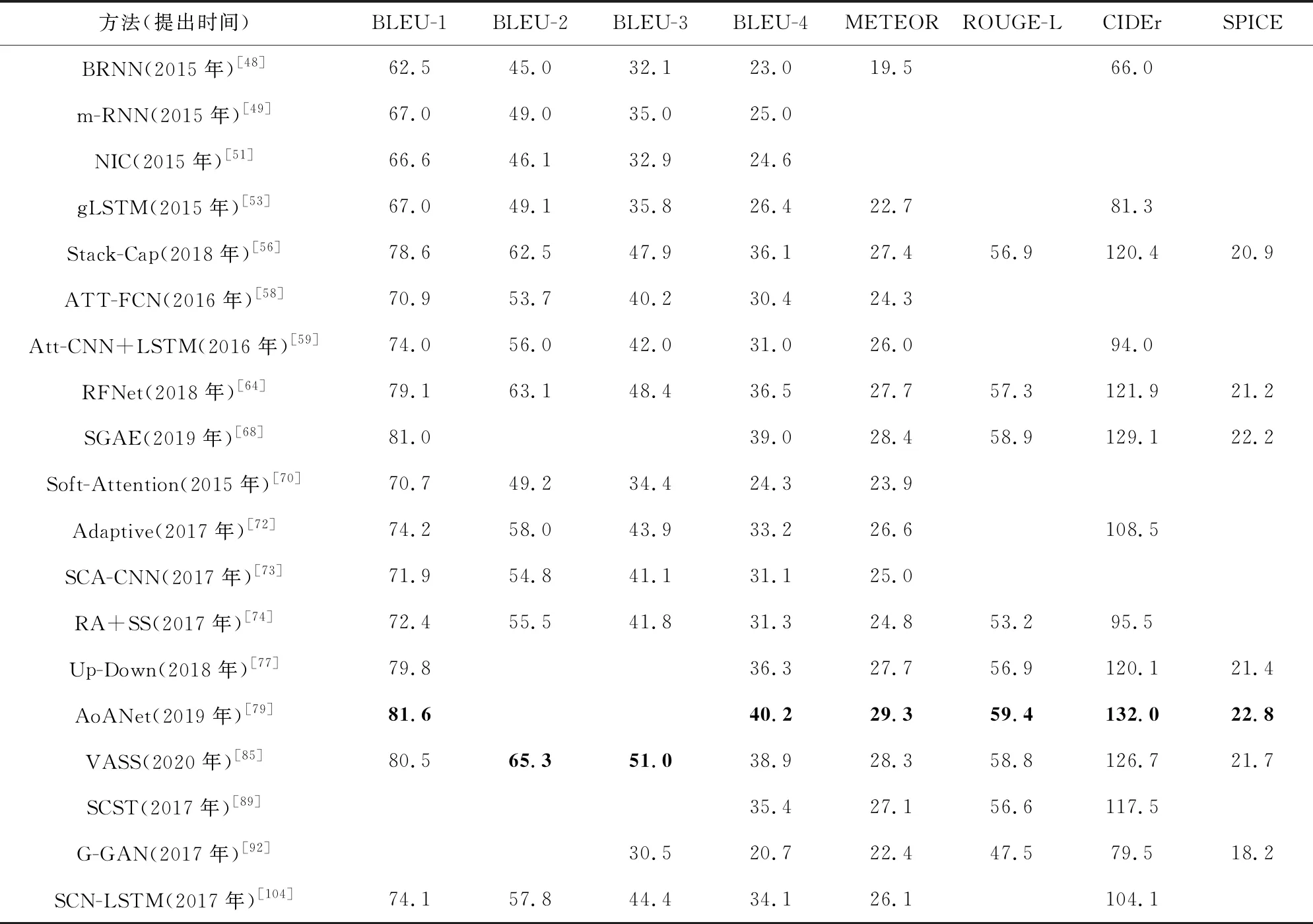
Table 2 Performance Comparison of Various Typical Methods on MS COCO Dataset表2 在MS COCO数据集上各种典型方法的性能比较
从表2中数据可以看出,图像描述生成的性能指标大致随着时间的推移逐步升高.近几年基于注意机制的方法AoANet,VASS,Up-Down和基于语义空间的方法SGAE,RFNet性能指标要明显高于前几年的方法,其中AoANet的大部分指标在表2中最高.这19种方法大都设计了良好的网络范式,融合了多种图像特征生成复合的语义表示,同时结合不同的注意机制来指导描述语句的生成.这说明融合多种图像特征和集成多级注意的方法对于生成准确的描述语句是行之有效的,也是未来的发展趋势.基于视觉空间的方法Stack-Cap和基于强化学习的方法SCST的性能指标也相当高,这表明对视觉空间进行改进的方法可以获得良好的性能,同时也表明强化学习对于提升描述语句的准确性非常有效.此外,尽管G-GAN方法的性能指标相对较低,但基于无监督学习的方法注重生成描述语句的多样性和自然性,当前的性能指标并不能完全衡量其描述语句是否符合人类感知.
