多任务数据采集系统的设计与实现
2021-06-19朱明超
朱明超,宋 晖
(东华大学 计算机科学与技术学院,上海 201620)
0 引言
近几年,越来越多的学者将目光聚焦在认知智能上,知识图谱受到越来越广泛的关注。随着知识图谱在各个领域中展现出价值,领域知识图谱构建成为智能应用系统的重要组成部分。在领域知识图谱构建过程中面对的首要问题是:领域数据的及时采集。知识图谱构建最常用的数据采集方式是网络数据采集。文献[2]通过人工操作方式从网页下载数据,文献[3]通过解析相关网页获得企业股票代码列表等企业信息。
领域数据通常有多个数据来源,获取途径相对分散,往往需要通过多渠道多次获取,费时费力。而且采集的数据无法及时与数据源同步。针对不同的数据源,采集任务的执行周期也不同,因此需要一个可从多数据源定时采集数据的系统。
本文针对领域数据采集问题,基于机器人流程自动化技术设计了支持数据定时采集和多任务并发处理的数据采集系统。此系统结合数据采集脚本和Celery定时任务实现了数据的定时采集,实现了Celery配置文件的动态加载与更新,使默认单线程的 Celery定时任务能够支持多任务并行。该系统基于Django开发框架及Docker容器技术进行开发和部署,提供了任务监控和数据管理功能。
1 相关技术
本系统采用Django快速开发框架搭建,使用Docker进行系统部署。数据采集最常使用的工具有Python爬虫工具库、爬虫框架和Selenium[5]自动化工具。本系统采用Selenium自动化工具进行数据采集。
已有的数据采集系统通常是单任务、面向特定需求的,如煤矿安全[6]、学科发展状态[10]和医疗数据等,可复用性弱。已有的面向多数据源的采集系统,不能保障多任务并行且无法保证数据的及时性。针对知识图谱数据获取的问题,本文参考分布式数据采集的实现思路[13]设计实现了多任务数据采集系统。
2 系统架构设计
本系统基于Django框架开发实现。系统分为任务管理和数据采集两大模块。
任务管理模块,将对特定数据源的采集脚本封装为任务。系统提供对任务的管理,包括任务定义、定时执行和多任务并发控制。
数据采集模块,包括数据采集、采集容错机制和数据存储。系统采用 MySQL和 Neo4j数据库分别存放任务信息和知识图谱的关系数据。系统架构如图1所示。
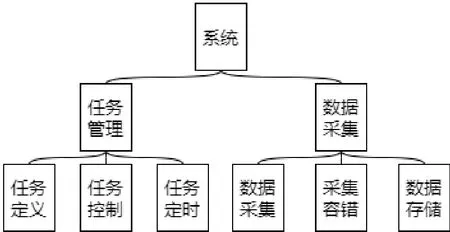
