基于深度学习的数据库自然语言接口综述
2021-09-13徐思涵蔡祥睿温延龙袁晓洁
潘 璇 徐思涵 蔡祥睿 温延龙 袁晓洁
1(南开大学计算机学院 天津 300350) 2(南开大学网络空间安全学院 天津 300350) 3(天津市网络与数据安全技术重点实验室(南开大学) 天津 300350)
关系型数据库自1970年[1]被提出以来,经过数十年的发展,已然成为数据存储的主流工具,被广泛应用在政府部门以及商业、学术等各种领域中.结构化查询语言(structured query language,SQL)是用户或应用程序与数据库交流的重要手段.自然语言接口的出现,打破了用户和终端之间的交互屏障,是人工智能研究领域的重要分支之一,其中面向数据库接口的实现也受到了研究人员的广泛关注.数据库自然语言接口(natural language interface to data-base,NLIDB)是一种通过自然语言实现关系数据库查询的接口,它能消除用户在查询数据库时遇到的技术壁垒,即解除了用户必须掌握SQL语法知识的限制,实现了通过自然语言的描述就可以查询数据库的功能.总的来说,NLIDB的目标就是实现自然语言查询到SQL的转化.
自20世纪70年代[2]以来,就有LUNAR[3],LADDER[4],Chat-80[5],ASK[6]等早期NLIDB系统相继问世.这里引用Affolter等人[7]的总结,可以将这些系统根据技术方法划分为4类:1)基于关键字(keyword-based)的系统,以SODA[8],QUICK[9]等为代表.这类系统以数据库中的基本数据与元数据的倒排索引作为检索对象,将它们和自然语言查询进行匹配,以识别出查询中提到的关键字.但是其缺点在于该方法无法识别出自然语言中未直接出现的潜在语义.2)基于模式(pattern-based)的系统,以QuestIO[10],NLQ/A[11]等为代表,这类系统能够将稍复杂的自然语言模式映射到预先指定的查询句式中.3)基于解析(parsing-based)的系统,以ATHENA[12],NaLIR[13]等为代表,这类系统引入了更多自然语言处理技术,比如借助语法分析树解析自然语言问句.因此这类方法能将问句中的语义映进一步射到预设的SQL模板中.4)基于语法(grammar-based)的系统,以Ginseng[14],TR Discover[15]等为代表,这类系统具有一组预设的语法规则,用它限制用户的输入行为,以形成格式规范的自然语言查询,易于系统分析.这4类方法可以归结为基于规则(rule-based)的生成方法.基于这4类方法的系统只能根据固定的数据库格式以及预设的查询模板,才能实现SQL的输出.但是自然语言中普遍存在多歧义和描述多样性现象,这就会导致在实际应用中预设的匹配规则或查询模板无法覆盖到更多更复杂的自然语言查询中.上述方法大部分只能处理固定领域的数据库,即NLIDB只能根据固定的表结构来设计实现,所以系统一般无法移植到其他数据库中使用.至今还没通用的商业化解决方案或原型系统,其主要原因还是由于目前尚无适用于不同数据库表结构的NLIDB[16].
近年来深度学习的应用极大提高了语音识别、视觉物体识别、生物信息等许多人工智能领域的技术水平[17].深度学习模型基于神经网络实现,而其中一类重要的网络结构——循环神经网络(recurrent neural network,RNN)在处理如文本和语音等序列数据中发挥着重要作用.基于RNN的编码器-解码器(encoder-decoder)框架是一种端到端的深度神经网络结构,被广泛应用于机器翻译、语义分析、文本摘要、对话生成等许多自然语言处理的任务中.其中语义分析(semantic parsing)任务的目标是将自然语言转化成逻辑形式(logical form).这种逻辑形式是以自然语言作为驱动的语义表示形式,能够映射自然语言的含义[18].比如Lambda Calculus,SQL和机械控制指令等程序语言,或者Python,Java等通用编程语言,都属于逻辑形式的范畴.因此基于编码器-解码器框架实现的NLIDB可以视为一类语义分析模型,输入为自然语言查询,通过编码器-解码器的分析,最终输出语义对应的SQL,总体流程如图1所示.
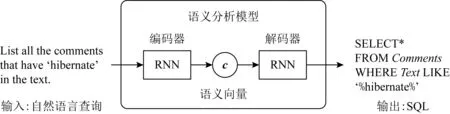
Fig.1 NLIDB based on encoder-decoder framework图1 基于编码器-解码器框架的NLIDB
编码器-解码器框架中,编码器将自然语言查询转化成中间语义向量,解码器再将中间向量解码成逻辑形式.这样的处理过程能降低语义分析模型对预设词汇、模板以及人工特征的依赖,可以让模型不再局限于固定领域的数据库或特定的逻辑形式表达.因此深度学习模型能够让支持跨数据库或跨语言NLIDB的实现成为可能.
虽然已有相关综述总结了机器学习在数据库系统中的应用[19],但是并没有专门针对NLIDB进行探讨.因此本文对近年来利用深度学习方法实现NLIDB的成果进行梳理,尤其针对输入是自然语言、输出是SQL的这类模型进行总结.由于还有一类研究是以执行数据库查询后的结果作为模型的输出目标[20-21],这类研究并不作为本文讨论的重点,因为从方法的可扩展性来看,以查询的逻辑形式作为目标输出,可以在任意时间以及面对任意量级的表内容的情况下实现方法的重用[22].
相关文献成果的搜索与分析过程如图2所示:首先在Google Scholar中分别以“natural language+neural network+sql”“natural language+deep learning+sql”“deep learning+text to sql”这3种关键词配置方案初步检索出209篇文献;再分别以实现途径是深度学习模型和输出目标是逻辑形式作为进一步判断标准,筛选出87篇文献;然后以解码方法为依据,将成果归纳成4个解码类别,分别为基于序列的生成方法、基于固定模板的生成方法、框架-细节的分阶段生成方法和基于语法的层级式生成方法.
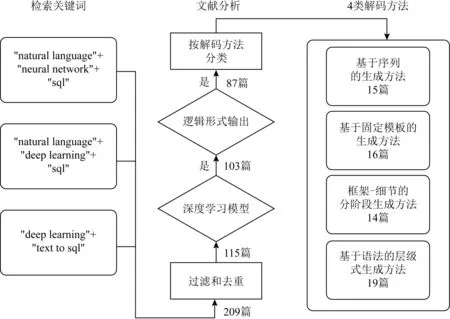
Fig.2 Literature search and analysis process图2 文献查询与分析流程
1 基于深度学习的NLIDB任务描述和总体流程
1.1 任务描述
基于深度学习的NLIDB可以描述为,以自然语言问句(natural language question,NLQ)以及其他已知信息(如数据库表结构信息)作为输入,通过深度学习的语义分析模型生成与NLQ语义对应的SQL.SQL是一种用于数据库交互的程序设计语言,能实现对关系数据库中数据的存取、查询和更新等管理操作.以数据集WikiSQL[23]为例,其中的SQL一般遵循基本查询句式:“SELECTaggselcolWHEREwhecolopval(ANDwhecolopval)*”.其中的几个变量有:“agg”为COUNT,MIN,MAX等聚合函数关键字,可以为空;“selcol”表示SELECT子句中被选中的列(SELECTcolumn,selcol);“whecolopval”表示WHERE子句中的1个查询条件,其中“whecol”为查询条件中被选中的列(WHEREcolumn,whecol);“op”表示=,<,>等运算符;“val”表示条件值;“*”为WHERE子句中条件个数大于1的情况.例如已知NLQ为“What is the height of Willis Tower in Chicago?”,以及已知数据库中有如下列:Rank,Name,Location,Height(ft),Floor,Year,则这句NLQ对应的SQL为“SELECTHeight(ft)WHEREName=‘Willis Tower’ANDLocation=‘Chicago’”.Spider[24]数据集中除了包含SQL的基本查询句式,还会涉及GROUP BY,HAVING以及嵌套查询等查询句式.NLIDB实现SQL的生成不同于Python等编程语言的生成,其数据库中的表结构也是已知信息,因此可以根据设计的需要而作为模型的输入信息.
NLIDB的实现具有一定挑战.1)查询关键词或数据库表信息有时不会在NLQ中直接出现,因此容易造成查询意图与SQL元素的错误匹配.比如有NLQ:“Show the names of students who have a grade higher than 5 and have at least 2 friends.”,其对应的SQL中,就包含GROUP BY子句:“GROUP BYfriend.student_idHAVING COUNT(*)>=2”,而查询关键字GROUP BY或列名student_id没有在NLQ中显式地体现出来.这项挑战的本质在于,SQL是以有效查询关系数据库为目的而设计的,并不具备自然语言意义表征的功能.因此NLIDB需要具有识别NLQ中无法显式映射到SQL的那部分信息的能力.2)NLIDB需克服以往系统只能处理特定领域数据库的问题,这就需要深度学习模型具备解析未见过的NLQ或数据库表的泛化能力.这项挑战的困难在于模型在生成SQL的过程中,比如遇到列名的输出时,需处理未能在训练集中出现的领域外(out-of-domain,OOD)词汇,而OOD词汇在已经训练好的模型中缺乏准确的相关表示[25],这项挑战也被称为零样本(zero-shot)挑战.
1.2 深度学习方法与传统方法的对比分析
1)方法对比
基于深度学习方法相比传统rule-based方法,其最大的优势在于前者能够支持更丰富的自然语言变化环境[7].由于rule-based方法在生成SQL时,需要遵循预先设定的规则和查询框架.因此对于NLQ中丰富而变化的查询语义,rule-based方法理解起来是比较局限的,只能利用附加方法弥补缺陷.例如Li等人[26]针对系统在遇到无法理解的查询语义时,采用生成查询建议的方式引导用户重组查询,直至查询符合规范为止.而基于深度学习方法的NLIDB能够处理更为灵活多变的查询描述,不仅能解析自然语言中的隐含语义,而且具有更强的NLQ到SQL的组件映射能力,从而使生成的SQL准确度获得大幅提高.为了比较这2种方法,将Kim等人[27]的比较实验进行整合,分别在2种方法中选择2个模型进行比较,如表1所示.比较所用的数据集为WikiSQL,其中Accall是在生成的结果中,语义正确的SQL在所有结果中的比例.Accselcol,Accagg,Accwhecol,Accop,Accval分别表示SELECT子句的列、聚合函数、WHERE子句的列、运算符和条件值这5个SQL元素的生成准确率.

Table 1 Accuracy Comparison of Deep Learning-Based Methods and Rule-Based Methods表1 深度学习方法与rule-based方法的准确率比较
从表1中可以看出,深度学习方法在所有评估指标中的结果都远高于rule-based方法,从而展现出前者在语义映射中的准确度高、稳定性好的优势.
2)新的任务挑战
深度学习方法较传统rule-based方法,存在新的挑战:①基于深度学习方法的NLIDB是一类有监督的机器学习模型,因此对训练数据的依赖性较强.为了保证生成SQL的准确率,需要向模型提供大量样本,也就是由NLQ和与之语义对应的SQL组成的训练数据.②在模型的训练方面,基于深度学习的NLIDB较rule-based方法包含更多的训练参数,比如词向量或神经网络参数等.因此模型的计算需要花费更久的时间,以及占用更多的内存空间.③从研究重点来看,rule-based方法侧重词表的质量、SQL句式模板的设计以及NLQ的特征转化等;而深度学习方法是基于编码器-解码器的表示学习框架,其研究重点转化为自然语言的编码表示方法、解码过程中的SQL生成方法、多方法的融合技术以及神经网络优化技术等,所以研究内容更为广泛和开放.
