人工智能辅助能力测量:写作自动化评分研究的核心问题
2021-08-23杨丽萍辛涛
杨丽萍 辛涛
摘要:写作自动化评分是目前智慧教育方兴未艾的研究领域,为缓解人工作文评分中存在的经济与时间成本等巨大压力提供了更加量化、及时和稳健的方案。然而,当前写作自动化评分模型大多是以特征值作为预测变量,拟合人工评分的分数预测模型。为了使写作自动化评分与提高学生写作能力的最终目标相匹配,写作自动化评分体系的建构需从能力测量视角出发,厘清测量范畴,突破写作自动化评分向能力测量转向的技术瓶颈。其中,需要解决的核心科学问题包括:(1)如何以写作评价标准为依据,建立具备解释性的特征体系,解决自动化评分与评价标准脱钩的问题;(2)如何突破拟合人工评分的局限,从分数预测模型拓展到能力测量模型,探索写作各能力维度的评估模型;(3)如何在实际应用中,在保证评分准确性的基础上,系统化论证写作自动化评分的信度与效度,强调跨子群体的公平性。为探索写作自动化评分的有效建构与使用的合理路径,今后的研究可以从自动化评分与人工评分的结合应用、写作自动化评分的稳定性和泛化性的检验、写作能力发展的持续性以及测验成绩的可比性等方面推进。
关键词:写作自动化评分;能力测量;特征体系;评估模型;信度与效度
中图分类号:G434 文献标识码:A 文章编号:1009-5195(2021)04-0051-12 doi10.3969/j.issn.1009-5195.2021.04.006
基金项目:国家自然科学基金联合基金重点支持项目“基于‘天河二号超级计算机的教育系统化监控评估、智能决策仿真与应用研究”(U1911201);国家自然科学基金面上项目“中文写作能力及其发展的自动化诊断研究”(32071093)。
作者简介:杨丽萍,博士后,北京师范大学中国基础教育质量监测协同创新中心(北京 100875);辛涛(通讯作者),博士,教授,博士生导师,北京师范大学中国基础教育质量监测协同创新中心(北京 100875)。
一、引言
写作是运用书面语言文字进行表达和交流思想感情的重要方式,是一种具有高度综合性和创造性的言语能力。作文是评估学生写作能力的重要载体。写作自动化评分(Automated Essay Scoring,AES )指采用计算机程序对作文进行智能评分,最初目的是缓解人工评分的压力。Page教授团队于上世纪60年代开发了第一个写作自动化评分系统PEG(Project Essay Grade)(Page,1966)。20世纪90年代以后,IEA(Intelligent Essay Assessor) (Landauer et al.,1998)、IntelliMetric(Elliot,2001)等写作自动化评分系统相继出现,并应用于各类大型考试中。例如,美国教育考试服务中心(Educational Testing Service,ETS)开发的电子评分员(Electronic Essay Rater,简称e-rater) (Burstein et al.,1998)被用于美国大学入学考试(American College Testing, ACT)、研究生入学考试 (Graduate Record Examination, GRE)、学术能力评估测试(Scholastic Assessment Test, SAT)、国际交流英语考试(Test of English for International Communication, TOEIC)、培生学术英语考试 (Pearson Test of English,PTE)、面向母语非英语者的英语能力考试(Test of English as a Foreign Language,TOEFL)和经企管理研究生入学考试(Graduate Management Admissions Test,GMAT) 等。在国内,梁茂成等(2007) 开发了面向英语二语学习者的作文评分系统;彭恒利(2019)基于哈尔滨工业大学刘挺教授团队对中文写作自动化评分关键技术的研究,对“中国少数民族汉语水平等级考试”和“普通高等学校招生全国统一考试”的作文进行了写作自动化评分与人工评分的对比研究。此外,一些写作自动化评分系统,例如,MY Access!TM(Elliot et al.,2004)、批改网(石晓玲,2012)等也被应用于低风险测验和课堂学习过程中,最终目标是帮助学生提高写作能力(Shermis et al., 2013)。
尽管人工智能与信息技术在写作评分中的积极作用得到了广泛认可,但在实践中,尤其是在高利害考试中迫于自动化评分解释性与有效性备受质疑,关于自动化评分体系测量的实质与合理性愈加成为学界关注的话题(Deane,2013; Attali,2015;Mayfield et al.,2020)。消除质疑首先要回答的问题是:写作自动化评分究竟测量的是什么?虽然到目前为止学界就该问题的答案并未能达成共识,但是对AES的测量范畴,即构念效度的评估是不可忽视的(Rupp,2018)。一方面,虽然有研究者对目前AES的特征与写作构念之间的关系进行了歸纳(Chen et al., 2018),但囿于各学科研究的价值取向差异,目前AES的建构往往以取得较高的分数预测准确率为原则,或直接将写作评价转化为文本分类任务,难以清晰地反映作文评价标准与特征体系之间的关系,这使我们进一步有效评价写作能力结构与能力发展受阻。另一方面,由于人工评分存在的各种问题,例如,趋中效应、评分环境与评分员对评分标准的理解差异等,人工评分本身的信度长久以来也备受质疑(赵海燕等, 2018)。在此背景下,人工评分是否可以作为AES建构与检验的完美效标是值得商榷的(Wolfe et al.,2018)。自从第一个AES系统提出以来,自动化评分在预测作文分数方面取得了巨大的进展,但是研究对象与研究目的比较单一,研究结果零散,缺乏在能力测量框架下对写作评价标准、特征体系与分数预测建模的系统性研究。写作自动化评分到底测量了写作能力的哪些部分、AES建构的原则与依据是什么、在特征体系的构造与评分模型构建中有哪些关键技术亟待突破、能否实现有效且公平的测量等重要问题值得深入探讨。
