BiGRU结合注意力机制的文本分类研究
2021-08-23黄忠祥李明
黄忠祥 李明
[摘 要] 随着信息时代的发展,文本包含的信息量越来越多,而同一段文本可以隶属于不同的类别,为了提升多标签文本分类任务的准确率,提出了一种基于ALBERT预训练、双向GRU并结合注意力机制的改进的多标签文本分类模型——BiGRU-Att模型。在百度发布的中文事件抽取数据集上进行实验,该模型的识别准确率达到了99.68%,相对比较组的BiLSTM-Att、LSTM-Att、BiGRU、BiLSTM、LSTM等模型的测试结果,准确率更高,性能更优。实验结果表明,改进的BiGRU-Att模型能有效提升多标签文本分类任务的准确率。
[关键词] 多标签;预训练;双向门控循环单元(BiGRU);注意力机制
[中图分类号] TP 391.1 [文献标志码] A [文章编号] 1005-0310(2021)03-0047-06
Abstract: With the development of information age, the amount of information contained in texts is increasing. It is often the case that the same text can belong to different categories. In order to improve the accuracy of multi-label text classification, BiGRU-Att model, an improved multi-label text classification model,is proposed based on ALBERT pre-training, BiGRU combined with attention mechanism. Experiments on Chinese event extraction data set published by Baidu show that the recognition accuracy of the model reaches 99.68%. Compared with the test results of BiLSTM-Att, LSTM-Att, BiGRU, BiLSTM, LSTM and other models of the comparison group, the model has higher accuracy and better performance. Experimental results show that the improved BiGRU-Att model can effectively improve the accuracy of multi-label text classification.
