基于多步LSTM模型融合的铁路客票订单量预测方法
2021-08-23朱颖婷曹先彬杨立鹏
朱颖婷,张 军,曹先彬,杨立鹏
(1.中国铁道科学研究院集团有限公司 电子计算技术研究所, 北京 100081;2.北京航空航天大学 电子信息工程学院, 北京 100191;3.北京理工大学 前沿交叉科学研究院, 北京 100081)
铁路12306售票系统是全球服务规模最大的客票系统,截至目前已平稳运行近10年。在所有铁路售票渠道中,其售票量占比接近90%,极大方便了旅客出行购票。为了保证售票系统平稳运行,12306运营团队在超级高峰期和一般高峰期采取差异化的运维策略。在春运、国庆节等超级高峰期将余票查询请求转至第三方云服务厂商处理,借助第三方云服务厂商的软硬件资源,为12306自有数据中心缓解80%以上的访问压力。在清明节、五一劳动节、周末等一般高峰期,目前主要通过实时监控订单量、流量等核心业务指标的波动变化,根据业务经验判断系统是否出现异常情况,再及时优化系统硬件配置、运行参数等。实时监控的方式要求技术人员能够及时、快速响应突发情况,若处理异常情况稍不及时,可能影响用户正常购票。因此,需要研究一种离线预估订单量和网络流量(点击次数)的方法,从而可提前较多时间准备系统运维应急预案。
以2019年4月至5月的订单量和系统所有业务的流量为例,对订单量和网络流量(即点击次数)分别进行最大最小归一化,得到订单量时序趋势,见图1。由图1可知,订单量和网络流量的趋势基本一致,在清明节后、五一劳动节前后两者同时趋于阶段性峰值;结束假期后,两者同步趋于阶段性低值。在一般性高峰期,订单量和网络流量具有明显的正相关关系,对12306售票系统网络流量的预测基本等价于对订单量的预测。但由于流量数据管理起步较晚、存储条件有限、缺少超级高峰期流量数据等原因,目前仅基于历史流量数据对未来流量进行预估,难以保证预估结果的准确性和可靠性。

图1 订单量和网络流量时序趋势对比
考虑到2020年新冠肺炎疫情对铁路旅客出行有较大影响,本文仅以2015年至2019年的铁路客票订单量为研究对象。2015年至2019年铁路客票订单量的时序图见图2,可以看到受我国节假日安排、高速铁路网络迅速发展和铁路运能持续提升等因素的影响,12306售票系统的订单量在不同年份的相同月份订单量出现相似的波峰波谷,且订单量呈整体上升趋势,具有明显的周期性、季节性和趋势性特征。