写作自动化评分发展与应用的瓶颈催生研究理念与研究框架的创新。随着心理测量学、自然语言处理(Natural Language Processing,NLP)和人工智能技术等跨学科研究合作的不断深化,写作自动化评分从评价表层文本质量拓展到测量写作能力迎来了新的发展契机。写作自动化评分应当以帮助学生提高写作能力为最终目标,将人工智能新技术融入对学生写作能力测量的完整教育评价框架中。自动化评分应明确写作能力测量的范畴,既要实现对文本质量的分数预测,也要通过能力诊断推动写作进阶;评分特征既要对分数预测有贡献,也要厘清其所涵盖的写作能力维度;评分结果既要保持与人工评分的一致性,也要避免人工评分中的偏误,保證评分的公平性。本文基于写作能力评价视角,从理论和实践层面提出写作自动化评分研究的新框架,以促进写作自动化评分范式的改进,推动写作自动化评分向深层写作能力诊断转变,保证在大规模与多元化情境下科学合理地开展写作自动化评分。
二、写作能力测量视角下AES的研究框架
1.AES测量的是什么
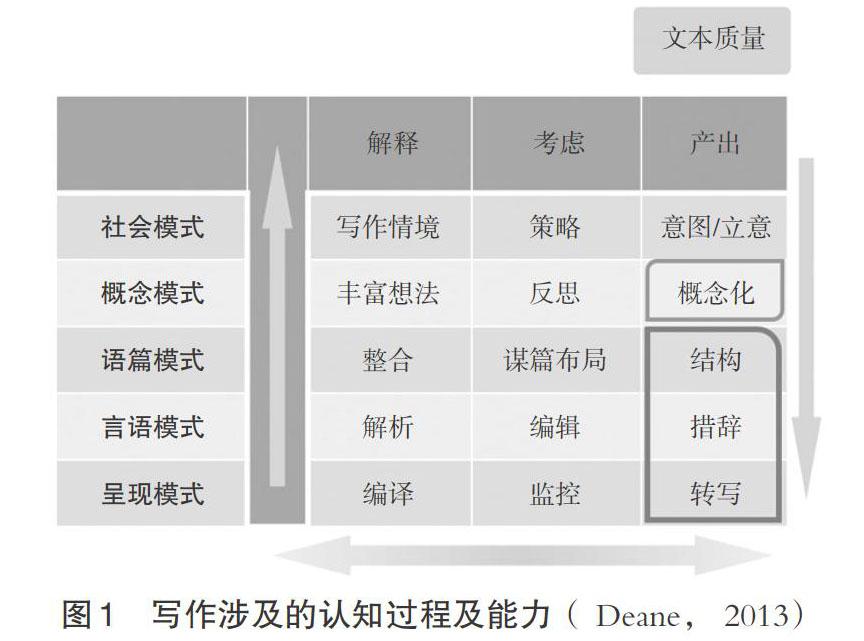
写作能力是学生在长期学习过程中形成的一种相对固化的潜在能力,涉及不同层面的复杂认知过程和认知成分(Deane,2013)。图1展示了写作过程涉及的多种认知能力。纵轴标签为个体在写作过程中需要处理的不同模式层面,从底层的语言层面(呈现、言语和语篇模式),上升到写作背后隐含的想法层面(概念模式),这其中蕴含着作者在特定写作情境下对社会现实的理解、合理化处理以及期望与读者交流的意图(社会模式)。横向标签是写作过程中涉及的个体内隐的认知行为,包括解释、考虑与产出。个体必须在写作情境下形成自己的解释体系,斟酌合理的写作策略,运用语言知识谋篇布局、选择体裁,最后利用熟悉的语言形式产出作品。每个单元代表一种认知能力元素,这些元素形成了一个单独的连通的整体,即我们通常所说的写作能力。个体在写作过程中需要激活并协调这些能力元素。因此,合理的写作评价应尽可能的覆盖这些元素,而不是将其中一个或几个单独分离的元素作为写作能力的替代。目前,现有的AES对学生在“概念模式”与“社会模式”层次的写作认知过程测量很少,并且大多集中在写作产出的言语或语篇层面(例如e-rater、 IntelliMetric、MY Access!TM等)。
基于情境的大数据时代可以利用的信息越来越多元,将文本质量评价结果与其他来源的证据(例如,眼动、log日志、光标与击键记录等过程性数据)相结合已是大势所趋(Sinharay et al.,2019;Zhang et al.,2019),甚至人工评分也可以作为写作能力证据的一部分。在确认想要评估的写作能力范畴之后,需要更加细致的模型来测量写作能力,而这些模型建构的目标甚至超越以人工评分为拟合对象的预测准确率。Yang等(2020)将作文映射为语义空间下的概念图,对作文主旨观点表现水平进行自动化评分,是作文评分从“语篇模式”层次拓展到“概念模式”层次的初步探索。随着多情境大数据、在线学习、信息技术环境在教育评价的应用日趋成熟,写作自动化评分的研究范式应从“文本证据”与“拟合评分”向“多元证据”与“能力诊断”逐渐转变。
2.AES建构的依据、原则与过程
传统的AES以文本质量为主要证据来源,教育和学科专家提出的 “作文评分规则”是目前AES建构的主要依据。评分规则反映了作文质量要评价的方面,描述了从哪些方面分几个等级对作文进行评分以及每个等级作文质量的详细说明。目前应用最广泛的是美国教育学家提出的“六要素评分模型”(Six-Trait Scoring Model)(Spandel et al.,1980),列举了“优秀作文”要具备的6个要素,包括想法(Ideas)、内容 (Content)、语气(Voice)、组织(Organization)、措词(Word Choice)、句子流畅性(Sentence Fluency)和语言规范性(Convention),后来又增加了“呈现”(Presentation)要素,下文简称为“6+1模型”。该模型在美国、英国、法国等欧美国家应用广泛,GRE和托福考试写作部分的评分规则也是基于这一模型发展而来。王鹤琰(2016)、刘悦( 2018)对“6+1模型”进行了本土化的改编,但是中西方写作评价标准存在不小的差异(王彦芳, 2015)。英语作文的写作逻辑起点是“交际”,强调作文的逻辑性与流畅性;中文的作文评价更强调作者主观意见表达,需要审题与立意,“中心思想”往往是中文作文最重要的评价属性(魏小娜, 2009)。因此,面向中文写作的自动化评分也应避免完全复制面向英文的AES建构方法。
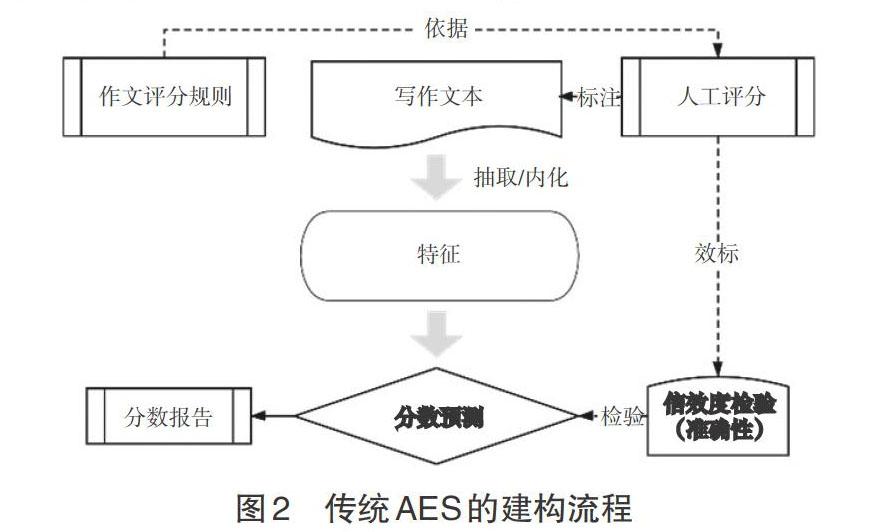
以往的AES研究范式是以追求与人工评分的最大一致性为原则来寻找文本特征的最佳组合方案,如图 2。基于统计拟合的方法训练模型,意味着在同一个测验下,AES对每个题目的评分标准可能并不相同。这一方面造成AES的特征方案并不稳定,评分内部一致性受到质疑;另一方面,随着分类模型的复杂度增加,模型的概化性与解释性变弱。更重要的是,对特征效度的忽视偏离了写作能力测量的本质,难以进一步刻画学生写作能力的发展状况。
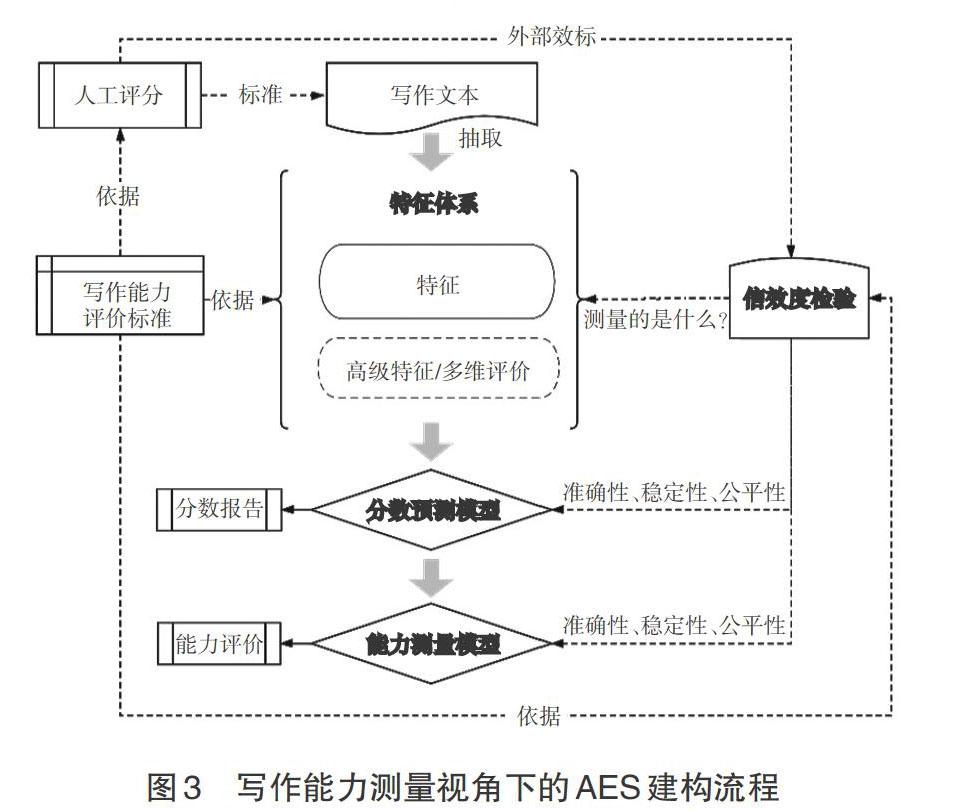
上述问题的背后是写作自动化评价的研究视角与研究范式的局限。当研究视角转移到能力评价而不是分数预测时,写作自动化评分不再是一个封闭的评分系统,而需要通过科学的能力测量设计实现自动化评分的迭代与升级。基于写作能力测量的自动化评分体系建构的基本思路是要厘清写作能力的范畴,依据写作能力评价标准策划特征体系的建构途径,进而建立可持续测量写作能力的模型。
