基于特征融合的人脸表情识别算法研究
2021-06-07李波王坤侠
李波,王坤侠
(安徽建筑大学 电子与信息工程学院,安徽 合肥 230601)
关键字:人脸表情识别;方向梯度直方图;人脸特征点;特征融合
面部表情作为人类语言的一部分,是表达内在情感和意图的最重要方法之一。由于面部表情识别在人机交互,商业产品和医学研究中的广泛应用,在过去的几十年中,它已经在计算机视觉和模式识别领域得到了广泛的研究。Ekman 等通过描绘不同的脸部肌肉动作与不同表情的对应关系,进而确定了六种不同的基本情感。Pantic 等通过从面部表情图像的正面轮廓中提取facial landmark 来获得32 个肌肉运动单元,并大致完成对六种基本类型的情感识别。胡敏等提出了一种Gabor 梯度特征直方图的表情识别方法,该方法使用Gabor 表示原始图像数据的局部特征,然后在相同比例的不同方向上进行特征的融合,并计算融合特征的直方图。面部表情的识别由多种特征组成,进行面部情感识别时,不相关的特征会影响情感识别的准确性,因此具有高影响因子的特征集的获取已成为面部表情识别的重要研究方向。
目前用于表情识别特征提取的方法主要有Gabor 小波、局部二值模式(Local Binary Patterns,LBP)、方向梯度直方图(Histogram of Oriented Gradient,HOG) 和 主 动 外 观 模 型(Active Appearance Model,AAM)等方法。Gabor 小波变换通常用于提取面部表情图像的局部纹理特征,Log-Gabor改进了原始的Gabor 滤波器以提取与人类视觉系统识别相似的特征。HOG方法通过使用HOG 算子计算局部图像像素值变化的幅度信息和方向信息,并统计梯度方向密度来描述图像的局部边缘特征。该方法计算复杂度低,提取效果好,更好地保持图像的几何不变性和光学不变性,是经典的特征提取方法之一。LBP方法是一种有效的局部纹理描述算子,对图像的灰度变化以及旋转具有一定的鲁棒性。AAM方法综合考虑全局形状和纹理信息,对人脸形状特征和纹理特征进行统计分析。胡敏等分别对眉毛和嘴巴部分进行特征提取和表情分类,取得了很好的分类效果。赵等提出了一种融合LBP 特征和多方向Gabor 直方图特征的方法,实验结果表明,与单独使用其中一种特征进行表情识别相比,融合特征可以获得更好的识别效果。文献[17]将人脸表情图像的几何特征和纹理特征进行融合,充分利用了纹理信息和人脸的结构特性,增强了因个体差异而产生的不同表情特征的鲁棒性。与传统的通过分类器训练的人工特征提取方法不同,CNN 无需预处理即可直接处理图像并输出最终的情感分类结果,这是一个“端到端”的网络模型。Hinton 等考虑到单个CNN 的结构太小这一事实,在2006 年提出了深度信念网络(Deep Belief Network,DBN)模型,通过模拟人类的视觉认知系统,DBN 逐层训练网络,以实现高维非线性数据的特征提取和分类。在2013 年Kaggle 举行的面部表情识别挑战赛中,Tang 和Bergstra使用了卷积神经网络,其准确率达到了69.7%,最终攀升至榜首。CNN 进行特征提取时,训练数据会隐式的进行学习,从而避免了显式的特征提取。然而,CNN在进行人脸表情识别任务中,需要大量的训练数据来训练模型的参数,由于人脸表情库的数据量较小远远不能满足网络参数训练的要求,为了提高面部表情识别的准确率,一种方式是通过改进CNN 网络模型,例如扩大卷积的宽度和加深网络模型的深度,另一种是将CNN 与传统方法进行融合,弥补彼此的不足,提高特征的提取能力,从而达到更好的识别效果。Jung 等提出了两步法进行表情识别,使用深度学习提取面部的外观特征和几何特征,之后,再次提出新的两步法识别模型,首先使用类似haar 的特征作为面部检测,再分别使用深度神经网络(Deep Neural Network,DNN)和卷积神经网络(CNN)两种类型的网络模型,最终结果表明,CNN比DNN具有更好的准确性。赵等提出了一种基于DBN 和逻辑回归的面部表情识别方法,该方法首先检测面部,利用鼻子、眼睛和嘴巴的位置信息,以进行面部表情识别。
将基于facial landmark 的几何特征用于面部表情识别也是一种已被应用的常用方法。Alexandra等通过描述面部表情然后使用多层感知器(Multilayer Perceptron,MLP)和支持向量机完成情感分类。Paul 等使用了facial landmark 和基于轨迹的几何特征,在UvA-NEMO 和CK 数据集上验证了该方法的有效性。本文综合利用人脸表情图像的局部特征和全局特征,提出了一种基于几何特征和纹理特征相融合的人脸表情识别方法。首先,使用基于三层级联体系结构的多任务卷积神经网络(MTCNN)从人脸面部表情图像中提取facial landmark,从而利用facial landmark 的位置信息来计算相关面部点之间的相对距离,以捕获由表情变化而产生的特征向量。同时,采用HOG 方法来获取人脸图像的幅度信息和方向信息,通过融合这两个特征创建LM_HOG 特征向量。最后,将LM_HOG 特征与经过CNN 网络模型获得的一维特征矢量进行拼接,使用分类器进行人脸表情识别。为了验证所提出方法的有效性,分别采用SVM 和Softmax 在FER2013 和CK+人脸数据集上进行人脸表情识别,实验结果表明,该方法在两个数据集上的识别率分别为75.14%和97.86%,验证了本文方法的优越性能。
1 本文算法
本文所提出的面部表情识别算法流程如图1所示,主要分为图像预处理、特征提取以及表情识别三个模块。在特征提取阶段,针对单一特征对人脸表情信息表征不全面的情况,将特征提取网络分为两个通道,通道一通过对输入的表情图像进过预处理后使用CNN 模型提取人脸表情图像的全局特征,对光照等物理因素的变化具有很好的鲁棒性;通道二根据facial landmark 的位置信息计算出人脸结构特征与HOG 特征,提取出面部图像的几何特征和纹理特征。表情识别模块分别采用了SVM和Softmax 分类器进行情感分类。
1.1 预处理
为了更好地提取人脸表情特征,需对输入的面部图像进行预处理。预处理可以提高图像质量,消除噪点,为后面的特征提取和分类奠定良好的基础。本文对输入的面部图像进行预处理的流程为:
步骤一:对图像进行人脸检测,以达到减少图像中与人脸无关的背景信息对特征提取等产生影响的目的。由于人脸可能出现在图像中的任何位置,本文使用一种固定大小的滑动窗口(sliding window)扫描整个输入图像以确定人脸位置。当使用滑动窗口进行图像扫描时,可能会得到多个候选框,此时采用非极大值抑制(non-maximum suppression,NMS)方法对候选框进行合并以及消除重复数据。
步骤二:根据人脸检测得到的候选框利用旋转矩阵进行旋转校正,增强其旋转的鲁棒性,然后裁剪出人脸面部区域。旋转矩阵定义如下:

