一种时空卷积的步态识别方法
2021-09-02许缓缓李洪梅李富余孙学梅
许缓缓,李洪梅,李富余,孙学梅
(1.天津市自主智能技术与系统重点实验室,天津 300387;2.天津工业大学 计算机科学与技术学院,天津 300387;3.花旗金融信息服务(中国)有限公司,上海 201203)
在生物特征识别领域,人的各种外在和内在特征如人脸、虹膜、指纹、掌纹、静脉、声纹、步态等可用来识别人的身份。其中,步态是一种独特的生物特征,可以远距离识别,非侵入且无需受试者的合作。因此,在身份鉴别、公共安全和医疗诊断等方面具有广泛的应用前景。但是,在现实场景下,步态识别的准确率会受到外部因素的影响,例如拍摄角度、行人穿着以及携带包等因素。
为了解决这些问题,当前主流步态识别方法对输入步态序列数据的处理主要有两种方式:第1种方式是把步态序列数据按照静态图像帧方式的处理,通常将所有步态轮廓压缩成一张图像或用步态模板进行预处理[1],然后进行步态识别。这类方法虽然简单易行,但很容易丢失时间和细粒度的空间信息。第2种方式是按照连续视频序列处理,即直接从原始步态轮廓序列数据中提取步态特征[2],如使用3D-CNN[5]。该方法可以较好学习特征,但是,比使用单个模板的深度神经网络更难训练。
文中将步态轮廓视为一组步态序列轮廓图。作为周期性运动,步态可以由一个周期表示。基于此,笔者提出一种基于时空卷积的步态识别方法。该方法框架由时空特征提取和高层语义度量两个模块组成,如图1所示。
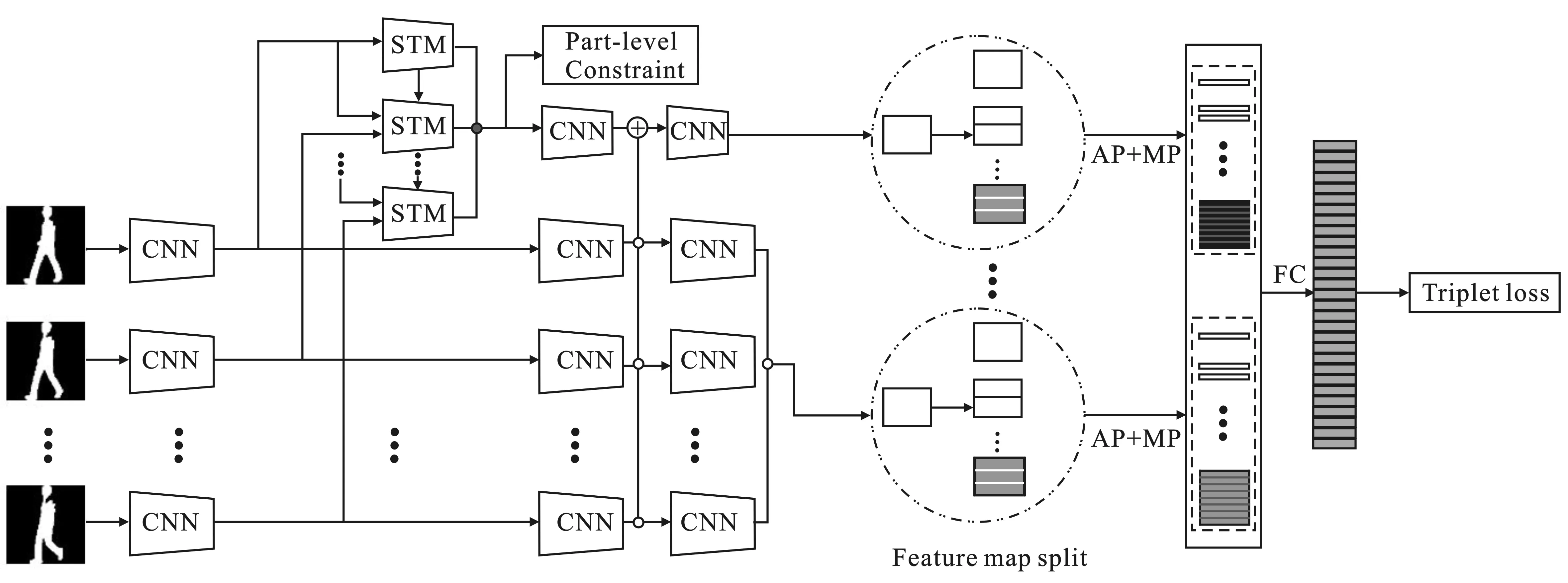
图1 基于时空卷积的步态识别算法框架
时空特征提取模块的输入是一组步态轮廓图像,第1级卷积神经网络块(CNN)用于独立地从每个轮廓中提取帧级特征,然后送入时空特征提取模块(Spatial-Temporal Module,STM),通过对相邻帧进行重复提取来弥补当前帧丢失的信息,从而在步态轮廓序列图里挖掘更丰富的时空信息,更多地关注特定条件下步态的差异性,如携带包和穿外套等情况。