基于YOLO v4卷积神经网络的农田苗草识别研究
2021-09-09权龙哲夏福霖姜伟李海龙李恒达娄朝霞李传文
权龙哲,夏福霖,姜伟,李海龙,李恒达,娄朝霞,李传文
(东北农业大学工程学院,哈尔滨 150030)
农田杂草是影响农作物生长的主要因素之一。田间复杂环境的影响且与作物生长状况以及产量密切相关,使农田杂草难以得到有效治理[1-2]。目前,化学除草大多为全覆盖式喷洒农药,成本高、污染环境且危及食品安全[3-4]。相较于技术比较成熟的行间机械除草技术,株间机械除草因其较低容错性、结果不可逆性以及除草无选择性,给玉米苗造成较高损伤风险,尤其是伤根风险[5]。因此,杂草的高效精准检测为促进化学除草由地毯式喷洒向靶向喷洒转变,根据杂草分类施用除草剂提供可能。此外,杂草检测对株间机械除草方式提供选择性。实现田间杂草的精准检测和分类,可降低化学药剂的使用,减少成本和保护环境,提高机械除草的工作效率,对促进除草机器人发展具有重要意义。
学者针对杂草检测已展开大量研究,Alchana⁃tis等基于声光可调高光谱传感器和一组算法检测野草,其中基于纹理特征,利用光谱特征和鲁棒统计特征进行检测,错误识别率达15%[6]。何东健等针对单一特征识别杂草的低准确性和低稳定性,提出一种支持向量机(SVM)和DS(Shafer-Dempster)证据理论相结合的多特征融合杂草识别方法。该方法中多特征包括植物的叶片形状、纹理和分形3类,试验结果显示对杂草的识别率可达96.11%[7]。张小龙等研制的变量喷洒控制系统需要对杂草进行精准识别,根据其色差分量R-B颜色特征,基于Canny算子对识别的杂草边缘检测并提取其面积、密度和形心位置3个特征参数进行定位,结果显示识别率达83.5%,均方差0.066[8]。
近年来,随机器学习发展,基于深度学习技术的检测手段在农业中应用广泛[9-10]。Tang等使用卷积神经网络检测大豆作物图像中杂草,并对阔叶科杂草和禾本科杂草分类,对杂草的检测准确率高达98%以上[11]。姜红花等针对田间复杂环境下杂草分割精度低的问题,提出基于Mask R-CNN的杂草检测方法。姜红花等在玉米、杂草数据集和复杂背景下的玉米、杂草图像上分别测试,mAP均>0.78,单样本耗时均<290 ms,检测效果较好[12]。Quan等以VGG19为主干网络改进Faster RCNN,完成对复杂田间环境下不同生长阶段玉米幼苗检测,准确率高达97.71%[13]。为探究其他基于深度学习技术的检测模型对田间目标的检测效果,文章对多工况下玉米苗和杂草图像采集并制作标准数据集。使用YOLO v4网络作为模型训练方法,研究不同模型之间检测性能,不同数据量以及不同数据增强方式对模型性能的影响,对比多类别组合训练和单一类别独立训练的效果。
