双路多尺度残差网络的图像超分辨率重建
2021-06-09赵佰亭贾晓芬
胡 锐,赵佰亭,贾晓芬
(安徽理工大学 电气与信息工程学院,安徽 淮南232001)
单幅图像的超分辨率重建,是一种从低分辨率图像恢复出高分辨率图像的技术。目前高分辨率图像广泛应用在遥感测绘、医学图像、视频监控和图像生成等领域中[1-3]。受当前技术发展限制以及成本考虑,利用软件处理方法来获得更高分辨率图像,已经成为图像处理领域研究的热点。
对于传统的插值[4]和重建[5]方法,通常存在着重建效果差,边缘模糊等问题。随着科技的发展,人们开始将目光放在深度学习技术上。DONG等[6]首次将深度学习引入到图像重建领域中,提出一种卷积神经网络的方法(super-resol ution convol utional neural net wor k,SRCNN),通过构建3个卷积层实现图像重建。SHI等[7]提出一种亚像素卷积的方法(efficient sub-pixel convol utional neural net wor k,ESPCN),不需要对低分辨率图像预处理,直接作为网络的输入进行特征提取,在最后一层对特征图进行排列实现上采样操作,减少低分辨率图像上下文信息的破坏,使得特征信息尽可能的得以保留。对于卷积网络来说,越深的网络,其处理能力也就越好,而在图像处理中,深度网络也能够更充分提取图像中特征信息,使得处理效果得到提升,但是在运用中发现,网络层数增加会导致梯度弥散问题。KI M等[8]结合残差网络[9],提出一种深度卷积网络的方法(ver y deep net wor k f or super-resol ution,VDSR),通过特征图的累加来解决这一问题。ZHANG等[10]提出了一种残差密集连接网络的方法(residual dense net wor k,RDN),通过多个残差密集块的相互连接融合,能够更有效的提取特征信息,提高重建质量。ZHAO等[11]构建了一种级联通道分割网络的方法(channel splitting net wor k,CSN),将特征信息在子网络中分散处理,来减轻深度网络的学习负担,提高训练效果。当前,在图像重建领域,基于学习的方法成为了研究的重点。
