一种面向时空神经网络的潜在情绪识别方法
2021-09-02宋剑桥师泽洲马军辉
宋剑桥,王 峰,牛 锦,师泽洲,马军辉
(太原理工大学 信息与计算机学院,山西 太原 030024)
情感作为高级智能的一部分,在人类信息沟通中有着重大意义,因此情感计算是实现和谐、自然、人性化的人机交互过程中不可或缺的部分,情感识别与理解技术已经成为人机交互应用中的关键技术之一。随着仪器设备的更新与人工智能的发展日趋成熟,情绪识别可以广泛应用于医疗诊断、安检防范、特殊岗位人员心理情况检测等各个领域。现有的情绪识别技术主要集中在对单一模态的信息进行分析研究而得出识别结果,例如对人脸图像表情(微表情)识别、对语音信息的情绪识别和提取人体生理信号进行情绪识别。在众多外在模态信号中,人脸表情信号包含有较多的情绪信息,人们很容易从一个人的表情判断其当时的情绪状态。虽然表情识别技术看似可以直观地反映一个人的情绪状态,但并不是所有的情感活动都伴随着表情的变化,而且表情也可以人为控制,进而误导对其情绪的判断。相比于外在模态信号,内在生物电信号不会随主观意志而改变,因此基于生物电信号的情绪识别更加可靠。但生物电信号的采集往往较为复杂,需要较为精密的仪器,采集的成本往往较高,并不适用于一般环境。
起初微表情识别问题主要是通过匹配从图像或视频中提取的传统微表情特征描述符来解决的[1-2]。手工设计的基于特征的微表情识别方法早在十年前就开始了。WU等设计了一种定位人脸的自动系统[3],他们使用Gabor过滤器来提取特征,Gentleboost作为特征选择器,并在生成的特征上使用支持向量机(Support Vector Machine,SVM)来识别面部微表情,系统识别正确率可达85.42%。LU等提出一种基于运动边界直方图融合的新特征[4],该特征是由运动边界直方图(Motion Boundary Histograms,MBH)激发的光流水平分量和垂直分量相结合产生的,将生成的特征向量输入支持向量机进行微表情分类。LIU等[5]提出一种用于微表情识别的主方向平均光流(Main Directional Mean Optical-flow,MDMO)特征,首先计算人脸不同子区域的方向平均光流,然后特征向量输入支持向量机进行微表情的训练和识别,得到比其他方法更好的结果。最近,计算机视觉科学家正在努力将深度学习模型应用于微表情识别。随着深度学习的不断发展,卷积神经网络(Convolutional Neural Network,CNN)逐步被用于输入为图像或视频的计算机视觉问题。LI等[6]使用深度多任务卷积神经网络检测面部子区域,利用融合卷积神经网络提取肌肉变化区域的光流特征并进行修正和细化,最终采用支持向量机实现微表情分类。PENG等[7]对在面部表情数据集上预训练的卷积神经网络进行微调,用于微表情和宏表情的识别。文献[8-11]利用两步深度学习架构对微表情实现分类。在这类典型的两步模型中,首先利用卷积神经网络对微表情视频的每一帧进行空间特征提取,然后将空间特征输入到长短时记忆网络(Long Short Term Memory,LSTM),以学习帧间的时间相关性。国内外很多学者通过提取生理信号特征来分析人类情绪。FRANTZIDIS等[12]提出一种两步分类的方法来区分不同条件刺激下所引起的情绪变化,首先进行唤醒度辨别,然后利用马氏距离分类器和支持向量机进行情绪识别。