针对KMC 局部最优问题的飞蛾捕焰优化方法*
2021-09-08张少帅陈永安
郭 璐,许 哲,黄 鹤,张少帅,陈永安
(1.西北工业大学无人机系统国家工程研究中心,西安 710072;2.西安爱生技术集团公司,西安 710065;3.中国电子科技集团公司第二十研究所,西安 710068;4.长安大学电子与控制工程学院,西安 710064)
0 引言
聚类分析是统计学习领域的重要组成部分,可以针对不同的对象分析差异,并且能够根据某种特定的规则进行模式分类。聚类的应用广泛,拥有很好的发展前景。随着社会发展对数据精度要求的不断提高,如何提高算法的聚类精度是广大学者一直以来的研究热点[1]。经典K-means 聚类(K-means Clustering,KMC)算法存在易受初始聚类中心和异常数据影响的缺陷[2],研究人员提出利用特征关联度对传统K-means 算法的初始聚类中心进行优化[3]和基于自适应权重的聚类算法[4]。
群智能优化算法作为新兴的演化计算技术取得了高速发展。2015 年Mirjalili 根据飞蛾总是围绕火焰做对数螺旋曲线轨迹的行为提出了一种飞蛾捕焰算法(Moth-flame Optimization,MFO)[5-6]。目前,MFO 算法已经在网络[7]、电力[8]、以及加工制造[9]等方面有了具体的应用,并在此基础上结合其他算法进行了设计。文献[10]将粒子群优化算法的速度更新方式与MFO 算法的位置更新方式相结合,使飞蛾群向历史最优解和全局最优解快速收敛,避免了陷入局部最优解的目的。文献[11]将MFO 算法位置更新的方式和Lévy 飞行搜索策略结合,达到增强局部搜索能力的目的,使得收敛速度和求解精度大幅度提高。文献[12]提出了一种纵横交叉混沌捕焰优化算法,采用纵横交叉机制,将火焰之间以及火焰不同维度之间相互结合,同时引入混沌算子,进一步提高了算法精确度和跳出局部最优能力[10]。目前,针对MFO 算法本身改进的文献并不多,MFO算法的收敛速度和精度并没有充分得到提升。同时,MFO 算法得自身特点非常适用于聚类,可以使求解的聚类中心更加精确,但目前并没有研究者将MFO 算法设计在聚类的应用中。
因此,本文提出一种快速的飞蛾捕焰(Rapid Moth-flame Optimization,RMFO)算法,解决了经典MFO 算法求解复杂函数时收敛速度慢与精度较低等问题。同时,设计了一种基于改进飞蛾捕焰算法的K 均值交叉迭代聚类方法,提升MFO 算法的全局收敛能力和收敛速度,并且能够改善聚类性能。
1 飞蛾捕焰优化算法
MFO 算法是根据飞蛾围绕火焰做对数螺旋曲线运动的生物学原理构建数学模型,经过多次位置更新迭代之后求解得到最优火焰解。在飞蛾捕焰优化算法中,矩阵M 表示飞蛾(Moth)的集合,矩阵F表示火焰(Flame)的集合。与之对应的是,矩阵OM表示飞蛾集合M 的适应度值,矩阵OF 表示火焰集合F 的适应度值。飞蛾和火焰都是算法的解,不同的是飞蛾是在搜索空间中的实际搜索的主体,而火焰则是用来存储飞蛾搜索的最优解[13]。
1.1 初始化种群
设飞蛾种群集合M 的大小为n×d,如式(1)所示,n 表示飞蛾总数,d 表示一个样本的特征数或是待寻优变量的个数(维度)。

其中,Mi=[mi1,mi2,…,mid]代表的是第i 只(i=1,2,…,n)飞蛾的状态,Mij代表的是第i 只飞蛾在第j(j=1,2,…,d)维变量空间中所处的位置。
飞蛾的适应度值OM 的大小为n×1,如式(2)所示。
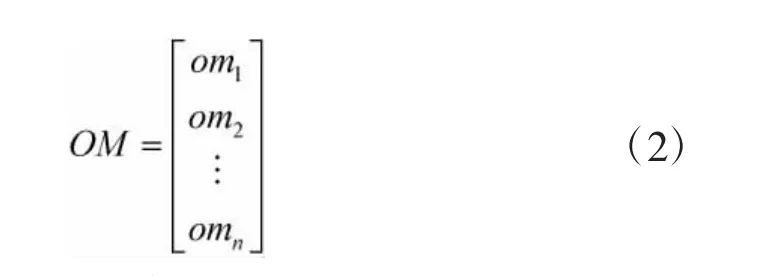
其中,OMi=[omi]表示第i 只(i=1,2,…,n)飞蛾的适应度值,是由Mi通过相应的适应度函数(寻优目标函数)得到的。
设火焰集合F 的大小与飞蛾M 的大小相同,为n×d。如式(3)所示。