在写作能力测量视角下,写作自动化评分构建的依据应当从“作文评分规则”转化为“写作能力评价标准”。写作能力标准应将写作能力定义为能力测量框架下可以评估的结构。科学的AES设计原则应以写作能力评价标准为起点,在保证自动化评分与人工评分一致性的基础上,厘清AES测量了写作的哪些方面,并且对自动化评分的信度与效度进行全面检验,见图 3。基于该原则, AES的研究框架与研究范式的突破应包括以下三个核心问题:第一,如何建立具备解释性的特征体系,解决自动化评分与评价标准脱钩的问题;第二,如何突破拟合人工评分的局限,从分数预测模型拓展到能力测量模型;第三,如何超越检验自动化评分的准确性,系统地论证自动化评分的信度与效度,保证评分的公平性。下文,笔者将尝试对研究转向中的上述三个核心研究问题进行梳理和论述。
三、如何建构可解释性的特征体系
计算机并不能像人一样来理解文章。传统AES是从写作文本中抽取特征来近似计算作文质量。采用计算语言特征预测作文总分(或某个特定评分维度分数)的过程是透明且灵活的,相较于人工评分策略的内隐性,基于稳定的计算语言的特征体系能更好地控制要评价的构念 (Construct) (Bennett et al.,1998)。在一个AES系统中,特征之间建立起的组合与层级关系被称为AES的特征体系,决定了AES对写作能力测量的范围与程度。
1.特征体系的类型
从教育测量的观点出发,对于同一个写作评估项目,AES的建构应基于相同的作文评价标准并采用稳定的特征体系,生成具有相近测量意义的分数。特征设计与想要测量的技能具有清晰的结构关系。当以文本质量为主要证据来源时,以“6+1模型”的建构依据为例,图4是一个理想特征体系(Deane,2013)。然而,即使是在文本质量评价层面,传统AES中的特征大多根据与人工评分的统计拟合确定,这导致特征体系并不稳定。当我们需要提高模型的稳定性与效度时,如何以评价标准为依据来构建稳定的自动化评分标准特征体系就显得格外重要。大多数写作自动化评分系统与作文评分规则的关联尚欠缺研究的证据支持,特征体系与评价标准相对分离。目前AES的评价内容大都集中在作文的语言规范、语法特征、语言结构和流畅性等语言形式层面。Crossley(2020)对于目前经常使用的特征与作文质量之间的关系进行了详细阐述。虽然一些AES能够提供语义层面的分析,但往往由于语义粒度过细(如词语搭配错误)或过粗(如整篇文章词语使用的相似度),难以捕捉作文的深层特质,也就无法向使用者提供更有利于改进写作能力的写作策略或技巧的反馈(McNamara,2015)。
根据特征体系的内部结构,本文将目前常见的计算语言特征体系概括为三种类型:无结构型、结构型和基于深度学习的内隐型,如图 5所示。无结构型的特征体系中,原始计算语言特征被作为预测变量直接进入分数预测模型,这种方式在AES中最为常见(陈一乐,2016;Zhao et al.,2017;莫慕贞,2018)。其存在的问题是:(1)某个特征可能在一个方案中很重要,而在另一个方案中并不存在,甚至是负向的,这些差异会对AES的效度造成威胁;(2)容易导致对某个单独特征的依赖,例如在对作文中心思想或内容进行打分时,我们并不希望过多依赖于“字数”这个特征来判断作文的质量,虽然作文的长度与分数之间通常存在高相关,但它与要测量的属性可能相关也可能完全无关 (Deane,2013)。鉴于无结构型特征体系的缺陷,研究者尝试对某些相似意义的特征进行组合,找到直接影响作文质量或写作某一属性表现水平的“高级特征”,同时构建出原始特征与高级特征之间的层级关系,形成结构型特征体系。例如,e-rater(V.2.0)是典型的结构型特征体系(Attali et al.,2005),与e-rater (V.1.0) (Burstein et al.,1998)相比,最大的区别是使用了一组少量但有直观测量意义的高级特征来预测作文分数。近年来,一些深度学习模型被直接用于AES领域以实现端到端的自动化评分。这类模型通常以文本为输入,特征抽取过程完全内化,经过多次复杂变换后直接输出作文分数或分类,形成基于深度学习的内隐型特征体系(Nadeem et al.,2019; Mayfield et al.,2020)。这类端到端 (End-to-End)模型虽然在一些任务中能取得较高的与人工评分的一致率(Mayfield et al.,2020),但评分过程与分数意义难以解释与检验。目前采用深度学习模型对作文进行端到端的自动化评分的实际应用非常少,研究也未形成延续性。
基于上述分析,无论从计算语言特征体系对写作能力的覆盖程度来看,还是从特征体系的稳定性来看,结构型特征体系都更适合发展出理想的特征体系。高级特征与评分标准中的属性联系更加紧密,有利于降低由于个别原始特征变化造成预测分数波动的可能,增强AES的稳定性。在实际运用中,结构型特征体系更适合于原始文本特征、高级特征以及写作属性之间的关系容易辨识的情况,例如“某个语言错误—语法错误—语言规范性”的关系比“某原始文本特征—中心思想”的关系更容易确定,后者需要大量研究支持。
随着AES特征体系从作文语言表层特征向内容与思想等深层属性不断深化,特征与能力各潜在维度或潜在属性的关系结构更加复杂化。Chen等人(2018)总结了目前AES中采用的特征与写作能力的各方面(类似于高级特征)之间的关系,发现从作文文本中抽取的原始计算语言特征对作文质量的影响是间接的,且粒度较细,一般不具有明显的测量意义(例如“词语搭配错误”);一些原始计算语言特征经过加权组合计算得到的“高级特征”通常有较为明确的测量意义(例如“语法错误”),与写作潜在属性的对应关系也更加明确(例如“语法错误”对应“语言规范性”属性)。与容易受到写作任务影响的浅层语言特征相比,这些潜在属性能够始终如一的描述写作能力,揭示写作活动中个体的写作策略与心理特征。基于潜在属性对写作能力的评价是一种普适性的客观评价,是基于能力层面而非题目层面的通用评价(Attali et al.,2013)。
2.特征的构造方法
尽管大多数AES系统的细节并未公开,但从已发表的研究可以推断,AES颇受争议的一个重要原因是对作文质量的测量仍以语法和语义内容为主。目前最先进的AES系统或相关研究中,对语言规范、措辞等基于语言形式的测量较为成熟(Yoon et al.,2018),对流畅性、议论文的组织和结构有一定程度的测量(Limpo et al.,2017;Zupanc et al.,2017),对思想、立意、创新性等深层属性的测量还远远不够。
