基于多模态融合的活体检测研究
2021-07-16朱大力陈志寰
朱大力,朱 桦,陈志寰
(1.海军工程大学 船舶与海洋学院,湖北 武汉 430033;2.安徽工业大学 商学院,安徽 马鞍山 243002;3.海军勤务学院 战勤指挥系,天津 300450)
人脸识别[1]加速了人类信息化的发展,但同时也面临极大的金融风险。因此,为提高人脸识别技术的核心安全能力,一些学者提出了活体检测的概念,即通过某种算子判断人脸是真实人脸还是虚假的攻击体,如电子照片攻击、电子视频攻击、3D头模攻击等。目前,主流的活体检测技术包括配合式和非配合式两种。配合式活体检测是通过用户配合系统提示做出相应的动作进行活体检测;非配合式活体检测是指用户无需进行相应的动作直接进行活体检测。笔者主要对非配合式活体检测进行研究。
对于非配合式活体检测,早期主要通过手工提取图像特征(纹理、颜色、非刚性运动变形等),然后比较活体特征与假体特征之间的差异。如WEN等[2]利用单帧输入的方式,设计了镜面反射+图像质量失真+颜色等统计量特征,融合以上特征后利用SVM[3]分类器进行分类决策。该方法能够区分大部分假体攻击,但当输入为质量失真不严重的高清彩色打印纸张或者高清录制视频时,则难以区分。BOULKENAFET等[4]分别提取HSV空间中人脸LBP特征[5]和YCbCr空间人脸LPQ特征[6],并将提取的特征进行通道融合,输入至SVM分类器进行分类,该方法证明了活体与假体在其他颜色空间具有可区分性。BHARADWAJ等[7]提出了光流法,通过捕获活体与非活体微动作之间的差异来设计特征。传统方法设计的特征虽然比较简单,但是手工设计特征较为繁琐,且特征信息较少,鲁棒性较差。随着深度学习的兴起,一些学者陆续采用深度学习提取特征开展活体检测研究。如ATOUM等[8]采用端到端的方法回归脉冲统计量及深度图,将二分类问题替换为目标性的特征监督问题。SONG等[9]将活体检测直接作为人脸检测框架里的一个类,即通过人脸检测器检测出的Bbox有背景、真人脸、假人脸三类的置信度,可以在早期就过滤掉一部分假体攻击。以上基于深度学习的方法虽然能够提取较鲁棒的特征,但极易受到光照因素影响,且仅基于RGB图像特征无法解决3D攻击问题。
针对以上研究的不足,笔者提出一种基于多模态融合的活体检测方法,包括基于局部图像块的特征学习和结合模态特征擦除的多流融合两个部分。该方法可从不同模态提取更具辩别性的特征并加以融合,可用于人脸识别系统中的活体检测,为人脸识别提供安全保障。
1 融合多模态的活体检测方法
1.1 多模态融合的活体检测框架