1 材料与方法
1.1 数据材料
1.1.1 数据采集
田间环境复杂,地面杂草形态丰富,同一物种的不同个体在颜色和形状之间也存在差异。部分杂草与玉米苗形态相近,田间光照强度和自然风等外界因素变化较多。针对以上非结构化的田间复杂环境,需大量多工况下苗草图像制作特征丰富的数据集,前期图像采集尤为重要。
苗草图像采集地点位于东北农业大学试验田,采集时间2020年6月。通过机器人移动平台获取田间图像,获得图像接近实际作业环境,图1a为机器人移动平台的田间工作场景,b为机器人移动平台图像采集示意图,摄像头安装在机器人移动平台可升降挂载架上。Quan等在采集玉米苗图像时,为获得丰富的数据集,提出3类田间工况:多角度、全周期、多天气[13]。文章基于上述研究构建数据集。玉米田的最佳除草期为3~5叶苗期,故选取玉米3~5叶苗期进行数据采集[14];倾斜拍摄虽然能够获取部分立体信息,但易造成玉米苗对杂草遮挡且拍摄图片中两者比例与实际不符,故文章采用摄像头垂直向下,距离地面高度1.0 m拍摄;分别于6月3日(小雨)、6月8日(多云)、6月11日(晴)三种天气状况下采集数据,采集时段:8:30~10:30、13:30~15:30、17:00~18:00开展田间苗草图像采集工作,共采集1 200幅图像。

图1 玉米苗和杂草图像采集Fig.1 Image collection of maize seedlings and weeds
1.1.2 数据增强
为提高数据集样本丰富性,对采集到的图像进行数据增强处理。本研究对采集到的原始图像进行颜色、亮度、对比度、噪声和旋转5种处理。
1.1.2.1 亮度处理
亮度处理图像。不同时段光照变化对检测模型性能产生不利影响。图像亮度过高或过低会导致目标边缘不清楚,手动标记时难以绘制边界框。为降低光照强度不稳定的影响,确定亮度调节系数为0.6~1.4[15],补偿神经网络因图像采集时间集中引起照明强度不稳定问题。
1.1.2.2 对比度处理