图1 系统架构Fig.1 System structure
3 系统核心功能设计
本系统使用Selenium自动化工具调用浏览器驱动,访问数据源网页,定位目标数据在网页结构中的位置以采集所需数据。此方式可以准确的采集页面中的目标数据。
系统的核心功能是定时任务、多任务并发控制、数据监控和数据管理。在Django框架下通常将数据采集任务封装为线性执行的函数,这种执行方式面临3个问题:(1)任务开始执行后,如果任务采集的数据太多或频繁切换网页会导致任务执行时间过长。采用线性执行方式会使系统前端页面一直处于等待状态,前端等待时间过长会导致页面长时间卡顿甚至报错,使得用户使用体验极差;(2)线性执行方式无法保证采集的数据与数据源同步更新,需频繁人工启动任务执行;(3)线性执行方式没有任务并发管理机制,多任务并行会导致采集报错。
为解决以上问题,本系统采用Django框架下最常用的定时任务实现工具 Celery。Celery中定时任务控制器Beat、中间件Broker和任务执行单元Worker分别负责任务分发,路由管理,具体任务执行。Celery定时任务流程为:Beat定时将任务派发给任务队列,任务队列和Worker的映射关系为路由,任务队列根据路由将任务分配给相应Worker执行。Celery默认只有一个队列和Worker,即只有一组路由。本系统以Celery定时任务为基础,设计实现了系统的核心功能。
3.1 数据定时采集
设置定时任务的关键步骤是任务注册和任务绑定。在采集脚本前加上“@app()”,将此采集脚本注册为Celery可识别的Task。在定时任务绑定页面从Celery已有Task列表中选择对应的采集脚本,设定执行间隔,定时任务名等参数。点击保存后将此Task的定时执行信息添加在定时任务表。如图2所示。
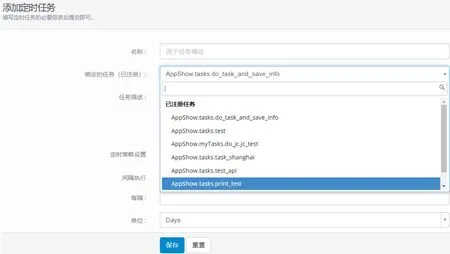
图2 定时任务绑定页Fig.2 Timed task binding page
基于Celery设计的定时采集任务,在任务执行中还需添加数据采集容错机制,解决数据重复采集问题。采集脚本在网页加载完成,网页中各元素的相对位置确定后,才能成功定位目标数据。当采集任务数据源响应慢或网络延迟时会导致页面数据定位失败等问题,为此系统设计了对应的容错机制,当捕获报错后,任务将主动等待一段时间后再次执行。任务重试次数和等待时间可在任务配置文件中设置。
