基于DGA域名检测方法的选优方案研究
2021-07-30罗海波陈星池董建虎
罗海波,陈星池,董建虎
(广东东软学院 计算机学院,广东 佛山 528225)
0 引言
动态域名生成算法(Domain Generate Algorithm,DGA)能够有效地生成伪随机域名。攻击者常常会使用域名将恶意程序连接至命令控制服务(Command and Control Server,CC服务器),从而达到操控受害者机器的目的[1]。攻击者可以轻松更改这些域名和IP,即使CC服务器地址部分失效或者变更也能保持连接,而且这些域名往往与恶意程序中的编码混合在一起,具有很强的隐蔽性。
截至2019年12月,网上公开的基于DGA算法变种就已经达到44种[2]。恶名昭彰的恶意软件Zeus和Conficker就是使用了该算法。DGA算法是实现恶意程序的重要技术,分析、复现、检测伪随机域名,进而有效地检测恶意程序,对于国家、企事业、军民网络空间安全有其现实意义。
用于应对 DGA算法生成恶意域名的传统方法有黑名单过滤和通过逆向恶意样本中的 DGA算法,提前抢注域名来夺取CC服务器的控制权。据研究表明,前者无法对动态生成的 DGA域名实时更新,准确率不高;后者虽然可以通过逆向样本深入理解该样本的 DGA算法和生成恶意域名机制,但是需要消耗大量的时间和精力,效率不高[3]。因此,人们的研究方向主要放在对DGA域名的实时检测,主流技术包括利用机器学习的方法构建 DGA域名分类器、使用深度学习的神经网络模型进行检测。
首先介绍了 DGA域名的研究背景和价值,DGA域名的特点、分类和基本定义。然后介绍了人工智能中几种流行的智能算法,例如XGBoost、朴素贝叶斯、多层感知器和循环神经网络。接着介绍了几种特征提取方法,包括 N-Gram模型、统计域名特征模型和字符序列模型。最后对算法和特征提取进行实验,并对结果进行对比分析,获取较优的特征提取和算法组合。
1 准备工作
使用人工智能构建模型,通过该模型对DGA域名的实时检测,这里需要涉及到分类(Classify)。分类指的是基于某种定义好的规则,将需要处理的数据集划分类别。常见的分类任务包括二分类、多分类和多标签分类,对 DGA域名的实时检测只需要判断域名是否正常,所以采用的是二分类。机器学习种常见的二分类算法有:贝叶斯分类、XGBoost算法等。而多层感知机和循环神经网络作为深度学习中的重要算法,除了可以用来做复杂的图像识别,应用在文本的二分类方面也有不错的效果。
下面将在特定的特征为基础上,分别实现贝叶斯分类、XGBoost算法、多层感知机算法和循环神经网络算法在DGA域名检测中的具体应用。
1.1 朴素贝叶斯
朴素贝叶斯分类器(Naive Bayes Classifier,NBC)是贝叶斯决策理论的一部分,可以也被应用于解决诸如某行业是否值得投资、个人信用等级评定、网络态势感知、医疗诊断等统计分析与预测领域[4]。该算法有点在于简单易懂、学习效率高、在某些领域的分类问题中的效果与决策树神经网络相媲美[5]。
假设类别为C,信息的特征值为W,则贝叶斯决策的基本公式为:

若在特定的条件前提下,假设信息体有n个特征W,即Wn={W1,W2,W3, ...,Wn},每个特征相互独立且互不影响[6]。则有朴素贝叶斯的公式为:

在朴素贝叶斯模型中,P(C)代表每个信息体类别的概率,也即被测信息体类别数除以总信息数量;P(W1,W2,W3,...,Wn)代表被测信息体的n个特征值集合,即是每个特征出现的概率相乘;P(W1,W2,W3, ...,Wn/C)代表指定类别下某个信息体的n个特征值集合,即是被测信息体中出现所有词的概率相乘。
1.2 XGBoost
XGBoost(Extreme Gradient Boosting,XGBoost),也被称为梯度提升决策树。近年来比较热门,经常被应用于一些机器学习的竞赛中,其中在Kaggle数据挖掘挑战赛中,29个冠军有17个使用了XGBoost算法[7]。其算法学习速度很快,效果也很好,性能比另一个机器学习库 scikit-learn库的增强梯度算法要好上不止10倍[8],而且可以应用与Python、R、C++等多个平台,有很强的扩展性和移植性。
XGBoost所应用的算法就是GBDT(Gradient Boosting Decision T ree)的改进,属于 Boosting集成学习,也即采用集成学习的方法,由多个相关联的决策树联合决策,目的使组合后的模型具有更强的泛化能力。XGBoost既可以用于分类也可以用于回归问题。
对于样本i=1,2,3,...,m,XGBoost的计算公式为:

