结合帧间目标回归网络的无人机视频车辆检测
2021-09-02张智,郑锦
张 智,郑 锦
(1.中国民航大学 计算机科学与技术学院,天津 300300;2.北京航空航天大学 计算机学院,北京 100191)
相较于传统的固定视角监控视频,无人机视频具有视角灵活、时效性强、监视范围广等优点,使得无人机监控市场在近些年得到迅猛发展。如何有效利用无人机视频的优点,成为智能监控的重要环节。其中,无人机视频中车辆检测作为智能监控的基础,同时也是计算机视觉的热点方向之一,被国内外研究者所关注。目前,无人机视频目标检测算法大致可以分为两类:一类是单帧无人机图像目标检测,该类方法使用通用目标检测网络对无人机视频中的每一帧进行特定目标的检测;另一类是视频目标检测,该类方法利用视频帧间的运动和时序信息,对视频中的特定目标进行检测。
在单帧无人机图像目标检测方法的研究中,LI等[1]借鉴基于区域候选网络的实时目标检测(Faster-Rcnn)[2]来提升无人机图像中车辆检测的精度。文献[3]通过改进单阶段多候选框目标检测(SSD)[4],并结合基于焦点损失的密集目标检测(Focal loss)[5]来实现无人机图像中目标的快速检测。文献[6-7]通过使用Yolov 3[8]的变体来实现无人机图像中目标的快速检测。这一类方法在单帧无人机图像中优势明显,但是当目标存在遮挡时容易漏检。此外,将单帧无人机图像检测器直接应用于视频检测时,由于无人机和车辆两者的运动会导致目标光照、视角发生变化,使得同一目标在连续帧中检测的置信度变化较大,甚至出现部分帧目标的漏检,即检测框“闪烁”现象。
相较于单帧图像检测方法,视频目标检测方法利用视频连续帧的时序和运动信息来实现检测精度的提升。目前基于深度学习的通用视频检测方法中,文献[9]采用跟踪结果对检测结果进行修正,进而提高视频检测精度。基于光流引导特征融合的视频目标检测(FAGA)[10]和基于运动感知的视频目标检测(MANET)[11]来利用光流进行运动估计,对当前帧的前后多帧进行特征融合,进而减弱目标遮挡的影响。这些方法在视频目标检测中性能优越,但主要针对通用目标检测,且属于离线检测器,不能满足无人机视频车辆检测实时处理的需求。
针对上述问题,笔者提出了结合视频帧间目标回归网络的无人机视频车辆检测算法。该算法主要贡献有以下3个方面:
(1) 针对无人机视频中车辆密集分布且遮挡所造成的大量检测框重叠问题,采用高斯加权衰减设计软化非极大值抑制[12]处理,将其作为单阶段全卷积目标检测(FCOS)[13]检测框合并策略,构成性能更优的单帧无人机车辆检测器。
(2) 在单帧无人机车辆检测器基础上,设计帧间目标回归网络。利用视频帧间连续性将相邻多帧的目标特征进行有效融合,并与当前帧目标特征进行匹配回归输出预测结果,最后利用单帧检测结果修正预测结果,形成无人机视频车辆检测算法,有效克服无人机平台运动噪声强的影响。
(3) 针对现有无人机数据集往往忽略小尺寸区域和静止车辆目标的问题,通过对小尺寸区域和部分静止车辆的补充标注来丰富现有数据集,并自采集、标注无人机视频数据集来引入更多典型场景,构建了一个更全面的无人机视频车辆数据集。在该数据集上的实验结果表明,笔者提出的算法可有效提高无人机视频车辆的检测准确率。
1 基本原理
1.1 整体框架
