基于拐点和区域划分的高维多目标进化算法
2021-09-09杨景明郝佳佳魏之慧李霞霞
杨景明,郝佳佳,孙 浩,魏之慧,李霞霞
(燕山大学 电气工程学院,河北 秦皇岛 066004)
1 引言
在科学研究和实际问题中常常需要同时优化多个相互冲突的目标,这类问题被称为多目标优化问题(multi-objective optimization problems,MOPs)[1]。而常规方法在求解目标个数大于3的问题(即MaOPs)时,种群的非支配解随目标数呈指数级增加,选择压力急剧下降,算法处于停滞状态[2];同时目标空间增大,Pareto前沿更加复杂,算法的收敛性和分布性难以同时保持。
目前,研究人员已经提出许多解决MaOPs的算法,大致可以分为3类:1)基于Pareto支配。这种方法需要引入新的机制来增强选择压力。例如,网格支配[3]通过自适应网格结构增加了选择压力,模糊支配[4]在Pareto支配的基础上引入了模糊的概念来选解,此外还有ε-MOEA[5]、KnEA[6]等。这类算法的收敛性一般比较好,缺点是常常需要引入一些参数,参数的确定比较困难。2)基于分解。该方法将多目标问题分解为若干个单目标子问题,然后对这些子问题进行同步优化和协同优化。经典的有MOEA/DD[7]、参考向量引导的进化算法RVEA[8]等。这类算法的收敛和分布效果受权重分布影响,因而面对退化、不连续或真实PF面不规则的问题时效果不佳。3)基于性能指标。算法在环境选择过程中采用个体的性能指标值选择个体。例如超体积算法Hype[9]、基于R2指标的高维多目标进化算法MOMBI-II[10]等。这类算法的主要缺点是需要大量的计算。针对上述问题,本文提出一种基于拐点和区域划分的高维多目标进化算法(KnSP算法)。
2 背景描述
2.1 高维多目标问题描述
不失一般性,考虑如下MaOPs:
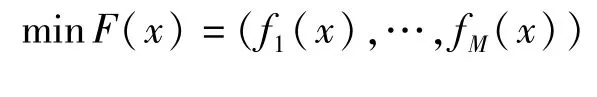
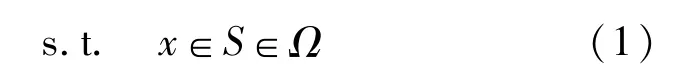
式中:X=[x1,x2,…,xn]T为n维决策向量;S为x的可行域;fm(x)为第m个目标函数,m=1,…,M,M为目标函数个数。
Pareto支配(定义):设xA,xB∈Xf是式(1)所示的MaOPs的2个可行解,当且仅当对于任意i=1,2,…,m,fi(xA)≤fi(xB)且存在j=1,2,…,m,fj(xA)<fj(xB)时,称xA支配xB,记为xA≺xB[11]。
