一种深度森林算法的乳腺癌检测方法研究
2021-07-30李进,何冉
李 进,何 冉
(河北地质大学 信息工程学院,河北 石家庄 050031)
0 引言
目前,许多学者出将机器学习(Mechine Le-arning, M L)算法应用于人类疾病的检测。如赵培培等[3]使用多种机器算法对糖尿病进行分类检测,最终发现投票聚合模型 Voting最适合糖尿病的分类检测;孔德峰等使用传统机器学习算法应用在乳腺癌诊断中,通过构建逻辑回归、决策树、SVM、KNN四种机器学习方法对该问题进行建模与分析,证明了KNN[4]分类器较其他算法有明显优势;苗立志等人[5]基于多个弱分类器的随机森林并行化进行乳腺癌发病概率的预测,并利用皮尔逊和Spearman系数的相关度分析,提高了乳腺癌发病概率的预测精度;叶明等[6]提出了SELEDAT算法,在集成学习中引入动态权重的思想,解决了数据不平衡问题,提高了疾病预测的分类性能。Pawlovsky等人[7]基于两种距离的集成KNN算法,提高了UCI标准化数据集的分类精确度。在实践调查中发现,到目前为止没有任何一种分类方法能在不同的数据类型和不同的领域中证明比其它的分类方法的性能更好[8],而且由于传统机器学习算法无法对数据的深层特征进行深度挖掘,导致在很多领域中无法应用传统机器学习算法,此时深度学习应运而生。深度学习[9]是一种通过多个变换阶段对数据特征进行分层处理最终得到这些特征的抽象表示的机器学习过程,但是目前常见的深度学习结构基本都是基于神经网络[10]的。直至 2017年,周志华等人给出了另外一种与神经网络类似的深度结构——深度森林(multi-Grained Cascade forest, Gcfor-est)[11]。深度森林的出现无疑为深度学习在除神经网络应用之外的应用领域给出了另外一个选择。
对于传统机器学习分类算法在医疗诊断领域效果不理想的情况,本文将深度森林算法应用于乳腺癌肿瘤数据分类问题,首先通过类似卷积操作中的滑动窗口提取原始数据特征并增强表征学习能力,使学习后的数据具有和感受野类似的结构感知能力;级联随机森林具有分层结构,可以对增强后的特征进行逐层学习,最终对乳腺癌肿瘤数据良恶性进行分类。经过对比实验发现,深度森林算法较支持向量机(Supoort Vector Machine,SVM)和决策树(Decsion Tree)算法更优。通过深度森林进行训练得到可信度和准确率都较高的模型,在乳腺癌肿瘤的良恶性检测上给出较为可靠的结果辅助影像医师对病患进行诊断。
