基于高光谱的小米产地溯源策略与模型研究
2021-09-09孙红敏董元李晓明孔繁泽
孙红敏,董元,李晓明,孔繁泽
(东北农业大学电气与信息学院,哈尔滨 150030)
小米是我国重要粮食作物之一[1],主要产区分布于黄河流域,包括内蒙古、陕西、甘肃等北方各省半干旱地区[2],受气候、土壤等因素影响,不同产区小米营养成分具有一定差异性[3]。在经济利益驱动下,一些不法商家假冒小米地理源信息,扰乱市场秩序,增加小米及其他农产品质量安全监控难度,对小米产地溯源方法和技术提出更高要求。因此,研究高效、精准的小米产地溯源方法对我国粮食安全及农产品地理标志保护具有重要意义[4]。
光谱技术因其高效无损的判别特性,在农作物溯源领域具有良好适用性[5]。宋雪健等利用近红外漫反射光谱技术结合因子化法等方法精准判别肇州、肇源两地小米[6];李佳洁等利用近红外光谱技术结合马氏距离法、线性判别法判别分析3个产地小米[7];李楠等利用近红外光谱技术结合费舍尔线性判别和多层感知器神经网络模型判别多个产地小米[8];田雪等采用傅里叶变化红外光谱和二维相关红外光谱分析技术鉴别4个小米品种[9]。上述研究表明光谱技术应用于小米产地溯源具有可行性,但普遍存在研究选取样本产地数量较少、多产地样本判别准确率偏低等问题。基于图像、光谱信息融合优势,高光谱成像技术已逐渐应用于农产品溯源研究[10],王庆国等利用偏最小二乘法实现玉米种子产地和年份鉴别[11];王朝辉等利用高光谱9个特征波长判别分析2种大米[12];林珑等利用HOG特征建立基于单波长图像特征的支持向量机模型识别东北和非东北大米[13];Deng等利用高光谱结合半监督分类算法识别水稻种子[14];Bao等利用高光谱成像结合线性判别分析、支持向量机和极限学习机基于全波长和特征波长建立分类模型识别小麦[15];吉海彦等基于高光谱成像技术,利用线性判别分析和支持向量机、逻辑回归结合的递归特征消除模型判别5种小米产地[16]。
目前研究主要集中于粮食作物产地、品种、物质含量等方面的光谱检测,但高光谱技术在小米产地溯源方面研究尚少,且现有溯源判别准确度有待提高。
研究表明,小米产地是影响其营养物质含量的主要因素之一。刘为红等利用近红外线分光光度计对5种小米样本开展试验,验证不同气候因子对小米中蛋白质和脂肪含量的影响,发现蛋白质和脂肪受不同环境的积温、降水量、日照时长及土壤化学成分影响显著[17];梁克红等对比5个地区小米营养物质含量,得出不同产地温度及土壤中矿物质元素含量是影响小米蛋白质合成关键因素,此外,产地因素对小米中膳食纤维含量影响大于品种因素[18];刘晓东等研究发现品种和地域因素对小米中矿物元素含量影响显著[19];王瑞等发现相同品种小米种植在不同地区含量差异最大的营养物质是直链淀粉、维生素、粗蛋白和粗脂肪[20]。
综上所述,产地对小米中脂肪、蛋白质、膳食纤维和矿物元素等营养物质含量影响显著。其中,脂肪和蛋白质含量差异较为明显,小米中脂肪含量变幅为1%~4%。蛋白质含量变幅为9%~13%,不同产地小米物质含量差异性在其高光谱数据中也有体现,说明基于高光谱技术研究小米产地溯源具有理论意义及可行性。本研究以3个产区7个产地小米样本为研究对象,提出新的小米产地溯源策略,建立基于该策略的小米产地判别模型。
