一种自适应模拟退火粒子群优化算法
2021-09-02闫群民马瑞卿马永翔王俊杰
闫群民,马瑞卿,马永翔,王俊杰
(1.西北工业大学 自动化学院,陕西 西安 710072;2.陕西省工业自动化重点实验室,陕西 汉中 723001 ;3.陕西理工大学 电气工程学院,陕西 汉中 723001)
自然界中的生物均具有一定程度的群体行为。在计算机中建模分析这些行为是人工生命研究的一个重要方面,其背后隐藏的规律将对人类的生活产生很大的启发。粒子群算法(Particle Swarm Optimization,PSO)[1]是KENNEDY博士和EBERHART教授通过对鸟群觅食模型进行改进所提出的。因为粒子群算法需设置的参数少且计算结构简单,目前已经广泛地应用在实际工程中,如多目标控制、神经网络研究、复杂多峰值优化求解问题等。众多的学者针对粒子群算法早熟和收敛速度慢等问题,做了大量的优化研究,主要可以分为3个方向:(1) 最早出现的是针对粒子群算法自身迭代策略的改进,将原本固定不变的学习因子和惯性权重系数改进,为其设置随着迭代次数线性或非线性动态变化的调整策略[2-6]。在搜索的初期、中期及末期等阶段有着不同的搜索重点,为达到平衡全局和局部搜索能力的要求,在保证搜索精度的情况下提升搜索速度。文献[6]中针对不同的迭代策略进行对比,经过仿真证明在初始权值和最终权值相同的情况下,正弦函数递减策略优于线性策略,而线性策略优于正切函数策略。(2) 将粒子群算法的优势和其他优化算法进行融合,结合其他算法的优势来改进粒子群算法[7-8]。文献[8]将牛顿最速下降因子引入粒子群算法中,提高了粒子群体的全局收敛性和收敛速度,克服了这种算法易“早熟”的缺点。(3) 针对粒子种群的拓扑结构进行改进[9-12]。