其中,Fi=[fi1,fi2,…,fid]表示第i 个(i=1,2,…,n)火焰的状态,Fij表示第i 个火焰在第j(j=1,2,…,d)维变量空间中所处的位置。
火焰的适应度值OF 的大小同样为n×1,如式(4)所示。

其中,OFi=[ofi]表示第i(i=1,2,…,n)个火焰的适应度值。OF 矩阵是OM 矩阵中每个量排序之后的结果,所以F 矩阵是M 矩阵根据OF 矩阵的排序得到的结果,这说明火焰F 是飞蛾M 在当前迭代搜索中的最优解。
1.2 捕焰过程
飞蛾在围绕火焰做对数螺旋曲线运动时的位置更新机制可以分为两个过程:飞蛾捕焰、飞蛾弃焰。
1)飞蛾捕焰:飞蛾Mi在搜索空间中寻找火焰的位置时,飞蛾会根据自己的趋光生物特性来寻找与它距离最近的火焰Fi,然后在每一次的位置更新迭代中围绕火焰做对数螺旋曲线运动,如图1 所示,螺旋线的起点为飞蛾初始化位置,螺旋线的终点即为最优解。

图1 飞蛾运动轨迹图
定义对数螺旋曲线如式(5)所示:

2)飞蛾弃焰:为了提高算法寻优的收敛速度并且使得所有的飞蛾尽可能收敛于一个最优火焰解中,所以应该使火焰的数目自适应地减少,让飞蛾舍弃适应度值差的火焰。这样也可以避免飞蛾丢失最优解的情况。火焰自适应减少如式(6)所示:

其中,flameno 为当前火焰的数量,N 为飞蛾种群的总数量,l 为当前的迭代次数,T 为规定的最大迭代次数。
2 K 均值聚类算法
K 均值聚类的目的是将给定的数据集X={X1,X2,…,Xn}划分成K 个类的子集{C1,C2,…,Ck},执行过程中初始聚类中心的选取很重要,直接影响聚类的结果,导致结果陷入局部最优解。聚类中心Cj的计算式如式(7)所示:

3 改进的飞蛾捕焰算法
本文针对经典MFO 算法的不足,提出了一种RMFO 算法,分别将飞蛾种群的初始化和飞蛾的适应度函数进行改进,通过设计最大最小距离积法初始化飞蛾种群,可以克服原始飞蛾捕焰算法初始化的随机性,避免算法陷入局部最优解。同时,结合飞蛾捕焰迭代搜索过程以及KMC 算法思想,提出一种新的适应度函数。
3.1 最大最小距离积法初始化
飞蛾捕焰算法的搜索起点是飞蛾群的初始位置,所以选取尤为重要。经典飞蛾捕焰算法的初始飞蛾群采用随机初始化易导致算法陷入局部最优解。同时,飞蛾种群的个体解往往会远离最优解,使得算法收敛速度变慢,收敛效率变低,增加了算法的时间复杂度。针对这一问题,本文设计了最大最小距离积法对飞蛾群进行初始化,不仅可以解决飞蛾群初始化的随机性,而且也可以在K 均值聚类中降低对初始点的敏感性。通过最大最小距离积法得到k 个初始飞蛾的步骤描述如下:
1)从飞蛾种群集合M 中随机选取一只飞蛾作为第一个初始点Z1,将其加入集合Z 并从集合M 中删除;
2)计算更新后M 中所有元素到Z1的距离,选取距离Z1最大的元素为Z2;
3)将Z2加入集合Z 并从集合M 中删除;
4)分别计算更新后M 中元素到Z 中各个元素的距离并存入Temp 中;
5)计算M 中每个元素对应的Temp 的最大值与最小值的乘积,取该值最大对应的元素存入集合Z 中并从集合M 中删除。若Z 中元素个数小于k,则转到步骤3;若Z 中元素个数大于k,则初始点选取结束,输出包含k 个初始点的集合Z,即为得到的初始点。
其中,k 是规定的聚类个数或是给定的初始点个数,Z 初始时是空集,存储等待加入的k 个初始点的集合,Temp 是存储Z 中各个元素到M 中各个元素距离的数组。
从以上步骤可以看出,最大最小距离积法将M中每个元素对应的Temp 最大值与最小值乘积中的最大值为初始点,不但能够使初始点的分布比较稀疏,而且可以选取到点密度比较大的点。
3.2 新的适应度函数
适应度函数将引导群体进化的方向,直接决定了群体的进化行为、迭代的次数和解的质量,不同的适应度函数会得出不同优劣程度的解[14]。本文提出一种新的适应度函数,如式(9)所示。

