CurveNet: Curvature-Based Multitask Learning Deep Networks for 3D Object Recognition
2021-06-18MuzahidWanggenWanFerdousSohelLianyaoWuandLiHou
A. A. M. Muzahid, Wanggen Wan,, Ferdous Sohel,,Lianyao Wu, and Li Hou
Abstract—In computer vision fields, 3D object recognition is one of the most important tasks for many real-world applications.Three-dimensional convolutional neural networks (CNNs) have demonstrated their advantages in 3D object recognition. In this paper, we propose to use the principal curvature directions of 3D objects (using a CAD model) to represent the geometric features as inputs for the 3D CNN. Our framework, namely CurveNet,learns perceptually relevant salient features and predicts object class labels. Curvature directions incorporate complex surface information of a 3D object, which helps our framework to produce more precise and discriminative features for object recognition. Multitask learning is inspired by sharing features between two related tasks, where we consider pose classification as an auxiliary task to enable our CurveNet to better generalize object label classification. Experimental results show that our proposed framework using curvature vectors performs better than voxels as an input for 3D object classification. We further improved the performance of CurveNet by combining two networks with both curvature direction and voxels of a 3D object as the inputs. A Cross-Stitch module was adopted to learn effective shared features across multiple representations. We evaluated our methods using three publicly available datasets and achieved competitive performance in the 3D object recognition task.
I. INTRODUCTION
IN the field of computer vision, 2D image analysis using deep learning (DL) methods has already achieved remarkable progress and outperforms human vision in many cases (e.g., image classification and human face analysis) [1],[2]. However, understanding three-dimensional objects is still an open research problem of modern computer vision research. A real object in three-dimensional space provides more detailed information. With the availability of low-cost 3D acquisition devices, it is easier to capture 3D objects. The rise of public repositories of 3D models has drawn attention to computer vision research such as 3D object recognition,reconstruction, semantic segmentation, and retrieval [3].
Convolutional neural network (CNN)-based 3D object recognition systems have advanced considerably [4], but 3D CNNs have been not as successful in identifying 3D objects as 2D CNNs, especially in object label prediction. There are several reasons behind this, e.g., selecting the input features of a 3D object [5] is critical due to its complex geometrical structures, comparatively smaller training databases, and the high computational cost required by 3D CNNs. The earliest volumetric deep learning approach is 3D ShapeNets [6],which deals with three tasks including 3D object classification. Recently, several approaches have been published that solve 3D object recognition tasks using deep CNNs; voxels [6]-[9], point clouds [10]-[12], and 2D multiview [13]-[15] are the most widely used representations of CNNs for 3D object recognition [4]. Two-dimensional multiview-based approaches that use 2D CNNs achieve high performance. This is because existing 2D-based CNNs can be directly used for 3D object recognition, and they require fewer computational resources. However, multiview representations have some technical issues; for example, choosing the number of views to capture the information of the entire 3D object is still an open issue. In addition, the projection of 3D data to the 2D domain discards intrinsic features (e.g., geometric,structural, and orientational information) of a 3D object.
In 3D shape analysis, the three-dimensional representation is the only way to preserve the intrinsic features of a 3D object; therefore, new features of a 3D object and advanced neural networks need to be explored to improve 3D vision tasks [8]. AI-based computer vision systems are developed with advanced machine learning (ML) algorithms (e.g., deep learning). In addition, the object classification accuracy of a CNN is also highly influenced by the input features [4].
In this study, we incorporated curvature directions as input features of a 3D object into our novel 3D CNN to identify object labels. Principal curvature directions of 3D objects are considered as perceptually relevant properties of the human visual system (HVS) that are widely used in 3D mesh visual quality evaluation [16], [17]. Considering perceptual features in the HVS, curvature maps represent the salient structural features of a 3D object [17]. The curvature map of a typical 3D CAD model is shown in Figs. 1(d) and 1(e). The plot of curvature vectors looks similar to a sketch of the original 3D model. The idea is that if a typical neural network model can recognize an object from the boundary information (from voxels) of a 3D object, then it can also recognize it from its sketch.

Fig. 1. The comparison of different 3D representations (a) original 3D Bimba CAD model; (b) voxel representation; (c) point-cloud representation;(d) curvature direction map using maximum values [17]; and (e) curvature direction map using minimum values [17].
Inspired by this, we propose CurveNet for 3D object classification, which is a novel volumetric CNN that inputs curvature points directly as low-level input features. In CNNs,multitask [18], [19] and multiscale [20], [21] learning-based approaches provide additional benefits that improve the performance of the network for object classification. In multitask learning, an auxiliary task is considered to optimize the loss and improve the performance of the main task. We added pose recognition as an auxiliary task to improve the performance of CurveNet for the object category-level classification. In general, the classification accuracy using curvature points should not be worse than that of voxel input as they provide more information (discriminative surface feature), especially for the curve surface or complex structured 3D model. Our experimental results demonstrate that curvature-based input features outperform the object boundary with voxel representations. A new inception module was introduced to generate a high-level global feature from the low-level surface input feature. Our proposed CurveNet benefits from multiscale learning from this new inception module. To improve the network performance further, we fused the two networks, which take curvature vector points and voxels as inputs. Data augmentation was applied to increase the number of training samples, which helped to reduce the risk of overfitting and improve the performance of the network.