3.3.2 Flickr30K数据集上的性能比较
表3给出了一些典型方法在Flickr30K数据集上的实验结果.由于这些方法都没有报告SPICE的数值,所以只列出了其余7个性能指标的数值.此外,3.3.1节中的Stack-Cap,RFNet,SGAE,AoANet,Up-Down,SCST方法都没有报告在Flickr30K上的实验结果,因此在表3中没有列出这些方法.
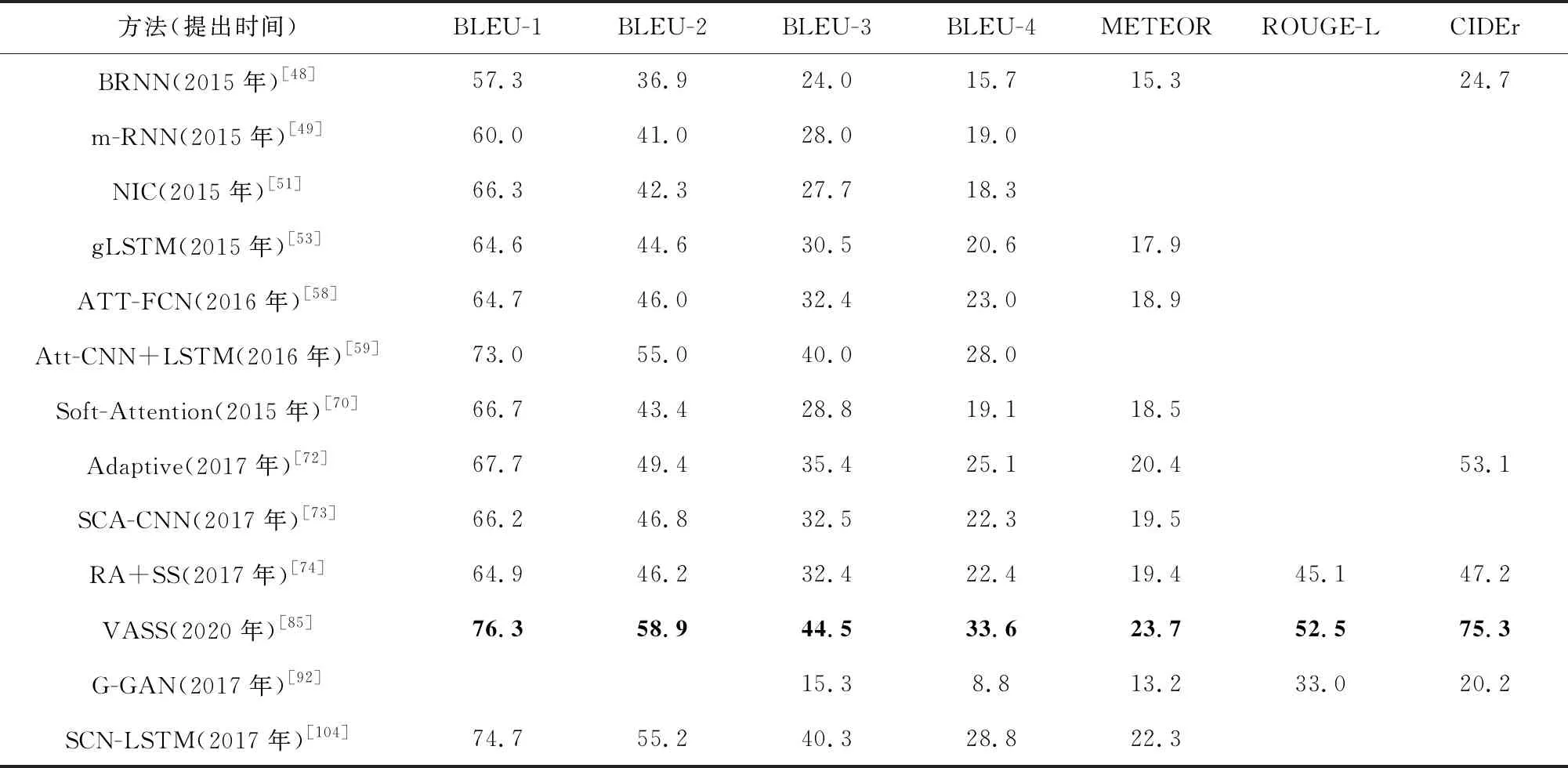
Table 3 Performance Comparison of Various Typical Methods on Flickr30K Dataset表3 在Flickr30K数据集上各种典型方法的性能比较
从表3可以看出,在Flickr30K数据集上,基于注意的方法VASS在这些典型方法中获得了最高的性能指标,而基于复合架构的方法SCN-LSTM性能指标也相当高.这说明基于注意机制的方法和基于语义空间的方法仍然将在未来的研究中占据重要地位,而复合架构在图像描述生成的发展中具有较大的潜力,其大致趋势与在MS COCO数据集上的实验结果一致.
4 未来趋势展望
图像描述生成近年来受到了研究者的广泛关注,收获了很多重要成果.然而,尽管目前基于深度学习的主流方法获得了有效的结果和良好的性能,但仍然面临着多方面的重大挑战,也是未来的重点研究方向和发展趋势.
4.1 识别细粒度语义生成区分性强的图像描述
基于深度学习的方法能够识别图像中的一些重要语义概念(如老虎、鸟等),但是对于细粒度语义概念(如东北虎、夜莺等)的识别仍然是个难题,需要在物体检测、语义分割和图像自动标注等课题的基础上寻求解决方案.