图2 2015年至2019年互联网订单量时序趋势
针对这类走势的时间序列,传统的时间序列预测算法有移动平均、ARIMA(Autoregressive Integrated Moving Average)、指数平滑和决策树模型[1-4],但这类算法往往只考虑近期数值对未来数值的影响,容易忽略过去较长的历史数值和近期数值之间的关系。近年来随着深度学习技术的发展,涌现出多种以深度学习算法为基础的时间序列预测算法。由于LSTM[5](Long Short-term Memory)模型可兼顾过去较长时期和近期数值对未来的影响,在医学、金融等领域被广泛研究和应用[6-7],通过优化模型结构、特征和参数,和ARIMA等传统方法组合应用[8-9]、多种深度学习模型综合应用[10]等方式,可以进一步提升预测结果。单纯的LSTM预测模型和多种深度学习模型组合预测的方法,其预测效果受所选择的特征和参数影响较大,类似铁路旅客出行这种存在明显季节性、周期性和趋势性特征的数据,不可能使用固定规则的特征。LSTM和ARIMA组合应用的方式,往往也取决于训练样本数据的平稳性,如果周期和趋势特征过于复杂,将大大增加模型的计算量。
在优化模型结构、特征和参数,以及多种方法组合预测都难以提升预测效果的情况下,模型融合是一种提升预测效果的简便方式。针对预测问题,常用的模型融合方法有加权求和、Bagging、Stacking、Blending和Boosting等方式[11-12]。加权平均方法对不同模型的预测结果赋予不同权值,对各模型的预测结果进行加权求和;Bagging方法采用有放回的方式进行抽样,用抽样的样本建立子模型进行训练;Stacking方法采取k-折交叉验证方式先训练第一层模型,得到预测结果,对第一层模型的预测结果拼接后训练第二层模型,得到最终预测结果;Blending和Stacking的预测流程基本相同,区别在于训练第一层模型时,Blending未采用k-折交叉验证;Boosting将不同基模型串联起来集成学习、顺序运行,下层模型的训练依赖于上层模型的计算结果。针对时间序列预测问题,若简单采用传统Bagging、Stacking和Blending的方式,会使用时间靠后的序列预测靠前的序列,这有悖于事物发展的自然规律,预测结果必然存在较大的不确定性、不可靠性和不可解释性。
本文通过分析铁路客票历史订单量的长短期趋势、周期性等特征,充分利用LSTM可兼顾长短期数据特征的优势,并借鉴传统Stacking和Blending模型融合方法的思想,提出了一种基于多步LSTM模型融合的铁路客票订单量预测方法。该方法将训练模型分为两层,首先在第一层模型根据订单量的周期性特征构建多个LSTM预测模型,并采用贝叶斯优化方法得到最优候选参数集合,通过验证集筛选后进一步得到最优参数集合;再在第二层模型对第一层模型的预测结果进行融合,进一步提升预测精度和稳定性。
1 数据预处理
1.1 特征分析
铁路客票订单量在2015年至2019年每周各天的走势见图3。由图3可知,周一至周日的订单量存在规律性的波峰和波谷,在近5年内走势几乎一致,且逐年稳步增长,说明铁路客票订单量呈现7 d一个小周期和每年一个大周期的变化规律。
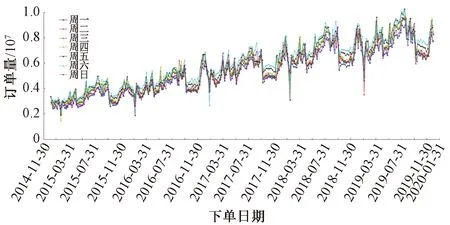
图3 2015—2019年周一至周日铁路客票订单量走势
根据输入的订单时序数据,构造一个包含第d天和前第r天内的订单量的矩阵D为
D=[yd-r,yd-r+1,…,yi,…,yd]
式中:yd为某一天d的订单量;yd-1、yd-2、…、yi、…、yd-r分别为第d-1、d-2、…、i、…、d-r天的订单量,是第d天订单量的特征。
yd和yi的皮尔森相关系数ρi为

d-r≤i≤d
(1)
式中:E(yd)、E(yi)分别为第d天订单量、前第i天订单量的均值。
yd和其前70 d内每日订单量的皮尔森相关系数见图4。由图4可知,除每隔6、7 d外,日期越小,其订单量和yd的相关性就越小;每隔7 d,相关性较前2天有所上升,之后再惯性下降。

图4 相关性分析
选择相关系数超过0.8的历史订单量作为主要特征,再结合订单量以7 d为一个小周期波动的特性,以{y1,y2,…,yb}作为数据集,预测某天的订单量yd,需要参考的历史日期最长为49 d,即b≤49。
1.2 数据归一化
为了提高模型的训练速度和预测精度,首先对数据集进行归一化。很多研究学者在处理类似问题时,往往将训练集和测试集当成一个整体进行归一化操作[15],但在实际工程应用中,测试集属于还未发生的数据,不可能像理论研究中一样对全体数据集进行归一化处理。因此,本文采用线性归一化方法,将原始数值等比例缩放至[0,1]区间,对训练集和测试集分别进行归一化处理,首先将训练集中的最大值、最小值和待预测日期的输入变量集进行合并,再对待预测日期的输入变量集进行归一化。

(2)
(3)
2 基于多步LSTM融合的铁路客票订单量预测方法
2.1 预测框架
基于多步LSTM模型融合的订单量预测框架即根据不同数量的特征变量,首先构造若干个LSTM模型作为第一层预测模型,再在第二层模型对第一层模型的预测结果进行融合,预测流程见图5。