文献[11]将原本的D维空间转化到混沌空间,根据混沌具有遍历性等特点进行迭代,提升了优化效果;文献[12]结合两种邻居拓扑结构,将种群分为3个子群,并采用不同的学习因子组合不同的搜索侧重点,经过一定迭代次数后对子种群的性能进行评估,指导粒子在不同子群间迁移,提升了算法的综合性能。笔者将前两种类型进行改进,采用线性变化的策略控制社会及自我认知因子,利用双曲正切函数来控制惯性权重系数,在此基础上融合模拟退火算法提升了算法跳出局部最优解的能力。选出5种近几年被提出的改进粒子群算法的优化算法[12-16],与笔者提出的算法共同通过CEC2017中选出的7种测试函数进行寻优测试(其中包含1种单峰函数和6种典型复杂多峰函数),结果证明该优化算法在寻优速度、收敛精度及算法稳定性等方面有显著的提升。
1 相关工作
1.1 粒子群算法
粒子群算法的寻优过程通过粒子在搜索空间的飞行完成。粒子每次迭代中的移动由3个部分组成,分别是对上一次速度的继承、自身学习以及种群的信息交互,其表达式为
vi(k+1)=ωvi(k)+c1r1(Pbest.i(k)-xi(k))+c2r2(Gbest-xi(k)) ,
(1)
xi(k+1)=xi(k)+vi(k+1) ,
(2)
其中,ω为惯性权重系数;c1、c2分别表示自身认知因子和社会认知因子,是控制粒子群算法的迭代最重要的参数;xi(k)和vi(k)分别代表第i个粒子第k次迭代时的位置和速度;r1和r2为随机数;Pbest.i为第i个粒子个体最优位置;Gbest为种群最佳位置。飞行粒子的搜索能力不仅受到粒子之前的速度影响,还受到两个学习因子指导。通过c1控制自我认知部分,指导粒子向该粒子自身的历史最优解飞行;c2控制社会认知部分,体现种群中各粒子的信息交换,指导粒子向种群最优解的位置飞行。实际问题的寻优的终止条件设置为全局最优解满足适应度的要求,而实验中为比较不同算法的效果,设置迭代终止条件为达到最大迭代次数时终止。