图像细粒度语义识别的重大挑战主要体现在类间差异小和类内差异大,如何检测并学习图像中的物体及其关键部件成为关键问题[5].此外,细粒度语义标注的成本要高于传统语义标注,难于获得大规模训练集,这使得很多强监督方法难于实际应用,需要借助弱监督方法完成识别任务.在图像描述生成任务中,识别细粒度的图像语义对于生成更准确更具区分性的描述语句有重要意义.
4.2 改进语言模型生成语法正确的图像描述
目前的图像描述生成方法大都采用LSTM等深度神经网络模型逐词生成描述语句.但这类模型并没有完全解决长期依赖问题,且本身的顺序特征阻止了并行化,使得计算比较耗时.Transformer模型[30]使用注意结构取代LSTM,减少了计算量同时提高了并行效率,但这个思路还没有在图像描述生成任务上得到广泛应用.在图像描述生成过程中,引入新的有效的语言模型对于生成语句的语法和语义正确性无疑能起到重要作用.但是,改进语言模型本身是个难题,需要广大自然语言处理领域的研究者通过长期的工作逐步解决问题.
4.3 探索学习架构生成完整细致的图像描述
目前图像描述生成的通用学习架构是编码器-解码器架构,将图像描述生成过程视为从图像“翻译”到文本的过程.这种架构通常将图像编码为中间向量再以此作为依据进行解码,中间向量包含的信息至关重要.如果中间向量包含的信息不足,将会导致生成的语句信息不完整.所以,这种架构有很大的改进空间,可以考虑改进编码器端获取更优的中间向量,也可以考虑改进解码器端以便更充分地利用中间向量包含的信息.此外,编码器-解码器架构并不是唯一可行的学习架构,提出全新的学习架构显然也是改善图像描述质量的途径.基于复合架构的方法强调识别复杂图像中的细节,取得了一些进展,但还没有重大突破.对于学习架构的探索,仍然是图像描述生成领域的重要课题.