对比度增强处理图像。使用对比度增强算法改善苗草轮廓与背景色之间对比度。对比度增强是将图像中亮度值范围拉伸或压缩到显示系统指定的亮度显示范围内,增加图像整体或部分对比度。将原始图像中每个亮度值映射到新图像中新值,使0.3~1的值映射介于0~1之间[15]。
1.1.2.3 添加噪声
噪声处理图像。向图像中随机添加少量噪声会干扰图像中每个像素RGB,可防止神经网络拟合输入图像的所有特征,防止过度拟合。高斯噪声通常表现为孤立的像素或像素块,对图像产生强烈的视觉效果,选择在原始图像上添加均值为0.1和方差为0.02的高斯白噪声[15]。
1.1.2.4 图像模糊
在实际应用场景中,相机抖动及快速移动,可能导致焦距不精准、图像不清楚。本文使用旋转对称的高斯低通滤波器,其大小为[5,5],标准偏差为5,使生成图像模糊。将模糊图像作为样本,以进一步提高检测模型的鲁棒性[15]。
1.1.2.5 旋转
旋转处理图像,分别作90°、180°、270°旋转以及镜像处理,同时以0.7、0.8、0.9和1.1、1.2、1.3的缩放处理对数据集进一步扩充,改善神经网络的检测性能。对选择后图像作上述数据增强处理后,处理效果见图2,数据集样本数量见表1。经过以上处理后,数据集样本量从最初1 200张扩充为7 200张。
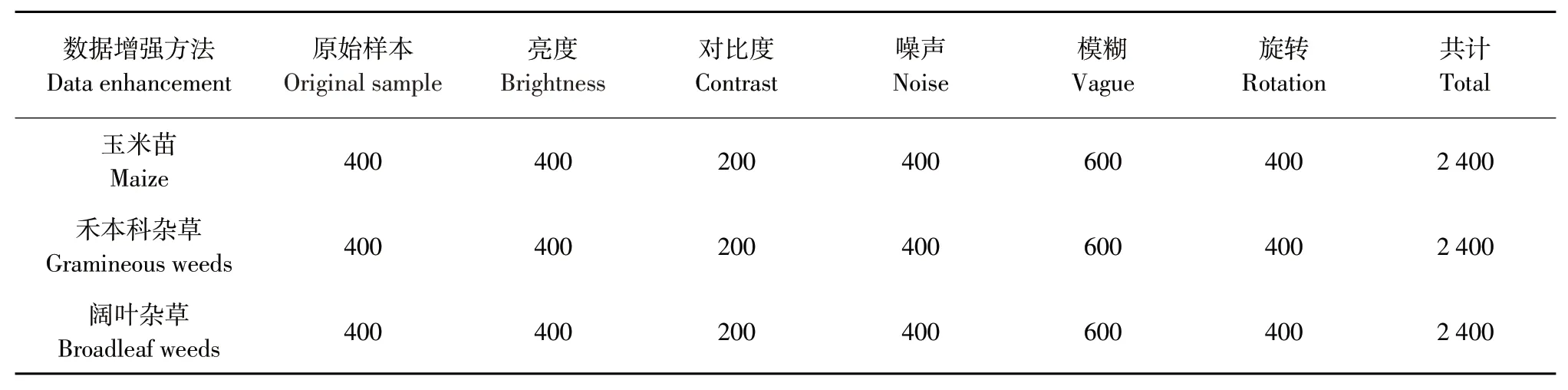
表1 数据增强后图像数量Table 1 Number of images generated by data augmentation methods

图2 数据增强处理Fig.2 Data enhancement processing
1.1.3 数据集标记
图像标记是训练检测模型的关键,标记质量决定检测模型的准确率。本研究在标记时,使用专业标记软件LabelImg手动创建图像标签,制作PASCAL VOC数据格式的玉米苗和杂草数据集,数据标注示意见图3。未标记具有不清楚像素区域的阳性样品,以防神经网络过度拟合。未标记遮挡面积大于85%的目标和图像边缘小于15%的目标。

图3 数据标注示意Fig.3 Data labeling diagram
黑龙江省玉米田一般受两类杂草危害,一类是稗草、狗尾草等禾本科杂草,另一类是苋菜、灰菜、蓼吊子、苍耳等阔叶杂草,故将田间杂草分为禾本科杂草和阔叶杂草两类[16]。文章参照Alessandro等提出的杂草检测方法,将田间杂草分为禾本科杂草和阔叶杂草[17],因此选取3个标签对图像中目标作标记,分别为:玉米苗(Maize)、禾本科杂草(Weed1)和阔叶杂草(Weed2)。通常1个完整的数据集包括训练集、验证集和测试集。训练集的作用是训练模型,计算梯度,更新权值。验证集用于避免过拟合,同确定一些超参数。测试集用来测试模型性能。本文中的训练集、验证集和测试集的组成比例分别为40%、40%和10%[11]。