每次粒子飞行前,先判断vi(k)是否越过设置的速度范围。若越过,则取速度边界值替代当前速度。飞行后再判断xi(k)是否超出最大搜索空间。若超出,同样取边界值替代当前值。根据相应的适应度值的变化来更新粒子群中Pbest.i和Gbest,更新方程为
(3)
(4)
1.2 模拟退火法
模拟退火算法(Simulated Annealing,SA )是由米特罗波利斯在20世纪50年代根据对固态物质退火过程的研究而提出的一种算法,后在组合优化领域中得到大规模的应用推广,如现代的玻尔兹曼机、图像恢复处理、VLSI最优设计、机器学习等科学领域中的组合优化问题。该算法是一种基于蒙特卡罗思想设计的近似求解最优化问题的方法,结构简单易实现,初始条件限制少,使用灵活且运行效率高,与其他算法的结合能力较强,有着广阔的前景。模拟退火算法的核心源自固体降温热力学过程,退火指物体的能量随着温度的降低达到最低值的过程。米特罗波利斯准则是模拟退火算法中的核心准则,其特别之处在于温度下降过程中不仅能够接受优值,也会根据温度变量产生的概率接受较差的值,增大了算法在寻优过程中跳出局部优解的概率。将粒子群算法和模拟退火算法相结合,可以有效地减少粒子群算法陷入局部最优解的概率。
模拟退火算法在迭代初始阶段需要根据种群的初始状态设置一个初始温度。每次迭代对模拟固体内部粒子在温度下降情况下的移动,根据米特罗波利斯准则判断是否由干扰产生的新解替代全局最优解,其表达式如下:
(5)
其中,Ei(k)表示第i个粒子在第k次迭代时的内能,即当前粒子的适应度值;Eg表示当前种群最优点的内能;Ti表示当前温度。温度每次迭代会以一定程度线性衰减,寻优过程是不断寻找新解和缓慢降温的交替过程。Ei(k)完全决定了其下一次产生的新状态Ei(k+1),与之前的Ei(0)至Ei(k-1)无关,这个过程是一个马尔可夫过程。使用马尔可夫过程分析模拟退火步骤,经过有限次的转换在温度Ti下的平衡态的分布如下:
(6)

(7)