1.3 基于深度学习模型的NLIDB处理流程
利用深度学习模型实现NLQ到SQL的转化总体分为5个步骤,如图3所示:
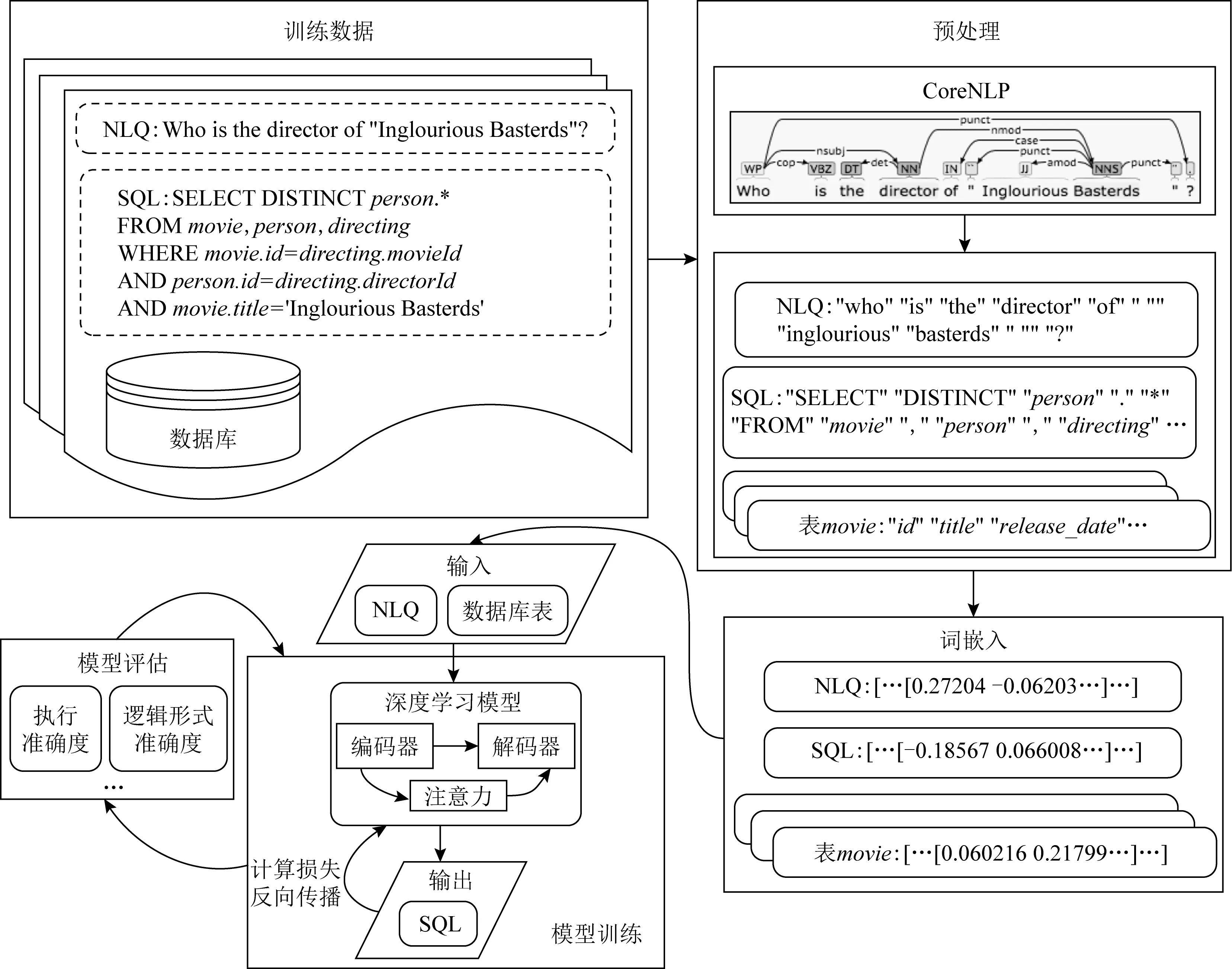
Fig.3 NLIDB implementation process based on deep learning framework图3 基于深度学习框架的NLIDB处理流程
1)准备数据集.数据集包括作为输入信息的NLQ、目标数据库以及作为监督信息的SQL.数据集按照一定比例分割成训练集、验证集和测试集.
2)预处理.以英文数据集的处理为例,在预处理中首先对文本分别进行小写化、纠正拼写、提取词根等处理,再利用分词工具(如Stanford CoreNLP[31])做分词处理.分词后样本中的每个原子级表达为一个标记(token).
3)词嵌入(word embedding).将分词化后的样本进行词嵌入处理.比如使用预训练模型Glove[32]对所有标记初始化为词嵌入向量.嵌入向量可以根据模型的设计需要同编码器-解码器一起训练,也可以将其固定不进行训练.
4)训练深度学习模型.对编码器-解码器使用基于梯度的优化方法(如Adam[33]或RMSProp[34]等)进行迭代训练,编码器的输入端一般为NLQ和数据库信息,解码器输出SQL.数据集中的SQL作为监督信息用于目标函数的计算.
5)模型评估.根据模型输出的SQL,利用执行准确度或逻辑形式准确度等指标评估模型.
2 数据集与评估方式
2.1 数据集
深度学习模型需要大规模语料数据作为驱动而实现训练,本节总结了可以作为NLIDB模型训练的数据集,共计20个,每个数据集除了NLQ和数据库,都明确提供了查询语句的逻辑形式描述,基本情况如表2所示.

Table 2 Basic Information of the Datasets表2 数据集基本情况
以下分别从单领域和跨领域数据集、语言类型、查询句式以及语义分析任务这4个角度对数据集进行介绍.
1)单领域和跨领域数据集
单领域数据集是指全部样本建立的查询均面向固定的表结构,因此数据集涉及的领域较为封闭,这使深度学习模型有足够能力学习针对特定领域数据库的信息表示.比如ATIS[35]是航班预定主题的数据集,一共涉及32张表,所有的样本全部在这些表的基础上建立.交叉领域数据集(cross-domain)中,每个样本有各自的数据库结构,比如:WikiSQL[23]数据集中,数据库来自Wikipedia的24241张HTML表格,涉及的主题比较广泛,每个样本建立的查询分别能够对应到数据集中的一个数据库;Spider[24]也是交叉领域数据集,包含了200个数据库,涵盖138个领域.这类数据集也称为zero-shot数据集,因为它需要模型能够在不同领域数据库形成的上下文中,实现NLQ到SQL的语义映射,因此模型应具备处理未知领域数据库的能力.
2)语言类型
从输出的语言类型来看,以上数据集涵盖了多种逻辑形式:比如ATIS[35]是以Lambda Calculus作为目标语言的数据集,之后被Iyer等人[36]改写成了SQL的版本;JOBS[37]则是以Prolog作为目标语言;LC-QuAD[43]是以SPARQL作为目标语言,是以查询DBpedia知识库为目的而设计的数据集.不过目前还是以SQL作为目标语言的数据集居多.从NLQ的语言类型来看,英文数据集居多.针对此现状,Min等人[46]提出了CSpider数据集,该数据集将Spider数据集中的NLQ以中文形式呈现,而数据库部分仍保留原来的英文版本.CSpider作为为数不多的跨语言数据集,为语义分析的研究引入了多语言环境下的跨语言语义理解等有意义的研究方向.1)和2)这2部分的相关总结如表3所示.
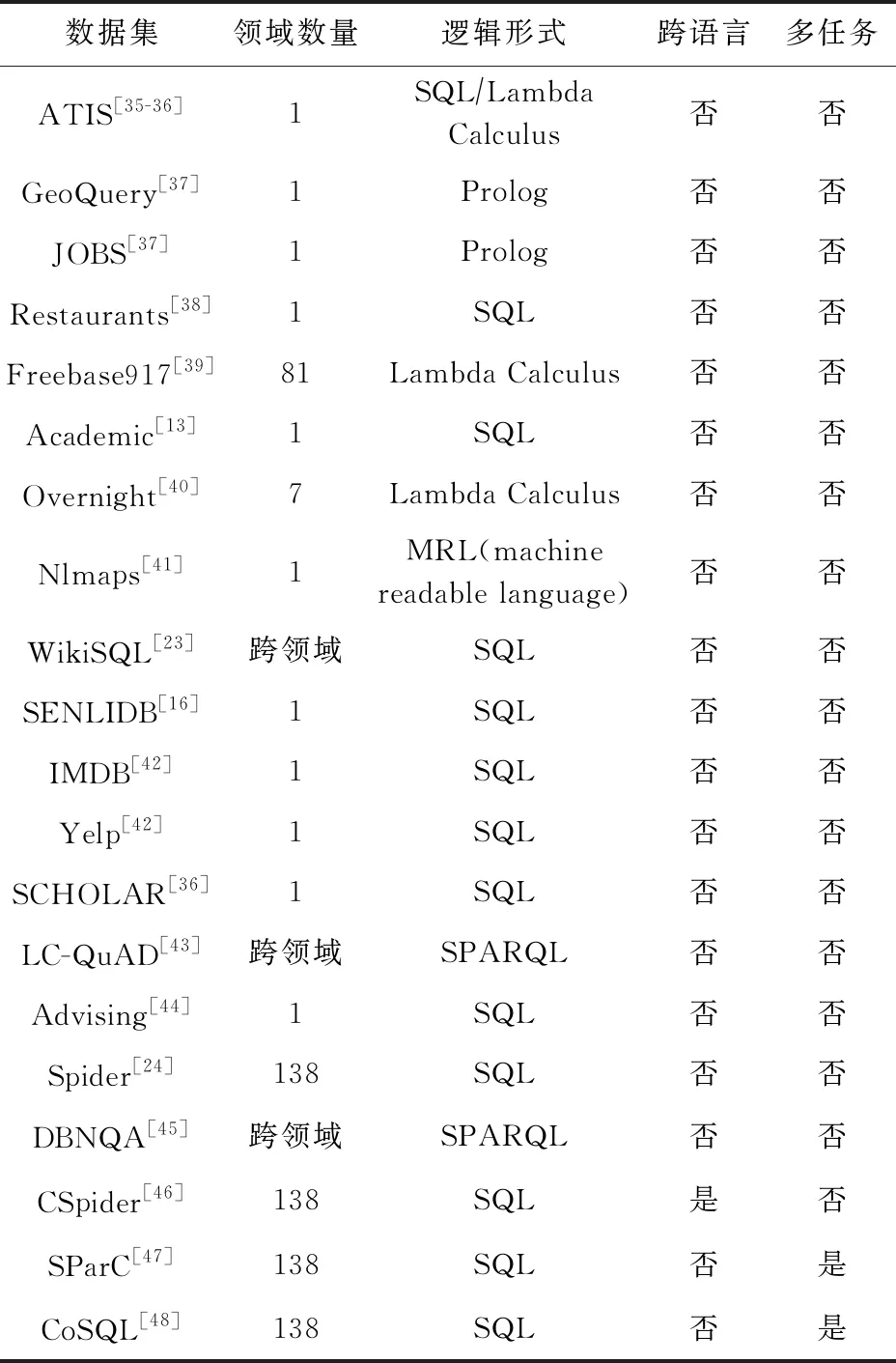
Table 3 Summary of the Datasets表3 数据集总结
3)查询句式
大部分数据集的创建流程是先建立一定数量的SQL句式模板,再通过手工标注填补模板预留的空白形成样本.所以句式模板决定了SQL的复杂程度.比如WikiSQL[23]数据集的样本大部分为SQL的基本查询句式,并且只涉及单表查询,SCHOLAR[36]数据集则预设了22种模板来创建样本,Spider[24]数据集包含的SQL句式较为丰富,除了基本查询句式,还涉及GROUP BY,HAVING,JOIN,INTERSECT,EXCEPT,UNION,NOT IN,EXIXTS,LIKE等子句,此外还有嵌套查询的样本.有的数据集会根据SQL句式复杂程度标注样本的难度等级,比如Academic[13]数据集根据SQL的agg类型和嵌套查询数量,将数据集划分成easy,medium,hard这3个等级,Spider[24]数据集通过综合评估子句类型,将SQL关键字按数量由低至高将数据集划分成easy,medium,hard,extra hard这4个等级,借助难度等级信息有助于全面评估模型在处理不同SQL句式中的语义分析能力.