1 深度森林
1.1 随机森林(RandomForest, RF)
集成学习[12]是训练若干个个体学习器,并通过特定的结合策略,最终形成一个性能较之原个体学习器更加优越和稳健的强学习器的过程。随机森林属于集成学习中的 Bagging(Bootstrap Aggegation)方法,包含多个决策树分类器,学习过程是每次从候选分类器中选择最优的分类属性,最终输出的类别是由森林中决策树输出类别的众数决定。随机森林中每个个体学习器之间都不存在强依赖关系,对超参数设置不敏感,并且可以判断输入数据特征的重要程度,所以不管是在小规模数据,还是大规模数据上都具有较为良好的泛化性能,这使得随机森林生成的模型不容易造成过拟合现象且可以平衡非对称数据集造成的预测误差。
随机森林算法流程:
Input: 1.训练集
2. 待测样本xt∊Rd

(I)对原始训练集S采用 Boostrap抽样,生成训练集Si
理论空燃比时,在电动势小于约0.4V的情况下AF+侧端子与AF-侧端子的电压相等,因此电流不会流向任何一侧。过浓时,在电动势大于约0.4V的情况下,AF-侧的电压比较高,因此从AF-侧流向AF+侧的电流与电压差成比例。过稀时,在电动势小于约0.4V的情况下,AF+侧的电压比较高,因此从AF+侧流向AF-侧的电流与电压成比例。所以空燃比传感器的输出电压与空燃比的大小成正比。由图1可知,空燃比小于14.7混合汽过浓时,传感器输出较小的电压(小于3.3V);空燃比大于14.7混合汽过稀时,传感器输出较大电压(大于3.3V)。
(II)使用Si生成一颗不减枝的树hi:
a. 从d个特征中随机选取M个特征
b. 在每个节点上从M个特征依据Gini指标中选取最优特征
c. 分裂直到树长到最大
End
Output:1.树的集合{hi,i=1,2,…,N}
2. 对待测样本xt,决策树hi输出hi(xi)
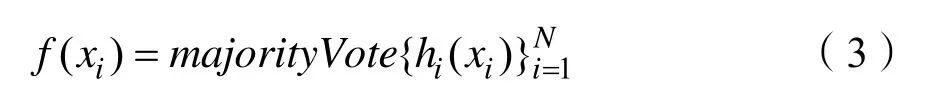
其中,式(1)中xi,yi为第i个数据的特征和标签,R为实数,hi(xi),f(xi)为分类结果,majority Vote表示多数投票,得到最终分类结果
1.2 深度森林(DeepForest)
