时变工况下行星轮轴承特征分布拟合与智能故障诊断
2021-07-22冯志鹏
赵 川, 冯志鹏
(1. 北华航天工业学院 机电工程学院,河北 廊坊 065000; 2. 北京科技大学 机械工程学院,北京 100083)
行星齿轮箱在工业与航空等领域应用广泛,但工作环境中存在多种因素容易对其零部件(齿轮、轴承等)造成不良影响导致发生损伤或失效,严重时会造成重大损失。文献[1]指出由轴承缺陷引起的故障和平均停机时间占整个齿轮箱缺陷和总停机时间的 60% 以上。因此,对行星轮轴承故障诊断的研究具有重要意义。
在实际应用中,行星轮轴承运动比定轴轴承更为复杂,一般的定轴轴承故障诊断方法很难适用[2];加之行星齿轮箱转速与载荷通常具有时变性,信号中的故障特征频率也随时间发生变化,使得发掘信号中的故障信息变得更为困难[3]。对于时变信号,通常采用时频分析法来研究信号中的特征频率成分以及频率随时间变化的规律。但在应用时频分析方法对时变工况下行星齿轮箱信号进行分析时,发现存在时频分辨率低与虚假成分干扰等问题,给故障特征的提取与识别造成困难。为解决该问题,相关学者进行了进一步的研究[4-9],基于广义解调与同步压缩变换、相角的熵特征、阶次谱分析、自适应线性调频模式分解等理论,提出多种时变工况下行星齿轮箱故障诊断方法。以上研究有助于在非平稳条件下对行星轮轴承进行故障诊断,但是大多数工作涉及专家知识,并依靠数据分析人员来人工识别故障特征频率,主观因素可能会影响故障诊断的准确性。
针对上述局限性,研究人员开展了相关的智能故障诊断研究。在近期的研究中,Zhang等[10]提出抗干扰深度卷积神经网络模型,用于处理强噪音与不同负载环境下轴承的故障诊断问题。Shao等[11]基于压缩传感,改进了卷积深度置信网络模型,并用滚动轴承故障数据进行了验证,研究表明提出的模型提高了数据分析效率,增强了压缩数据的特征学习能力,与传统方法相比具有一定的优越性。Jia等[12]将特征提取与故障识别融合到一个模型中,用归一化的稀疏自编码器学习特征,后经特征层处理获取移不变特征,最后在输出层进行模式识别。经齿轮与轴承数据验证表明,该模型提取的特征具有独立的意义,增强了特征模式识别性能,具有一定的优越性。Ding等[13]利用局部多项式拟合和基于稀疏性的算法以及阶次跟踪技术来提取时域瞬态特征,并将非平稳瞬态特征转换为角域中的平稳特征以进行故障诊断。