The key contributions in this paper are as follows: i) We propose to use curvature information of a 3D CAD model as an input for the 3D classifier, CurveNet. To the best of our knowledge, this is the first time that a 3D CNN has directly taken curvature vectors as inputs and outperformed boundary representation from voxels. ii) We introduced a new inception block consisting of three conv layers, and one max pooling layer, which is an efficient alternative to the conventional multiscale learning strategy. This improves the learning capability of CurveNet and generates very high-level global features with fewer parameters. iii) We extended our technique by combining multiple inputs (boundary information from voxels and curvature directions) and experimented with the influence of soft and hard parameter sharing to improve the performance of 3D object classification.
The rest of the paper is organized as follows: The related work on 3D object recognition based on neural networks is reviewed in Section II. Section III describes the proposed CurveNet architecture including the feature extraction method, network architecture, and network fusion techniques.Network training and the experimental results and analysis are presented in Section IV. Finally, we draw a conclusion in Section V.
II. RELATED WORKS
The most common representations of 3D objects used for 3D object recognition are multiview, point clouds, volumetric,hypergraph, and 3D descriptors.
1) Multiview:One of the earliest approaches to 3D object recognition was presented in the context of RGB-D images[22], [23]. This feature learning approach is similar to image classification, where an additional input is used for the depth information. The multiview convolutional neural network(MVCNN) [13] model is a pioneering multiview-based CNN model, in which a 3D object can be rendered to 2D images from 12 to 80 viewpoints. A pre-trained model from ImageNet[20] was used to train the network model on the ModelNet40 dataset [24] for the 3D classification task. RotationNet [25]was proposed to jointly predict the object label and pose using multiview images of a 3D object. To use the correlation information between the multiview image of a 3D object, Maet al.proposed [26] a novel multiview-based network for classification and retrieval tasks. However, multiview representation discards the geometric properties, and it is hard to determine the number of projections required to capture the entire surface of a 3D object.
2) Point Cloud:The point cloud representations are popular for their ease of 3D shape representation and their direct usage in CNNs as inputs. PointNet [12] is one of the earliest approaches proposed to address the problems of 3D object classification and segmentation tasks. PointNet directly inputs the pointset and outputs the object class label. However,PointNet does not capture the local structure induced by the pointwise feature extraction method. This problem is addressed in PointNet++ [11] by processing a set of points sampled in a hierarchical order. Ben-Shabatet al.[27]proposed a hybrid point cloud representation, namely 3D modified fisher vectors (3DmFV), which efficiently combines discrete point structures with a continuous generalization of fisher vectors for 3D point cloud classification and part segmentation. Point2Sequence [10] was proposed by Liuet al.as a means of capturing fine-grained contextual information and learning point cloud features by aggregating multi-scale areas of each local region of 3D objects with attention. The relation-shape convolutional neural network (RS-CNN) [28]was introduced to learn contextual shape-aware information for point cloud classification and segmentation problems.However, point clouds are somewhat different from rasterized data (voxels or pixels), which are formed in a spatial irregular fashion, but the main benefit of their coordinates can be used straightforwardly in CNNs as inputs. Due to the advancement of 3D scanning tools, it is very easy and fast to develop a point cloud model, but the model fails to preserve the surface information of the object in the real environment because of the unordered point sampling.
3) Volumetric:Volumetric representation is a very powerful representation that can describe the full geometry of a 3D object. It holds the intrinsic feature of viewpoint information.Voxel and octree are the most commonly used representation methods of volumetric data for 3D object recognition tasks[3]. Wuet al.proposed a deep learning model for volumetric shape analysis including recognition, namely 3DShapeNets[6], the pioneering and earliest approach to 3D object recognition with volumetric data. The following outlines several fruitful volumetric approaches proposed using 3D voxel grid representation [5], [7], [12], [25]. Recently, octreebased volumetric CNNs [30]-[32] significantly improved the performance of 3D object recognition, consuming less memory compared to voxel-based methods. In addition, there are several new approaches introduced to 3D volumetric CNNs such as multitask learning [33], including sub-volume supervision [9], [14], [32], and network fusion methods with multi-representation input, which have gained noticeable progress [8], [14], [34] in recent years. In general, volumetric CNNs require higher computational cost, which may be challenging for real-time applications. VoxNet and LightNet addressed this issue and introduced volumetric networks with the smallest parameters of about 0.92 M and 0.30 M,respectively. Brocket al.proposed the voxel-based Voxception-ResNet (VRN) [35] model that learned latent space using a variational autoencoder (VAE). The VRN ensemble has achieved the best classification accuracy until now on the ModelNet public dataset [24]. Ghadaiet al.[36]introduced a multi-level 3D CNN that learned multi-scale features by utilizing a coarse voxel grid representation.
4) Others:Lucianoet al.introduced a deep similarity network fusion framework, namely DeepSNF [37], for 3D object classification, where features from the geometric shape descriptor are fed into a graph convolutional neural network[38]. Recently, several methods were introduced using graph CNNs [38], as these CNNs can process both sparse and unordered data. Among them, dynamic graph [39],hypergraph [40], and multi-hypergraph [41] stereographicbased methods achieve significant improvement in 3D object recognition tasks. These aforementioned methods follow supervised learning strategies; in addition, there are several unsupervised methods [42]-[44] introduced for 3D object recognition. However, the performance of unsupervised approaches is generally worse than that of supervised methods.