第2级和第3级卷积神经网络块将帧级特征聚合成独立序列级特征,从而得到视觉特征。这样可以获得更高级特征图,它可以比基于步态模板更好地保留空间和时间信息。高层语义度量模块用于帮助深度网络同时提取局部和全局特征。对时空特征进行全局池化后,使用全连接层完成特征嵌入空间学习。采用两个三元组损失函数联合训练,使模型最后得到的特征更有鉴别性。总之,该方法的贡献如下:
(1)提出了一种基于时空卷积的步态识别方法。该方法可以实现细粒度信息学习与更好的保存时空信息。
(2) 在同一个步态识别框架下,将行人的步态信息和全局信息进行融合。
(3) 在公开数据集CASIA-B上进行了评测,在正常行走、携带包和穿外套的情况下,Rank-1准确度都得到了提升。
1 相关工作
1.1 传统的步态识别方法
步态识别最早是由文献[7]提出的一种识别方式。传统的步态识别方法包括早期的手工提取特征的方法[8]和构造步态模板的方法[9],前者主要通过手工提取步态图片中的特征进行步态识别,因此步态识别率很低。后者构造的步态模板有步态能量图和步态熵图等。这种构造步态模板的方法很好地保留了步态轮廓图中的空间信息,但却丢失了时间信息,导致步态识别率降低。
1.2 基于时序的相关步态识别方法
由于传统的步态识别方法不能很好地保留步态中的时空信息,所以很多研究者提出了新的步态识别方法,这些识别方法注重保留步态中的时空信息,很好地提高了步态识别率。文献[10]提出一个多任务的生成对抗式网络,用于学习视角特征表示。为了能保留更多的时间信息,他们还提出了一种新的模板——多通道步态模板。文献[3]提出了一个以自动编码为基础的方法——GaitNet,该方法可以从RGB帧中分离出外观特征和姿势特征,然后利用长短期记忆网络将姿势特征结合在一起形成一个视频段的步态特征。文献[4]提出了一种新的损失函数,通过该损失可以同时最小化类内差和最大化类间差。文献[12]提出了一种基于深度学习的算法来精确识别受影响的帧,并预测缺失的帧来重建完整的步态循环。基于提取时间信息的方式,可以将它们分类为基于长短期记忆网络的方法和基于3D CNN的方法。这些方法虽然可以获得更全面的空间信息和收集更多的时间信息,但是忽略了特定条件下步态的差异性,如携带包和穿外套等情况。