以上方法取得了一定的重建效果,但是均存在着感受野小、收敛速度慢以及信息丢失等问题,且所有的网络结构均是通过单一尺度的卷积核来提取特征信息,这里提出了一种双路多尺度残差网络(binar y channels multi-scale residual net wor k,BMRN)的图像超分辨率重建方法。将低分辨率图像直接作为网络的输入进行特征提取,减少网络参数量,降低训练难度,采用双路并行的多尺度残差卷积子网络对底层特征进行提取,得到高频信息,通过将亚像素卷积对特征图进行排列,最终得到重建图像,实现图像的超分辨率重建。
1 残差连接
在理论上,神经网络的深度越深,所能够提取的信息也就越充分,对于后续的处理也就越有利。但是在实际中发现,简单增加网络深度,会导致网络出现梯度弥散问题。虽然正则化层能够避免这一问题,但是又会导致网络退化问题出现。为此,HE等[9]提出了残差网络,用来维持网络稳定,增强信息的有效提取。公式为

式(1)中:ƏX1为残差输入,ƏX2为残差输出,W1为权值,b1为偏置量表示残差过程学习映射。其结构如图1所示。

图1 残差结构图Fig.1 Residual str uct ure
2 双路多尺度残差网络
对于图像的超分辨率重建来说,通过对LR图像中的细节特征提取利用,构建由LR图像到HR图像之间端对端的关系映射,最终实现高分辨率图像的重建。通常图像重建的效果与卷积核大小及网络深度有关,而对于每个图像特征都有着自己最佳的卷积尺度,在这种尺度上,图像的特征是最明显的。这里提出一种双路多尺度残差网络的单幅图像超分辨率重建方法。网络包含3个部分:特征提取、非线性映射和上采样与重建。网络中的特征提取部分是用于提取输入LR图像底层特征,非线性映射部分用于学习高频特征,最后的上采样与重建部分实现最终的重建。整个网络的结构如图2所示。
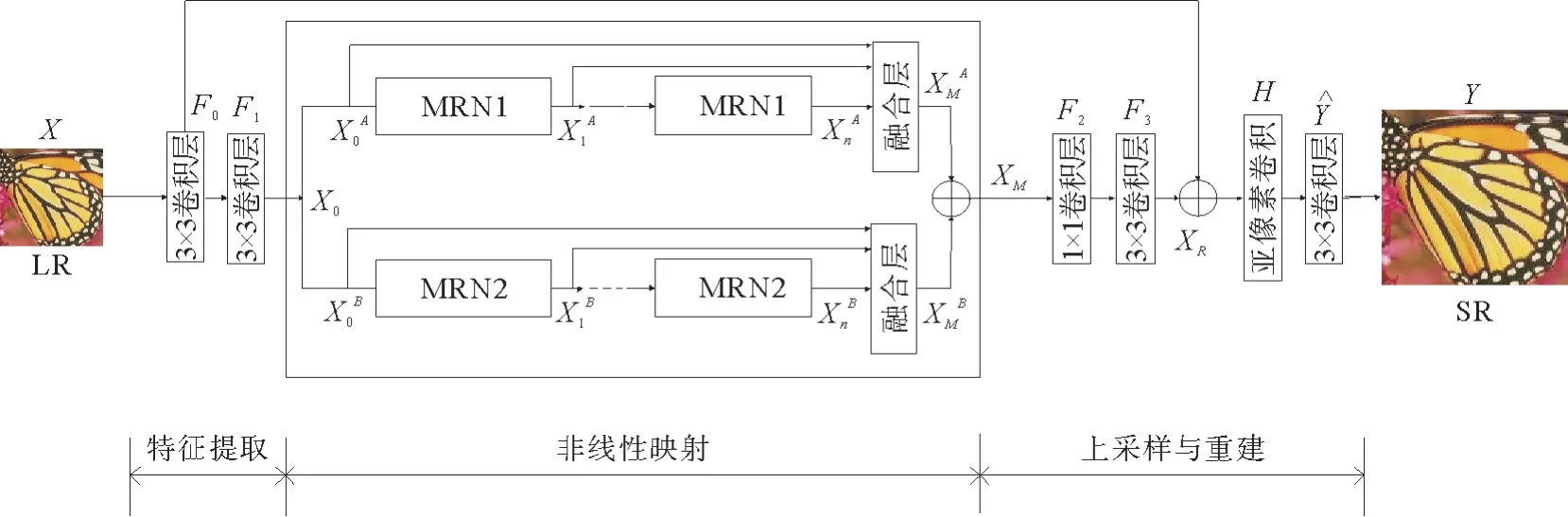
图2 双路多尺度残差卷积网络结构Fig.2 Str ucture of binar y channels multiscale residual net wor k
2.1 特征提取
为了更充分的提取低分辨率图像中的特征信息,这里采用两个串联的卷积层,卷积核的尺寸大小均为3×3。相较于大尺度卷积来说,利用两个串联的小尺度卷积,能够降低训练难度,获得更多的特征参数,便于后续的重建操作。

式(2)中X为输入的低分辨率图像,H3×3(·)是用3×3像素卷积核处理的关系映射,则F1=H3×3(F0)。
2.2 非线性映射