III. PROPOSED METHOD
We consider a volumetric CNN in this paper. In volumetric data, voxels are commonly used to represent a 3D object.However, to improve the performance and reduce the computational cost of volumetric methods, several approaches have been introduced, such as octree [26], [28], combined voxel with curvature map [45], and normal vector [8], used as an input for a 3D CNN. There is still a large performance gap between 3D and 2D CNNs as 2D-based methods benefit from techniques from numerous existing works in image processing and perform better in 3D object recognition tasks. To reduce this gap, we propose a novel 3D CNN network, called CurveNet, which uses curvature points as inputs. The main reason for using a 3D CNN is to extract rich information from spatial structures and learn the fine details from the non-plane surface at various orientations. This section presents input data preparation, CurveNet architecture, and its learning strategy in detail.
A. Input Data Preparation
Two popular ways of representing a 3D object with a CNN are multiview and volumetric. Multiview representation is a 2D image of a 3D object captured from multiple viewpoints that discard the structural information. On the other hand,volumetric representation preserves the intrinsic features with viewpoint information, which is widely used as an input of 3D CNNs.
We extracted the curvature direction map of a 3D mesh (3D CAD model). The irregular curvature point vectors are formed into a 3D data tensor, which is encoded further to regular points that are input into the 3D CNN. To calculate curvature direction in 2D when applied to a circle of radiusr(Fig. 2), let us define two pointse1ande2on the circle, and their normals aren1andn2respectively from the circle’s center. The curvature of the circle can be calculated as
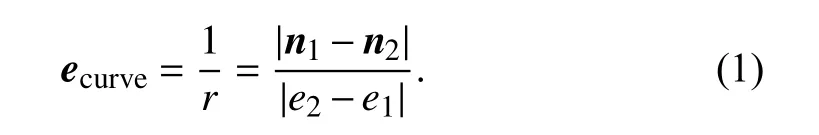
The curvature calculation from (1) can be extended on arbitrary 3D meshes by projecting the vectorn1-n2onto the curvature edge as
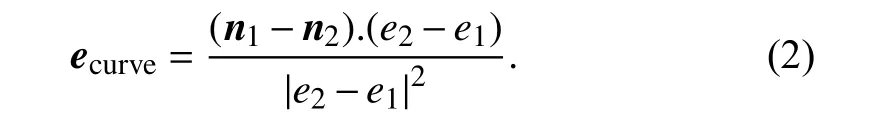


Fig. 2. Circular curvature computation in 2D.

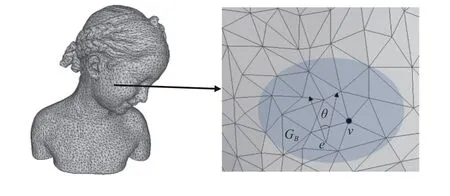
Fig. 3. Geometric elements used for curvature computation for a 3D mesh.
To extract these curvature vectors (min, max), we used an open-source tool, mepp1https://github.com/MEPP-team/MEPP(3D mesh processing platform), with modified TPDM metrics [17] on Ubuntu. The curvature vectors (3D vectors for three dimensions) are calculated in an iterative manner and stored as unstructured points (3D tensors) on the local drive. To encode these points, we cut 3D tensors of each 3D model with 5k points, and distributed them uniformly by Poisson disk sampling using Meshlab [47] and transformed them into a 3D grid [7] as the input for the CNN.Fig. 1 shows a representation of a 3D CAD model from voxels, point clouds, and curvature points.
B. CurveNet Network Architecture
Our proposed CurveNet is a 3D deep convolutional neural network, consisting of conv and FC layers. Fig. 4 depicts the general block diagram of CurveNet. The network is designed in the form of a multitask learning strategy. In multitask learning, at least two or more tasks are assigned [18]. Between them, one is the main task, and the rest of the tasks are auxiliary tasks. Auxiliary tasks are used to improve the performance of the main task. In this work, object label prediction is the main task, and pose prediction is the auxiliary task of CurveNet. CurveNet directly inputs the binary of the 3D data tensor by its input layer, which has a size of 30×30×30. A new inception block was equipped to generate discriminative features using a multiscale training approach.We used three identical inception blocks. Each inception block consisted of three conv layers and one max-pooling layer. Convolution parameters are represented as (C,S) ×N,whereCis the convolution kernel,Sis stride, andNrefers to the number of output feature maps. The output of each conv layer is passed to a sequence of a batch normalization layer, a scale layer, and a leaky rectified linear unit (Leaky ReLU)layer with a negative slope of 0.1.
We used a typical form of a max-pooling layer. We applied a non-overlapping pooling function using kernel size 2 with a stride of 2, so the resolution of the feature map decreased by a factor of 2. The output of conv-2 and conv-3 is the same with the number of output feature maps that are concatenated to be input into the conv layer of the next inception block.However, conv-2 and conv-3 input features from the output of conv-1 and max-pooling layers, respectively, where the dimensions of two input features are (d/2-1), and (d/2),respectively. These multiscale features are produced by the inception block and sent to the next block as an input, which generates more distinguishable features to recognize object class labels. The number of learned feature maps by Inception-1 is 112, and this is increased twice (224, and 448)by the following Inception blocks. CurveNet uses four FC layers at the top, where the last two FCs, FC-3 and FC-4, are used to get the prediction score of object label and pose,respectively. FC-3 and FC-4 both take the output of FC-2 as an input. We used a softmax classifier to compute the accuracy and loss [48] of CurveNet for object label classification tasks.