在语义方面,潜在语义分析(Latent Semantic Analysis,LSA) 和内容向量分析 (Content Vector Analysis,CVA)常被用来测量作文与高分作文的相似度(曹亦薇等,2007;Hao et al.,2014; Sakti et al.,2016)或识别作文是否“跑题”(Sakti et al.,2016;Liu,2017)。近年来有研究者采用开放信息抽取 (Open Information Extraction,OIE) 来判别作文中语义的关系信息 (Zupanc et al., 2017),能够比较准确地判断常识与语言逻辑的正误。广义潜在语义分析 (Generalized Latent Semantic Analysis,GLSA)、语义网络 (Semantic Networks,SN)、模糊逻辑 (Fuzzy Logic,FL) 和描述逻辑 (Description Logic,DL) 等分析技术也被用来拓展作文中语义分析的结果 (Xu et al.,2017)。在主题研究中,潜在狄利克雷分布 (Latent Dirichlet Allocation,LDA)模型能够对文本的内容进行无监督聚类。作文内容的一致性与连贯性一般通过相邻句子或段落之间实体词的重叠或基于LSA或CVA语义相似度来计算(Shermis et al., 2013;Stab et al.,2014;Rahimi et al.,2015)。基于论证挖掘对议论文论点清晰度(Persing et al., 2013;Wachsmuth et al.,2016)、论证说服力(Persing et al.,2015;Wachsmuth et al.,2016)与作文的总分(Nguyen et al.,2018;Ke,2019)进行预测也是AES研究的热点。随着基于情境的大数据时代来临,研究者认为基于过程性数据挖掘(刘红云,2020)能得到更丰富的能力证据。近年来一种基于图的作文表征方法被用于写作评价中,通过将作文中出现的各种思想和概念表征为图结构,形象、直观地呈现出学生在写作过程中的語义认知结构 (Nafa et al., 2016;陈志鹏,2017;Zupanc et al., 2017;高京坚等,2018; Maharjan et al.,2019)。该方法还能够评估作者想法的发展(Somasundaran et al., 2016)。辛涛等(2020)将概念图的全局结构与Word2Vec的局部语义信息进行融合,构造了评价中文作文主旨观点与创新性的特征,表明基于复杂网络(Ke et al.,2016)或概念图(Maharjan et al., 2019)的特征能够有效地预测文本的整体质量。总的来说,现有研究中构造的特征较为零散,基于图的深层特性与写作能力之间的关系仍有待持续深入研究。
不可忽视的是,由于语言特性差异,在英文作文评价中占很大比重的基于语言形式的属性(例如,语言规范、语法等)对中文作文质量的影响较为有限。面向中文写作的自动化评分从最早基于字频与词频的统计特征 (张晋军等,2004)发展到识别作文中的修辞手法(巩捷甫,2016; 付瑞吉等,2018)和篇章主题(刘明杨,2015)等方面的特征。吴恩慈和田俊华(2019) 对汉语写作自动化评分中采用的关键自然语言处理技术与问题进行了详细回顾;彭恒利(2019)总结了国内自动化评分技术在高利害考试中应用的情况与问题。面向中文的AES特征构造方法应根据中文语言特性,探索能够捕捉中文写作能力水平差异的多元特征的构造途径与计算方法。
四、如何构建能力测量模型,突破拟合人工评分的局限
1.常见的分数预测模型与构建
目前AES评分模型大多是以特征值作为预测变量,拟合人工评分的分数预测模型。普遍的构建方法是将经过人工评分的作文分为训练集与测试集,在训练集上训练模型参数,获得特征的最优权重,接着在测试集上预测作文分数。这个过程中采用的统计方法和训练程序都影响着AES的实践应用效果。
基于构建好的特征体系,特征的权重计算可以由多种方式来实现,最简单的就是特征的加权平均,权重反映了特征对于分数预测的重要性。AES分数预测中最常见的统计模型是多元线性回归模型。多元线性回归是一种顺序量表,得到的连续分数能够反映作文质量的高低。国内针对大型考试的中文写作自动化评分研究也大多采用多元线性回归模型(陈一乐,2016)或经过优化的回归模型(Yao et al.,2019)。随机森林 (Radom Forest)、支持向量机 (Support Vector Machines) 等常见的机器学习模型也被应用于作文评分任务中来提高作文分类准确率。深度学习模型往往能够整合特征抽取与分数合成,输入文本后直接输出预测分数 (Zhao et al.,2017; Mayfield et al.,2020),准确率较高但解释性弱。
在分数预测模型的参数确定后,自动化评分不会随着时间变化而发生改变,即重测信度为1。这时应检验模型跨题目时特征权重的一致性与合理性。同一个测验下,在多个写作任务中表现不稳定或不合理的特征权重会导致难以控制和解释AES产出分数的意义。值得注意的是,由于计算机至少目前还不能真正模仿人工评分员在评分时的心理认知过程,基于各种数据驱动的统计方法获得的最优权重并不一定能反映评分员在评分过程中对作文特征的关注程度,因此,一些并不单一追求与人工评分一致性的特征权重赋值方法,例如专家事先标定、等权重、因素分析和信度最大化方法(Attali,2015)也会被用于非高利害考试或无事先标定分数的评分任务中。
在分数预测模型的建构中,训练集中的作文组成决定了AES可以合理地推广到哪些人群和写作任务上。训练集中的作文必须来自AES要使用的目标群体,根据训练集中作文组成来源可以将分数预测模型分为题目模型与通用模型。如果在同一测验中有多个不同版本的平行作文题目,那么,在评分的初期可以专门针对某个题目进行建模,抽取每个题目下500~2000篇作文构造特定题目的分数预测模型,这种模型称为“题目模型”。相对地,从全部题目下的作文中抽取样本构建的是“通用模型”。这时,同一个测验中的所有作文题目都统一采用通用模型进行评分,提高了评分内部一致性,生成的分数具有相对稳定的解释意义。Ramineni等(2013)认为“通用模型”增强了自动化评分的标准化程度与可接受性,但是,当有新的题目加入时,需要重新训练通用模型或对AES系统进行调整。