2 方 法
2.1 概 述

2.2 时空特征提取
时空特征提取模块可获取步态序列的时空特征表征。该模型的输入是一组步态轮廓图,经过第一级CNN之后得到帧级特征图,然后将帧级特征图分别输入时空特征提取模块中进行重提取,STM的输入是当前帧的特征图和下一帧的特征图。如果当前帧的步态信息被携带物所遮挡,通过对下一帧的相同部位进行提取来弥补当前帧因遮挡丢失的信息,可以很好地解决携带包和穿外套问题。然后将提取的帧级特征映射到序列级特征。整个过程提取每一帧图像的空间特征的同时还提取整个序列的时间特征,很好地保留了步态的时空信息,比步态模板的方式提取的特征更全面。
具体地,STM的具体结构如图2所示。
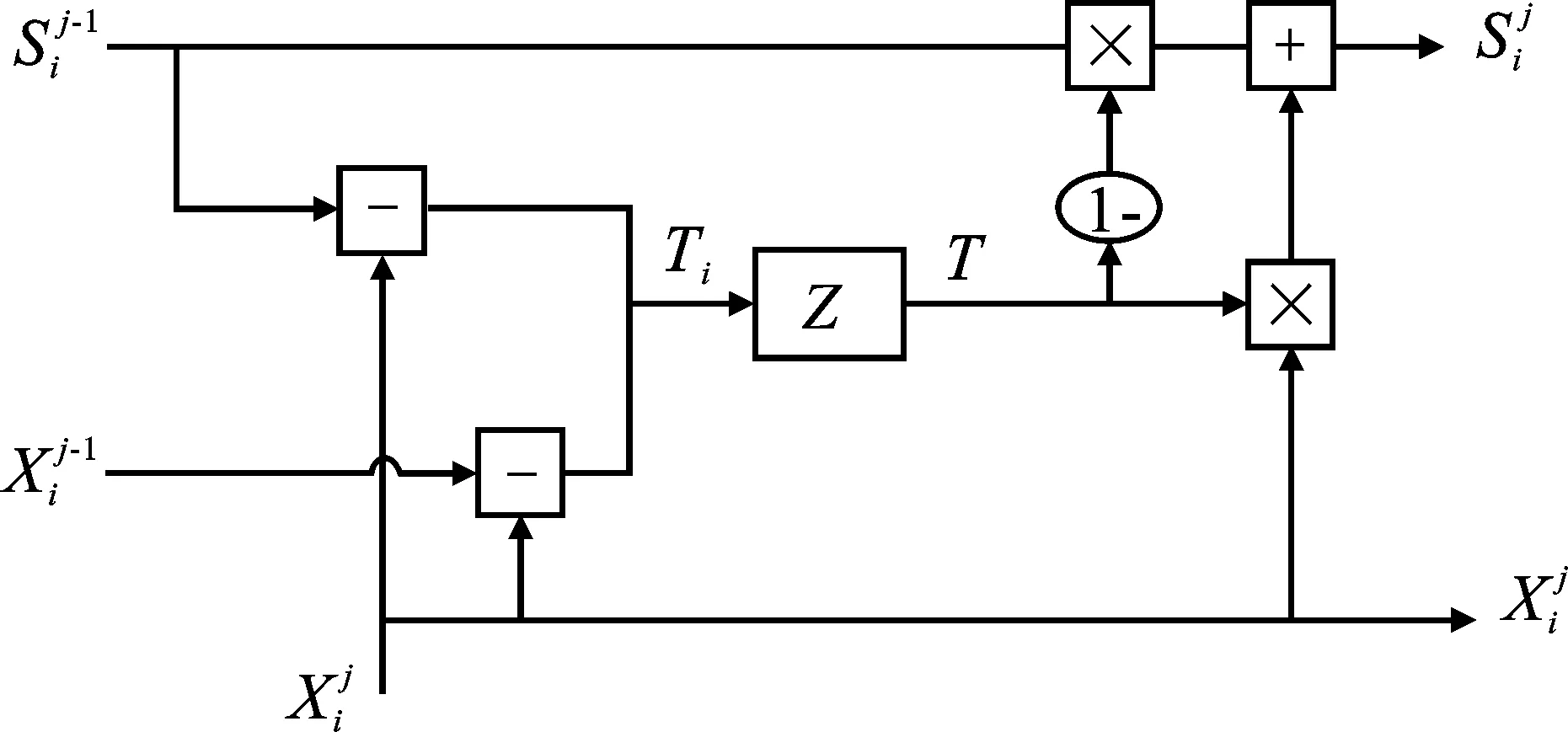
图2 时空特征提取模块的内部结构
(1)
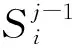
(2)
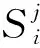
2.3 高层语义度量
高层语义度量模块是对提取的时空特征进行度量学习,获得更具鉴别力的步态特征。为了使深度网络同时提取局部和全局特征,将时空特征图水平划分,然后对每部分分别进行最大池化和平均池化,两者结果对应相加。这是因为不同的分割条在不同的尺度中描述不同的感受野,并且不同的分割条在每个尺度中描述不同空间位置,所以将视觉特征进行水平划分。同时,为了提高表观特征的鉴别力,将使用两个三元组损失融合的度量学习策略。接下来使用全连接层将特征映射到鉴别子空间,进而可以提高鉴别子空间的表达能力。
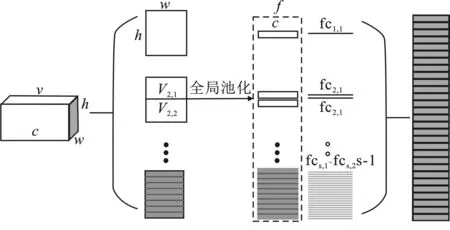
