应用Sentinel-2A卫星遥感影像估测森林蓄积量
2021-07-30庞晓燕刘海松年学东张志超李崇贵董相军
庞晓燕 刘海松 年学东 张志超 李崇贵 董相军
(内蒙古自治区林业监测规划院,呼和浩特,010031) (西安科技大学) (内蒙古自治区克什克腾旗白音敖包机械防火站)
森林蓄积量是衡量一个国家或地区森林资源的重要指标,也是制定林业经营方案、实现森林资源可持续发展的重要依据。及时掌握森林资源现状及其发展变化趋势是林业科技工作者关注的热点。传统森林蓄积量调查方法主要有标准木法、采集表法等,需要进行大量的野外调查,费用昂贵、耗时费力[1]。随着3S技术的快速发展及应用,国内外林业科技工作者对森林蓄积量估测进行了大量的研究试验,但多应用在县/林业局或林场级尺度上,而在小班尺度的应用研究较少[2-5]。国内外学者多用Landsat TM系列、Modis、SPOT5、资源三号、高分系列等遥感数据进行森林蓄积量估测,利用Sentinel-2A遥感影像进行蓄积量估测只有少量的报道。
Sentinel-2A卫星是全球环境与安全监测(GMES)计划的第2颗卫星,采用的多光谱成像仪。卫星遥感影像依据光谱带的不同,空间分辨率分为10、20和60 m,从可见光、近红外到短波红外覆盖了13个谱段,其中包含的3个红边波段是植被长势监测的理想数据源。3个红边波段在全球环境变化、农作物生长监测、森林监测、灾害应急与救援等方面具有重要价值[6]。何云等[7]利用Sentinel-2A影像结合随机森林方法对中南半岛穆河流域的东南部区域对土地覆盖进行了分类,分类精度达到87.53%,Kappa系数达到0.8461;陈瑜云[8]应用三个时期Sentinel-2影像数据对毛竹林区分大小年进行生物量了估测,实验表明7月数据的RF模型精度最高,总体样本验证R2为0.46,均方根误差为10.68 Mg/ha,相对均方根误差为19.09%;韩涛等[9]针对Sentinel-2A与Landsat-8数据在油菜识别方面的差异性进行了研究,结果表明Sentinel-2A数据能够在种植结构复杂的小尺度区域提取更高精度的作物分布信息;苏伟等[10]利用Sentinel-2A影像对玉米冠层叶绿素进行估算,表明引入红边波段后玉米冠层叶绿素含量的估算精度的决定系数为0.796;高璐璐[11]基于Sentinel-2A数据反演低山丘陵区苹果树冠层叶绿素含量,研究表明以植被指数建立的支持向量机反演模型较好,决定系数为0.729。综上所述,Sentinel-2A数据在不同的领域的应用均取得了良好效果。
本研究以内蒙古自治区某林业局的数据(包括:一类清查样地数据、二类调查小班数据、数字高程模型(DEM)以及林地数据)和Sentinel-2A影像为数据源,采用k-近邻(k-NN)法、稳健估计法及偏最小二乘法,以样地大小为单位,分别按照针叶林、阔叶林和针阔混交林等3种林型构建的森林蓄积量估测模型,并从林业局、林场和小班等3个尺度讨论应用Sentinel-2A影像进行森林蓄积量估测的可行性。
