单双边混合设计下基于置信区间宽度的样本量确定
2021-07-14刘青松王黎明瞿颖秋邱世芳
刘青松,王黎明,瞿颖秋,邱世芳
(重庆理工大学 理学院,重庆 400054)
在生物医学研究中,人们常常需要处理大量的相关数据,例如,在眼科(耳科)研究中,每个个体可以得到2只眼睛(耳朵)中每1只眼睛(耳朵)的重要信息,而得到的这些数据往往是高度相关的。研究表明:忽视这些成对数据之间的相关性往往会得到错误的统计推断[1]。如在治疗儿童中耳炎时,Mantel等[2-3]在双盲临床试验中比较2种抗生素(Cefaclor和Amoxicillin)的治愈率。既有1只耳朵患病又有2只耳朵都患病的儿童,被随机分配到使用不同抗生素的治疗组中,每个儿童都接受为期14 d的治疗。2只耳朵都患病的儿童经过14 d治疗后,治疗的结果被分为3类:一是儿童的2只耳朵都被治愈;二是儿童仅仅只有1只耳朵被治愈;三是儿童没有1只耳朵被治愈。只有1只耳朵患病的儿童治疗后,结果有被治愈和没有治愈2种情况。试验数据见表1所示。

表1 接受14 d治疗后儿童的中耳炎数据
针对此类研究,人们常常想要检验的是Cefaclor和Amoxicillin的治愈率是否相同。近年来,对于此类组内相关数据的研究备受关注。Rosner[1]在样本量很大的情况下,基于大样本理论讨论了双边数据的统计假设检验,提出了该检验假设的2种检验统计量。随后,Tang等[4]针对这种成对器官的双边治疗数据,提出了独立性假设和非独立性假设下的渐近和近似非条件的检验过程,Tang等[5]基于2种药物治疗率之差提出了其置信区间的构造方法。对于混合单双边试验数据,Pei等[6]基于治愈率之比研究了2种治疗的等价性检验问题,覃愿等[7]研究了单双边混合试验设计下,2种治疗的治愈率之比的渐近置信区间。
然而,在临床试验研究中,对样本量的研究也是至关重要的。对于具有组内相关的双边试验数据,邱世芳等[8-9]基于比例差分别从显著性检验的角度和区间估计的角度,推导了近似样本量的公式和有效算法。然而,对单双边混合试验设计下基于比例差的区间估计所需要的样本量的确定还未有文献研究,本文将就此问题进行研究,提出几种有效的样本量的确定公式或有效算法。
1 数据结构与概率模型
假设i=0表示使用Cefaclor的治疗组,i=1表示使用Amoxicillin的治疗组。假设(i=0,1;q=1,2)表示个体接受第i种治疗后,有h只耳朵被完全治愈的患者的个数。当q=1时,代表单边数据,此时h=0,1;当q=2时,代表双边数据,此时h=0,1,2代表其相应的概率。单双边混合试验设计下的数据结构如表2所示。

表2 单双边混合试验数据的观测频数及相应的概率

其中,R是用来衡量患者2只耳朵相关性的指标。显然,当R=1时,表示2只耳朵完全独立,即1只耳朵治愈与另外1只耳朵治愈情况完全无关。基于以上假设,易得到:

令Δ表示2种药物治疗的治愈率之差,即Δ=λ0-λ1。因此,在此模型下,对于观测频数m=的对数似然函数为:

式中:C是1个常数。本文所感兴趣的参数是Δ,λ1和R是当前问题的讨厌参数。
2 样本量的确定
2.1 基于非限制性极大似然估计的Wald置信区间的样本量

因此,Δ的100(1-α)%置信区间为
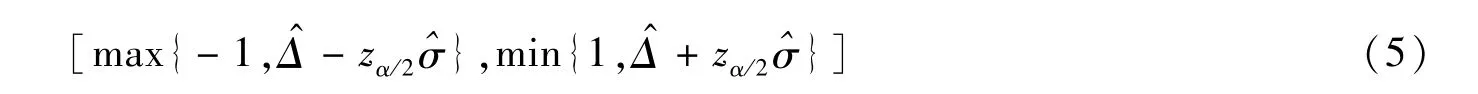
式中:zα/2是标准正态分布的上α/2分位数。简单计算可以得到Δ的100(1-α)%置信区间宽度控制在2ω内的样本量为

2.2 基于限制性极大似然估计的Wald置信区间、Score置信区间和似然比置信区间的样本量
2.2.1 基于限制性极大似然估计的Wald统计量的置信区间
在给定的原假设Δ=Δ0下,λ1和R的限制性极大似然估计和可以通过如下的方程组求得:

这个方程组是没有显示解的,因此可以通过一种迭代的方法(如Fisher-Score迭代)求解。的方差中的参数可以使用其限制性极大似然估计,从而得到的方差的估计为:


此方程没有显示解,可通过迭代法求出此方程的解。
2.2.2 基于Score检验统计量的置信区间
在Rosner模型下,假设检验H0∶Δ=Δ0的Score检验统计量为:


下限和上限分别是方程Ts(Δ)=zα/2和Ts(Δ)=-zα/2的解。
2.2.3 基于似然比检验统计量的置信区间
当样本量足够大时,Rosner模型下,对于假设检验H0∶Δ=Δ0的似然比检验统计量为:

在大样本下Tl服从自由度为1的卡方分布。因此,基于似然比统计量关于Δ的100(1-α)%置信区间上下限可通过迭代方法求解关于Δ的方程得到:
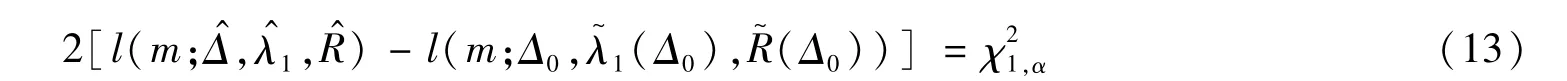
2.2.4 样本量的数值解法
由于基于限制性极大似然估计的Wald检验统计量、Score检验统计量和似然比检验统计量的置信区间都没有显表达式,因而本文采用如下的近似算法来计算区间宽度控制在2ω内的样本量:
步骤1给定m+1、R、λ1、Δ、κ和s的值,产生K组样本其中服从二项分布服从三项分布
步骤2基于步骤1产生的随机样本,分别通过式(9)(11)(13)得到Δ的100(1-α)%置信区间,从而得到在样本量m+1下Δ的经验区间宽度,记为c*(m+1)。
步骤3如果c*(m+1)大于(小于)2ω,则增大(减小)m+1的值,重复步骤1、2,直到区间宽度c*(m+1)非常接近于给定的区间宽度2ω,即满足min{m+1:|c*(m+1)-2ω≤0.001}的m+1即为所求的样本量。