C. Parameter Sharing by a Combination of Two Inputs
In this work, we employed network fusion strategies on CurveNet using both curvature directions and surface boundary representation from voxels as inputs. To experience the influence of parameter sharing, two CurveNets were fused to improve the classification performance, which takes boundary information from voxels [7] and curvature information as inputs. We trained our CurveNet using three different fusion strategies, namely no sharing, hard parameter sharing, and soft parameter sharing. All fusion networks are illustrated in Fig. 5. Training samples were chosen from the same object with similar volume resolutions for two inputs.The aim was to train a fusion of CurveNets to improve the classification accuracy using multiple inputs and find an effective feature sharing strategy.
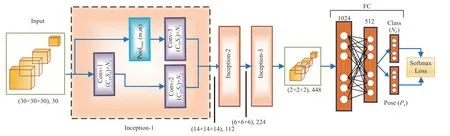
Fig. 4. CurveNet framework. A new Inception module is proposed. Inceptions 1, 2, and 3 are identical but differ with the number of input and output features and parameters (C1 = 3, C2 = 1, C3 = 2, S1 = 2, S2 = 1, and m = 2). The total number of training parameters is 3.1 M.
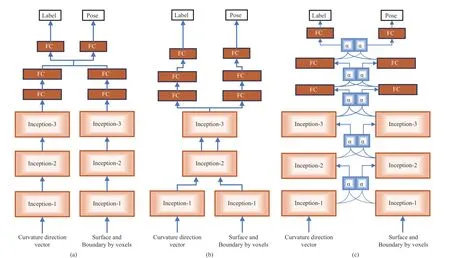
Fig. 5. Parameter sharing using network fusion methods with two CurveNets (a) no sharing; (b) hard parameter sharing; and (c) soft parameter sharing.
The first fusion pipeline is shown in Fig. 5(a). This pipeline is trained with no sharing strategy, and all learned features are concatenated before classification. The classification decision comes from the linear combination of FC outputs. The combination of learned features by two networks is fused before classifiers (topmost FCs). Then, the high-label global features are shared to classify the object into two categories.Our goal was to identify the correct object label (main task).We designed the networks to predict the object pose as an auxiliary task to improve the network performance using orientation information for our desired task [18].
In the second fusion pipeline, we follow the hard parameter sharing (see Fig. 5(b)) where one or more conv and FC layers can share their learned features. We shared parameters between Inception-2 and Inception-3 layers. We found that sharing all layers including FCs did not help at all to increase the performance but consumed 50 percent more training time.In multitask learning, some layers should be invariant for auxiliary tasks [18], and we found that two separate branches of FCs provided better results than shared FCs.
We implemented soft-parameter sharing by adopting Cross-Stitch networks [49], as illustrated in Fig. 5(c), where it was determined whether distinct learned features were shared or learned. The weighted parameters of two networks are sharable and trainable. The decision of sharing to the following layers is mediated by α, a matrix of a linear combination of activation maps. The mediated parameter decides whether the features are shared or learned.Accordingly, the network distributes task-related features to improve the prediction scores of the desired task. Finally, all learned features inside the network are forwarded to classifier layers through the final mediator block, which has the ability to select suitable and important features for the specific task(label or pose recognition). In both cases, the final output layer (softmax function) of two networks is averaged, and the largest prediction indicates the target class. All our fusion networks are followed by a layer-based parameter sharing strategy.
IV. EXPERIMENTS AND ANALYSIS
A. Training and Evaluation Setup
We evaluated the classification performance of our proposed CurveNet on two different types of 3D objects,specifically 3D CAD models and LiDAR point clouds using Princeton ModelNet [24] and Sydney Urban objects datasets,respectively. Our CurveNet was implemented on the TensorFlow deep learning framework, which was installed on a Xeon-x5650 CPU with a Teslak20c GPU enabled by cuDNN8.0.
We trained our CurveNet end-to-end in a supervised manner by stochastic gradient descent (SGB) [50] with the momentum parameter set to 0.9. The batch size was set to 32. Initial learning was set to 0.01 and decreased by a factor of 10. We added dropout regularization after each output layer with a ratio of 0.6. We computed the multiclass loss function using multinomial cross-entropy losses [51]. Our CurveNet took approximately 26 hours to be trained for 90 epochs. We applied voting strategy during testing where multiple rotations of a sample 3D object were fed to the network, and outputs were averaged to get the final prediction of the object class label.
B. Data Alignment and Augmentation
Modelnet40 and ModelNet10 are the two main datasets widely used to evaluate classification performance for 3D objects. However, the 3D models in ModelNet10 are aligned perfectly; in contrast, more than 1000 models in ModelNet40 are not aligned. We first sorted the classes of non-aligned objects and prepared a reference set for each class to be aligned. We adopted an unsupervised generation of viewpoint[52] methods to align objects according to class, and labeling of object pose was assigned iteratively by running three different subsets using 90-degree rotations. Some rotationally invariant objects (e.g., samples in flower pots and bottles)were forcibly assigned to class 1 as they did not provide any significant information in different poses.
The visual attribute of a 3D object is influenced by the object pose and the number of samples per class. We extended the dataset samples by rotating each 3D model around the horizontal direction along thez-axis. We prepared two augmented subsets of the original datasets. We generated 12 and 24 copies of each 3D model by rotating by intervals of 30 and 15 degrees for two subsets, respectively. This augmentation procedure has been applied for both ModelNet40 and ModelNet10 datasets. This augmentation method helps to increase the number of training samples of each class (both pose and category) and helps to improve the performance of the network.