但是,大多数智能诊断方法主要用于处理稳定工况下的故障诊断问题,且是对一维信号进行分析,提取特征;提取的特征通常为原始信号在低维度的抽象,没有显式的表达,缺乏可解释性与可控性。而赋予特征显式的表达与意义,能够更具体地描述特征,并且通过对其显式的表达进行变换或控制更容易实现对特征的优化,从而提高特征的聚类性能与模式识别准确率。因此,如何采用相关方法提取时变特征,同时赋予特征显式意义,强化不同类别特征间的差异性需要进一步研究。
近来,生成模型因为能够自适应提取特征,通过已知的分布对隐变量(即特征)进行拟合从而赋予特征显式的表达而受到越来越多的关注[14-17],并开始应用到故障诊断领域[18-19]。Wang等[18]将生成对抗网络(generative adversarial network, GAN) 和堆叠式降噪自动编码器组合在一起以生成新样本来扩展样本集,解决了故障诊断中的小样本问题。Zhao等[19]将变分自动编码器 (variational auto-encoder, VAE) 引入故障诊断框架,使用来自高斯分布的隐变量生成人工振动信号,与真实信号混合,增强样本集,然后结合卷积神经网络提出了一种增强的故障诊断方法,解决了故障诊断中小样本与样本不平衡问题。但上述研究主要针对故障诊断中的小样本问题,模型对于非平稳信号的适应性以及在特征分布拟合方面的应用还有待进一步研究。因此,在非平稳状态下行星齿轮箱的智能故障诊断仍然是一个具有挑战性的问题。
为了能够自适应提取时变工况下行星轮轴承的信号特征,进行行星轮轴承智能故障诊断,本文构建了基于对抗变分自编码的智能故障诊断模型。首先,获取样本时频图,为简化模型输入结构,对时频图进行二值化处理;构建多维独立高斯分布,并进行采样,根据类别信息,对样本进行变换使其服从新的分布;利用变分自编码模型提取的特征与变换后的对应类别的采样样本对判别器进行训练,从而实现利用已知的先验分布拟合未知的特征分布,赋予特征显式的意义,并通过控制分布强化不同类别特征间的差异;最后利用优化后的特征对分类器进行训练,通过测试数据验证其性能。整体实现流程如图1所示。
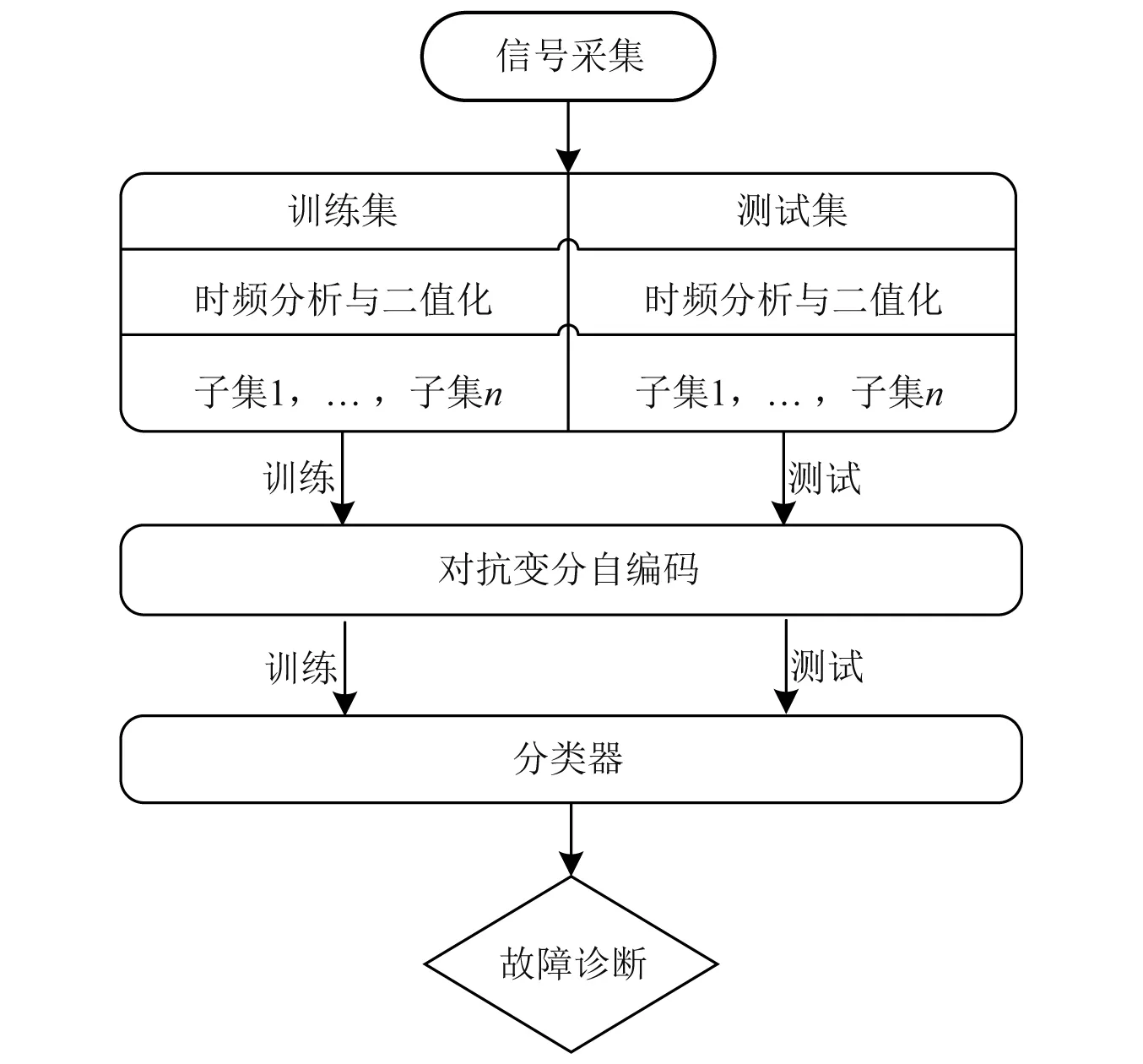
图1 故障诊断过程
1 自编码与对抗生成网络