文中提出的结合帧间目标回归网络的无人机视频车辆检测框架如图1所示。图1中上半部分的虚线框内为单帧无人机图像检测器,下半部分的虚线框内为帧间目标回归网络。单帧无人机图像检测器算法流程如下:首先对输入的当前帧(第i帧)图像采用骨干网络残差网络(ResNet101)[14]+基于特征金字塔的目标检测(FPN)[15]进行特征提取;然后对每层特征进行分类、中心度和逐像素回归;最后采用软化非极大值抑制来更有效地从大量候选框中选取检测结果。帧间目标回归网络算法流程如下:首先将当前帧图像的单帧检测结果和上一帧的最终检测结果进行最近邻匹配,获取丢失目标,记为R;然后将目标R在前序多帧中对应位置处的特征扩展后融合,并将融合特征与目标R在当前帧预测位置处的特征共同输入全连接层进行特征匹配,进而得出当前帧R的预测框;最后为了避免误差累积,利用单帧检测器的候选检测结果进行修正,得到最终检测结果。图1中“⊕”表示特征像素值相加[15]的特征融合方式。
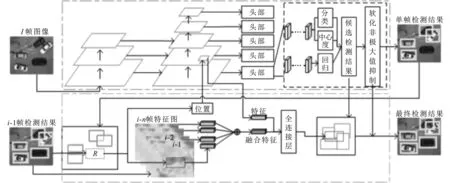
图1 结合帧间目标回归网络的无人机视频车辆检测框架
1.2 单帧无人机图像检测器
针对无人机图像中车辆目标分布密集且尺寸相对较小的特点,文中选取了单阶段全卷积目标检测[13]作为基础目标框架。该框架采用ResNet101+FPN进行特征提取。与基于预定义的锚框(anchor)的算法不同,该框架属于基于密集采样无锚框的单阶段目标检测算法。在单阶段全卷积目标检测的特征提取阶段采用FPN策略,将网络中顶层强语义特征上采样与低层强细节特征融合,从而引入对小目标尤为重要的低层特征。在检测候选框产生的过程中采用中心度快速过滤负样本,提高召回率和检测性能。与单阶段全卷积目标检测原有后处理方式不同,文中提出高斯加权衰减的软化非极大值抑制(Soft-NMS),根据重叠度和距离重置候选检测框的置信度分数,改进后的后处理策略可在一定程度上解决原有非极大值抑制(NMS)对遮挡目标候选框的置信度过度抑制造成的漏检问题。

图2 VisDrone[16]数据集中遮挡情况下的置信度选择
如图2所示,图像中框出的两辆车辆,后者被前者部分遮挡,其中前者的检测置信度为0.98,而后者的检测置信度为0.82。如果直接使用非极大值抑制,当两个候选框的重叠面积大于交并比(IOU)所设定的阈值时,图中便会只剩下置信度为0.98的候选框,若仅将其作为最终的检测情况,则会发生漏检。为解决这一问题,与原来使用非极大值抑制直接将重叠面积大于交并比阈值的置信度重置为0的思路不同,软化非极大值抑制根据重叠面积、相隔距离降低其置信度分数,故而可以同时保留两个候选框。原始非极大值抑制置信度分数重置函数为
(1)
其中,B={b1,…,bn},为搜索范围内的候选框的位置;S={s1,…,sn},为与之对应的候选框的分数;M为非极大值抑制某一次循环中置信分数最高候选框的位置;Nt是非极大值抑制阈值;Iou为计算两个候选框交并比的函数。从式(1)中可以看出,非极大值抑制采用硬阈值来决定是否保留相关联的候选框。高斯加权衰减软化非极大值抑制的置信度分数重置函数为
(2)
其中,σ为超参数。与前者采取暴力淘汰的方式不同,软化非极大值抑制逐步衰减与M有重叠面积的候选框的置信度分数。对与M重叠面积大、距离近的候选框,衰减权重就大;反之,重叠面积小、距离远的候选框,衰减权重就小。
1.3 帧间目标回归网络