2.写作能力测量模型的构建与发展方向
随着心理测量與计算机等相关学科合作的不断深化,写作自动化评分的作用不应局限于评分上,而是要拓展到对学生的写作能力水平进行评估或诊断上。
(1)能力的整体评价与分项评价
目前中文写作评价中,单独评价写作能力某个特定方面的研究相对较少,大多数研究并未检验写作分数与写作能力之间的关系。大规模考试中,基于作文评分规则对作文打出总分,可看作是对写作能力的整体估计。在另一些情境下,专门针对写作能力的不同方面(例如,“中心思想”“创造性”等维度)制定评分标准并单独评分属于对写作能力的分项评价。比如,Zedelius等人 (2019)通过一些客观的计算语言特征来测量作文的创造性;徐建平等(2020)对学生写作中的发散思维进行了自动化评分;Yang等(2020)基于概念图的特征对中国8年级学生的作文主旨观点的组织水平进行了自动化评价研究。针对作文某个特定维度的自动化评分能够为学生改进写作指明方向,是写作评分发展的新趋势。
为了揭示写作能力的结构与发展,写作自动化评分应当对写作某个维度(或属性)的测量从基于语言形式的表层属性逐渐拓展到与写作认知过程联系更紧密的深层属性上,给学生提供更有价值的反馈。AES研究应注重写作能力各维度发展水平的测量,建构更加精细化和更具针对性的能力测量模型,提供潜在特质或属性的评分或反馈,帮助改进写作教学质量。
(2)写作能力测量模型的构建
当聚焦于测量写作能力的发展水平而不是作文文本之间的横向对比(例如,某篇作文是6 或8 年级水平,而不是3分还是6分)时,应当使AES估计的能力分数标定在一个跨题目的标准化写作发展量表(Standardized Writing Development Scales)上,这个量表上分数的高低应当反映学生写作能力水平,从而对学生写作能力进行可持续的测量与诊断。
写作能力测量模型构建的研究目前刚刚起步。Raquel等(2014)采用一套诊断性英语语言追踪系统评估一项大规模英语语言测验的写作部分,定期评估学生写作水平;莫慕贞(2018)采用多面Rasch模型得到校准后的人工评分,采用多元线性回归模型预测校准后的学生能力分数,回归模型的解释率R2为0.47;Uto等(2020)基于BERT预测IRT模型估计的学生写作能力值,R2为0.56。由于写作能力的发展在不同时期的进度并不相同,即使同为相差1分,在不同分数区间上所代表的写作能力的差异很有可能并不相同。例如学生从1分上升到2分要比从5分上升到6分容易得多。因此,能力测量模型应建立等距量表,基于特征体系建立能力分数的测量模型。这个过程有两个重要步骤:首先应当将不同评分员的打分标定在同一个能力量表上,从而减小人工评分的偏误;其次,采用合理的特征体系中得到的特征值来估计写作能力,建立能力测量模型。在这个能力量尺上,分数越高表明写作能力越高,并且可以与其他测验的能力分数进行链接。这方面的研究具有非常广阔的探索空间与应用潜力。
五、如何论证AES的信度与效度
教育测量界不断更新的信度与效度概念深深地影响着自动化测评工具的开发与应用。随着人工智能技术的快速更新与迭代,各种自动化测评工具的信效度也被赋予融合时代特色的新含义。对于写作自动化评分工具来说,信度与效度的论证应该包含一套完整的逻辑,仅仅呈现自动化评分与人工评分的相关是远远不够的,需要更充分的研究来论证自动化评分与学生写作能力之间的潜在关系,其意涵超越了对人工评分的复制,增强了自动化评分结果的合理性与解释性。Attali等人 (2013) 提出了基于作文质量评价的AES信度与效度评价框架,该框架将AES的评估从预测准确性拓展到对AES中所采用特征的检验、自动化评分与人工评分的关系、跨样本的稳定性以及AES与其他测验的关系四个方面,见图 6。基于写作能力测量与评价的视角,写作自动化评分体系中所采用的特征的意义、AES与人工评分的关系以及跨样本的稳定性是最重要的信效度问题,分别对应着AES的测量构念、AES的有效性与公平性,是影响AES推广与应用的关键问题。
1.特征的意义
作为对人工评分的补充或者替代,AES要能从建构原理上清楚地反映出是测量写作能力的哪些方面。因此,当AES中引入一个新特征时,一个基本问题就是要考虑特征的解释性。计算语言特征应呈现与我们预期相符的意义。
特征意义的证据应当来源于计算语言学等相关领域的基础研究,或来源于语言学和认知研究中对于经典文学作品的分析。例如,第二语言习得的研究中,研究者发现了测量连贯性、词汇和句法复杂性等多种计算语言特征( Jiang et al.,2019;解月,2020)。还有研究发现,TTR (Type-Token Ratio, 作文中相同的词和所有词的比例)指数反映了词汇的复杂性和多样性。特征之间的相关模式也为从原始文本特征合成高级特征的解释性提供了一定支持,因素分析也可以用于考查AES特征体系的内部结构。如Attali等(2009)对e-rater得到的作文特征分数进行了探索性因素分析,结果表明e-rater的特征覆盖了语言规范、语篇与措辞三个写作评价维度。需要指出的是,在一些情境下有用的特征不一定适合于所有作文评分的情境。例如,阅读可读性指数虽然能有效估计阅读难度,但是对预测作文评分的贡献就很小(Zupanc et al., 2017)。语言特征与作文分数的相关也能在一定程度上辨识出特征对评分的贡献,但需要同时考虑相关系数和偏相关系数,尤其是要将作文长度的影响纳入分析。例如,“平均句子长度的负对数”与人工评分的相关为0.16,但在控制了作文长度后,与人工评分的相关为 -0.01(Attali, 2015)。
2.AES与人工评分的关系
传统AES的准确性是通过自动化评分与人工评分的一致性来衡量。表 1呈现了目前AES需要满足的与人工评分一致性的基本要求(Ramineni et al.,2013)。需要注意的是:首先,该标准依赖于人工评分的质量。如果人工评分的内部相关小于0.70,则对AES的建构更加不利,人工评分的低信度会影响AES的准确性。其次,由于自动化评分往往表现出比人工评分更小的变异(Bridgeman et al.,2017),这暗示着自动化评分很可能与人工评分员对作文的考虑并不相同。在实践中应尽量保证自动化评分与人工评分者具有相同的变异度。
