基于注意力机制的铁路巡检视频场景分类方法研究
2021-08-23刘益成高仕斌庞鸿宇
刘益成,于 龙,高仕斌,庞鸿宇
(西南交通大学 电气工程学院,四川 成都 610031)
接触网安全巡检关系到高速铁路系统安全和国家经济发展,保证接触网系统的安全对于高速铁路可靠运行具有十分重要的意义。然而接触网设备露天设置、工作环境恶劣且没有备用[1],要杜绝安全隐患无疑是一个极大的挑战。为了保障高铁受电弓-接触网系统的运行安全,高速铁路部门广泛采用了6C系统(高速铁路供电安全检测监测系统)。其中2C系统[2](接触网安全巡检装置)采用便携设备对接触网的状态及外部环境进行视频采集,通过图像处理技术分析视频,以确定接触悬挂部件状态[3],然后优先检测易出现故障的接触网场景中的接触网部件。因此针对巡检视频中接触网所处场景的准确分类成为一个必要的任务。
目前的视频图像分类方法主要是逐帧分类,对单帧图像采用图像分割或特征提取算法得到特征表达向量,之后将视频的所有帧特征进行聚合输入到分类器中。文献[4]针对人体运动识别,根据3D可控滤波器估算时空定向能量生成具有高运动显著性的大量3D区域,使用HOE(时空定向能量直方图)、HOG(梯度直方图)表示视频帧的特征,再通过SVM(支持向量机)对人体运动进行分类。Wang等[5]利用光流场获得视频序列的轨迹,沿着视频轨迹提取HOG、HOF(光流直方图)、MBH(光流梯度直方图)等多种特征,然后将特征编码后送入分类器进行视频分类,然而这些特征都是由人工设计的传统特征,较难捕捉高级语义信息。Karpathy等[6]首先训练CNN(卷积神经网络),然后从不同分辨率的视频中提取不同尺度的特征,从而构建了一个多分辨率的架构进行视频片段分类,但这个方法只适用于帧数固定的片段。Karen等[7]针对捕捉视频人体动作与静态背景的关系,在3D卷积神经网络中引入时间关系,但这种方法需要在网络训练之前对视频进行分段,难以处理时间序列较长的视频。在文本识别与自然处理领域,CRNN(Convolutiona Recurrent Neural Network)[8]将从CNN部分输出的特征图中提取的特征向量作为RNN(循环神经网络)部分的单元输入,每一个特征向量在特征图上按空间位置从左到右生成,这种方法可以利用RNN解决空间序列问题,但并不适用于视频场景分类这类时间序列问题。在机器翻译领域,对序列信息有着高效挖掘能力的注意力(Attention)机制被广泛应用于语音识别、文本分析中[9-12],但未被应用于视频场景分类领域。
针对铁路领域的场景分割,王洋等[13]采用卷积神经网络,基于单一图像帧对轨道区域、天空、接触网等多个区域进行分类;徐凡等[14]根据有砟、无砟场景的不同特征,由边缘检测绘出方向统计直方图来区分图像帧中的有砟、无砟场景;李家才等[15]针对铁路视频场景入侵目标的分类,根据相对背景差分法区分出视频中的运动目标与背景,提取目标特征进行跟踪,并实现对入侵运动目标的分类。然而这些方法均缺乏对图像时序特征的考虑,无法解决针对铁路场景下的对整个视频图像序列的分类任务。
为解决铁路视频场景的分类问题,本文根据铁路巡检视频的场景特点与场景帧之间的变化规律,采用深度学习技术,对巡检视频中4种不断交替变化场景的分类方法展开研究,提出针对性的图片预处理方式,在不损失关键信息的前提下缩小视频帧大小,采用预训练的Inception-v3网络[16]提取视频帧的图像特征,并结合注意力机制的双向GRU网络分类方法,通过引进帧与周围帧之间的相互联系及重要程度,以提高模型对帧的分类准确率,从而提高模型场景分类的准确率与召回率,为工作人员快速准确监测接触网零部件故障提供进一步的便利。
1 基于注意力机制的视频分类模型
基于注意力机制的视频场景分类模型架构见图1。

