基于PSENet的人民币文本检测方法
2021-06-19于文清
于文清
(河北地质大学 信息工程学院,河北 石家庄 050031)
0 引言
目前场景文本检测技术可以大致分为两类,一类是传统的场景文本检测方法,另一类是基于深度学习的场景文本检测方法。传统的场景文本检测方法大多是基于字符的,即先对字符进行检测,然后将字符进行关联组合,形成单词。如易尧华[1]等人提出的结合MSCRs与MSERs的自然场景文本检测以及张国和[2]等人提出的最大稳定极值区域与笔画宽度变换的自然场景文本提取方法在某些场景中,字符非常模糊,甚至无法看清,采用传统的场景文本检测方法难以检测出此类文字,因此基于深度学习的场景文本检测方法被陆续提出。基于深度学习的场景文本检测方法大体分为两类,基于目标检测的方法和基于分割的方法。基于目标检测的方法通常把目标检测的方法针对文本的特点来进行改进,进而应用到文本检测中,Tian等人[3]在基于Faster-RCNN[4]思想的基础上提出了用于检测水平文本的CTPN。Ma等人[5]在基于Faster-RCNN的基础上提出了一种通过对检测框进行旋转来检测倾斜的文本的RRPN。Shi等人[6]在 SSD[7]的基础上提出了可以处理多方向和任意长度的文本的 SegLink。由于该类方法对多方向文本和弯曲形文本的检测效果不是很精准,因此有学者提出了基于分割的方法。基于分割的文本检测方法可以不受文本形状的限制,不仅可以检测横向和斜向的文本,而且还可以准确有效的检测出不规则的文本,比基于目标检测的方法,适用的范围更广。旷视科技采用基于分割的方法提出了PSENet[8]不仅可以对任意形状的文本进行定位而且解决了过于接近的文本难以分离的问题,首先小比例缩放检测,然后使用渐进扩展算法逐步扩展成完整的文本。
上述的文本检测方法均可应用于人民币文本检测,但会存在以下问题:(1)若采用传统的人民币文本检测方法,会存在以下几个问题:当人民币出现破损折角、文字模糊时,会难以检测人民币图像文本区域,影响人民币文本检测的准确率;当拍摄采集的人民币图像受到光照强度、图像变形、拍摄角度影响时,人民币文本区域的定位会出现偏差,影响人民币文本区域定位的精准度。(2)若采用基于目标检测的人民币文本检测方法,由于拍摄的人民币图像受到图像变形、拍摄角度影响时,很难使人民币图像的候选框与真值框之间具备较好的匹配关系,影响人民币文本检测的准确率。针对以上问题,本文将旷视科技提出的基于分割的 PSENet应用到人民币文本检测中不仅可以对人民币图像变形的文本进行定位而且解决了相邻人民币文本难以分离的问题,从而提高人民币文本区域检测的准确率。
1 相关工作
由于残差网络(ResNet)解决了网络深度达到饱和之后出现的梯度消散或梯度爆炸的问题,特征金字塔网络(FPN)在不增加原有模型计算量的情况下,解决了物体检测中的多尺度问题,因此PSENet采用在ImageNet数据集上预训练的ResNet+FPN作为特征提取的网络结构。
1.1 ResNet
随着深度神经网络的发展,深度神经网络模型的网络层数变得越来越深,深度神经网络的训练因其层次加深而变得愈加困难,为了解决网络深度达到饱和之后出现的梯度消散或梯度爆炸的问题,He Kaiming等人[9]提出了残差网络,其内部的残差模块使用了跳跃链接,缓解了在深度神经网络中增加深度带来了梯度消失的问题。残差网络是由多个残差模块堆叠而成,输入一张图像数据,残差网络首先将输入数据依次送入卷积层、非线性激活函数层、批处理层;然后将处理结果送入到多个残差模块,经过批处理归一化层和全连接层之后,最后得到输出结果。令第l个残差模块的输入为xl,那么下一层的输出为:
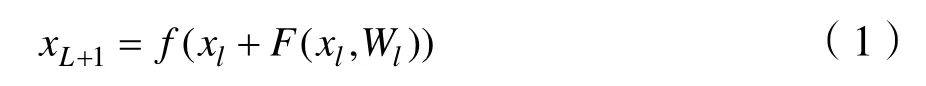
其中,F(xl,Wl) 是残差函数,Wl是该残差函数对应的权重,f(*)是非线性激活函数Relu。残差网络具有五种不同深度的网络结构,分别为ResNet18,ResNet34,ResNet50,ResNet101,ResNet152。本文所使用的是ResNet50。
1.2 FPN
在计算机视觉学科中,多维度的目标检测一直以来都是通过将缩小或扩大后的不同维度图片作为输入来生成出反映不同维度信息的特征组合,这种办法对硬件计算能力及内存大小有较高要求,只能在有限的领域内部使用,因此Lin等人提出了特征金字塔网络[10](Feature Pyramid Networks for Object Detection,FPN)可以有效的在单一图片视图下生成对其的多维度特征表达,在不增加原有模型计算量的情况下,大幅度提升了物体检测的性能。特征金字塔网络有三部分组成,第一部分为自底向上部分,该部分的过程就是神经网络普通的前向传播过程,特征图经过卷积核计算,通常会越变越小;第二部分为自底向上部分,该部分过程是将低分辨率的特征图做 2倍上采样,然后通过按元素相加,将上采样映射与相应的自底而上映射合并,这个过程是迭代的,直到生成最终的分辨率图;第三部分是横向连接部分,该部分的过程是将上采样的结果和自底向上生成的相同大小的特征图进行融合,横向连接的两层特征在空间尺寸相同,这样做可以利用底层定位细节信息。
2 PSENet模型
PSENet是基于深度学习的场景文本检测模型,它有两方面的优势,第一,其可以对任意形状的文本进行定位;第二,其提出了一种渐进的尺度扩展算法,该算法可以成功区分相邻的文本实例。PSENet由网络结构和渐进尺度扩展算法两部分组成。
PSENet采用在 ImageNet数据集上预训练的ResNet+FPN作为特征提取的网络结构。网络结构的处理流程为:首先通过FPN自底向上部分提取图像的特征,然后通过FPN横向连接部分与自上而下部分连接融合产生新的特征图P5,P4,P3,P2最后将特征图P5,P4,P3逐层上采样至特征图P2尺寸并与P2级联在一起得到融合特征F,如图1所示。
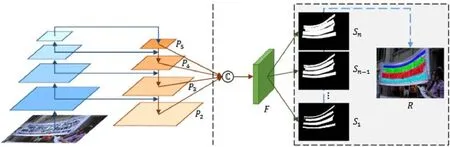
图1 PSENet算法处理流程Fig.1 Processing flow of psenet algorithm
PSENet采用基于广度优先搜索的渐进式尺度扩展算法作为后处理算法,该算法对n个分割区域从小到大依次进行扩展并得到最终的预测结果。分割区域表示称为“核”,并且对于一个文本实例,有几个对应的内核。渐进式尺度扩展算法处理流程为:(1)从具有最小尺度的核开始往外扩张,由于尺度极小的核之间存在较大的几何边缘,因此很容易区分相邻文本实例;(2)将找到的连通域的每个像素点以广度优先搜索的方式,逐个向上下左右扩展;(3)重复上述过程,完成直到发现最大的核作为预测结果,最终得到文本区域。渐进式尺度扩展算法在算法1中进行了概述,在算法1中,T,P为中间结果,Q为队列,Neighbor(·)表示 p 的相邻像素,GroupByLabel(·)表示按标签分组中间结果。“Si[q]=True”表示预测Si中像素q属于文本部分。