变分自编码器是对自编码器 (auto-encoder, AE)的改进与升级。AE本质是以一种无监督的方式自适应地提取非线性特征。图2展示了多层自动编码器的深层网络结构。其中,编码器部分旨在从输入数据生成隐变量表示,而解码器部分用于根据隐变量重构输出,使其尽可能接近原始输入[20]。如图2所示,该结构具有输入层,2r-1个隐藏层以及输出层。输入数据表示为向量x=[x1,x2,…,xm]T,输出向量表示为u=[u1,u2,…,um]T,其中m为输入与输出层神经元个数。
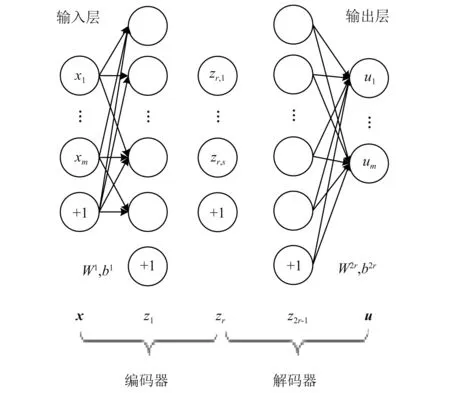
图2 自编码网络结构
第k个隐含层的向量为zk=[zk,1,zk,2,…,zk,s_k]T,其中s_k为第k层的神经元个数为s。每一层的激活计算可按式 (1) 进行。
(1)
与AE不同,GAN的本质是以一种简单的方式从潜在空间生成与真实数据近似的样本,并使生成样本服从与真实样本相同的分布。在GAN模型中,生成器G从潜在空间生成新样本,而判别器D则将生成样本与训练样本区分开。具体地,生成器利用函数G(z) 欺骗判别器D(x),使判别器认为生成的样本来自训练集,而判别器则尝试正确识别生成样本。经过训练,生成器生成的样本与训练数据近似。图3给出了一个GAN的结构。

图3 对抗生成网络结构
对抗过程损失函数可通过目标函数式 (2) 进行计算。
(2)
式中:E为期望;pdata(x) 与p(z) 分别为x与z服从的概率分布情况;D(x) 为判别器的输出结果,用于判断判别器输入为x的概率。目标函数一方面希望当把真实数据放入判别器后,输出的概率值与目标函数值最大,另一方面希望找到最优的生成函数G(z),使得目标函数值最小,因而二者进行对抗。最后,使用交替随机梯度下降法来进行训练,直到收敛。
2 对抗变分自编码
2.1 变分自编码
Kingma等[22]提出变分自编码思想,揭示了输入数据与隐变量间分布的映射关系,改善了AE由于单值映射而造成的过拟合问题。变分自编码器 (variational auto-encoder,VAE) 结构如图4所示。
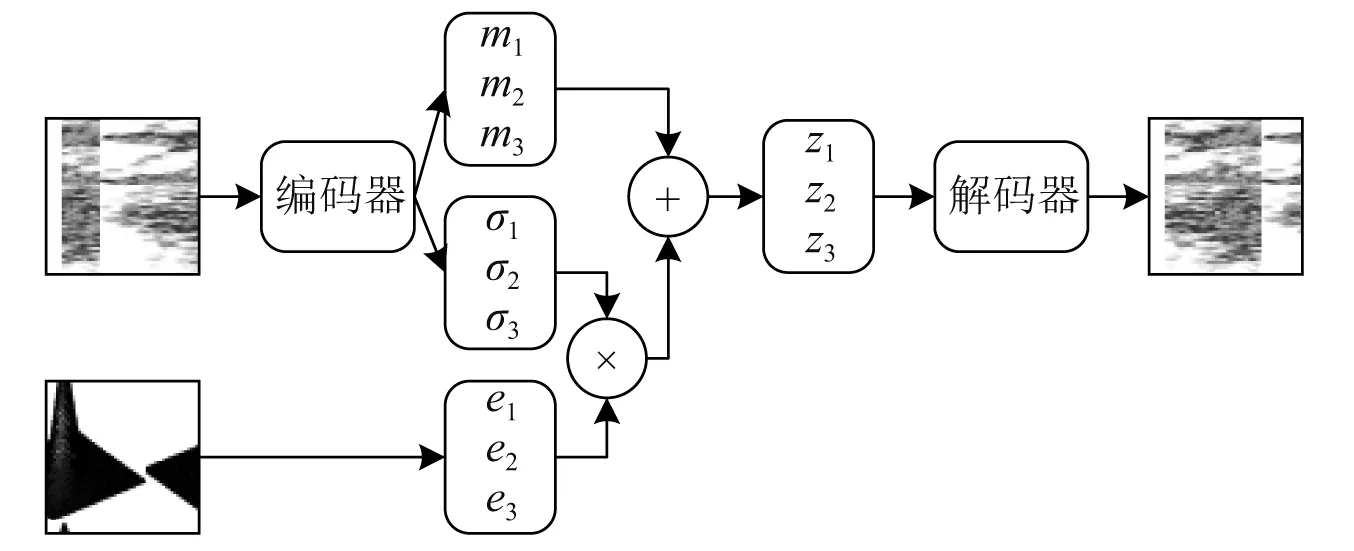
图4 变分自编码网络结构
在AE中,当训练得到解码器后,我们希望输入一个编码,通过解码器生成一张图片,但实际上仅仅通过自编码器得到的结果并不好。研究表明,变分自编码器能够提升编码器对图片的重构效果。在VAE中,编码器与解码器过程不变,编码器输出两个向量,不妨设定编码维数为3,则两个向量分别为(m1,m2,m3)与(σ1,σ2,σ3),此外再从高斯分布中采样 (e1,e2,e3),通过式(3)计算隐变量(z1,z2,z3),通过解码器获取输出,使重构误差更小。