1 研究区概况
研究区位于内蒙古自治区东北部,地理坐标为东经120°36′~121°46′,北纬47°5′~47°45′,属于大兴安岭兴安落叶松林区的南延部分,森林覆盖率为75%。该区域主要以兴安落叶松(Larixgmelinii(Rupr.) Kuzen)为主,同时生长有白桦(BetulaplatyphyllaSuk.)、山杨(Populusdavidiana)、黑桦(BetuladahuricaPall.)、蒙古栎(QuercusmongolicaFisch. ex Ledeb)等树种。森林类型主要以蒙古栎、黑桦、白桦和兴安落叶松组成的针阔混交林。
2 研究方法
2.1 数据获取与处理
数据来源于研究区2018年森林资源连续清查固定样地数据和依据2016年二类调查小班数据系统布设的解译样地。2018年一类清查样地数据为0.06 hm2的长方形(10 m×60 m)样地,样地长边为南北方向,样地坐标采集点位于样地中心,样地总数为55个,有林地43个,无法满足依据林地类型进行建模估测的需求,故参照一类样地的大小和形状在试验区内按照4 km×4 km的间距布设解译样地,将解译样地所落小班的公顷蓄积乘以0.06推算各个样地的蓄积。综合两类样地数据共得到175个有林地样地,其中针叶林样地63个,阔叶林样地80个,针阔混交林样地32个。
遥感影像采用Sentinel-2A卫星遥感影像,成像时间为2016年8月28日。Sentinel-2A的Level-1C数据经过了辐射校正、几何校正、正射校正和亚像素精度全球参考系统的空间配准[12]。先利用Sen2Cor对影像数据进行大气校正,在利用SNAP软件进行重采样处理,将所有波段全部重采样至分辨率为10 m,最后利用ENVI5.3SP1的Layer Stacking将影像数据波段2~波段8A进行组合,获得具有8个波段的遥感影像[11-12]。将样地数据叠加到遥感影像上,即可提取样地范围对应的遥感信息(见图1)。
数字高程模型采用在地理空间数据云下载的30 m分辨率的DEM数据,用于获取研究区域的坡度和坡向信息,并作为可能影响蓄积量估测的地形因子参与建模。利用ArcGIS10.1将研究区2017年林地数据生成林型分布图,包括针叶林、阔叶林和针阔混交林等3种类型(见图2)。
2.2 蓄积量估测模型构建方法
设在监测区域共计布设了n个样地,每个样地设置了可能影响蓄积量估测的p个自变量X1,X2,…,Xp,每个样地就是p维欧式空间中的一点。将n个样地展绘在校正好的遥感影像上,提取样地对应的遥感影像各波段的灰度信息,并构造比值波段。考虑地形信息,得到可能影响蓄积量估测p个自变量因子的值。经过最优变量选择和建模样地抽样后,依据所抽样地分林地类型建立以样地大小为单位的蓄积量估测模型。将遥感影像转换为以样地大小为单位的影像,结合DEM数据获取各样地大小单元对应的自变量值,代入估测模型计算每个样地大小单元对应的蓄积量[4-5,13]。在针对不同林地类型构建蓄积量估测模型时,本文选用稳健估计法、偏最小二乘估计法和k-近邻法等3种方法建立模型。