当直接使用上文中单帧无人机图像目标检测器对视频进行检测时,会发现整段视频中部分车辆目标的检测置信度如图3中曲线所示,起伏变化明显。原因在于连续帧中无人机和车辆目标同时运动,车辆目标在运动过程中发生了遮挡及视角变化,使得检测置信度发生波动。针对这一情况,文中设计了基于视频帧间连续性的帧间目标回归网络。如图1所示,该网络分为3个部分:第1部分为采用最近邻匹配的相邻帧间目标匹配,获得当前帧中的丢失目标,如图1中上一帧检测结果的目标R;第2部分为帧间目标融合算法设计,利用视频帧间信息连续性将前序的连续多帧目标特征进行有效融合,并与目标R在当前帧预测位置处的特征进行匹配回归,输出预测结果;第3部分为检测结果修正,对预测结果和单帧检测器的候选检测结果,使用软化非极大值抑制策略进行结果修正,以避免误差累计,得到最终的检测结果。
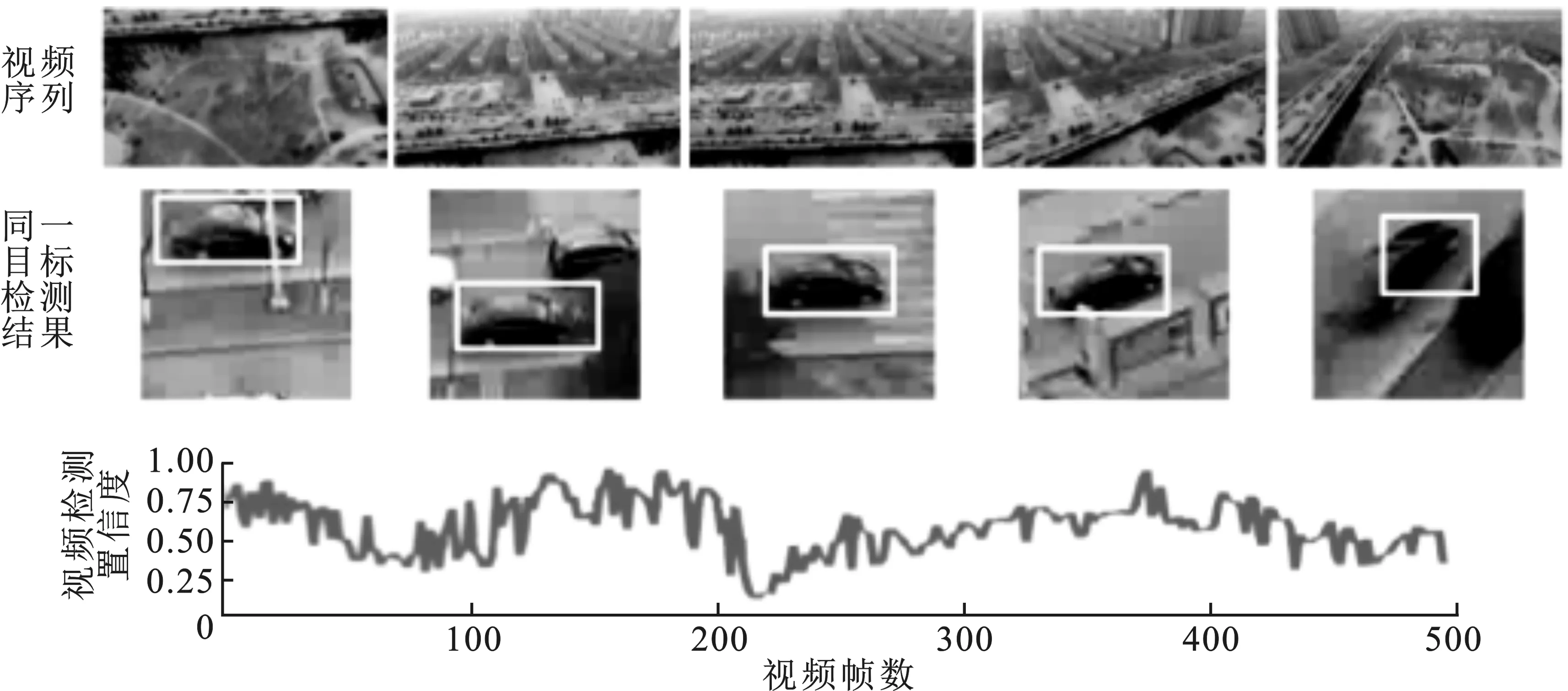
图3 视频帧间目标置信度变化示意图
1.3.1 相邻帧间目标匹配
依据视频帧间信息的连续性特点[17],同一目标在连续帧之间的位置应该由背景运动和目标运动的相对运动决定;除了背景特别剧烈的运动以外,一般情况下,目标中心点位置在连续帧的变化不会太大。故而可以通过最近邻匹配思路,依据相邻两帧目标检测框的重叠面积来构建相对应的匹配关系。具体过程如下:
(1) 从i-1帧中选取目标R,假设其中心点坐标为c=(cx,cy),检测框的大小为w×h,以中心点坐标c为中心,分别将宽度和长度拓展为kw和kh,此处k=1.5。
(2) 在i帧中,将以c为中心、kw×kh面积内所有检测框与i-1帧中目标R计算交并比,并排序。
(3) 从排序的检测框中选取第1个满足交并比值大于阈值N且未被标记的检测框(已与其他目标匹配则进行标记)作为R的匹配目标,并进行标记。若没有满足条件,则将其标记为丢失目标。重复(1)、(2),直至结束。
(4) 在i帧中未被标记的目标,则确定为新目标。
(5) 若当前帧没有出现丢失目标,则采用单帧无人机图像检测结果作为最终输出结果。
1.3.2 帧间目标特征融合算法设计
为了实现对当前帧丢失目标R的回归预测,需要将当前帧丢失目标特征和对应的前序帧该目标的融合特征进行特征匹配回归。在进行特征匹配回归之前,需要确定两者的具体输入。假设上一帧丢失目标R的中心点位置为c=(cx,cy),则上一帧与当前帧的目标中心点位置、目标宽度和高度可建立如下公式:
c′x=cx+wΔx,c′y=cy+hΔx,w′=wγw,h′=hγh,
(3)
其中,c′= (c′x,c′y),为当前帧的目标中心点位置;w、h、Δx、 Δy分别是上一帧目标的宽度、高度以及x、y方向上的相关随机变化值;w′、h′、γw、γh分别是当前帧目标的宽度、高度以及与x、y相关的随机变化值。同时Δx、Δy服从μ=0、b=0.2,γw、γh服从μ= 1、b=1/15的拉普拉斯分布[17]。拉普拉斯分布的概率密度函数为
(4)
由上述可以确定当前帧中丢失目标的位置及大小,进而将该位置及大小作为当前帧目标所在位置和大小,确定当前帧丢失目标特征。
融合特征由当前帧丢失目标R在前n帧中所在位置的特征融合而来。具体过程为:① 采用节1.3.1中的相邻帧间目标匹配方法确定丢失目标R在前n帧中的位置;② 将丢失目标R在前n帧中的大小进行扩展,大小与丢失目标在当前帧中所确定的目标大小一致,原因在于全连接层的输入和特征融合都需要统一大小;③ 提取丢失目标在前n帧中对应位置处的特征,并进行像素值相加的特征融合,其中融合权重按前序帧与当前帧距离的远近分配,如融合总帧数为K,则当前帧i的前n帧,即第i-n帧特征权重为1-(i-(i-n))/K。