zi=exp(σi)×ei+mi
(3)
2.2 多维独立高斯分布
在自编码模型中,如果编码器产生的隐变量服从高斯分布,即z~N(μ,σ),则可实现分布的映射。从N(μ,σ)采样输入解码器,可以重构原始数据。但采样操作对μ和σ不可导,导致通过误差反向传播的梯度下降训练法无法使用。因此,VAE给定了一个标准正态分布N(0,1),并从该分布采样e,使得z=exp(σ)×e+m,从而实现z~N(μ,σ)。此时,从编码器输出到z,只涉及线性操作,而且e对于神经网络而言只是常数,因此,可以正常使用梯度下降训练法进行优化。
但对于多类别输入,变分自编码中的标准正态分布只是使得编码器输出的隐变量服从正态分布N(μ,σ),特征分布由未知变为已知,进一步规范了特征,而不同类别特征间的差异性却并没有得到明显强化。因此,该方法对特征模式识别性能的改善比较有限。
针对该问题,本文构建了多维独立高斯分布,以使提取的每个隐变量 (即特征向量的每个元素) 都有自己的专属分布,从而实现用已知分布拟合特征的未知分布,赋予特征显式意义,也为通过控制已知分布来强化不同类别特征间的差异性提供可能。设p维的随机向量为O=[o1,o2,…,op]T,且有密度函数如式(4)所示。
(4)
式中:μ为p维向量;H为p阶正定对角矩阵;detH为H的行列式,则称O服从p维独立高斯分布,记为O~Np(μ,H)。
这里以二维独立高斯分布(p=2)为例,不妨给定参数μ=[0, 0]T,H=[0.5,0; 0,0.1],然后从该分布采集b个样本,样本点记为(o1k,o2k),k=1,2,…,b,则o1与o2分别服从一维高斯分布N(0,0.5)和N(0,0.1)。为了能够使采集的b个样本约束n类特征,通过式(5)、式(6)将其分成与类别信息相关的n组
(5)
(6)
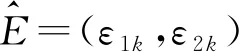
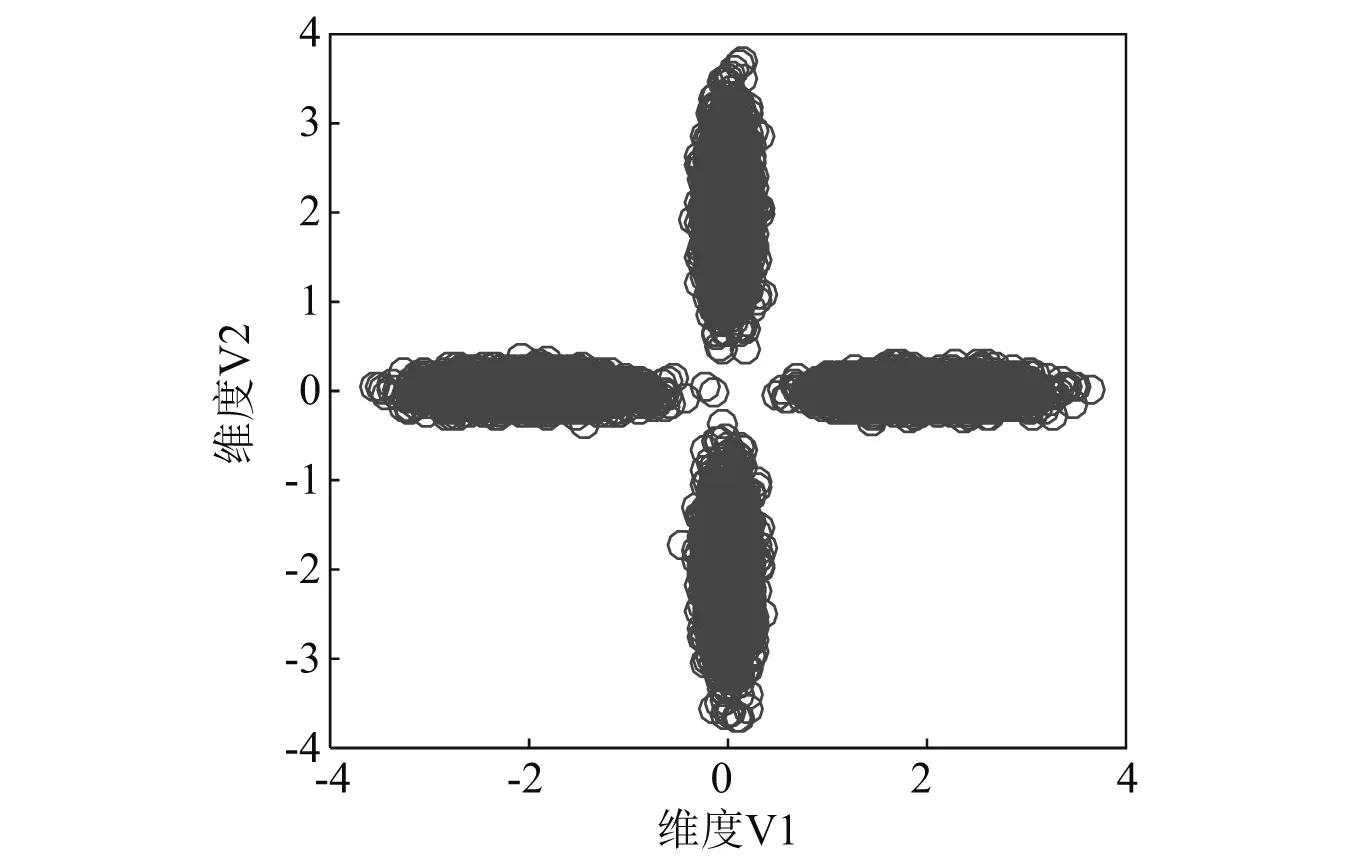
图5 从分布Np(A μ, AHAT) 采集的样本(n=4,b=4 000)
2.3 对抗变分自编码与模式识别
为了便于理解模型,将特征可视化。引入二维独立高斯分布 (p=2),通过对抗学习,用已知的二维高斯分布拟合未知的特征分布,使得不同类别的特征具有专属分布,计算过程如图 6 所示。