3.跨样本的稳定性
作为一种自动化评价工具,AES跨样本评分的稳定性以及对不同子群体的公平性风险不可忽视。例如,托福考试中,亚洲学生在“组织”上得分更高,语法和措辞得分较低,特征的相对权重方案将对不同种族群体的作文分数产生差异化的影响(Breyer et al., 2017; Kusner et al.,2017)。AES在不同子群体上评分准确性往往是有差异的(Attali et al., 2005;Bridgeman et al.,2012),这些差异可能会导致对某些子群体不公平(Ramineni et al.,2013)。在大规模高利害的考试中,尤其需要谨慎检验AES跨群体的评分稳定性。例如,使用“标准化的平均分差别”来衡量不同子群体之间的准确性的差别,如果差异超过0.10或0.15个标准差则被标记为可能存在公平性问题(Ramineni et al.,2013)。
AES信度與效度的研究应当是比开发自动化评分系统更长久且更重要的工作。在信息环境与人工智能的辅助下,AES信度与效度的论证可以考虑更丰富的数据与试验研究。例如,当写作自动化评分的分数与外部测验的相关相较人工评分与外部测验的相关呈现出明显不同的相关关系时(Attali,2015),意味着人工评分员和自动化评分系统评价的内容很可能存在较大差异,需要进一步分析差异来判断评分的合理性。
六、写作自动化评分的推进方向
令人鼓舞的是,当不以预测准确率为研究的方向时,在写作能力测量的视阈下,AES所采用的特征不仅能够为写作能力等相关研究提供客观量化的证据,同时也能为其他教育评价研究提供支持。AES从开发到使用并不是简单的一蹴而就,而是科学与实践在现实中互相促进与完善的长期过程。AES的研究同样需要遵循这样的推进路径,同时需要权衡科学创新性与实践滞后性的矛盾。为探索写作自动化评分的有效建构与使用的合理路径,今后的研究应注意:
第一,自动化评分与人工评分的结合应用。AES可以在人工评分的过程中对人工评分的质量进行监控,或者作为一个特别的维度分数,为人工评分提供一个稳定且量化的参考分数。
第二,写作自动化评分的稳定性和泛化性的检验。公平性一直是教育测量领域的重要概念,需要通过在不同写作任务与不同学生样本上的应用来完善与更新AES体系,为AES的使用提供更多的证据支持与合理的使用建议。
第三,写作能力发展的持续性研究。合理的写作能力测量模型能够为学生的写作能力以及潜在属性发展提供追踪研究的证据,揭示写作能力的发展规律与不同子群体的写作能力发展差异。
第四,测验成绩的可比性研究。当写作能力与写作题目参数被标定在同一量尺上时,通过题目参数的链接,能够进一步建立写作能力与其他语言能力(如阅读)之间的关系。在大规模考试中,常常因评分员的背景与培训差异导致对作文评分标准的把握不完全一致,而AES的优势在于,一旦建构好模型,它的评分结果不会随着时间或地点的改变而波动。在此基础上,能够进行一些大胆的探索。例如,当写作能力被标定在一个通用的写作能力发展量尺上时,利用特征体系中比较稳定的特征作为“锚”对人工评分的结果进行监督或者矫正,或当AES用于不同测验时,探索通过稳定的特征对不同的写作测验分数进行链接的可能性。
七、结语
在教育评价领域,随着人工智能在写作教学与评价中日益广泛的应用,写作自动化评分的建构途径与技术方法应当被纳入能力测量的科学框架。本研究对写作自动化评分测量的范畴和依据、特征体系与评分模型构建等重要问题进行阐述,有助于相关研究者在理解其研究价值的基础上开展有针对性的创新与应用。可以看出,由教育和测量学专家提出的写作能力评价标准是AES建构的依据,在保证自动化评分与人工评分一致性的基础上,以写作全过程中多元化数据为证据来源,AES的特征体系应最大程度地覆盖写作能力的范畴。需要指出的是,AES的研究重点应当逐渐从分数预测的准确性转向写作能力测量的合理性上。对于AES跨题目的信度、跨群体的稳定性以及由此产生的公平性等问题需要基于真实数据的大量研究与检验。作为大规模考试中写作自动化评分体系建构项目的参与者,笔者深刻感受到,当前的写作自动化评分距离“写作能力自动评价”的目标仍有较大差距,该领域的研究仍处于探索阶段,存在储多挑战。面向未来的大数据情境,AES的研究应重视计算机技术与教育测量研究的融合,同时注重与写作能力发展等相关研究的相互促进与支持整合。
参考文献:
[1]曹亦薇,杨晨(2007).使用潜语义分析的汉语作文自动评分研究[J].考试研究, (1):63-71.
[2]陈一乐(2016).基于回归分析的中文作文自动评分技术研究 [D].哈尔滨:哈尔滨工业大学.
[3]陈志鹏(2017).基于词分布的文本表示研究 [D].苏州:苏州大学.
[4]付瑞吉,王栋,王士进(2018).面向作文自动评分的优美句识别[J].中文信息学报, 32(6):88-97.
[5]高京坚,张文彦,张凯(2018).句法谓词的主题表现力研究[J].语言文字应用,(1):71-80.
[6]巩捷甫(2016).面向语文作文自动评阅的修辞手法识别系统的设计与实现[D].哈尔滨:哈尔滨工业大学.
[7]梁茂成,文秋芳(2007).国外作文自动评分系统评述及启示[J].外语电化教学,(5):18-24.
[8]刘红云(2020).基于过程数据的合作问题解决能力测量模型的构建[Z]. 2020全球人工智能与教育大数据大会(北京).
[9]刘明杨(2015).高考作文自动评分关键技术研究[D].哈尔滨:哈尔滨工业大学.
[10]刘悦(2018).作文诊断量表的启示研究[J].课程教育研究,(15):181-182.
[11]莫慕贞(2018).中文作文自动评分研究[Z].第十三届海峡两岸心理与教育测验学术研讨会(台北).
[12]彭恒利(2019).计算机自动评分技术在高利害考试中应用的前景分析[J].内蒙古教育,(2):4-6,28.