KHZRI等[13]提出一种融合多种情绪模式的自适应方法来改善情绪识别系统的性能,通过记录信号形成几个分类单元以独立识别情绪,然后利用自适应加权线性模型对结果进行融合,得到最终结果。多模态即内部存在相互补充的各类反映情绪特征的信号的结合[14],在1997年由DUC等[15]首次提出,通过提取人面部和语音的特征用于身份识别。BAILENSON等[16]通过提取测量心血管活动、身体活动和皮肤电反应等生理特征,并结合面部特征进行开心和悲伤的二分类实验,实验结果证明融合后的双模态识别效果较单一模态效果好。TRIPATHI等[17]首先使用IEMOCAP数据集上执行多模态情绪识别,使用来自语音、文本的数据,以及来自面部表情、旋转和手部动作的动作捕捉数据。所以目前越来越多的学者将研究的重点由单一模态的识别转向多模态情绪识别,通过便于采集的人脸特征信息结合不同的生理信号进而实现对人的情绪识别。最近的多模态情感分析研究主要采用深度学习模型对模态内部信息和模态之间的交互信息进行建模[18-19]。尽管众多学者对于多模态情绪识别研究有很大进展,但现有的多模态情绪识别技术存在一定的问题,首先是研究年限较短,识别效果并未达到理想状态[18],其次是现有的多模态情绪识别技术并未简化情绪识别的复杂度,其采用的生理信号往往还需要较为复杂的过程采集。
为了改进情绪识别的识别效果,笔者提出基于三维卷积神经网络(3D Convolutional neural networks,Conv3D)+长短时记忆卷积神经网络(Long Short Term Memory Convolutional neural networks,ConvLSTM)的时空神经网络,一方面通过Conv3D提取微表情的短时维度特征和空间维度特征,另一方面加入ConvLSTM直接对输出的特征图提取长时间维度特征,由此结合二者优势实现对微表情序列的训练与分类。除此之外,针对多模态中生理信号提取复杂这一问题,提出融合时空神经网络和人脸脉搏信号的潜在情绪识别,按照双路架构:一路按照基于色度模型的人脸脉搏信号方法提取人脸脉搏信号及其特征,并训练反向传播(Back Propagation,BP)分类器对其分类,得到情绪的分类概率值;另一路通过训练文中提出的时空神经网络(Spatio Temporal Neural Network,STNN),实现对微表情的分类,最终通过D-S(Dempster-Shafer)证据理论,融合两路结构的决策信息,完成对潜在情绪的识别。
1 脉搏信号的特征提取
1.1 基于色度模型的人脸脉搏信号的提取
笔者采取基于色度模型的脉搏信号提取方法,通过计算红绿蓝(Red,Green,Blue,RGB)三通道的信息差值和比例得到色度模型,可以有效地去除静态成分、运动干扰与漫反射干扰。基于色度模型的脉搏信号提取过程如图1所示。首先用综合自适应增加(AdaBoost)和VIOLA-JONES[19]方法对视频进行逐帧人脸检测,其主要原理是通过积分图像的方法,计算其哈尔(Haar-like)特征,基于Adaboost原理训练强分类器用于人脸检测。选取去除眼睛和嘴巴后的面部区域作为感兴趣区域(Region Of Interest,ROI),由此可以避免眼睛眨动和嘴巴动作对脉搏信号提取的影响。