Pareto最优解(定义):一个解x*∈Xf称为Pareto最优解,当且仅当满足以下条件[11]:
Pareto最优解集(定义):Pareto最优解集是所有Pareto最优解的集合[11]:
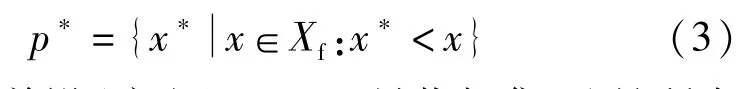
Pareto前沿(定义):Pareto最优解集p*是所有Pareto最优解对应的目标矢量组前沿面PF*[11]:
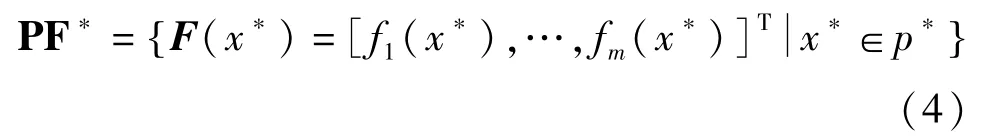
2.2 基于CHIM的拐点确定法
在许多实际问题中,给定一个折衷解曲线或类似Pareto前沿曲面,一般会选择曲面的“中间”点作为代表性点。因为它与Pareto曲面的极值点距离最远,在某种程度上可以代表良好的“折衷”,这种“凸起”被统称为曲线的拐点。例如,在图1中,Pareto曲线是AKB,选择的拐点可以是K点,也可以是K点附近的点。
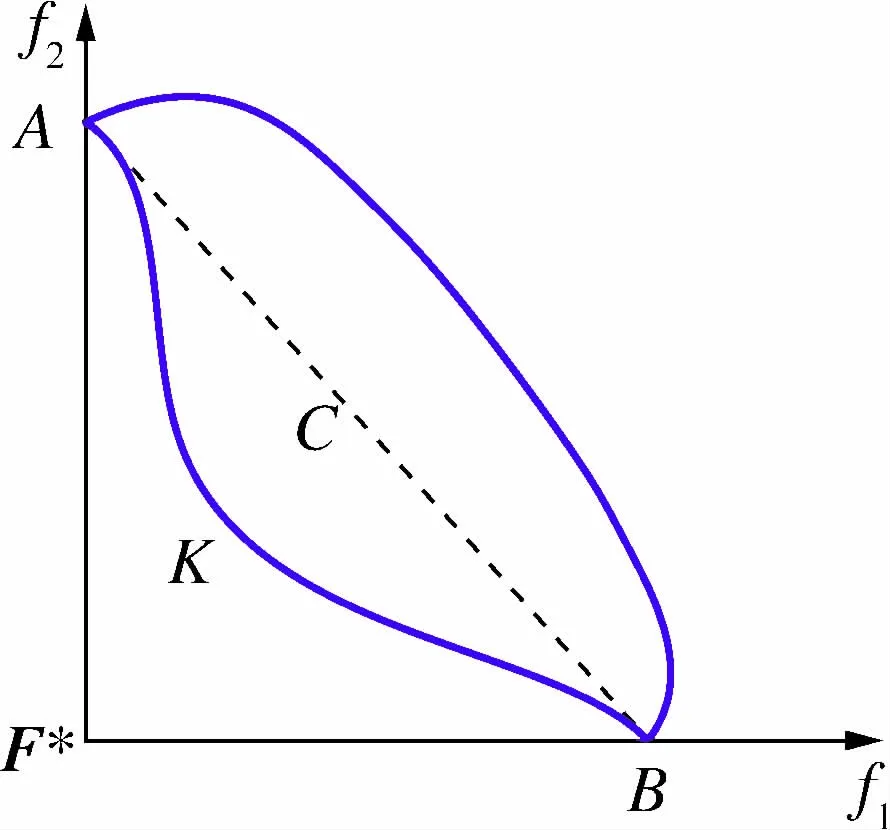
图1 拐点K通常为Pareto前沿比较代表性的点Fig.1 The knee point K is usually a representative point in the Pareto front
确定拐点采用Das和Bechikh等[12]中提出的定义。理想点F*被定义为包含目标的单个全局最小值的向量,则:


3 KnSP算法
3.1 确定拐点和第一次区域划分
在MaOPs中,拐点是帕累托最优解的子集,其中一个目标的改进将导致至少另一个目标的严重退化,在没有用户指定或特定问题的偏好时,帕累托前沿的拐点自然是首选。
3.1.1 确定拐点
在每一个非支配前沿中,极值超平面L的求解与CHIM类似。根据种群目标空间的单极值点可以确定一个极值超平面L。计算个体到超平面L上的距离,若解到极值超平面的距离是最大值,那么该解被视为该非支配前沿的第一个拐点,再根据自适应生成的邻域,可以依次找出所有拐点。
3.1.2 第1次区域划分
第1次区域划分是将获得的拐点作为中心点,自适应的生成1个邻域。而邻域大小将严重影响拐点的识别结果。
根据文献[6]来自适应生成邻域。假设第g代组合种群包含l个非支配前沿,每个前沿都有1组非支配解,用Fi表示,1≤i≤l。解的邻域由1个维度为M的超立方体组成。第j(1≤i≤M)个维度上的邻域大小被确定为Rj。