对于基于局部图像块的特征学习,笔者采用从面部图像随机提取的局部图像块来训练深度神经网络,以学习丰富的外观特征。对于多流融合,在训练过程中会随机擦除来自不同模态的特征,再将其融合以进行分类。神经网络的输入为RGB、深度和红外3个模态的人脸图像。其中,RGB可提取较丰富的颜色特征信息;深度图像反馈的是相机与人脸的距离信息,利用深度信息可区分二维假体攻击,如电子照片攻击和视频攻击等;由于真实的人脸和纸片、屏幕、立体面具等攻击媒介的反射特性都是不同的,所以成像也不同,而这种差异在红外波反射方面会更明显。因此,3种模态的特征融合对于活体检测具有指导意义。
笔者基于ResNet[10]网络设计了更深的卷积神经网络结构,该网络由3个组卷积块,全局平均池化层,全连接层以及softmax层组成,如图1所示。由于不同模态的特征分布不同,因此,基于多模态融合的活体检测算法可有效探索不同模态之间的特征依赖性。笔者使用具有3个子网的多流体系结构来执行多模态特征融合,网络的输入为3个模态的图像的局部块。在每个子网络提取各自模态的特征,然后在高层语义特征层将不同模态的特征进行融合。

图1 多模态融合的活体检测框架
1.2 注意力模块
为了让网络有选择性地增强信息量大的特征,使得后续处理可以充分利用这些特征,并对无用特征进行抑制,引入了通道注意力模块SENet[11]。首先,对主干网络提取的特征进行Squeeze操作,得到通道级的全局特征;其次,对全局特征进行Excitation操作,学习各个通道间的关系,得到不同通道的权重;最后,乘以原来的特征图得到最终特征。SENet模块适用于任何映射,以卷积为例,由于对各个通道的卷积结果做了求和操作,所以通道特征关系与卷积核学习到的空间关系混合在一起。而SENet模块可以抽离这种混杂,使得模型直接学习到通道特征关系。SENet模块主要分为Squeeze操作和Excitation操作,SENet网络结构如图2所示,其中C、H、W分别表示特征图的通道数、高和宽。
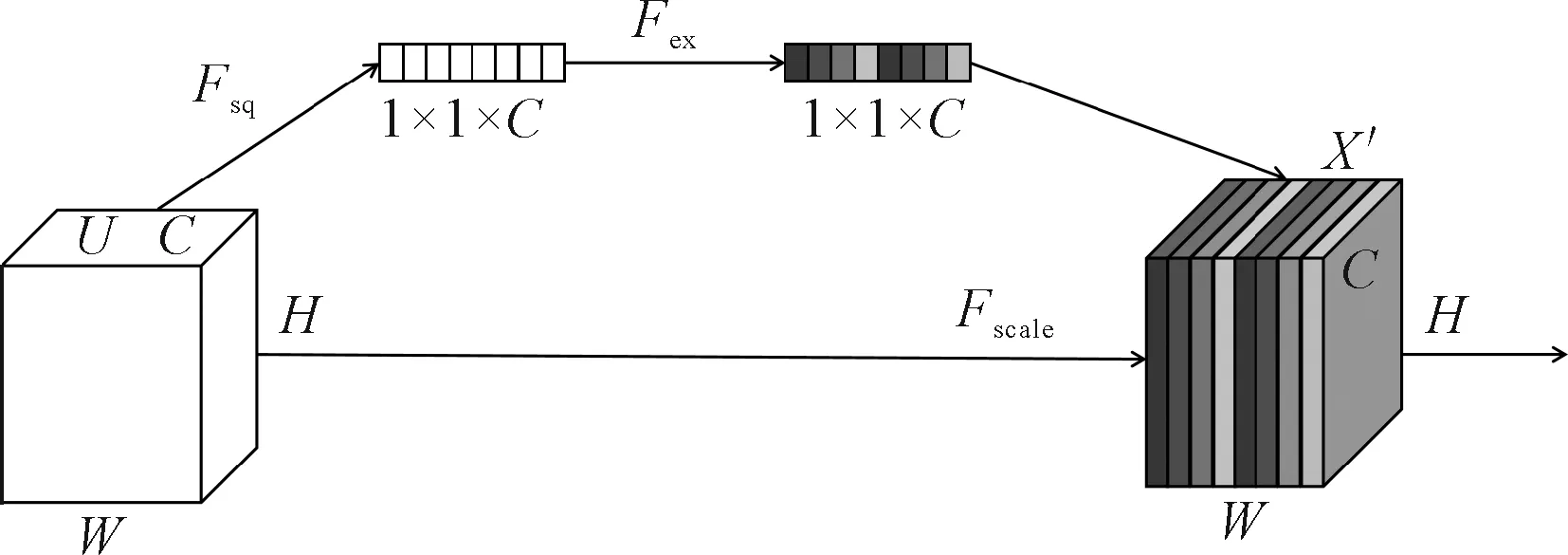
图2 SENet网络结构
(1)Squeeze操作。由于卷积只是在一个局部空间内进行操作,很难获得足够的信息来提取通道之间的关系,这对于低层次的网络更为严重,因为其感受野较小。因此,SENet的设计者提出了Squeeze操作,将一个通道上整个空间特征编码为一个全局特征,采用全局平均池化操作来实现。
(1)
式中:Zc表示Squeeze操作的输出;Fsq为全局平局池化操作;Pc为某层的卷积特征;Pc(i,j)为不同通道的卷积特征;i、j为像素位置索引。
(2)Excitation操作。通过Sequeeze操作可以得到全局描述特征,接下来需要抓取通道之间的关系。这个操作需要满足两个准则:①要灵活,可以学习到各个通道之间的非线性关系;②学习的关系不是互斥的,因为这里允许多通道特征,而不是one-hot形式。基于此,采用sigmoid形式的gating机制:
S=Fex(Zc,W)=β(W2θ(W1Zc))
(2)
式中:Fex为Exicitation操作;β为非线性激活函数sigmoid;θ为非线性激活函数ReLU;W1与W2分别为两个全连接层的参数。
为了降低模型复杂度和提升泛化能力,笔者采用包含两个全连接层的bottleneck结构。其中,第一个全连接层起到降维的作用,最后的全连接层可以恢复到原始的维度。图2中U为经过多层卷积后的特征,Fscale表示将学习到的各个通道的激活值乘以经过多层卷积后的特征U上的原始特征即为信息增强后的特征X′。网络的损失函数为Softmax+CrossEntropy[12],如式(3)所示。
(3)
式中:Lsoftmax为交叉熵损失函数,用来衡量模型预测值与实际值的差异程度;fj为输出类别的第j个置信度;yi为样本的真实标签;N为训练样本的个数。
2 实验与评估
2.1 数据集
为了评估实验的有效性,笔者利用自研的RGBD相机采集了若干不同活体的人脸图像,并采集了不同攻击类型的假体数据。数据集EPC660包含300个活体的50 000张人脸图像,真脸数据包含了强光、暗光、背光、弱光等各种场景。基于2D的假脸数据是使用打印纸、铜版纸、照片纸、平板Pad 屏幕、手机屏幕采集的数据。基于3D的假脸数据则是采用头模、硅胶面具和纸质照片抠洞的人脸面具进行采集。EPC660部分数据如图3所示。

图3 EPC660部分数据
为了使得实验更具有效性,笔者使用随机翻转、旋转、调整大小、裁剪来增强数据,并从112×112全脸图像中随机提取图像补丁。增强后的真脸图像数据为10万张,假脸数据为8万张。将数据集分为训练集、验证集和测试集。其中,训练集包含3万张真脸数据、2万张假脸数据,验证集包含1万张真脸数据,1万张假脸数据,测试集包含6万张真脸数据,5万张假脸数据。与一般情况下的数据集划分不同,笔者划分少量的数据到训练集和验证集,划分大量的数据到测试集。利用小数据量训练的模型来测试该模型在大数据量的数据集上的泛化性。为了较准确地进行活体检测,先利用开源的目标检测算法检测数据集中的人脸图像,再对人脸图像进行对齐操作,最后将对齐的人脸图像输入至网络。
2.2 训练与推理
笔者采用基于ResNet修改的自研网络作为主干网络训练模型,使用Softmax+CrossEntropy Loss作为训练分类的监督。使用常规的SGD和标准的学习率递减策略进行训练,直至收敛为止。使用不同尺度的图片作为网络的输入训练数据,网络训练时,在人脸图像原图上(多个模态)随机裁切不同大小的图形补丁作为网络输入。为了增加模型间的互补性,在若干个卷积块后融合3个模态的特征进行训练。另外,为了减小模型的冗余性,在网络训练初期随机擦除任一模态的特征,将该模态的特征值置为0。