[13]石晓玲(2012).在线写作自动评改系统在大学英语写作教学中的应用研究——以句酷批改网为例[J].现代教育技术,(10):67-71.
[14]王鹤琰(2016).基于“要素评价量表”的写作教学内容研究——以上海市X学校为例[D].上海:上海师范大学.
[15]王彦芳(2015).中美作文命题与评分准则的比较[J].文学教育(上),(10):73-74.
[16]魏小娜(2009).中美作文评价标准比较[J].语文教学通讯,(1):59-60.
[17]吴恩慈,田俊華(2019).汉语作文自动评价及其关键技术——来自作文自动评价(AEE)的经验[J].教育测量与评价,(8):45-54.
[18]解月(2020).二语写作连贯研究综述和展望[J].山东外语教学,(6):20-30.
[19]辛涛,杨丽萍(2020).基于概念图的作文自动化评分探索[Z].2020全球人工智能与教育大数据大会(北京).
[20]赵海燕,辛涛,田伟(2018).主观题评分中的评分者漂移及其传统检测方法[J].中国考试,(8):20-27.
[21]徐建平,段海燕,李露(2020).发散思维测验的机器评分[Z]. 2020全球人工智能与教育大数据大会(北京).
[22]张晋军,任杰(2004).汉语测试电子评分员实验研究报告[J].中国考试,(10):27-32.
[23]Attali, Y., & Burstein, J. (2005). Automated Essay Scoring with e-rater? V.2[J/OL]. [2020-02-10]. https://files.eric.ed.gov/fulltext/EJ843852.pdf.
[24]Attali, Y. (2015). Reliability-Based Feature Weighting for Automated Essay Scoring[J]. Applied Psychological Measurement, 39(4):303-313.
[25]Attali, Y., Lewis, W., & Steier, M. (2013). Scoring with the Computer: Alternative Procedures for Improving the Reliability of Holistic Essay Scoring[J]. Language Testing, 30(1):125-141.
[26]Attali, Y., & Powers, D. (2009). Validity of Scores for a Developmental Writing Scale Based on Automated Scoring[J]. Educational and Psychological Measurement, 69(6):978-993.
[27]Bennett, D., & Parry, G. (1998). The Accuracy of Reformulation in Cognitive Analytic Therapy: A Validation Study[J]. Psychotherapy Research, 8(1):84-103.
[28]Breyer, F. J., Rupp, A. A., & Bridgeman, B. (2017). Implementing a Contributory Scoring Approach for the GRE? Analytical Witing Section: A Comprehensive Empirical Investigation(ETS Research Report No. RR-17-14)[R]. NJ: Princeton: Educational Testing Service.
[29]Bridgeman, B., & Ramineni, C. (2017). Design and Evaluation of Automated Qriting Evaluation Models: Relationships with Writing in Naturalistic Settings[J]. Assessing Writing, 34:62-71.
[30]Bridgeman, B., Trapani, C., & Attali, Y. (2012). Comparison of Human and Machine Scoring of Essays: Differences by Gender, Ethnicity, and Country[J]. Applied Measurement in Education, 25(1):27-40.
[31]Burstein, J. C., Kukich, K., & Wolff, S. et al. (1998). Computer Analysis of Essays[Z]// Paper Presented at the Annual Meeting of the National Council of Measurement in Education. IL: San Diego.
[32]Chen, L, Tao, J., & Ghaffarzadegan, S. et al. (2018). End-to-End Neural Network Based Automated Speech Scoring[C]// Proceedings of the International Conference on Acoustics, Speech, and Signal Processing. IL: Calgary.
[33]Crossley, S. (2020). Linguistic Features in Writing Quality and Development: An Overview[J]. Journal of Writing Research, 11(3):415-443.
[34]Deane, P. (2013). On the Relation Between Automated Essay Scoring and Modern Views of the Writing Construct[J]. Assessing Writing, 18(1):7-24.
[35]Elliot, S. M. (2001). IntelliMetric: From Here to Validity[Z]// Paper Presented at the Annual Meeting of the American Educational Research Association. IL: Seattle.
[36]Elliot, S., M., & Mikulua, C. (2004). The Impact of MY Access!TM Use on Student Writing Performance: A Technology Overview and Four Studies[Z]// Paper Presented at the Annual Meeting of the American Educational Research Association (AERA). IL: San Diego.
[37]Hao, S., Xu, Y., & Peng, H. et al. (2014). Automated Chinese Essay Scoring From Topic Perspective Using Regularized Latent Semantic Indexing[Z]// Paper Presented at the 22nd International Conference on Pattern Recognition. IL: Calgary.
[38]Jiang, J., Bi, P., & Liu, H. (2019). Syntactic Complexity Development in the Writings of EFL Learners: Insights From a Dependency Syntactically-Annotated Corpus[J]. Journal of Second Language Writing, 46. doi:10.1016/j.jslw.2019.100666.
[39]Ke, X., Zeng, Y., & Luo, H. (2016). Autoscoring Essays Based on Complex Networks[J]. Journal of Educational Measurement, 53(4):478-497.
[40]Ke, Z. (2019). Automated Essay Scoring: Argument Persuasiveness[D]. Richardson: The University of Texas at Dallas.
[41]Kusner, M. J., Loftus, J., & Russell, C. et al. (2017). Counterfactual Fairness[M]// Guyon, U., von Luxburg, S., & Bengio, H. M. et al. (Eds.). Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems. IL: Long Beach.
[42]Landauer, T. K., Foltz, P. W., & Laham, D. (1998). Introduction to Latent Semantic Analysis[J]. Discourse Processes, 25:259-284.
[43]Limpo, T., Alves, R. A., & Connelly, V. (2017). Examining the Transcription-Writing Link: Effects of Handwriting Fluency and Spelling Accuracy on Writing Performance via Planning and Translating in Middle Grades[J]. Learning and Individual Differences, 53:26-36.
[44]Liu, L. (2017). A Comparative Study of Different Text Similarity Measures for Identification of Off-Topic Student Essays[J]. Boletin Tecnico/Technical Bulletin, 55(11):602-606.
[45]Maharjan N., & Rus V. (2019). A Concept Map Based Assessment of Free Student Answers in Tutorial Dialogues[M]// Isotani, S., Millán, E., & Ogan, A. et al. (Eds). Artifificial Intelligence in Education(AIED 2019). Lecture Notes in Computer Science, vol. 11625, Cham: Springer:244-257.
[46]Mayfield, E., & Black, A. (2020). Should You Fine-Tune BERT for Automated Essay Scoring?[C]// Proceedings of the Fifteenth Workshop on Innovative Use of NLP for Building Educational Applications. IL: Seattle.
[47]McNamara, D. S. (2015). The Tool for the Automatic Analysis of Text Cohesion (TAACO): Automatic Assessment of Local, Global, and Text Cohesion[J]. Behavior Research Methods, 48(4):1227-1237.
[48]Nadeem F., Nguyen H., & Liu Y. et al. (2019). Automated Essay Scoring with Discourse-Aware Neural Models[C]// Proceedings of the Fourteenth Workshop on Innovative Use of NLP for Building Educational Applications. IL:Florence.