图3 视觉特征水平划分结构
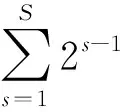
其次,为了增强STM模块在局部的细化能力,这里使用基于三元组损失函数的局部约束形成公式为
(3)
其中,N是批处理中的行人数量,K是步态轮廓序列,m是三元组函数正负样本对距离的边缘幅值。
最后,三元组损失进行端到端深度度量学习,作用是将同一个ID的样本在特征空间中拉近,同时将不同ID的样本在特征空间中推远。三元组损失优化了嵌入空间,使得具有相同特征的数据点比具有不同特征的数据点更接近。
给定一个图像三元组,即锚样本a、正样本p和负样本n,三元组损失函数形成公式为
(4)
(5)
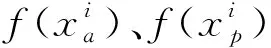
3 实 验
该部分的实验包含两个部分。第1部分是该方法的相关实验设置。第2部分是比较该方法和其他先进算法在公开数据集CASIA-B[19]上的效果。
3.1 设置
CASIA-B是一个大规模的,多视角的步态库,如图4所示。共有124个人,每个人有11个视角(0°,18°,36°,…,180°),在3种行走条件下(普通条件,穿大衣,携带包裹条件)采集。即,每个人有3种行走条件,其中,普通条件下每人6段视频序列,穿大衣条件下每人2段视频序列,携带包裹条件下每人2段视频序列。每个行走条件下有11个视角,所以,每个人有110段视频序列。
按照相关文献,该数据集按训练集的数据规模来划分为3种设置。第1种设置为前24个人作为训练集,后100人作为测试集的称为小样本训练(ST)。第2种设置为前62人作为训练集,后62人作为测试集的称为中样本训练(MT)。第3种设置为前74人作为训练集,后50人作为测试集的称为大样本训练(LT)。在3种设置下的测试集中,普通条件下的前4段视频序列在训练集里,剩下的两个序列和穿外套条件下的两个序列及携带包裹条件下的两个序列留在测试集里。