TANG等[12]和ZHAO等[11]通过构建独立子网络来增强网络性能。如图3所示,在非线性映射阶段,通过双路并行的串联MRN子网络构成,上下两支路之间彼此对称相似,为了避免单一尺度多导致的特征提取不充分的弊端,这里对两条支路分别采取尺寸大小为3×3像素和5×5像素的卷积核来实现。后续通过融合操作将两支路特征数据融合,利用1×1卷积层降维,并将网络的输入参数引入,建立起残差模块,避免数据膨胀和网络衰退。
假设整个非线性映射网络被表示为N M(·),则该模块的输出为N M(X0)。这里以上支路为例,假设在上支路中有n个MRN1,并且X0=F1是第1个的输入,那么第i个MRN1输出有

其中(·)对应着上支路中第i个MRN1的过程。因此,对于最后输出的MRN1值有
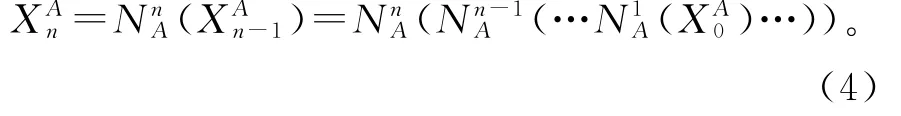
对于下支路MRN2同理。

图3 MRN1独立子网络结构Fig.3 MRN1 independent net wor k str uct ure
图3为上支路MRN1独立子网络结构,其中每条支路包含j个串联的残差结构(j=1,2,…,m)。从上一个MRN1模块的输出作为第i个MRN1中第1阶段的输入。这里设为第i个MRN1中第j阶段映射的输入,其中的i=0,1,2,…,n和j=0,1,2,…,m,则第1阶段的输入为。对于MRN1中单个残差结构的运算则有
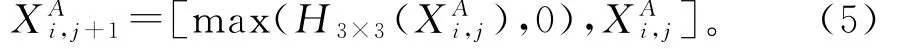
公式(5)中max(,)为激活函数运算,[…]表示“concat”连接。
在MRN1结构中,最终生成的特征映射会通过一层卷积结构,然后将局部残差学习(Local Residual Lear ning,LRL)引入,达到改善信息流的作用。表达式有
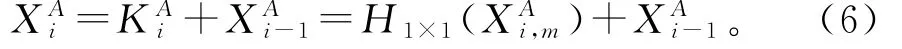
公式(6)中,H1×1(·)是在MRN1结束部分的1×1卷积运算,用来改变数据维度,残差特征来自MRN1模块的输入,不受其它特征的影响。下支路MRN2同理。
为了获得重建图像,还需要进行上采样重建操作。分别将非线性映射部分中上下支路每个独立子网络的输出结果全部连接成一个张量,得到特征数据和,然后叠加融合得到X M,最终将输入到上采样重建阶段进行重建操作。其中的X M有
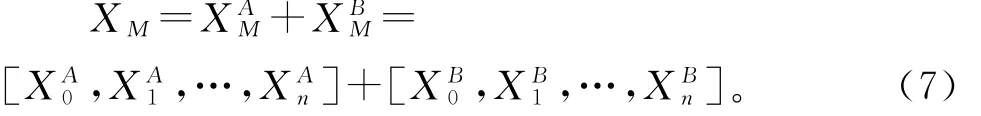
2.3 上采样与重构
这一部分利用亚像素卷积实现上采样操作,对于非线性映射模块的输出X M,先后通过1×1和3×3的卷积来处理,降低参数量,便于计算。后续将特征提取阶段的F1引入,构建全局残差模块稳定模型,最终得到待恢复的融合特征数据X R。

