融合表示学习的文档链接网络语义社区发现
2021-06-19郭江林
郭江林
(河北地质大学信息工程学院,河北 石家庄 050031)
0 引言
网络是一种通用的数据结构[1],由节点和边构成,其中节点代表实体,边代表实体间的关系。属性网络[2]是在网络的基础上考虑了节点和边的属性信息。在现实世界中互联网每时每刻都在产生海量数据,这些数据便可构成属性网络,例如文档链接网络、社交网络、铁路网络。这些网络涉及关乎社会发展和民生的各个领域,因此有大量学者研究属性网络。以文档链接网络为例,网络中的节点代表论文,网络中的边代表论文间具有引用关系,而节点的属性代表论文的具体内容。对文档链接网络做社区发现和表示学习可以将属于同一主题的文档聚类,也可以获得文档的表示。
社区发现是分析网络的一个基本任务,它旨在将网络中的节点划分为不同的社区。同一社区内的节点彼此联系较为紧密,而不同社区间的节点联系较为稀疏。社区发现可以有效的捕获网络的全局结构。很多社区发现方法是基于矩阵分解的。这些方法通常会利用图的邻接矩阵或其他矩阵的低秩分解。如Fei Wang等人提出的三种非负矩阵分解(NMF)技术[3]和Jaewon Yang等人提出的BIGCLAM(Cluster Affiliation Model for Big Networks)[4]。但是,这些方法由于矩阵分解的复杂性而无法扩展。还有很多社区发现方法模拟了图的生成过程构建了生成模型,例如 Hongyi Zhang等人提出的 PNMF(preference-based nonnegative matrix factorization)[5]模型和Mingyuan Zhou提出的EPM(edge partition model)模型[6]。由于这些方法是基于生成模型的,因此可以用于生成网络和预测缺失的边。
对网络中节点进行表示学习旨在获得节点的分布式表示,节点表示可以有效捕获网络的局部结构,可以使局部连通性相似的节点具有相似的表示。应用到文档链接网络中便可使具有相似引用关系的论文表示相似。经典的网络表示学习方法包括 DeepWalk[7],LINE[8],node2vec[9]。这些方法通过随机游走探索每个节点的局部联通性。但是这些方法考虑的是图的局部信息,而忽略了全局社区信息。
已有方法共同考虑社区发现和表示学习[10],但这些方法并非同步解决社区发现和表示学习。而Fan-Yun Sun等人提出的VGRAP[1]模型通过概率生成模型来同步进行社区发现和表示学习。但该方法并未考虑节点的属性信息即文档的内容信息。本文提出的RColc模型融合表示学习对文档链接网络进行了语义社区发现学习,不仅对节点邻居的生成过程建模,还对节点属性的生成过程建模。