在所有的实验中,输入的是一组大小为44ⅹ64的对齐轮廓图。轮廓图直接由数据集提供,并基于文献[15]中的方法进行对齐。选择Adam作为优化器[15]。HPP中尺度S的数量设置为5。三元组损失的边缘幅值设定为0.2[2]。文中实验使用PyTorch框架实现,并在一个TITAN XP GPU上进行了训练。学习率设置为1e-4。批处理设置为128。在CASIA-B中,由于训练集数据规模不同,对于ST、MT和LT,分别进行50 000次、60 000次和80 000次的迭代训练。

图4 CASIA-B数据集中的部分轮廓图样例
3.2 实验结果
在CASIA-B数据集上做了实验,结果如表1,显示了该方法的算法与当前先进算法之间的比较。除了文中使用的算法,其他结果数据是直接从相应文章中引用的。所有结果均在11个视角中取平均值,并且不包括相同的视角。例如,视角18°探针的正确率是除18°以外的10个视角平均值。
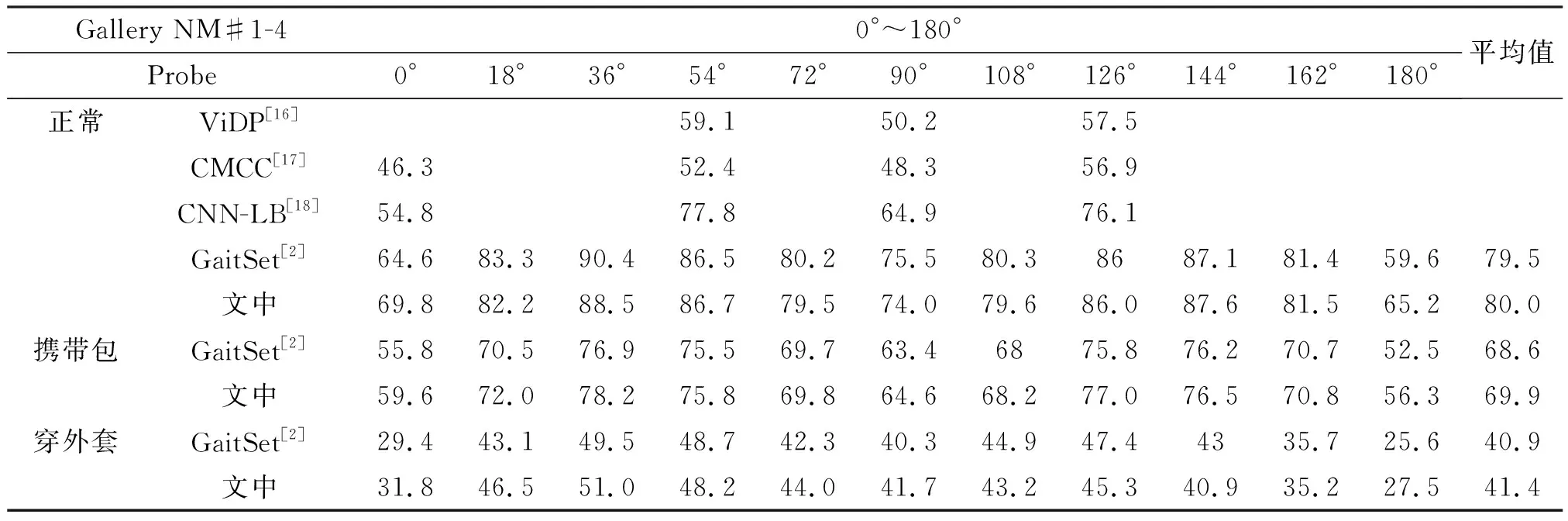
表1 在CASIA-B数据集的ST设置下,平均Rank-1准确度,不包括同视角情况
步态信息不仅包含与步行方向平行的步幅信息,还包括与行走方向垂直的步态信息。虽然在平行视角(90°)和垂直视角(0°&180°)容易丢失部分步态信息,但是,从表1中可以看出,文中方法仍然得到了很好的性能;与当前最优的GaitSet算法相比,准确度在视角90°、0°和180°处分别平均提高了0.4%、3.8%和3.8%。
文中的方法在仅有24个目标的训练集(ST)上,分别在3种行走条件下都有所提高,如表1所示。在正常,携带包和穿外套上,相比于当前最优值分别提高了0.5%、1.3%和0.5%。原因是由于文中的模型通过STM模块可直接从轮廓图中提取时间和空间信息,然后,通过度量学习获得更有鉴别力的步态特征,从而得到很好的训练模型。另外,在3种行走条件下,11个视角整体平均Rank-1准确度提高了0.8%。表观变化在步态识别中是一个大的挑战,文中的方法在CASIA-B数据集中的携带包和穿外套序列下都得到了很好的性能。