4)语义分析任务
随着新数据集的不断推出,相关语义分析任务正朝着以下2个方面发展:1)数据集的复杂程度逐渐提高,导致任务的难度也逐渐提高.数据集的发展趋势体现在:单领域向跨领域数据集发展;单语言向跨语言数据集发展;NLQ由单问句向基于交互的问句形式发展,比如SparC[47]数据集改变了以往样本中1个NLQ只对应1个SQL的形式,它将Spider[24]数据集的样本扩展成多轮对话的形式,每个样本包含多个NLQ,并且前后NLQ之间存在上下文依赖关系.因此模型不仅需要提高跨领域、跨语言的语义分析能力,而且在处理对话式数据集时,模型需要追踪历史对话信息来识别当前查询的意图,因此还需具备上下文依赖的对话追踪能力.2)任务类型朝多元化发展.比如模型在处理CoSQL[48]数据集时除了需要处理语义分析任务,还要实现对话生成任务.因此模型需要同时具备3种功能:基于对话跟踪的SQL生成功能;将SQL执行结果反馈给用户的对话生成功能;用户意图的监测与消歧功能.以下针对3)和4)提到的单表查询、多表查询和涉及上下文依赖的数据集,分别进行样本的举例,如表4所示:

Table 4 Examples of Dataset Samples表4 数据集样本示例
2.2 评估方式
模型评估方法的可归纳为7种.评估时通常采取2个以上方法,才能实现多角度的综合评估.
1)执行准确度(execution accuracy)Accex.Accex=Nex/N,其中Nex表示SQL执行结果正确的样本数,N表示样本总数.该方式的缺点在于尽管有的样本执行结果正确,但是无法确保生成的SQL是语义正确的.
2)逻辑形式准确度(logical form accuracy)Acclf.Acclf=Nlf/N,其中Nlf表示能够精确匹配真实值字符串的样本数,N表示样本总数.该方式的缺点在于会过滤掉不能精确匹配,但是执行结果正确的样本.
3)查询匹配准确度(query-match accuracy)Accqm.对于SQL的WHERE子句包含多个条件的情况,条件的顺序并不影响查询的逻辑含义,比如“SELECTnameFROMinsuranceWHEREage>18 ANDgender=‘male’”这句SQL就与“SELECTnameFROMinsuranceWHEREgender=‘male’ANDage>18”在逻辑含义上是完全一致的.因此Accqm是在Acclf的基础上消除了预测值和真实值之间因为条件顺序不一致而被判定为false negative的情况.
4)子句准确度.为了评估模型在不同子句上的表现,需要将完整的SQL拆解成不同子句,分别进行逻辑形式准确度的评估.比如用于评估agg的预测准确率Accagg、评估selcol的预测准确率Accselcol等.由于评估对象的细化,有的模型[16]还利用Precision,Recall,F1分数评估SQL各子句的生成情况.
5)树的精确匹配准确度(tree exact match accuracy)[49].在一些使用抽象语法树(abstract syntax trees,ASTs)实现解码(详见3.4节)的模型中,ASTs是生成SQL过程中的具有树结构的中间产物.该方法是将模型生成的ASTs作为评估对象,真实值则是按照统一方式,将SQL转化成由规范化树节点组成的ASTs,然后对两者的匹配程度进行评估.
6)问题匹配(question match)准确率与交互匹配(interaction match)准确率[47]这2种评估方法适用于评估模型在对话式数据集(如SParC)中的表现.问题匹配准确率是指以问题为单位,其预测正确的问题数量占全部问题数量的比例.交互匹配准确率是指以样本为单位,其预测正确的样本数量占全部样本数量的比例.
7)语言模型评估指标 NLQ到SQL的转化可以看作是一种机器翻译任务,因此有的模型[16,50]通过计算BLEU分数[51]或Perplexity分数评估预测结果.但是由于SQL序列的字符排列顺序对于查询的有效性来说至关重要,因此将BLEU分数作为评估指标并不完全可靠[50].
3 不同解码方法下的SQL生成模型
基于深度学习模型的NLIDB绝大部分是建立在端到端的机器翻译框架之上的,而编码器-解码器作为框架的实现方法,其中针对各个环节的改进成为了NLIDB研究的重点.在相关成果的归纳整理中发现许多模型的优化路线聚焦在解码环节中,因此以解码方法为依据进行分类是有意义的,这样不仅能将目前的研究成果清晰地加以区分,还能够突出每个类别下模型各自的特点.本节根据归纳分析得出的4类解码方法分别进行总结,其概念图如图4所示.

Fig.4 Concept graph for 4 categories of decoding methods图4 4类解码方法概念图
3.1 基于序列的生成方法
3.1.1 方法概述
基于序列的生成方法是利用序列-序列[52](sequence to sequence)的机器翻译框架实现SQL的生成,该方法是将NLQ和SQL均作为序列进行处理.其中NLQ作为输入,分别通过编码器和解码器,最后输出SQL.编码器与解码器是2个互不共享训练参数的多层RNN,大部分采用长短期记忆(long short-term memory,LSTM)[53]单元或者其他门控循环单元(gated recurrent unit,GRU)[54]作为网络基本单元,以1个时间步处理1个标记的方式循环处理整个序列,如图5所示.
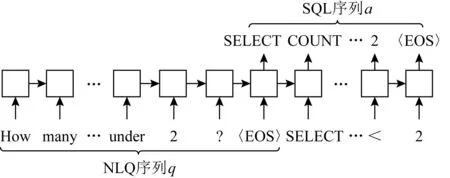
Fig.5 Sequence to sequence model图5 序列-序列模型
图5中编码器处理|q|个时间步,|q|表示输入NLQ中的标记个数,每步编码一个标记,处理顺序可以单向,也可以双向.然后解码器处理|a|个时间步,|a|表示输出SQL的标记个数,每步输出一个标记,处理顺序为单向来保证输出序列需具有可读性.
以LSTM单元举例,编码器的处理流程就是把向量化的输入序列逐一通过LSTM函数计算后得到隐向量(也称中间语义编码向量)的过程.解码器的处理流程为:在每步输出中,根据当前隐向量计算得到输出空间中所有标记的概率分布,然后利用Softmax函数输出最大概率对应的标记.模型的最终输出是最大化SQL序列的条件概率,即输出序列中所有标记的概率之乘积,如式(1)所示.其中q=x1x2…x|q|为NLQ标记序列,a=y1y2…y|a|为SQL标记序列.为了使模型在解码进程中选择性地突出输入序列中不同的细节,通常在每一步解码时利用注意力机制强调输入中特定的局部信息.
(1)
预测阶段中,SQL序列的生成通常使用集束搜索(beam search)完成.由于解码器在输出时对应的词汇表规模比较大,而过于庞大的搜索空间会降低序列输出的准确度.比如Brad等人[16]提到即便只保留了高频词,编码器和解码器对应的词汇表内容也都非常庞大,其词汇量分别是500和2 000.因此基本的序列-序列模型的表现力非常局限,需要改进中间流程或借助其他辅助方法以提高SQL输出的准确度.
3.1.2 改进方法
针对基本序列-序列模型的缺陷,许多研究都提出了改进方案,在此归纳为6个改进方向.
1)限制解码搜索空间.Zhong等人[23]提出了基于Pointer Networks[55]的序列-序列的改进模型.Pointer Networks被广泛应用于文本摘要[56]和问答任务[57]中,它的作用是将输入信息和上下文中的标记拷贝至输出序列中.改进模型通过使用Pointer Networks把解码的搜素空间限制在输入端的NLQ序列范围内,或者还可以扩展为由数据库列名、SQL关键字词汇表和NLQ这3部分组成的搜索空间.这样不仅大幅度降低了解码器的搜素范围,还解决了解码器无法生成词汇表未登录词(out-of-vocabulary,OOV)的问题,类似方法还有Copy Mechanism[58].
Jia等人[59]提出了基于注意力的动态拷贝机制,解码过程中先用Softmax选择下一步输出的“动作”类型,再用选择的动作进行解码.其中“写”动作是指从解码对应的词汇表中进行输出;“拷贝”动作则依据注意力分数拷贝输入序列中的标记.该方法融合了普通序列-序列的输出方法和基于Pointer Network的输出方法,突破了2种方法各自的局限,这种思路也为后续ASTs解码方法的出现奠定了基础.
2)数据库元素的匿名化.Utama等人[60-61]提出了DBPal系统,该系统通过匿名化样本中WHERE子句val的出现方式,来减轻模型的学习负担.DBPal中专门设立了参数处理器,它负责将NLQ中提及的val用占位符替代.模型生成SQL后再将其中的占位符还原成NLQ中的描述.这种处理使模型在训练中能从数据库的实际内容中独立出来,避免了模型无法输出OOD或OOV词汇的问题.
3)强调NLQ中的数据库元素.与匿名化做法不同的是,Wang等人[62]是将NLQ中提及到的数据库列名或条件值(以下统称为数据库元素)标注在输入序列中.标注过程分为2步:第1步借助编辑距离、词嵌入空间距离、元知识匹配等方法搜寻NLQ中所有可能关联的数据库元素,并作为候选;第2步对NLQ构建语法分析树,并对分析树利用最大二分匹配算法得到符合全局一致性的标签分配方案.之后Wang[63]又对标注过程做了改进,先以基于RNN的二分类器逐一对所有与NLQ可能相关的数据库元素进行语义层面判断,确定存在关联的元素集合,然后用对抗文本方法定位这些元素在NLQ中出现的位置来完成标注.
4)数据增强.Jia等人[59]在序列-序列模型的训练阶段引入“数据重组”的数据增强方法,专门建立一个生成模型来扩充训练集的规模,进而更多地向深度学习模型注入先验知识来提高SQL的生成能力.与以往只在输入数据中添加噪音,却不改变输出结果的模式不同,该方法通过设计“上下文无关”的语法作为数据生成规则,为每组样本同步改变输入和输出中的细节内容,从而成为新的样本.
5)神经网络的优化.Yin等人[50]在3个SPARQL数据集(Monument,LC-QuAD,DBNQA)中分别测试了RNN、卷积神经网络(convolutional neural networks,CNN)和Transformer[64]这3类不同的网络架构.在所有数据集的表现中,基于CNN架构的改进模型ConvS2S[65]获得了最高BLEU分数,而且达到了最快收敛速度.ConvS2S的多卷积层的分层处理机制能缓解RNN的长程依赖问题,而且其并行的计算方式在训练速度上占据优势.
