融合上下文语义信息的汉越平行短语对抽取方法
2021-06-24高盛祥余正涛朱浩东文永华
杨 舰,高盛祥,余正涛,朱浩东,文永华
(1.昆明理工大学 信息工程与自动化学院,云南 昆明 650500; 2.昆明理工大学 云南省人工智能重点实验室,云南 昆明 650500)
自然处理应用依赖于大规模的平行语料库,而这种平行语料仅可用于少数几种语言,比如英语、中文、少数欧洲语言等,对于大多数其他语言,并行数据实际上是稀缺的.可比语料作为一种丰富型资源,为数据稀疏性问题提供了一种可能的解决方案.虽然在2个可比较的文档之间很少有句子级平行的情况,但是在可比较的语料库中仍然存在潜在的大量并行短语,从可比语料中抽取平行短语对能缓解资源匮乏的语言数据稀疏性问题.
随着互联网的快速发展,网络上存在大量的汉越可比语料资源,如维基百科的汉越对照页面,双语新闻网站等,这些新闻都是对同一事件进行描述,但并不是完全对齐的双语文本.从这些双语文本能很好的提取双语知识,主要的提取任务有双语词典抽取,其主要是基于WordNet的语义相似性度量的使用,它可以消除翻译后的上下文向量的歧义,然后通过种子字典构建2种语言之间的双语词典,这个方法的关键是种子字典,它在影响精度方面起着重要作用[1].如双语短语对抽取,Zhang等使用SVM来从可比语料中抽取平行短语对,但是该方法需要人工设计短语特征,如:短语长度差、短语单词数目等等,非常耗费人力和资源[2].近年来,随着将词使用分布式表示方法得到低维向量表示取得了较好的效果,越来越多的研究人员开始研究更大语言单元的分布式表示问题,尤其是短语[3],是由词组成,但粒度又比句子小,如Mikolov等人将短语视为不可分的n-gram[4],Socher等提出了递归自编码器来学习短语表示[5-8].然而上述的短语表示很少考虑融入上下文语义信息,使得短语表示脱离了句子语义本身,抽取出的短语准确率不高,因此本文提出融合上下文语义信息的汉越平行短语对抽取方法,主要利用注意力机制将句子编码向量融入到短语向量中,本文为了学习双语短语表示,引入半监督自编码器,如下图1所示,利用平行短语对作为约束条件,诱导性的学习双语短语表示,在本文提出的方法中有效避免了构建SVM分类器模型需要使用的特征选择过程,也引入了上下文语义信息和双语短语对的约束条件来学习双语短语向量表示.
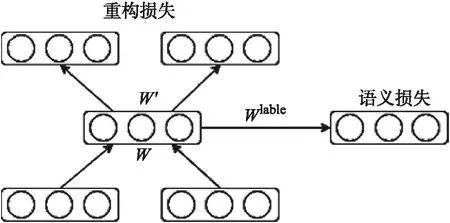
图1 半监督自编码器
文中的主要贡献有以下2个方面:(1)融合上下文语义信息到短语表示中;(2)学习双语短语向量表示的预训练编码器.
1 相关工作
可比语料作为丰富型的语料资源,为数据稀疏性问题提供了一种很好的解决方案,早期对可比语料库的许多尝试都集中在学习双语单词翻译,这些尝试的基本假设是基于单词及其翻译在相应的语言中以相似的上下文出现,因此可以使用共现统计来检测它们;Munteanu等首次提出了从可比句子中检测亚句片段[9].
目前,从可比语料库中抽取平行短语对的方法主要有以下几种方法:(1)SVM分类器,Zhang等提出将短语提取作为分类任务,首先在平行语料库中通过GIZA++生成所有可能的短语对,将平行短语对设置为正例,然后把非平行的短语设置为负例;然后,人工设计短语对特征,如短语长度差、相同起始、相同结尾、短语中单词数目等;最后,构建SVM分类器以判断短语对是否平行[10-11].(2)模板方法,Santanu Pal等人通过定义模板方法抽取短语对来提升英语-孟加拉语机器翻译的性能.首先,使用文本蕴含方法将双语可比语料库的两侧分为几组;然后,使用概率双语词典的n-best列表在组之间建立了跨语言链接;最后,在每个对齐的组之间使用了基于模板的短语提取技术[12].Hewavitharana S等从可比句子对中,绕过非平行片段,只对齐平行片段,抽取双语平行短语,融合到统计机器翻译中,解决数据稀疏的问题[13];(3)短语树对齐,Zhan等[14]提出了一种利用解析技术和词对齐方法从汉英双语语料库中提取短语翻译对的新方法.