其中(x,y),表示原始坐标;(x',y')表示旋转后的坐标;θ 表示旋转角度,旋转角度可通过测量两个眼睛中心点向量与水平方向的夹角得到。
步骤三:归一化操作,将裁剪后的面部图像归一化为统一大小,多维特征将具有相似的缩放比例。从而减少了特征提取的面积,有助于梯度下降算法更快的收敛。并且,若输入图像为RGB 格式,将其进行灰度化处理以降低数据维数,在保持大部分信息的情况下减少了计算量,同时便于后续的facial landmark 定位以及HOG 特征提取。
1.2 人脸特征点定位
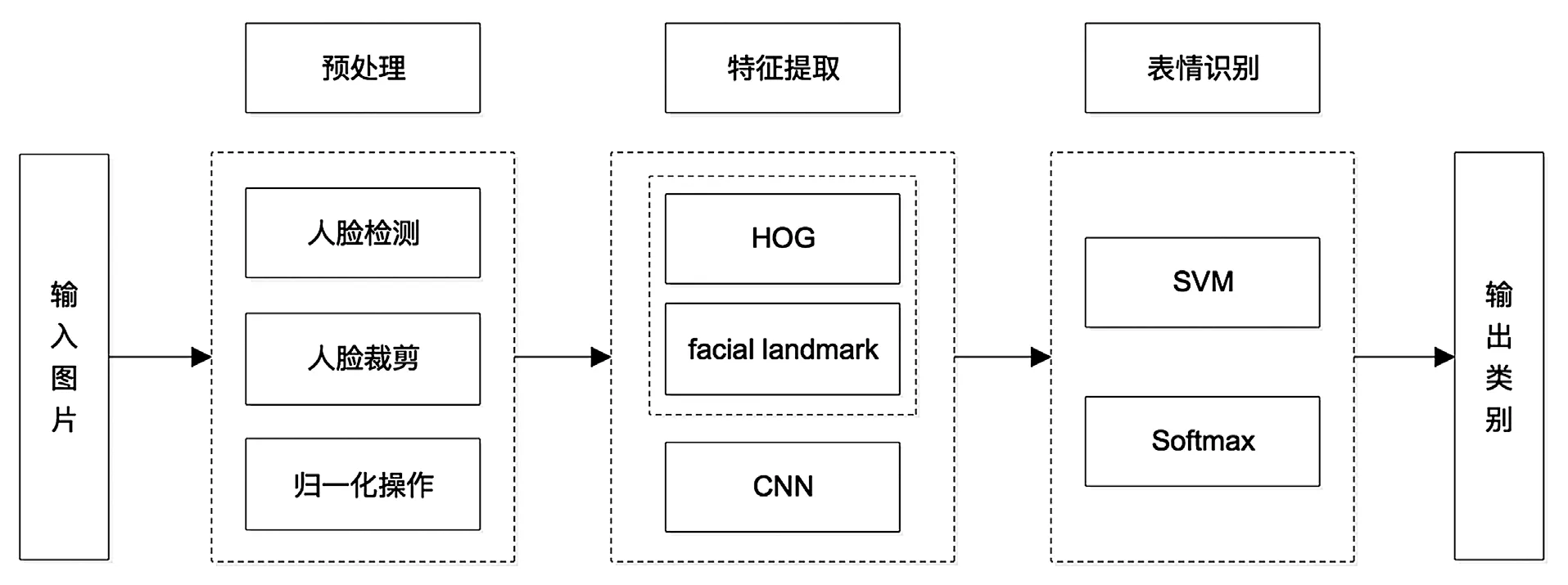
图1 本文算法流程图
在进行图像预处理之后,进行人脸特征点定位和特征提取。汤晓鸥等提出了一种基于DCNN的多任务学习方法,并用于人脸特征点检测。该方法采用人脸特征点定位任务为主,其他多任务为辅的策略,最终的实验结果表明该方法在一些遮挡和大姿态人脸面部图像中取得了较好的性能。在文献中,人脸特征点分为两个部分,第一部分用于预测面部图像特征的51 个特征点,这部分被称为内部点;另一部分被用来预测面部轮廓的17 个特征点,即轮廓点。其中,当对着两部分的特征点进行预测时,它们是完全分离的,并且分别对各个网络进行了训练和预测,从而获得相应的边界框。此外,在预测内部点时,使用四级DCNN 模型分离面部特征,并且不共享相同的损失函数,从而避免了不平衡问题并实现了精确定位。由于直接使用人脸检测器检测到的人脸边界框通常包含太多不相关的背景,因此会干扰训练,故使用CNN 模型预测人脸边界框时更有效。基于该方法,考虑到人脸特征点定位与姿态估计关系密切,二者使用相似的特征与内部表示,都需要对光照、遮挡等因素表现出鲁棒性,因此本文结合了新的级联深度神经网络(Deep Alignment Network,DAN),并且添加了特征点热图(feature heatmap)的方式对人脸特征点进行定位任务(如公式2)。DAN 每个阶段包含三个输入和一个输出,输入分别是被矫正后的图片、关键点热图和由全连接生成的特征图,输出是面部表情的形状。其中,CONNECTION LAYER 的作用是将本阶段得到的输出进行一些列变换,生成下一阶段所需要的的三个输入,具体操作如图2 所示。由于CNN 的输入是变换后的图像,故得到的偏移量为相对偏移量,偏移后应通过逆变换将其还原到原始空间,因此对姿态变换具有良好的适应性。