1 材料与方法
1.1 样本收集
本研究收集小米样本共126份,来自全国3个小米主产区,包括54份西北地区小米样本(甘肃、陕西、宁夏),36份东北地区小米样本(内蒙古、黑龙江),36份中部地区小米样本(河南、山西),采集样本均真空密封保存于同一避光干燥环境。待测样本均匀铺满直径50 mm、高10 mm一次性培养皿,保持表面平整,每份样本采集8条平均光谱反射率,共收集到1 008条平均光谱反射率数据,如表1所示。

表1 小米样本数据Table 1 Data of millet samples
1.2 高光谱成像系统与数据采集
试验数据采集使用Headwall公司生产高光谱成像系统见图1。系统硬件部分包括高光谱图像摄像仪(HyperSpecVNIR)、CCD相机(1 392×1 024)、镜头(Compact Schneider Xenoplan)、可调节高光谱升降台、100 mm或250 mm运动距离精准直流伺服线性控制器、150 W可调功率光纤卤素灯(Illumination Techonologies USA)、电控移动平台、标准反射白板以及计算机构成。光谱范围为400~1 000 nm,采样波段间隔为0.74 nm,分辨率为2~3 nm,空间分辨率为0.15 mm。系统由计算机控制,通过Hyperspec软件控制移动速度、曝光时间、扫描步长、扫描宽带、压缩倍数等试验参数。
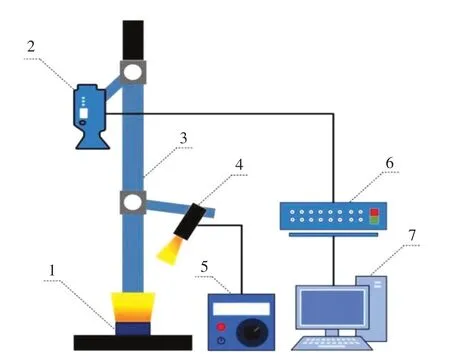
图1 高光谱成像系统装置Fig.1 Schematic diagram of hyperspectral imaging system
为保证试验光源一致性,减少外部光源影响,试验于密闭黑箱中完成,将系统开机预热180 s后采集图像,设置参数如下:曝光时间0.250 s,物距450 mm,载物台起始位置90 mm,终止位置130 mm,移动速度8.5 mm·s-1。为降低高光谱图像采集时由于系统光源因素或摄像头暗电流干扰产生大量噪声,每组样本拍摄完毕后,对高光谱成像系统开展一次黑白标定校正,获取标准白板标定和全黑标定图像,开展亮、暗电流校正[21],校正公式如公式(1)所示:

R为校正后图像;Rsample为样本图像;Rwhite为标准白板标定图像;Rdark为全黑标定图像[22]。
1.3 数据分析方法与模型评价指标
试验采集126份小米样本高光谱图像,共提取1 008条平均光谱反射率数据,使用ENVI Classic 5.3软件(美国Exelis Visual Information Solutions公司)对每张高光谱图像选取8个面积约4 mm×4 mm ROI区域,计算所选取ROI区域内像素平均光谱反射率,并将得到的ROI平均光谱反射率计算结果,作为该样本一条试验光谱反射率数据。