图1 视频场景分类的模型架构
给定一个视频序列,首先按时间顺序从视频段中依次选取m个视频帧,根据视频帧的特点进行图片预处理,不仅能突出原帧的关键信息,还能减小帧的大小从而减小后续模型的计算量。随后依次将处理后的m个视频帧输入到预训练的Inception-v3网络中,以提取视频序列中每帧图像的特征信息。再依次将卷积神经网络输出的视频帧的特征信息输入到双向循环神经网络,加入注意力机制使模型关注到帧与相邻帧在时序与内容上的联系,从而找到与类别相关的有效特征,减少不相关区域对模型分类的影响。最后根据该帧属于每个类别的概率来决定该帧真正的类别归属。
1.1 基于Inception-v3网络的特征提取模型
预训练的卷积神经网络是将卷积神经网络在海量数据集上进行不断训练、调整网络参数而得到的。由于海量数据涵盖了日常所能见到的各种图片分类,因此在此基础上训练出来的模型可以用于提取图像特征。Inception-v3网络是谷歌公司提出的经典卷积神经网络,其预训练模型是图像提取特征的常用模型之一。
本文设计的Inception-v3网络模型的结构见图2。底层网络由传统的卷积神经网络组成,包含6个卷积层和2个池化层,在最后一个卷积层后接入堆叠的Inception块。该模型去除了原有预训练Inception-v3网络的一个全连接层以及一个softmax输出层,使其成为特征提取器。视频中的帧经过该特征提取器,最终得到一个2 048维向量,该向量即为Inception-v3网络提取到的帧特征。

图2 Inception-v3网络模型的特征提取
在图2所示的Inception-v3网络模型中,特殊的地方在于Inception块,这是一种网中网结构,即多个Inception块堆叠形成一个整体结构。Inception-v3网络模型包含3种不同类型的Inception块,分别为Inception1[16]、Inception2[17]和Inception3[17],网络结构见图3。
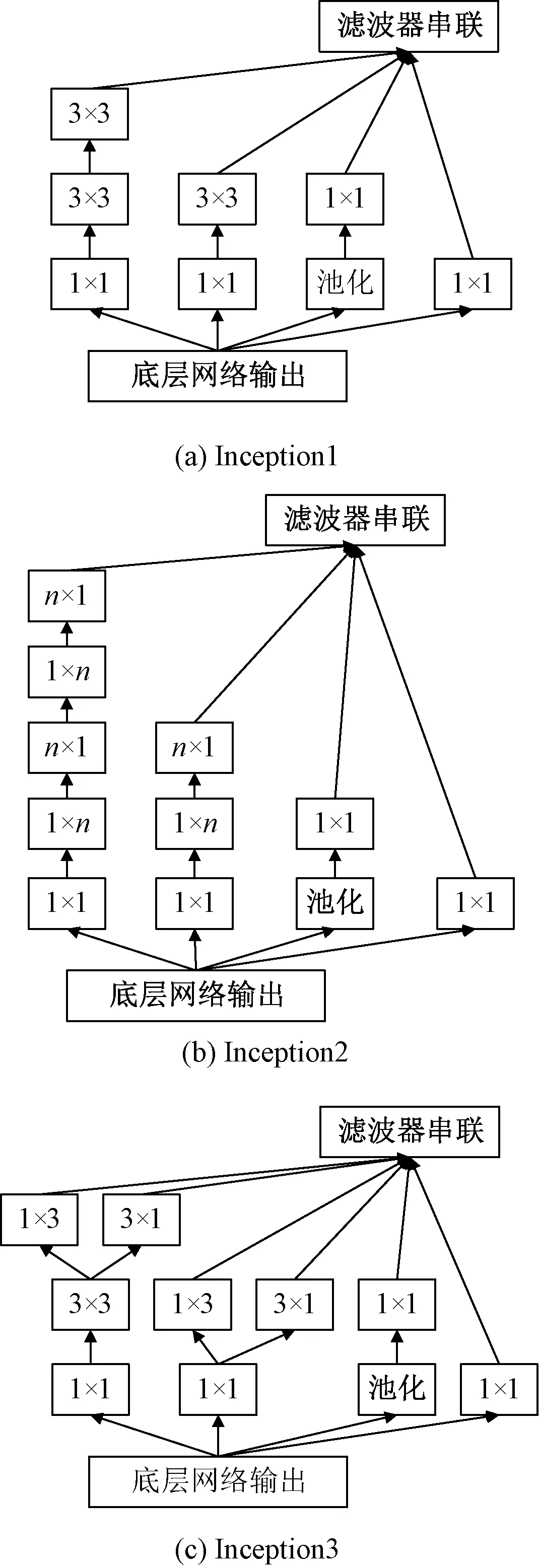
图3 Inception-v3网络结构
1.2.1 双向GRU编码网络
首先采用传统RNN模型的变种——GRU(传统门限循环单元)网络,按序列顺序处理由Inception网络输出的视频帧的特征向量。GRU网络由Cho等[18]于2014年提出,它能够有效地处理长序列,识别远距离的序列信息。提取视频序列信息之后采用注意力机制可以提升视频帧分类的效果。GRU单元结构见图4。