通过以上算法获得的基于限制性极大似然估计的Wald、Score和似然比置信区间的样本量分别记为Nw2,Ns和Nl。
3 模拟研究
为了检验所提出方法的准确性,考虑参数设置:Δ=-0.1,0.0,0.1;λ1=0.3,0.5;R=1.0,1.2以及κ=1.0,1.2,s=0.5,1.0;置信水平为1-α=0.95,置信区间宽度的一半控制在ω=0.05,0.1下的样本量的确定。通过式(6)和样本量的数值算法,可得到近似的样本量Nw1、Nw2、Ns和Nl,为了考察样本量公式的准确性,基于估计的样本量,随机模拟计算了各种置信区间的经验覆盖概率(ECP)和经验覆盖宽度(ECW),结果见表3~6。
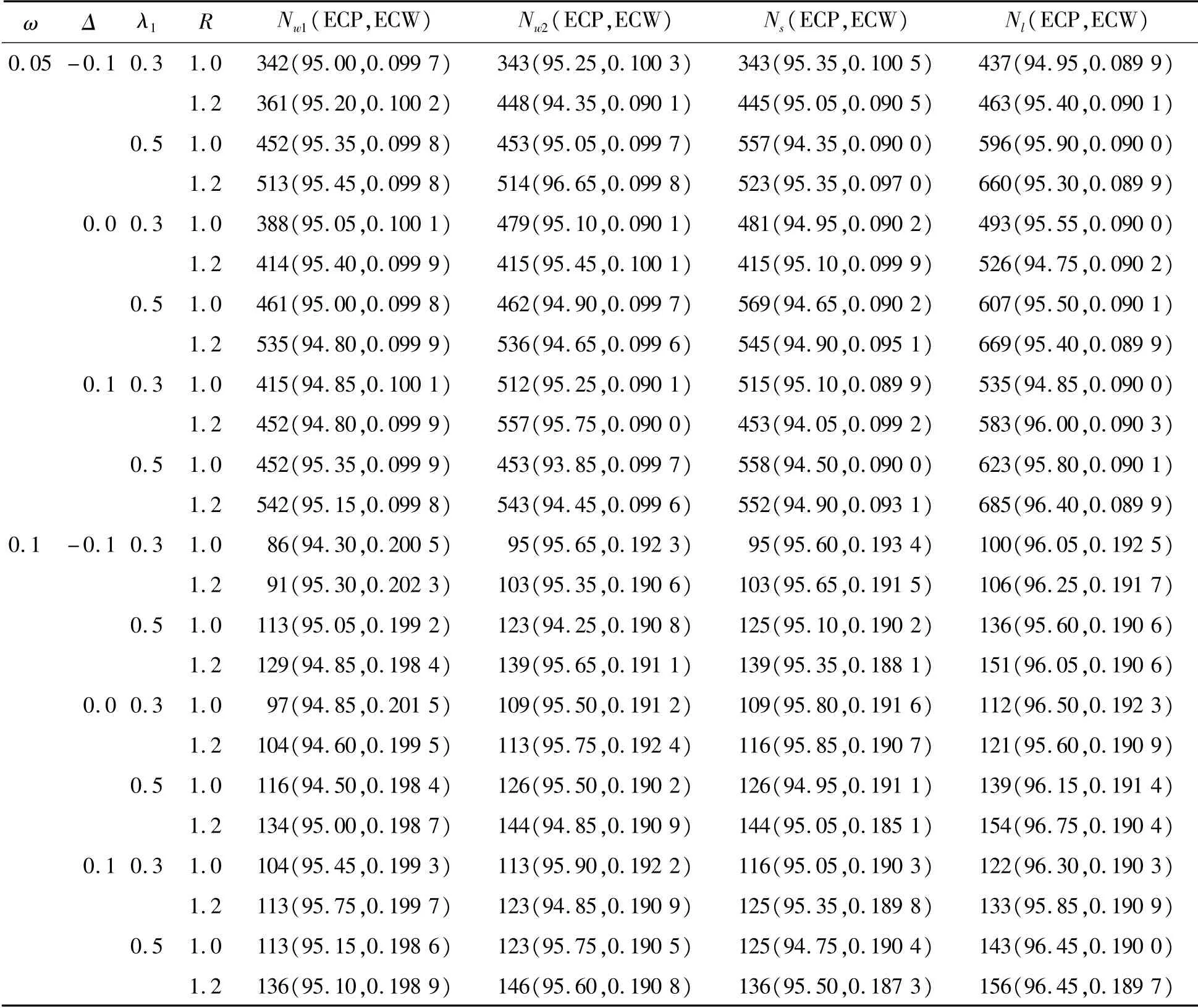
表3 置信区间宽度控制在2ω下的近似样本量、经验覆盖概率和区间宽度(κ=1.0,s=0.5)
模拟研究表明:
1)基于Wald置信区间、Score置信区间和似然比置信区间确定的样本量都很准确,因为在估计的样本量下,各种置信区间的经验覆盖概率接近于事先给定的置信水平,且半区间宽度也很接近预先设定的宽度ω。
2)在文中所提出的4种方法中,基于似然比置信区间得到的样本量是最大的,基于非限制性极大似然估计的Wald置信区间得到的样本量是最小的,基于限制性极大似然估计的Wald置信区间和基于Score置信区间所得到的样本量差别不大。
3)随着Δ、λ1、R的增大,要使95%的置信区间宽度控制在2ω以内,所需要的样本量就越大。