为提高高光谱信噪比,减少试验时受光线散射、光程变化、基线漂移等多种因素引起的大量噪声,使用标准正态变换处理(Standard normal vari⁃ate,SNV)、平滑处理(Savitzky-golay,SG)方法,对采集到的光谱反射率作数据预处理[23]。
采用主成分分析(Principal component analysis,PCA)和偏最小二乘判别分析(Partial least squarediscriminant analysis,PLS-DA)方法对高光谱数据作定性判别分析,通过PCA判别结果获取小米产地溯源可行性,计算主成分得分以判定各样本间差异性,通过PLS-DA建立小米样本产地判别模型;建模软件使用Matlab(R2019b),采用残差统计剔除异常值,置信水平设为95%(P<0.05);为避免过拟合,在校正模型中使用“venetian blinds”法作交互验证(CV),数据级随机划分8次,保留样本比率13%;试验利用Kennard-Stone法对得到的光谱样本数据集作划分处理,划分75%样本集作校正集,建立校正集定性判别模型,划分25%样本作为验证集对校正集建立的定性模型作验证[24];模型性能定性分析用模型灵敏度、特异度、分类误差评价,模型灵敏度、特异度越接近于1,分类误差越接近于0,说明定性判别效果越好;以下公式用于计算评价指数,式(2)为灵敏度计算公式,式(3)为特异度计算公式,式(4)为分类误差计算公式。
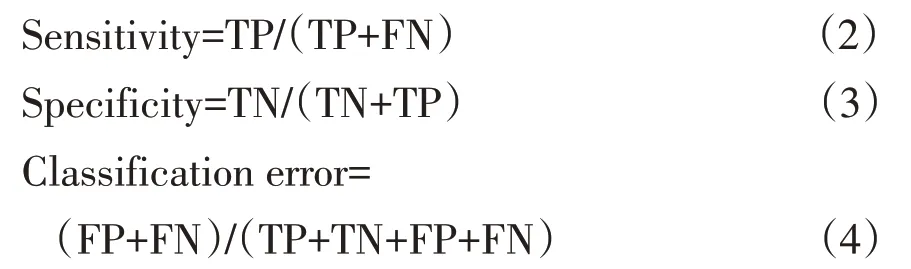
其中,TP为真阳性样本个数;TN为真阴性样本个数;FP为假阳性样本个数;FN为假阴性样本个数。
2 结果与分析
2.1 小米产地溯源主成分分析
对7个产地小米样本高光谱数据作P CA判别,得到7个产地小米样本主成分载荷图见图2。在图2(a)中,第一、第二主成分分别占总变异系数22.40%和11.56%,内蒙古、黑龙江两个产地样本点全部分布在第一主成分正半轴,陕西样本点大多分布在第一主成分正半轴,少量落在负半轴,内蒙古、黑龙江、陕西3个产地相互重叠且分布集中、聚类明显,宁夏样本点少量分布在第一主成分正半轴,多数分布在负半轴,其余甘肃、河南、山西3个产地分布在第一主成分负半轴;在第一主成分上,内蒙古、黑龙江、陕西3个产地和宁夏、河南、山西、甘肃4个产地有明显区分。宁夏、甘肃两个产地样本点相互重叠全部分布在第二主成分正半轴,河南、山西两个产地样本点相互重叠分布在第二主成分负半轴,沿第二主成分,宁夏、甘肃与山西、河南有明显区分。在图2(a)中,内蒙古、陕西、黑龙江聚类明显,宁夏、甘肃聚类明显,山西、河南聚类明显,三类样本点可显著区分,但每类各产地间重叠严重无法有效区分。