表2 CASIA-B数据集在正常行走情况下的不同方法下的rank-1准确度(ST)
同时,不同规模大小的训练样本,所训练的模型会得出不一样的结果,文中的模型在跨视角(0°,54°,90°,126°)下性能依然比较好。表2显示,训练样本数为24人(ST),行走条件在NM下,Gallery为0°~180°时,平均精确度比当前最优算法提高了10.7%,Gallery为36°~144°时,平均精确度比当前最优算法提高了6.3%。
当训练集规模增大,数据干扰越大的情况下,文中的模型在准确度上也是最优的。表3显示,在训练样本数为74人(LT),行走条件在NM、BG和CL以及跨视角(0°,54°,90°,126°)的情况下,优于当前算法的平均准确率,最高达5.2%。
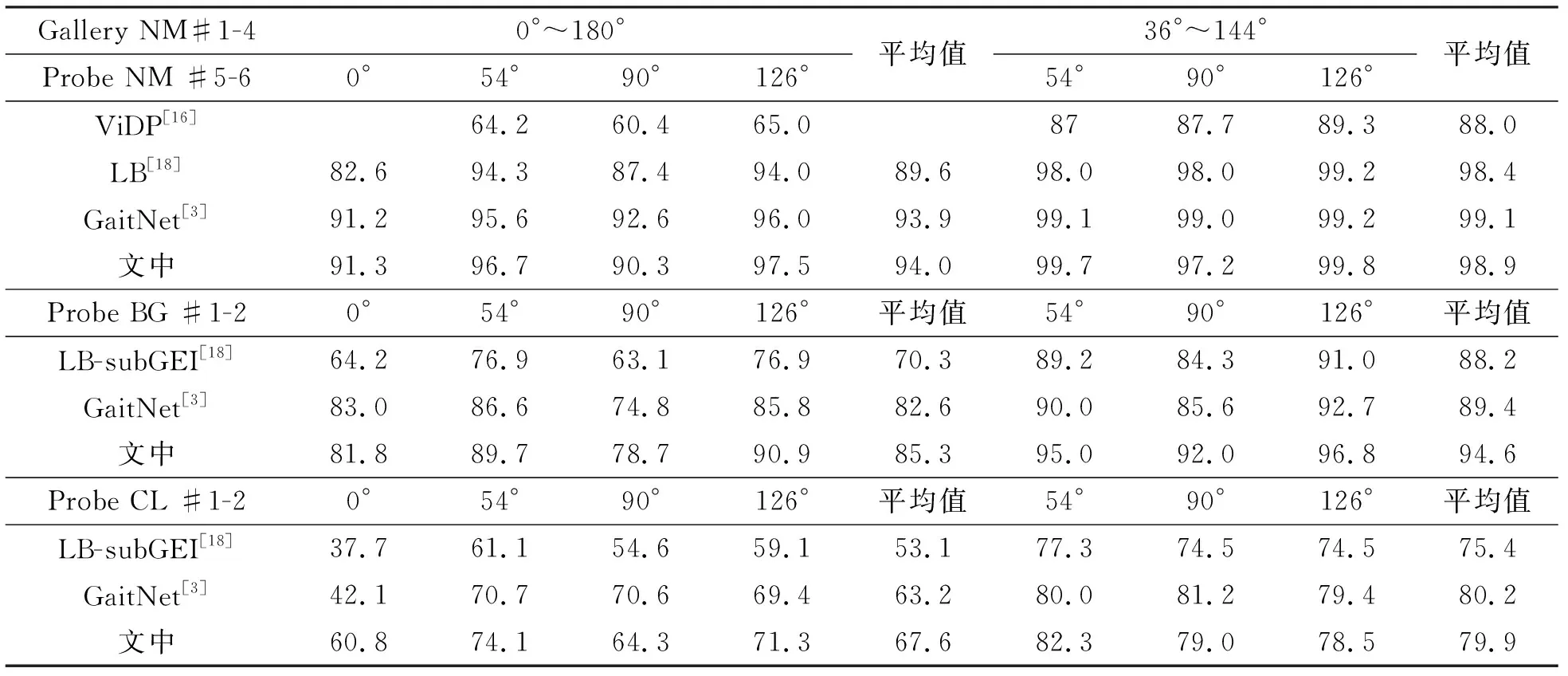
表3 CASIA-B数据集行走情况下的NM,BG,CL,在不同方法下的Rank-1准确度(LT)
4 结束语
笔者提出了一种基于时空卷积的步态识别方法。该方法与将步态作为模板或序列的现有方法相比较能更有效地提取空间和时间信息,首先利用时空特征提取模块对步态信息进行重提取以弥补帧中因为遮挡而丢失的信息;然后利用层级卷积网络将帧级特征聚合为序列级特征;最后利用高层语义度量模块将提取到的序列级特征进行水平分割,使模型更多的关注局部特征,从而提取到更具辨别性的步态特征,可在特征鉴别力上有很大提升。表观变化在步态识别中是一个大的挑战,并作为主要因素影响步态识别率,但在这里都得到了很好的性能提升。通过在目前流行的基准步态数据集CASIA-B上的实验表明,与目前最先进的算法相比,实现了高的识别精度,并在复杂环境中(携带物,穿外套)显示出良好的灵活性。在接下来的工作中,会更加关注影响步态识别率下降的外部因素。同时,把步态应用到行人再识别和行为识别等方面,也是一个很有前景的方向。