其中,Smin是最优值的搜索空间集合。当温度降到0时,pi的分布见式(7)。温度下降的同时伴随着大量的状态转移,达到热平衡的状态,则找到全局最优的概率为1。模拟退火算法最大的优点是跳出局部最优点的能力突出。
2 自适应模拟退火粒子群算法
以往应用经典的粒子群算法设置ω、c1和c2的值时,大多依赖经验的判断,或者根据大量的仿真实验来确定一个固定的值。但通过上述的分析知,如果这3个参数能够随着优化的进行不断变化的话,粒子群算法将会有更加优秀的效果。惯性权重系数ω直接影响着算法搜索能力的强弱,控制粒子继承以往运动趋势,即搜索飞行的惯性。若需要算法的全局搜索能力较强,则设置ω的值比较大,但受前一次迭代速度的影响较大,相应的粒子飞行距离较大,不利于局部寻优。若需要进行局部精细解的搜索,提升局部区域的寻优能力,则设置ω的值较小,但陷入局部最优的概率会变大。ω值的选取与算法收敛速度和全局搜索能力成正比,与局部搜索能力成反比。笔者选取[-4,4]之间负的双曲正切曲线来控制惯性权重系数的变化。双曲正切曲线是一个非线性的控制策略,在搜索初期其递减速度较慢,给粒子充分的时间进行大范围的全局搜索,减小陷入局部最优的情况;中期近似线性递减,逐渐加强局部搜索的能力;后期变化率再次减小,着重细致的局部搜索,精准确定全局最优解。惯性权重函数如下:
ω=(ωmax+ωmin)/2+tanh(-4+8×(kmax-k)/kmax)(ωmax-ωmin)/2 ,
(8)
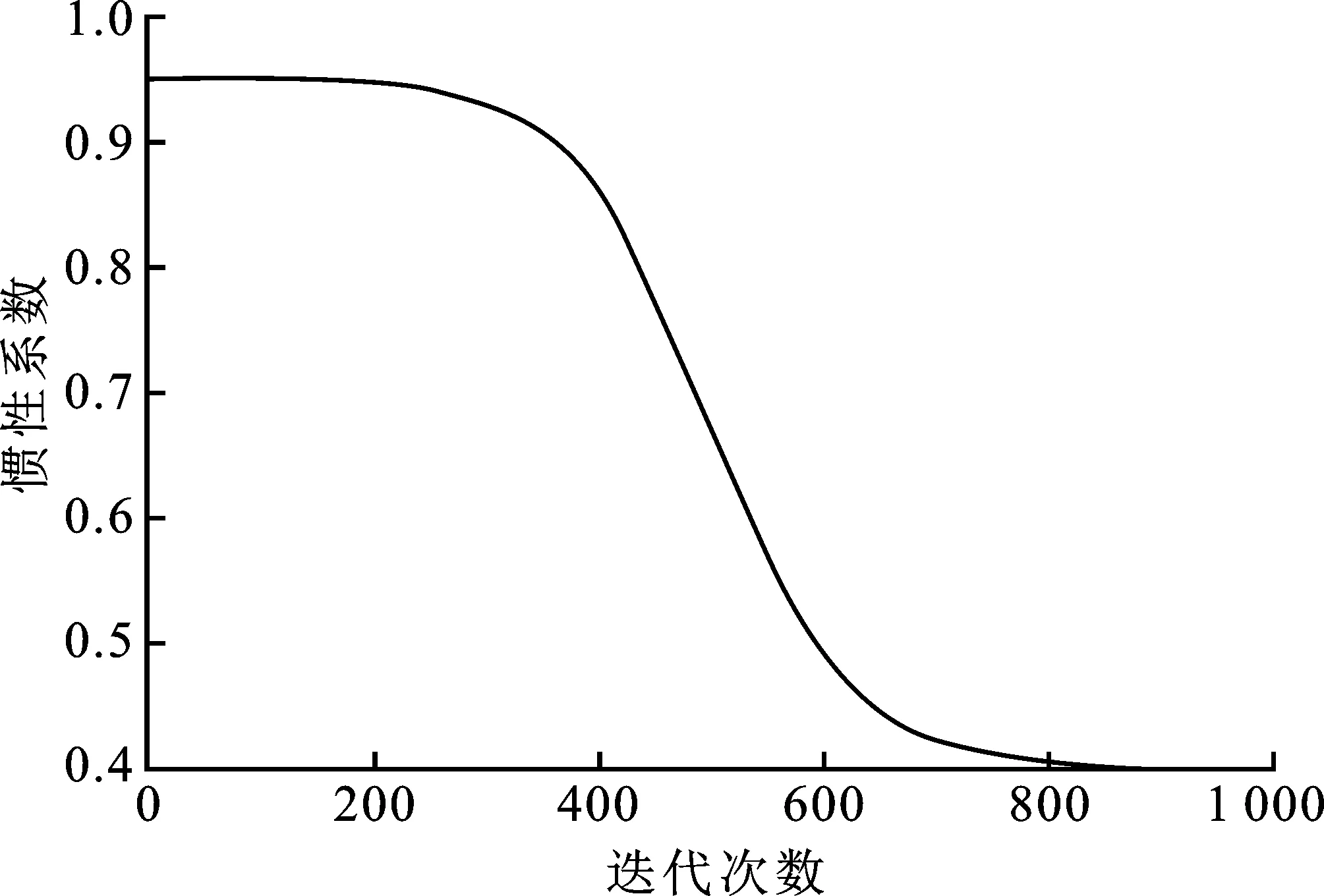
图1 惯性系数自适应变化图
其中,ωmax,ωmin是惯性权重系数的最大值和最小值,文中取ωmax=0.95,ωmin=0.40。经大量实验证明,采用如上取值时算法性能会大幅度提升[2]。k是当前迭代次数,kmax是最大迭代次数,其图像见图1。
