Relief-F算法及决策树方法下的湿地信息提取
2021-07-16郝玉峰满卫东汪金花刘明月
郝玉峰,满卫东,2,3,汪金花,刘明月,2,3,张 阔
(1.华北理工大学 矿业工程学院,河北 唐山 063210;2.河北省矿业开发与安全技术重点实验室,河北 唐山063210;3.河北省矿区生态修复产业技术研究院,河北 唐山063210)
0 引言
湿地是地球三大生态系统之一,虽然只占地球表面积的6%左右,但凭借其丰富的自然资源,为动植物提供了良好的生存环境,同时也具有调节气候、保护生物多样性、蓄洪抗旱、改善环境等作用[1],被称为“地球之肾”[2].近年来,由于受气候变化、自然灾害、环境污染、城镇扩张、农业发展等因素的影响,大面积的自然湿地转变为建设用地、农业用地以及人工湿地[3],导致湿地生态系统功能遭到严重破坏.第二次全国湿地资源调查结果表明,截止2013年,中国湿地总面积为5 360.26万km2,相较于第一次调查结果,湿地面积减少了339.63万km2[4].准确掌握湿地的面积和分布情况,对湿地的管理与保护以及生态系统的可持续发展具有重要意义.
快速、准确提取湿地信息是进行湿地探究的基础,20世纪70年代,计算机技术在遥感图像解译中得到广泛应用,其中目视判读凭借简单易操作、灵活性强等优点,成为主要的方法之一[5],但该方法很大程度上取决于解译人员的专业知识水平.随着遥感技术的发展,土地覆被信息提取方法也取得了较大发展,分类精度得到了很大提高,主要包括监督分类、非监督分类、支持向量机、决策树等方法[6].其中,决策树分类方法凭借其灵活、直观、运算效率高等特点在湿地分类中较为常用[7].但当前多数方法都以像元为基准进行分类,使得光谱相似的地物类型无法准确分离,必然造成“同谱异质”、“同质异谱”等现象[8].面向对象分类方法应用地物类型的光谱、形状、空间关系等特征建立规则,将含有更多信息的对象应用到分类中,能够解决传统分类方法出现的光谱混淆等问题[9].将面向对象分类和决策树相结合,利用面向对象法将影像分割成同质对象,再经过决策树进行满足和不满足的条件判断[10],实现更加快速、高效地影像分类,使得分类结果更准确.由于湿地所处地形丰富,覆被地物类型多样,需要应用较多的特征变量,才能对湿地进行精确的分类.从影像中提取的特征变量间往往存在相关性,且应用过多的特征变量参与分类将影响分类精度和分类速度.因此,如何能在特征集中选择出最优的特征变量的同时,又能高效的对湿地进行精确分类显得尤为重要.
Relief-F算法[11]是一种典型的过滤式特征优化算法,通过计算特征变量的权重并进行排序,进而提取出最优特征集合.Relief-F算法具有高效、不受数据类型限制的优点,被广泛应用于国内外各研究领域.何云[12]等利用优选特征进行随机森林土地覆盖分类,并与原始随机森林分类结果进行对比,得出基于特征优选的分类结果精度明显提高.刘家福[13]等采用 Relief-F算法对全部特征变量进行权重排序,采用基于特征优选的随机森林模型与传统的分类方法提取黄河口滨海湿地信息,得出特征优选的随机森林模型精度和效率最高.以上研究都是利用随机森林决策树模型进行分类,但不同决策树对于湿地分类的适用性没有明确说明,不同决策树方法分类精度存在一定差异.对不同的决策树模型进行比较,选择出最优模型,有助于提高分类精度.
该研究以唐山市曹妃甸为研究区,基于Landsat8 OLI数据,经辐射定标、大气校正等预处理后,对影像进行面向对象分割,提取分割对象的光谱、纹理、几何、植被指数、水体指数等特征,并利用Relief-F算法对特征变量进行优选,获取适合本研究区的最优特征集,分别使用 CART、C5.0和QUEST决策树及未特征优化的QUEST决策树对研究区的湿地类型进行分类,评价不同方法在湿地分类中的优劣.
1 数据与方法
1.1 研究区概况
曹 妃 甸 区 ( 39°07′43″N ~ 39°27′23″N ,118°12′12″E~118°43′16″E)处于河北省唐山市南部沿海、渤海湾中心地带,面积为1 943.72 km2,其中野生动植物丰富多样,省级湿地和鸟类保护区110 km2,被国际湿地组织称为“开发潜力巨大、不可多得的湿地保护区”.该地区位于东部季风区温带半湿润区,大陆性季风特征显著,夏季潮湿多雨,冬季寒冷干燥,四季分明,年均气温11 ℃,年降水量636 mm,主要集中在7月和8月.研究区土地利用类型多样,主要以盐田、水田、养殖池、不透水表面等为主,湿地植被主要以芦苇和翅碱蓬为主,见图1.