Keywords: Multi-label;Pre-training;Bi-direction Gate Recurrent Unit (BiGRU);Attention mechanism
0 引言
文本分类是自然语言处理中比较经典的任务,以往的文本分类任务通常属于较为简单的单标签文本分类任务,并且各标签之间是独立的。随着互联网的发展,文本的分类精细化要求越来越高,一段文本常常可以对应多个标签,例如,对于同一篇文章,其所属类别可以同时是军事类和科技类。对于多标签分类问题,还没有很成熟的处理方案,这就对多标签文本分类技术提出了更高的要求。
文本分類方法一般分为两类:传统的机器学习的方法和基于深度学习的分类方法。由于深度学习技术的发展较为迅猛,所以,目前大多数研究采用基于深度学习的模型去处理多标签文本分类任务。例如,Kim[1]首先提出的TextCNN模型,首次将常用于图像处理领域的CNN结构引入到文本分类任务中,开辟了这一领域新的篇章;Lai等[2]在TextCNN基础上提出了TextRCNN模型,以改进TextCNN不能处理长序列文本的缺点;Liu等[3]提出了TextRNN模型,改进了当时网络只针对单一任务训练的缺点;Zhang等[4]提出了BP-MLL模型,以处理多标签文本分类任务。
为了改进现有研究,有效提高模型处理文本分类任务的准确性,本文开展了下述研究:首先,针对多标签文本分类中使用Word2Vec[5]等静态编码的方法,存在因为忽略了特征所在的上下文依赖关系,导致最后识别准确率不高的缺陷,本文采用ALBERT[6-8]预训练模型进行文本内容的动态编码,使得文本特征向量能保留更多的细节信息,同时,预先训练好的词向量包含的先验信息对于小数据集很有帮助;其次,对于使用单向LSTM模型[9]无法较好地获取语义信息的缺陷,本文采用了双向GRU网络[10-13];最后,为了增强分类效果,模型在通过softmax分类前,加入了注意力机制[14-16],形成本文基于ALBERT预训练的BiGRU-Att多标签文本分类模型。
1 相关技术
1.1 ALBERT预训练模型
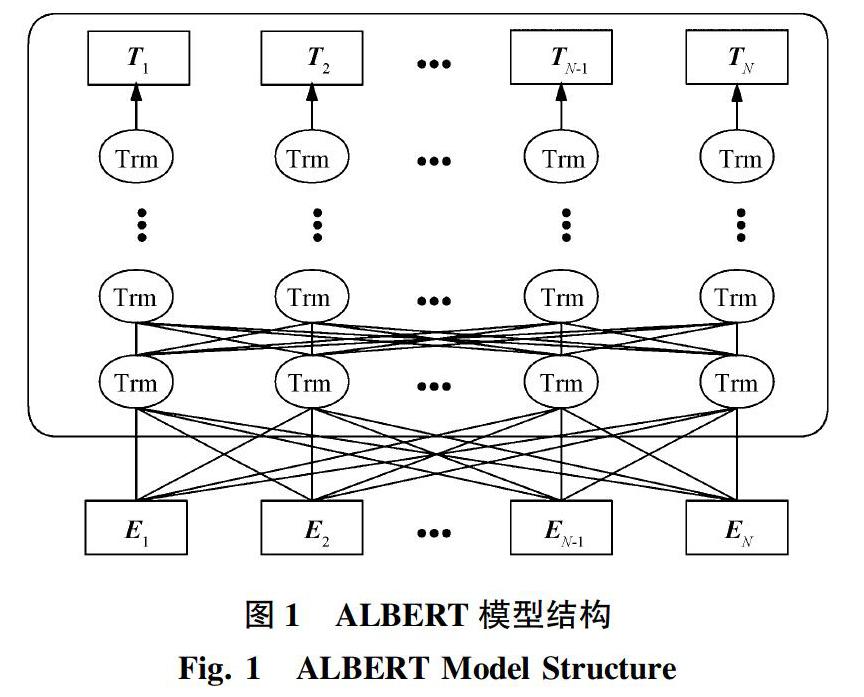
ALBERT层对文本处理的基本流程为:首先输入文本,变成序列文本E1,E2,…,EN,然后将序列文本输入到多层双向Transformer中进行训练;最终得到输入文本的特征向量表示T1,T2,…,TN。其中,Transformer编码器是一个包含了Encoder-Decoder结构的编码器,同时使用了多头自注意力层以便处理更长的序列信息,而ALBERT模型只保留了Encoder的部分。Encoder又包含多个相同网络层的叠加,Encoder的每一层网络包含着两个次级网络层:一层是多头自注意力机制层,另一层是前馈网络层,两层之间的特征传输使用了残差连接,而两层内部各自有着相同的处理数据输入输出的求和及归一化(Add&Norm)模块。ALBERT模型结构如图1所示。
