采购驱动下高校图书馆借阅数据挖掘分析
2021-08-26赵晓芳
赵晓芳
(常州大学图书馆 江苏·常州 213000)
采编工作直接关系到图书馆的馆藏结构质量,随着教育改革的不断深入以及大数据时代的到来,对图书采编工作创新提出了艰巨的任务和挑战[1]。图书采购是图书采编的关键工作,如何充分发挥有限的资金投入,合理购买广大师生真正需要的图书,从而提高图书资源的利用效率,直接影响到图书馆整体服务水平。传统的采购计划制定方法主要采用专家法和经验法等,受到专家和馆员的个人研究领域和喜好等主观因素的影响,而且传统的方法大多采用人工为主的方式进行,具有工作量大、精准度差、资金使用效率低等弊端。因此,制定图书采购计划应结合学校学科和科研的发展需要,充分考虑全校师生的实际需求,对师生借阅记录、访问日志等进行数据挖掘和建模,以模型结果为基础制定图书采购计划,为高校图书馆图书结构优化提供依据[2]。
一、图书馆借阅数据聚类分析
(一)数据挖掘理论简介
数据挖掘(DM)是一种从大量数据中提取未知数据的过程。数据挖掘的流程是:首先,收集相关数据,对数据进行清理、集成、选择和数据变换等预处理;其次,通过智能算法进行数据挖掘和建模,并对模型有效性进行评估;最后,对数据挖掘表现出来的知识进行可视化呈现。高校图书馆具有大量馆藏信息资源和读者借阅与阅读信息数据,通过对这些数据进行深度挖掘,使用聚类分析和关联规则分析等方法,最终准确掌握读者信息,为图书采编工作提供决策[3]。
(二)图书馆借阅数据聚类分析
聚类分析是依据某种规则将数据集划分为不同的类别,将相似度较高的数据对象划归为同一类,并尽可能将不同类别的数据进行分离。聚类分析的常见算法有层次聚类、k均值算法、EM算法和Optics聚类算法,其中k均值算法是目前用于划分数据中心聚类最广泛应用的算法之一,采用标准距离函数作为其相似性的度量和评价指标,对于对象与样本间相似性进行间接度量分析,对于对象之间距离相近的多个数据对象进行多次迭代计算,把满足精度要求的紧凑且独立数据对象最终确定为聚类集。主要从两个方面对图书馆借阅数据进行聚类分析,一方面对读者进行聚类分析,可以很好地反映读者整体阅读兴趣度,另一方面对图书分类号进行聚类分析,可以从侧面反映读者的阅读趋势,为图书采购提高指导[4-6]。
1.读者聚类分析
通过对某高校图书馆读者借阅数据进行收集,根据读者借阅图书数量进行聚类分析。采用SPSS Modeler工具统计读者借阅总体情况,如图1所示。采用k均值算法对8568位读者的借阅数据进行聚类数据挖掘分析,本文首先设定初始数值k为10,采用k-means算法进行计算,得到第一次聚类结果,对10个聚类距离中距离最近的类进行合并,因此聚类中心数减少为9,同理重复上述方法,采用k-means算法进行反复计算,直到评判函数值达到需要的精度为止,最终得到最优的聚类结果。经过多次计算,最终将k值设置为5,此时聚类效果最好,聚类挖掘效果如表1所示。根据聚类结果将读者分成了5个大类。第一类(聚类-1)平均借阅图书量只有1.95本,读者人数占到读者总数的62%,说明接近三分之二的读者图书借阅兴趣不高,主要原因可能是读者没有去图书馆借书的兴趣,也可能由于随着互联网+数字图书馆的迅猛发展,越来越多的人更倾向于网上查阅资料。因此图书馆应多增加数字图书和期刊等电子资源的采购力度,同时可以举办各种活动来提高读者到图书馆借书的兴趣。第二类(聚类-2)平均借阅图书量为4.85本,读者人数占总人数的四分之一,针对这类读者,图书馆可以为他们提供有较强针对性的个性化服务,不断提高他们的阅读兴趣。第三类(聚类-3)平均借阅图书量为7.76本,这类读者数量不多,只占到9.8%。第四类(聚类-4)、第五类(聚类-5)平均借阅图书量达到两位数,读者人数最少,只有272人。这类读者有着很广泛的阅读兴趣,图书馆应为他们提供图书推荐服务。
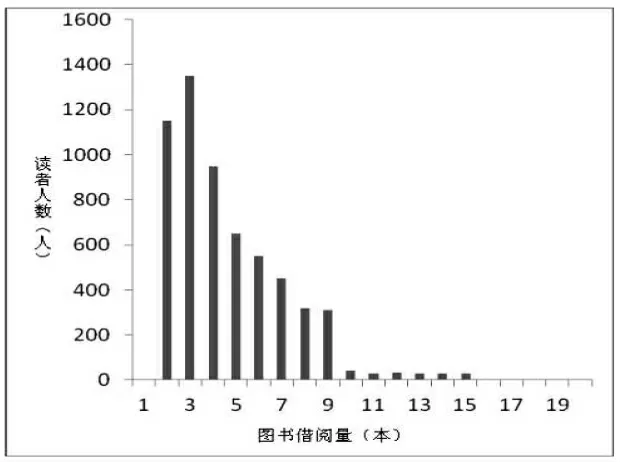
图1 读者图书借阅量直方图