深度森林[11]又叫多粒度级联森林,它首先采用了类型滑动窗口的方法对原始输入进行特征变换,增强其特征表达能力,然后再通过级联的多个随机森林层做逐层表征学习。
深度森林是由多个随机森林构成一个森林层,然后通过级联的方式连接多个森林层,最终形成层间连接。其中森林中每一层的输出类向量都是一组对上一层输入特征向量转换之后的表征学习,随后将变换表征之后的处理结果提交给下一森林层,同时使用验证集判定这一层输出是否满足预设输出条件,若不满足则将输出向量组合与原始训练向量相连接,并以连接之后的向量作为下一森林层的输入,直至输出向量组合的预测值满足预设条件。深度森林网络结构模型如图1所示。
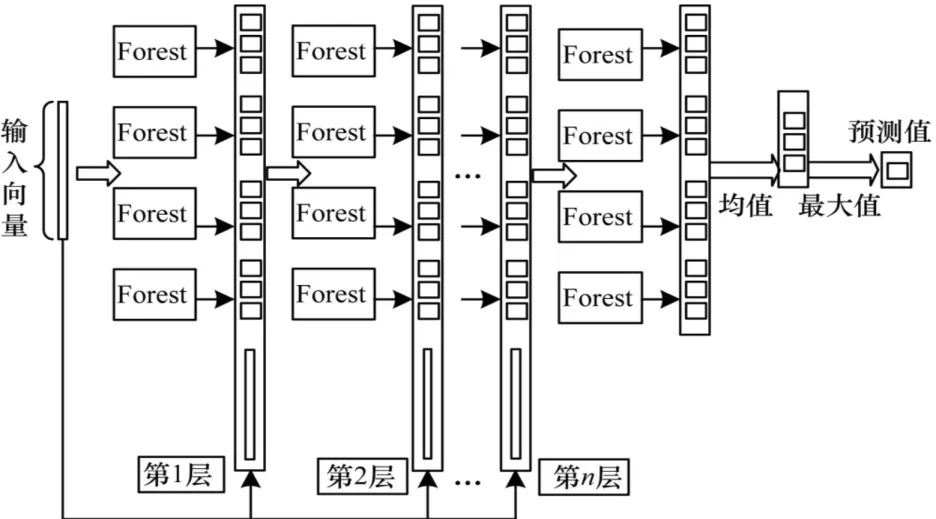
图1 深度森林网络结构模型Fig.1 Structure Model of deep forest network
在图1中,输入向量输入第一个森林层之后,森林层的所有森林分别计算所有样本的类别概率,将得到的类别概率组合作为输出向量并与原始数据进行拼接或组合,随后将组合的数据作为下一森林层的输入,循环直至达到预设的循环次数或者收敛条件后停止对训练数据进行处理,并最终对输出层的向量组合求均值,并将输出概率最大的类别输出为预测的样本类别。
2 实验与分析基于深度森林算法的乳腺癌良恶性检测
2.1 实验环境介绍
本文实验所用的计算机硬件环境配置为Inter(R) Core(TM) i7-8750H 2.2 GHz,内存 16 GB,实验所运行的软件环境为安装在windows10操作系统下的python3.6.5
2.2 实验数据
本文实验采用的数据集为William H. W olberg博士提供的标准乳腺癌肿瘤数据,此数据集可以从UCI数据集官网上获取。
乳腺癌肿瘤数据集共包括569个观测样本,其中每个数据样本都有30种特征属性,这些特征都是对乳腺癌肿瘤的各个维度特征的抽象表征,每种特征的数据类型均为64为浮点数类型,每个样本有且仅有一个标签,标签一共分为两大类,分别是恶性(malignant)和良性(benign)。样本集中,212个样本被标注为恶性,357个样本被标注为良性。部分样本特征名称及其解释如表1。
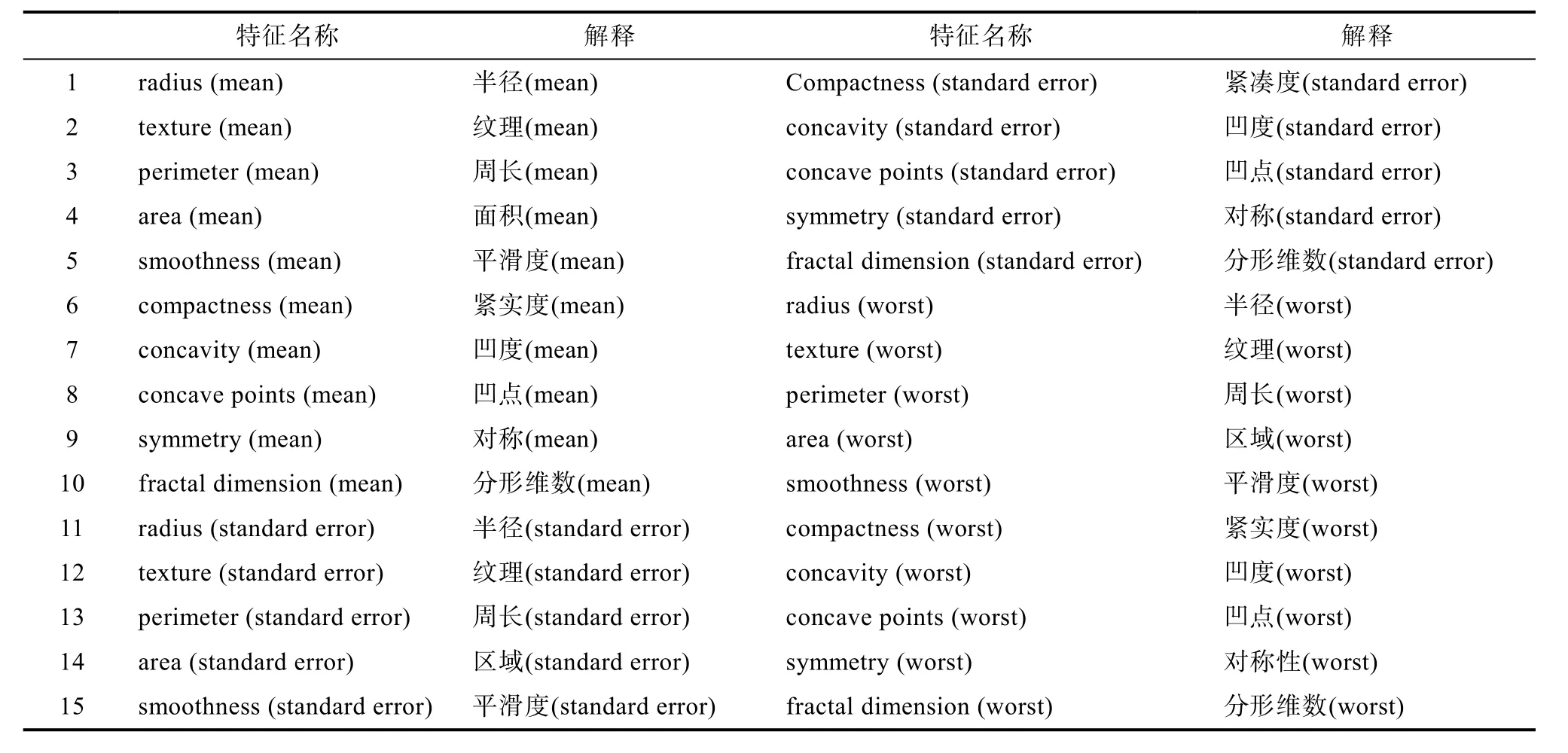