稳健估计法:稳健估计对异常样地具有较好的抗干扰能力,能够有效消除异常值的影响,确保模型具有良好的稳定性。
按照一定的比例,随机抽取m个样地参与建立估测模型,用其余n-m个样地来检验模型的预报精度,假设单个样地蓄积量v与其对应的q个自变量之间存在如下线性关系:
v=β0+β1X1+β2X2+…+βqXq。
故m个样地蓄积v与q个自变量之间的关系可以表示为:
V=Xβ+eV,
E(eV)=0,
Cov(eV)=σ2I。
式中:V为因变量矩阵,V=(v1,v2,…,vm)′;β是待定参数向量,β=(β0,β1,…,βq)′;σ2为样地蓄积量估测方差;eV是m个样地蓄积量的观测误差向量,eV=(eV1,eV2,…,eVn)′;I为m阶单位阵;X是m个样地对应q个变量因子组成的自变量矩阵
则误差方程表示为:
eV=Xβ-V。
稳健估计用误差的绝对最小值作为稳健估计的极值函数,以便减弱异常样地的影响,此时需满足下式要求。
式中:ρ(ei)是极值函数。
建立稳健估计蓄积量估测模型的重点是选用增长速度缓慢的有界函数作为极值函数,从而有效控制异常样地对蓄积量估测模型中待定参数的影响。以ρ(e)=|e|为例,采用1-范数作为极值函数。本文采用如下迭代函数法进行求解。
Xiqβq-vi|。
利用迭代法求解稳健估计模型中待定参数最优解,其步骤如下:
③构建法方程(X′W)(1)Xβ=X′W(1)V;
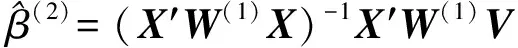

偏最小二乘法:偏最小二乘估计集多元逐步回归分析,主成分分析和典型相关性分析的基本功能于一体,不仅能够从自变量集中选取具有最佳解释能力的新综合变量,克服多重相关性造成的不利影响,还能够有效区分系统中的信息和噪声,提高型模的可靠性[15-16]。
偏最小二乘估计建模步骤如下:(1)设参与建模的m个被抽样地蓄积量组成的向量为V,每个样地p个自变量组成的观测矩阵为Xm×p;(2)提取观测矩阵X的一个主成分t1(t1是x1,x2,…,xp的线性组合),要求t1不仅需要尽可能多地携带X中的变异信息,还要与V的相关性最大;(3)提取第1个主成分后,求出V和X对t1的回归方程。若此时回归方程达到精度要求,则算法停止,否则,需利用X和V被t1解释后的残余信息进行第2轮主成分提取,如此反复,直至满足精度要求为止。若最终对X提取了q个主成分t1,t2,…,tq,偏最小二乘回归将变为V对q个主成分的回归,据此再求出V对原变量X的回归方程[14,17]。
k-近邻法(k-NN):k-NN法是一种典型的非参数化方法,核心思想是根据多维特征空间中待估测点与已知点之间的空间相似性进行单变量或多变量估测,相比于通过参数化方法的回归分析建模,k-NN方法能够更多的考虑蓄积量与自变量之间的非线性依赖关系,不受自变量间存在复共线性的影响[17-18]。估测公式如下:

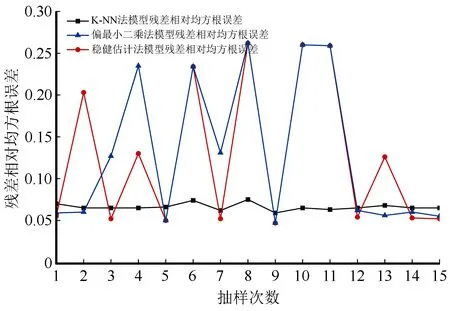
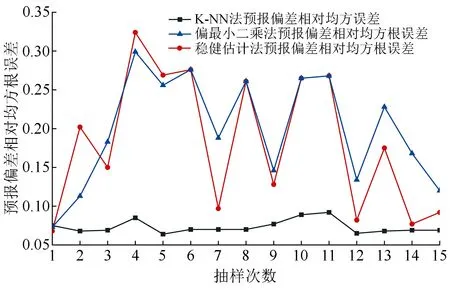
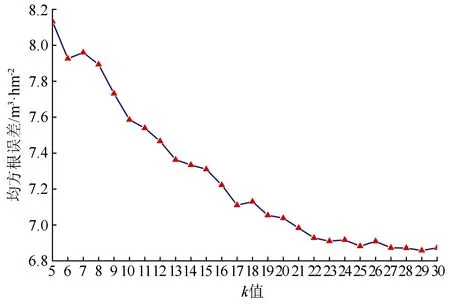
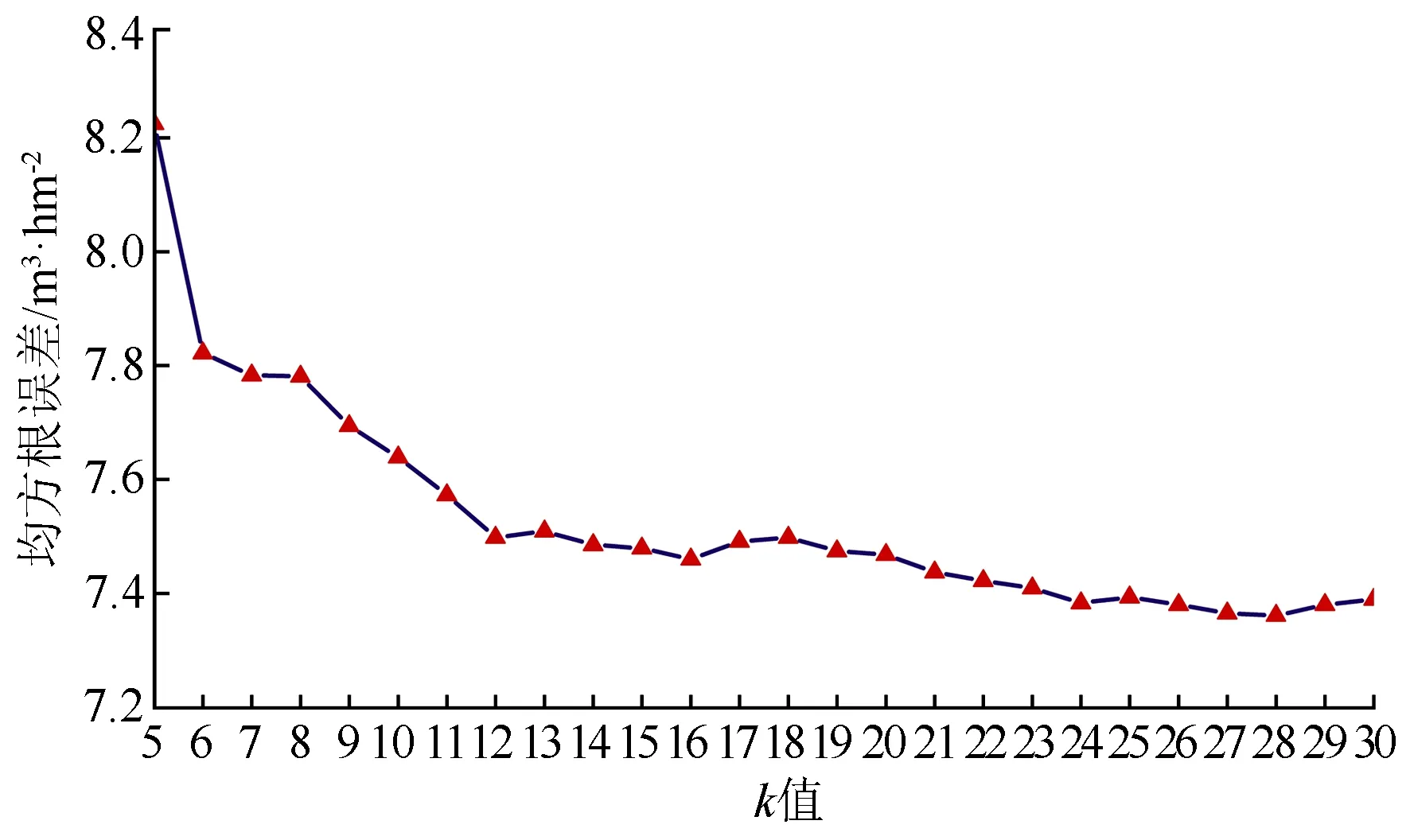
在光谱空间中找出与待估测单元最邻近的k个样地,其中p1,p2,…,pk,其中Dp1,q 可能影响蓄积量估测的自变量主要包括影像波段灰度信息、比值波段和地形信息三种类型。影像波段灰度信息包括Sentinel-2A影像B2~B8、B8A共8个波段光谱的反射率信息。地形信息包括阴坡、阳坡和坡度。比值波段分为传统光谱特征指数(归一化植被指数、增强型植被指数、差值植被指数、改进红边归一化植被指数、简单比值植被指数)和红边光谱特征指数(红边差值植被指数、红边归一化植被指数、修正型叶绿素吸收反射率指数、特征色素简单比值指数、差值植被指数45)[8-12,20-21]。 Sentinel-2A数据包含3个红边波段,参考现有资料,中心波段在705 nm处的反射率与叶绿素含量间的相关性优于740 nm和783 nm处的反射率,因此本文红边光谱特征指数除PSSRa外,均选取波长为705 nm的波段作为红边波段[11-12]。比值波段构造公式如表1所示。 表1 植被指数的计算公式 参与建模的变量并不是越多越好,有些变量可能对蓄积量估测影响较小甚至没有影响,有些变量之间可能存在复共线性。过多的变量会造成数据冗余,在增大计算量的同时,也会影响模型预报精度。本文采用平均残差平方和准则和穷举算法对以上提及的21个变量进行建模变量优选[15,17,22-23]。平均残差平方和表达式为: 式中:q为建模变量个数;V为因变量向量;X为观测阵。 按照建模样本与验证样本7∶3的比例对样地进行随机抽样,然后依据建模样地进行最优变量选择,最后采用k-NN法、稳健估计以及偏最小二乘估计等3种方法分林型进行建模。建模过程重复进行15次,以此来减少随机抽样给建模效果带来的偶然性影响(见表2和图3、4)。 表2 3种估测方法建模综合评价 由表2、图3~4可知,k-NN法建模稳定性较好,随机抽样不会对建模效果带来较大影响,而稳健估计法和偏最小二乘法建模效果波动性较大,随机抽样带来的偶然性影响较大。 图3 各模型残差相对均方根误差 按照模型残差相对均方根误差与预报偏差相对均方根误差相近且两者都在一倍标准差范围内的原则,对15次抽样建模结果进行筛选,分别挑选出3种方法各自最具代表性的蓄积量估测模型。 