C. Classification Performance on ModelNet Datasets
The ModelNet datasets were built especially to evaluate 3D object classifiers by Changet al.[24] in 2015. ModelNet40 is a large-scale dataset containing 12311 3D CAD models that are classified into 40 categories. ModelNet10 is a small dataset that is a subset of ModelNet40, containing 4899 3D CAD models in 10 categories. The datasets come with their own training and testing splits. For consistency, we used the original splits from the datasets in our experiments. During the test, we sent all augmented models of a test sample to the network in one batch, and the object category was decided by averaging the activations of the output layer.
1) Classification Results:We evaluated our model using both surface boundary information from voxels and curvature information. The classification accuracy (average class) is presented in Table I. We found that the normalized maximum curvature direction vector showed superiority over voxels.Our proposed method improves the classification accuracy by 1.2% compared to surface boundary information using the same network. It also outperforms 3DShapeNet [6] and VoxNet [7], which are state-of-the-art volumetric methods for 3D object classification. The improvements are mainly the result of two factors: curvature information as an input feature and auxiliary learning by adding pose classification. Curvature provides considerable depth and perceptual features to the CNN, and auxiliary pose learning helps to improve object classification accuracy, which is the main task of our network.In addition, the voting method is another common approach to improving the performance of the classifier. Table II shows the influence of pose learning and voting methods on improving the classification accuracy using our CurveNet. We used two augmented datasets from ModelNet40 using 12 and 24 copies of each sample. Experimental results show that classification accuracy is improved by 3.8% using 12-view and 3.2% using 24-view while using both the pose learning and voting approach.
The best performance was achieved using 24-view, with an average classification accuracy of 90.2% on ModelNet40.
From these experiments, we found that the number of training samples has an effect on the classification performance, i.e., the class with a large number of training samples has high accuracy. However, high interclass similarity between two classes can lead to a slight deviation in this trend, e.g., Chair vs. Stool and Dresser vs. Nightstand (seeFig. 6). Similar observations have also been reported in earlier works [30], [32]. When we visualize the confusion matrix of ModelNet40 in Fig. 7, it illustrates that this ambiguity only occurs if the target object belongs to some similar categories of objects, e.g., Dresser, Flower Pot, Sink, and Vase, which are examples of most confused objects in the database as they have close visual properties in instances where our network misclassified some of them.

TABLE I COMPARISON OF CLASSIFICATION ACCURACY OF OUR CURVENET AND STATE-OF-THE-ART-METRICS ON MODELNET40

TABLE II THE INFLUENCE OF POSE CLASSIFICATION AND VOTING METHODS ON CLASSIFYING OBJECT LABELS ON MODELNET40
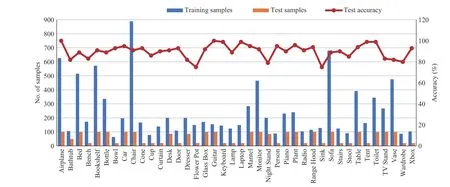
Fig. 6. Classification accuracy per class on ModelNet40 dataset.
2) Parameter Sharing:To improve the classification performance further, both voxel and curvature features were fused using our proposed volumetric model. We applied three methods of parameter sharing between two networks, which were no sharing, hard sharing, and soft sharing, as shown in Fig. 5. Both networks (for voxel and curvature) were pretrained independently to reduce the training time.
In the case of no sharing, generated features from different layers were concatenated before the last FC (classifier) layer.Moreover, for hard sharing, Inception-1 and Inception-2 layers were shared, then shared features were sent to FC layers consecutively. For channel-wise attention, the generated features across all layers were shared using a crossstitch algorithm (see [55] for details).
Overall, the classification results of fusion networks were improved compared to a single network. The results are presented in Table III. We find that soft sharing has a great impact on achieving good results. It achieved average class and sample accuracy of 90.7% and 93.5%, respectively.Moreover, hard sharing performs slightly better than no sharing, as the average class and sample accuracy increased by 0.2% and 0.6%, respectively.