在上述方法中,基本上是利用短语的特征来提出算法和分类器等,而实际上,上下文语义信息对于短语的定位、切割有很重要的支撑作用,同时,表示学习方法能够有效的学习到短语本身的特征.因此,本文提出融合上下文语义信息的汉越平行短语对抽取方法,来从可比语料中抽取平行短语对,缓解汉越数据稀疏的问题.
2 融合上下文语义信息的汉越平行短语对抽取模型
考虑到上下文语义信息会对平行短语对抽取产生影响,本文提出的融合上下文语义信息的汉越平行句对抽取模型,主要基于两部分组成:预训练模型和分类器模型.对于预训练模型,其主要目的是预训练出编码器,通过注意力机制将句子编码信息融入到短语中,同时,利用平行短语对约束学习汉越双语短语表示,如下图2(A)所示.分类器模型则主要是由编码器和全连接层组成,如下图2(B)所示.
其中源语言句子A和目标语言句子B代表汉越平行句对,源语言短语X和目标语言短语Y分别表示A,B句子中利用工具抽取到的汉语短语集合及越南语短语集合.图2(A)左边输入为汉语句子和汉语短语,输出的X1是带有上下文语义信息的汉语短语,右半部分输入为越南语句子和越南语短语,输出的Y1是带有上下文语义信息的越南语短语,这个过程为自编码,其中损失称为重构损失.为了使汉语、越南语训练的短语向量相关联,采取训练双语词向量的方法训练双语短语向量,让汉、越短语向量在空间中靠近,目的是把学习到的汉、越短语编码器用作分类器.