1.2 检测网络
YOLO(You Only Look Once),是由Joseph Red⁃mon等于2015年创建的新算法[18]。YOLO算法与基于区域分类算法不同,其单个卷积网络可在一次算法运行中预测整个图像的目标类别和Bounding box(边界框)。输入图像被分为S×S个网格,每个网格检测1个对象。在每个网格中,本文取m个边界框,对于每个边界框,网络提供一个边界框和类概率的偏移值,选择类概率高于特定阈值的边界框,并进一步用于定位图像中的对象。
YOLO[18],YOLO v2[19]和YOLO v3[20]网络,属于一阶段检测网络。YOLO v4网络采用多尺度检测算法,能有效检测图像中大目标和小目标[21]。YO⁃LO v4网络结构较YOLO v3更复杂,在特征提取方面,由主干特征提取网络Darknet53更新为CSP⁃Darknet53[22];在特征金字塔结构部分,采用空间金字塔池化结构(Spatial pyramid pooling,SPP)和路径聚合网络(Path aggregation network,PAN)。SPP可显著改善感受域尺寸,提取上下位特征,网络处理速度无明显下降;PAN网络结构通过自下而上的路径增强方法增强具有精确定位信号的特征层次结构,缩短底层和最顶层之间信息路径,避免信息丢失问题,同时拼接后特征图得到的信息既包含底层特征也包含语义特征。
在玉米苗3~5叶期,图像中杂草和玉米苗在尺寸上相差较大,因此调整输出张量以适应不同大小目标的检测。YOLO v4网络原输出张量为26×26尺度,针对大目标玉米苗将输出张量增大四倍、变为52×52尺度,而小目标杂草输出张量缩减四倍、变为13×13尺度。其目的是提高整体模型速度,使其更好检测到玉米苗(大目标)和杂草(小目标),基于修改后YOLO v4网络的杂草和玉米苗检测流程[23]见图4。
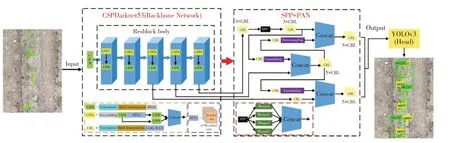
图4 修改后YOLO v4网络苗草识别过程Fig.4 YOLO v4 network seedling identification network architecture diagram