1 RColc模型
RColc模型是针对文档链接网络融合表示学习进行社区发现的方法。RColc模型的图表示如图1所示,它是一个联合概率模型,虚线框描述了文档文本内容部分,实线框描述文档链接的拓扑部分,这两部分共享的是特定于文档的混合比例p(z|d)。这种联合建模方法的优点是,它以原则性的方式集成了内容和链接信息。其中,φn表示节点dn的嵌入,ψ表示社区嵌入,φ表示p(c|z)生成的节点的嵌入,μ表示p(w|z)生成的节点的嵌入。
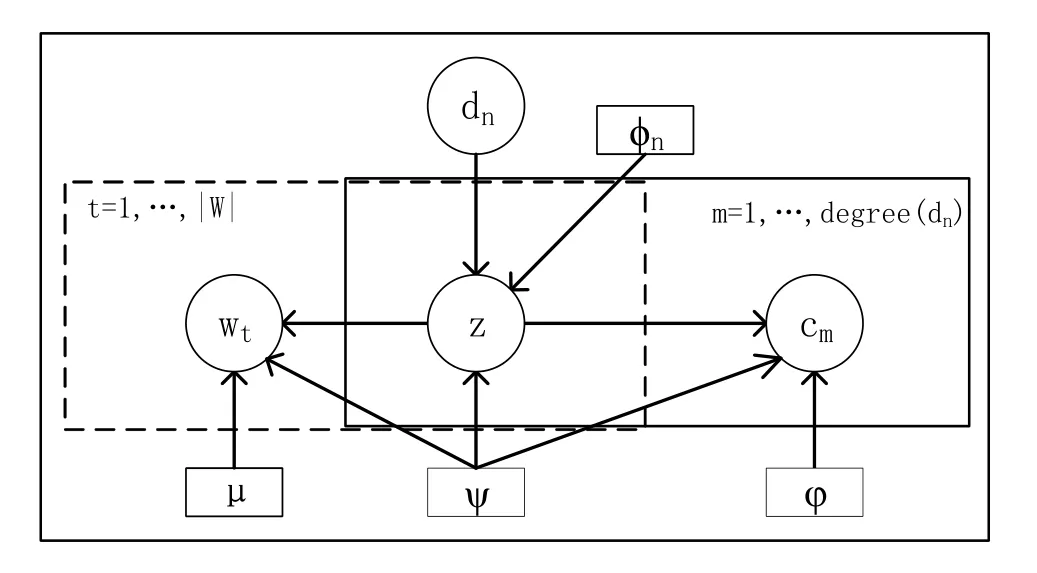
图1 RColc的图表示Fig.1 Graph representation of RColc
RColc对节点邻居(文档链接)和节点属性(文档内容)的生成建模。生成过程如下:
1.根据分布p(dn)随机选择一个节点dn
2.根据p(z|dn)为节点绘制一个社区分配z:
(a)以p(c|z)的概率生成节点的邻居
(b)以p(w|z)的概率生成节点的属性w
这个生成过程用概率的表达方式如公式(1)所示:

RColc通过引入一组节点嵌入和社区嵌入参数化分布p(z|d),p(c|z)和p(w|z)。令φi表示分布p(z|d)中使用的节点i的嵌入,φi表示分布p(c|z)中使用的节点i的嵌入,μt表示分布p(w|z)中使用的节点t的嵌入,ψk表示第k个社区的嵌入。由于三者都是基于类似的分解,可以通过三个softmax模型参数化社区分布、节点分布以及节点属性分布,分别如公式(2)、(3)、(4)所示:
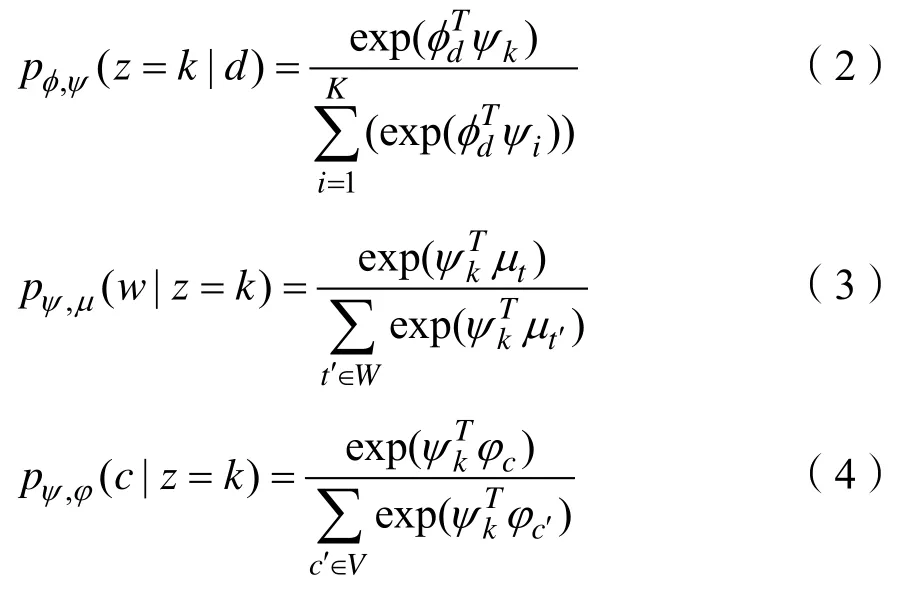
式(3)中的W代表语料库的大小,式(4)中的V代表总链接数,因此公式(3)、(4)的计算成本和总链接数与语料库的大小成正比,在实践中是不可行的。对于这种情况,与标准的skip-gram模型类似,采用负采样方法提高效率,对每一个单词训练时,对词汇表中的词汇进行随机采样,只更新部分权重;同理,在对文档链接训练时,在所有目标节点中随机采样。只更新部分目标节点的权重。使用负采样后,如公式(5)、(6)所示:
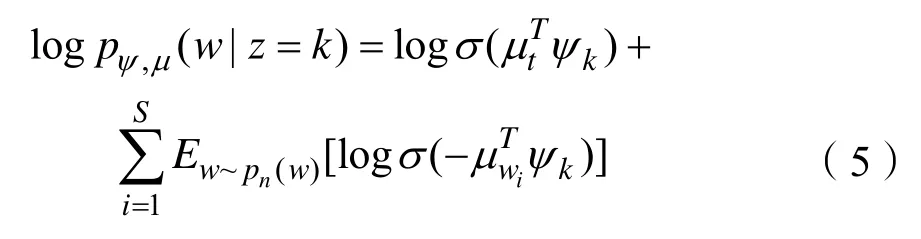

式(5)、(6)中的σ(x)代表 sigmoid函数,σ(x)= 1 /(1+exp(-x));S是负采样的个数。进行负采样时使用频率的次方,这是根据经验来的,在Mikolov et al[11]的文章中,他们说这个公式比其他函数的表现更优。
我们通过最大化观测变量的对数似然来学习模型参数,和的对数在进行梯度回传求解导数时过于繁琐,考虑将其转化为对数的和减少计算量,我们使用Jesson不等式将和的对数转换为对数的和,将式(1)转化为式(7)(8)所示:
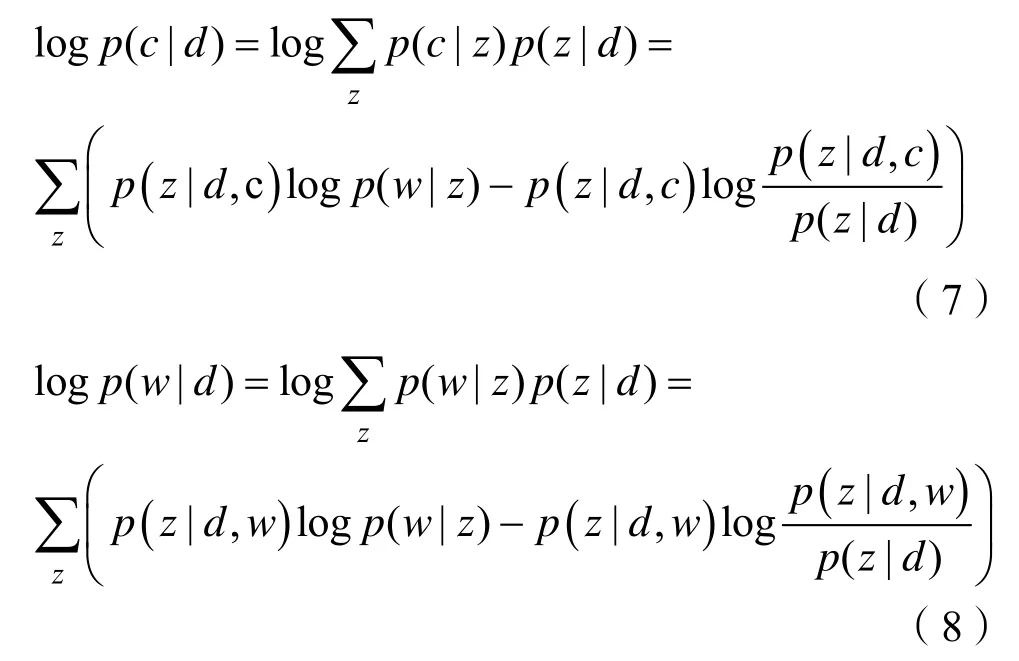
式(7)、(8)中p(z|d,c )和p(z|d,w)难以求解,我们使用变分推断求得参数分布q(z|c,d)和q(z|w,d)来分别近似真实后验分布p(z|d, c)和p(z|d,w),通过最小化每个数据点的变分分布和真实后验分布之间的Kullback-Leible(rK-L散度)来实现。具体来说,我们使用神经网络参数化变分分布q(z|c,d)和q(z|w,d),如式(9)(10)所示:
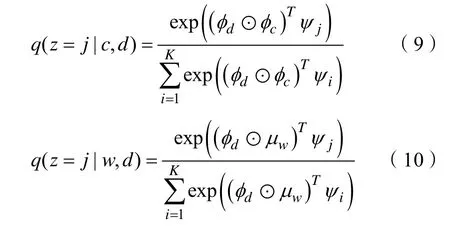
式(9)(10)中⊙代表元素乘法,之所以使用元素乘法是因为源节点的表示与目标节点和源节点的表示与节点属性的表示是对称的,并且可以将文档与链接文档的表示、文档与文档内容的表示联系起来。
q(z|c,d)代表(d,c)的社区成员,q(z|w,d)代表(d,w)的社区成员。我们将每个节点的链接文档和每个节点的属性进行加权聚合,用来近似每个节点d的社区成员分布,p(z|d)的计算如公式(11)所示:

式(11)中N(d)是节点d的链接节点集合,W(d)是节点d的属性集合。我们使用 argmax来近似推断p(z|d),对于文档与链接节点和文档与内容节点的相对重要性对p(z|d)进行切分,一般我们把在同一个主题下的文档链接在该主题下的概率和文档内容在该主题下的概率通过α加权聚合来求解社区z,具体求解如式(12)所示:
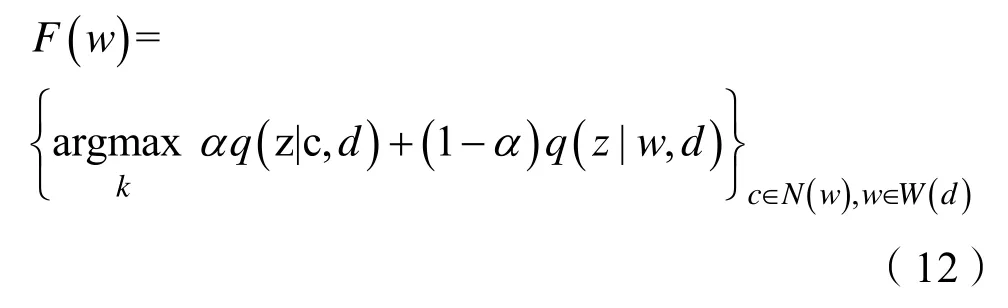
使用变分推断近似后,我们现在已经准备好所有能够计算的概率,得到最后的目标函数如式(13)所示:
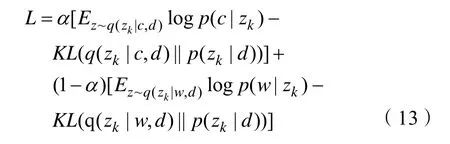
式(13)中α表示我们使用的权重,Ez~q(zk|c,d)logp(c|zk)和Ez~q(zk|w,d)logp(w|zk)分别表示logp(c|zk)和logp(w|zk)的期望。KL(·||·)表示两个分布之间的 Kullback-Leibler散度。KL散度越小说明两个分布越接近。
2 实验
这部分首先介绍使用的数据集和实验设置。然后,我们使用模块度(Modularity)[12]评估RColc模型得到的社区划分的效果。
2.1 数据集及实验设置