表1 样本部分特征及其解释Tab.1 Partial characteristics of samples and their explanations
其中半径指从中心到周界各点的平均距离,纹理指肿瘤灰度图的标准差,平滑度指半径的局部变化的程度,密实度指周长的平方除面积-1,凹度指肿瘤轮廓凹陷部分的严重程度,凹点指论文凹面部分的数量。mean代表平均值,standard error代表标准差,worst代表最差的或者最大值。乳腺癌训练集及测试集分布如表2所示。

表2 乳腺癌训练集测试集分布Tab.2 Test set distribution of breast cancer training set
2.3 网络超参数配置
为了选取随机森林最佳超参数集合,需要多次对随机森林参数进行调试,并从得到的超参数集合中选取最好的超参数集对模型超参数进行初始化,使模型在测试集上拥有更高的分类准确率和泛化性能。随机森林中着重需要配置的超参数分别为max_depth和n_estimators。其中max_depth为构建决策树的深度,值越大越容易过拟合,n_estimators为构建随机的个体决策树的个数。随机森林中最大迭代次数和决策树个数对深度森林分类曲线如图2。
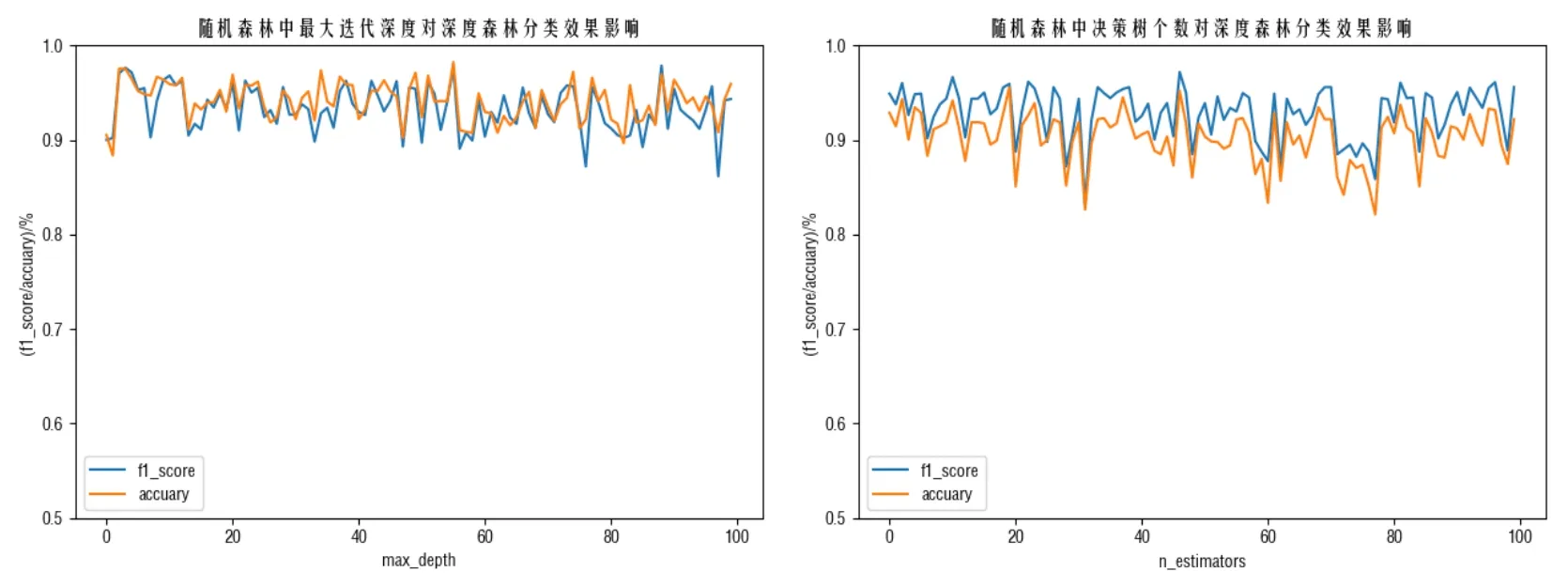
图2 随机森林中最大迭代次数和决策树个数对深度森林分类曲线Fig.2 The relationship between the maximum number of iterations and the number of decision trees in a random forest to the depth forest classification curve
由图2不难看出,随机森林的最大迭代深度和个体决策树个数能较大地影响深度森林的分类性能,所以对于最大迭代深度和个体决策树个数的选择需要选取使得深度森林分类效果最好的极点值。网格搜索是一种基于穷举的调参手段,在所有的候选参数中通过循环遍历,尝试每一种可能性,并从中找出表现最好的参数。经网格搜索之后得到的最优max_depth和n_estimators如表3。

表3 深度森林超参数配置Tab.3 Super parameter configuration of deep forest
2.4 实验结果及对比分析