[49]Nafa, F., Khan, J. I., & Othman, S. et al. (2016). Discovering Bloom Taxonomic Relationships Between Knowledge Units Using Semantic Graph Triangularity Mining[C]// Proceedings of the 2016 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery. IL: Chengdu.
[50]Nguyen, H., & Litman D. (2018). Argument Mining for Improving the Automated Scoring of Persuasive Essays[C]// Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence. IL:New Orleans.
[51]Page, E. B. (1966). The Imminence of Grading Essays by Computer[J]. Phi Delta Kappan, 48:238-243.
[52]Persing, I., & Ng, V. (2013). Modeling Thesis Clarity in Student Essays[C]// Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics. IL: Sofia.
[53]Persing, I., & Ng, V. (2015). Modeling Argument Strength in Student Essays[C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. IL: Beijing.
[54]Rahimi, E., Van den Berg, J., & Veen, W. (2015). Facilitating Student-Driven Constructing of Learning Environments Using Web 2.0 Personal Learning Environments[J]. Computers & Education, 81:235-246.
[55]Raquel, M., Lockwood, J., & Hamp-Lyons, L. (2014). Exploring the Use of an Automated Essay Scoring System for a Diagnostic Writing Test[C]// Proceedings of the 36th Language Testing Research Colloquium. IL: Amsterdam.
[56]Ramineni, C., & Williamson, D. M. (2013). Automated Essay Scoring: Psychometric Guidelines and Practices[J]. Assessing Writing, 18(1):25-39.
[57]Rupp, A. A. (2018). Designing, Evaluating, and Deploying Automated Scoring Systems with Validity in Mind: Methodological Design Decisions[J]. Applied Measurement in Education, 3:191-214.
[58]Sakti, E., & Fauzi, M. A. (2016). Comparative Analysis of String Similarity and Corpus-Based Similarity for Automatic Essay Scoring System on e-Learning Gamification[C]// Proceedings of the International Conference on Advanced Computer Science & Information Systems. IL: San Diego.
[59]Shermis, M. D., & Burstein, J. (2013). Handbook of Automated Essay Evaluation: Current Applications and New Directions[M]. London and New York: Routledge:1-12.
[60]Sinharay, S., Zhang, M., & Deane, P. (2019). Prediction of Essay Scores From Writing Process and Product Features Using Data Mining Methods[J]. Applied Measurement in Education, 32:116-137.
[61]Somasundaran, S., Riordan, B., & Gyawali, B. et al. (2016). Evaluating Argumentative and Narrative Essays Using Graphs[C]// Proceedings of the 26th International Conference on Computational Linguistics: Technical Papers. IL: Osaka.
[62]Spandel, V., & Stiggins, R. J. (1980). Direct Measures of Writing Skill: Issues and Applications[M]. Eugene, OR: Northwest Regional Educational Laboratory.
[63]Stab, D., Strobelt, H., & Rohrdantz, C. et al. (2014). Comparative Exploration of Document Collections: A Visual Analytics Approach[J]. Computer Graphics Forum, 33(3):201-210.
[64]Uto, M., & Okano, M. (2020). Robust Neural Automated Essay Scoring Using Item Response Theory[C]// Proceedings of the Artificial Intelligence in Education, 21st International Conference. IL: Morocco.
[65]Wachsmuth, H., Khatib, K., & Stein, B. (2016). Using Argument Mining to Assess the Argumentation Quality of Essays[C]// Proceedings of the 26th International Conference on Computational Linguistics. IL: Osaka.
[66]Wolfe, E. W., Ng, D., & Baird, J. A. (2018). A Conceptual Framework for Examining the Human Essay Rating Process[C]// Paper Presented at the Annual Meeting of the National Council on Measurement in Education. IL: New York.
[67]Xu, Y., Ke, D., & Su, K. (2017). Contextualized Latent Semantic Indexing: A New Approach to Automated Chinese Essay Scoring[J]. Journal of Intelligent Systems, 26(2):263-285.
[68]Yang, L., Xin, T., & Cao, C. (2020). Predicting Evaluations of Essay by Computational Graph-Based Features[J]. Frontiers in Psychology. 11. doi:10.3389/fpsyg.2020.531262.
[69]Yao, L, Haberman, S., & Zhang, M. (2019). Penalized Best Linear Prediction of True Test Scores[J]. Psychometrika, 84:186-211.
[70]Yoon, S.-Y., & Bhat, S. (2018). A Comparison of Grammatical Proficiency Measures in the Automated Assessment of Spontaneous Speech[J]. Speed Communication, 99:221-230.
[71]Zedelius, C. M., Mills, C., & Schooler, J. W. (2019). Beyond Subjective Judgments: Predicting Evaluations of Creative Writing from Computational Linguistic Features[J]. Behavior Research Methods, 51(2):879-894.
[72]Zhang, M., Zhu, M., & Deane, P. et al. (2019). Analyzing Editing Behaviors in Writing Using Keystroke Logs[C]// Proceedings of the 83th Annual Meeting of the Psychometric Society. IL: New York.
[73]Zhao, S., Zhang, Y., & Xiong, X. et al. (2017). A Memory-Augmented Neural Model for Automated Grading[C]// Proceedings of the Fourth ACM Conference on Learning Scale. IL: Cambridge.
[74]Zupanc, K., & Bosni?, Z. (2017). Automated Essay Evaluation with Semantic Analysis[J]. Knowledge-Based Systems, 120:118-132.
收稿日期 2020-12-25責任编辑 汪燕
Aided Ability Measurement by Artificial Intelligence:
The Core Problems of Automatic Writing Scoring Research
YANG Liping, XIN Tao
Abstract: The automatic scoring of writing is an emerging research field in the current intelligent education, providing a more quantitative, real-time and robust scheme to alleviate the enormous pressure of economy and time cost in human rating. However, most current automatic writing scoring models take features as predictors to fit the measurement model of manual scoring. To match automatic essay scoring with the ultimate goal of improving students writing ability, the automatic scoring system should be constructed from the perspective of writing ability measurement, to clarify the range of measurement and break through the technical bottleneck of the shift from automatic essay scoring to ability evaluating. The core scientific problems that need to be addressed include: (1) How to establish an explicable feature system based on writing evaluation criteria, in order to solve the problem of decoupling between the automatic scoring and the evaluation standard; (2) How to break through the limitation of fitting for human scores to expand the score-prediction model to the ability-measurement model, and explore the evaluation model for each dimension of writing ability; (3) How to systematically demonstrate the reliability and validity of automatic writing scoring and emphasize the fairness across subgroups based on ensuring the accuracy of scoring in practice. In order to explore the effective construction and the reasonable path of using automatic writing scoring, future research can be advanced from such aspects as the combination of automatic scoring and manual scoring, the test of the stability and generalization of automatic writing scoring, the sustainability of writing ability development and the comparability of test scores.
Keywords: Automatic Writing Scoring; Ability Measurement; Feature System; Evaluation Model; Reliability and Validity