图5 预测框架
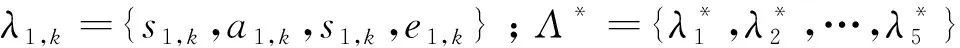
(1)首先将数据划分为训练集、验证集和测试集,并按照1.2节中的方法将训练集和验证集进行整体归一化得到训练集{y1,y2,…,yn}、验证集{yn+1,yn+2,…,yn+m},再对测试集进行归一化得到{t1,t2,…,tl}。
(2)根据铁路客票订单量周期特征构建多步LSTM模型,并采用贝叶斯优化算法计算最优候选超参数集合。
(3)根据候选超参数在验证集上的预测效果,选择最优超参数集合,并对LSTM模型预测结果进行融合,从而进一步提升预测效果。
(4)在测试集验证预测效果,若效果不及预期,则调整时间窗口b值,再次训练模型。
2.2 构建LSTM模型及参数寻优研究
分别以待预测日期的前21、28、35、42、49 d订单量作为特征(look_back分别为21、28、35、42、49),构造5个由LSTM层、dropout层和dense(全连接)层构成的3层结构LSTM预测模型,以look_back=21为例,LSTM预测模型的结构见图6。由于训练集数据较少,为了防止过拟合,采用dropout方法在学习过程中随机删除神经元。图中“⊆”表示dropout层。深色标出的神经元表示在训练过程中会被删除,被删除的神经元将不再参与数据的传递。剩余的神经元pn-21、pn-19、…、pn-1传递给dense层,对数据进行整理计算后最终得到预测结果pn。

图6 LSTM预测模型结构示意图
训练深度学习模型一般都比较耗时,本文采用贝叶斯优化方法求解LSTM模型的最优超参数。贝叶斯优化[13-14]通过基于目标函数的过去评估结果建立替代函数,来找到最小化目标函数的值。贝叶斯优化方法和网格搜索与随机搜索的不同之处在于,它在尝试下一组超参数时,会参考之前的评估结果,并不断更新替代函数,通过推断过去的结果来逼近最优参数,可以提高寻找最优参数的计算速度。贝叶斯优化的大体思路如下[7-8]:首先生成一个初始候选解集合,然后根据这些点寻找下一个有可能是极值的点,将该点加入集合中,重复这一步骤,直至迭代终止。最后从这些点中找出极值点作为问题的解。
平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)是评价预测效果的指标之一,以q为样本数,yi为实际值,MAPE的预测值PMAPE为
(4)
以PMAPE为优化目标,对不同look_back值下的LSTM模型,采用贝叶斯优化方法迭代计算T次,分别得到LSTM模型的候选参数集合Λ1={λ1,1,λ1,2,…,λ1,k}、Λ2={λ2,1,λ2,2,…,λ2,k}、…、Λ5={λ5,1,λ5,2,…,λ5,k}。其中,k为按照PMAPE从小到大排序,取前k个PMAPE值对应的超参数集合。
在使用贝叶斯优化方法求解最优参数时,需要选择PMAPE最小值对应的超参数集合,但在训练模型过程中发现这样非常容易导致过拟合[13-14]。取前几个较小PMAPE对应的超参数集合,分别在验证集上训练模型,选择最小PMAPE对应的最小超参数集合作为LSTM模型的最优超参数集合。LSTM模型参数包括隐藏层尺寸s、dropout层中删除神经元的比例a、批处理数据个数s和训练次数e;以b=21为例,λ1,k是一个候选超参数集合,λ1,k={s1,k,a1,k,s1,k,e1,k}。
基于文献[7-8]中的贝叶斯优化算法,本文的LSTM模型参数寻优过程如下:
Step1输入一组超参数,并根据特征分析结果、训练集长度和业务经验等确定超参数的搜索范围,以look_back=21为例,隐藏层尺寸s的搜索范围为[1,100],删除神经元比例a的搜索范围为[1,50],批处理数据个数s的搜索范围为[2,50],训练次数e的搜索范围为[50,200]。
Step2构造替代函数,该函数包含LSTM预测模型的完整训练过程。
Step3以PMAPE为评价指标,构造目标函数,在优化过程中记录并输出PMAPE。
Step4迭代T次顺序计算Step1~Step3,选择前k个较小PMAPE对应的超参数集合。