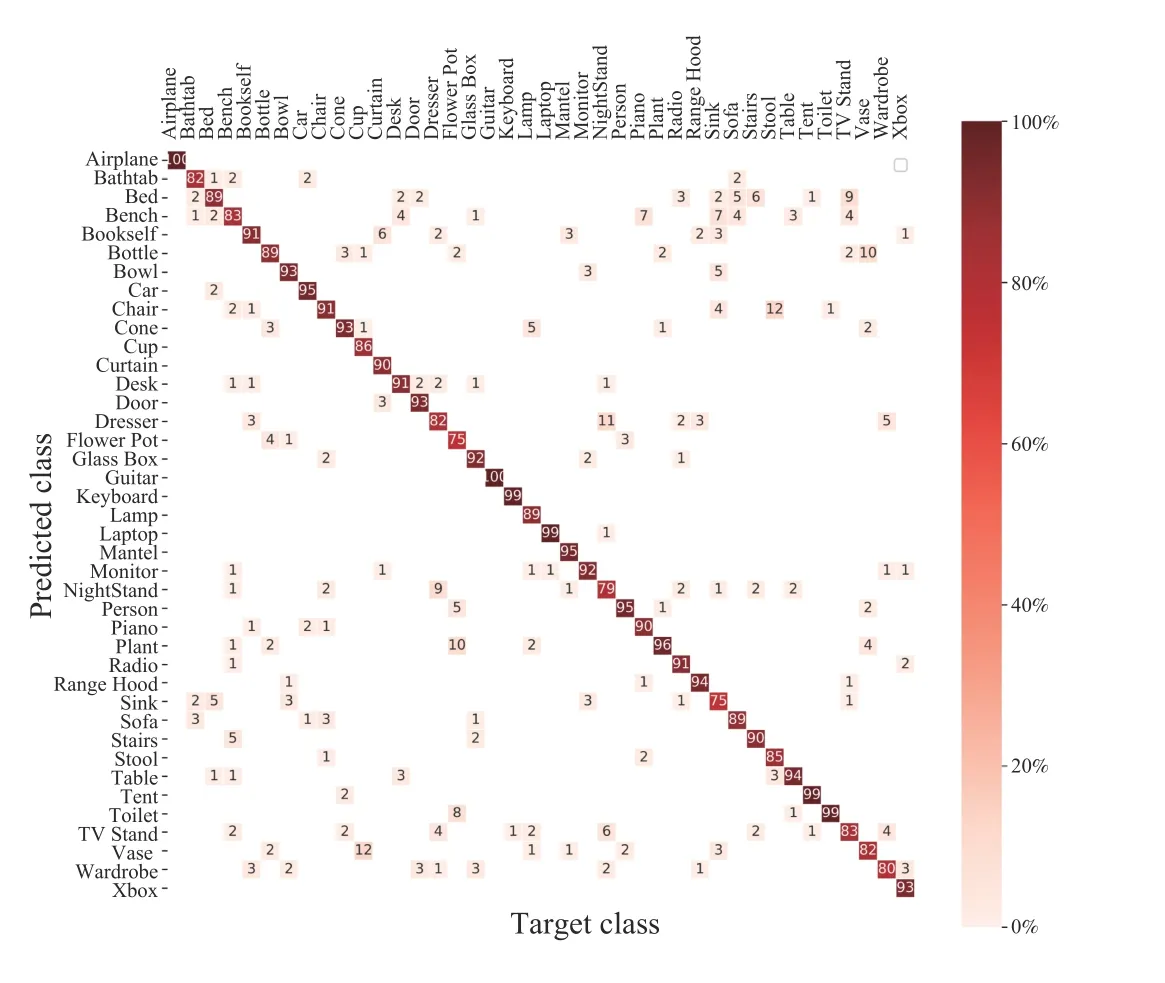
Fig. 7. The confusion matrix of the ModelNet40 dataset shows the similarity between a pair of 3D objects; lower diagonal values indicate a higher degree of similarity between the objects.
The experimental result indicates that the network with soft sharing benefited from mediated features (see Section III-C),by which it was decided whether the parameters needed to be shared or learned. On the other hand, sharing all parameters by hard sharing does not help to improve the classification result significantly; rather, using too many combinations of parameter coefficients may produce a more confusing scorethat may lead the network to a locally optimal solution.
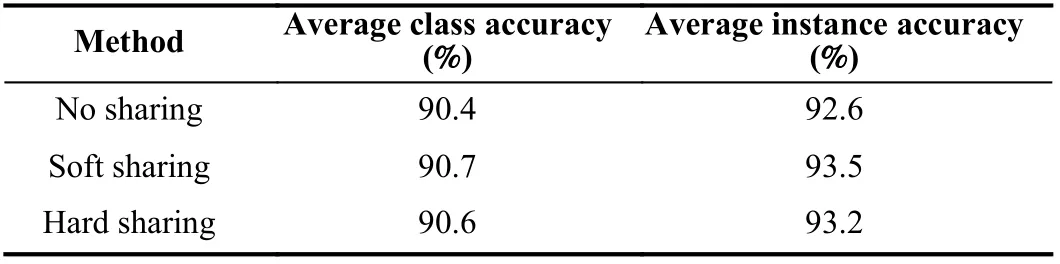
TABLE III PERFORMANCE EVALUATION OF CURVENET WITH SHARING FEATURES BY COMBINING CURVATURE AND BOUNDARY INFORMATION FROM VOXELS ON MODELNET40 DATABASE
3) Comparison With Other Methods:The classification accuracy of our model is compared with state-of-the-art methods in Table IV. We found that Multiview and pointcloud methods still dominated in the 3D object classification task. In addition, our method achieved the highest accuracy among volumetric methods but was inferior to the VRN ensemble [35]. Our CurveNet has 3.1 M parameters, whereas fusion contains about 6.2 M. In comparison to the 90 M parameters of the VRN ensemble, our network is lighter, and the performance is comparable to other methods. In addition,our network also performed well on a low scale ModelNet10 database and achieved an average classification accuracy of 94.2%, which is also comparable to other methods.Theoretically, deep networks should perform better on large datasets as they need more training samples. However,samples in ModelNet10 are built with some selected classes with clean objects from ModelNet40. The confusion matrix for ModelNet10 is shown in Fig. 8, where higher diagonal values exhibit fewer similarities with other objects. In comparison to ModelNet40, all classes in ModelNet10 obtained a higher confusion score, which implies a lower similarity between the objects, resulting in better classification accuracy achieved over the ModelNet40 dataset.
D. Sydney Urban Objects Dataset
The Sydney Urban Objects dataset2http://www.acfr.usyd.edu.au/papers/SydneyUrbanObjectsDataset.shtml.consists of labeled Velodyne LiDAR scans of 631 urban road objects (point cloud samples) in 26 distinct categories including vehicles,pedestrians, signs, and trees. As it provides single 3D point cloud samples scanned on a common scenario of urban road,we considered this dataset to be of special interest in terms of object classification and observing the performance of our CurveNet. Because of unordered point-samples, we converted the points to volumetric representation [7] by putting all points around the objects in a bounding box and encoding them to a 303occupancy grid voxel. We empirically set the voxel size to 0.2 m. Data augmentation and test voting wereapplied accordingly with 24 rotations around thez-axis.