1.3 方法
1.3.1 硬件介绍
本文使用Pytorch框架搭建网络,在工作站上进行训练。工作站配置为:显卡GeForce RTX 2080Ti NVIDIA(11 GB内存),CPU为Intel Xeon E5-2678 V3(12核和24线程,2.50 GHz,30 M,22 nm)32 GB RAM,操作系统为Ubuntu16.04 LTS,安装CUDA和cuDNN库,Python版本为3.6,Pytorch版本为1.3。
1.3.2 模型训练
7 200 幅训练集图像用于训练,其余图像进行验证和测试。因杂草目标尺寸较小,为提升检测精度,选择输入尺寸为416×416像素。将图像分成13×13像素的网格单元,以便向网络输入开展训练。训练时,以32幅图像作为1个批次,每训练1批图像,更新1次权值参数。根据1预试验结果,权值衰减速率设为0.0005,动量因子0.9,最大训练次数20 000,初始学习率0.0005。在迭代次数为15 000和18 000时,学习率降低为初值10%和1%,使模型在训练后期振荡减小,更接近最优解。
本文对修改后YOLO v4模型进行20 000次迭代,损失变化曲线见图5。由图5可见,前1 000次迭代损失值急剧减小,直到4 000次迭代后趋于稳定,后面训练过程中损失值波动平缓,在小范围内振荡。
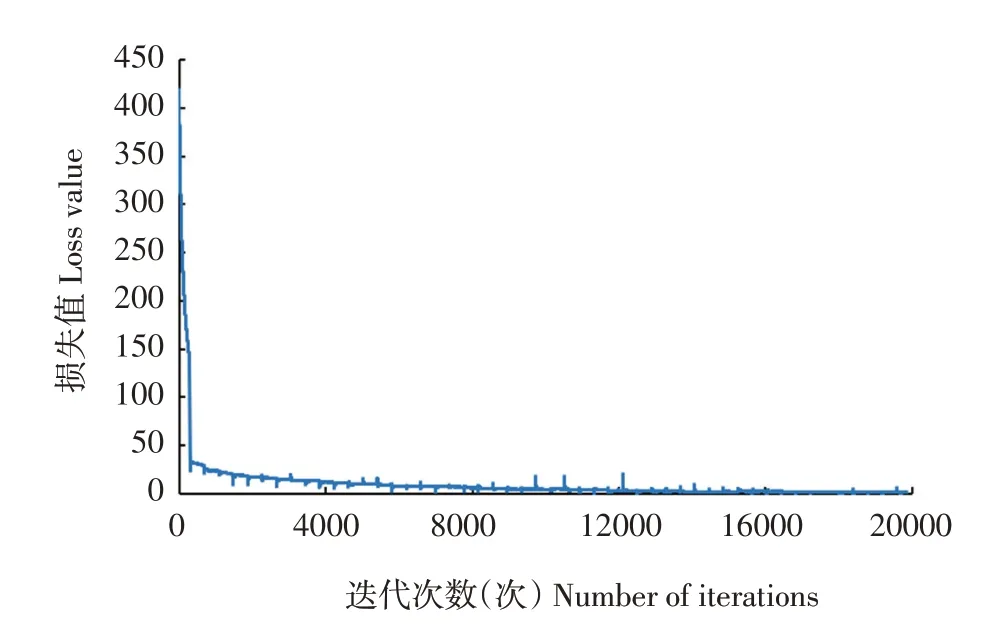
图5 损失值随迭代次数变化曲线Fig.5 Changing curve of loss value with iterations
训练过程中每代完成后在验证集上对模型评估,计算F1值、mAP、准确率P和召回率R这4个指标,将这些数据保存至日志文件中,并使用Tensorboard软件对训练过程进行实时监控。对于二分类问题,可根据样本真实类别和模型预测类别组合将样本划分为4种类型:预测为正的正样本(True positive,TP),数量为TP;预测为负的正样本(False negative,FN),数量为FN;预测为正的负样本(False positive,FP),数量为FP;预测为负的负样本(True negative,TN),数量为TN[24-25]。
准确率P表示预测为正的所有样本中真正为正的样本所占比例,计算公式为:

召回率R表示真正为正的样本中被预测为正的样本所占比例,计算公式为:

F1值(F1)可综合考虑准确率和召回率,是基于准确率和召回率的调和平均,定义为:
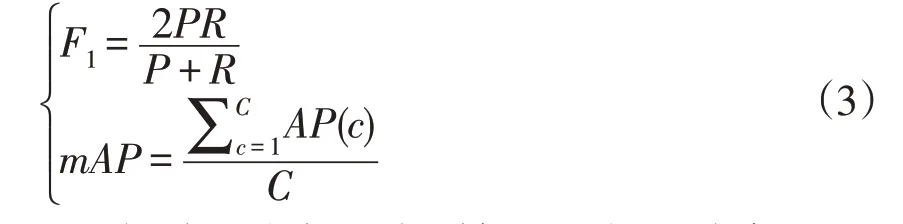
在目标检测中每个类别都可根据准确率P和召回率R绘制P-R曲线,AP值为P-R曲线与坐标轴之间面积,而mAP是所有类别AP值的平均值。为对模型性能进行恰当排序,需要明确性能参数优先级。在检测系统中,试验采用的性能参数优先级由大到小依次为mAP、F1值、P、R。
2 结果与分析
2.1 不同网络之间比较
为验证文章提出修改后的YOLO v4网络检测性能,将玉米苗和两类杂草图像用作训练集,同将该模型与YOLO v3、原本YOLO v4和Faster R-CNN进行比较,其中FasterR-CNN的主干网络为VGG19。
在测试集上,几种模型P-R曲线和混淆矩阵见图6、7。表2为各模型的F1值,IoU和平均检测时间。
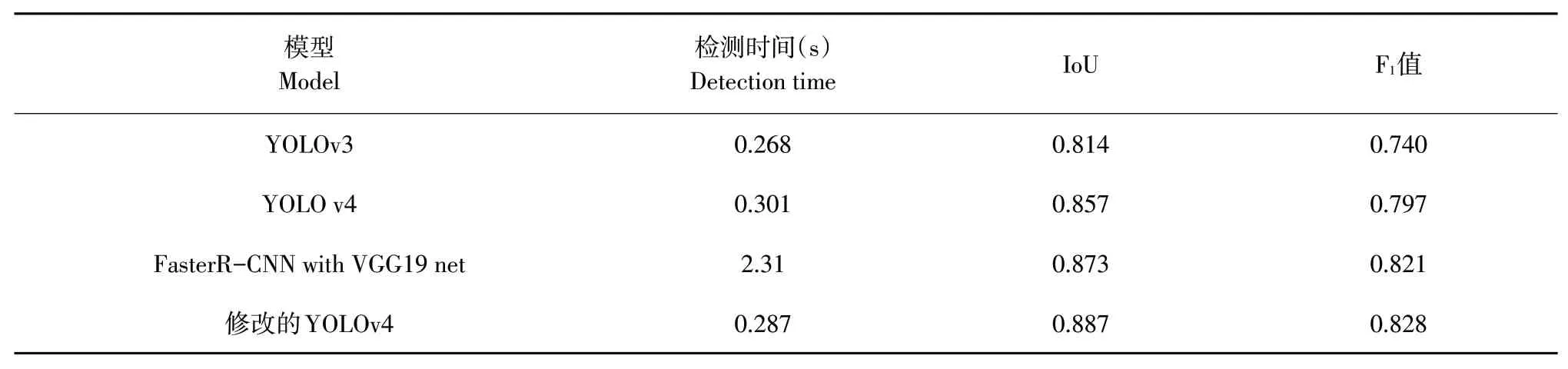
表2 不同网络检测性能对比Table 2 Number of images generated by data augmentation methods
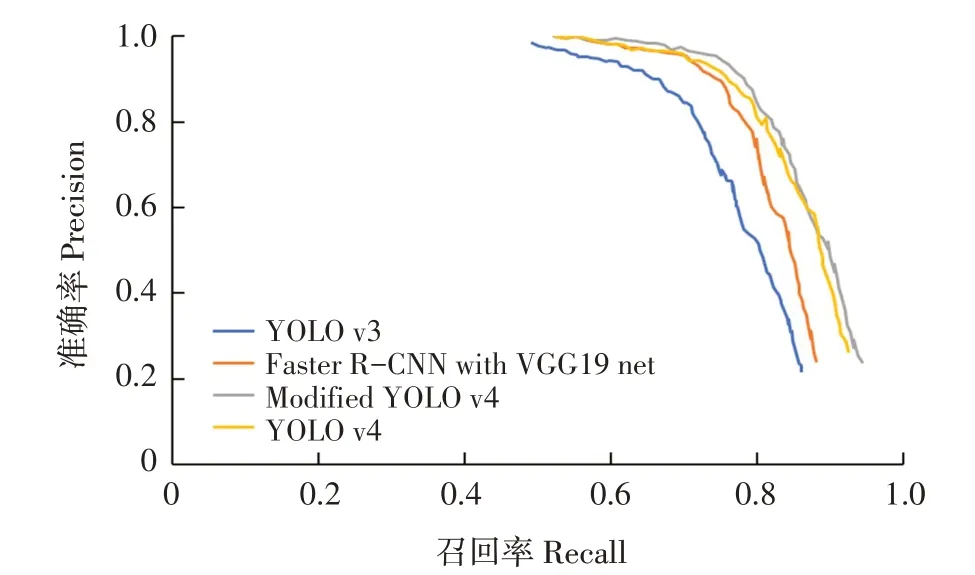
图6 不同检测模型的P-R曲线Fig.6 P-R curves of the detection models
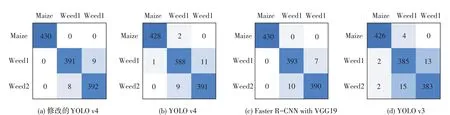
图7 不同检测模型混淆矩阵Fig.7 P-R curves of the detection models
在检测性能方面,提出修改后YOLO v4模型优于主干网络为VGG19的FasterR-CNN,YOLO v4和YOLO v3模型。修改后YOLO v4 F1值为0.821,高于其他3个模型。表明具有两个检测尺度的YOLO v4模型的综合召回性能和精度优于其他3个模型。修改后YOLO v4 loU值为0.878,高于其他3个模型的loU值。结果表明,修改后YOLO v4在边界框检测中准确性高于其他3个模型。修改后YOLO v4的平均检测时间最短,且相较于原本YOLO v4模型变化明显,减少0.306 s,比主干网络为VGG19的Faster R-CNN缩短1.824 s。可提供高分辨率图像中苗草实时检测。在检测过程中,修改后YOLO v4模型提供的准确性和置信度显著高于其他3个模型,反映修改后YOLO v4检测模型的优越性。