表1 渐进式尺度扩展算法Tab.1 Sc ale expansion algorithm
PSENet的每个内核与原始的整个文本实例共享相似的形状,并且它们都位于相同的中心点但在比例上不同,因此需要标签生成部分产生不同比例的核对应的标签。该模型的损失由整体文本实例(Sn)的损失和缩放后文本实例(S1→Sn)的损失两部分组成,因此标签生成是计算模型损失重要的一部分。
2.1 标签生成
PSENet会产生不同比例的核(S1,S2,…,Sn),如图1所示,因此在训练的过程中,需要有和不同比例的核相对应的标签,但在使用标注工具 roLabelImg制作数据集时只能制作完整文本框的标签,为了得到不同尺度的分割图相对应的标签,需要对数据集给定的标签进行缩放处理,通过对数据集给定的文本框(文本框是一个多边形)pn缩减di个像素得到缩放后的标签pi。假设缩放比例为ir,则pn和pi之间di的计算方式为:
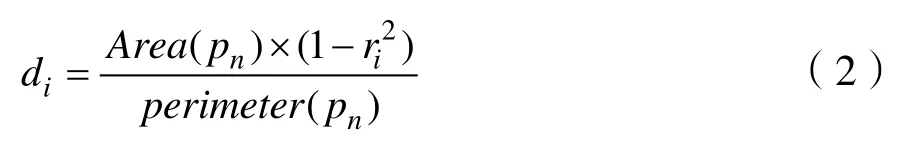
其中Area(pn)表示多边形pn的面积,perimeter(pn)表示多边形pn的周长。
对于缩放比ri计算方式为:

其中,m∈(0,1]为缩放的最小比例,缩放比ri的取值范围为[m,1]。
2.2 损失函数
本文的损失函数由整体文本实例(Sn)的损失LC和缩放后文本实例(S1→Sn)的损失Ls的损失两部分组成,损失函数L的定义为:

其中λ用于平衡整体文本实例的损失LC和缩放后文本实例的损失Ls,本文设置为 0.7。由于通常文本实例可能只占自然场景很小的一部分,因此LC、Ls都采用Dics系数进行损失函数的计算,计算方式为:

其中Si,x,y表示分割结果Si在(x,y)位置处的像素值,Gi,x,y表示标签Gi在(x,y)位置处的像素值。为了避免误检,在训练过程中采用在线难例挖掘算法(Online Hard Example Mining,OHEM)[11],则LC的计算方式为:
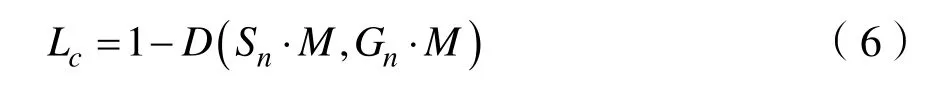
其中M为训练过程中OHEM预测的文本区域,Ls的计算方式为:
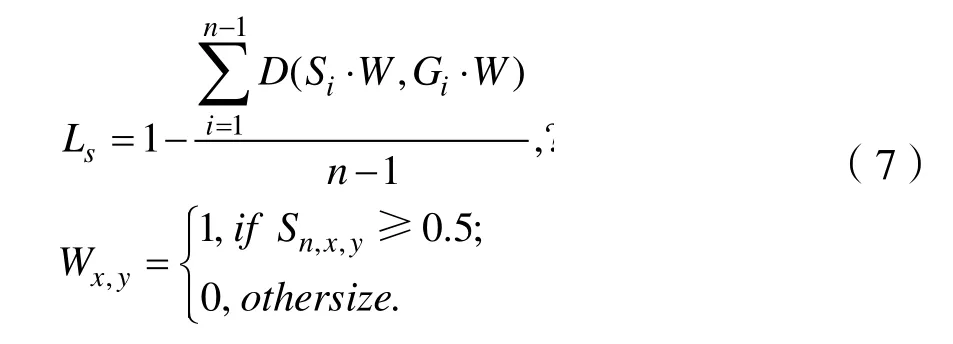
其中W表示Sn中忽略非文本区域像素的掩模。
3 实验
3.1 数据集
3.1.1 人民币图像的构成
人民币图像有人民币冠字号、人民币金额、中国人民银行这三部分组成,如图2所示。(1)人民币冠字号字符一共有 10个字符,由固定的26个英文字母 10个阿拉伯数字共同组成,有的人民币冠字号位于人民币的左下角,有的人民币版本存在双冠字号,不仅左下角有冠字号,并且在右侧边也存在冠字号;(2)人民币金额存在两种表达,第一种由人民币金额的阿拉伯数字表达,有的位于人民币的中心、右上角及左下角三个位置,有的位于人民币的中心、右上角两个位置,第二种是由人民币金额的繁字体表达,位于人民币金额阿拉伯数字位置的下方;(3)有中国人民银行5个汉字组成,位于人民币金额阿拉伯数字位置的上方。