为了验证RColc模型的效果,我们在DBLP[13]、samll-hep和large-hep这三个文档链接网络的公共数据集上进行实验,这三个数据集中的文本是论文的标题和摘要,链接是论文间的引用关系。small-hep拥有397篇文档,三个类别,698个链接。DBLP数据集有6936篇文档,5个分类,12353个链接,large-hep有 11752篇文档,4个类别,134857个链接。数据集中的文本是每篇论文的标题和摘要,链接是论文间的引用关系。现在我们将对数据集进行处理,对于DBLP数据集,首先将数据集中所有文档中词频小于1的词去掉,然后将文档剩余词的个数小于10和大于50的文档从数据集中删除。再将这些删除的文档在文档链接中删除。最后得到1460篇文档,2848个链接。对于large-hep,我们将数据集中词频小于5的词删除,然后保留文档剩余词的个数在10和30之间的文档。最终得到3017篇文档,10323个链接。
实验电脑处理器为Intel(R) Core(TM) i7-3770 CPU,8G 内存,GeForce GTX1060 显卡。实验将文档的节点嵌入、社区嵌入和词嵌入维度都设为 128;权重α设为 0.75;学习率设为 0.05,迭代1000轮进行参数训练。
2.2 社区检测效果评估
我们通过模块度评估RColc模型社区检测的效果。模块度由Mark NewMan 提出,是常用的衡量网络社区结构强度的方法。模块度定义如式(14)所示:
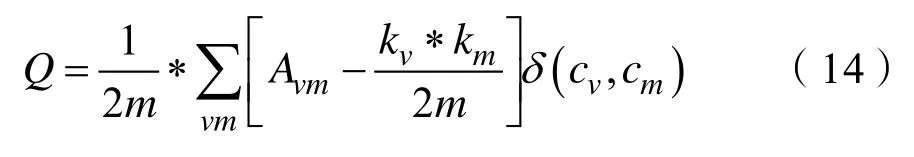
其中Q代表模块度,其值越大说明社区划分效果越好。当两个节点直接相连时Avw=1,否则Avw= 0 。kv代表节点v的度。当节点v和节点m在 同一个社区内δ(cv,cm)=1,否则δ(cv,cm)=0。
我们使用贝叶斯计算的 PHITS[14]和使用嵌入计算的Vgraph进行对比实验,实验结果如表1所示。

表1 真实数据集上算法的模块度对比结果Tab.1 Modularity comparison results of algorithms on real datasets
表1显示了本文提出的RColc模型在三个真实网络数据集上的运行结果,在社区划分任务上的效果明显优于对比模型。与PHITS模型相比,我们摒弃了使用朴素贝叶斯的传统计算方法,使用迭代更多,速度更快、适用性更强的神经网络进行计算,得到了更加准确的社区划分;与Vgraph模型相比,RColc模型除了考虑源节点及目标节点的节点嵌入外,还考虑了源节点的属性信息,因此社区划分的质量更高。
3 结语
本文提出了一种针对文档链接网络进行表示学习和语义社区发现的联合概率模型,对文档内容的生成过程和文档链接的生成过程建模,并用一组共同的潜在因素来解释文档内容和其引用关系。这种方法可以提高社区检测和文档表示的质量,在社区划分任务上证明其效果较好。未来将考虑对文档上下文的生成过程建模,并考虑解决一词多义带来的主题模糊性的问题。