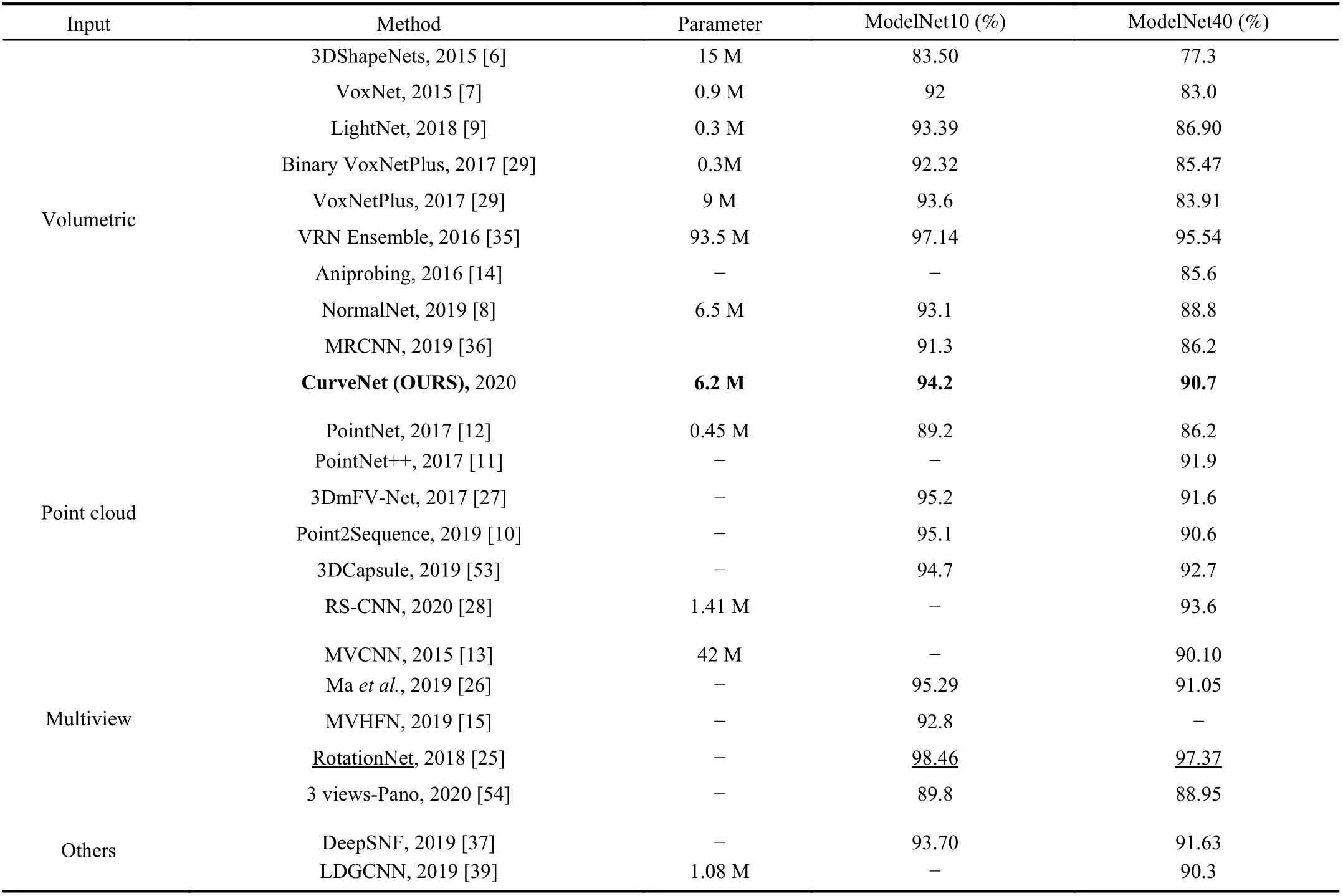
TABLE IV THE COMPARISON OF CLASSIFICATION ACCURACY ACHIEVED BY OUR CURVENET AND OTHER METHODS ON MODELNET40 AND MODELNET10 DATASETS
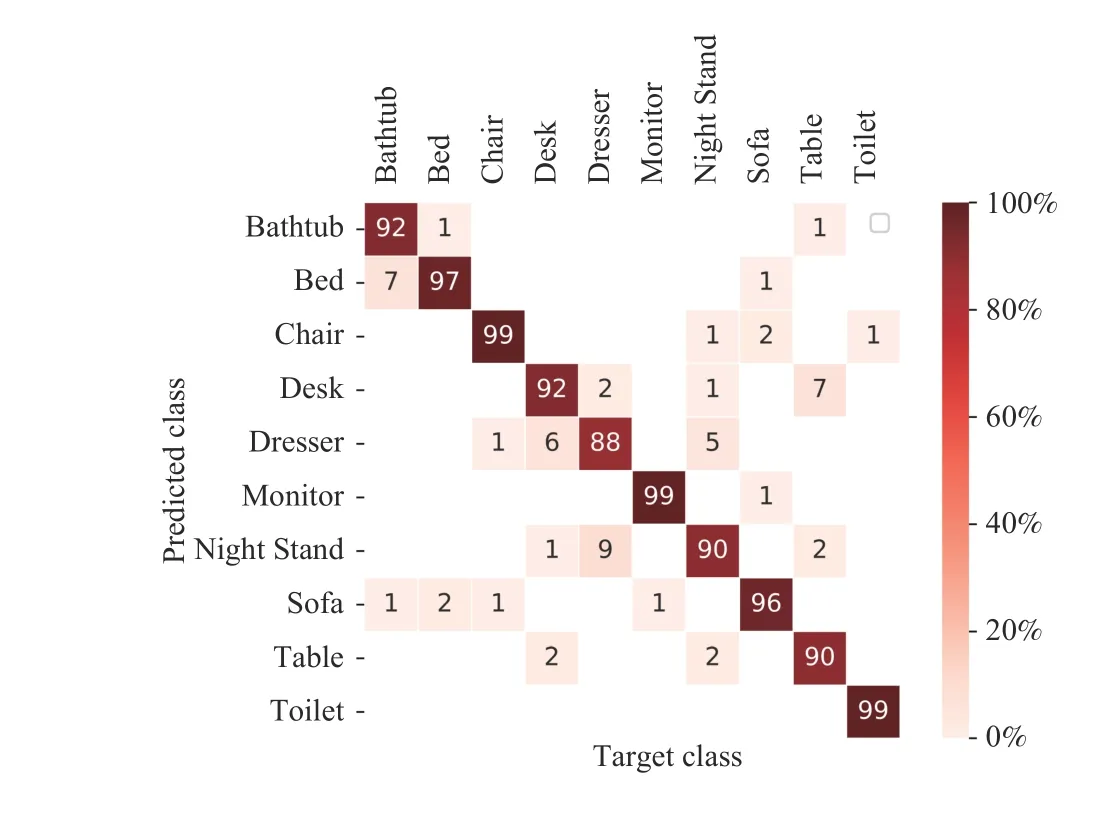
Fig. 8. Confusion matrix of ModelNet40 dataset.
Classification Results:To compare the classification result with state-of-the-art methods, we followed the original dataset’s protocol [56]. The dataset was folded to four standard training and testing splits for a subset of 588 samples in 14 classes. This dataset was smaller than ModelNet;therefore, we still kept a drop-out connection of 0.6 to mitigate the overfitting during training. We report the classification performance by the averageF1score. We present the classification performance of different methods in Table V. Our model obtained an averageF1of 79.3%. The classification performance of CurveNet is significantly better than those of volumetric methods such as VoxNet [7], ORION[33], and NormalNet [8] but is slightly worse than that of LightNet [9]. This improvement implies that the classification performance on a low scale dataset is also influenced by combined multiscale features using our novel inception module and auxiliary learning on orientation information.
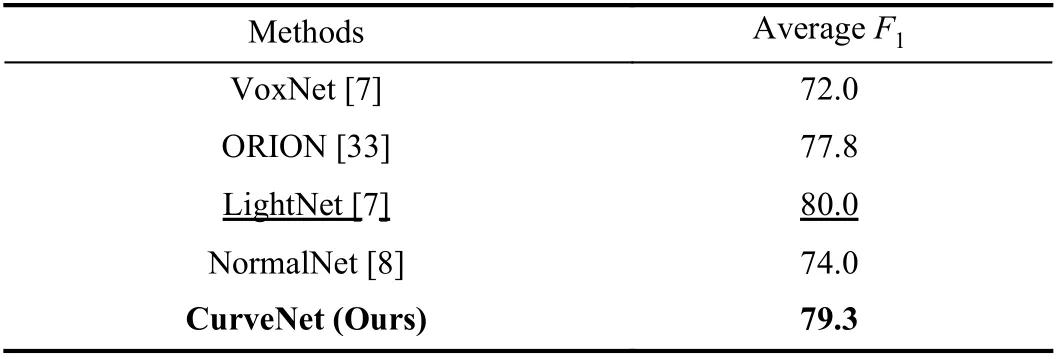
TABLE V CLASSIFICATION ACCURACY OF DIFFERENT VOLUMETRIC METHODS ON SYDNEY URBAN OBJECTS DATASET
V. CONCLUSION
In this paper, we introduce CurveNet, which uses a curvature direction vector with a 3D CNN for 3D object recognition. Our framework takes into account multitask(label and pose) and multiscale learning (in an inception module) strategies. We applied network fusion and data augmentation methods to improve the recognition rate. Using the relevant perceptual features, our proposed CurveNet performed better than existing voxel representation models.The results are competitive with state-of-the-art point-cloudbased and multiview-based methods. In contrast, our model only works for 3D triangle mesh (3D CAD models). A weakness of our model is that it is not suitable for other 3D data representations (e.g., point clouds).
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Speed and Accuracy Tradeoff for LiDAR Data Based Road Boundary Detection
- Distributed Asymptotic Consensus in Directed Networks of Nonaffine Systems With Nonvanishing Disturbance
- Finite-Time Fuzzy Sliding Mode Control for Nonlinear Descriptor Systems
- A Novel Rolling Bearing Vibration Impulsive Signals Detection Approach Based on Dictionary Learning
- Dual-Objective Mixed Integer Linear Program and Memetic Algorithm for an Industrial Group Scheduling Problem
- Output-Feedback Based Simplified Optimized Backstepping Control for Strict-Feedback Systems with Input and State Constraints