图4 GRU单元结构
GRU单元包含了重置门与更新门。重置门决定记忆的重组,即将上一时刻的记忆与新输入的重新组合形成新的记忆;更新门决定带入上一时刻记忆的比例。重置门值越小代表忽略上一时刻记忆的越多;更新门值越大代表上一时刻记忆占比越多[19]。这两个门控向量控制GRU的输出信息。GRU单元的结构与向前传播式为
rt=σ(Wr×[ht-1,xt])
( 1 )
zt=σ(Wz×[ht-1,xt])
( 2 )
( 3 )
( 4 )
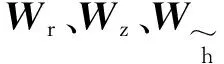
GRU编码网络是为了将图片特征序列压缩成一个固定维度的向量。在单向GRU编码网络中每个输入的隐含状态只压缩了其前面输入的信息。而对于许多序列建模任务而言,过去的信息固然很重要,但是未来信息的参与更可以使模型的准确率得到进一步提升。因此采用双向GRU网络可以实现同时整合过去与未来的信息。双向GRU神经网络单元结构见图5。

图5 双向GRU单元结构

1.2.2 注意力机制
注意力机制最开始启发于人类观察图像的特点。人观察图像时,注意力不会放在每一个像素点上,而是放在图像中某一重要部分。由此Googlemind团队在应用循环神经网络时加入了注意力机制来学习一幅图像中的重要部分。注意力机制第一次在自然语言处理中的应用,是在机器翻译时使用注意力机制来将翻译和对齐同时进行[20]。实验证明,注意力机制的加入的确使得循环神经网络的效果得到大幅提升[21]。
在一段连续的视频中,不同场景不断地交替变换。当判断其中的一帧属于哪个场景时,除了此时帧本身所含的信息外,还需要周围帧的信息。处于不同位置所含信息不同的周围帧对本帧所产生的影响是不同的,距离近的周围帧对此时帧影响大,距离远但是内容很重要的帧对此时帧的影响同样大。双向GRU网络编码得到的此时帧的隐含状态已包含了周围帧在位置上对此时帧的影响(离此时帧越近的帧信息影响越大)。此时在帧所包含信息上引入注意力机制,基于周围帧所包含的信息赋予周围帧不同权重来表达周围帧所含信息对于此时帧预测的重要程度,必定能提升分类器的性能。因此本文提出在双向GRU神经网络上应用基于帧级别的注意力机制来提升帧分类效果。注意力机制网络结构示意见图6。

图6 注意力机制网络结构示意
定义视频第i帧的类别概率向量为yi,则其中第i帧的类别j概率yij为
(5)
ti=Ws·zi+bs
(6)
zi=f(zi-1,yi-1,ci)
(7)
式中:n为共有类别;zi为i时刻的隐层状态;ti为第i帧未经归一化的输出结果;f为GRU单元等效函数;yi-1为i-1时刻图片的预测结果向量;ci为i时刻包含帧与周围帧信息的上下文向量;Ws为权重矩阵;bs为偏移向量。式(5)所示即为图6中所示的softmax函数。
在接触网安全巡检视频中,对不同时刻的帧而言,与它有关的周围帧信息是不同的,因此在模型中它是动态变化的。每个帧的上下文向量ci依赖于双向GRU网络得到的隐层状态集合(h1,…,hT),其中每个ht∈(h1,…,hT)压缩了输入端每个帧信息并且包含了它周围的帧信息。对ci可以通过各个隐层状态的加权平均得到:
( 8 )
( 9 )
( 10 )