当c1>c2时,粒子的运动更偏向个体最优的方向;反之,则更偏向群体最优方向。笔者所提的优化算法初始阶段注重全局搜索,着重突出粒子的自我认知能力,注重粒子运动的遍历性,减小陷入局部最优解的概率。随着迭代的进行,加强粒子间的交流,使种群最优解的位置对每个粒子的运行起到更大的影响作用,着重对Gbest的附近进行局部搜索。对应着这样的搜索策略,随着迭代次数的增加,ω不断减小,c1逐渐减小,c2逐渐增大。笔者采取如下参数变化策略:
c1=c1max-k(c1max-c1min)/kmax,
(9)
c2=c2min-k(c2min-c2max)/kmax,
(10)
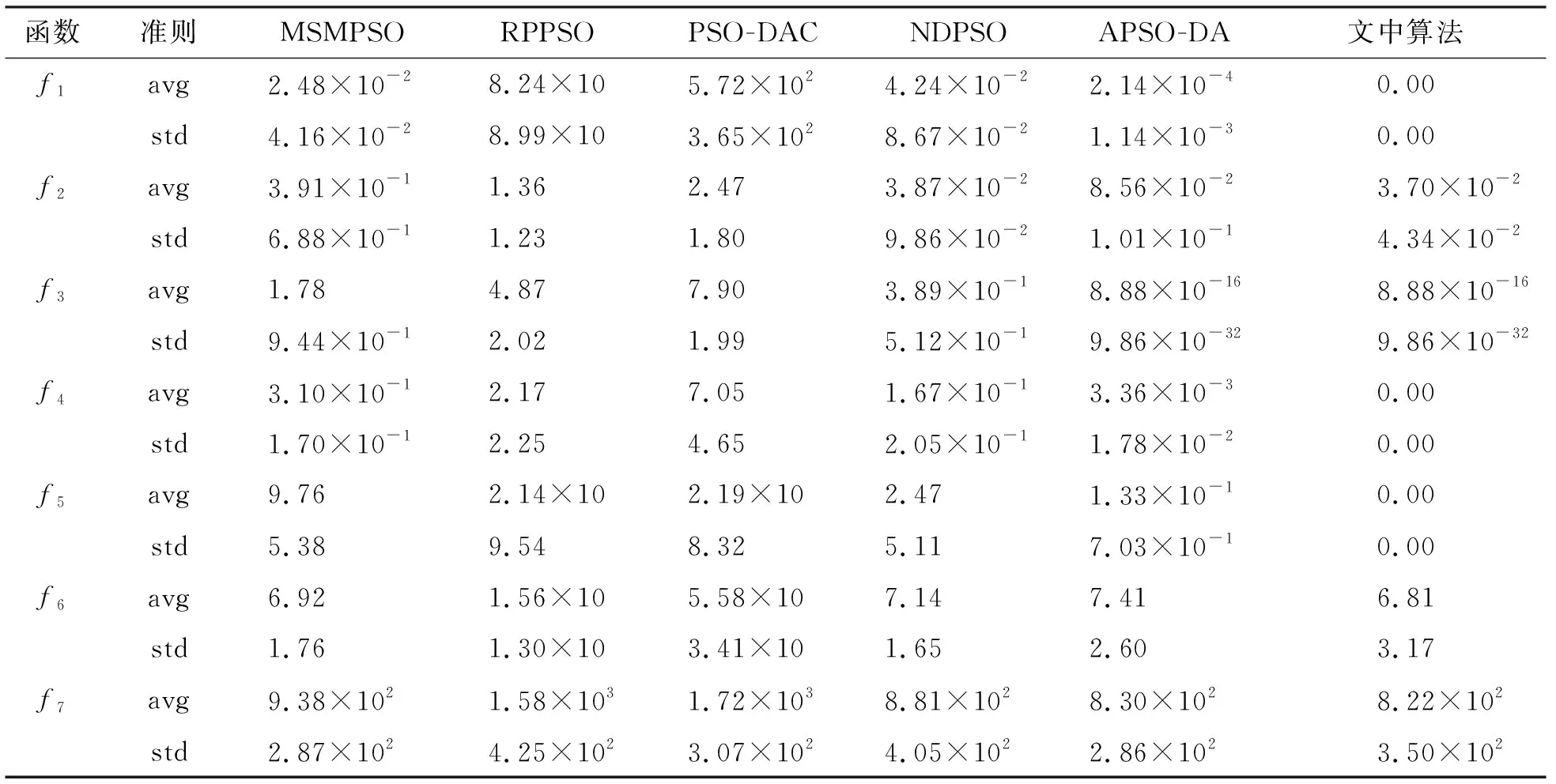
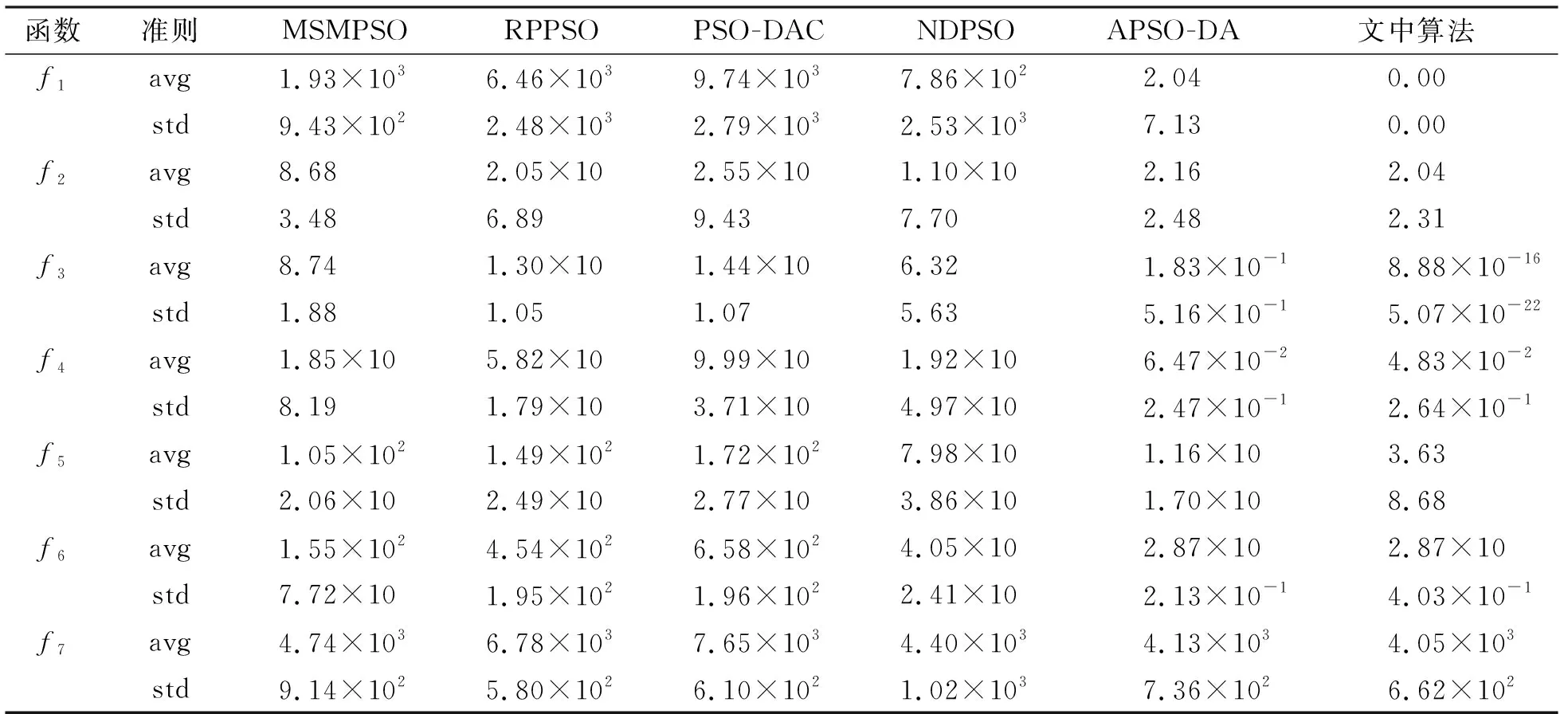
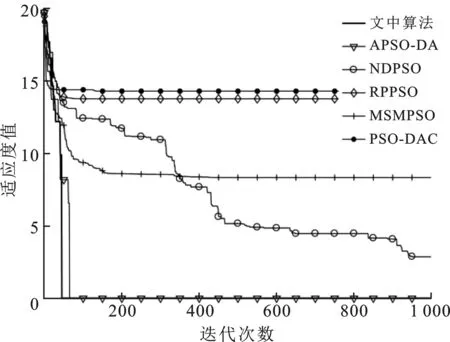
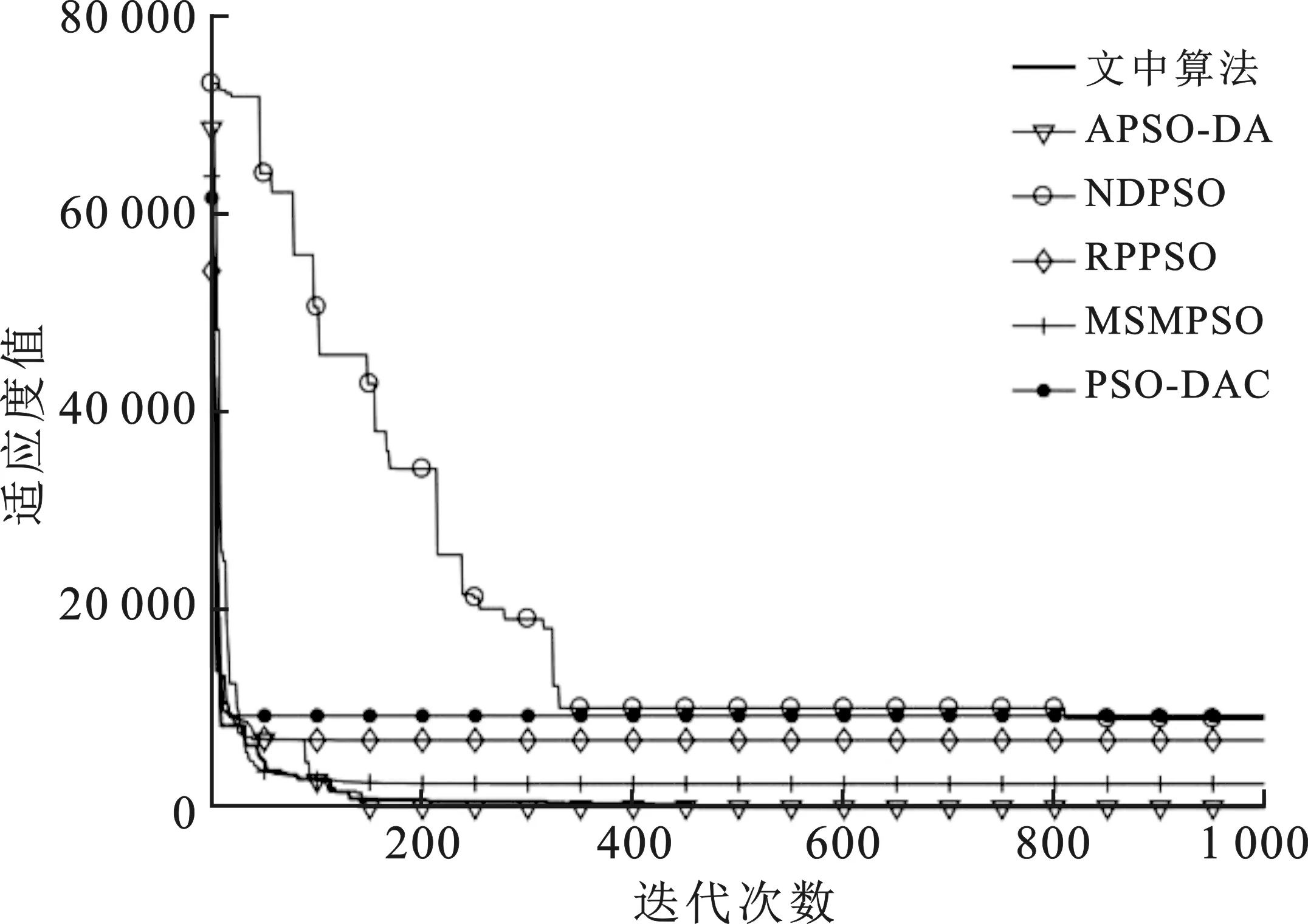
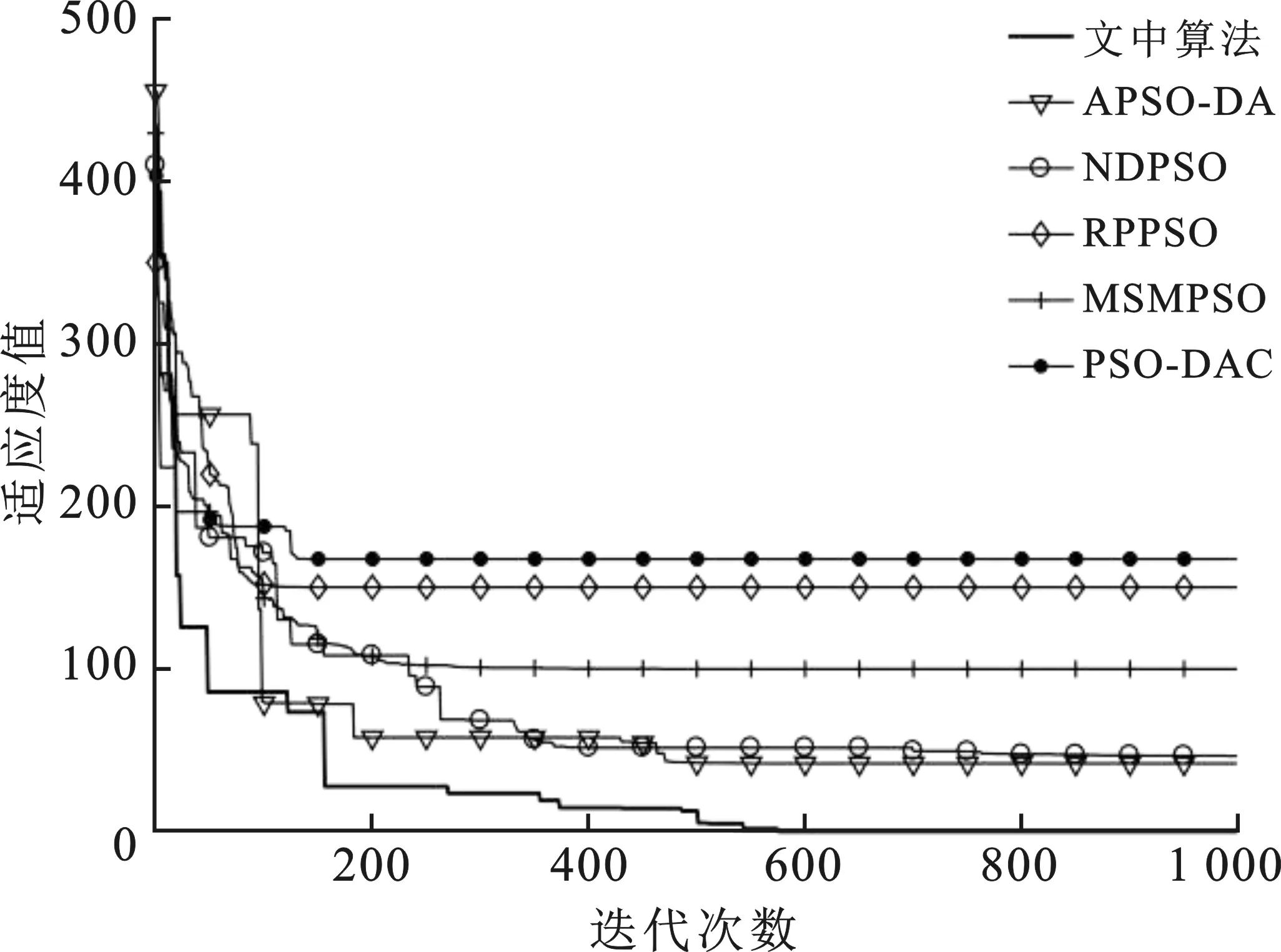
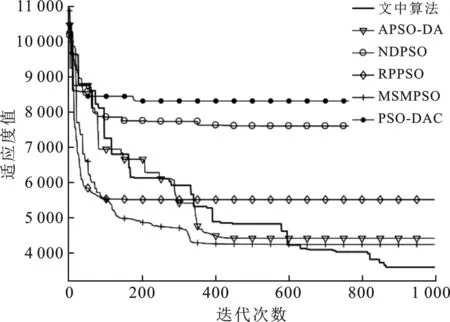
其中,c1max,c1min分别是自我学习因子的最大值和最小值;c2max,c2min分别是社会学习因子的最大值和最小值。参照文献[16]并进行大量实验后,取c1max=2.50,c2max=1.25,c1min=1.25,c2min=2.50。随着迭代次数k的增加,c1由2.50线性减小至1.25,而c2则由1.25逐步线性增加到2.50,这样设置就满足了初期注重粒子在空间上的遍历性要求,增强了全局搜索的能力。在迭代次数过半时,c1 将模拟退火算法中的米特罗波利斯准则引入迭代中。根据最初的粒子最优值设置初始温度,并且每次迭代后以一定的降温系数μ衰减。具体操作如下: (11) 其中,T为初始温度。每次迭代后,计算更新后位置的内能(适应度)与种群最优点内能的差距,根据式(5)计算得出的概率与rand()进行对比,判断是否接受较差的解。