图4 各模型预报偏差相对均方根误差 k-NN法选取第12次所建模型,最优变量为:绿光波段(B3)、近红外波段(B8)、窄边近红外波段(B8A)、红边差值植被指数和增强型植被指数; 稳健估计法选取第13次所建模型,最优变量为:植被红边1波段(B5)、近红外波段(B8)、归一化植被指数、简单比值植被指数、坡度和阴坡; 偏最小二乘选取第3次所建模型,最优变量为:绿光波段(B3)、红光波段(B4)、植被红边1波段(B5)、近红外波段(B8)、改进红边归一化植被指数、归一化差分指数、红边归一化植被指数、简单比值植被指数和阴坡,各模型精度如表3所示。 表3 各模型精度 如图5~7所示,对k取不同值时的均方根误差计算结果进行分析,针叶林、阔叶林、针阔混交林蓄积量估测模型的最佳k值分别为29、28和17。 图5 针叶林蓄积量估测模型k取不同值时的均方根误差 采用稳健估计法所得估测方程如下: 0.087 289×P+0.062 703×ISR-0.0.377 512×Py+2.388 314; 式中:P表示坡度;Py表示阴坡。 图6 阔叶林蓄积量估测模型k取不同值时的均方根误差 图7 针阔混交林蓄积量估测模型k取不同值时的均方根误差 采用偏最小二乘估计所建估测方程如下: 式中:Py表示阴坡。 利用Sentinel-2A遥感影像和DEM数据获取各样地单元对应自变量的取值,并代入模型估测各单元对应的蓄积量估测值,获得研究区域森林蓄积量分布(见图8),再利用积分法统计林业局、林场和小班等3个尺度的蓄积量估测值。随机抽取研究区域内5%的有林地小班(699个)用于小班尺度的估测精度分析,并以二类调查小班数据为标准进行检验,结果如表4所示。 图8 森林蓄积量估测等级分布图 表4 不同尺度下估测精度比较 由表4可知,k-NN方法在3个尺度中的估测效果均明显优于其他两种方法,对于3种尺度的森林蓄积量估测均能满足精度要求,而稳健估计法和偏最小二乘法在小班尺度的估测精度较差。 本文运用Sentinel-2A卫星影像提取样地范围的波段灰度信息并构造比值波段,结合样地数据和地形信息,建立以样地为单位的森林蓄积量估测模型,对研究区的森林蓄积量进行反演,所得结果如下:(1)非参数化方法k-NN法在林业局、林场和小班等3个尺度中的估测精度分别达到了97.0%、93.2%和83.6%,均表现出良好的估测效果,明显优于其他两种参数化方法。(2)稳健估计和偏最小二乘估计的估测精度相差不大,均不能满足小班尺度蓄积量调查的精度要求,如何提升这两种方法在小班级尺度上的蓄积量估测精度有待进一步研究。(3)多次抽样建模发现,k-NN法具有较好的建模稳定性,而稳健估计法和偏最小二乘法的建模效果波动性较大;若采用参数化方法进行建模,实际生产应进行多次抽样以提高估测模型的稳定性。
2.3 自变量设置与优选

3 模型评价及精度检验
3.1 不同建模方法的综合评价

3.2 不同建模方法的最优模型


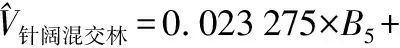

3.3 不同模型对蓄积量的估测结果与不同尺度的精度


4 结论