2.3 实验评估与分析
为了评估模型的有效性,分别设计基于RGB、深度和红外3种不同的模态数据为输入的网络进行训练,输入的图像补丁尺寸分别为16×16、32×32、48×48和64×64。为了进行性能比较,使用9个不重叠的图像补丁来推理所有模型9次,最后取所有图像补丁推理结果的均值。同时,为了验证多模态融合的性能提升效果,设计多模态实验,将单模态实验中3种不同模态的输入融合为9个通道的输入,在网络训练时将9个通道的输入分成3组分别输入不同模态的子网络中参与模型训练。实验结果如表1所示,可以发现输入大小分别为32×32、48×48时,基于深度数据训练的模型性能较好,错误率可达到0.8%,真阳性率为 99.4%;当输入大小为32×32时,RGB和红外图像的错误率分别为4.2%、1.5%;当输入大小为48×48时,RGB和红外图像的错误率分别为3.1%、1.5%。对比不同模态的错误率可以发现,当网络输入大小相同时,基于深度数据、红外数据训练的模型的性能优于基于RGB训练的模型的性能。而将3种模态融合在一起,模型在所有图像补丁上都具有很强的性能。当网络输入大小为48×48时,融合后的特征在测试集上的表现最好,错误率可达到0.2%,真阳性率为99.8%。
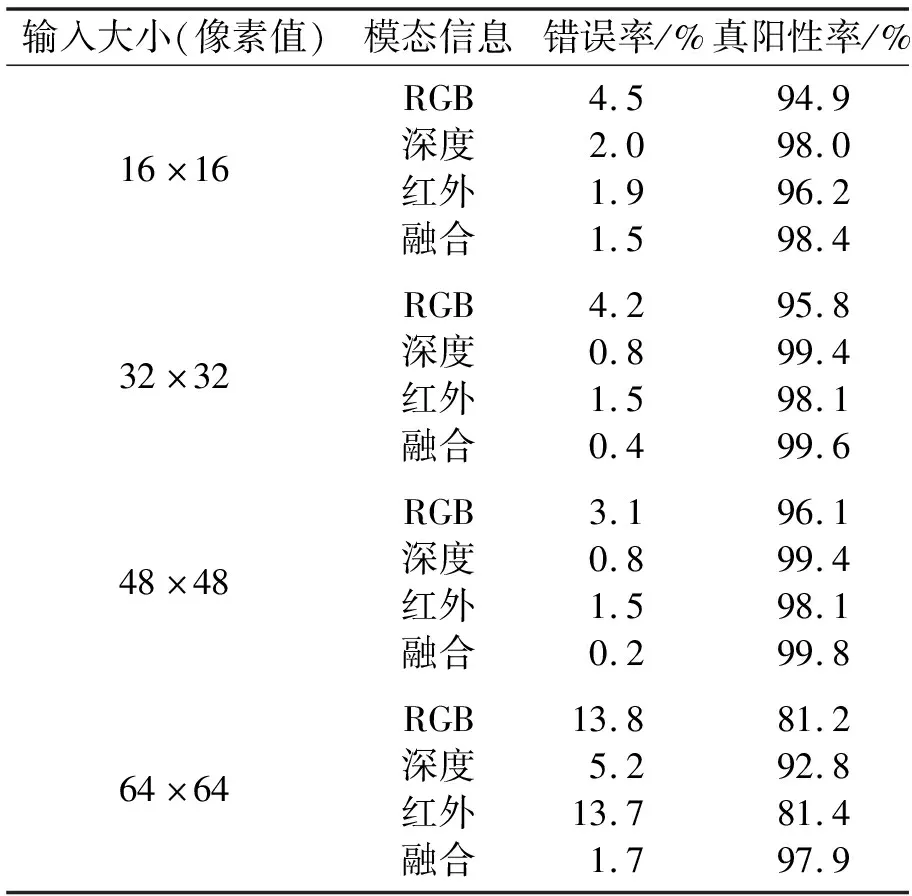
表1 不同补丁大小和模态的实验结果
另外,为了防止过拟合,并验证不同模态对不同假体攻击的有效性,选择16×16的图像块作为网络的输入进行实验,在训练过程中加入一种随机擦除任一模态特征的机制,随机擦除每一批输入网络中不同模态的训练数据,然后评估模型。实验结果如表2所示,不难看出当训练过程中随机擦除任一模态的特征时,模型的错误率会降低。当擦除RGB模态特征时,融合深度特征与红外特征的模型能达到99.5%的真阳性率,错误率降到了0.46,且在PC端的推理速度能达到30FPS。实验结果表明,学习不同模态之间的互补性可以获得更优的结果。

表2 不同训练策略的实验结果
3 结论
(1)笔者利用自研的RGBD相机EPC660设计了1 200个具有3种模态(RGB、深度和红外)的视频片段,并提出了一种基于多模态融合的活体检测网络框架以充分利用数据。网络输入为补丁级的图像块,从不同模态提取更具辩别性的特征并加以融合,有利于提取局部具有欺骗性的丰富特征信息。实验结果表明,多模态融合可以将错误率降为0.4%,真阳性率达到99.8%。
(2)为防止过度拟合并更好地学习融合特征,在多模态特征上设计了模态特征擦除操作,在训练过程中从一个随机选择的模态中擦除特征。实验结果表明,模态擦除操作能够有效提升真阳性率。