Shaw等人[66]在序列-序列模型中引入了图神经网络结构(graph neural network,GNN),编码器和解码器使用了含有多层自注意力的Trans-former[64]结构,其中以GNN层替换掉其中1个自注意力层,使模型能很好地捕捉到序列节点之间的关系.因此基于图的表示方法能将NLQ、数据表实体以及实体间的关系系统地关联起来,消解了语义分析任务中数据库实体和自然语言表达之间的潜在冲突.
6)注意力的加工.TREQS[67]在序列-序列模型中添加了基于注意力的Translate-Edit机制和查表修正这2方面的改进.Translate-Edit使用了2个注意力来引导解码:①通过使用时序注意力[68]来避免解码时重复关注NLQ中的相同信息;②使用动态注意力,以灵活机动的方式强调解码历史中已出现过的表名或列名等数据库信息,以提高生成SQL的逻辑有效性.
Zhang等人[69]的序列-序列模型为了更好地适应SParC[47]数据集的样本特征,做了4处注意力的设计:1)利用联合注意力(co-attention)将NLQ编码和数据表的编码互相添加注意力;2)为当前NLQ编码添加历史NLQ的注意力(turn attention);3)解码过程中,将融合有数据表信息和历史NLQ注意力的上下文向量添加到计算中;4)在解码的上下文向量中添加历史输出的SQL的注意力,这样在新SQL的生成过程中,可以参考到历史SQL的信息.
3.1.3 方法总结
此类方法的缺陷与机器翻译任务表现出来的问题一致,即存在输入序列越长,模型预测效果越差的情况,以及庞大的搜索空间会削弱模型的解码能力等.因此相关改进方案也是针对这些缺点进行优化,比如使用Pointer Networks缩减解码搜索空间的方法,就适用于生成SQL这种需要从输入中摘取信息的任务,同时还能解决模型无法生成OOD和OOV问题.其他优化方法还包括:引入注意力机制突出输入端的局部信息;解码方法向多元形式转化,比如将词汇表抽取和输入序列抽取结合起来进行处理;利用不同程度的数据增强手段加强模型的适应力;强调或弱化NLQ中的数据库元素等.基于上述优化方法,可以使模型从强制学习输入信息的形式特征中解放出来,从而更多地投入到结构特征的挖掘.
3.2 基于固定模板的生成方法
3.2.1 方法概述
SQL作为一种结构化语言,不仅能以序列的方式来处理,还可以将SQL的结构考虑进来作为生成方式,这样较序列-序列模型能更进一步缩减输出空间[23],从而获得更准确、逻辑性更强的结果.本节主要介绍基于固定模板的生成方法,其核心思想是加强SQL生成过程的控制操作,使解码在SQL句式结构的框架指引之下进行输出.
3.2.2 实现方法
此类模型的实现,大部分以基于SQL语法的Slot-filling方法作为基本框架.该方法是指在既定的SQL句式结构(也称为模板)中,通过填补预留的空白来实现SQL的输出.模板的定制是根据任务中具体涉及的SQL句式来设计的,可以是数据库元素,如表名或列名,也可以是SQL关键字,还可以是NLQ中映射到val的关键词序列.
Seq2SQL[23]是Zhong等人根据WikiSQL数据集中的SQL句式特点,在序列-序列模型的基础上添加了输出模板的模型.具体将原来生成完整SQL序列的形式,拆解成为3个子任务,分别为agg的生成、selcol的生成和WHERE子句的生成.其中agg和selcol通过分类器方式输出,WHERE子句仍以序列方式输出.考虑到WHERE子句中,多个条件的顺序无关性特点,Seq2SQL采用了强化学习方式,以最大化累计奖励的方式作为训练方法.
之后Xu等人[29]在Seq2SQL的基础上提出了改进模型SQLNet,在子任务设计上做了进一步的细化,将WHERE子句拆解为4个子任务,分别负责生成WHERE条件数whenum,whecol,op,val.子任务之间存在依赖关系,如图6所示:其中每个虚线框表示一种子任务;每个箭头代表一种依赖关系,箭头的尾部为被依赖的子任务或信息,比如op和val的预测均依赖whecol和输入端的信息.
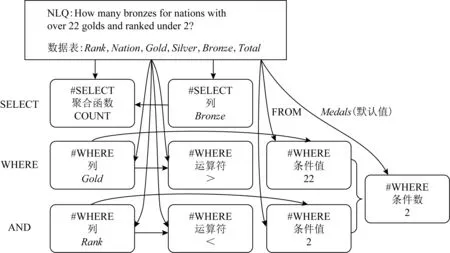
Fig.6 SQLNet’s sub-tasks and their dependencies图6 SQLNet的子任务及其之间的依赖关系
3.2.3 改进方法
1)编码和注意力的优化.SQLNet就是利用基于列的注意力强调了NLQ中涉及列名的信息.之后Gao等人[70]在SQLNet的基础上引入了Bidirectional Attention[71]机制,与列注意力的单向计算不同,它通过对NLQ和列名分别计算前向和后向的2轮注意力来捕捉NLQ和列名之间的关联,实现2种信息相互强调的作用.此外,还在词嵌入中引入了CNN,通过对字符级词嵌入向量使用3个卷积核得到词表示,再和Glove的词嵌入串接起来,形成更为丰富的词向量表示.
随着Transformer[64]和BERT[72]编码模型的相继提出,将序列的上下文表达融入到编码之中,使编码结果获得了带有丰富上下文信息的词向量表示,进而令基于Slot-filling模型的预测效果得到进一步提高.在Hwang等人[73]提出的SQLOVA模型中,将BERT编码NLQ后的输出视为词嵌入向量,再将其作为后续子任务网络的输入.子任务类别与SQLNet类似,每个子任务有自己的编码解码模块,其中负责生成val的子任务从以往的序列化输出,改进为分别预测val在NLQ中的起始与结束的位置的形式.SQLOVA在WikiSQL数据集中的生成准确度达到了该数据集准确度的上限,甚至稍好于人类表现.因此上下文表示技术的引入,大幅提升了模型的语义分析能力.
He等人[74]提出的X-SQL模型中,首先在BERT的选择上,使用了MT-DNN[75]代替了SQLOVA使用的BERT-Large,获得了更好的生成效果.此外X-SQL对列名编码添加了“全局上下文注意力”,也就是在每个列名的编码中添加了上下文信息,以此强化列名之间的关联,扩大了BERT的自注意力覆盖范围,使编码的全局上下文表示能力更加完备.X-SQL在子任务上的设计比SQLOVA更为简单,但是基于以上的优化,使其在WikiSQL数据集上的表现进一步提高.
以往模型在用BERT编码时,习惯将NLQ和所有列名串接起来进行处理,Lyu等人[76]提出的HydraNet模型对此做了改进,将NLQ与每个列名分别串接起来进行编码,这样使每个列名都能融合NLQ信息,可以省去建立用于捕捉NLQ和列名关联的相关处理流程,比如池化或添加编码层的操作.
2)基于模板规则的解码.与3.1.2节1)中提到的分类解码方法类似,此类改进方法是根据SQL句式结构,将解码过程划分成不同阶段分别处理.Wang等人[77]在序列-序列模型基础上,在解码过程中根据WikiSQL数据集中涉及的SQL句式结构来决定每步解码的输出方式,共计3种方式,分别用于输出SQL关键字、列名和val,每种解码的实现方式各不相同.因此若以T1,T2,T3表示3种解码方式,则输出过程就可以形式化表示为 “T1T1T2T1T2T1(T1T2T3)*”.该方法不仅细粒度地控制解码输出,还保证了序列模型的简洁性和语法结构的正确性.
STAMP[78]模型依据SQL语法也将解码设计成为3种生成通道,分别用于SQL关键字、列名和val的生成.每步的输出先利用选择器判断当前的通道,再根据对应的解码方法输出,以此来保证SQL的有效性.
Xu等人[22,79]在序列-序列模型的基础上引入了一组逻辑控制的外部方法,用于追踪解码过程中的语法状态,实现SQL的生成约束.该方法以一组由BNF(backus normal form)范式描述的生成规则为指导,解码环节的每一步输出都会匹配当前标记对应的规则中的符号,以此来跟踪输出结果在语法层面的语义信息.
每步解码时,根据当前对应的语法状态,以一种“输出屏蔽”机制过滤掉无效的搜索空间,来保证SQL输出的有效性和搜索的高效性.基于BNF范式描述的规则是在SQL语法的基础上设计的,具有上下文无关的特征,所以可以视作更细化的模板,如图7所示:

Fig.7 The SQL sketch rules based on BNF[22]图7 基于BNF的SQL模板[22]
3)添加标注.与3.1.2节中3)提到的改进方法类似,此类方法也有在NLQ中添加标注以实现改进.标注信息作为外部知识,能让模型更容易理解输入信息的语义.Yu等人[80]提出的TypeSQL模型就设置了对NLQ注释的预处理操作.注释类型涉及数据库元素、数字、日期和实体名称.其中实体名称的注释,是通过对NLQ关键词查询并匹配至Freebase知识库的方式来实现,匹配类型涵盖人物、地点、国家、组织、运动(WikiSQL数据集含大量体育主题的样本)等.此外,对于数据库元素的注释,不仅包括列名,还通过对表的查询,将NLQ中能匹配到的数据库记录的内容也进行了注释,以上做法将外部知识最大限度地注入到了语义分析流程中.
3.2.4 方法总结
基于固定模板的生成方法是一种比较模式化的解码方法,在处理WikiSQL这类只涉及单表查询和固定SQL句式的数据集中能得到很好的效果,甚至能超越人类表现[73].这类方法的缺陷在于不能生成更多复杂多变的SQL句式.对于新句式的生成,还需要预设更丰富的模板,或者设计更加灵活的生成方法才能满足实际应用中的需求.
3.3 框架-细节的分阶段生成方法
3.3.1 方法概述
在3.2节中,解码利用的模板对训练数据集的SQL句式是强依赖的,这就使模型能够生成的SQL句式比较固定和局限,导致模型即使在某个数据集中具有良好表现,也不一定能在其他数据集中发挥同样的性能.因为NLIDB需要同时保证生成的SQL在句法和语义2方面都是有效的,所以模型可以把这2方面的学习过程从完整的框架中分离开来,通过独立建模的方式分别进行训练.因此本节方法的特点是把SQL的生成分解为2个步骤:第1步是根据NLQ动态识别出粗粒度的SQL框架,作为最终输出的基本句法结构;第2步是利用类似Slot-filling的方法,填补框架中缺失的细节信息.因此模型在第1步中只需要学习SQL的句法结构,比如SQL关键字的排列顺序、不同子句之间的优先顺序以及各种操作符的用法等.由于该阶段只负责生成逻辑层面内容,不涉及细节信息,因此解码时的搜索空间能大幅度缩减;第2步是在第1步的基础上细化结果,因此能保证SQL结果在结构上的规范性.这类方法也经常被利用在NL2API[81]等其他语义分析任务中.
3.3.2 实现方法
根据第1步框架部分生成方法的不同,具体可分为“分类式”和“生成式”这2类.分类式是在已知框架全部类别的基础上,通过分类方法输出框架;生成式则是以序列生成的方式输出框架.
1)分类式框架.Coarse2Fine[30]模型是这类方法的代表.其中分阶段生成模式在WHERE子句的生成中得到了体现.在处理第1步的框架部分时,通过前期对WikiSQL数据集的整理,归纳出35种WHERE子句的句式框架,在具体生成中利用Softmax分类器实现类别预测.在第2步细节生成中,填补框架中的whecol和val这2部分信息.其中在处理whecol时,输入端除了必需的NLQ信息,还引入了第1步生成的框架信息,这样就能在框架信息的指导之下进行解码;val的生成则通过分别输出其在NLQ中的起始与结束的位置的方式实现,因此这部分任务转化成了最大化2个位置索引的概率分布乘积的形式.图8举例说明了一个WHERE子句的生成过程,下方是该句框架部分信息:“WHERE >AND =”,上方是对框架做进一步填充,最终完整的子句为:“WHEREYear_of_Recording>1996 ANDConductor=‘Mikhail Snitko’”.