相对于BERT预训练网络,ALBERT模型的网络参数较少,训练所需要的资源也少了很多,训练的时间大大缩短,主要因为ALBERT做出了两点比较独特的改进:一是ALBERT模型通过进行嵌入层参数因式分解和跨层参数共享等两个方面的改进,参数的数目得以大量减少,从而使得模型进行语义理解的速度得到了显著的提升。二是针对BERT模型中的NSP任务存在的弊端[17-18],ALBERT模型提出了使用SOP任务取代NSP任务,使得多句子输入的下游任务效果得到提升[6]。
序列文本经过ALBERT层处理后,得到对应的特征向量表示后,还要输入到下级的BiGRU神经网络层进行进一步的处理。
1.2 双向GRU
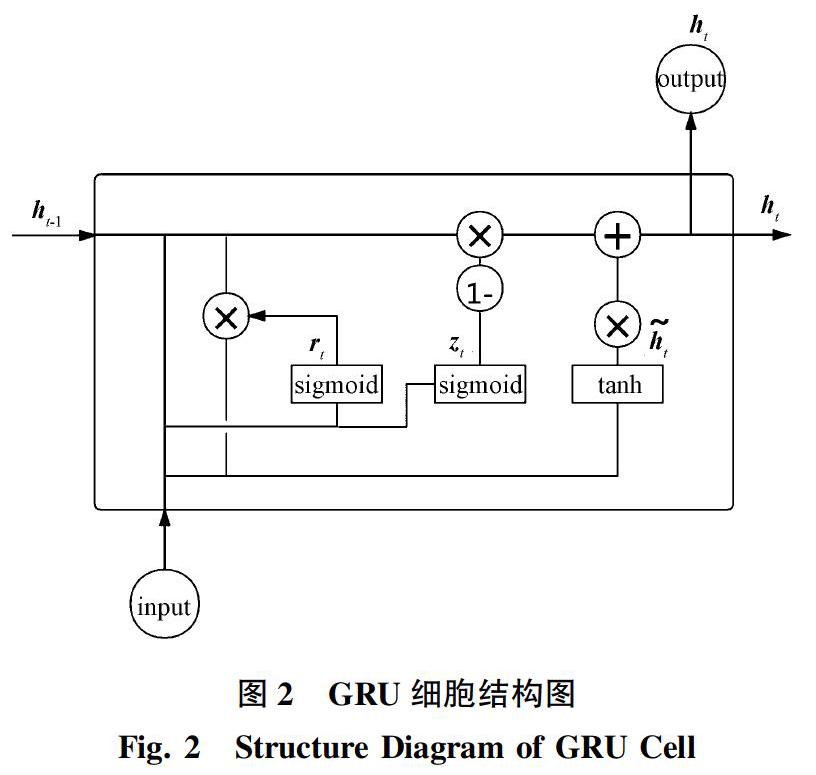
在需要关注词语上下文关系的时候,通常使用LSTM进行特征向量的处理,使得语料特征能根据所在特定语境产生动态的变化。LSTM模型包含了3个门控模块的计算,分别为输入门、输出门和遗忘门。GRU和LSTM模型同属于对RNN的改进,但是GRU在LSTM的基础上,进行了模型的简化,设计为只包含重置门和更新门两个门控单元的结构。重置门主要决定对于上一个状态信息的丢弃比例,重置门值越小,表示丢弃越多;更新门主要决定要将多少过去的特征传递到目前状态,更新门值越大,表示传递越多。如果将重置门设定为1,更新门设置为0,则GRU模型就退化为传统的RNN模型。重置门与更新门的结构设计使得GRU[19-20]相对于LSTM的参数更少而且收敛速度更快,并同樣有效地解决了模型训练过程中梯度爆炸和梯度消失的问题。GRU细胞结构如图2所示,其中rt代表重置门,zt代表更新门,ht-1和ht分别表示前一时刻隐藏层状态和当前时刻隐藏层状态。
在使用单向的GRU时,状态的传输只是简单的从前向后单向传播,使得重要信息容易丢失,可能出现最能包含整句话信息的特征向量得不到充分使用的问题。在这种情况下,可以考虑使用双向的GRU结构,双向的GRU结构让网络不仅能从前向传播中获得信息,更能反向地利用信息,使得更多重要特征得到充分使用,网络提取到的特征也更为丰富[21]。
1.3 注意力机制
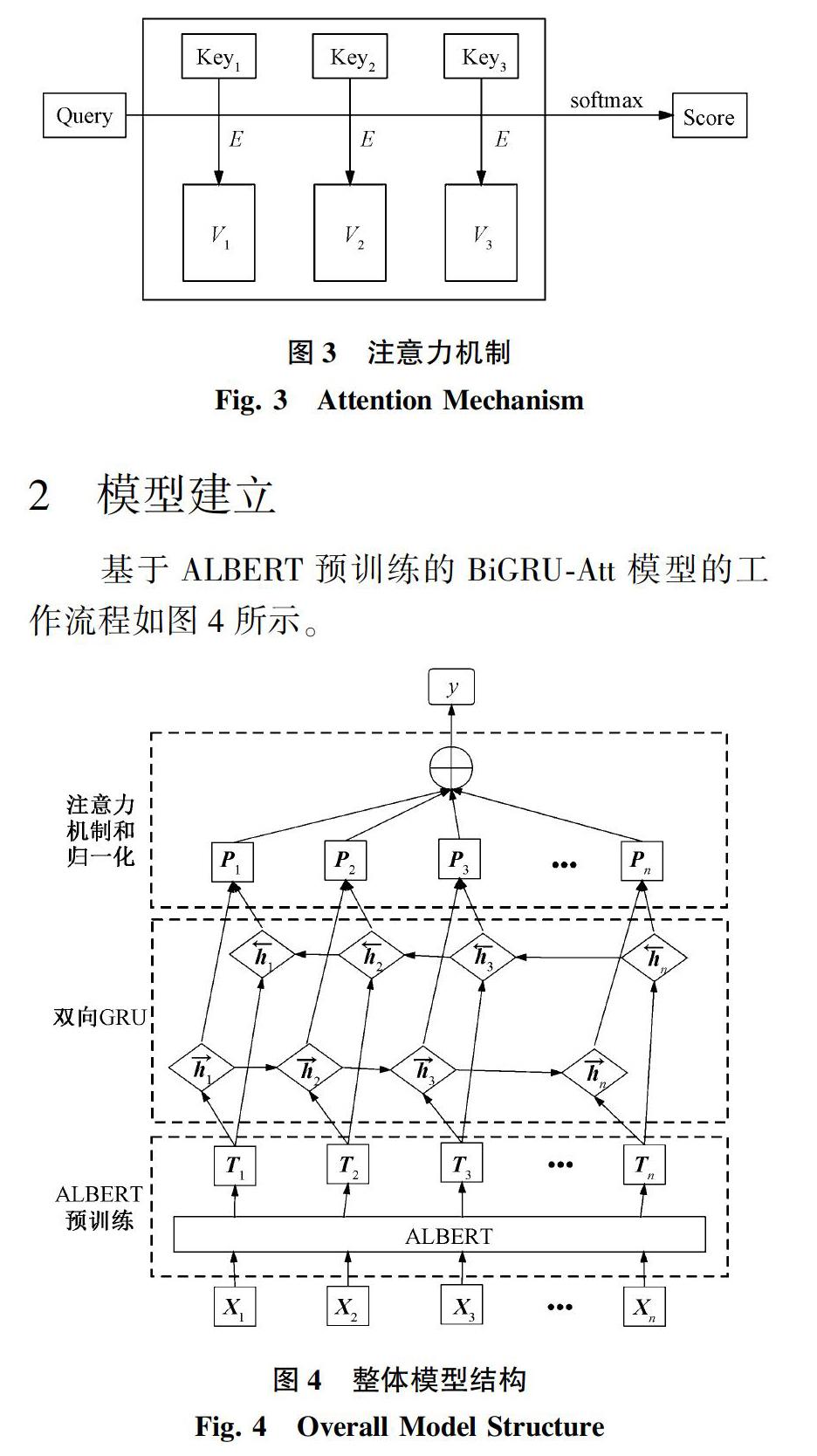
注意力机制(Attention Mechanism,ATT)如图3所示,注意力机制本质上还是一个编码器到解码器的结构,表现为序列到序列的处理方式,模仿了人脑在处理大量信息时,忽略不必要细节、只聚焦于处理关键细节的人脑思维方式。这种方式可以有效避免由于GRU网络输出层直接连接全连接层造成的特征信息浪费,使得模型对于重要局部信息的捕捉能力得到提升,从而提高模型判断的准确率。具体计算过程大概可以分为3个阶段:首先是在词嵌入特征向量经过BiGRU处理后,根据Query和对应的Key值计算两者的相关性,其中E为能量函数,负责计算当前Query与序列特征的相关度;然后使用softmax函数进行数字转换,实现数值归一化,同时softmax函数的内在机制使得更重要的特征得到凸显,即对应的权重值也更高;最后,根据权重系数对value进行加权求和,得到注意力数值Score。