在图2(b)中,第三主成分占总变异系数8.01%,甘肃样本点分布在第三主成分正半轴,宁夏样本点分布在负半轴,山西样本点大量分布在第三主成分正半轴,少量分布在负半轴,河南样本点大量分布在负半轴,少量分布在正半轴,对比图2(a),在第一、二主成分中聚类明显的甘肃、宁夏两个产地在第三主成分上有明显区分,样本点几乎无重叠;在第一、二主成分中聚类明显的河南、山西在第三主成分上可区分,样本点仅有少量重叠;内蒙古、陕西、黑龙江仍无法明显区分,但重叠情况有所改善。对7个产地小米样本溯源分析发现,高光谱信息具有溯源小米产地的可行性。在上述分析中,不同产区样本聚类明显,可能与相邻产地间土壤、海拔、气候及降水量等环境因素相近有关。

图2 小米产地溯源主成分分析载荷图Fig.2 Principal component analysis load diagram of millet origin traceability
2.2 小米产地溯源判别模型
基于7个产地小米样本建立PLS-DA鉴别模型,利用高光谱数据对不同产地小米作溯源分析,模型判别结果如表2所示,与主成分分析结果相同,各产地PLS-DA判别表现依次为:甘肃>山西>宁夏>河南>内蒙古>黑龙江>陕西,其中甘肃表现最好,灵敏度为0.993,特异度为1.000,分类误差为0.003;山西、宁夏、河南灵敏度分别为0.979、0.972、0.944,特异度分别为0.994、0.992、0.964;分类误差分别为0.013、0.018、0.046;内蒙古、黑龙江、陕西表现较差,灵敏度分别为0.958、0.896、0.826,特异度分别为0.894、0.836、0.870,分类误差分别为0.074、0.134、0.152。在7个产地小米样本光谱数据溯源分析模型中,各产地溯源模型灵敏度、特异度两项评价标准均高于0.80。结果表明,利用7个产地小米样本高光谱数据建立的溯源判别模型对小米产地溯源具有可行性,但判别结果准确性有待提高。

表2 小米产地溯源PLS-DA模型判别结果Table 2 Discriminant results of millet origin traceability PLS-DA model
7个产地小米样本溯源模型分析结果见图3,同一产区不同产地间存在相互干扰,图3(a)与表2中数据结果一致,甘肃不受其他产地影响,区分效果明显;图3(b)中对陕西的判别结果受其他产地影响较大;图3(c)中对河南的判别结果主要受山西干扰;图3(d)和图3(e)中对黑龙江的判别主要受内蒙古、宁夏影响,对内蒙古的判别主要受黑龙江、陕西影响,其中黑龙江和内蒙古两个产地相互干扰最为严重;图3(f)和图3(g)中对宁夏、山西的判别几乎不受其他产地影响,区分情况较好。
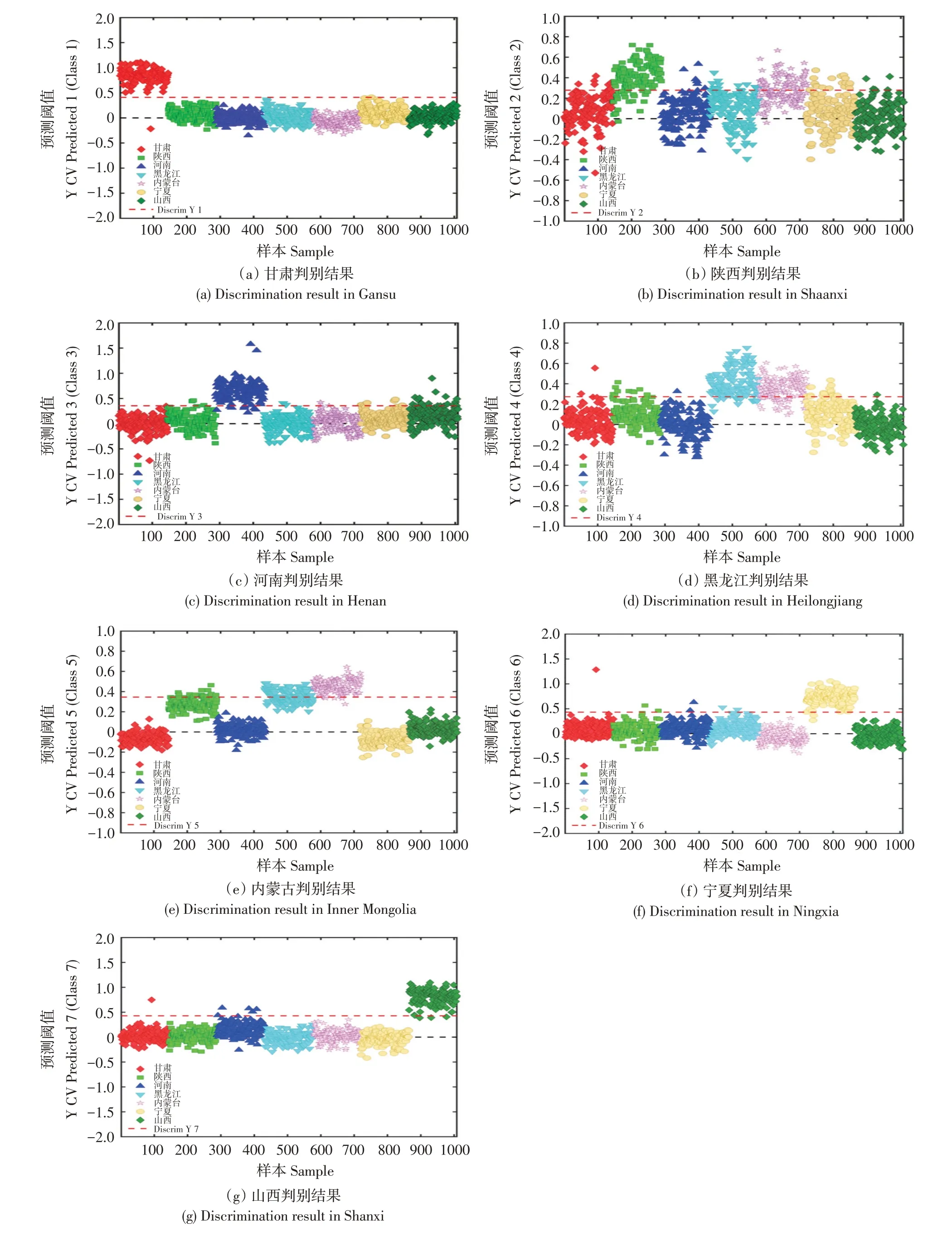
图3 小米产地溯源PLS-DA判别分析图Fig.3 PLS-DA discriminant analysis chart of millet origin traceability
2.3 小米产地溯源策略