图1 基于色度模型提取脉搏信号流程图
根据色度模型原理,脉搏变化会引起面部皮肤反射光强度的变化,其可以体现在图像中亮度信息的变化,亮度信息可以通过计算图片的像素均值得到。为分析这种皮肤反射光的变化,色度模型作出如下描述,对于第i帧,其通道亮度信息变化可表示为
(1)
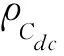
按下式对通道信息进行归一化处理以消除Ici的影响:
(2)
其中,Ci表示颜色通道信息,μ(Ci)表示该段时间序列内颜色通道亮度信息的均值,Cni为标准化后的信号。然后,计算色度信号为

图2 基于色度模型的脉搏信号
Xs=2R1(n)-3G1(n) ,
(3)
Ys=1.5R1(n)+G1(n)-1.5B1(n) ,
(4)
其中,R1(n)、G1(n)和B1(n)为标准化后信号。
最后,为消除漫反射及静态成分的干扰,对Xs和Ys通过带通滤波器(0.7~4.0 Hz)得到Xf和Yf,并由下式提取脉搏波信号S:
S=Xf-αYf,
(5)
(6)
其中,σ(•)表示信号的标准差。
基于色度模型的脉搏信号如图2所示。
1.2 脉搏信号特征提取
对脉搏波提取时域特征,主要包括均值、标准差、一阶差分信号的绝对值、均值、二阶差分信号的绝对值、均值,以及归一化差分信号的绝对值、均值,对得到脉搏波进行五点移动平滑滤波并除去异搏,然后检测上述波形的主波峰,计算相邻主波峰的时间间隔(峰-峰间隔,即P-P间隔),剔除时间间隔小于50 ms的脉搏波,将正常P-P间隔绘制得到脉搏变异信号(Pulae Rate Variability,PRV),对PRV提取均值、标准差等时域特征,统计P-P间隔大于50 ms的个数,并计算P-P间隔大于50 ms的百分比,计算P-P间隔的差值均方根。对脉搏波提取频域特征,用典型的1 024点快速傅里叶变换将原始信号(0.7 Hz~4.0 Hz)划分为6个不重叠的子带,分别计算每个子带的功率谱熵:
(7)
p(ωi)由不同子带的功率谱密度归一化得到。将6个子带中前3个子带作为低频带,后3个子带作为高频带,计算高低频带功率谱熵比。对PRV进行3次样条插值,细化脉搏波峰值点,通过去除信号均值保留信号瞬时特性,进行傅里叶变换分析PRV频域特征,分别计算甚低频功率a(VLF,0.003 Hz~0.400 Hz),即
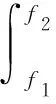
(8)
其中,DPSD(f)为信号功率谱密度,f1和f2分别为起始频率。同理求得低频功率(LF,0.40~0.15 Hz)、高频功率(HF,0.15~0.40 Hz)、总功率、低频功率与高频功率比、低频功率与总功率比、高频功率与总功率比。
通过学习生物工程等领域的方法,提取生理信号的非线性特征用于情绪识别,包括最大Lyapunov指数、多尺度熵和Lempel-Ziv复杂度。最大Lyapunov指数[20]可以用于判断非线性系统是否处于混沌状态,定量刻画相空间中相邻轨道收敛或发散的速率,可以体现出系统的混沌状态。多尺度熵[21]为研究不确定时间尺度下的观察视角,将样本熵进行多尺度扩展,解决时间序列中不同时间尺度的问题。由于多尺度熵计算不同时间尺度信号的熵,因此对生理信号在不同时间尺度下的复杂度变化有很大作用。Lempel-Ziv复杂度是一种表征时间序列里出现新模式的速率的方法,具有一定的抗干扰能力,可以有效处理一些高度不平稳的信号。
2 融合时空神经网络和人脸脉搏信号的潜在情绪识别
笔者提出的融合时空神经网络和人脸脉搏信号的潜在情绪识别,是一种双路识别结构,如图3所示。双路结构的潜在情绪识别,一方面从非接触式的生理信号入手。鉴于采集生理信号所需要的仪器精密,采集过程复杂,耗时费力,可通过非接触式的方式基于色度模型采集人脸脉搏信号,简化生理信号采集过程;对于提取的脉搏信号,提取其时域特征、频域特征及非线性特征,然后通过反向传播神经网络分类器得出不同情绪的分类概率。另一方面从微表情着手,采用提出基于深度学习的时空神经网络,如图3下部分所示。利用时空神经网络提取微表情视频序列中的时间维度特征和空间维度特征,经过全连接后通过多项逻辑斯特(Softmax)得出不同情绪的分类概率。由此可以得到输入视频通过双路结构后出现不同的概率值,最终通过D-S证据理论进行决策融合,得到最终的潜在情绪识别结果。

图3 融合时空神经网络和人脸脉搏信号的潜在情绪识别框图
首先介绍所提出的时空神经网络的网络架构。该网络主要由Conv3D+ConvLSTM组成,通过Conv3D提取微表情序列的空间维度特征和短时时间维度特征,通过ConvLSTM对输出的特征图提取长时间维度特征,其网络架构如图4所示。