2 模型建立
基于ALBERT预训练的BiGRU-Att模型的工作流程如图4所示。
1)ALBERT预训练层:文本数据经过预处理后,输入到ALBERT层进行文本数据的向量化。ALBERT层可以很好地捕捉到词语所在位置与前后词语之间的联系,会根据同一个词在不同的语境体现出不同含义的情况,生成对应的动态词向量。为了减少计算资源的消耗,这一层使用了tiny版本的ALBERT预训练模型进行文本内容的向量化。
2)双向GRU层:将经过ALBERT层向量化所获得的动态词向量,分别输入到前向传递GRU层和后向传递GRU层中,且由GRU层中的更新门控制保留前一时刻特征信息的比例,由GRU层的重置门决定忽略前一时刻特征信息的比例,对输入的文本特征进行训练。其中,每一个前向传递GRU层和对应的后向传递GRU层组成一个BiGRU单元,网络中包含多个BiGRU单元,BiGRU单元的更新公式如式(1)所示:
ht=WFthFt+WBthBt+bt。(1)
其中,WFt表示前向(Forward)传递时的权重矩阵,WBt表示反向(Backward)传递时的权重矩阵,bt为偏置量,通过前后传递的GRU对特征信息进行叠加,使得最重要的特征得到了最大限度的保留。
3)注意力机制和归一化层:将经过双向GRU训练后得出的特征向量作为Attention层的输入,对特征向量进行加权操作后,再将从Attention层获取的语义向量输入到Dense层,最终实现多标签文本分类。
4)验证:输入待预测的语句,通过模型判断出事件的类别标签。
3 实验结果与分析
选取谷歌的Colab平台进行实验,使用Python 3.6进行编程,深度学习框架版本为Tensorflow 1.15.0。实验使用的数据集为百度发布的中文事件抽取数据集,包含65个事件类型的具有事件信息的句子,每个句子对应一个或者多个事件类型。从中抽取13 456条新闻数据,且将句子顺序打乱,重新进行随机混合编排分布,按照8∶2的比例划分,使用10 764个样本作为训练集、2 692个样本作为测试集进行实验。
设置BiGRU-Att、BiLSTM-Att、LSTM-Att、BiGRU、BiLSTM、LSTM等共6个模型,模型中均使用tiny版本的ALBERT预训练模型进行编码,除BiGRU-Att外,其他5个模型作为对照组进行实验,迭代训练20次。其中,tiny版本的ALBERT模型的参数为:隐藏层尺寸为768,隐藏层层数为12,注意力头数为12个,使用ReLU激活函数的变种——GELU作为模型激活函数;BiGRU的参数为:隐藏层尺寸为128,网络层数为1,使用ReLU激活函数,将Dropout系数设置为0.2;输出层的激活函数为softmax,将多分类交叉熵作为损失函数。