图1 曹妃甸区Fig.1 study area ofCaofeidian
1.2 数据来源与预处理
该研究使用的数据为曹妃甸地区2013年7月24日夏季的Landsat8 OLI影像,来源于USGS官网(https://www.usgs.gov/),轨道行列号为 122/33,影像的云量少,图像清晰,主要包括7个波段,可见光与近红外包括5个波段,TIRS 包括2个波段,空间分辨率为30 m,其中全色波段的分辨率为15 m.辅助数据主要包括Google Earth 卫星影像、曹妃甸矢量文件和野外调查数据.
利用ENVI软件对遥感影像进行辐射定标和大气校正,消除大气所造成的辐射误差,获得地物表面的真实反射率;采用二次多项式对遥感数据进行几何精校正,将几何误差控制在0.5个像元内;采用Gram-Schmidt变换对30 m的多光谱影像和15m的全色波段影像进行融合;最后利用曹妃甸矢量边界对遥感影像裁剪,得到研究区遥感影像.
1.3 湿地遥感提取的分类系统
以《湿地公约》、《全国湿地资源调查与监测技术规程》和文献的湿地分类体系为依据,通过实地考察和Google Earth影像的目视判读,将研究区的主要湿地划分草本沼泽、河流、泥沙质滩涂、库塘/水库、养殖池、盐田、水田、非湿地(建设用地、耕地)共9类,见表1.

表1 研究区遥感分类体系Tab.1 remote sensing classification system in study area
1.4 特征变量说明
本文选取光谱特征、纹理特征、几何特征、形状特征、指数特征和缨帽变换求得的亮度、绿度、湿地构建共52个特征集(表2).

表2 样本特征与描述Tab.2 features and description of sample

续表2
将遥感影像波段的平均值和标准差作为光谱特征;并利用各波段反射率为基准构建水体指数和植被指数;但研究区湿地类型丰富多样,仅依靠光谱特征和指数特征很难将相似的地物分离[14],纹理特征能够更好的描述地物信息的细节[15],因此本文利用灰度共生矩阵(Gray-level Co-occurrence Matrix,GLCM)提取56个特征变量.并利用主成分分析对其降维,其中第一主成分的贡献率达到51.23%,第6主成分的贡献率达到95.74%,因此选取前6个主成分作为纹理特征.
缨帽变换不仅对原始影像的地物信息起到图像增强的效果,还能压缩各波段间的冗余信息[16].本文选择Baig等人提出的Landsat8 OLI缨帽变换系数进行缨帽变换[17],得到6个分量,其中前3个分量为亮度、绿度、湿度,第3到6变量均为噪声,因此提取前3个分量的均值和标准差用于区分不同的湿地类型.
1.5 分类方法
(1)多尺度分割
面向对象方法是将影像分割得到同质对像,再根据地物类型的光谱、形状、空间关系等特征建立规则,将对象分配到相应的类中[18].其核心步骤是多尺度分割,分割的好坏直接影响到分类结果的精度.其原理是根据给定的阈值对像元进行聚集合并,形成具有更多信息的对象,并将对象提取出来的过程[19].面向对象分割方法主要设置6个参数:波段权重、分割尺度、光谱、形状、紧凑度和光滑度.其中分割尺度对分类结果的影响最为明显,尺度设置的越大,像元合并的面积就越大,获得的对象越少,越容易造成像元混淆的现象,反之则导致分割对象过于破碎,大大增加工作量[20];光滑度和紧凑度、形状因子和光谱因子的取值范围均为0.1~0.9,参数的和均是1.由于地区的空间差异和不同信息提取的需要,应根据实际情况设置相应的参数,从而得到最优的分割结果.
(2)特征优选算法
Relief-F算法是一种基于数理统计的多类别特征选择算法,其核心思想是通过随机抽取样本的方式,计算各个特征变量的权重,并对权重值的大小进行排序[21].其主要内容是从训练集中随机选择一个样本R,然后从和R同类的样本中寻找k最近邻样本H,从和R不同类的样本中寻找k最近邻样本M,最后定义特征权重为