图4 STNN网络架构
如图4所示,时空神经网络包括两个三维卷积层、1个最大池化层、两个ConvLSTM层、1个平铺(Flatten)层和两个全连接层(FC)。该网络的输入为w×h×d,其中w和h表示输入图片尺寸大小,在文中固定为64,d表示输入视频的帧数,文中为96。与2D卷积只能提取空间特征不同,3D卷积运算可以同时提取视频序列的短时时间维度特征和空间维度特征。笔者所提出的时空神经网络中,每个Conv3D层有32个卷积核,卷积核的尺寸为3×3×15,其中3×3为接受空间域的大小,15为时间深度,卷积层中填充(padding)设为有效(Valid)模式,步长设置为1×1×1。

时空神经网络的具体网络参数设置如表1所示。

表1 时空神经网络具体参数设置
此外,时空神经网络中采用的丢弃(dropout)优化策略以避免网络过拟合[22],因为在丢弃率选择0.5时随机生成的网络结构最多,所以丢弃率选为0.5。其中各个卷积层和FC层均采用线性整流函数(Relu)非线性层激活。采用交叉熵损失函数和随机梯度下降对默认学习率进行优化。
D-S证据理论的核心思想是通过证据积累来减少不确定性。文中的多模态融合中,共有脉搏信号和时空神经网络情感识别模型2个分类器,其概率赋值函数(Basic Probability Assignment,BPA)分别为m1(0)、m1(1)、m1(2)、m1(3)和m2(0) 、m2(1)、m2(2)、m2(3),代表每个分类器对于不同识别结果的可信度。对于每个BPA,首先乘以相应的情感识别率,之后进一步进行融合。利用所有分类器对产生的同一结果A值的BPA函数进行累乘得到融合之后的结果m12(A),其和最大的值即为相应的类别。
3 实验结果分析
3.1 数据集
由于潜在情绪的识别需要采集一定时长的脉搏信号信息,而常用的数据库如CK+等不能满足脉搏信号的提取,故数据库选用中科院CAS(ME)^2数据库和自己建立的大学生潜在情绪数据库(University Student Potential Emotion,USPE),剔除部分样本量太少以及不满足要求的数据,最终CAS(ME)^2数据库保留296个样本用于实验;USPE潜在情绪数据库使用408个样本,选取的情绪包括厌恶、悲伤、愤怒和开心4种。当训练神经网络使用小型训练数据集时,如CAS(ME)^2数据库用100个样本,USPE潜在情绪数据库使用200个样本时,模型会过度拟合,训练集和验证集的损失函数如图5所示。