其中L(yi,ft-1(xi))为XGBoost原始目标损失函数,而是为防止训练中数据过拟合的正则项。

其中GL,HL,GR,HR分别是当前节点左右子树的一阶二阶导数和。
XGBoost算法的主算流程如下:
Part.1首先向分类器输入训练样本数据集合I,I={(x1, y1) ,(x2, y2) ,(x3, y3)...(xm, ym)},初始化训练参数:迭代数T,损失函数L,正则化系数λ,γ;
Part.2迭代T轮训练数据;
Setp.1计算i个样本(1,2,3,…,m)在当前轮损失函数L基于ft-1(xi)的一阶导数g和二阶导数h,并分别对所有样本的一阶导数和二阶导数求和;
Setp.2基于当前节点尝试分裂决策树并更新分数score值,默认分数score为0;
Setp.3基于最大的score对应的划分特征和特征值分裂子树;
Setp.4若最大score值为0,则当前决策树建立完毕,计算所有叶子区域的ωtj,得到弱学习器ht(x),更新强学习器ft(x),进入下一轮弱学习器迭代。如果最大score不是0,则会转到Setp.2继续尝试分裂决策树;
Part.3输出强学习器f(x);
1.3 多层感知器
多层感知器(Multi-Layer Perceptron,MLP)也称为人工神经网络。它类似与于人类的神经元结构:树突、细胞体和轴突[9]。最简单的MLP只有三层结构,最底层是输入层,中间是隐藏层,最上层是输出层,层与层之间是全连接。多层感知器作为深度学习常用的一种算法,常常被用于处理非线性可分离的问题,分类的准确度高,并行分布处理能力强,分布存储及学习能力强,对噪声神经有较强的鲁棒性和容错能力,能充分逼近复杂的非线性关系,具备联想记忆的功能等。
假设输入为x,最简单的多层感知器公式为:
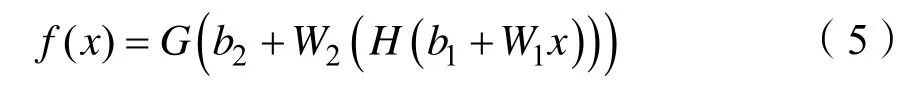
其中H(b1+W1x)表示输入层与隐藏层连接的激活函数,常用函数有sigmoid、anh和relu。求解出来的值作为下一层输出层函数G(b2+W2x)的输入,常用的函数有softmax。而b1、W1、b2和W2都是层与层之间连接的权重和偏置参数。
1.4 循环神经网络
循环神经网络(Recurrent Neural Network,RNN)在 21世纪初被列入深度学习算法中[10]。因为循环神经网络参数共享,具有记忆性,被用于处理诸如文字、时间等序列数据。
但循环神经网络不具备长期依赖信息的学习能力,在长链中若相隔时间太长容易产生梯度消失的问题。后来LSTM(Long Short-Term Memory)的出现,通过精妙的门控制将长短期记忆结合起来很好的解决了这一问题[11],让网络非常擅长长时间学习文本和言语处理,因此被广泛应用。
2 检测方法
2.1 模型描述
DGA域名识别采用如图1所示框架。
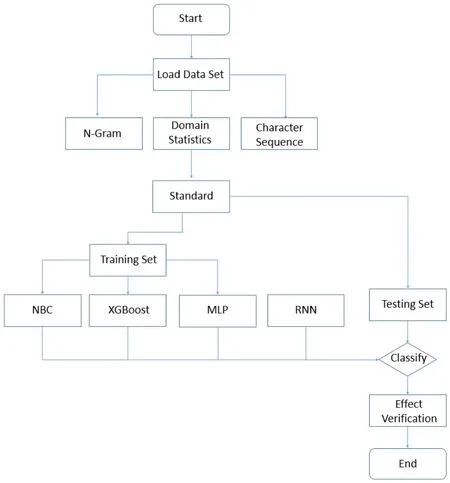
图1 DGA 域标识框架Fig.1 DGA domain identification frame
Setp.1加载Alexa前100万域名数据作为白样本,360netlab开放的DGA域名为黑样本,并且对黑白样本进行数据合并;
Setp.2特征提取。方式1,使用N-Gram模型;方式2,使用统计域名特征模型;方式3,使用字符序列模型;
Setp.3将合并后的数据集的数据分为两份部分,其中一部分是测试集占40%,另一部分是训练集占60%;
Setp.4利用分类算法对训练集进行训练,得到模型数据,算法 1:朴素贝叶斯,算法 2:XGBoost,算法3:多层感知器,算法4:循环神经网络;
Setp.5使用模型数据进行预测,进行分类;
Setp.6效果进行验证。
2.2 DGA 域名特征提取
用于识别 DGA域名的特征提取方法有:N-Gram模型、统计域名特征模型以及字符序列模型等。
特征提取(Feature Extraction)无论是在文本处理、图像识别等都有着广泛的应用。特征提取的方法主要是通过属性间的关系,组合不同的属性得到新的属性,这样做改变了原来的特征空间。目的就是试图去减少特征数据集中的属性,对原来特征数据进行降维,必须保证描述原特征数据的精确性和完整性的同时,更加方便模型学习。
2.3 N-Gram 模型
N-Gram是一种基于统计语言的算法模型。其核心思想是将文本内容按照字节进行大小为N的滑动窗口操作,最终形成长度为N的字节片段序列。
在该模型构成的文本向量特征空间中,列表的每一个字节片被称为gram,并且按照事先设定好的阔值进行过滤和对所有的gram出现频率进行统计。N-Gram模型常被用于评估语句是否合理[12]、搜索引擎或者输入法的猜想提示[13],N值越大,
对下一个备选提示词的选择就更多,但更加稀疏;而N值越小,对下一个备选提示词的约束信息更少,但更加精确。文章使用的是2-Gram的特征提取模型。例如域名[‘baidu.com’]经过该模型的处理之后,会变成词汇表[‘ba’,’ai’,’id’,’du’,’uc’,’co’,’om’]。
2-Gram模型的处理过程如表1所示。