从表1中的數据可以看出,所有模型在迭代20次以后,无论是否加入注意力机制,基于BiGRU的模型性能都优于基于BiLSTM和单向LSTM的模型;当模型都被加入注意力机制时,相较于无注意力机制的网络,性能均会得到相应的提升。另外,当LSTM网络加入注意力机制形成LSTM-Att模型时,会和无注意力机制的BiGRU模型有着相似的性能,两者在训练集和测试集上的准确度都十分接近。
由表1中的数据可以对比发现,基于BiGRU-Att的模型取得了最好的效果,在训练集的准确率达到了99.68%,损失值为0.0111,相对于无注意力机制的LSTM和加入注意力机制的BiLSTM-Att模型,准确率分别提升了4.37%和1.56%;其在测试集的准确率达到了99.64%,损失值为0.0117,相对于无注意力机制的LSTM和加入注意力机制的BiLSTM-Att模型,准确率分别提升了4.34%和1.37%。双向GRU网络的使用和注意力机制的加入,使得BiGRU-Att模型在训练集和测试集的表现均优于其他对比模型,证明双向GRU网络能够规避梯度爆炸和梯度消失的问题,同时还能在网络前向和后向传播中使重要的特征信息更好地保留下来,注意力机制也使得分类过程中重要特征信息的权重得到了提升,从而提高了分类的准确性。
使用训练好的模型进行文本分类验证,从表2可以看出,模型对于单标签或者多标签的文本内容均能正确识别其类别。
4 结束语
目前,我们处于互联网技术不断发展的时代,各种平台里的文本信息数据量十分巨大,在存储这些信息之前,给信息分门别类地打上标签是十分必要的。本文提出一种基于ALBERT获取文本对应的动态词向量,且结合双向GRU网络加入注意力机制的BiGRU-Att模型。相对于以往的模型,该模型使用了预训练ALBERT模型进行词向量的获取,在数据集较小的情况下使得词向量表达的语义特征更强;双向GRU网络使信息在模型中进行了前向和后向传播,能够保留聚焦词附近上下文之间的语义特征关联;注意力机制把不重要的语义信息进行了隔离,将注意力放在最重要的特征上,提升了分类效果。实验表明,结合双向GRU网络和注意力机制的模型表现最优,其性能与对比模型相比有着明显的提升,最后通过输入待预测语句验证实验结果,说明模型能较好地完成多标签文本分类任务。
[参考文献]
[1] KIM Y. Convolutional neural networks for sentence classification [Z/OL]. (2014-09-03) [2021-05-13]. https://arxiv.org/pdf/1408.5882v2.pdf.