在溯源分析中不同产区(东北、西北、中部)小米样本存在明显聚类现象,这一聚类现象可能影响模型溯源准确度。在不同产地小米样本PLSDA模型判别分析中发现,同一产区不同产地小米样本间相互干扰情况较严重,证实“聚类现象会影响模型判别准确度”这一观点,提出同一产区不同产地小米样本间相互影响可能是造成模型判别准确度较低的原因。结合相关研究[25-28],发现PLSDA模型判别样本范围越小,变量间相关性越高,模型性能越好,在基于PLS判别模型中也显示出相似结果。
综上,为提升鉴别模型准确度,消除不同产地小米样本间相互干扰,提出基于高光谱成像技术的小米“产区-产地”二级溯源策略,如图4所示。基于“产区-产地”二级溯源策略对本研究多分类模型作拆解和集成,在本研究中拆解依据是根据产区划分不同产地,基于溯源策略将原本一级溯源模型叠加成二级溯源模型,以减小不同产区样本聚类现象,提高分类精度。

图4 小米产地溯源策略流程Fig.4 Flow chart of millet origin tracing strategy
实施步骤如下:首先对提取的小米光谱平均反射率预处理,建立PLS-DA模型对小米产区溯源,判定小米所属产区(东北、西北、中部),基于产区判定结果,进一步建立PLS-DA模型对小米产地作溯源分析。
2.4 小米溯源策略可行性分析
基于“产区-产地”溯源策略对不同产区小米光谱数据作可行性分析,得到主成分得分图如图5所示。第一主成分和第二主成分分别占总变异系数23.62%和11.99%,东北地区样本点分布在第一主成分正半轴,西北地区、中部地区样本点分布在第一主成分负半轴,在第一主成分上,东北地区与西北地区、中部地区有明显区分;在第二主成分上,西北地区样本点分布在正半轴,中部地区样本点分布在负半轴,西北地区与中部地区区分显著;对3个产区小米样本作溯源分析发现,高光谱信息具有溯源小米产区的可行性;且各产区间区分显著。
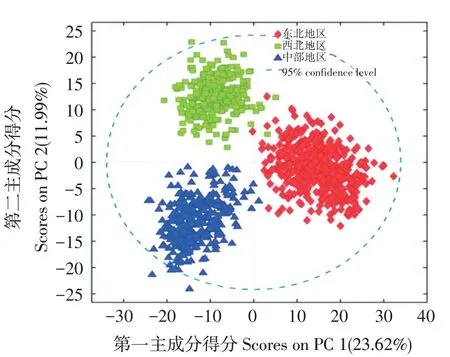
图5 小米产区溯源主成分分析载荷图Fig.5 Principal component analysis load graph of different origins
在此基础上,进一步建立不同地区小米样本PLS-DA判别模型,模型结果如表3所示。东北地区、西北地区、中部地区灵敏度分别为0.997、1.000、1.000,特异度分别为0.997、0.999、1.000,分类错误分别为0.003、0.001、0.000,3个地区均取得良好判别结果,验证溯源策略可行性。

表3 小米产区溯源PLS-DA模型判别结果Table 3 Discriminant results of traceability PLS-DA model for millet production areas
2.5 基于小米“产区-产地”二级溯源策略判别模型
基于上述分析结果,建立小米产地PLS-DA溯源模型,模型结果如表4所示。7个省份PLS-DA模型,灵敏度分别为:甘肃1.000、陕西0.958、河南1.000、黑龙江0.917、内蒙古0.910、宁夏1.000、山西0.993;特异度分别为:甘肃1.000、陕西0.976、河南0.993、黑龙江0.958、内蒙古0.965、宁夏1.000、山西1.000;分类误差分别为:甘肃0.000、陕西0.033、河南0.003、黑龙江0.063、内蒙古0.063、宁夏0.000、山西0.003。对比分析可知,基于小米“产区-产地”二级溯源策略的小米产地溯源模型准确度显著提升。