2.2 不同数据类别对模型的影响
为比较数据类别对检测结果的影响,使用修改后YOLO v4网络分别训练玉米苗、禾本科杂草和阔叶杂草,同时,三类数据的组合也作为一类数据用于训练。训练后模型的P-R曲线见图8。修改后的YOLO v4检测模型在4种类别(玉米苗、禾本科杂草、阔叶杂草、三类数据组合)的F1值分别为0.871、0.845、0.841、0.816。
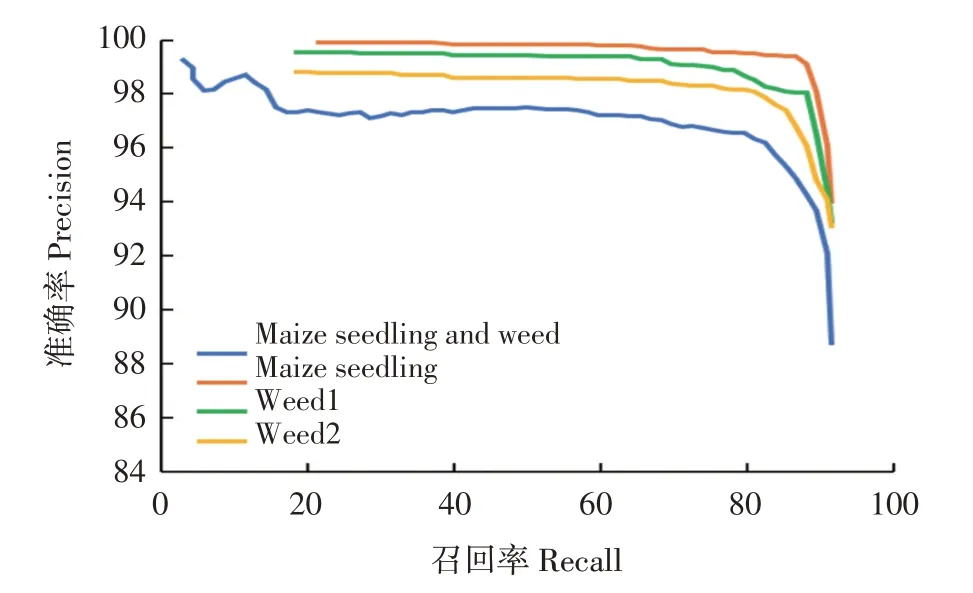
图8 苗草检测模型在不同数据类别上P-R曲线Fig.8 P-R curves of maize seedling and weed detection models in several categories
根据以上检测结果可知,使用每1类数据训练得到模型的F1值分数高于将3种类别组合训练模型的F1值。这表明输入类别数量影响模型检测能力。禾本科杂草和阔叶杂草包含的杂草种类较多,每种杂草特征不同,因此两类杂草较玉米苗的检测结果差。玉米苗单个体积大、重叠少,且种类单一,所以该模型对玉米苗检测性能最佳。模型检测结果见图9。

图9 玉米苗和杂草检测效果Fig.9 Effectiveness of identification of corn seedlings and weeds in field trials
2.3 数据量和数据增强对模型的影响
在本节中,分析图像数据集大小对修改后YO⁃LO v4模型的影响。从每个数据类别中随机选择100、200、300、500、1 000、1 500和2 000张目标图像,分别形成包含300、600、900、1 500、3 000、4 500和6 000张图像的训练集。
表3显示对应于不同大小的训练集模型的F1值和IoU值。

表3 不同数量图片训练的模型F1值和IoUTable 3 F1 scores and IoU of models trained with different numbers of images
试验发现修改后YOLO v4模型的性能随训练集大小增加而提高。如果训练集少于1 000张图像,则随训练集增长,性能迅速提高;当数量超过1 000张时,增强速度会随图像训练集增加而逐渐降低。当图像数量超过1 500时,训练集大小不会对模型性能产生更大影响。本研究中每个数据类别选择2 400张目标图片,数据集数量符合最终模型测试需求,能够得到模型测试的效果。