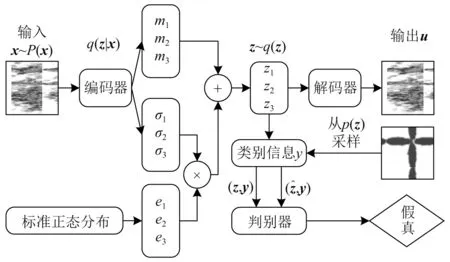
图6 对抗变分自编码模型
在图 6 中:x表示输入向量,假定服从分布p(x);z为隐变量向量,如果将编码器分布表示为q(z|x),则可以根据式(7)计算后验分布q(z)。
(7)
由于p(x) 未知,因而无法对q(z) 进行显式的表达。对抗变分自编码旨在用已知的分布p(z) 拟合分布q(z),同时最小化VAE的重构误差。判别器用于确定样本来自哪个分布。如果样本来自p(z),则判别器将认为它是真实样本,并且输出为 1,否则输出为零。同时,作为对抗网络的生成器,VAE不断更新并试图欺骗判别器以给出错误的结果。
具体地,将信号的时频图数据输入编码器,并通过标准正态分布给隐变量增加噪声。将隐变量、二维独立高斯分布的采样样本分别与相应的标签信息融合,形成复合向量。与常规对抗网络输入不同,这里以高斯分布的复合向量为真,隐变量复合向量为假,对判别器进行训练,从而使得隐变量受到专属分布的约束。之后,提取训练集的特征来训练分类器。在训练多维独立高斯分布对抗变分自编码器和分类器之后,将使用测试样本来测试整个框架及其性能。
针对时变工况下行星轮轴承故障信号,模式识别具体处理过程如下:
步骤1样本分类。将时变工况下行星轮轴承信号样本分为训练集与测试集,每个样本集包含四类样本,分别对应正常(状态1)、外圈损伤(状态2)、滚动体损伤(状态3)与内圈损伤(状态4)等状态。
步骤2信号处理。采用短时傅里叶变换 (short time fourier transformation, STFT) 法获取样本时频图,并根据最大类间方差法[23]进行二值化处理,从而简化模型输入结构,便于特征提取。
步骤4softmax分类器训练。用提取的训练样本的特征训练分类器,提取所有测试样本特征,测试分类器性能,最终识别行星轮轴承故障。
3 实验信号分析
3.1 实验说明与信号采集
行星齿轮箱实验台基本组成如图 7 所示,驱动电机与齿轮箱之间通过速度传感器连接,负载由电磁制动器提供 (实验中为零负载),数据采集系统用于检测齿轮箱运行状态,对信号进行测量与保存。相关齿轮箱参数如表1所示。

图7 实验系统平台

表1 行星齿轮箱齿轮参数
为模拟行星轮轴承故障,分别对外圈、某一滚动体、内圈进行人工处理,形成剥落损伤,损伤尺寸如表2所示,实物如图8所示。由此可形成时变工况下的四种运行状态:①基准——状态1,所有零件无损伤;②外圈损伤——状态2,只一个行星轮轴承外圈有损伤;③滚动体损伤——状态3,只有一个行星轮轴承的单个滚动体有损伤;④内圈损伤——状态4,只有一个行星轮轴承内圈有损伤。