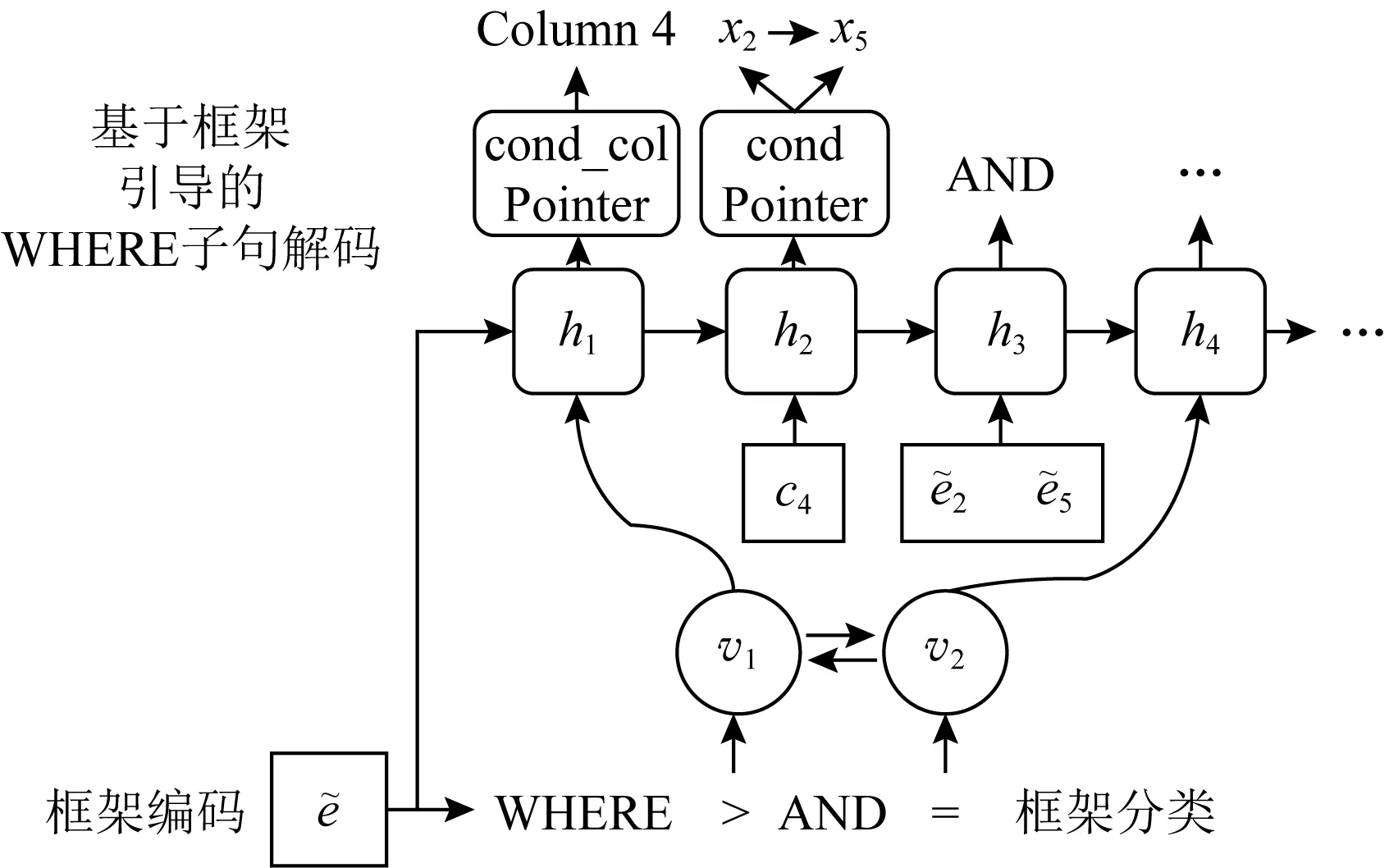
Fig.8 WHERE clause decoding in Coarse2Fine[30]图8 Coarse2Fine中WHERE子句的解码[30]
Lee[82]则采用了“面向子句”的框架生成方式.模型按照句式类型设计了8种可以组成各种SQL句式框架的子模块,分别为SELECT,WHERE,GROUP BY,HAVING,ORDER BY,LIMIT,IUEN,NESTED QUERY.其中IUEN代表INTERSECT,UNION,EXCEPT,NONE这4种查询关键字.在第1步框架生成阶段中,利用Softmax分类器挑选出和NLQ匹配的SQL句式模块组成框架.在第2步面向子句的细节解码过程中,具体填补各模块的细节信息.每个模块对应解码方式各不相同,当解码到嵌套查询NESTED QUERY模块时,先输出“[SUB_QUERY]”作为临时标记,当主句解码完成后,再以上述方式递归地完成嵌套查询的部分.支持生成嵌套查询的模型还有RYANSQL[83],它也是先利用分类方法生成SQL框架,在此基础上提出一种“位置声明码”来定义嵌套查询.解码时先输出位置声明码,再递归生成相应的子查询.基于模块化框架输出方式,将原始SQL细节之间的序列化依赖关系改进成基于上下文的模块化依赖关系,使模型可以学习到结构级别的表达.
2)生成式框架.Hosu等人[84]分别借助2个序列生成模型实现2个阶段的解码.第1步的框架部分,是一个融合了全局注意力的序列生成模型,其中NLQ为输入,SQL框架为输出.涉及具体的表名、列名、常量等非SQL关键字的部分均以占位符输出,如图9所示:

Fig.9 SQL sketch generation based on sequence to sequence method[84]图9 基于序列-序列方法的SQL框架生成[84]
在第2步的细节解码中,以双重编码(dual-encoder)处理输入信息,即编码的输入由NLQ和第1步生成的SQL框架这2部分组成.该阶段只负责生成细节信息,比如填入表名或列名等数据库实体名称.此外模型还可以根据生成的实体名称修正第1步生成的框架结构.
Shi等人[85]提出的IncSQL模型是分阶段生成方法的变形,它可概括为一种“序列-行动”的解析方法.IncSQL中设置了“增长式解析器”,能从“行动仓库”选取需要的“行动”.解码时根据解析策略,利用解析器先增长式地选择需要的行动,再逐步完善行动序列,最终形成序列化的解析决策,即SQL结果.IncSQL结合了序列-序列模型的优势,既包含了序列形式的内部依赖,也实现了模块化输出.
Zhong等人[86]提出的GAZP模型进一步引入了一致性验证机制,其模型由向前的语义分析器和向后的NLQ生成器组成.GAZP首先根据数据库信息和SQL句式采样生成新的SQL,生成器再根据新的SQL输出相应的NLQ,达到扩充样本的目的;之后利用新样本训练负责生成SQL的语义分析器.因此分析器和生成器相辅相成,最终达到“循环一致”的效果.由于GAZP可以对不同的数据库进行采样,所以该模型可用于扩充Spider,Sparc,CoSQL等zero-shot数据集的样本.
3.3.3 方法总结
框架-细节的分阶段生成方法和基于固定模板的生成方法相比,前者的解码输出更为灵活化和精细化,并且能够适应更多的SQL句式结构.Dong等人[30]总结了此类方法的3个优势:1)它能够把抽象的高级语义信息从低级语义中抽离出来,相比基于整句级的一次性输出方式,该方法使解码更易于实现不同粒度语义层面的输出,而且生成的框架信息也更为紧凑;2)2步生成方法更易于捕捉SQL句法的语义框架,虽然不同样本中的细节内容也不尽相同,但是在具有相同句法框架的样本之间,其抽象结构是可以共享的;3)第1步生成的框架信息,能够让解码器提前掌握最终结果的基本概况,它可以作为全局上下文信息,辅助细节部分的生成.不过该方法的缺点在于,框架输出的形式大部分仍依赖训练数据包含的SQL句式或预设的输出方案,因此输出方案的完备程度直接决定了SQL的生成效果.
3.4 基于语法的层级式生成方法
3.4.1 方法概述
此类方法中,模型以SQL语法为依据来约束解码过程,解码时通过一种自上而下的方式,逐层拓展目标输出的子序列,最终形成树状结构的结果,因此可以称为树解码方法.本节中总结3种树解码方法以及介绍相关改进方法.
3.4.2 自上而下的层级式树解码
Dong等人[87]在2016年提出了序列-树(seqence-to-tree,SEQ2TREE)模型,采用了层级式树解码方法,用于捕捉逻辑形式的组成结构.SEQ2TREE不同于以往的序列-序列模型的输出形式,而是以自上而下的方式(top-down manner)输出结果.模型通过定义“非终结符”表示序列中的子结构,当生成包含子结构的部分时,其内容会从原始序列中分离出来,向下拓展形成子树,因此完整的输出最终会以树状结构呈现.树解码器通过RNN实现,从第1层开始自上而下逐层解码.每一层的解码直至输出结束符出现为止,当前层中所有子结构以非终结符表示.当前层完成解码后,再转向序列中的子结构部分,向下继续解码子序列.子结构的解码采用parent-feeding机制,即根据上一层非终结符的隐向量作为输入来解码.当全部序列不再有未解码的非终结符,且当前层已输出结束符时,就结束解码.SEQ2TREE方法为后续其他层级式解码模型奠定了基础.之后Xiong等人[88]在此基础上使用了带有SQL关键字的起始标记来表示不同子句结构,比如解码到SELECT子句或WHERE子句时,分别以〈select〉和〈where〉作为起始标记,更利于SQL的结构化表示.
3.4.3 抽象语法树解码
为了更准确地捕捉程序语言内部语法结构,有的模型引入了逻辑形式的语法(syntax)作为层级式解码的依据,从而形成ASTs解码方法.而且与SEQ2TREE中的序列化子结构不同,由语法引导的解码是以ASTs作为中间表达,再进一步过渡到最终的逻辑形式.因为ASTs可以借助分析工具确定地转化成程序语言,并且能以较少的模式表示丰富的语法信息,所以被许多基于树解码的模型采用.能以ASTs解码的前提是目标程序语言的语法可以归纳成抽象语法,并且能够用一组生成规则(production rules)进行描述,从而能利用生成规则将程序语言确定地表示成由头部节点和子节点组成的ASTs结构[89].生成规则是一种抽象化的程序语言语法描述,每条规则一般由左右2端组成,右端内容是由左端根据语法而衍生出来的.这样基于语法指引的ASTs解码,能极大程度地约束与规范解码的搜索空间,适用于生成语法结构较为复杂的程序语言.