表1 读者借阅情况挖掘结果
2.图书分类号聚类分析
对图书分类号进行聚类分析可以了解各种图书的受欢迎程度,从而为馆藏建设提供理论指导,基于图书分类号对某高校图书馆的图书借阅率进行聚类分析,聚类结果如表2所示。由于图书种类数较多,表3展示了部分分类号所属聚类结果。利用k均值算法聚类,将258种图书分类号进行聚类分为3类。第一类(聚类-1)图书借阅率仅为0.007,占总图书量的比例达到17.5%,种类数达到77种,主要是政治类、经济类、综合性图书类等,这类图书的借阅利用率较低,但藏书量较高,图书馆可以适当减少这类图书的采购量。第二类(聚类-2)图书借阅率为0.02,占总图书量的比例为67.8%,种类数有123种,主要是化学、机械、能源与动力工程、力学类、各国文学类等,这类图书的利用率大体正常,说明这123种图书的藏书量很适合当前的借阅量。第三类(聚类-3)图书借阅率为0.07,占总图书量的比例为14.7%,种类数有58种,分别为计算机技术类、工程技术类、中国文学类、艺术类等,这类图书的借阅利用率较高,但是藏书量较低,图书馆采购方面可以加大这类图书的采购量。

表2 基于图书借阅率的图书分类号聚类分析结果

表3 各分类号所属聚类结果(部分)

?
二、图书馆借阅数据关联规则分析及建议
(一)图书馆借阅数据关联规则分析
关联规则分析是一种基于规则从数据集中寻找不同对象之间隐含关系的分析方法。采用关联规则分析对读者借阅图书种类的进行挖掘分析,可以对读者同时借阅几类图书的可能性进行预测,从而为图书馆图书的摆放位置优化提供理论指导,为提高图书的整体借阅率奠定基础。采用Apriori算法对图书馆借阅数据进行关联规则分析,设置最小置信度为30%,设置最小支持度为0.5%,通过多次迭代计算共发现了38条关联规则,读者借阅数据的发掘结果如表4所示。

表4 借阅图书分类号之间的关联规则挖掘结果(部分)
从上述关联规则挖掘分析结果可以看出,很多学科有同时借阅两种及以上图书的需要,如电子类专业的读者除了借阅电子技术类图书外一般都会借阅计算机技术类图书,借阅艺术类和哲学类图书的读者大多会借阅语言文字类图书,安全类等交叉学科专业的读者除了借阅安全类图书外一般还会借阅化工类、机械类、电子类等图书,说明学科交叉是技术进步的一大趋势。总体来看,文学类、计算机类和各种工业技术类图书最受欢迎,图书馆可以重点关注这类图书的采购。
(二)基于数据挖掘的图书采购建议
第一,由数据发掘结果可知,62%左右的读者纸质图书借阅量较低,建议图书馆加大电子期刊与图书的采购力度,增加数字图书馆建设投入力度,满足大多数读者喜欢下载阅读电子图书的习惯。
第二,计算机技术类、工业技术类、中国文学类、艺术类等图书的借阅利用率较高,但是藏书量较低,图书馆采购方面可以加大这类图书的采购量。
第三,政治类、经济类、综合性图书类等,这类图书的借阅利用率较低,但藏书量却很高,图书馆可以适当减少采购量。
第四,交叉学科类图书借阅率较高,图书馆可以加大这类图书的采购量。