图5 少量样本损失函数图
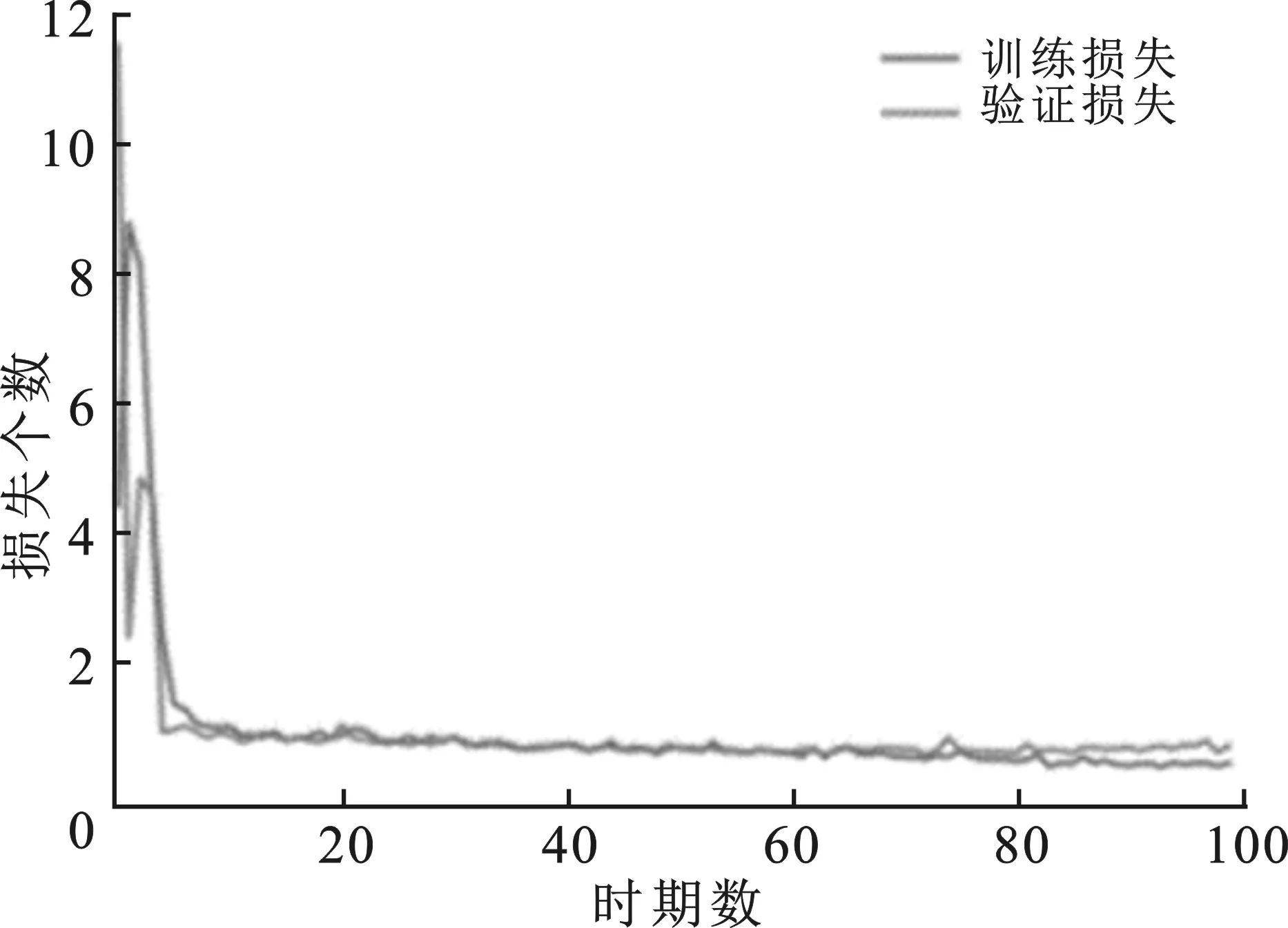
图6 数据扩充后损失函数图

表2 实验数据样本分布
为解决这一问题,常用的方法有水平或垂直镜像、裁剪、小的旋转等数据扩充操作。但大幅度的操作可能会改变微表情的运动信息,故本节将图像序列按照{-7°,-3°,3°,7°}的角度进行旋转,最终得到原始数据的5倍数据,将数据集进行拆分,80%作为训练集,20%作为测试集,最终用于实验的数据样本分布如表2所示。由于潜在情绪识别中所需要的数据时间较长,故用于时空神经网络训练的视频帧选为96帧,同时截取包含该微表情的10 s视频用于提取非接触式的脉搏信号及其特征。扩充数据集后训练集和验证集的损失函数如图6所示。基于时空神经网络的微表情识别使用交叉熵损失函数和随机梯度下降(SGD)优化技术来实现默认的学习速率调整。网络经过100个epoch的训练,其批处理大小为8,输入尺寸大小为64×64×96。
3.2 对比实验
3.2.1 基于时空神经网络的微表情识别
网络模型的性能依赖于网络的许多超参数,使用较小的步长可以更好地遍历整个图像,更好地采集特征,所以使用1×1×1的步长。另一个重要的超参数是3D卷积核的尺寸;不同尺寸的3D卷积核提取时空特征的能力不同。笔者通过设置不同尺度的卷积核尺寸,使网络达到最佳的性能。如表3所示,最优的3D卷积核尺寸是3×3×15。实验结果表明,在空间范围尺寸较小、时间深度较大时,识别效果最好。
较大核的ConvLSTM能够捕捉快速的运动,而较小的核则能捕捉较慢的运动。为了选择最优的卷积核尺寸,通过更改其核尺寸进行实验,实验结果如表4所示。实验表明在卷积核尺寸为3×3时,识别效果最好。