Yin等人[89]提出的代码生成模型就是基于ASTs解码实现.虽然目标语言为Python,但是其具备很好的可移植性,所以被很多NLIDB模型应用.其解码器根据输入端NLQ的语义,序列化调用“动作节点(action nodes)”,最终形成“派生AST(derivation AST)”.动作节点的类型和调用规则都根据程序语言的生成规则而设计,具体分为2类:第1类是AR(apply rule actions)节点,属于非终结节点,用于表示当前节点在衍生时调用的生成规则,即用于描述程序语言的结构,比如逻辑形式的描述或声明,所以ASTs中的所有节点,都是由AR节点衍生而来;第2类是GT(gentoken actions)节点,属于终结节点,它用于输出程序语言中具体的操作符、变量或常量等标记.解码时从根节点开始构造ASTs,通过在语法规则中选择相应的AR节点形成程序结构,以深度优先和从左至右的原则添加新节点,该过程也称为拓展边缘节点(frontier node,FN).直至FN为GT节点时,模型再实例化对应的常量或变量等标记,直至输出结束标记为止.然后解码器继续处理其他FN节点,直至所有子树都输出结束标记为止.最终得到的AST通过分析器明确地转化成程序语言,作为最终结果.其实AST展开后,实际上就是由多个时间步解码得到的串行化动作节点序列,RNN的隐状态用于追踪和引导序列的生成过程,也就是决定输出的节点类型.ASTs解码可以根据不同目标程序语言,设计相应的生成规则,所以基于ASTs解码的模型不受逻辑形式输出类型的限制,即具有程序语言无关性(program language-agnostic).
之后Brad等人[90]利用Yin等人[89]的方法在SQL的生成中得到了实践,证实了ASTs解码的可移植性特点.模型中除指定了SQL的生成规则,还添加了针对数据库表结构的处理功能.这里以其中一项SQL生成规则举例:“SELECT→COLUMN FROM WHERE”,其中的SQL关键字属于AR节点,基于该规则的一个实例化SQL为:“SELECTsalaryFROMemployeesWHEREage>5”,对应的动作节点序列为“SELECT→COLUMN FROM WHERE,COLUMN→‘salary’,‘salary’→FROM,FROM→TABLE,…,CONSTANT→‘5’”,其中“salary”和“5”是由终结节点衍生出来的实例,此例对应的AST如图10所示.
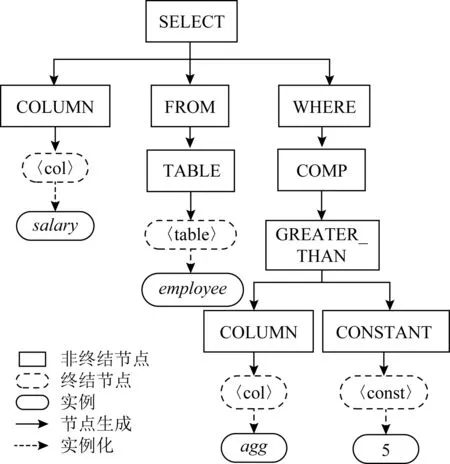
Fig.10 An example of an AST for SQL generation图10 用于SQL生成的AST实例
Rabinovich等人[49]提出的ASNs(abstract syntax networks)也是基于ASTs解码的模型,节点类型的设计引入了ASDL(abstract syntax description language)[91]框架.ASNs中的ASTs是以逻辑形式模块为节点构成的解码树,每个模块代表一个程序语言的片段.解码过程中,同样是从根节点开始,根据程序语言语法的约束,自上而下递归选择需要启用的模块.生成的模块若包含子结构,再分别调用子模块向下拓展,因此ASTs其实是一种程序语言递归调用的结构图.
GANCoder[92]是引入了GAN(generative adver-sarial networks)架构的ASTs解码模型,其目的在于以对抗训练的方式,使生成器掌握更多数据分布特征,以提高生成准确度.
TRANX是Yin等人[18]在之前模型[89]的基础上,参考ASDL框架做了进一步规范的SQL生成模型.其中在AR节点引入了ASDL的构造器结构,FN变成了组合式的前端域(frontier field)结构,GT节点增设了列的输出类型,使节点的拓展更加开放和灵活,也更适配SQL的语法结构.
IRNet[25]在前面的基础上做了3个方面优化:1)表连接(schema linking),通过标注NLQ中涉及的数据库信息,来增强NLQ与数据库之间的关联;2)丰富了SQL的生成规则设计,在语法描述上更加完备,比如合并了部分细节性语法结构,提高模型学习效率,以及建立了强调数据库元素的相关规则;3)拓展GT节点类型,进一步对列名和表名进行区分;4)ASTs的生成采用了Coarse2Fine[30]的处理流程,即先解码所有AR节点作为框架信息,再解码GT节点填充细节信息.
Lin等人[93]指出在ASTs解码中,生成规则的设计需要权衡语法的复杂度和模型的可学习性.因为针对SQL的生成,有些输出规则是依赖于表结构的具体信息的,而仅凭上下文无关(context free)的规则是无法涵盖这部分生成的.因此需要添加数据库表依赖的语法(schema-dependent grammar),构成上下文相关的规则,以补充以往规则中无法实现的部分,从而完善ASTs解码规则的完备性.
3.4.4 基于堆栈的语法树解码
Yu等人[94]提出的SyntaxSQLNet模型是在树解码基础上,利用堆栈来控制解码的进程.与ASTs作为过渡信息不同的是,SyntaxSQLNet在解码中省去了中间表达,而是直接输出SQL片段.Syntax-SQLNet和ASNs[49]相似,也是根据SQL语法预设了9种可递归调用的程序模块,其中Root模块表示查询的开始,可用于引出嵌套查询.模块的调用也遵循预设的生成规则.解码时根据历史状态决定调用的模块类型,有些规则需要向前回溯多个时间步,才能准确判断后续的输出.解码过程使用了堆栈机制,从Root模块开始调用新模块,被调用的模块实例化后压入栈,之后在每一步解码中,先从栈弹出当前实例化的模块,再根据生成规则激活新的模块,实例化后再压入栈,以此往复直至栈空为止.基于堆栈的模块调用机制能实现嵌套查询这种复杂句式的生成.
Min等人[46]利用SyntaxSQLNet[94]模型对跨语言数据集CSpider[46]进行了实践,评估了不同的词嵌入方法和分词工具对生成结果的影响.结果证明跨语言的词嵌入方法好于将不同语言分别进行词嵌入的方法.说明将输入信息映射至相同维度的嵌入分布中,相比分别映射的方式,更能强化NLQ和表结构之间的关联.此外在中文NLQ的处理中,分词效果对SQL生成有重要影响,分词误差和OOV很大程度影响语义分析的正确率.此外中文句式结构的识别和代词指代问题也给语义分析任务带来了新的挑战.
3.4.5 基于关联表示的改进方法
许多基于ASTs解码的模型,其改进方向都聚焦在强化NLQ与数据库元素的关联,使之成为提高SQL生成准确度的关键因素.其中HSRNet模型[95]重点设计了NLQ和数据库表的关联表示方法,其中将表的类型特征、表的关系特征和NLQ的词序特征这3个层次的特征表示成图结构,称之为层次化的表图谱(hierarchical schema graph,HSG),它实际上是一种强化的标注形式.之后HSG与NLQ共同被编码,提高了样本的表示能力.
Bogin等人[96]利用GNN对数据库表结构形成全局表示,进一步强调了对表结构语义进行表示的重要性,提高了模型处理zero-shot样本的能力.之后Bogin等人[97]又提出了GLOBAL-GNN,并做了2方面改进:1)在图表达基础上增设全局节点,强化了NLQ和表结构全局化的特征;2)设置了重排机制(re-ranker),以全局的角度对集束搜索中的候选值进行2次评估,进一步突出与数据库元素关联较高的候选结果.
RAT-SQL[98]模型也是从输入信息的特征表达角度进行优化,通过一种面向关系的自注意力机制(ralation-aware self-attention,RAT),以提高模型的全局推理能力.RAT-SQL编码器实现对输入信息共计33种关系特征的表示,这些关系不仅涵盖NLQ与数据库元素的关系,还包括数据库内部各元素之间的关系,关系特征作为嵌入向量融入RAT的表示之中.当ASTs解码到GT节点,需要实例化数据库元素时,利用携带关系信息的RAT分别建立表和列的对齐矩阵(alignment matrix),实现数据库内部关联的再次强化.RAT不仅建立了NLQ和数据库元素之间的关系,还实现了数据库内部元素之间预定义关系的组织与表示.这种联合式的表示学习,对输入信息存在预定义关系的语义分析任务来说十分重要.
3.4.6 方法总结
基于语法的层级式解码方法的优势在于:1)利用目标程序语言的语法结构引导解码,可以进一步限制搜索空间,从而保证输出的内容是规范的.语法在模型中作为先验知识被设计成一组已知的动作节点,使模型不用再根据有限的训练数据去还原SQL语法,从而让模型专注于学习语义合成特征.2)层级化信息有助于神经网络信息流的建立,同时也能自然地反映程序语言的递归结构[18].3)层级式解码方法有较高的概括性,相同的模型可以用于多种程序语言的生成,只需要重塑基于抽象语法的生成规则,就能实现模型的移植.因此基于层级式解码模型在概括性、可拓展性、有效性和可操作性均具有不错表现.在改进方案中,强化NLQ和数据库元素的关联映射是提高模型表现的关键.不过和分阶段的生成方法表现出的问题类似,此类模型的性能表现取决于生成规则的完备程度.
3.5 基于4种解码方法的模型总结
本节对基于3.1~3.4节所述的4种解码方法(分别简称为序列、模板、分阶段和层级式)的模型进行了汇总,如表5所示:
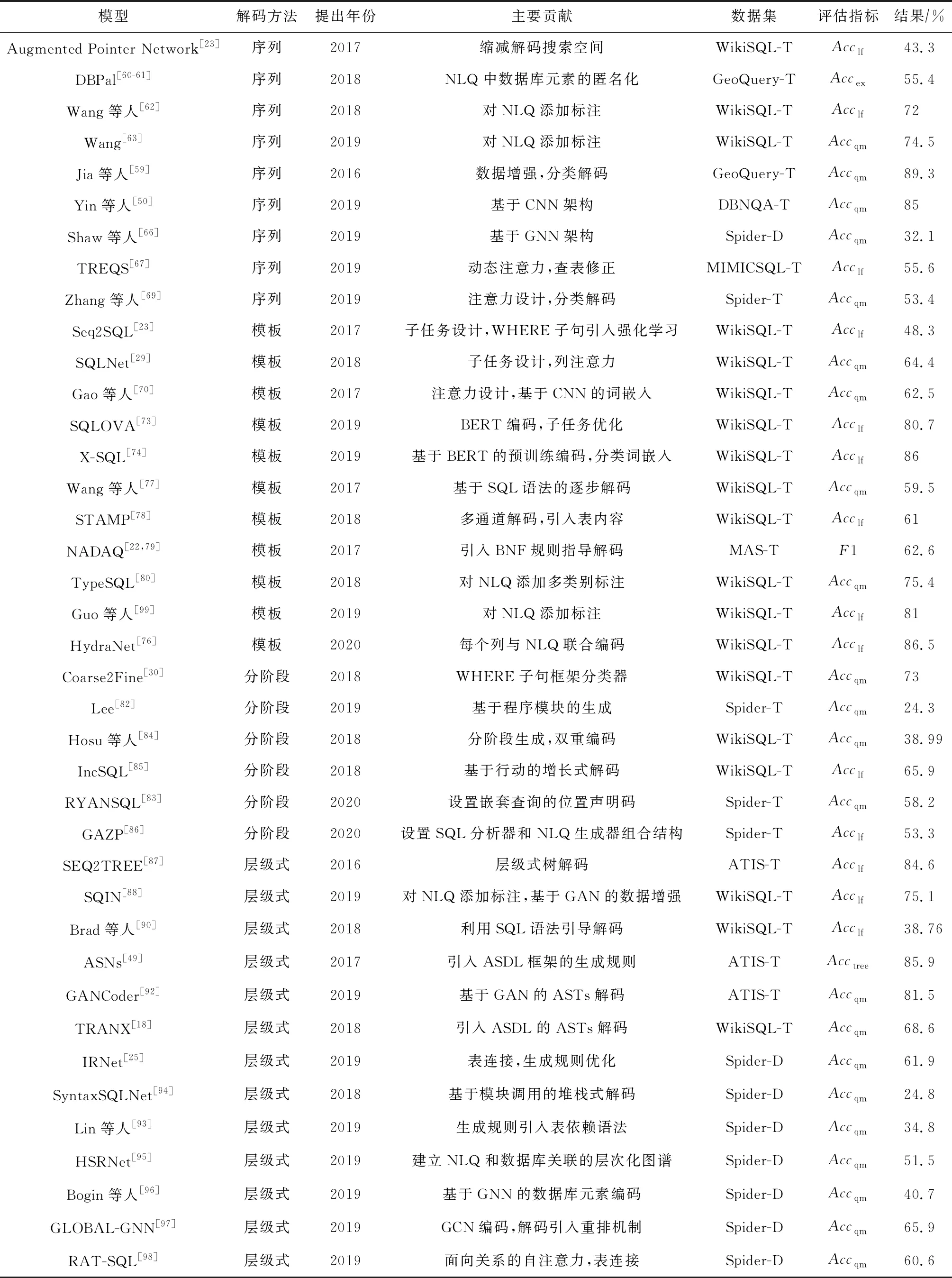
Table 5 Summary of the Models Based on 4 Decoding Methods表5 基于4种解码方法的模型总结
4 辅助方法
本节总结在基于深度学习的NLIDB模型中使用的7种辅助方法,除了在3.1.2节出现过的标签化输入、匿名化输入、数据增强这3种方法以外,还包括引入用户反馈、不同训练模式、程序语言特性以及对编码-解码过程的优化这4种辅助方法.