4.4 利用多级注意机制生成语序合理的图像描述
注意机制在很多计算机视觉的任务中都得到了很好的应用,也已经证明能够显著提升图像描述生成的性能.但目前多数注意模型只关注图像中的局部实体特征,没有关注实体间的相互关系,生成的图像描述存在语义不够完整和语序不合理的问题.为此,需要进一步挖掘不同层级的注意并加以整合,如协同单词级和语句级的注意[80]、结合视觉注意与语义注意[85]等方法都是建立在整合不同层级注意的基础上.如何设计整合不同层级注意并使它们协同工作的机制,以生成语义和语序更合理的图像描述,仍然是图像描述生成领域的重点研究方向.
4.5 集成外部知识推理生成新颖自然的图像描述
现有的方法存在生成的图像描述与原始描述过于相似的问题,且不具备像人类一样的推理能力,难于发现图像中隐含的新物体和新行为.然而,仅仅依靠图像的视觉内容本身,很难解决这个问题.一个可行的思路是在图像描述生成方法中引入外部知识并进行适当地推理[63],模仿人类自主学习新知识的方法和能力,使得生成的描述语句新颖自然,从而实现初步的视觉推理.如何引入外部知识,并通过知识图谱等方法集成到现有的学习框架,使其具备从局部到整体、从属性到语义的视觉推理能力,是图像描述生成未来研究面临的重大挑战.
4.6 基于模型优化生成准确多样的图像描述
现有的图像描述生成方法通常要依赖大量的图像-语句对样本进行训练,才能取得较高的性能.然而,人工标注费时费力,难以获得大量的有标签样本,这使得图像描述的性能容易出现瓶颈.因此,基于无监督学习的方法扩充训练集及基于强化学习的方法优化系统的评估指标成为突破性能瓶颈的重要思路.目前,生成的图像描述在各种评估指标上都已经很高,但这很大程度上是因为生成的图像描述可区分性不够强.一方面,对于视觉内容有差异的图像,生成的描述语句差异性不高,即生成语句的语义粒度不够细致、描述不够准确;另一方面,对于同一幅图像,生成的描述语句相似度很高,即难于生成多样化的描述语句.基于无监督学习的方法可以充分利用无标签图像扩充训练集,生成多样化的描述语句;而基于强化学习的方法则可以利用奖励函数指引图像描述生成的方向,使得系统生成更准确可靠的描述语句.
4.7 设计更符合人类感知的性能评估措施
目前图像描述生成领域有BLEU,ROUGE,METEOR等多种常用的性能评估措施,但这些措施有各自的适用范围,不能完全反映生成描述语句的质量.即使性能指标数值很高的系统生成的描述语句也仍然可能不符合人类感知,也就是说评估措施与人类判断之间仍然存在着鸿沟.为缓解这个问题,一方面可以利用强化学习技术缩减评估措施与人类感知之间的差距,另一方面则需要设计出更好更全面的评估措施,既能反映描述语句质量(如语句多样性度量),也能尽量与人类判断保持一致,从而能够更客观地反映图像描述生成系统的优劣.
5 结束语
综上所述,图像描述生成是一个极具挑战性的课题,既要考虑图像视觉理解的全局完整性和局部显著性,也要考虑生成描述语句的语法正确性和表达自然性,还有可能需要指出图像中不存在的物体和行为,生成有新意或者有风格的描述语句.在现有的技术条件下,为了最大限度地满足用户需求并生成更符合人类感知的描述语句,需要在多个方面开展更深入的研究:充分学习图像中的视觉内容,获得不同粒度的语义信息;改进语言模型保证生成语句的正确性;探索新的学习架构提升描述语句的质量;结合不同层级的注意信息指导语言生成;在外部知识的帮助下,借助知识推理增强模型功能;利用强化学习和无监督学习技术进一步优化模型;设计良好的性能评估措施,使得系统对生成语句的判断尽量客观并与人类判断保持一致.