为了得到最终的重建图像,需要对所获得的特征数据X R进行亚像素卷积上采样,实现图像尺寸的提升,然后经过3×3卷积处理,调整参数量,最终获得重建的高分辨率图像Y。公式有
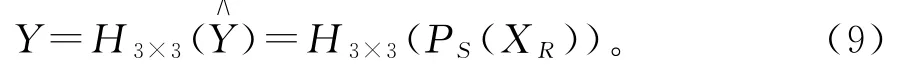
其中P S(·)为对应的亚像素卷积上采样函数,为待重建图像。
3 实验结果及分析
3.1 实验准备
实验采用的硬件平台中CPU为Intel(R)Core(T M)i7-7700,GPU为NVIDIA GTX 1060,实验环境为pyt hon 3.7,深度学习框架为Tensor Flow 1.10。采用了在SRCNN中所使用91张图片作为训练数据集,为了达到更好的重建效果,还使用了BSD训练集中的200张图片,共291张图片作为训练数据集。为了避免过拟合,使用旋转、翻转的方法,使得训练集扩充4倍[13]。为了较为准确的评判模型的优劣,这里采用当前主流的Set5、Set14、BSD100和Ur ban100作为测试集来分析研究[14]。
在网络训练过程中,首先对训练集图片进行预处理,裁剪为若干个原始高清图像块,其中步长16,分辨率为32×32。接着随机选取64个作为一个bat h,进行插值下采样来缩放3倍,然后输入到网络中训练。为了加快训练速度,减少训练复杂度,将独立子网络的数目设置为5个,每个子网络中的残差单元数目设置为3个,卷积层设置为64通道。
网络模型是基于LR图像到HR图像之间的关系映射决定的,通过使得重建图像与高清图像之间损失最小化实现模型的建立。这里使用l1损失来进行模型的训练。
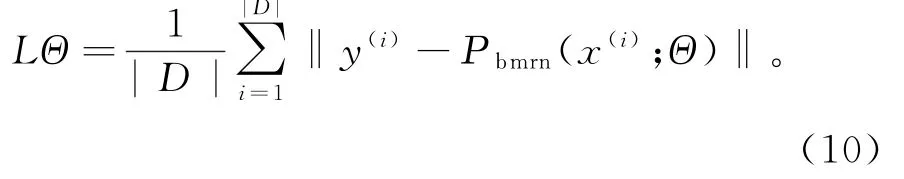
其中:Θ为整个模型训练集,Pbmrn(·)为网络的映射函数,x(i)为输入LR图像,y(i)为对应HR图像。
3.2 实验结果
3.2.1 实验评价标准
对于重建图像的客观评价,当前常用峰值信噪比(peak signal to noise ratio,PSNR)[15]和结构相似性(str uctural si milarity,SSI M)[16]来判定。
在这一部分,提出了一个访问控制机制,对用户发布到在线社交应用上的消息进行处理。隐私策略和请求访问消息的用户等级由消息发布者自己定义。用户对自己社交应用中好友的分类类似于基于角色访问控制中角色的分类,不同类型的好友对发布的消息有不同的访问权限。
PSNR是用来描述随机噪声对重建图像所造成的失真情况。计算公式为