4.1 基于标签化输入的辅助方法
与3.1.2节提到的一致,该方法以添加标签的方式,对NLQ注入数据库相关的外部知识,从而增强NLQ和数据库之间的关联.标签的引入一定程度地减弱了处理zero-shot样本的困难.对于标签的添加,除了3.1.2节提到的方法,还有利用条件随机场(conditional random fields,CRFs)分类器[22]、字符串匹配[25,80]、多层卷积分类器[88]或建立专门的映射模型[100]等方法.
4.2 基于匿名化输入的辅助方法
与添加标签的做法相反,匿名化输入的目的是减少语义分析模型对新领域样本的学习负担,同时起到简化编码词汇表的作用[93].一般的做法为识别NLQ中包含的数据库元素,作为输入时,以占位符代替这部分信息,模型先以包含占位符形式输出,再恢复成原始NLQ中的字符.数据库元素的识别方法包括:基于TF-IDF方法[36];字符串匹配[93];基于CRFs的2分类器[101];还有的方法先识别NLQ中涉及数据库信息的类型,再对其具体关系(如whecol和val的从属关系)进行判断[102].
4.3 数据增强的辅助方法
数据增强缓解了因为样本数量不足导致模型得不到充分训练的问题.基本思路是利用已知数据集,自主生成更多训练样本,以提高模型对数据集的适应度.具体的实现方法包括:设计文本生成模型实现NLQ的扩充[88,103];利用外部资源(比如paraphrase database)对已知样本中的NLQ进行改述,实现样本的增加[61];还有的方法通过归纳数据集中的SQL句式,形成SQL模板,然后填入不同的实体名称来实现样本的扩充[36,59,94].
4.4 基于用户反馈的辅助方法
由于NLQ中经常包含歧义或模糊表述的情况,所以要求模型一次性生成准确的SQL是比较困难的.而通过交互方式,通过用户反馈确认查询意图,是符合逻辑的做法.
因此以拓展外部知识和加强语义理解为目的,将用户角色添加到模型的处理流程中[104]是值得考虑的改进路线.引入用户能够消除NLQ中的歧义,提高语义分析的准确率.并且在实际应用场景中,通过人机互动方式能够提高用户对平台的信任[105].
Iyer等人[36]将用户角色融入到数据增强中,其实现流程为:先利用基本的训练数据学得初始的语义分析模型.再让模型线上回答用户新提出的NLQ,并且让用户对生成的SQL结果给出判断.若用户认为结果正确,则把本轮问答作为新样本加入训练集中;若用户认为结果错误,则从后台利用人工标注的方式更正结果,然后将修正后的数据作为新样本添加到训练集中.模型在扩充后的数据集中重新训练,之后再从线上收集新样本,以此循环往复来提高模型性能.
事实上从人机交互的角度来看,在用户不熟悉数据库结构或SQL语法的情况下,要求用户判断生成SQL的准确性是不友好的.DialSQL[104]则是一个适用于所有用户的辅助框架,它通过与用户进行多轮对话,逐步修正并确认SQL中的细节.在每轮对话中,相关模块识别并提取输出结果中潜在的错误片段,然后针对错误片段生成相关的候选项反馈给用户进行选择,以此来消除NLQ中的歧义,修正输出的结果.
对话辅助框架MISP[105](model-based interactive semantic parsing)也是通过用户反馈来修正语义分析结果中的错误解析,而且MISP不拘泥于数据集的具体逻辑形式,是一个能通用于不同语义分析任务的通用框架.其处理流程是通过数个组件协作实现,如图11所示:
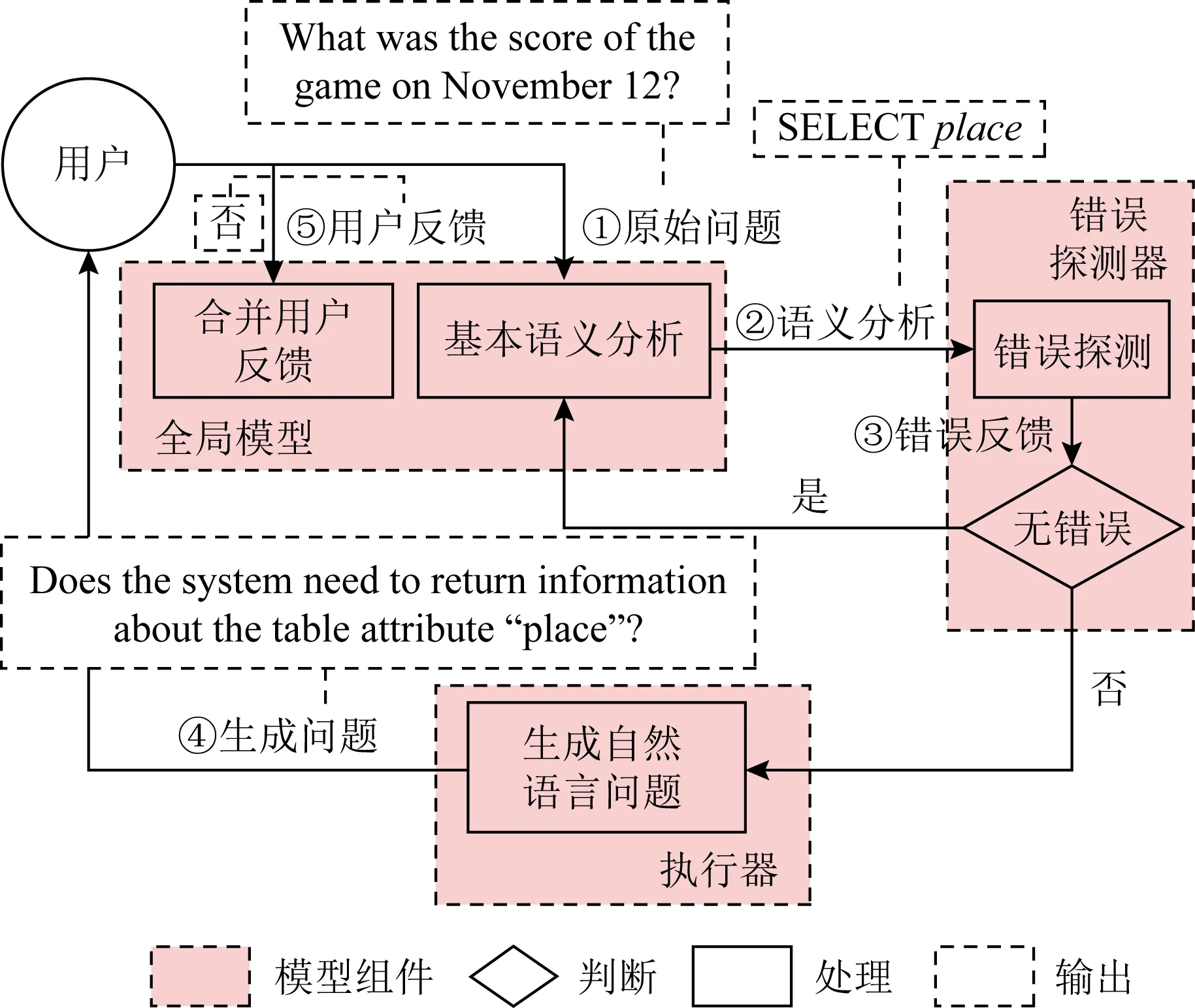
Fig.11 MISP framework[105]图11 MISP框架[105]
以SQL的处理流程为例,首先从外部引入语义分析模型,负责生成初始的SQL结果;期间MISP会跟踪解码中的细节信息,当“错误探测器”识别到解码在决策时存在较大的不确定性时,就启动向用户征求反馈的机制,“执行器”生成对应的自然语言问题来向用户提问.之后“全局模型”负责接收用户反馈信号,并递送至语义分析模型,使解码器消除不确定内容,修正输出结果.MISP框架中的每个组件在互相关联的同时也保证了各自的独立性.
4.5 引入不同训练模式的辅助方法
传统的学习模式是训练一个模型来匹配数据集中的所有样本.为了使模型在面对大规模数据集时,能对不同样本实施有针对性的参数策略,Huang等人[106]引入了“元学习”模式,先训练一个基本模型,再用另外少量样本在基本模型中训练“伪模型”,以满足不同“伪任务”的需要.伪任务的产生是在原始数据集中,通过相关性函数将原始任务拆解成子任务,每个子任务只对应少量样本,因此伪模型的训练能更有针对性地适应目标样本的特点.各伪任务的训练不仅耗时短,而且结果的准确性也比单模型高.
MQAN[57]是一个多任务协同学习的模型,除了包含SQL生成的语义分析任务,还结合了问答、翻译、摘要、文本推理、情感分析、语义标注、关系抽取、会话跟踪和指代消解共计10种任务.模型将所有子任务都整合成为问答模式,全部在一个编码器-解码器模型中训练,每个任务没有特定的模块或参数,实现了单模型支持多元任务的需求.基于10种任务的预训练模型适用于迁移学习和元学习的场景.
4.6 基于程序语言特性的辅助方法
此类辅助方法是利用SQL特有属性或组件来辅助结果的生成.例如曹金超等人[107]使用了基于数据库模式图的斯坦纳树,作为辅助JOIN路径的生成工具.理论上该方法生成的路径是全局最优解,所以能保证FROM子句的准确性.Baik等人[28]利用SQL查询日志作为辅助工具,提高NLQ与数据库元素的关键词映射以及JOIN路径推导的准确性,日志中的历史查询用于构建一种查询片段图(query fragment graph),它可以反映出现在日志中的各种查询片段之间的共现情况,将共现率高的组合作为SQL生成决策的参考.