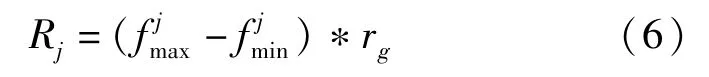
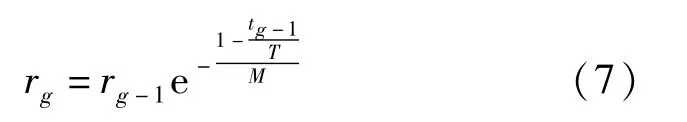
式中:rg-1为第(g-1)代Fi中解的邻域个数与第j个目标的跨度之比;M为目标数;tg-1为拐点与第(g-1)代前沿Fi非支配解的数量比;0<T<1是控制解集Fi中拐点比率的阈值。式(6)确保当tg-1远小于指定阈值T时rg将显着减小,并且随着tg-1的值变大,rg的减小将变得更慢。当tg-1达到给定阈值T时,将保持不变。tg和rg分别初始化为0和1,即t0=0和r0=1。拐点确定和第一次区域划分如算法1所示。
算法1 确定拐点和第1次区域划分(Find_kneepoint(F,T,r,t)→[K,NB,r,t])

3.2 第2次区域划分
第2区域划分是将3.1.2节中的邻域通过角度分层进行第2次区域划分得到最终子区域,然后在每个子区域内选择1个最优解作为候选解。
2目标情况下的第2区域划分如图2所示,其中Z*为每1个邻域内的理想点(即每1维度上的最小点),向量V是坐标系中的中间向量,S1、S2是第2次区域划分后的最终子区域,α为区域划分的角度,第2区域划分过程如算法2所示。
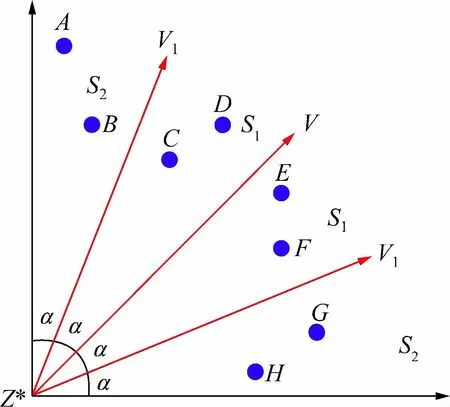
图2 2次区域划分示意图Fig.2 The second region division
假设某个邻域内有8个点A~H,进行二次区域划分时,首先需要进行标准化,使得Z*成为原点。将中间向量V设置为V=[1,1,…,1],计算每个点与向量V之间的夹角β,取,将每个点划分到所属的子区域中。从图2可以得出点A、B、G、H属于子区域S1,而点C、D、E、F属于子区域S2。高维情况下的划分情况与此相同。二次区域划分完成之后在每一个邻域内的每一个子区域中选择距离超平面L最远的个体作为候选解。
算法2 第2次区域划分(Second_region(NBH)→Φ)

3.3 环境选择
环境选择是为了从种群中选择性能较好的解作为下一代的父代种群。由于在高维情况下的个体基本上都是非支配而拐点的个数一般会小于当前种群,所以需要进行两次区域划分来进行种群选择。环境选择过程如算法3所示。