表1 2-Gram 模型处理流程Tab.1 2-Gram processing flow
2.4 统计域名特征模型
域名统计特征模型(Domain Statistics),域名最初的诞生就是为了解决用户请求更方便请求资源的问题,为了更好的体验正常域名长度一般不会存在过长的状况。而 DGA域名仅仅是为了保持被恶意软件主机和 CC服务器通信,为了尽可能避免 DGA生成的域名与正常域名产生冲突,一般 DGA域名长度会比正常域名长。但这不是绝对的,有些 DGA域名为了躲避打击和检测,生成 DGA域名长度也会使用较短,所以只凭借域名长度这个特征判断是不够的。
从域名的内容方面研究,正常人通常在取域名的时候,会偏好选取容易记忆与理解的几个字母组合,也即是元音字母比例会比较高。而DGA算法生成的是随机域名,所以元音字方面的特征不明显;除了元音字母出现的比例不同,文献[14]也指出唯一字符数分布区间也有差异。
本次实验通过统计每个域名的元音字母个数、不重复字符个数、数字个数和域名长度,可以有效的将正常域名和DGA域名进行区分。
统计域名特征模型的处理过程如表2所示。

表2 域统计处理流程Tab.2 Domain statistics processing flow
2.5 字符序列模型
字符序列统计模型(Character Sequence),每个域名都是由字符组成的序列,将对应的字符直接转换成对应的ASCII值。相比一些诸如聚类等复杂的特征提取方法,该方法只需要对域名进行简单的编码,可令分类模型能够直接学习数据的原始特性。
字符序列模型的处理过程如表3所示。

表3 字符序列处理流程Tab.3 Character sequence processing flow
3 仿真实验
3.1 实验数据
Alexa是一家著名的发布世界网站排名的网站,当前拥有最权威、详细的网站排名信息。而360netlab则记录着目前公开的所有DGA家族域名数据。本次实验采取Alexa全球前100万个的网站域名作为白样本和 360netlab的开放数据作为黑样本。
3.2 评价指标
在混淆矩阵中,TP代表真正例,TN代表真负例,FP代表假正例,FN代表假负例。
精确率(Precision)是指预测正确的样本占真实样本比例,常常被作为二分类模型的评估指标。计算精确率的公式为:

召回率(Recall)能反映出一个模型对样本的覆盖能力,也被称为灵敏度(Sensitivity)。计算灵敏度的公式为:
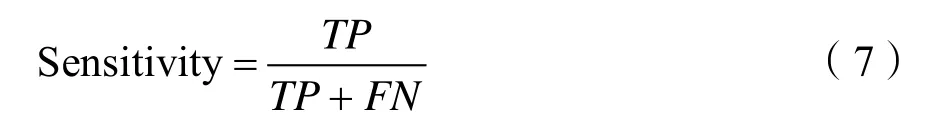
F1-Score是精确率和召回率的一个均衡评价,国内外很多机器学习竞赛都关注这个 F1-Score值。F1-Score的计算公式为:
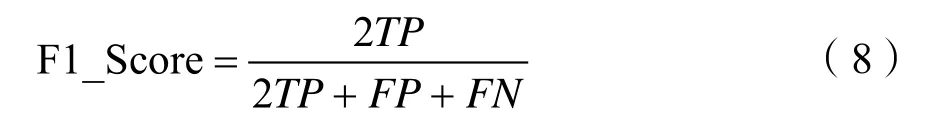
ROC(Receiver Operating Characteristic Curve)也被称为受试者工作特征曲线。数十年前在分析无线电、医学等领域都有应用,而最近在机器学习领域中也得到了良好的发展。ROC曲线相对于准确率、召回率等这类指标评估标准,它减少了对预测概率设分类阔值步骤,大大提高了模型的泛化能力。ROC是以假正率(False Positive Rate,FPR)为横坐标,真正率(True Positive Rate,TPR)为纵坐标绘制的曲线。而真正率与召回率的计算公式相同。假正率的计算公式为:

ROC曲线能反映其模型的灵敏性和特效性连续变量的综合指标,一般曲线越光滑就表示模型与数据的过拟合度越低,曲线越靠左上角就表示该模型的准确性越高。AUC(Area Under the Receiver Operating Characteristic Curve)物理上的含义就是代表ROC曲线下的面积,其值越大也表示模型准确性越高[15]。
3.3 实验结果与分析
图2展示了基于域统计/字符序列的不同分类器的评价指标实验结果。从图上可以看出,在相同的数据集下,基于字符序列特征模型的RNN效果明显优于其他分类器,并且AUC的检测准确概率值达到0.93。图3展示了基于2-Gram特征模型不同分类器的评价指标实验结果。从图上可以看出,MLP对DGA域名检测的准确率最佳,AUC的值可以达到0.94。

图2 基于域统计/字符序列的分类器指标Fig.2 Classifier comparison based on domain statistics/character sequence
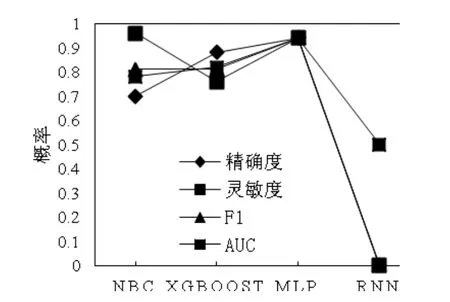
图3 基于2-Gram的分类器比较Fig.3 Classifier comparison based on 2-Gram
对比图2和图3可以看出,基于2-Gram特征模型的F1、灵敏度、精确率等指标均优于基于域统计/字符序列模型。
4 结论
文章简要阐述了 DGA域名课题的研究背景和价值,DGA域名的特点、分类和基本定义。本文介绍了机器学习和深度学习中几种流行的XGBoost、朴素贝叶斯、多层感知器和循环神经网络算法。介绍了几种特征提取的方法,包括NGram模型、统计域名特征模型和字符序列模型。经过对比发现,基于2-gram特征模型的多层感知器在 DGA域名检测中的得到较高的评价,未来研究得主要方向将放在如何进一步提升该组合的DGA域名检测能力,而在实践工程中往往也有其他特征提取模型和分类算法,接下来也会尝试新的可能性,组合不同的特征模型分类算法对DGA域名检测进行改进。