图2 含有单冠字号和双冠字号的人民币图像Fig.2 Image of RMB with single and double crown
3.1.2 数据集选取
人民币图像没有公开的数据集用于训练和测试,本文所用的人民币的图像数据集是均由roLabelImg软件对人民币图像标注,标注后的人民币图像如图3所示。人民币图像的文本行标注是一个繁琐的过程,需要消耗大量的人力和精力,本实验对1元、5元、10元、20元、50元、100元一共选取500张进行标注,人民币图像按照顺时针的格式标注,顺序为左上角、右上角、右下角、左下角。

图3 标注后的人民币图像Fig.3 Annotated RMB image
3.2 实验设置
本文在Linux系统上搭建实验平台,CPU型号为Inter@CoreTMi7-10750H,内存为16G,使用Python3.6作为编程语言,使用的深度学习框架为pytorch 1.0。本实验使用ResNet-50作为基础网络并使用随机梯度下降进行优化,初始学习率设为1e–4,训练600轮。
3.3 评价指标
本文采用场景文本检测的任务中常用的评价指标:准确率(Precision,P)、召回率(Recall,R)、综合评价指标(F-measure, F值),其中准确率、召回率、综合评价指标的计算方式为:

其中D表示使用PSENet检测出的人民币文本框,G表示真实的文本框。Match(D,G)表示使用PSENet检测的正确的人民币文本框的数量,|D|表示使用PSENet检测出的人民币文本框的数量,|D|表示真实的文本框的数量。
3.4 实验结果
本文使用PSENet对六种不同面值即一元,五元,十元,二十元,五十元,一百元的人民币进行了检测,如图4所示,基于 PSENet的人民币文本检测方法的召回率为 95%,准确率为 98%,f-measure为 97%(实验结果保留两位)。经实验证明 PSENet应用于人民币文本检测具有较好的参考价值。将 PSENet应用人民币文本检测有以下优点:(1)基于 PSENet的人民币文本检测方法受人民币出现破损折角、文字模糊等问题影响较小,提高了人民币文本检测的准确率。(2)基于 PSENet的人民币文本检测方法解决了人民币文本检测易受图像变形、光照强度、拍摄角度等影响的问题,提高了人民币文本区域定位的精准度。(3)基于 PSENet的人民币文本检测方法是基于分割的文本检测方法,可以使候选框与真值框之间具备较好的匹配关系。(4)基于 PSENet的人民币文本检测方法可以将相邻的人民币文本区分。(5)根据测试结果来看,将 PSENet应用于人民币文本检测检测结果较好,为人民币文本检测的研究提供了新的思路,具有一定的应用价值。
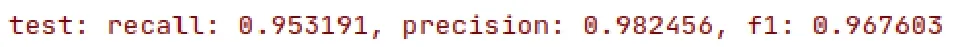
图4 人民币检测结果Fig.4 RM B test results
4 结论与展望
针对人民币文本检测准确率不高以及文本区域定位的精准度不准等问题,本文提出了基于PSENet的人民币文本检测方法,通过利用PSENet对变形文本进行定位以及可区分相邻文本的特性,将其应用到人民币文本检测中不仅提高了文本区域定位的精准度而且提高人民币文本检测的准确率。通过实验表明本文的方法取得了不错的检测效果,为人民币文本检测的研究提供了新的思路,具有一定的应用价值。本文虽然有效地提高了人民币文本区域检测准确率,但是场景图像背景复杂性、受拍摄的外界环境影响等问题依然是人民币文本检测的巨大挑战,人民币文本检测还有空间值得进一步的研究和完善。