2.3 模型融合
(1)验证集预测结果融合
以5个不同b值为例,用验证集{yn+1,yn+2,…,yn+m}及其预测结果{p1,n+1,p1,n+2,…,p1,n+m},…,{p5,n+1,p5,n+2,…,p5,n+m}构造第二层模型的训练数据集T,分别采用两种方式对进行融合,从而进一步提升LSTM模型的预测效果。
(5)

(6)
在训练模型时,由于将训练集、验证集和测试集按照年份划分,线性回归模型难以捕捉到训练数据的长期周期特征,需要按照订单量的年增长规律对预测结果进行调整。其中θ为订单量年增长均值,可根据历年订单量增长趋势统计得到。β1、…、β5为自变量系数,ε1、ε2、…、εm为误差项。
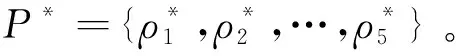
针对加权平均和LightGBM采用网格搜索方法可得到最优超参数,由于其计算方法较简单,本文不再赘述。
(2)验证测试集预测效果及特征调优
3 实验结果及分析
以2015年至2019年铁路客票订单量为实验数据,其中2015年至2017年的数据为训练集、2018年的数据为验证集、2019年的数据为测试集,在时间窗口b为21、28、35、42、49时分别迭代执行100次贝叶斯优化算法,选择MAPE值最小的前10个超参数集合,对比分析不同b下的LSTM预测效果,以及在第二层模型中不同融合方式下的预测效果。
3.1 多步LSTM预测效果分析
根据2.2节的参数寻优过程,再在验证集上执行LSTM模型后选择最优超参数,经过进一步筛选计算,得到最优参数见表1。
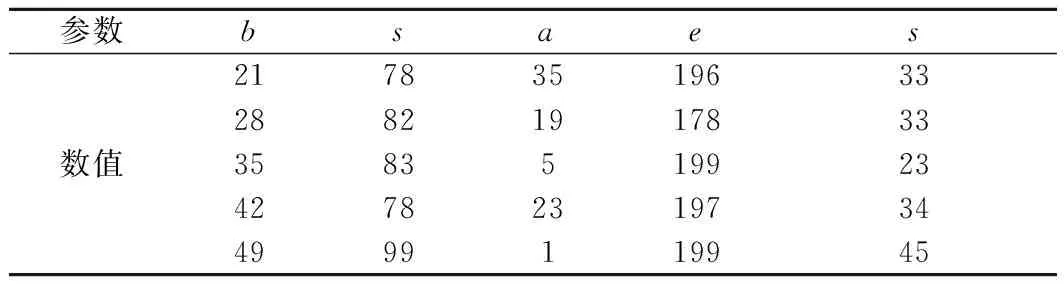
表1 LSTM模型最优参数
由于LSTM模型中包含dropout层,在计算过程中随机删除神经元,导致多次预测结果可能存在一定的差异性。针对不同时间窗口b,分别对测试集进行50轮预测,每轮计算的MAPE值见图7;并计算MAPE均值和方差,结果见表2。
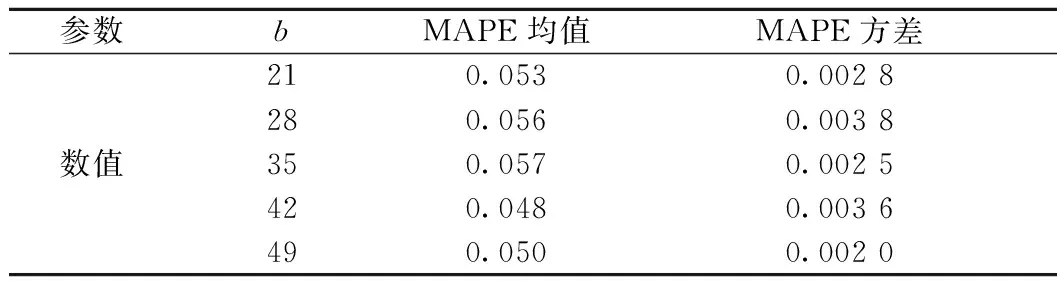
表2 LSTM模型预测MAPE分析
由表2可见,由于b的取值以一个星期为间隔,且和待预测日期的订单量存在较强的相关性,在上述不同b值下的LSTM预测模型均能达到较高的预测精度,其误差范围均不超过0.06,且预测准确度比较平稳。当b=42时,MAPE均值为0.048,预测精度最高;其次为b=49时,MAPE均值为0.050。