从式(8)可以看出适应度越小,所解出的聚类中心点与该类中其他点的欧式距离的差值之和越小,也就是求解出的聚类中心越精确。
4 RMFO 优化KMC 算法
本文提出了基于RMFO 优化的KMC 算法,主要过程是:通过RMFO 算法先进行一次迭代,得到新的聚类中心作为KMC 算法的初始聚类中心,再将KMC 运行的结果作为改进MFO 算法的初始点。两种算法交叉迭代进行,最终找到最优聚类中心以及最优解。
算法的具体步骤描述如下:
1)输入标准数据集即飞蛾种群集合M,根据数据集类别的个数确定该数据集中类的个数k;
2)根据最大最小距离积法确定每个类的初始聚类中心点;
3)计算飞蛾群中的某个点到每个初始聚类中心的距离,当该点与某一初始聚类中心的距离最小时,则把该点与这个初始聚类归并为一类,依此将所有的点归并到相应的初始聚类中;
4)使用MFO 算法确定步骤3)中归并之后的每个类的新聚类中心;
5)利用步骤4)得到的新的聚类中心对飞蛾群进行K 均值迭代聚类,根据其他点与聚类中心点的欧式距离再次进行聚类划分,用每一类的新的聚类中心再次更新当前的飞蛾群,当迭代次数没有达到设定的迭代次数时,转向步骤3),直到达到设定的迭代次数,结束。
主程序流程图如图2 所示。

图2 主程序流程图
5 实验结果分析
实验平台采用CPU 为Intel Core i5 2.60 GHz、内存为4 GB 的计算机,操作系统为Windows 7,编译软件为Matlab R2014a。选择的数据集为UCI 国际通用测试数据库,是专门用来聚类算法的国际的通用的数据库。实验采用Iris、Wine 和Glass 3 种数据集,主要特征如表1 所示。
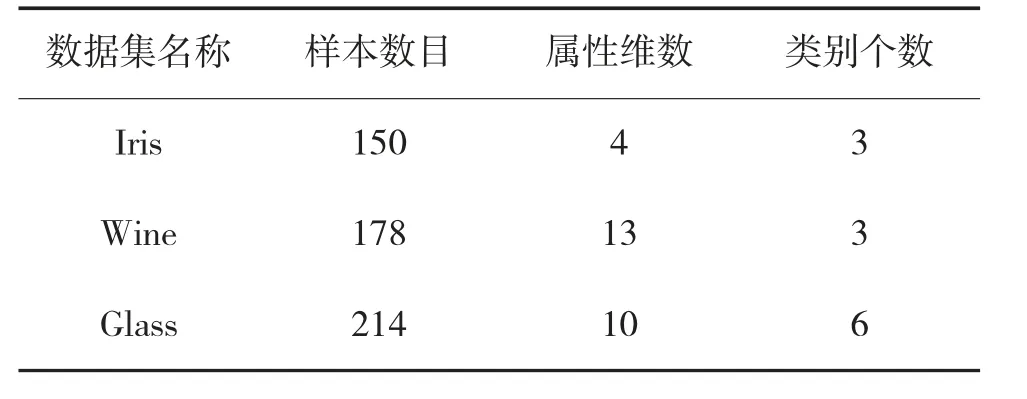
表1 标准数据集特征
5.1 RMFO 算法性能测试
对RMFO 算法进行性能测试比较,分别在3 种数据集上使用MFO 算法和RMFO 算法进行聚类,对比聚类效果并进行数据分析。两种算法的参数设置如下:在Glass、Iris 最大迭代次数为200 次,在Wine 数据集上最大迭代次数为100 次,飞蛾种群的规模为30,数据集中的聚类数目如表1 所示。采用适应度来评价改进算法的性能,则两种算法在3 种数据集上聚类的实验结果图如下页图3 所示。可以看出,改进的RMFO 算法的适应度值比经典MFO算法的适应度值要小,收敛速度更快。RMFO 算法在初始值的选取上使用最大最小距离积法,避免了初始值的随机性,不易使算法陷入局部最优解,得到的最优解更加精确。RMFO 算法确实比MFO 算法在求解的最优解方面更有优势。但从图3(c)中看出,两种算法很有可能陷入局部最优解,所以需要将RMFO 算法和K 均值算法进行混合迭代。