如图2(B)中所示,把编码器学习到的参数用到分类器中再进行微调以得到效果最优的分类器,其中源语言句子C和目标语言句子D代表可比句子,源语言短语M和目标语言短语N代表C,D句子中的汉、越短语.
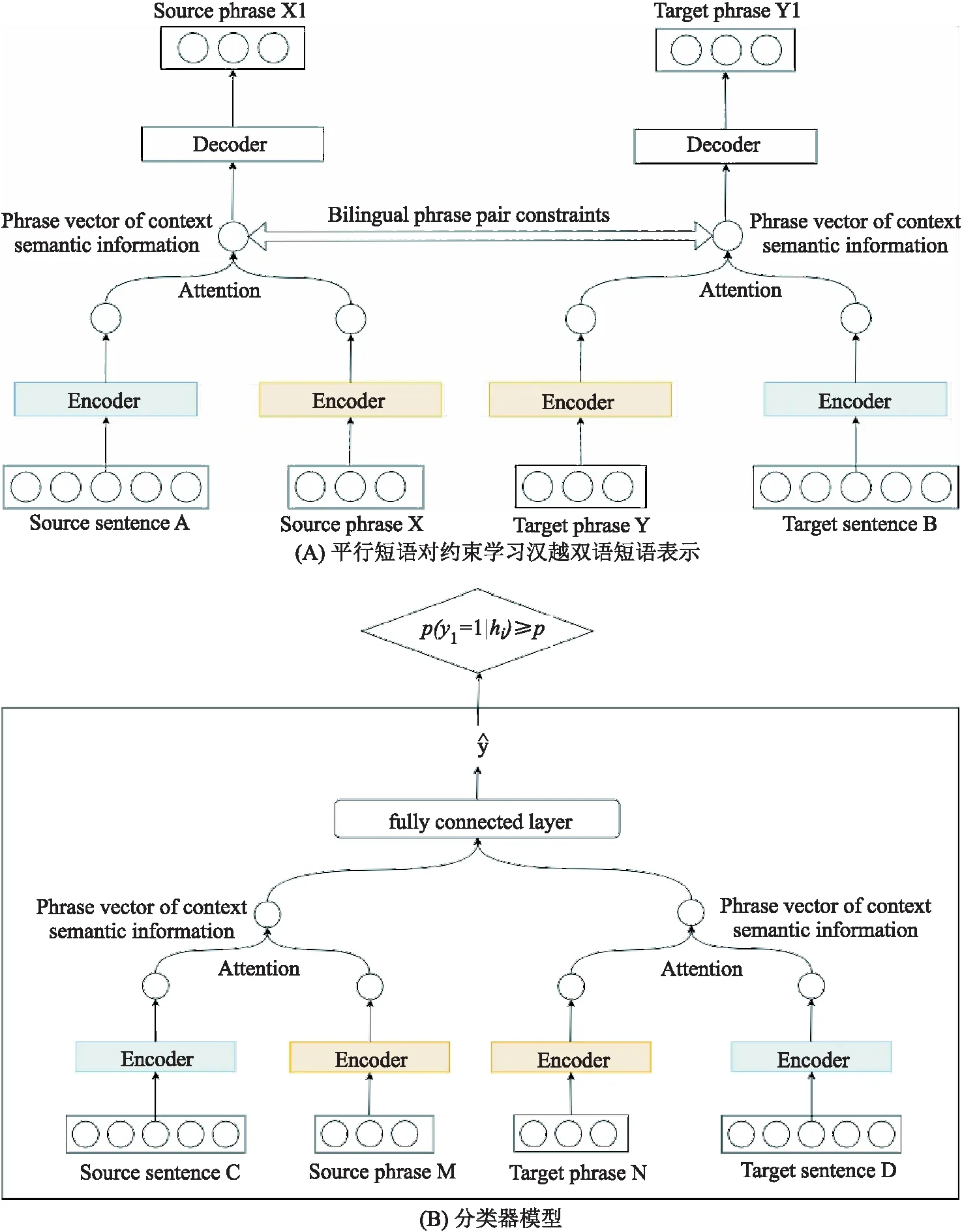
图2 模型架构
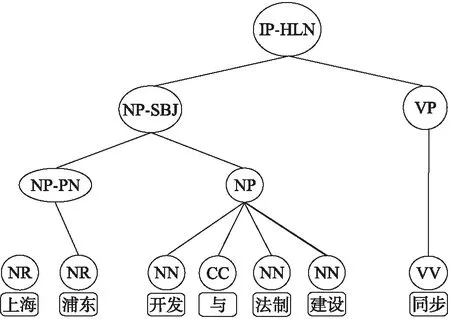
图3 汉语短语结构树
2.1 汉、越单语短语抽取
在本小节中,将从汉越可比语料中抽取汉语、越南语的短语集合,以便模型从中抽取出平行短语对,对于汉语和越南语的短语抽取,先利用伪平行句对抽取模型方式从可比语料中得到可比句子,将可比句子转化为短语结构树的形式[15-16],然后根据短语结构树中的结点来获取短语.汉、越单语短语抽取方法一致,以中文为例,如下图3所示.
具体描述如下:
1) 利用斯坦福工具可以将句子转化为Tree结构.
2) 对Tree结构进行遍历,对于本文来说,只需将叶子节点以及相应的父结点取出来,如NP-PN,NP等.
3) 对于每个父结点可认为是句子中的一个短语,再利用短语中包含的单词个数进行二次筛选.
4) 最后得到了汉语短语集合和越南语短语集合.