2 数据集及参数设置
在铁路视频分类的研究工作中,没有可直接使用的图像数据库。本文数据集采集自6C系统总体技术规范中的2C系统所拍摄的成渝客专下行线路视频。该视频包含了各种情形的影像,从中截取图像的分辨率为2 560×2 160。根据视频的帧率,可以得到每小时有近4万幅的图像。在保证包含全部铁路场景的基础上,对视频的内容进行了图像采集。经过筛选后,成功对成渝客专线路数据集的74 000帧图片约8万幅的图像数据进行了逐一标注,建立了训练和测试所需的样本库。然后将它们分成4类,分别为单腕臂、锚段关节、隧道和硬横跨,见图7。

图7 铁路场景视频帧示例
在以上常见的4种场景中,硬横跨场景包含的帧数最少,且同类别中帧之间差别小。为了避免训练时类别样本数量不均衡造成分类器性能下降,本文将其他场景的训练集数量与硬横跨场景训练集数量保持接近。挑选出训练集的场景帧后,将剩余的场景帧作为测试集。数据集场景类别及对应帧数量见表1。

表1 数据集场景类别及对应帧数量
注意力机制模型的基本参数设置见表2。

表2 模型设置参数
3 实验
3.1 2C图片预处理
由上文可知,每帧图像的尺寸为2 560×2 160,即每张图像的像素点为5 529 600个。根据对于2C系统所拍摄视频的先验知识,在整个2C视频中,所有类别片段中的图片下半部分都共同拥有场景,且下半部分对判断该图片属于哪一个类别片段并没有帮助。为了便于后续提取图像特征的有用信息,且减小后续模型的计算量,本文舍弃了图片的下半部分。且在图片的上半部分,只需要用到包含关键信息的部分,就足以判断出图片所处的片段种类,如此可以进一步缩小输入模型的图片的像素。视频帧图像示例见图8,其中红色区域为关键信息部分。

图8 代表场景视频帧关键信息的部分
在整条线路上,代表每一帧关键信息的部位可能位于左上1/4侧,也可能位于右上1/4侧,提取每张图片关键部位的处理流程见图9。
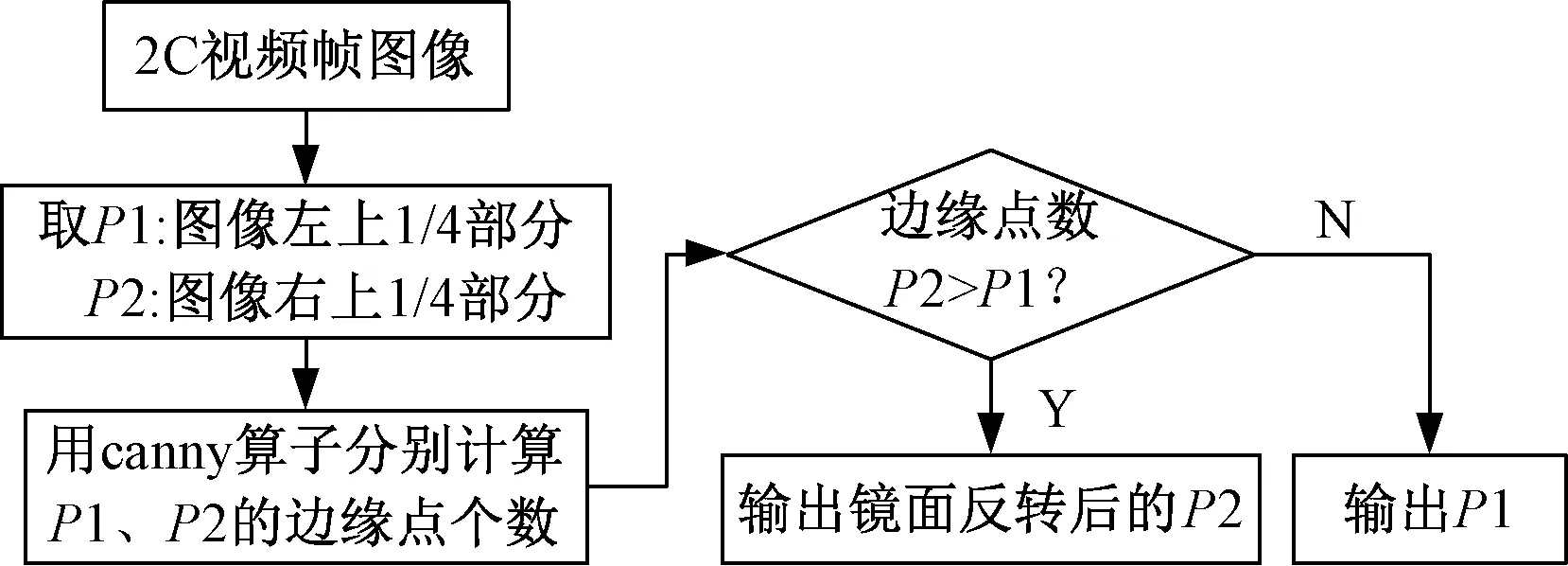
图9 视频帧图像预处理流程
根据图9计算流程得到的预处理后的输出结果见图10。
3.2 检测实验评价标准
本文模型实际上是对视频进行场景分类,因此可以将其视作分类问题。与传统的图片分类问题不同的是,场景分类关注的是一个片段是否被分类正确。因此这里的评价单位是一个片段而非单帧图片,在得到帧分类结果后还需要进行进一步处理。本文定义类别同为i的连续帧称为i类的一个片段,Qi为模型类别i的片段集合,对于预测为i类的一个片段gi,其预测正确的规则为
∃p∈Qi,使得p∩gi≠∅
(11)
对于模型而言,采用准确率P、召回率R和F值来作为评价指标,计算式为
(12)
(13)
(14)
P值为预测正确的片段数除以整个测试集中预测为正确的样本总数;R值为预测正确的片段数除以真实为正确样本的数目。由于P和R是相互矛盾的一对变量,故常采用F值综合考虑P和R,以反映模型对分类的总体情况。
3.3 实验结果及分析
本文提出的方法是在使用预训练的Inception-v3模型提取帧特征后,利用结合注意力机制的双向GRU网络对帧进行分类,模型训练过程中的损失曲线见图11。

