稳健动态时间规整的面板数据聚类
2021-07-14唐婷婷邓光明
唐婷婷,邓光明
(桂林理工大学 理学院,广西 桂林 541006)
面板数据是现实数据库中极为常见的数据形式,是一种多指标的时间序列,包含的信息量较充足,且具有截面数据和时间序列的双重特性,用面板数据进行聚类分析能够更好反映指标的动态发展趋势和发展状态,因此,大多数学者为得到更为精确的聚类结果,经常使用面板数据进行聚类分析。面板数据聚类的基本思想是围绕如何找到更为精准的相似性度量和采用何种方法进行聚类这2个方面展开,其聚类方法大致可分为多元统计方法和非多元统计方法,非多元统计方法主要从数学和计算机角度入手,主要包括:灰色聚类[1-3]、模糊C均值聚类[4-6]、基于投影寻踪的聚类[7]等方法。在基于多元统计方法的面板数据聚类中,其聚类的主要思想就是从多元统计的角度寻找更为精准的相似性度量,如李因果等[8]为了能够展现指标的动态发展趋势,选用“绝对量”“增长速度”和“变异系数”分别表示面板数据的“绝对量”“相对量”和“时序波动”特征,根据实际需求赋予这3个特征相应的权重,采用欧氏距离重构了相似性度量的“综合”距离函数,改进了Ward聚类算法;任娟[9]提取了面板数据的水平指标、增量指标和增长变化率,选择欧式距离来描述样品之间的邻近程度,重构了离差平方和函数,再进行系统聚类;党耀国等[10]针对面板数据聚类中采用欧氏距离进行聚类存在缺陷这一问题,对面板数据的动态变化进行深度挖掘,通过提取“绝对量”“波动”“偏度”“峰度”等特征来构建新的特征向量,进而进行聚类分析。但这些方法都存在着不足之处,其一,欧氏距离无法处理对应数据间沿时间轴方向弯曲、伸缩等问题,无法合理的反应2个时间序列趋势的相似性;其二,用特征提取的方法对面板数据进行降维之后,需依据现实需求或主观给定相应的特征权重,这无法保证赋权的客观性和合理性。
基于欧氏距离无法合理反应时间序列趋势相似性和赋权问题,刘云霞[11]提出了一种基于动态时间规整的面板数据聚类方法,运用了主成分的思想对面板数据进行降维,再对降维后的时间序列采用动态时间规整的方法进行面板数据的聚类分析,这一方法具有一定的普适性且可视化效果较好,既能反映面板数据的动态发展趋势,又能够避免由于赋权不合理而影响聚类结果这一问题。但这一方法易受离群值的影响,数据中存在离群值会影响时间序列提取的准确性,进而影响聚类的效果,因此本文运用稳健统计量对动态时间规整的面板数据聚类方法进行改进,通过获得稳健的时间序列,消除离群值对动态时间规整结果的影响。
1 稳健统计量的选取
稳健一词在统计学中是用以表征控制系统对特性或参数扰动的不敏感性。Box认为:若过程在所基于的假设违背的条件下,仍然能给出较好的结果即为稳健[12]。在统计分析中,通常用稳健性来度量模型对离群值的敏感性,采用稳健统计量来优化不符合规格的模型,进而提升模型对离群值的抵御能力。稳健统计的思想和估计方法最早由Huber等[13]提出,Rousseeuw提出的最小协方差(minimum covariance determinant,MCD)是最具代表性的一种估计方法[14]。MCD估计是一种最经典的用于寻找稳健协方差估计量的方法,其目的是通过构造稳健的样本协方差矩阵来抵御离群值的影响[15]。MCD估计主要利用迭代和马氏距离的思想构造一个稳健的协方差矩阵估计量,其基本步骤如下:
步骤1从n行p列的矩阵中选取h个样本,计算这h个样本数据的样本均值和协方差矩阵,样本均值记为T1,协方差矩阵记为S1。
步骤2计算n个样本数据到T1的距离,此处采用的是马氏距离:

步骤3选取n个距离中最小的h个距离,计算这h个距离所对应的样本数据的样本均值和协方差矩阵,样本均值记为T2,协方差矩阵记为S2。
步骤4 不断迭代步骤3,当det(Sk)=det(Sk-1)时,迭代停止,当且仅当T1=T2,S1=S2时,det(1)=det(2)。
步骤5根据得到的Sk对其进行加权,即可得到稳健的协方差矩阵估计量,记为S*。
但这一方法计算复杂度较高,因此,在实际应用中,通常采用的是Rousseeuw提出的快速MCD(FAST-MCD)方法来构造算法,获得稳健的协方差矩阵,进而计算出稳健相关矩阵并进行聚类分析[16]。
2 动态时间规整原理
动态时间规整(dynamic time warping,DTW)是度量时间序列相似性的一种方法,也是时间序列的聚类方法之一[11]。该方法与欧氏距离是用于衡量时间序列相似性的2种常用的度量方法,不同于欧氏距离的是,该方法可以用于时间序列不等长的情况,并且在整体波形形状很相似,但在时间轴上不对齐的情况下,使用DTW来度量2个时间序列的相似性更为合理。DTW是一个典型的优化问题,通过把时间序列进行延伸和缩短,从而达到将2个不等长的时间序列进行对齐的目的,进而找到2个波形对齐的点,在满足约束条件的众多路径中,选取距离最短的那条路径来计算2个时间序列之间的相似性,将相似性较高的序列划分为同一组。DTW方法用于面板数据聚类时,对时间序列的提取效果有较高的要求,时间序列的提取效果不好对DTW聚类的结果会产生很大的影响,因此,提升时间序列提取的准确性能够得到更为准确的DTW距离矩阵,进而提升聚类效果。计算DTW距离的方法如下:
假定比较2个时间序列X=(x1,x2,…,xn)和Y=(y1,y2,…,ym),若m=n,则这2个时间序列为等长时间序列,若m≠n则需要通过动态规划的思想将X和Y这2个时间序列进行对齐。
首先计算2个时间序列中每对元素xi和yj的局部相异性测度函数f(·),即元素xi和yj间的欧氏距离。有

弯曲曲线(warping curve)定义为:

式中:弯曲函数Φx(k)和Φy(k)分别映射x和y的时间指数,k=1,…,T,Φx(k)、Φy(k)∈{1,…,t}。
在给定弯曲路径Φ的前提下,计算弯曲时间序列X和Y的平均累积变形,即X和Y动态规整后的距离为:

式中:mΦ(k)是权重系数;MΦ(k)是对应的归一化常数;Φx(k+1)≥Φx(k)。
在众多规整路径之中找到时间序列X和Y整体代价最小的路径,即时间序列X和Y的最优配置Φ,此路径对应的动态规整后的距离即为时间序列X和Y的DTW距离,即:

3 稳健动态时间规整的面板数据聚类
动态时间规整是一种时间序列的聚类方法,作用于面板数据提取时间序列之后,因此时间序列的提取会对动态时间规整的结果产生影响,而离群值的存在会影响时间序列提取的准确性,进而影响最后的聚类结果,因此本文为了提升时间序列提取的准确性,将稳健统计量与动态时间规整相结合,构建出稳健动态时间规整的面板数据聚类方法,具体步骤如下:
1)用Fast-MCD方法计算t个时间点上的样本稳健均值向量Tt和稳健协方差矩阵,再根据稳健协方差矩阵计算出稳健相关矩阵:


3)为了减少数据信息流失,本文取全部主成分计算每个样本在每个时间点上的综合得分F*h。
4)将所得到的F*h作为新的数据集,利用DTW方法来度量各综合得分时间序列的相似性,得到样本间的初始距离矩阵:

5)根据DTW距离矩阵,采用系统聚类法中的Ward法进行聚类。
4 实证分析
选取2005—2019年,我国31个省市自治区人口总数、城镇人口数、农村人口数、死亡率、出生率和自然增长率这6项人口情况数据,并根据上述数据对31个省市自治区进行聚类分析。本文所使用数据均源自《中国统计年鉴》。
首先,以地区为单位,将原始数据分成31个样本,对每个样本分别进行稳健主成分分析来获取稳健主成分综合得分,如表1所示。由于篇幅有限,表1给出的是2019年31个省市自治区的综合得分,为了便于比较,表1中还给出了未进行稳健处理的主成分综合得分。
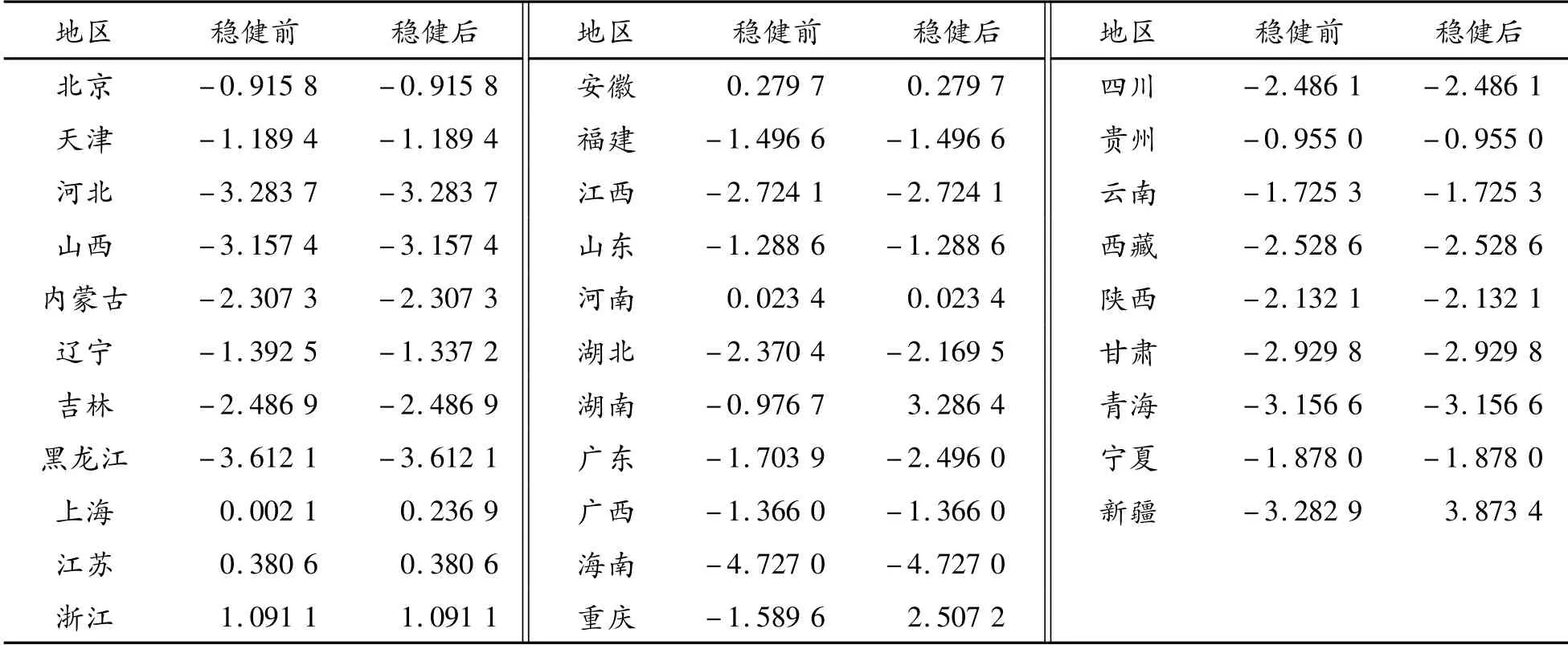
表1 2019年31个省市自治区稳健前后的综合得分
从表1中可以看出:重庆、湖南、新疆、湖北、上海、广东和辽宁7个地区在引入稳健统计量前、后的综合得分变化较大,说明数据中存在离群值,这7个地区所对应的数据在引进稳健统计量后,偏离样本中心的样本点被排除了,使得引入稳健统计量后的综合得分发生了改变。
接下来运用动态时间规整方法计算引进稳健统计量后的各时间序列间的距离,然后用系统聚类法中的Ward法进行聚类。在聚类之前,需要确定合理的聚类数,聚类的数目可参照碎石图来确定,图1给出的是DTW方法的系统聚类碎石图。

图1 稳健DTW方法的系统聚类碎石图
从碎石图中可以看出,当聚类数目取4的时候,曲线坡度变化较小,逐渐趋于稳定,因此聚类数目取4类较为合理。最后采用系统聚类法中的Ward法进行聚类,将31个省市自治区分为4类,聚类结果如图2所示。