[2] LAI S W, XU L H, LIU K, et al. Recurrent convolutional neural networks for text classification[Z/OL]. (2015-02-19) [2021-05-13]. https://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/view/9745/9552.
[3] LIU P, QIU X, HUANG X. Recurrent neural network for text classification with multi-task learning[C]//Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence. New York: IJCAI Inc, 2016: 2873-2879.
[4] ZHANG M L, ZHOU Z H. Multilabel neural networks with applications to functional genomics and text categorization[J]. IEEE Transactions on Knowledge and Data Engineering, 2006, 18(10): 1338-1351.
[5] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space [Z/OL]. (2013-09-07) [2021-05-13]. https://arxiv.org/pdf/1301.3781.
[6] LAN Z Z, CHEN M D, GOODMAN S, et al. ALBERT: a lite BERT for self-supervised learning of language representations[Z/OL]. (2020-02-09) [2021-05-13]. https://arxiv.org/pdf/1909.11942v6.
[7] CHOI H, KIM J, JOE S, et al. Evaluation of BERT and ALBERT sentence embedding performance on downstream NLP tasks[C]//2020 25th International Conference on Pattern Recognition (ICPR). Milan: IEEE Computer Society, 2021: 5482-5487.
[8] 余同瑞,金冉,韩晓臻,等.自然语言处理预训练模型的研究综述[J].计算机工程与应用,2020,56(23):12-22.
[9] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780.
[10] CHALKIDIS I, FERGADIOTIS M, MALAKASIOTIS P, et al. Extreme multi-label legal text classification: a case study in EU legislation[C]//Proceedings of the 17th Natural Legal Language Processing Workshop 2019. Minnesota: NAACL HLT, 2019: 78-87.
[11] CHALKIDIS I, FERGADIOTIS M, MALAKASIOTIS P, et al. Large-scale multi-label text classification on EU legislation[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Florence: ACL, 2019: 6314-6322.
[12] 刘心惠,陈文实,周爱,等.基于联合模型的多标签文本分类研究[J].计算机工程与应用,2020,56(14):111-117.
[13] 温超东,曾诚,任俊伟,等.结合ALBERT和双向门控循环单元的专利文本分类[J].计算机应用,2021,41(2):407-412.
[14] KITADA S, IYATOMI H. Attention meets perturbations: robust and interpretable attention with adversarial training [Z/OL]. (2020-09-25) [2021-05-13].https://arxiv.org/pdf/2009.12064v1.
[15] KITADA S, IYATOMI H. Making attention mechanisms more robust and interpretable with virtual adversarial training for semi-supervised text classification [Z/OL]. (2021-04-18) [2021-05-13]. https://arxiv.org/pdf/2104.08763v1.
[16] LU H, MAO Y, NAYAK A. On the dynamics of training attention models[Z/OL]. (2021-03-19) [2021-05-13]. https://arxiv.org/pdf/2011.10036v2.
[17] LIU Y, OTT M, GOYAL N, et al. RoBERTa: a robustly optimized BERT pretraining approach[Z/OL]. (2019-07-26) [2021-05-13]. https://arxiv.org/pdf/1907.11692.
[18] JOSHI M, CHEN D, LIU Y, et al. Spanbert: improving pre-training by representing and predicting spans[J]. Transactions of the Association for Computational Linguistics, 2020(8): 64-77.
[19] DEY R, SALEM F M. Gate-variants of gated recurrent unit (GRU) neural networks[C]//2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS). Massachusetts: IEEE, 2017: 1597-1600.
[20] 方炯焜,陳平华,廖文雄.结合GloVe和GRU的文本分类模型[J].计算机工程与应用,2020,56(20):98-103.
[21] DENG J F, CHENG L L, WANG Z W. Self-attention-based BiGRU and capsule network for named entity recognition[Z/OL]. (2020-01-30) [2021-05-13]. https://arxiv.org/pdf/2002.00735v1.pdf.
(责任编辑 白丽媛)