最后,将i帧丢失目标预测位置特征和融合特征输入到全连接层得到预测结果。上述帧间目标特征融合方法见算法1。
算法1帧间目标特征融合方法。
输入:视频序列{Ii},融合帧数范围K。
fori=2 to ∞ do:
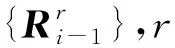
forr=1 toudo
forj=max(2,i-K) toido


提取拓展后图像的特征;
else
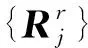
end if
计算融合权重W=1-{i-j}/K;
采用像素值相加方式进行特征融合;
end for
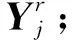
end for
end for
2 实验验证
2.1 数据集构建
一个高质量的数据集可以对算法性能进行更全面的评价。目前已有的无人机视频车辆数据集存在一些问题:① 数据集中将尺寸较小的目标标记为忽略区域,但其中部分车辆目标相对清晰。对较小车辆的检测也是对算法评测的一个重要方面;② 标记道路上的运动车辆,但对部分静止车辆不进行标记;③ 数据中的场景主要集中在交通路口,而场景数据的多样性可以使得算法具有更好的泛化性能。针对这些问题,文中基于VisDrone[16]数据集、航空图像中的车辆检测(VEDAI)[18]数据集及自采集标注的数据集,通过补充标注、筛选和融合,构成高质量的无人机视频车辆数据集,数据集下载地址:https://pan.baidu.com/s/1umAfY9I3wEVtJUQDIiZT0g,提取码:drjk。具体操作包括:① 从VisDrone-VDT数据集中去除主要为行人数据的视频,对筛选后视频中未标记的车辆进行补充标记;② 引入VEDAI数据集作为训练集,该数据集中的车辆目标尺寸主要集中在10×10~40×40像素,尺寸较小,同时该数据集的拍摄方式和高度均与VisDrone数据有一定差异性;③ 引入自采集标注的数据集,其中包括车辆高度密集分布的大型停车场及斜视的无人机车辆视频。最终文中构建的无人机视频车辆数据集有以下几个特性:① 训练集包括视频40段,共27 346帧。外加VEDAI的1 268张图片。测试集8段,共6 127帧;② 图像大小主要为1 904×1 071像素和2 704×1 520像素两种;③ 车辆目标大小尺寸主要分布在10×10~320×320像素。
2.2 实验设置
文中算法在训练过程中采用了包括翻转、裁剪及随机平移等数据增强方式。训练过程分为两部分,在单帧无人机图像检测器中输入图像大小为800×1 280像素,批处理大小设置为4,学习率初始值设置为0.01,每10个轮(epchos)变为原来的1/10,学习率最小值为0.000 1。优化过程采用随机梯度下降(SGD)算法,其中动量设置为0.9。soft-NMS的超参数σ设置为0.3。帧间目标回归网络中输入图像大小为224×224像素,批处理大小设置为4,优化过程同样采用SGD来更新网络参数,在后一部分训练中只使用视频测试集。