为了更好地验证深度森林的模型性能,本文通过将乳腺癌肿瘤数据分别输入已经训练好的支持向量机、决策树和深度森林,其中支持向量机和决策树均采用模型自带值初始化,采用准确率和F1-度量评价指标对每个模型的性能进行评估。不同模型算法得到的乳腺癌肿瘤数据良恶性分类对比结果如表4,三种不同模型算法得到的乳腺癌肿瘤数据就良恶性分类评价曲线如图3。
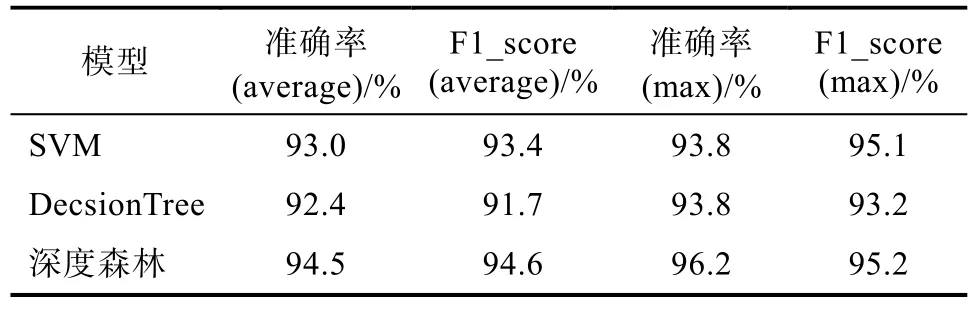
表4 乳腺癌肿瘤数据良恶性分类对比结果Tab.4 Comparison results of benign andmalignant breast cancer data
图3 乳腺癌肿瘤数据就良恶性分类评价曲线Fig.3 Classification curve of benign and malignant breast cancer data
由表4可知三种算法的准确率和f1_score的均值及最大值均大于90%,说明对于二分类问题来说三种算法都能有较好的分类预测效果,其中深度森林拥有最好的分类性能,最高分类准确率达 96.2%,出现这样的情况是由于乳腺癌肿瘤数据集的数据不均衡问题,支持向量机和决策树这两个算法不能很好地解决数据不均衡问题,而深度森林由于其有随机抽样算法使其获得了更好地分类准确率。从图3中在乳腺癌肿瘤数据良恶性分类曲线可以看出深度森林的分类性能明显好于另外两种分类器,且在综合评价指标f1_score上具有明显优势。
综合上述实验结果,深度森林在乳腺癌肿瘤良恶性分类预测上的模型性能要优于支持向量机和决策树模型。
3 结论与展望
本文针对当前医疗领域乳腺癌肿瘤分类预测中浅层机器学习算法无法对肿瘤数据的特征属性进行深度挖掘和常规肿瘤数据中特征属性较少的问题,利用深度森林中的随机抽样方法对原始如数进行特征变换以增强原始肿瘤数据的特征表达能力,然后通过级联森林结构对增强特征进行逐层表征学习,获取肿瘤数据原始特征中无法表达的高维属性,达到提高分类乳腺癌肿瘤良恶性准确率的目的,更好更高效地提高乳腺癌良恶性诊断水平。实验结果表明,基于深度森林的乳腺癌肿瘤良恶性分类准确率及 f_score均好于支持向量机和决策树算法。在医疗领域中对乳腺癌肿瘤良恶性辅助诊断上有较大帮助。然而,该算法的预测性仍然没有到达完全准确判断乳腺癌肿瘤良恶性分类的结果,所以下一步将研究如何改进深度森林算法以进一步提高该算法的分类预测性能。