2.2 融合上下文语义信息的预训练模型
本文的预训练模型主要利用上下文信息和双语短语对作为约束训练出汉、越编码器.模型的实现主要是基于半监督自编码.从上图2(A)可看出,本文通过平行句对以及其包含的短语对作为训练语料,在编码层通过LSTM模型获取短语和句子特征,经过注意力机制把获取到的特征融入到短语表示中,使其带有一定的上下文语义信息.对于给定长度为m个词组成的句子x={x1,x2,…,xm},LSTM编码得到的隐含向量ht在时间步为t时刻的更新公式如下所示:
ht=f(xt,ht-1),
(1)
其中,xt表示第t个词,ht-1表示t-1时刻的隐含向量,通过逐词编码,生成句子语义向量h,同理,可以得到短语编码向量.为了获取最终包含上下文语义信息的短语向量表示c,通过注意力机制将句子编码向量h和短语每个时刻的隐状态hj=(h1,h2,…,hn)进行结合,如下公式所示:
(2)
(3)
et,j=a(st-1,hj),
(4)
其中,et,j表示的是句子编码向量和短语中的对应关系,at,j则代表所占权重大小.a是匹配函数,其目的是计算该时刻两个隐层状态的匹配程度.其具体实现有多种方法,本文中采用点乘法.在解码层同样使用LSTM进行解码,引入注意力机制后t时刻词的产生概率公式如下所示:
st=f(st-1,yt-1,ct),
(5)
(6)
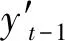
定义重构损失为Erec,其中s是源短语的向量列表,s′是目标短语的向量列表,si表示短语中的每一个词,如下公式所示:
(7)
因此,汉越双语短语对可以用(s,t)表示,θ为参数,分别学习到的向量特征代表源语言及目标语言短语对的约束程度:
Erec(s,t;θ)=Erec(s;θ)+Erec(t;θ).
(8)
为了学习到双语短语表示,本文将平行短语对作为约束条件,目的是使得源语言的短语语义表示和目标语言的短语语义表示距离最小化,由于两种语言的词嵌入是分别单独学习的并且位于不同的向量空间中,因此假设两个语义嵌入空间之间存在转换矩阵w,则双语短语语义损失为Esem(s,t;θ),如下式所示:
Esem(s,t;θ)=Esem(s|t;θ)+Esem(t|s;θ).
(9)
用ps表示源短语s的向量特征,对语义损失作以下变换,首先将转换矩阵w*pt,添加偏置项b,激活函数使用f=tanh激活函数,最后,我们计算它们的欧几里得距离为:
(10)
Esem(s|t;θ) 可以使用相同的方式计算.
由于公式9只计算了语义的正向误差,所以为了增强语义错误使用了正反两个例子,即相应的最大语义边际误差变为
(11)
2.3 融合上下文语义信息的汉越短语对分类器
本文的短语对分类器模型主要是通过少量语料,对预训练好的编码器进行微调,对含有上下文语义信息的汉越短语向量输入到全连接层中进行Softmax分类,用来判断任意的汉、越短语是否为平行短语对,首先对短语对进行点乘和相减得到包含下文语义信息的短语向量表示c,然后分别与权重矩阵Wa及Wb点乘使之处于同一向量空间,加上偏置项b后使用激活函数tanh得到隐状态hi,最后计算出短语对的概率p,σ代表sigmoid激活函数,公式如下所示:
(12)
(13)
(14)
p(yi)=σ(Wchi+c).
(15)
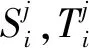
E(s,t;θ)=αErec(s,t;θ)+(1-α)Esem(s,t;θ).
(16)
超参数α代表了重构损失和语义损失的占比程度,模型在训练集中要达到的最终目是:
(17)
本文的分类器的损失函数应为:
(18)
3 实验与分析

表1 语料统计表

表2 实验语料

表3 实验设置
3.1 实验数据
为验证本文提出融合上下文语义信息的汉越平行短语对抽取方法的效果,本文的实验数据规模如下表1所示,主要包含汉越平行语料和汉越可比语料.对于汉越平行语料,主要是利用GIZA++和一致性短语算法,获取的平行短语对作为正例,非平行短语对作为负例.对于汉越可比语料,先得到可比语料中的可比句子,然后利用短语树,得到句子中的短语集合.
本文模型的实验设置如下表3所示.
实验中采用了基于SVM的分类器[2]模型、自编码器Auto Encoder训练的分类器模型和融合短语对的半监督自编码器Semi-AutoEncoder模型与本文模型在汉越短语对抽取效果上进行比较.其中SVM的参数设置及分类特征选择引用Munteanu[9]的方法.Auto Encoder选择tensorflow1.14版本,使用gpu,latent_size设置为128,batch_size设置为512,test_batch_size设置为256,training_epochs设置为50,神经网络层数3层.Semi-AutoEncoder其参数training_epoches设置为100,drop_out设置为0.5,word_ebd_dims设置为300,dev_batch_size设置为50.