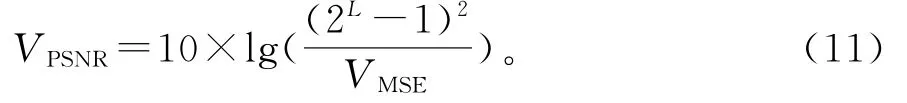
其中,L为最大的灰度等级;VMSE为均方误差。计算得出的VPSNR值越大,表示重建后图像的质量越高。
SSI M是用来衡量两幅图像之间的结构相似度,从对比度、结构特征和亮度上对图像的质量进行考虑。计算公式为
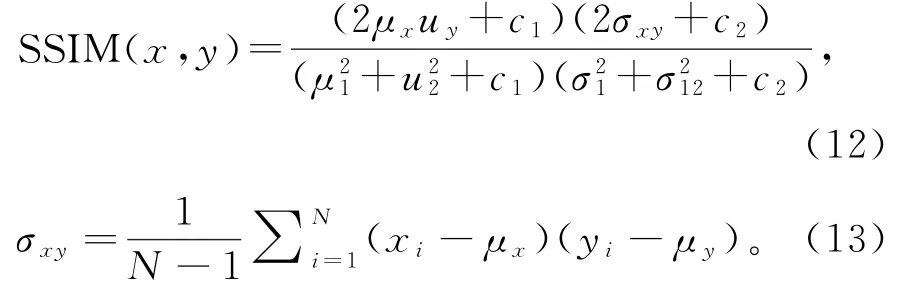
其中μx和μy分别为x和y的平均值,而σx和σy分别为x和y的方差,σxy为x和y的协方差。计算得出的SSI M值越大,表明图像越相似,重建的效果就越好。
3.2.2 实验结果对比与分析
为了验证BMRN方法的优势,这里将BMRN与Bicubic[4]、SRCNN[6]和VDSR[8]方法进行重建效果的比较。
表1为各方法在Set5数据集中进行单幅图像重建测试的PSNR值,表2为各方法在Set5、Set14、BSD100和Ur ban100共4个测试集上进行的3种放大倍数的平均PSNR和SSI M值,表中优者均用黑体表示。从表1中可以发现,针对Set5测试集的5幅图像重建比较,相较于Bicubic、SRCNN和VDSR方法,BMRN方法的PSNR数值表现均为最高,平均值分别提高了4.05、1.05和0.18 d B;从表2中可以发现,BMRN在不同数据集的重建测试中,多数获得了最高的PSNR和SSI M测试结果,VDSR为次优结果。在×2、×3和×4三个尺度下,BMRN的PSNR值分别比VDSR提高了0.11、0.02和0.07 d B。与数据集Set5、Ur ban100和BSD100相比,BMRN在数据集Set14上获得了最高的PSNR增加。比如,在×2尺度下,BMRN的PSNR值分别比Bicubic、SRCNN和VDSR提高了3.09、0.88和0.30 d B。综上,在客观评价指标中,BMRN方法表现最好。
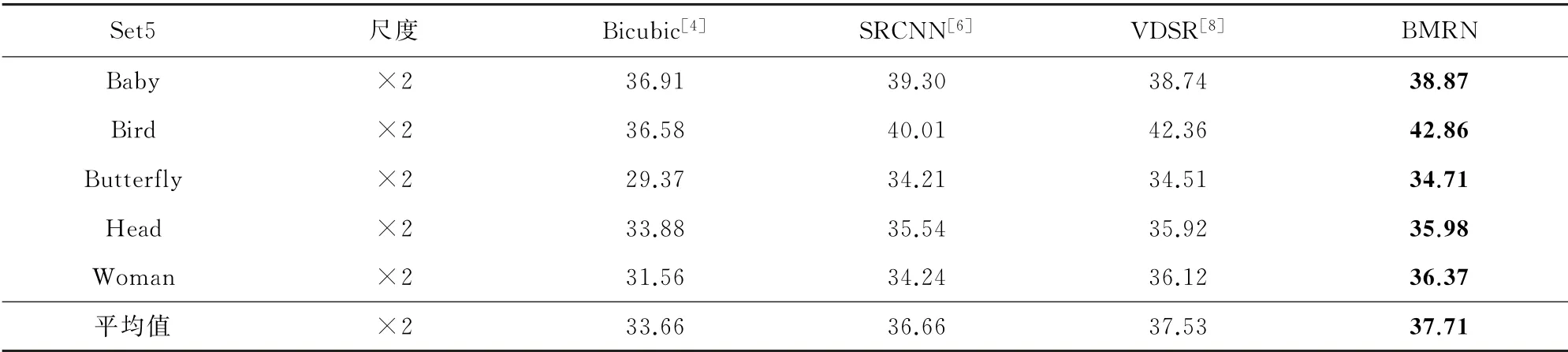
表1 不同重建方法在Set5测试集上重建效果的PSNR(d B)对比Table 1 PSNR(d B)co mparison of different reconstruction methods on set5 test set
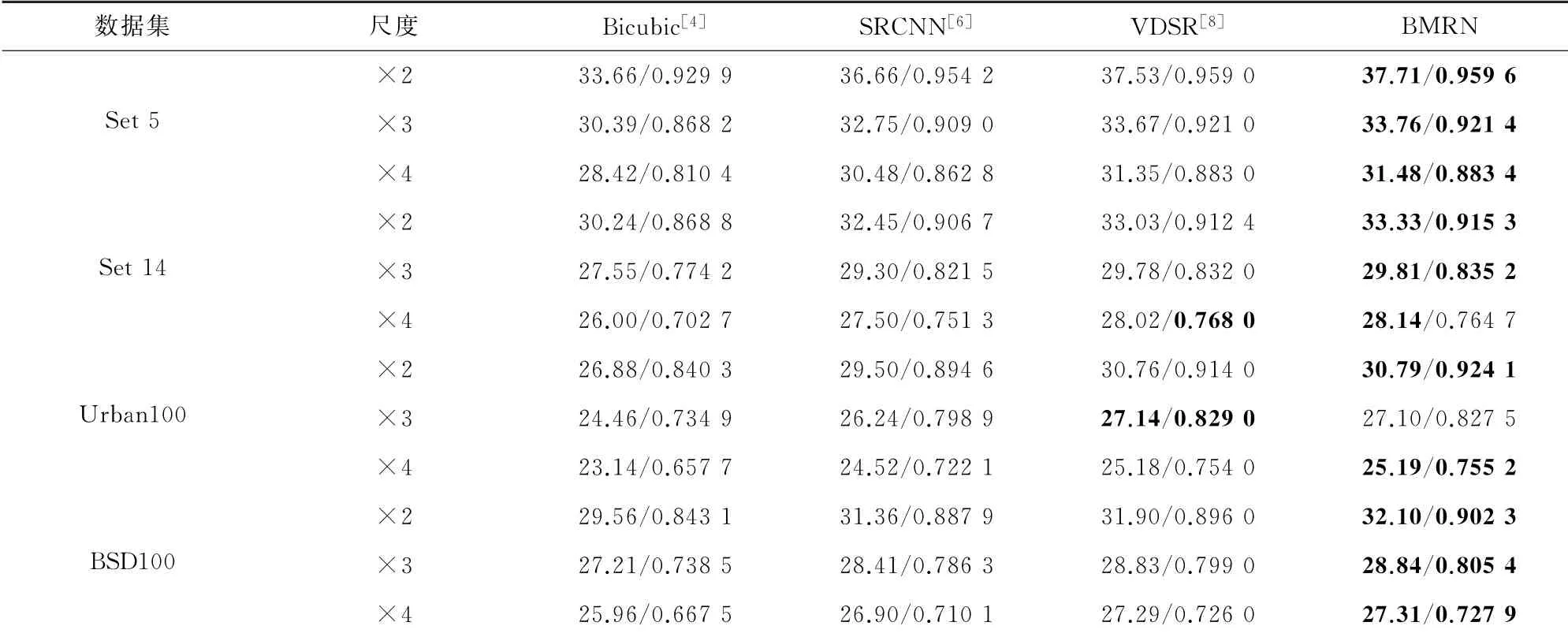