表2 轴承损伤尺寸

图8 轴承损伤
驱动电机转速根据分段函数式(8)进行设定,其中fmax=19 Hz。转速曲线如图9所示。分别对每种运行状态进行两次实验,采集位于齿圈上方齿轮箱箱体顶部传感器的振动信号。设置采样频率为102 400 Hz,每次实验采样时间60 s。将第一次实验的数据作为训练数据,第二次的作为测试数据。
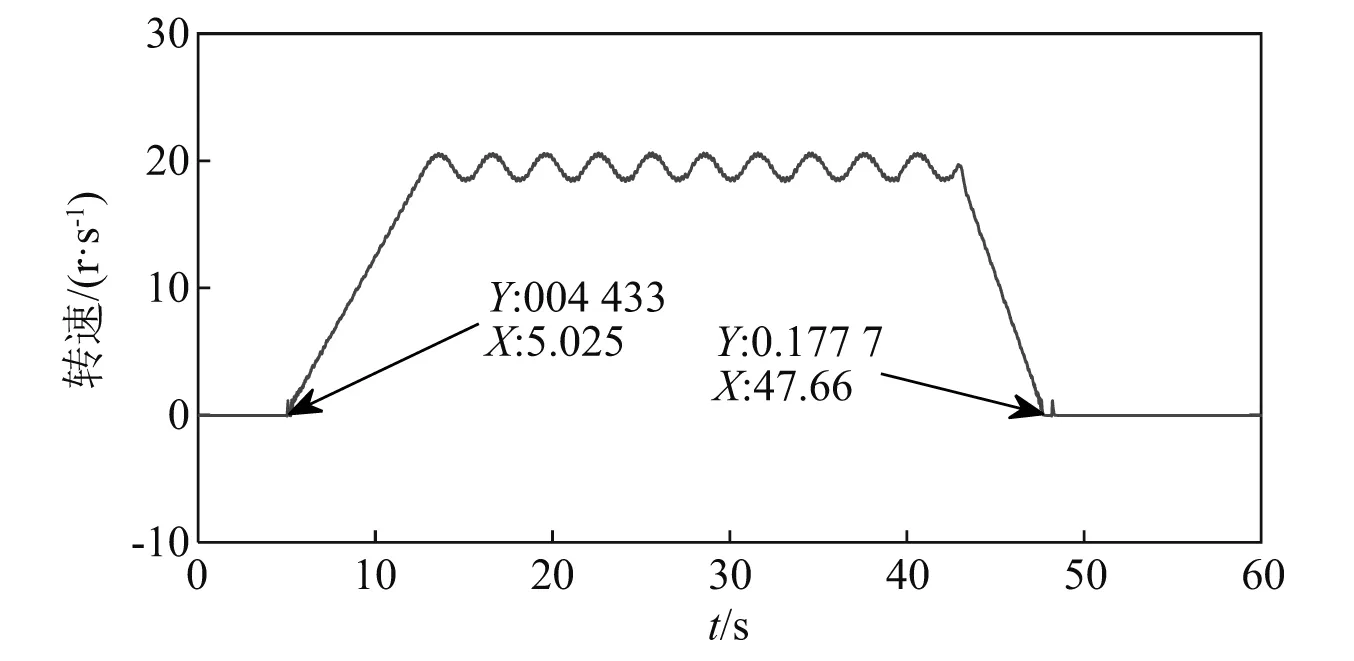
图9 转速曲线图
(8)
分析对应转速曲线5~45 s内的数据。为方便计算,对信号进行重采样,采样频率5 120 Hz,对应每种运行状态可获得两组数据,每组包含209 920个数据点。图10给出了轴承不同状态训练信号的时域波形。

图10 信号波形
采用时移的方法,将每组数据划分为150个样本,每个样本包含5 120个点,则四种状态对应训练样本总数为600,测试样本总数为600。
3.2 信号分析与参数选择
根据2.3节中模式识别的基本步骤对信号进行处理与分析。不妨选对应转速曲线第15 s内的不同状态的样本为例,样本时频图如图11所示。

图11 样本时频图
在研究中,所涉及的参数主要是批量大小,隐含层神经元数量和迭代次数。首先根据表 3 建立模型,再通过单因素分析法分析和选择适当的参数。观察当其他参数确定,只有一个参数发生变化时,该参数对模型故障诊断准确率的影响。
首先,给定批处理的大小和隐含层中神经元的数量分别为100和1 000,迭代次数预设为100,200,300,400,500。考虑到训练过程中样本选择的随机性,针对每个迭代次数,重复计算5次,选择每个状态对应的5个准确率中的最小值作为最终结果,则由迭代次数变化引起的影响结果如图12所示。

图12 迭代次数选择
根据图 12 可知,迭代次数为100和500时,模型的故障诊断准确率偏低。通过200~400次迭代,模型能够以较高准确率诊断四种状态。其中,当迭代次数为300时,模型整体的诊断准确率更高。因此,可以选择迭代次数为300。
接下来,给定神经元数量为100,迭代次数为300,预设批量大小为25,50,75,100,125。图13显示了对应不同批量大小样本数的故障诊断结果。由图13可知,当批量样本数为25和125时,模型的故障诊断准确率偏低;批量大小为50时,整体上能够以较高的准确率识别四种状态。因此,可以选择批量大小为50。