算法3 环境选择(Environment_selection(F,K,N,NB,Φ)→Next)

若种群选择后下1代种群的个数仍小于当前种群规模,则计算候选解与剩余个体的角度,选择角度最大的个体直到所选下1代种群的数量等于种群规模。若所选下1代种群的个数大于种群规模时采用角度去除法,计算候选解彼此之间的角度,选择角度最小的2个点,然后比较这2个点与其它点之间的角度值,去除角度较小的个体。
需要注意的是,每次通过角度增加或去除一个个体之后都需要重新计算角度值再进行下一个个体的增加或去除。
3.4 算法的总框架
下面算法为KnSP的总框架。
算法4 KnSP总框架(General Framework of KnSP)

4 实验结果与分析
4.1 实验设置
为了公平比较几种算法的性能,采用能够使比较算法处于良好性能状态的参数。
1)交叉和变异。交叉和变异采用SBX[14]和多项式变异[15]来产生后代种群。根据文献[16]设置相应的参数。
2)常规参数设置。对于每种算法中每种测试函数在同一设备上均独立运行20次,将迭代次数作为终止条件。WFG1的最大迭代数设置为1 000,WFG2为700,其他的设置为250代。
3)其它参数设置。GrEA中表示维度分割的参数div根据文献[3]来设置。对于MOEA/DD,所有测试问题的邻域范围都设置为N/10,使用Tchebycheff方法作为聚集函数,其中N为种群大小。
4)性能指标。
超体积指标(hyper volume,HV)[17]和反向世代距离(inverted generational distance,IGD)[18]是2个广泛用于评估比较算法的性能指标。这2个性能指标不仅可以说明算法的收敛性,也可以衡量算法的分布性。其具体设置根据文献[17,18]设置。
4.2 实验结果分析
本文选取6个测试问题WFG1、WFG2、WFG4、WFG5、WFG7和WFG8进行试验对比。表1和表2分别列出了5种算法在测试函数上立运行20次的IGD值和HV值的平均值和标准偏差值(括号内数值),其中性能表现最好的用加粗字体标出。