Celery定时任务中同一任务多次执行时,如果每次执行没有标识,将导致每次采集的数据重复。为解决重复采集问题,本系统以数据发布日期来区分同一任务的多次执行。网页数据带有发布日期,在任务的配置文件中加入开始日期“start_date”和时间跨度“interval_time”两个参数,分别表示开始采集的数据日期和单次采集任务的时间跨度。采集任务把数据发布日期作为标识,本次任务执行开始日期取上次任务执行结束时的数据日期,若当前为第一次执行则取“start_date”。采集任务采集完一个日期的数据后,日期自增,任务采集下一日期数据,以上步骤循环“interval_time”次,完成此次采集任务。则每次采集任务是对上次采集任务的增量更新,数据源发布新数据时,新数据对应最新日期,下次采集时可增量采集新数据。采集任务按任务日期的时序采集数据,可以避免重复采集和对新数据的查询判断,保证数据采集的及时和高效。
3.2 多任务并发
使用定时任务方式执行采集脚本,Worker执行任务时最终是执行一个线性函数。当多个采集任务同时执行,默认都在系统的主进程执行,系统会因多个任务争用唯一的浏览器驱动而报错。同时Celery默认只有一个任务队列和一个Worker,多个任务并发会使任务队列阻塞。
本系统采用新的定时任务执行策略和新的Celery路由更新逻辑解决浏览器驱动争用和任务队列阻塞问题。
3.2.1 定时任务执行策略
默认的执行方式是 Worker执行任务时在系统的主进程中执行任务函数。新的策略是系统主进程中不再执行采集任务,采集任务在独立的线程中执行,每个线程有自己的上下文,互不影响。
3.2.2 Celery路由更新逻辑
Celery默认所有任务发送给唯一的默认任务队列,交由默认Worker执行。为了解决多任务并行队列阻塞问题,系统在新任务创建时为 Celery添加除默认路由之外的新路由,使其可以同时执行多个任务。Celery默认的路由更新方式是在Celery配置文件“celeryconfig.py”中手动添加路由。此种方式用户友好性很差,新的路由更新逻辑在新的定时任务创建时自动为此任务创建任务独占的路由,将其和原有路由一并写入新的路由字典,在配置文件“celeryconfig.py”中以文件读取的方式访问路由文件,读取新的路由字典替换原有的路由信息。