表2 不同重建方法在4个测试集上的PSNR(d B)/SSI M比较Table 2 Co mparison of PSNR(DB)/SSI M of different reconstr uction met hods on f our test sets
为了更加直观的比较BMRN方法的优势,这里将BMRN与Bicubic、SRCNN和VDSR方法进行主观视觉效果的比较。在Set5、Set14、BSD100和Urban100测试集中共选出4幅图像作为测试图像,分别输入到各方法模型中来实现×3尺度下的重建操作,最终的重建效果如图4所示。
从图4中可以看出,相较于其它方法,BMRN重建的图像在PSNR和SSI M评测指标上均为最高,从重建图像的细节上看,BMRN和VDSR方法相较于Bicubic和SRCNN方法来说,得到的图像更为清晰,边缘细节以及轮廓特征更为明显,但是BMRN方法的视觉效果最好,锐度得到了一定的增强。综上,在主观评价比较中,BMRN方法表现的最好。

图4 BMRN方法与其它方法的重建效果对比Fig.4 Co mparison of reconstr uction effect bet ween BMRN met hod and other met hods
由于SRCNN卷积层数较少,并不能有效提取图像中的特征信息,而VDSR虽然增加网络的深度,但是仅利用单一尺度卷积来处理,对图像中的高频信息提取能力较差。本研究所设计的BMRN采用不同尺度的分支结构,更有效的提取图像中的细节特征,并且利用密集残差连接来保证信息的有效性,能够在增加网络深度的同时稳定模型梯度,避免信息丢失,较大程度的保留特征信息,最终使得重建图像获得较好的质量效果。从以上实验中可以得出,BMRN方法所重建的图像,在客观评价指标以及主观视觉效果上均优于Bicubic、SRCNN和VDSR方法。
4 结 论
这里提出一种双路多尺度残差网络(BMRN)的图像超分辨率重建算法。该方法主要是由多个独立子网络构成的双路并行特征提取模块来实现,两支路彼此相似,采用不同尺度卷积核来互补单一尺度带来的信息提取不充分问题,通过残差连接实现网络的稳定,避免梯度弥散现象,最后利用亚像素卷积模块来实现图像的上采样操作,最大程度的保留原始低分辨率图像的特征信息。在对不同数据集进行不同比例倍数的重建测试中,BMRN方法的平均PSNR和SSI M值比传统Bicubic、SRCNN和VDSR方法有所提升,重建所得到的图像在主观评价指标上也有着明显优势。实验结果表明:BMRN方法能够实现单幅图像的超分辨率重建,较好的恢复出图像轮廓特征和细节信息,具有一定的应用价值。