由于训练集和测试集数据年份跨度较大,但LSTM模型的预测精度仍然达到较高水平,说明本文的特征提取及参数优化方法具有较高的有效性。尽管使用贝叶斯优化方法求解最优参数较为耗时,但若已发生的订单数据依然呈现图3中的趋势特征,则可继续使用表1中的参数值,而不需要再次执行LSTM模型的调参方法。
3.2 模型融合效果分析
根据2.3节中的3类融合方法,对3.1节中LSTM模型的50轮预测结果分别进行二次融合,计算不同方法下的MAPE,每轮预测的MAPE值见图8;计算MAPE均值和方差,结果见表3。
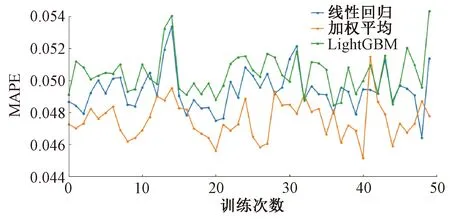
图8 模型融合MAPE分析
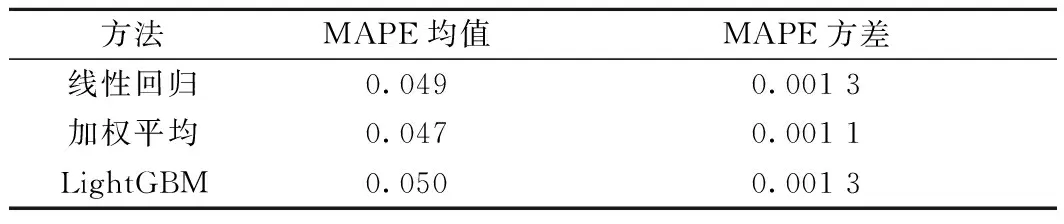
表3 模型融合MAPE分析
可以看出,无论采用哪种模型融合预测几个后,MAPE方差都明显减小,预测结果的稳定性得到较大改善;加权平均融合方法的平均MAPE小于所有b下LSTM模型的平均MAPE,预测精度最高;而采用线性回归和LightGBM模型融合LSTM的预测结果后,其预测精度反而稍低于b=42时的预测精度。
在这3种融合方法中,加权平均的计算流程最简单。这说明当对订单量特征提取得比较准确时,简单的模型反而可能得到更高的预测精度和计算效率。
采用加权平均模型融合后预测值和实际订单量的走势对比见图9。由图9可以看到,预测值和实际值走势几乎保持一致,本文的预测方法几乎完全捕捉到了订单量的所有周期性和季节性特征。但是,从图9中也能看出,当订单量处于波峰位置时,部分预测值稍低于实际值;当订单量处于波谷位置时,部分预测值稍大于实际值。
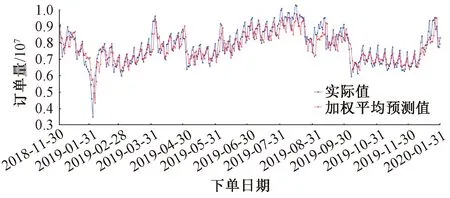
图9 加权平均模型融合预测效果
4 结论
为维护12306售票系统平稳运行,技术人员需要实时监控系统订单量、流量等核心指标变化。提前预估12306售票系统订单量数值及其变化规律,可以为技术人员准备应急预案提供决策依据。
(1)分析了近5年的铁路客票订单量的分布特征,根据订单量的周期性特征,设计了一种多步LSTM模型融合的预测方法,并达到了较高的预测精度,其平均绝对百分比误差不超过5%。
(2)通过对比加权平均、线性回归和LightGBM模型融合的预测效果,发现预测稳定性均有明显提高;但最简单的加权平均融合方法的预测精度反而高于其他两种方法,并较第一层的LSTM模型预测精度有明显提高。
结果表明,在特征选取合理、参数优化可靠的情况下,简单的计算方法就足以提供高效、准确的预测结果,这为开展实际工作也带来了一些新的思路。