为验证不同数据增强方法对训练模型的影响,使用控制变量方法即每次删除一种数据,获得IoU值和F1值。添加噪声处理可改善检测效果,删除噪声处理降低检测精度。亮度转换有利于模型适应全天照明情况。通过去除亮度变换,训练模型的检测结果较使用完整数据集训练的模型检测结果差。旋转变换对训练模型影响有限,去除旋转变换后训练模型性能略低于完整数据集性能。模糊处理对提高模型鲁棒性有利,与未模糊处理的数据集相比,使用完整数据集训练的模型具有更高检测精度。不同数据增强方式的性能表现见表4。
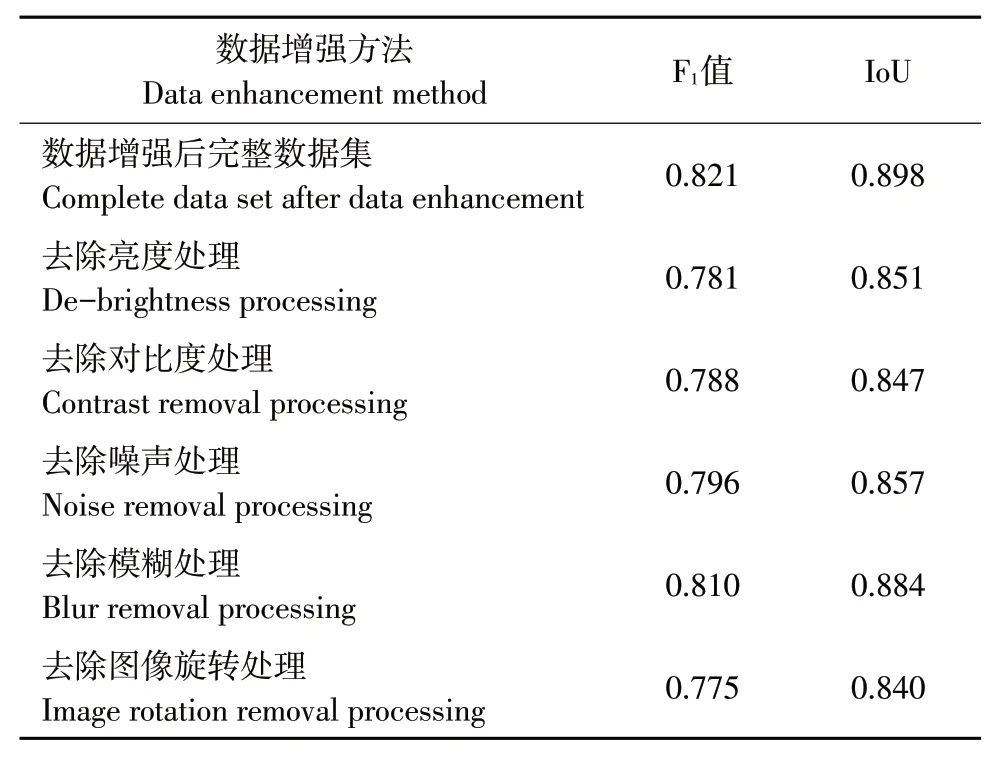
表4 基于控制变量方法模型训练的F1值和IoUTable 4 F1 scores and IoU values for models trained using the control variable method
3 结论
a.文章针对玉米田中玉米苗和杂草识别问题,采用多苗期、多时段和单一拍摄角度的图像采集方式并配合数据增强方法制作特征丰富的数据集。训练修改后YOLO v4网络使用制作的数据集得到苗草检测模型,在测试集上性能表现良好,对指导田间精准除草具有重要意义。
b.对比修改后YOLO v4网络与YOLO v3、YOLO v4和主干网络为VGG19的FasterR-CNN。修改后YOLO v4网络F1值为0.828,优于其他3类模型,较修改前网络提升0.031,检测时间缩短0.014 s。修改后YOLO v4网络的IoU为0.887,为4个模型中最高。
c.采用不同类别数据集对网络作训练,得到不同检测性能模型。其中,玉米苗F1值最高,为0.871,玉米苗和杂草组合训练后模型F1值最低,为0.816。对不同类别目标进行单一训练比多类别目标组合训练效果好。
d.不同数据增强方法和不同数量数据集对网络作训练,模型检测性能不同。随训练集数量增加,F1值和IoU也随之增加,当训练集数量为2 000时,F1值为0.835,IoU为0.841,相比于数量为100得到的模型F1值提升75%,IoU提升70%,提升效果显著。此外,不同数据增强方法对模型F1值和IoU影响也不同,图像模糊处理对F1值贡献最大,为0.046,图像旋转处理对IoU贡献最大,为0.058。