图2 改进后的DTW聚类结果
为了便于比较改进前后聚类结果的差异,将改进前与改进后的DTW聚类结果一并放入表2中。

表2 改进前后的DTW聚类结果
从聚类结果中可以看出:改进前后的聚类结果差异较大。综合得分发生较大变化的重庆、湖南、新疆、湖北、上海、广东和辽宁这7个地区在聚类后的变化较为明显,改进前的聚类结果中,上海、湖南和辽宁聚为一类;广东一类;新疆、重庆和湖北聚为一类。改进后这7个地区中,重庆、湖南和新疆聚为一类;湖北、辽宁各自为一类;上海和广东聚为一类。
从总体聚类效果来看,改进前的DTW聚类结果将浙江独自聚为第1类,但在实际情况中,浙江人口情况数据的变化趋势并不是特有的,其总人口数和城镇人口数逐年平稳增长,农村人口数逐年递减,出生率和自然增长率在近2年都显著降低,与重庆、湖南等城市的人口情况数据变化趋势高度相似,因此,将浙江独自聚为一类显然是不合理的。第3类中将云南与上海、北京聚为一类,但从人口情况数据的变化趋势来看,云南的各项人口情况数据的总体变化趋势较为平稳,而北京、上海的总人口数增长速度较快,且自然增长率和出生率的波动起伏较大,与云南的人口情况数据变化趋势差异较大,因此,将云南与上海、北京等地区聚为一类也是不合理的。
改进后的聚类结果将浙江与重庆、湖南、新疆聚为一类,这4个地区的总人口数和城镇人口数逐年平稳增长,农村人口数逐年递减,出生率和自然增长率在近2年都显著降低,可见将这4个地区聚为一类是合理的。第2类将山东、福建、陕西、湖北、江西、山西、宁夏、青海、内蒙古、西藏、河北、吉林、四川、甘肃、黑龙江和海南聚为一类,这类地区的总人口数增长较为平稳,且增长幅度非常小,总人口数基本保持不变,出生率和自然增长率均呈现平稳或下降的趋势,这类地区经济发展相对稳定,人口流动形式多属于省内人口流动。第3类将上海、北京、天津和广东聚为一类,这类地区城镇人口数的增长速度较快,农村人口下降幅度非常小,自然增长率总体呈现较为平稳的趋势,但具体变化趋势波动性较大,北京、天津、上海、广州这类地区经济发展较为迅速,人才流入量较大,这在一定程度上致使总人口数和城镇人口数增长速度较快。第4类将贵州、广西、江苏、安徽、河南、云南和辽宁聚为一类,这类地区的城镇人口数的增长速率与农村人口数的下降速率基本一致,总人口数基本持平,自然增长率、死亡率和出生率非常平稳,无太大的改变,这类的城市经济发展与文化发展都非常稳定。
为了进一步直观反映改进后的聚类效果,本文给出2005—2019年各类地区取全部主成分后的综合得分趋势图,如图3所示。