表4 基于小米产地溯源策略建立的PLS-DA模型判别结果Table 4 Discriminant results of PLS-DA model based on millet origin traceability strategy
小米产地PLS-DA溯源模型判别分析结果如图6所示,前文中明显聚类的甘肃、宁夏和河南、山西此时分类效果较好,可显著区分;内蒙古、陕西、黑龙江聚类情况得到改善,3个产地间干扰明显减弱。可见,溯源策略有效提升小米产地溯源模型判别准确度。

图6 基于小米产地溯源策略建立的PLS-DA模型判别分析Fig.6 Discriminant analysis of PLS-DA model based on the strategy of millet origin traceability
3 结论
本文针对我国3个产区7个产地小米样本,运用高光谱成像技术(400~1 000 nm)和化学计量学方法,开展小米产地溯源研究,提出“产区-产地”二级溯源策略,建立基于该策略的小米产地溯源模型,通过试验验证,该模型可有效解决不同产区小米样本聚类现象和同一产区不同产地小米样本互相干扰问题,为小米及其他农产品产地溯源和食品安全保障提供新思路和方法。
a.采用主成分分析(PCA)和偏最小二乘判别分析(PLS-DA)分别对预处理后小米样本高光谱数据作产地溯源可行性分析和模型建立,试验结果误差为:甘肃0.003、陕西0.152、河南0.046、黑龙江0.134、内蒙古0.074、宁夏0.018、山西0.013。结果表明,高光谱成像技术和化学计量学方法应用于小米产地溯源具有可行性,但模型对陕西省和黑龙江省小米样本判别结果较差,且同一产区不同产地小米样本在溯源分析上互相干扰。
b.样本间互相干扰及聚类现象因相邻产地间土壤、海拔、气候及降水量等环境因素造成,受环境影响,相邻产地小米中蛋白质、水分、矿物质、脂肪及其他营养物质含量同样具有相似性。结合相关研究发现,PLS-DA模型判别样本范围越小,变量间相关性越高,模型性能越好,在基于PLS判别模型中也显示出相似结果。针对上述问题,提出小米“产区-产地”二级溯源策略,利用同一产区小米样本的高光谱数据对小米样本进行两次溯源判别,达到缩小样本范围,提高变量相关性目的。
c.构建基于“产区-产地”二级溯源策略的小米产地判别模型,通过试验验证,结果误差为:甘肃0.000、陕西0.033、河南0.003、黑龙江0.063、内蒙古0.063、宁夏0.000、山西0.003,对比初始试验结果,基于“产区-产地”二级溯源策略的小米产地判别模型准确率显著提升,表明该策略和基于该策略的模型具有较强可操作性,有效解决样本间互相干扰问题和聚类现象,为小米产地溯源及农产品安全提供技术支持。