取降温系数μ=0.95。笔者所提出的自适应模拟退火粒子群算法对粒子群算法的3个重要参数进行了自适应变化且加入了模拟退火操作,增加了寻优的精度和速度。具体步骤如下: 步骤1 设置搜索空间及搜索速度的边界值,设置种群规模及最大迭代次数kmax。 步骤2 随机产生种群中所有粒子的初始位置和初始速度。 步骤3 评价全局粒子的适应度值并记录Gbest,根据式(11)设置模拟退火的初始温度。 步骤4 根据式(8)~式(10)自适应地改变ω、c1和c2。 步骤5 根据式(1)改变粒子速度,根据式(2)进行一次迭代寻优。 步骤6 计算移动后粒子的适应度。 步骤7 根据式(3)更新粒子的自身的历史最优位置。 步骤8 根据式(5)计算接受新解的概率pi(k)。 步骤9 以米特罗波利斯准则为依据,对比概率pi(k)与rand(),判断是否由产生的新解替代全局最优解进行退火操作,更新温度。 步骤10 判断是否达到最大迭代次数kmax,若未达到则返回步骤4。 步骤11 输出当前最优粒子,即寻优结果,算法终止。 为了验证笔者提出的模拟退火粒子群优化算法的效果,现从CEC2017测试集中选取出1种单峰函数f1及6种多峰函数f2-f7来对笔者所提出的算法进行测试,根据要求设置其搜索空间。具体的函数表达式见表1。 同时在不同类型的粒子群算法的优化算法中选取5种,分别是MSMPSO[12](Multi-population based Self-adaptive Migration PSO),RPPSO[13](PSO with Random Parameters),PSO-DAC[14](PSO baesd on Dynamic Acceleration Coefficients),NDPSO[15](PSO with inertia weight decay by Normal Distribution)和APSO-DA[16](Adaptive PSO via Disturbing Acceleration coefficents)进行仿真。