图3 RMFO 实验结果
5.2 基于RMFO 优化的KMC 算法性能评价
将KMC 算法、基于RMFO 优化的KMC 算法和文献[15]算法分别对3 种数据集进行聚类分析。其中基于RMFO 优化的KMC 算法参数设置为:飞蛾种群的规模为30,算法在3 种数据集上聚类的最大迭代次数都为100 次。图3 和图4 是基于RMFO 优化的KMC 算法在3 种数据集的运行结果,可以看出,算法能够很快迭代到最优解的位置,适应度值变化幅度不大。图3 还可以看出算法能够很好地避免局部最优解,这与MFO 算法本身的飞蛾弃焰行为和基于RMFO 优化的KMC 算法混合迭代每一次聚类的重新划分有很大关系。对比实验表明,本文算法迭代次数更少,聚类过程中的收敛速度快,能够很好地跳出局部最优解寻找出全局最优解,适应度变化幅度不大,稳定性更强。
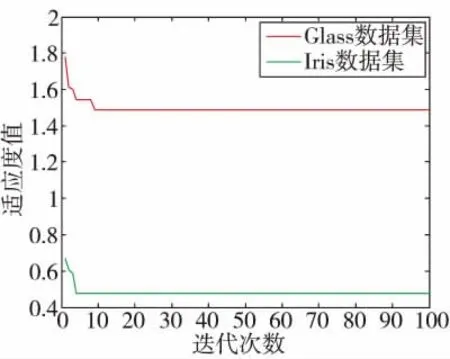
图4 在Iris 和Glass 数据集上的结果

图5 在Wine 数据集上的运行结果
采用KMC 算法、基于RMFO 优化的KMC 算法、文献[15]算法,分别对3 种数据集进行聚类分析,实验结果如表2~表4 所示。可以看出KMC 需要的迭代次数过多,算法达到稳定状态耗时过长。同时,由于KMC 算法依赖初始点的选取,所以很容易陷入局部最优解,使所得适应度值并不是最优解,全局搜索能力较差。文献[15]在聚类算法中引入模糊控制的概念,使用模糊聚类算法,使得迭代曲线趋于平滑,相比KMC 算法,文献[15]的迭代次数较少,但由于初始点选取的随机性,仍未达到全局最优解,使所得聚类中心点不够准确。本文算法改进了MFO 算法的初始化和适应度公式构造方法,并通过与KMC 算法混合迭代使收敛速度加快,迭代次数减少,适应度值最小,具有跳出局部最优解的能力,全局搜索能力较佳,解得的聚类中心更加精准。

表2 不同算法在Glass 数据集上的对比结果
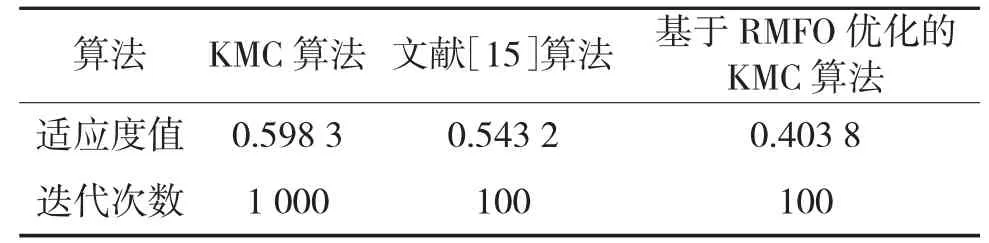
表3 不同算法在Iris 数据集上的对比结果
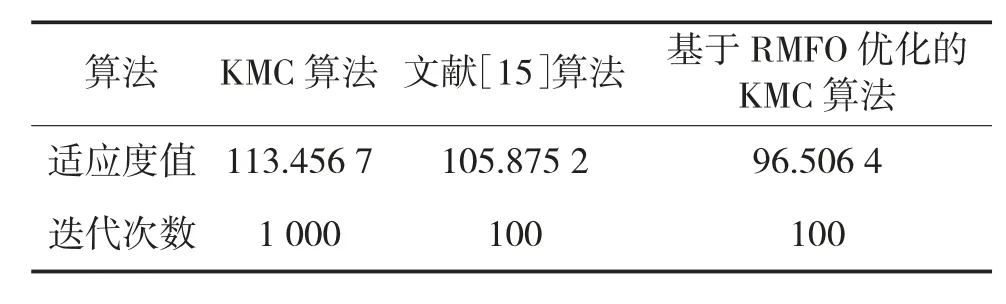
表4 不同算法在Wine 数据集上的对比结果
6 结论
1)本文从飞蛾群的初始化以及适应度函数两个方面对MFO 算法进行了改进,提出了RMFO 算法,克服了原始飞蛾捕焰算法初始化的随机性,解决了飞蛾的个别解较差和容易陷入局部最优解等问题。
2)将RMFO 算法和KMC 算法进行交叉迭代,构建新的基于RMFO 优化的KMC 算法,克服了KMC 算法由于初始化的随机性使得初始点敏感,使KMC 算法的迭代次数大大减少,避免了陷入局部最优解。
3)对比结果表明了本文算法的有效性,通过引入改进的飞蛾捕焰算法,提升K 均值聚类算法全局搜索能力,提高了算法的鲁棒性,并且解决了KMC算法由于初始化的随机性使得初始点敏感的问题。
4)保证聚类效果的条件下,效率当然是越高越好。如何进一步降低基于RMFO 优化的KMC 算法复杂度将是本文下一步研究方向。