从表1中可以得出以下结论:首先,NSGA-III在WFG系列测试问题上表现出良好的性能,尤其是在3个目标和5个目标的情况下,说明NSGA-III处理低维多目标问题十分有效。对于具有8个目标的WFG问题,GrEA有2个表现最好,而KnSP有3个处于最优位置,展现出一定的争力。在10个目标和15个目标情况下,KnSP表现出较好的性能,其中10个目标时IGD值最小的测试函数有4个,15个目标均为最好。就IGD值而言,KnSP在整个WFG测试函数中的性能较好。这是因为KnSP算法的主要选择标准是距离超平面L的距离,而距离L越远,距离Pareto前沿的距离也就最近,而在目标维数增多的过程中是用了2次区域划分来缩小目标空间,增加选择压力,所以种群的收敛性能在高维情况下表现良好。从表2中可以看出相比之下,NSGA-III和GrEA在WFG问题上的HV具有3个以上目标的情况下,其性能大体上比MOEA/DD和KnEA要好。NSGA-III和GrEA在所有具有3个以上目标的WFG问题上,尤其是WFG1中获得了最佳HV或接近最佳HV。在5个比较算法中,KnSP在具有10个目标上获得了3个最佳的HV,而在15目标的情况下基本上都是最优或者接近最优。这些结果表明,与其它算法相比,KnSP更适合于处理具有8个以上目标的MaOPs。在本文考虑的30个WFG测试实例中,KnSP在12个测试实例上获得了最佳的HV。总体而言,就HV而言,KnSP在WFG测试套件上的性能优于其他比较算法。这是因为在KnSP算法中二次区域划分时在每一个小区域内都保留了一些分布性较好的个体,而且还采用了角度增加个体或者删减个体的机制,将角度相差较大的个体进行保留,对角度相差较小的个体进行去除。
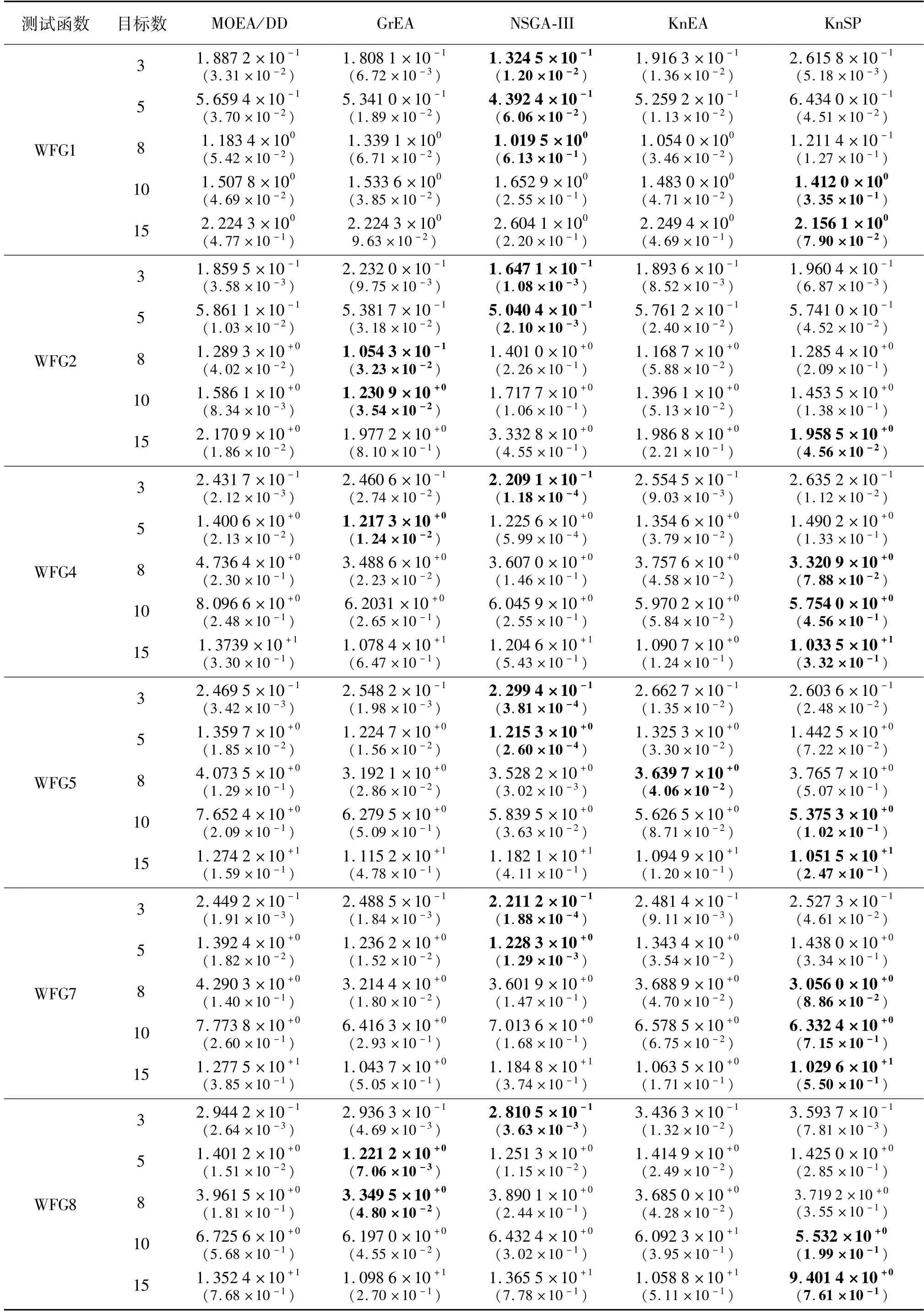
表1 5种算法在WFG测试函数上的IGD值统计表Tab.1 The IGD value of 5 algorithms on WFG test functions
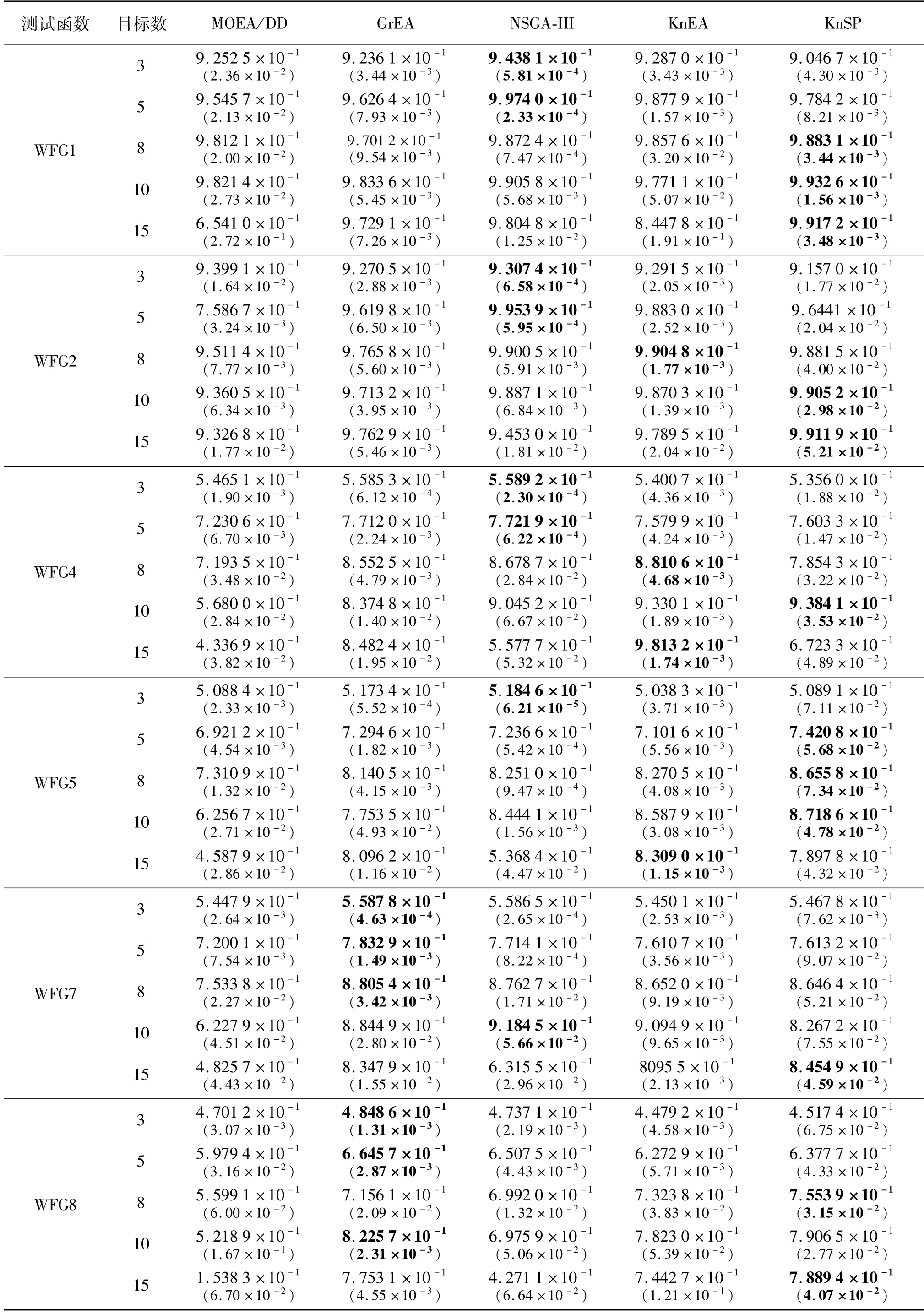
表2 5种算法在WFG1~WFG8测试函数上的HV值统计表Tab.2 The HV value of 5 algorithms on WFG test functions
为更加直观得到算法在测试函数上的表现结果,选取3目标和15目标的WFG1作为代表,测试结果如图3所示。
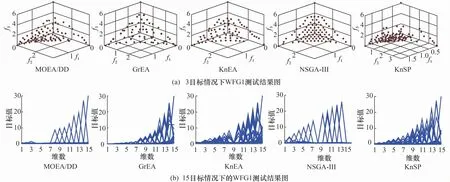
图3 5种算法在3目标和15目标下的WFG1测试结果图Fig.3 The experimental results of 5 algorithms for WFG1 in 3 objectives and 15 objectives