通过对比笔者所提算法与这5种算法在搜索空间维数分别是D=10和D=30时,粒子群包含的粒子数相同,最大迭代次数相同的情况下的运行效果,来体现笔者所改进的算法的优越性。 表1 测试函数信息表 使用MATLAB 2016b环境进行仿真验证。所选取的5种对比算法的惯性权重系数和认知因子等参数都按照文献[12-16]中的设置,粒子种群规模统一设置为30,最大迭代次数kmax=1 000。每个测试函数的维数在D=10和D=30的情况下分别运行30次,结果记录如表2及表3所示。从表2~表3中根据30次寻优结果的平均值和标准差可以看出,无论是针对单峰函数还是多峰函数,本文算法针对多种测试函数的搜索精度都优于以往的算法。f2~f5这4个复杂的多峰函数的寻优精度,优于以往优化算法数十倍。f1~f5的寻优结果的标准差最小,有极强的搜索稳定性。 表2 D=10时6种优化算法的运行结果对比 表3 D=30时6种优化算法的运行结果对比 搜索空间维度的增长,表示着每次迭代所需要处理的数据成倍提升,全局最优点位置信息也更加复杂,寻优任务变得十分困难。在实际工况下,面对高维问题首先要做的是降低维数,减少计算量。D=30的这类高维数情况较少,但为证明优化算法面对高维问题时的性能,进行了针对D=30时的寻优实验。实验中面对搜索空间维数从10增长到30,大部分算法的收敛精度都大幅度下降,而笔者所提出的算法依然有着精准的寻优精度,针对高维数的复杂多峰测试函数有很强的寻优结果。 为了更加直观地对比不同算法在精度上的差别以及迭代速度的优劣性,选出部分测试函数的优化曲线图。图2~图5分别显示在高维数D=30时,笔者所提算法与5种算法的对比。