3.2 评测指标
为了验证方法的有效性,本文采用准确率(Precision)、召回率(Recall)、F值(F-Measure)作为评测指标.计算公式如下:
(18)
(19)
(20)
3.3 实验结果与分析
实验1汉越短语对抽取实验对比
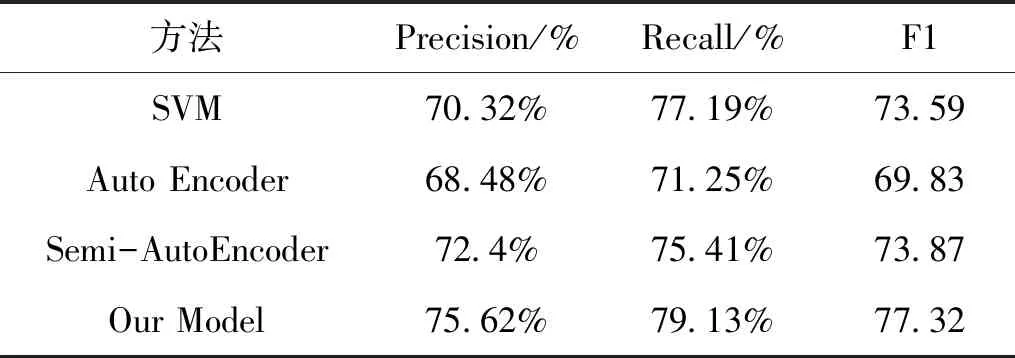
表4 汉越短语对抽取实验对比
从表4实验结果可以看出,对比SVM和AutoEncoder模型可知,将汉、越短语向量分别训练效果不是很好,而当添加了短语对作为Semi-AutoEncoder约束,其准确度超过了基于SVM的分类器,同时,也可以看出本文提出融合上下文语义信息的汉越平行句对抽取模型,其准确率达到了75.62%,召回率为79.13%,相比于其他模型来说,都有所提升.说明融入了上下文语义信息的句子对分类器模型准确地更高更好.
实验2短语对融入Moses系统前后Blue值对比
同时,为了检测本文从可比语料中抽取的平行短语对能否提升翻译性能,本文搭建了Moses翻译系统,在数据清洗时将长语句与空语句删除,词对齐使用GIZA++训练,语言模型训练使用IRSTLM,最后对pharse-table和reordering-table进行优化加快速度,首先用汉越平行语料训练得到基线的Blue值,然后将本文抽取的平行短语对添加到训练数据中观察Blue值的提升.性能评估使用BLEU值,实验结果如表5所示:

表5 融合短语对的机器翻译
从表5可以看出,当增加从可比语料中抽取的平行句对为200 k时,其BLEU增加了0.48,短语对增加为500 k时,BLUE值增加为0.93.从中我们可以看出,抽取的平行短语对能够有效提高机器翻译的性能.而随着增加更多的平行短语对,性能会更优.因此,从可比语料中抽取知识是一种能够有效解决数据稀缺型问题.
实验3融入短语对后的译文示例
表6给出的是基线系统与本文提出的加入抽取短语对后的翻译对比示例.

4 结语
本文为了解决稀缺型数据稀缺的问题,利用可比语料作为丰富型资源的特点,提出融合上下文语义信息的平行短语对抽取方法,从可比语料中抽取平行短语对,该方法主要考虑句子能为短语提供上下文信息以及平行短语对作为半监督的约束条件,可以预训练出编码器,通过预训练的编码器很容易训练出汉越双语平行短语对分类器,实验结果表明,本文方法相比传统的手工设计特征的基于SVM分类器方法性能有所提升,同时将本文方法用于抽取平行短语对应用于Moses系统中,也提高了翻译性能.在接下来的工作中,探索将抽取的平行短语对融入到端到端的神经机器翻译.