图3 改进后2005—2019年各类地区综合得分趋势图
从图中可以较为直观的看出每一类中的样本的综合得分走势十分相似,第1类呈现稳定增长的趋势,第2类呈现稳定下降的趋势,第3类呈现先下降后平稳的趋势,第4类呈现先平稳后下降的趋势,说明聚类结果较为稳健。
为了更加直观地比较2种方法的聚类效果,本文还给出了改进前的各类地区综合得分趋势图,如图4所示。
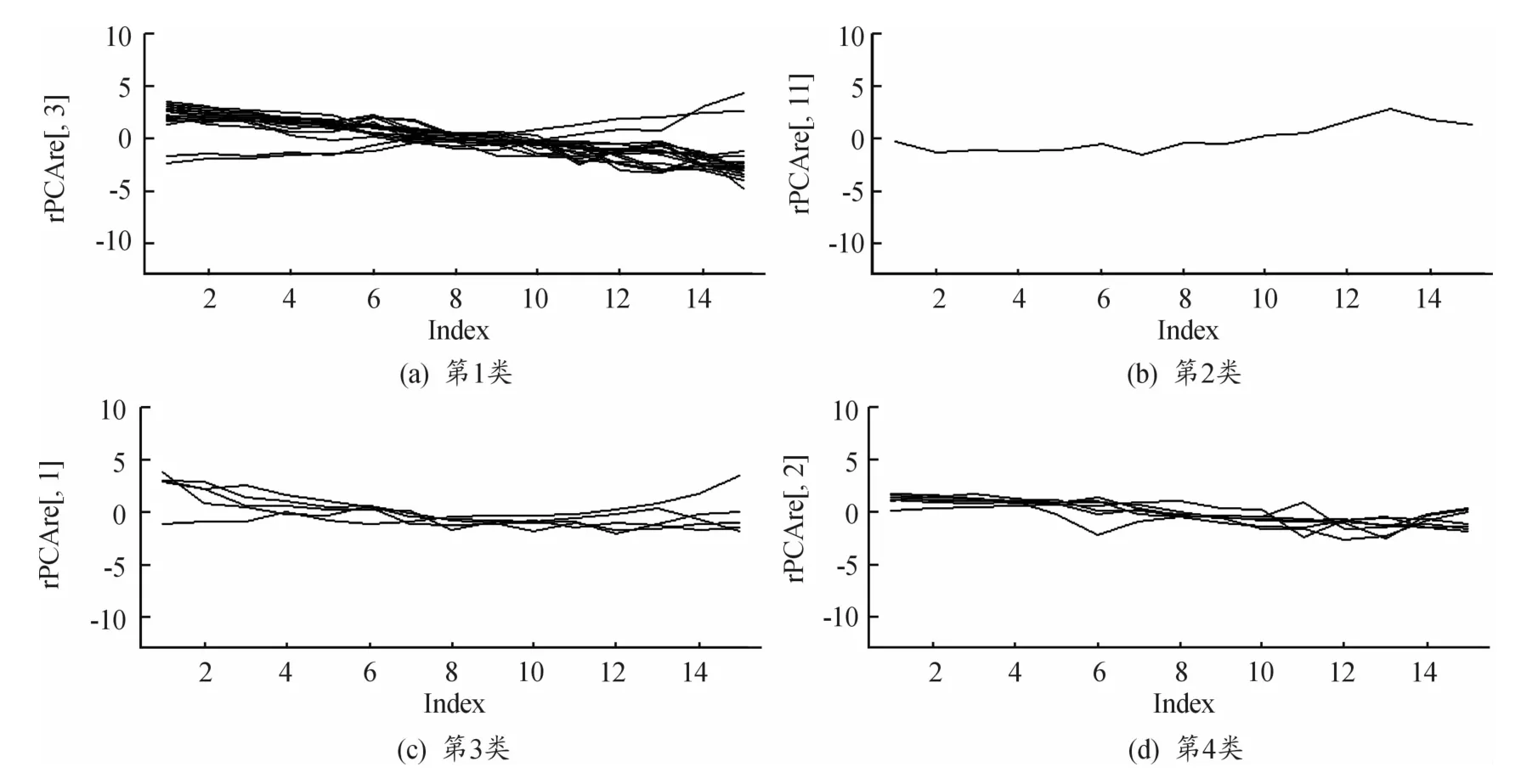
图4 改进前2005—2019年各类地区综合得分趋势图
从图中可以看出:第1类的综合得分趋势,将增长的趋势与下降的趋势聚为一类,显然是不合理的,且第2类的综合得分趋势与第1类中部分变量的增长趋势相似却独自聚为一类也是不合理的。因此,通过比较2种方法得出的综合得分趋势图可以得出以下结论:采用改进前的方法进行聚类的效果不是非常合理,而改进后的综合得分趋势图中,每个类别中的变量综合得分趋势都十分相似,说明此方法能够更加准确地将综合得分趋势相近的城市聚成一类,与改进前的方法相比,改进后的DTW聚类方法得到的聚类效果更好。
综上所述,将2种方法得到的结果与实际情况相验证,可知改进后的动态时间规整的面板数据聚类的聚类效果要比改进前的动态时间规整的面板数据聚类的聚类结果好,提升了时间序列提取的准确性,能够很好地抵御离群值的影响,使聚类效果更好,更稳健,更贴合实际意义。
5 结论
文中引进Fast-MCD稳健统计量消除离群值给聚类结果的影响,提升时间序列提取的准确性,消除了离群值对动态时间规整结果的影响,得到较为稳健的聚类结果,实证结果表明:引进稳健统计量后的DTW聚类结果较为稳健且更符合实际。