图2显示在面对简单的单峰函数f1时,文中算法的速度优势并不突出,个别算法也具有较快的速度和精度。由图3~图5可知,在面对f3、f5和f7复杂多峰函数时,笔者所提算法在收敛速度上的优势得到显著的体现,寻优速度快的同时也保证了收敛的精度。观察图5,面对搜索空间极大、峰值极多且分布极不规则的Schwefel测试函数,并且这个函数的各个局部优解的差值极小,寻优难度较大。可以看出在迭代到中期(500次左右)时大部分算法已经陷入局部优解,因为这些算法的寻优过程在这个阶段,种群中的大部分粒子已经聚集在局部最优处。随着越来越多粒子受种群最优的影响被引向局部最优解处,所以跳出局部最优解的能力逐步减弱至丧失;但笔者所提的算法虽然在初始迭代的前400次,其精度优势并不突出,但其优势突出体现在其因为融合了模拟退火操作,极大程度地增强了跳出局部最优的能力,在迭代800多次的后期,仍然可以不断地更新全局最优值,保证跳出局部最优的能力,提升搜索结果的精准性。综上所述可知,笔者所提的算法在收敛速度上也具有一定程度的优势。 图2 f1函数的6种方法优化曲线对比图 图3 f3函数的6种方法优化曲线对比图 图4 f5函数的6种方法优化曲线对比图 图5 f7函数的6种方法优化曲线对比图 采用双曲正切函数控制惯性权重系数随着迭代进行非线性变化,用线性变化策略控制认知因子c1、c2,从而保证了3个控制搜索性能的参数都能随着迭代进行自适应变化;同时,在粒子群算法寻优过程中加入模拟退火操作,通过米特罗波利斯准则引导种群以一定的概率接受差解,弥补了粒子群算法易陷入局部最优的缺陷,极大地提升了粒子群算法的搜索能力,满足了算法在不同阶段的搜索要求。面对多种高维多峰的测试函数,与以往的粒子群优化算法的寻优效果进行对比,其寻优精度提升数十倍,能精准地收敛在全局最优处,以较快的收敛速度完成寻优目标。3 实验及结果分析
3.1 测试函数及参数设置

3.2 算法精度对比
3.3 收敛速度对比
4 结束语