表4 置信区间宽度控制在2ω下的近似样本量、经验覆盖概率和区间宽度(κ=1.0,s=1.0)

续表(表4)
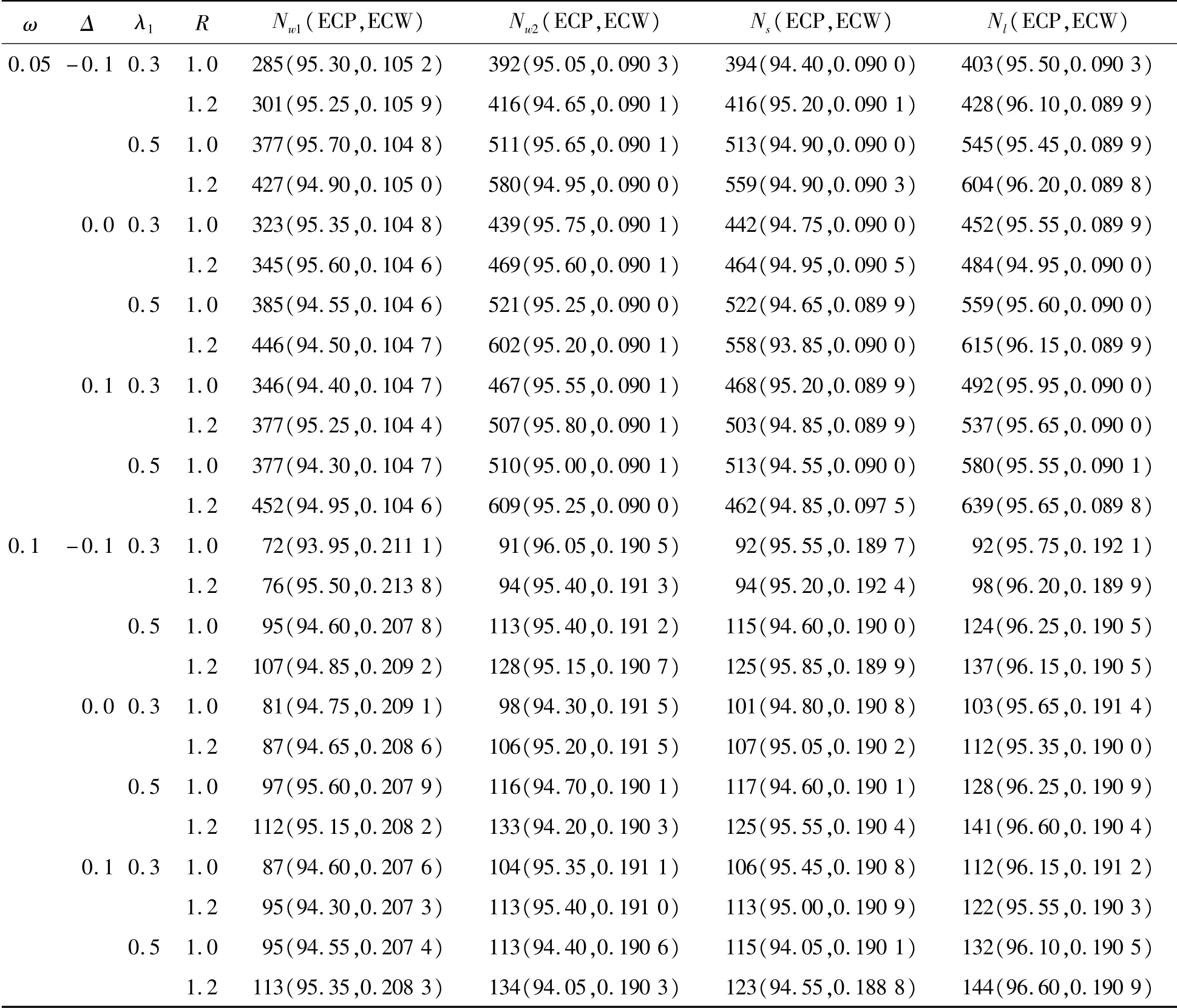
表5 置信区间宽度控制在2ω下的近似样本量、经验覆盖概率和区间宽度(κ=1.2,s=0.5)

表6 置信区间宽度控制在2ω下的近似样本量、经验覆盖概率和区间宽度(κ=1.2,s=1.0)
4 实例研究
对于表1中的儿童中耳炎数据,采用所提出的方法研究样本量。从表1的数据易知:=-0.203 7,=0.537,R^=1.517 1。因此,可认为此数据是高度组内相关的。假设κ=1.0,s=0.5,当ω=0.05时,利用提出的方法,可得到基于非限制性极大似然估计的Wald、限制性极大似然估计的Wald、Score和似然比置信区间确定的样本量(m+1)分别为:587、588、577、736。它们所对应的经验覆盖概率(经验覆盖宽度)分别为:95.45(0.099 9)、95.20(0.099 7)、94.80(0.090 1)、96.60(0.090 0)。当ω=0.1时、基于非限制性极大似然估计的Wald、限制性极大似然估计的Wald、Score和似然比置信区间方法确定的样本量(m+1)分别为:147、157、137、169。它们所对应的经验覆盖概率(经验覆盖宽度)分别为:94.60(0.198 6)、94.35(0.192 1)、94.95(0.184 8)、96.95(0.191 9)。
5 结论
基于单双边混合试验设计下治愈率之差,考虑了基于2种Wald型置信区间、Score置信区间和似然比置信区间的宽度控制在给定长度内的样本量计算公式和近似样本量的数值算法。通过研究表明:
1)基于Wald置信区间、Score置信区间和似然比置信区间所得到的近似样本量的置信区间的经验覆盖概率与给定的置信水平十分接近,且区间宽度也很接近设定的宽度,因此在实际中这4种方法应被推荐使用。
2)所需样本的大小与参数取值有关,参数Δ、λ1、R的值越大,所需要的样本量就越大。综上所述,文中提出的样本量的估计公式和数值算法都是有效的。
附录:
在Rosner模型下,检验H0′:Δ=Δ0的Score检验统计量为:

其中:

且