执行引导解码(execution-guided decoding)是利用了SQL可执行特性的一种辅助方法.它的设计思路是在解码的过程中,只要产生了部分可执行的SQL,就实时地执行它来验证输出的有效性.若执行后返回的是无效查询或结果为空,就判定这部分SQL为无效的解码,然后回溯到之前的状态继续搜索其他可能的结果,直至解码出有效的SQL为止.该辅助方法能及时过滤掉无效的输出,从输出SQL的准确度来看,为许多模型都带来了辅助提高的效果.
4.7 编码-解码过程中的辅助方法
此类辅助方法是在编码-解码框架中,通过一些辅助机制,将模型评分低但是比较有潜力的候选结果进一步挖掘出来.除了3.4.5节介绍的GLOBAL-GNN[97]在解码阶段引入了重排机制,Bertrand-DR[108]模型在编码输入信息之后设置了重排辨别器.其形式为二分类器,在训练阶段使其只对真实值判定为真,然后在预测阶段使其对beam search输出的候选结果进行重排,从而把解码中分值较低但是接近真实结果的SQL强调出来.它可以作为一种辅助工具添加到基于预训练BERT的模型中,被证实在GNN[96],EditSQL[69]等模型中实现了辅助提高的效果.
5 未来研究方向
本节根据目前基于深度学习方法的NLIDB模型中尚存在的不足与缺陷,指出未来仍需集中关注的6个研究方向.
5.1 NLQ和数据库的对齐机制
很多模型在误差分析中指出,大部分生成偏差来自于NLQ与数据库列名或表名的错误匹配.Hwang等人[73]总结了2个产生误匹配的原因:1)出现在SQL中的列名信息有时并不会在NLQ中对应出现;2)NLQ中存在叙述歧义.因此模型不仅要提高消除NLQ叙述歧义方面的能力,还需加强实体名称的识别以及数据库元素的映射能力,比如OOV、稀有词或特定属性的专有名词(如时间)等词汇和名称的识别与提取.
改进方案可以从3个方面入手:1)从编码的角度,可以利用图或其他映射工具建立NLQ和数据库元素之间的关联信息,其中数据库元素除了常见的表名和列名信息,还可以进一步建立属性类型、表内与表间关系等内部特征的关联,再将以上关系信息融合到编码流程中;2)从NLQ预处理的角度,可以设计有针对性的标签添加法,将实体、关系等信息更显式地体现在NLQ中,例如引入外部知识库,甄别NLQ中的各类实体名称,或者设计包容性更强的识别算法;3)从数据库利用的角度,目前许多模型由于考虑隐私保护的问题,并没有将数据库表中的记录融入到语义分析中,也就无法更进一步理解查询意图和有效识别数据库元素.因此可以考虑在条件允许情况下,将表中记录作为模型的部分输入.例如ColloQL[109]考虑到实际应用中的NLQ存在噪声问题,提出一种面向数据库记录的采样方法.编码时,对数据库每一列的记录进行采样,将采样得到的内容注入BERT中,使模型更深入地掌握数据特征.所以数据库记录的融合方法也可以作为进一步研究的内容.
5.2 训练数据的加工与利用
目前模型在处理zero-shot样本的泛化能力仍需加强,这部分能力的提高,需要向模型提供更多、更复杂的训练数据.数据集给语义分析模型造成的限制体现在2个方面:1)训练数据的SQL句式类型不够丰富.Finegan-Dollak等人[44]比较评估了不同模型分别在不同数据集和不同数据分割方式(即训练集与测试集的配置方案)下的表现.在以SQL句式为分割依据的评估中,模型整体性能表现远远低于以NLQ特征为依据的分割方式.因为前者考验的是模型在SQL知识层面的泛化能力,其很大程度增加了语义分析任务的难度,揭露了模型在对SQL框架层次的zero-shot处理能力还有待提高.2)训练数据数量存在严重不足.Guo等人[25]指出Spider数据集中extra hard等级的样本数量在所有等级中的占比最少,使模型在嵌套查询等复杂句式的处理方面得不到充分的训练.因此增加训练样本数量,尤其针对复杂SQL样本和跨领域数据库样本的扩充是很有必要的.目前在数据增强方法中,常见做法是替换已知样本中的实体名称,该方法只能在原始数据集基础上,扩充固定SQL句式的样本.因此可以尝试跨数据库、跨SQL句式,甚至跨数据集的数据增强方法.此外,在通过改述NLQ来增加样本的方法中,存在新样本偏离原始查询意图的问题[103].针对此问题,可以引入反向监督机制,即建立SQL为输入、NLQ为输出的语义分析模块,实现NLQ的生成质量的控制,保障数据增强效果.
5.3 完善模型评估策略
5.2节提到,模型在不同的样本分割方式下,其性能表现也不尽相同.因此通过建立更加完善的评估机制,才能了解模型的真实能力.具体有4个建议:1)扩大评估目标的覆盖面.例如Suhr等人[110]提出一种基于zero-shot与非zero-shot数据集的交叉评估方法,揭示目前的模型虽然在固定的数据集上表现良好,但是在基于数据集的交叉评估中,就进一步显示出模型在实体识别、语义消歧以及数据库映射方面的能力仍存在不足.因此通过设计更全面的评估方法,有利于及时发现语义分析模型泛化能力中的不足.2)完善数据集分割策略.建议基于不同的数据集分割方式[44],多方位地评估模型.3)开展更多的迁移实验.例如Sun等人[78]将WikiSQL数据集中训练得到的模型,在WIKITABLEQUESTIONS[111]数据集中进行迁移测试,来评估模型性能.因此开展跨数据集的评估实验,可以全面检验模型鲁棒性.4)引入人类评估相关指标.人类评估除了可以作为模型评价指标,在交互模型中也是衡量对话生成质量的重要参考.Hwang等人[73]、Yao等人[105]均指出在人类评估中,目前由于人对数据库结构的了解不足,造成对NLQ查询意图的理解存在偏差的问题.所以在人类评估指标的设计中,除了需要提高评估的有效性,还需要考虑人为因素的不确定性.
5.4 复杂SQL句式的生成
目前模型在生成复杂SQL句式中的不足,主要体现在2个方面:1)模型缺乏对表内和表间关系的理解能力.具体表现在处理包含自连接、多表连接等组合式查询的样本能力存在不足.比如Guo等人[25]提出的生成规则中,就缺乏自连接查询的相关规则.而在多表连接方面,外键关系越多,其JOIN子句中涉及的表就越多,从而导致模型匹配数据库元素的准确率也越低[24].2)嵌套查询的生成能力有待加强.目前在实现嵌套查询的生成中,较多采用的是基于层级式的解码方法,但是其准确率仍然不高,而且层级式解码也存在NLQ与数据库元素在实体映射方面的误匹配问题.
针对以上不足,完善层级式解码方法是一种改进的方向.其中以ASTs解码为代表的方法,在递归程序的生成和程序片段的拼接方面具有明显优势,因此目前仍是生成复杂SQL句式的重要实现途径.其中改进ASTs的生成规则是一种重要的优化路线,可尝试的改进方向有4方面:1)借鉴其他程序语言的语法框架,以弥补在SQL生成中缺失的规则;2)Brad等人[90]提到在人工定义生成规则之前,可以在大量样本中先进行无监督预训练,使模型预先学习样本中潜在的ASTs生成规则;3)Lin等人[93]提出在输出ASTs时,为了避免模型拟合困难的问题,应尽量避免过度生成和AST的树高过深,因此可以设计基于更短路径的派生规则,以便于模型的学习;4)提高生成规则的灵活度和动态性,比如设计基于具体样本的表结构特征的动态规则,因地制宜地控制解码输出.
5.5 交互模型的研究
目前模型在处理SparC和CoSQL这类对话式数据集的能力还有待提高.因为每个样本由对话构成,仅凭其中单句的NLQ是不足以理解查询意图的,而且脱离了上下文的NLQ,难免会存在一些逻辑缺陷,尤其在对话中越靠后出现的NLQ,其叙述方式越省略,也就越容易出现歧义,从而导致这部分SQL结果的准确率较低.并且模型针对CoSQL数据集时,需要同时处理对话追踪、对话生成以及用户行为预判这3种任务,所以未来NLIDB的设计,需更多考虑实际应用中的对话场景,提高模型基于上下文依赖(context-dependent)的分析能力.具体可以考虑2个方向的研究:1)提高NLQ消歧能力.通过优化基于关联表示的上下文依赖机制,提高模型对历史对话信息的利用能力,达到从全局的角度理解查询意图的效果.2)引入用户反馈机制,并强化反馈环节的设计.具体可以在交互过程注入限制性措施,引导用户在对话中提供更有价值的线索,来达到细化查询和消除歧义的目的.引入用户反馈是一种持久的辅助机制,因此在保证模型稳定性的前提下,可以开展终生学习(lifelong learning)的语义分析相关研究.
5.6 方法的创新与新领域的探索
针对5.1~5.5节提到的诸多挑战,可以跳出针对深度学习模型细节部分的优化,考虑从整体角度进行方法的创新,例如:1)尝试多方法的融合.比如在3.1.2节和4.6节提到的辅助方法中,就有将查询日志、语法分析树、程序可执行特性等元素融合至深度学习模型的做法.此外,其他启发式成果也可以考虑在未来实现进一步融合,例如有的成果通过建立孪生网络,分析NLQ和SQL之间潜在的语义相似性[112],如果把它融合至语义分析模型中,就可以实现在编码-解码之前,先识别NLQ潜在的SQL句式结构,再将它作为指导解码输出的决策;还有的成果利用有向图表示SQL,实现了基于“图-序列”的NLQ生成模型[113],此类逆向任务可以作为实现数据增强的辅助方法.2)优化神经网络的学习方式.目前已有相关成果引入了多任务学习、元学习、强化学习等训练方式,其中许多环节都可以进一步优化.例如在McCann等人[57]提出的基于多任务课程学习(curriculum learning)模式中,就可以尝试更多不同任务之间的组合方式,从而优化阶段式训练过程.Huang等人[106]提出的基于少样本(few-shot)元学习模型中,作为伪任务建立依据的相关性函数,是决定元学习表现的关键,对此也可以进一步优化.在引入强化学习的模型中,可以考虑结合SQL特性设计更有针对性的期望奖励方法.此外还可以参考基于语义分析的弱监督模型[114],利用其中的模型优化策略改进训练过程等.在研究领域的拓展方面,扩展跨语言模型的相关研究是重要的发展方向.因为目前模型仍是以处理英文NLQ为主,而在实际应用中,跨语言NLQ的处理对模型来说是必须具备的功能.其中跨语言句式结构的识别和代词指代问题给语义分析任务带来新的挑战[46],因此分词优化技术和跨语言语义映射方法等都是未来值得进一步研究的方向.
6 总 结
在NLIDB的实现中,基于编码器-解码器的深度学习模型在表示学习、语义分析、跨领域数据挖掘等方面表现突出,较传统rule-based方法更具优势,因此仍是一类很有前景的解决方案.根据目前的研究现状,深度学习模型在各环节的设计中还存在一定的提升空间,并且未来还可以积极尝试多方法的交叉融合,以实现模型的优化.本文以解码方法为依据,梳理了基于深度学习方法的NLIDB成果,分析了尚待解决的问题以及提出未来发展方向,希望能对该领域的相关研究提供一定的参考.
作者贡献声明:潘璇负责文献搜集、文献归纳和文章撰写工作;徐思涵负责文献筛选和论文修改工作;蔡祥睿负责提供研究思路和补充参考文献工作;温延龙参与设计论文框架和提出论文修改意见;袁晓洁负责文章选题工作,以及对文章撰写提出指导意见.