图11 模型训练过程的损失曲线
由图11可见,损失曲线可在迭代50次后趋于平稳;验证集上的损失比训练集上的损失稍高但是没有出现过拟合现象,证明网络训练过程有效。根据对单帧的分类预测结果,可以画出模型的ROC(Receiver Operating Characteristic)曲线,见图12。

图12 单帧分类结果的ROC曲线
由图12可以看出,本文模型的AUC值(ROC曲线下方的面积)为0.93,并且模型能在假阳率很低的同时取得十分高的真阳率,代表模型在该单帧分类问题上整体性能良好。视频帧根据每个类别的预测概率确定最终的分类后,再按照式(11)确定片段的预测结果。其结果显示本文模型在2C视频场景分类问题上准确率为95.2%,召回率为97.5%。
为了比较本文提出模型的有效性,将本文的方法与单独使用CNN(即不考虑帧之间的联系,基于单帧进行图像分类)和不含注意力机制的双向GRU网络方法做了对比实验,实验结果见表3。

表3 实验结果对比
由表3可见:3个模型的召回率都能达到95%以上,其中循环神经网络表现要比卷积网络稍强,这归功于循环神经网络结合时序关系的原因;在准确率上,结合注意力机制的双向GRU网络表现要远远强于其他两个模型,由此证明关注周围帧所包含信息的重要程度可以提高片段分类的准确率。结合注意力机制后的模型会使得片段的预测结果更加具有连贯性,使其预测的片段数量更少,这个特性更有助于贴近实际的应用。同时由于连贯性更强,在长短片段交替时会导致一些短片段的帧在第一步预测时会被判定为前方长片段的分类,从而导致双向GRU网络在结合注意力机制后的召回率会稍低。
4 结论
本文提出将加入注意力机制的双向GRU神经网络模型用于接触网2C系统视频的场景分类。该模型采用预训练好的Inception-v3模型提取帧的特征作为输入,对输入的帧信息采用双向GRU网络进行编码建模,同时加入帧级别的注意力机制,利用周围帧的有效信息来提升分类器的精度。通过与Inception-v3网络及未结合注意力机制的双向GRU网络进行对比实验,验证了结合注意力机制的2C视频场景分类模型效果要优于普通的神经网络模型,具有较好的适用性和鲁棒性。