图3(a)为3目标下的WFG1测试结果图。图3(a)可以很直观地表示出解的优劣。其中,解的收敛性表现最好的是NSGA-Ⅲ,其次为GrEA、MOEA/DD和KnEA,这3种算法的收敛性相差不大,而KnSP则表现较差。从分布性上来说,NSGA-Ⅲ的解分布均较为均匀,而GrEA、MOEA/DD和KnEA相差不大,略逊于NSGA-Ⅲ,而KnSP则表现较差。总体来说,NSGA-Ⅲ在3目标情况下的WFG1中表现最好,而KnSP表现最差。
15目标下的WFG1测试结果如图3(b)所示。平行坐标是一种常用的将高维数据可视化的方法,其横轴表示目标的维数,竖轴表示目标值的大小,1个高维空间的点可以被表示为1条拐点在多条平行坐标轴上的折线。由于竖轴反映对应维度上的目标值,所以根据目标值的情况和测试函数的真实前沿可以大体判断算法的收敛性和分布性的性能表现。一般来说,竖轴上的目标值距离真实前沿相同维度上的目标值越远,收敛性越差;平行坐标中,折线的重复程度越大,则分布性越差。
由图3可知,MOEA/DD在第4~6目标维度上的目标值较小,GrEA在第1、2和4维度上数值较小,KnEA是第2和6维度上数值较小,NSGA-Ⅲ在第8、14和15维度上数值较小,而KnSP在第1~3维度上的目标值较小。根据WFG1测试函数的特性可知目标维数越大,目标值的最大值也最大,而NSGA-Ⅲ在3个维数较高的目标上数值很小,所以NSGA-Ⅲ在这些目标维度上的收敛性就会很差,进而在种群中的收敛性上就会表现较差,反之KnSP的收敛性相对较好。从折线的重复程度上来看,MOEA/DD和NSGA-Ⅲ的重复程度较大,其次是GrEA和KnEA,KnSP的重复程度最小,所以,MOEA/DD和NSGA-Ⅲ的分布性较差,KnSP的分布性最好。
5 结论
为了更好地平衡收敛性和分布性这两个重要的性能指标,本文提出一种基于拐点和区域划分的KnSP算法。与4种算法的比较实验结果表明,提出的KnSP算法在分布性与收敛性性能指标占优的比例接近一半,尤其在目标维数大于8时,基本上处于占优位置,展现出极大的竞争力。本文证明了使用拐点来增加MaOPs的选择压力的想法是可行的。进一步开展工作以开发更有效和计算效率更高的算法来识别拐点是非常必要的。最后,算法性能仍有待在实际的MaOPs上进行验证。