3.3 任务监控与数据管理
为了方便用户了解任务的执行情况,在系统主页上展示任务执行信息,并实时更新。系统调用Celery监控工具Flower提供的API获取每个任务状态的信息,并返回给前端,并将任务执行结果存入任务执行日志表中。调用Flower获取任务状态数据的API如图3所示。
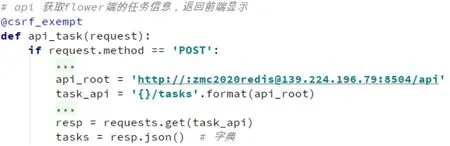
图3 任务状态APIFig.3 T ask status api
不同任务采集的数据不同,格式难以统一,数据存储时无法根据数据类型管理。为了统一管理,具体的数据如文字,pdf等作为附件以文件形式保存,不存入数据库,将数据保存的路径存入数据库。
4 系统实现与部署
为了使系统具备功能调整和扩展的能力,系统的功能修改和添加更加弹性化,本系统采用Docker容器技术在服务端进行动态部署,并使用Nginx+Uwsgi替换 Django自带的 Web服务。部署时根据系统包含的服务进行了容器划分,在docker-compose文件中编排容器。图4展示了服务端的Docker容器划分。(1)Web容器是主容器,运行基于 Django项目构建的Web镜像,包含项目的主要逻辑代码;(2)Nginx容器是Django自带Web服务的替代容器,提供对外的Web服务;(3)Selenium容器是数据采集支持容器,用于屏蔽系统环境对采集脚本的影响;(4)MySQL和Neo4j是两个数据库,分别在不同容器,为系统提供数据存取服务。
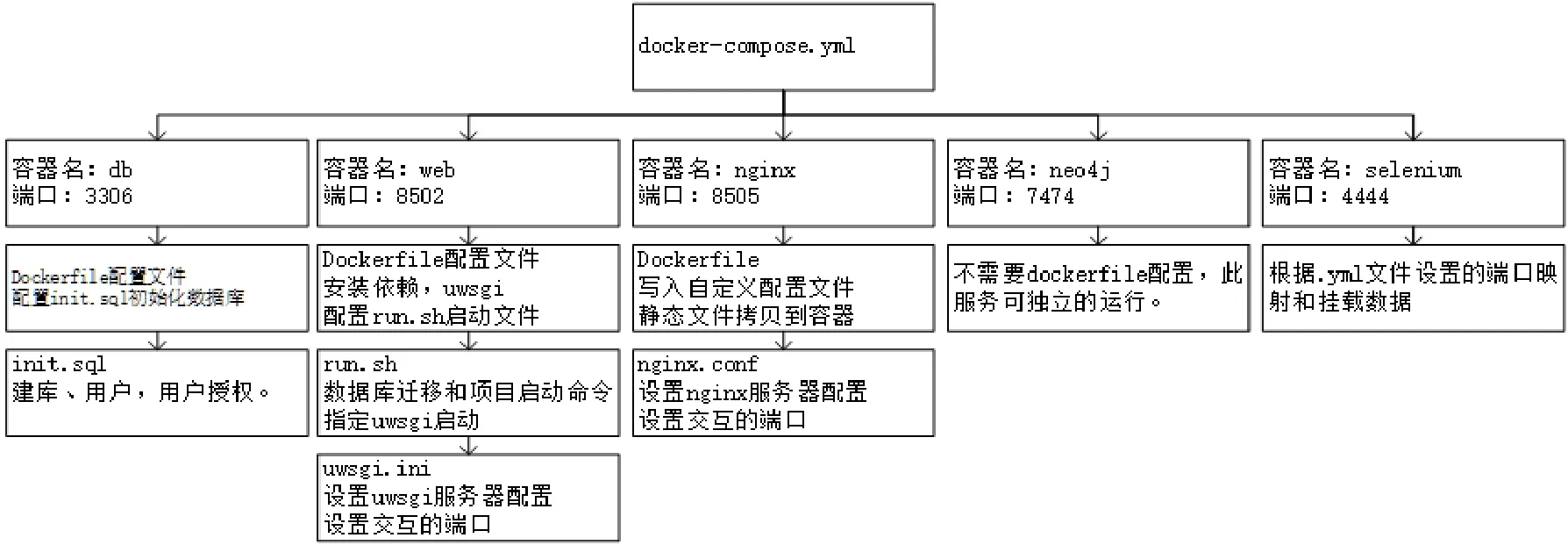
图4 容器划分Fig.4 Container division
系统主要页面包括主页、任务添加页、定时任务绑定页和数据查询展示页。主页如图5所示。左边三个板块分别是任务相关页面、数据相关页面和数据查询展示页面。主页中间是已有任务的信息及系统支持的对任务的操作,包括任务开始和停止、修改、删除和数据展示。主页下方是任务的执行状态信息。
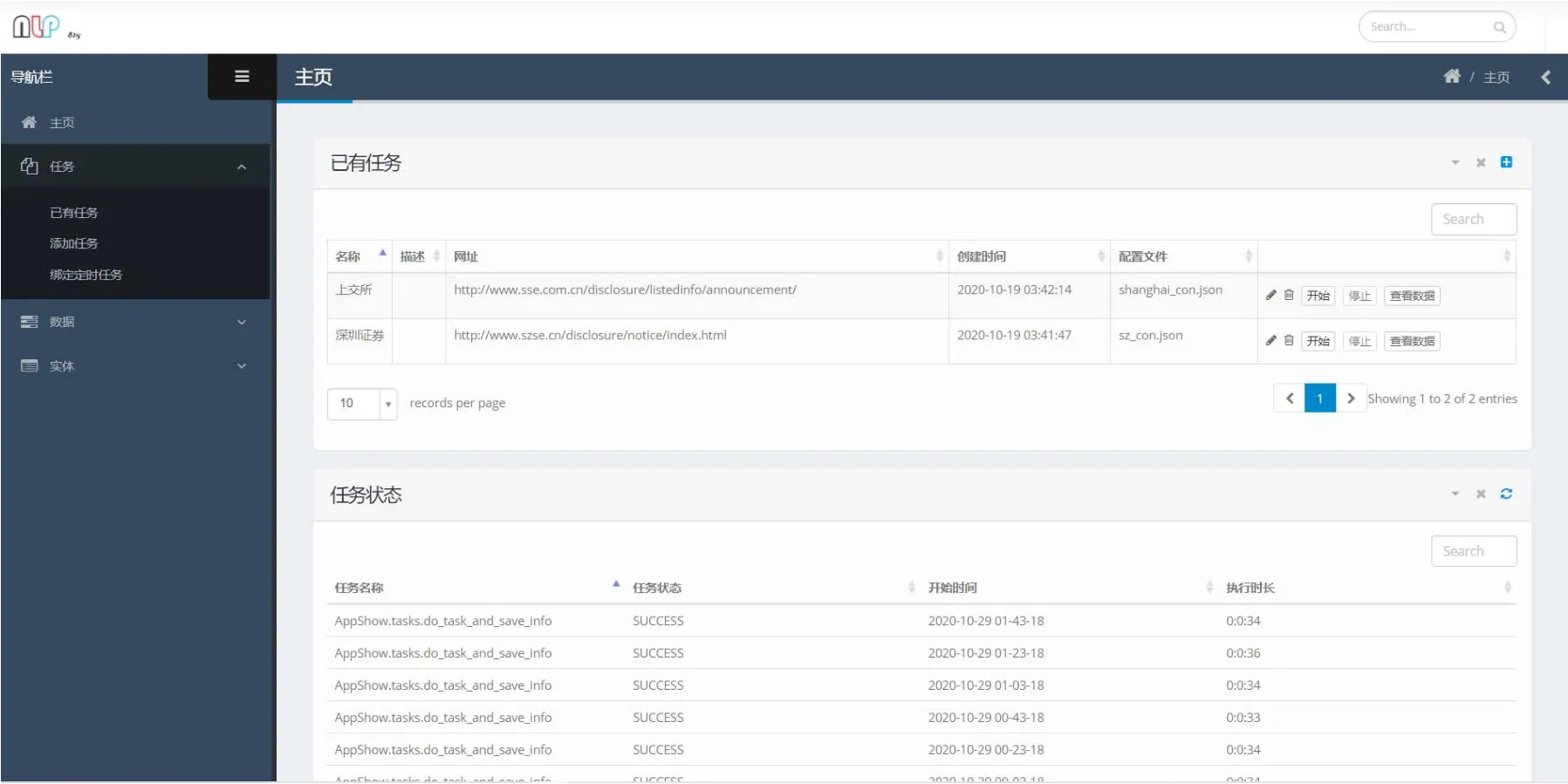
图5 主页Fig.5 Homepage
5 总结
本文针对领域知识图谱构建过程中遇到的领域数据采集难点,设计实现了多任务数据采集系统,给出了系统的架构设计和系统核心功能的设计与实现。最后展示了系统在服务端基于Docker容器的部署。