表3 不同尺寸3D卷积核下的识别效果

表4 不同尺寸ConvLSTM卷积核下的识别效果
3.2.2 融合时空神经网络和人脸脉搏信号的潜在情绪识别
融合时空神经网络和人脸脉搏信号的潜在情绪识别采用决策融合的方式构建潜在情绪识别系统。该系统结构为双路结构,分别对各路进行分类,将两路的分类结果进行融合,得出潜在情绪的识别结果。一路从非接触式的生理信号入手,实验结果如表5实验1所示;另一路从微表情着手,通过时空神经网络模型提取微表情视频序列中的时间维度特征和空间维度特征,经过全连接后通过Softmax得出不同情绪的分类概率实验结果如表5实验2所示。最终将得到双路结构输出的不同概率值,经过D-S证据决策融合,得到最终的潜在情绪识别结果,实验结果如表5所示。

表5 融合时空神经网络和人脸脉搏信号的潜在情绪识别结果
分析表5可知,实验1结果表明,在CAS(ME)^2数据库和USPE数据库的情绪的平均识别率差距不大,表明文中所提出的基于非接触式人脸脉搏信号的情绪识别对潜在情绪的识别有一定作用。实验中辨识度较高的情绪识别率较高,例如惊讶和开心,最高可达71.93%和75.96%;相反,辨识度较低或者容易混淆的情绪识别率较低,例如生气、厌恶和悲伤,最低为57.88%、59.10%和62.90%。实验2与实验1相比,对于CAS(ME)^2数据库和USPE数据库的识别率分别提高了12.71%和10.79%,证明微表情在潜在情绪识别中的重要意义,同时也证明文中所提出时空神经网络在微表情识别中的可靠性。实验3表明,经过D-S证据理论决策融合后的潜在情绪识别的识别率相比于单一模态的非接触式生理信号的识别率和微表情的识别率均有提升,在CAS(ME)^2数据库上分别提升了14.28%和1.57%,在USPE数据库上分别提升了12.87%和2.08%。由此可以看出,潜在情绪识别中的非接触式人脸脉搏信号和微表情互为补充,可更好地表征人当前时刻的潜在情绪状态。
3.2.3 不同情绪识别算法的比较
目前已有的一些情绪识别算法在文中所用的两个数据库上进行比较,最终实验结果如表6所示。从表中可以看出,文中所提出的融合时空神经网络和人脸脉搏信号的潜在情绪识别网络在加入生理信号的决策信息之后,相比于目前常用的微表情识别方法,识别效果更好,而在算法复杂度方面较其他算法无明显提升,表明该算法有一定的优越性。

表6 不同情绪识别算法的比较 %
4 结束语
笔者提出基于Conv3D+ConvLSTM的时空神经网络与融合时空神经网络和人脸脉搏信号的潜在情绪识别。实验在CAS(ME)^2数据库和USPE自建库上进行实验,研究双路结构的潜在情绪识别结果,平均识别率约达78.59%和76.91%,较单一模态的非接触式人脸脉搏信号和微表情的识别均有一定提升,证明结合上述二者的潜在情绪更符合人类情绪机制,可以更好地表征人的情绪状态。笔者提出的方法对部分类型的情绪识别率较低,未来可以针对这一部分情绪,从情绪检测的原理和检测模型的设计方面进行深入研究。