式中,A为特征变量的个数;m为样本抽样次数;k为最近邻样本个数;Hj为样本R的第k个最近邻同类点;diff(A,R,Hj)为在特征A上样本R和Hj的差;Mj(C)为异类样本点;Class(R)为样本R的类别;P为概率.
(3)决策树分类方法
CART(Classification and Regression Tree,分类回归树)算法基本原理是将测试变量与目标变量构成数据集,通过计算基尼系数(Gini Index)选择最优分割特征,再根据特征值构建二叉树,并循环此步骤,直到待分类的样本集达到停止分类的条件[22].基尼系数的计算式为
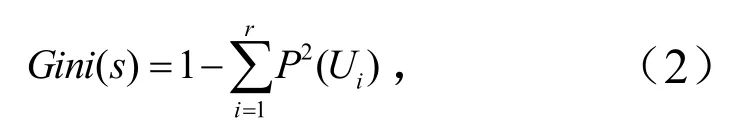
式中,r为类别变量的个数;P(Ui)为所选样本的数据集中属于第i个类别概率.
C5.0决策树算法以特征变量信息增益率(Information Gain)为标准确定最优分割特征和分割值,并通过代价矩阵对决策树的节点进行修剪[23],除此之外,C5.0算法还引入了Boosting技术.Boosting技术依次建立一系列决策树,后建立的决策树会对前面构建决策树出现的错分现象加以分析,最终生成更加准确的决策树模型[24].
QUEST决策树算法是一种二元分类方法,其基本流程和其他决策树相同,主要分为特征变量和特征分割值的选择.QUEST将特征变量和分割阈值的确定分开进行,一方面对连续性变量和离散型变量同时适用,另一方面还减小了分类方法中常见的偏向类别较多预测变量的趋势,因此在特征变量选择上基本无偏[25],同时可通过多个变量构成的超平面在特征空间中区别类别成员和非类别成员[26].
基于分类结果,构建混淆矩阵,利用总体精度、Kappa系数、生产者精度和用户精度对不同方法的结果进行评价.
2 结果与分析
2.1 影像多尺度分割
本研究采用试错法选择最优分割尺度,分割尺度以20为步长,从60到200,不断改变分割尺度、形状和紧密度的权重,得到不同尺度的分割结果.由于研究区主要为水田、养殖池和水库这样较为规则的地物,因此将形状因子的权重设置的较高,经过多次试验发现,设置形状因子权重为0.9、紧凑度权重为0.5,当分割尺度为60时,地物类型分割的过于破碎;而当设置尺度为 160时,建设用地能够准确的分离,但是水田、养殖池会出现错分的现象;当分割尺度为100时,不同的地物类型均得到较好的分割,见图2.因此,选取分割尺度为100,形状因子为0.9,紧凑度为0.5对研究区进行多尺度分割.

图2 研究区局部不同尺度的分割结果对比Fig.2 comparison of segmentation results of different scales in study area
2.2 特征优选
利用Relief-F算法对52个特征变量进行优选,主要设置两个参数,分别为决策树数量和输入特征变量个数.假设构建决策树的数量N=1 000,以5为步长,从1到52,不断改变特征变量个数k,计算得出分类精度.由图3可知,随着特征变量的增加,前7个特征的分类精度呈现持续增长的态势,由第一个特征分类精度为79.3%增长到89%,这是由于前期特征变量间的相关性较低,对分类都起到了积极作用;但到了7~20个特征变量时,少数的冗余特征开始出现,致使分类精度呈现波动上升趋势,输入 20个特征变量时,分类精度达到最大值,为89.5%;从21个特征变量开始,分类精度呈现明显的下降趋势,这是由于不相关特征的增加,对最优特征的选择产生了干扰,导致分类精度降低.固定特征变量的个数k=20,对决策树数量N进行选取,通过测试发现,当决策树的数量N≥1 000时,分类精度逐渐趋于稳定.因此,本文在特征数k=20,决策树数量N=1 000时选取最优特征集.

图3 特征变量个数与分类精度关系Fig.3 relationship between number of feature variables and classification accuracy
利用上述Relief-F算法计算52个特征变量的权重,得出权重系数排在前 30的特征变量见图4.根据Relief-F算法计算得到的最优特征数量,选取前20个特征变量构成最优特征集.最优特征集中,光谱特征有8个,缨帽变换有4个,水体指数有3个,几何特征和植被指数均有2个,纹理特征有1个,形状特征则最不明显,权重最高的形状特征排在所有特征的第21个.结果表明光谱特征在本研究区的分类中作用最为显著,其次是缨帽变换求得的湿地、亮度和绿度.图4中,Std Red/Blue/SWIR1/PC1/PC2/PC3/ PC4/ PC5为红波段、蓝波段、红外波段1、第一、第二、第三、第四、第五主成分标准差,MeanWetness/ Brightness/Greenness为湿度、亮度、绿度均值,MeanRed/Blue/Coastal/Green/SWIR1/SWIR2为红波段、蓝波段、海岸波段、绿波段、红外波段1、红外波段2均值,Std Wetness/Brightness为湿度、亮度标准差,其他变量参照表2.下文中图6变量符号与图4相同.