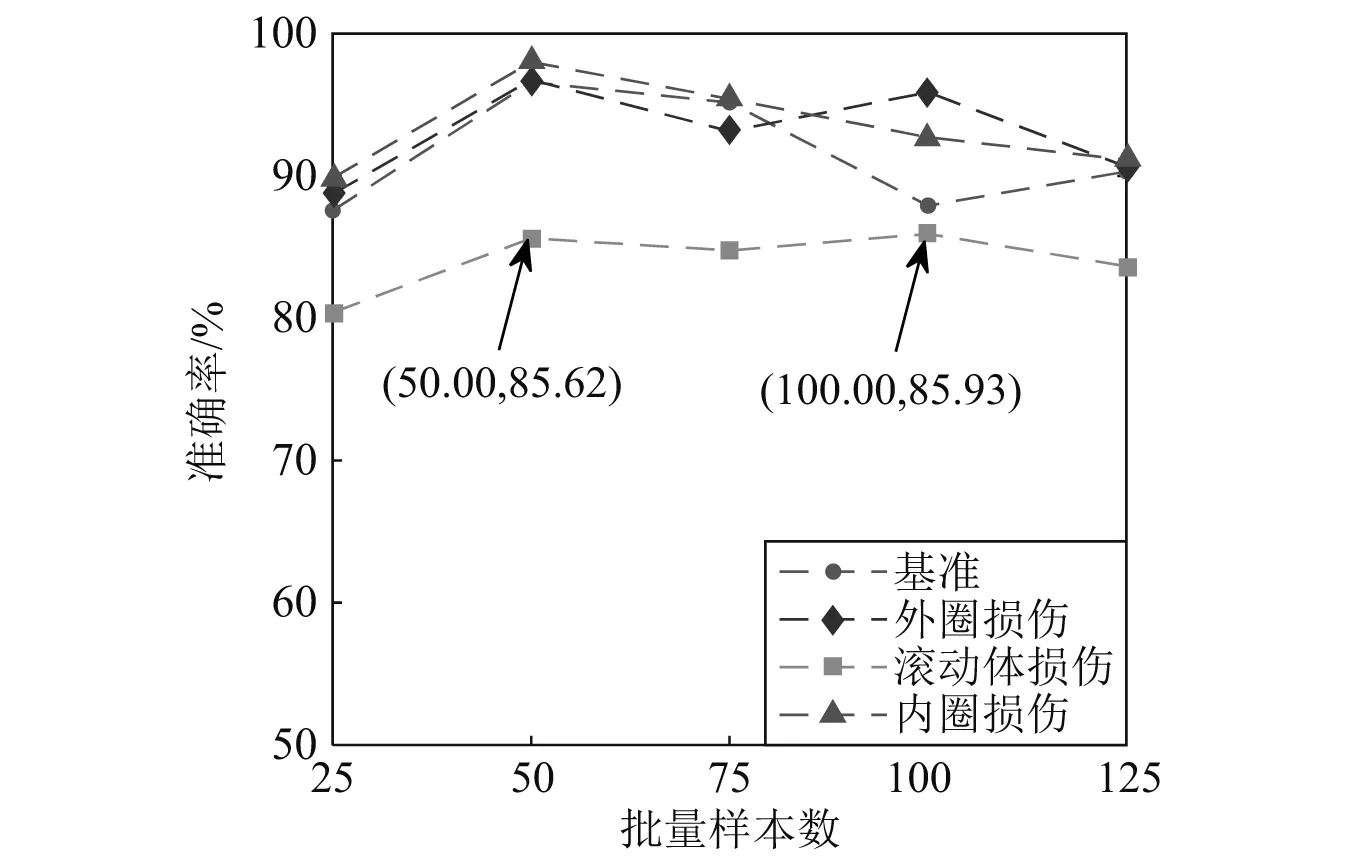
图13 批量样本数选择
最后,给定迭代次数为300,批量大小为50,将神经元数设置为250,500,750,1 000,1 250。图 14给出了不同神经元数量对诊断准确率的影响。根据图14,神经元数从500~1 250,能够以较高准确率诊断四种状态。但是随着神经元数量的增加,结果并没有变得更好。因此,为了保证计算效率,可以选择神经元数量为750。
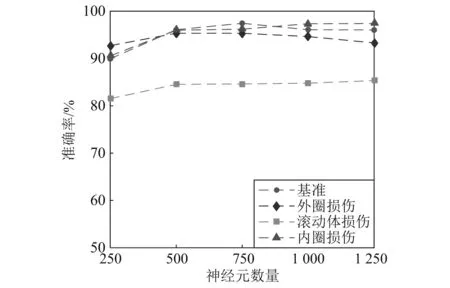
图14 神经元数量选择
根据上面的分析不难发现,模型迭代次数与批量样本数对模型故障诊断准确率有一定的影响。当参数值较小时,模型训练不充分,导致故障诊断准确率偏低;参数值较大时,模型训练产生过拟合现象,使得模型的泛化能力下降,也会导致模型故障诊断准确率降低。对于每层神经元数量而言,当参数值取较小值时,模型权值需要来回调整,不易稳定,导致诊断准确率相对偏低,而随着神经元数量的增加,权值训练则更容易快速趋于稳定,但该参数值的变化对于模型诊断准确率的影响较小。为保证计算效率与网络性能,一般在满足精度要求的前提下选择较少的神经元个数。综上所述,相关参数通常需要根据经验和实验分析确定。这里选择的参数是300(迭代次数),50(批量大小) 和750(神经元数量)。
3.3 对比分析
在本节中,将AVAE与其他两种广泛使用的方法AE和VAE进行比较。根据表3以及在3.2节中选定的参数建立AVAE模型。AE和VAE模型的网络结构参数 (包括网络层数与每层神经元个数) 与AVAE的对应部分相同,训练参数如迭代次数、批量样本数等通过单因素分析法确定。AE对应的训练参数值为300,50;VAE对应的训练参数值为700,50。在分类器部分,网络结构设置为2-250-4,标签设置为[1, 0, 0, 0],[0, 1, 0, 0],[0, 0, 1, 0]和[0, 0, 0, 1],分别对应于状态1,2,3,4。为了观察提取的特征,将特征可视化,如图15所示。
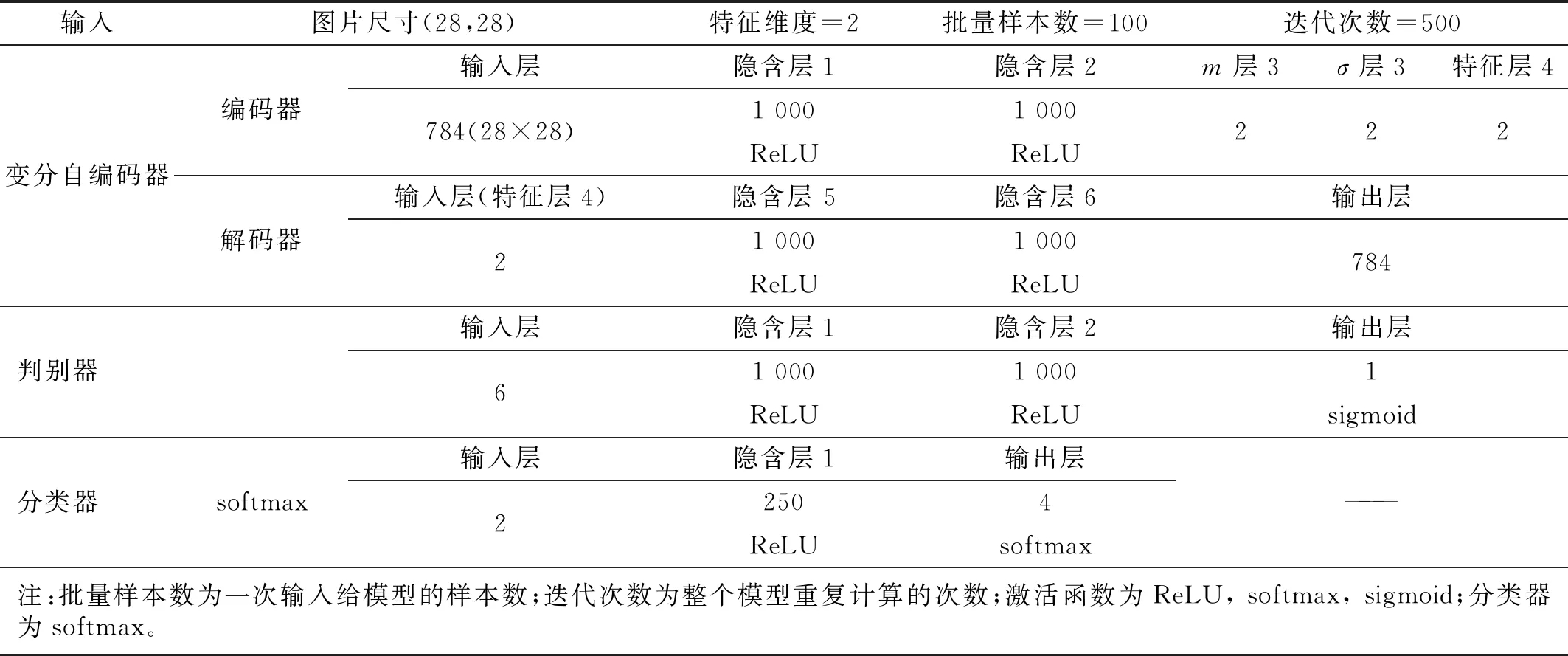
表3 模型构建参数
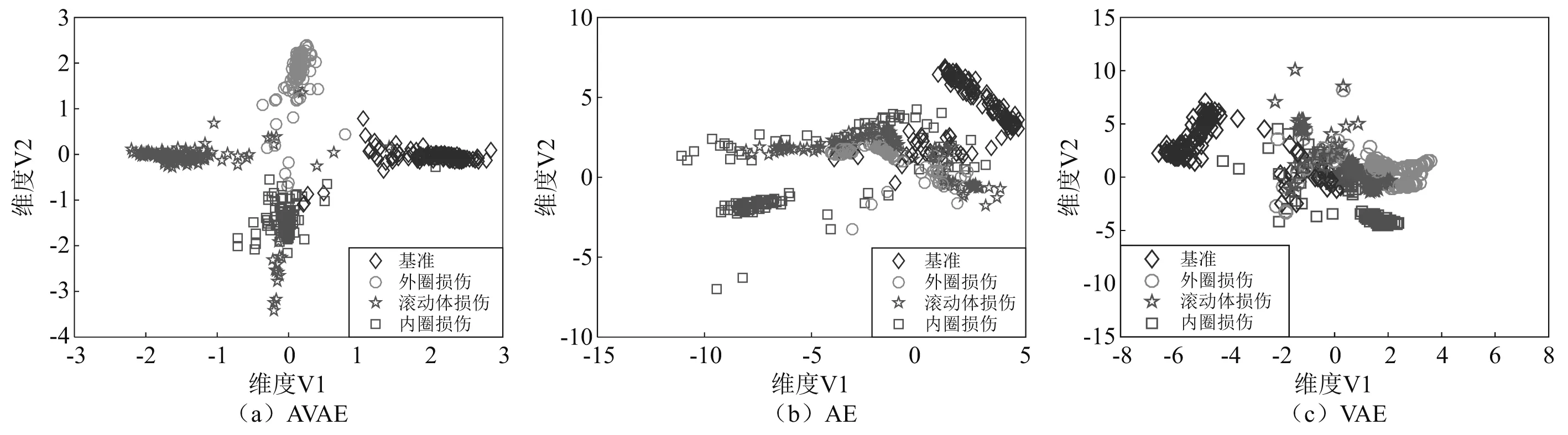
图15 聚类结果