与文中方法进行比较的算法中,Faster-Rcnn[2]、Yolov 3[8]、FGFA[10]采用的优化器为SGD,动量设置为0.9,初始学习率为0.001,权重衰减正则项系数为0.000 5,批处理大小为4。RetinaNet[5]采用的优化器为自适应矩估计(Adam),初始学习率为0.01,计算梯度以及梯度平方的运行平均值的系数分别为0.9、0.999,批处理大小为4。文中测试平台硬件配置为CPU i7-9700,GPU为GTX 1080Ti×2,内存为16 GB;软件配置为CUDA 9.0、cudnn 7.1。
2.3 实验结果及验证

表1 在无人机视频车辆数据集的结果对比

表2 与现有算法的比较
为了进一步分析评价算法性能,这一节的消融实验分别从软化非极大值抑制对单阶段全卷积目标检测的影响、帧间目标网络中融合帧数的多少对算法的影响两方面进行分析。与此同时,为了更全面地和现有算法进行比较,文中选取了包括单帧无人机图像目标检测器和视频检测器两类现有算法同时比较。图4对文中算法的检测结果进行表示,具体对比结果见表1和表2。
从表1中的实验结果可以看出,在无人机视频车辆数据中,Soft-NMS的后处理方式对单阶段全卷积目标检测这种单帧无人机图像检测器的性能有明显提升。从图4(a)中也可以看出,其对相互重叠的密集车辆同样有较好的检测结果。在引入帧间目标回归网络后,相较于单帧图像检测器,精度(AP)值提升了1个百分点左右。与此同时,从图4(c)中可以看出,在目标相对较小且存在夜间强光干扰的情况下,文中算法也没有出现闪烁的现象。
从表1的实验结果还可以看出,在融合1帧、5帧和10帧的情况下,算法的检测性能是高于不融合的,说明融合特征可以有效提升帧间目标回归网络的性能。但是从表中可以看出,当融合帧数逐步加多时,在时间和内存代价更大的情况下,检测性能反而下降。说明前序帧特征过多引入,不仅增加了有效特征,同时也带来了更多的噪声,减弱了网络的性能。故文中算法最终选择融合5帧的帧间目标回归网络。
从表2中可以看出,在与现有方法的比较中,无论是与单阶段全卷积目标检测思路一样的端到端目标检测器RetinaNet、Yolov 3,还是与经典级联目标检测器Faster-Rcnn在内的通用单帧图像目标检测器相比,在骨干网络同样采用ResNet 101+FPN的情况下,文中提出的更有针对性的FCOS+Soft-NMS单帧无人机图像检测器的性能更胜一筹。更进一步,与FGFA这一结合光流特征的视频检测性能相比,文中增强了单帧检测器的性能,在针对静止及尺寸较小的目标时性能更加鲁棒;而且引入基于视频帧间信息连续性的帧间目标回归网络,使得整体算法在数据集上呈现出更为优秀的实验结果。从图4(b)和(d)的实验结果中也可以看出,文中算法在完全俯视角度、车辆目标较小和车辆存在树木遮挡等情况下都具有优异表现。综上所述,文中提出的结合帧间目标回归网络的无人机视频车辆检测算法具有良好的鲁棒性和泛化性能。
图4中4组图中上面一行为部分挑战视频序列帧的检测结果,下面一行为这些视频序列帧检测结果的局部放大图。

图4 算法检测结果展示
3 结束语
笔者提出的结合帧间目标回归网络的无人机视频车辆检测算法,采用Soft-NMS作为FCOS的检测框后处理策略,构建更适合无人机车辆分布特点的单帧无人机视频车辆检测算法;针对前者应用于无人机视频检测出现的闪烁情况,设计基于视频帧间信息连续性的帧间目标回归网络;为了更客观分析评价算法,构建了更高质量更全面的无人机视频车辆数据集。实验结果表明,文中所提算法有效地提高了无人机视频车辆检测的性能。