图4 特征权重分布和前30个特征变量的占比Fig.4 distribution of feature weight and proportion of the first 30 feature variables
2.3 决策树的建立
基于9种地物类型578个训练样本和20个特征变量,应用 C5.0、CART、QUEST建立决策树模型,与未进行特征优选的QUEST决策树模型进行比较分析见图5.用 4种方法构建决策树使用的特征变量明显不同,见图6.C5.0决策树应用到Boosting算法,所选的20个特征变量都参与到模型的构建,且权重没有较大差距,其余的三种方法使用了10个左右的特征变量.从出现次数上看,近红外均值、地表水指数是最主要的变量,在C5.0、QUEST和未特征优选的QUEST决策树种均出现1次;从特征的权重系数上看,未特征优选的QUEST决策树的形状指数的最大系数为0.54,而其他特征变量的权重系数较低,CART与QUEST决策树的最优特征变量系数均在 0.20左右,且各特征变量间的差距不大.

图5 决策树模型Fig.5 decision tree model

图6 不同决策树权重对比Fig.6 comparison of weights of different decision trees
2.4 分类精度评价
对比4种模型得到的结果见图7.由图7可见,经过特征优化的 3种决策树方法与未特征优化的QUEST决策树在对湿地类型的判断上存在较大差异.图8(d)中,都出现了草本沼泽、建设用地、水田等湿地类型混淆严重,其中建设用地(道路)被错分为细河流最为明显,还有部分水库坑塘被划分为养殖池和盐田.特征优化下的 3种决策树方法相比,QUEST决策树的分类效果更优.在区域1中,C5.0和CART决策树都将部分草本沼泽错分为养殖池和建设用地;在区域2中,都存在建设用地与河流混淆的情况,但QUEST决策树相较下错分的较少,部分水库坑塘被分为河流和养殖池;在区域 3中,C5.0和CART决策树都将建设用地错分为河流,水田、旱地与草本沼泽相互错分.

图8 不同方法分类结果对比Fig.8 comparison of different classification result
4种决策树分类结果出现不同的错分情况,原因可能为:Landsat8影像为中等分辨率的影像,导致细小的河流、道路容易和周围的植被形成混合像元,光谱特征与草本沼泽相似;在设置分割尺度时,只查看了主要的湿地类型是否分割,而造成了过多的小斑块出现,导致部分分类结果稀碎化.因此针对差异较大的地物类型,应利用多尺度、多数据源相结合的方法来优化分类结果.
为更直观地比较不同决策树方法对湿地分类的效果,参照实地考查数据和Google Earth高分辨率影像,均匀的在研究区内选取水田、养殖池、水库坑塘等9类地物类型共291个验证点.将验证点与分类结果进行叠加分析,利用统计结果构建混淆矩阵,计算得到总体精度(Overall Accuracy,OA)、Kappa系数、生产者精度(Producer’s Accuracy,PA)和使用者精度(User’s Accuracy,UA),对分类结果的好坏进行评价.
4种分类方法的精度评价见表3,QUEST决策树的总体精度86.9%,Kappa系数为0.85;未特征优选的QUEST决策树的分类精度最低,总体进度为75.6%,Kappa系数为0.71,其他两种决策树的分类结果均能满足精度需求.从使用者精度来看,旱地和河流的分类效果在4种方法上都达到了最优,而对草本沼泽的分类效果较差,这是由于在多尺度分割时,建设用地、植被这种相邻地物间的混合像元易造成错分现象,从而与草本沼泽的光谱特征相似.从生产者精度来看,C5.0和QUEST决策树在水田和盐田的分类精度达到最大值,但是在河流的精度较低,为57.7%,存在较为明显的错分现象.因此总体来看,利用特征优选下的QUEST决策树对研 究区湿地信息提取得到的效果最佳.

表3 4种分类方法的精度评价Tab.3 accuracy evaluation of four classification methods
3 结论
(1)基于Relief-F算法,从光谱特征、纹理特征、水体指数等共52个特征中选取出20个最优特征集,解决特征变量过多引起的“维度灾害”现象,从而提高湿地的分类精度.基于特征优选的 3种决策树模型的分类结果均能满足分类精度的要求,但未特征优选的QUEST决策树,总体精度为75.6%,未能达到分类精度的要求.其中,针对草本沼泽、旱地这种光谱特征相似的地物类型,分类精度有了明显提高.
(2)将决策树的数据自动挖掘的能力和面向对象方法的多特征相结合,实现了更加精确的分类.从 3种决策树模型的分类精度中可以看出,应用Relief-F算法的QUEST决策树模型的分类精度最高为86.9%,Kappa系数为0.85,C5.0决策树的分类精度最低为83.8%,Kappa系数为0.81.基于特征优化下的决策树算法在提高湿地的遥感分类精度方面具有很好的作用,为湿地信息提取在特征变量和决策树的选择上提供了新思路.