此外,使用模糊C均值聚类算法[24],以分类系数F和平均模糊熵H为指标来评估聚类性能。当F越接近1同时H越接近0时,聚类效果越好。表4列出了不同方法提取的特征对应的F和H值,从中可以看出AVAE提取出的特征聚类性能最好,这是因为AVAE提取的特征受到了多维独立高斯分布的专属约束,强化了不同类别特征间的差异。此外,从图15中也可以看出,AVAE提取的特征比AE和VAE提取的特征具有更好的聚类性能,这与上面的定量分析保持了一致。最后,用训练样本的特征对分类器进行训练,然后通过测试样本进行测试。考虑到模型训练过程中样本选择的随机性,重复5次计算过程,选择每个状态对应的5个准确率中的最小值作为最终结果,如表5所示。这表明所提出的模型能够以较高准确率识别时变工况下的行星轮轴承故障,具有一定的优越性。其中,滚动体损伤的故障诊断准确率相对较低,这是因为行星轮轴承中滚动体的运动最为复杂,除了绕自身轴线旋转外,还会围绕行星轮轴转动,同时随着行星架的运动而运动。此外,滚动体损伤与内圈或外圈接触时都会引发冲击振动。因而滚动体损伤引起的振动信号包含更多复杂的成分,受到的干扰更多,识别难度也最大。
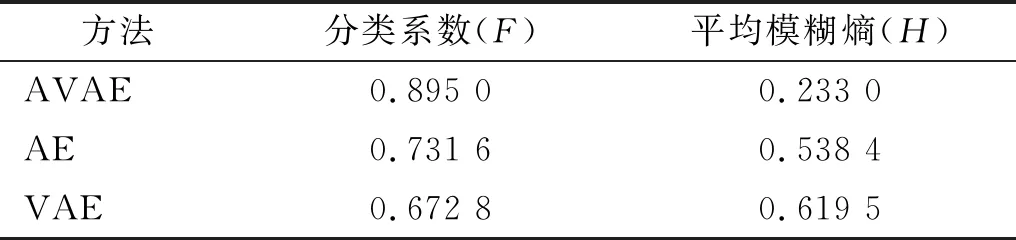
表4 聚类效果评估
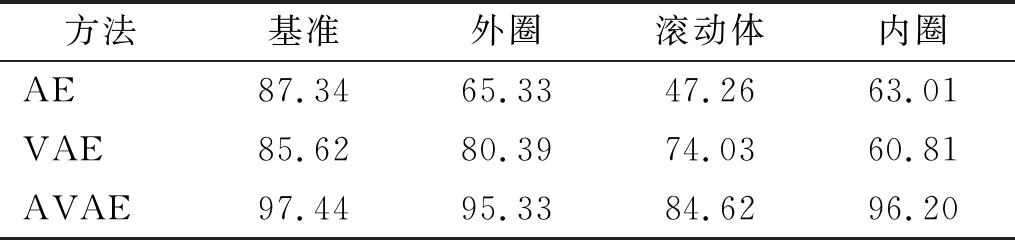
表5 诊断准确率
4 结 论
在研究中,我们将多维独立高斯分布引入对抗变分自编码模型,提出了一种新的智能故障诊断方案,用于对时变工况下行星轮轴承进行故障诊断。该方法用变分自编码模型来提取原始信号的时频图特征,同时通过对抗机制,用已知的多维独立高斯分布来拟合未知的特征分布,赋予了特征显式的意义,同时强化了不同状态样本时频图特征间的差异性。方法经实验数据进行了验证,结果表明:
(1)模型迭代次数与批量样本数对故障识别准确率有一定的影响。参数值较小时,由于训练不充分导致模型准确率不高,参数值较大时,则容易产生过拟合现象,导致模型泛化能力下降,降低模型准确率。
(2)模型每层神经元数量取较小值时,模型权值需要来回调整,不易稳定。为保证计算效率与网络性能,一般在满足精度要求的前提下选择较少的神经元个数。
(3)与AE、VAE相比,AVAE提取的特征具有更好的聚合性能,特征能够被显式的表达,且不同类别特征间的差异更为明显。AVAE能够以较高的准确率诊断时变工况下行星轮轴承故障,表现出一定的优越性。