图2 DAN 基本框架

关键点热度图的计算就是一个中心衰减,关键点处值最大,越远则值越小,其中T表示变换后的图像,t 是当前stage 的序号,T(S)表示变换后的特征点,H(x,y)表示变换后的热力图图像。
通过DAN 获得特征点后,利用这些锚点坐标来进行一些相关距离的计算,如图3 所示。在本文提出的方法中,将眼睛靠近鼻子最接近的点即图2中的特征点39 和42 作为固定点,鼻子的下端为特征点33。从这些固定点出发计算相关距离。基本上,需要考虑与眉毛与运动有关的8 个特征点和与嘴巴相关的6 个特征点。但是,这些点之间的绝对距离不能直接使用,因为可能存在各种其他因素产生干扰,例如不同的脸部大小以及图片拍摄距离等,因此为了消除这些变化需要对距离进行归一化。为了归一化左眉的距离,将计算出来的距离除以特征点39 和21 之间的距离(如公式3)。类似的,利用特征点42 和22 对右眉的距离进行归一化。同时,还可以使用特征点33 和51 之间的距离来归一化嘴巴的宽度、嘴巴的高度。对于每只眼睛,相对于嘴巴上唇的左上角和右上角将计算出两个距离,最终计算出六个值的特征向量。

图3 人脸特征点定位

1.3 HOG 特征提取
方向梯度直方图(Histogram of Oriented Gradient,HOG)最初由Dalal 和Triggs提出用于目标检测,主要被用于统计图像的局部梯度特征。HOG 特征具有很多优点,首先,由于HOG 是在图像的局部单元上计算得出的,因此可以很好的保持图像的几何不变性和光学不变性;其次,HOG 描述了边缘结构特性,因此很好的描述图像的局部形状信息。HOG特征提取具体过程主要分为以下几个步骤:
步骤一:归一化处理,利用Gamma 校正对输入进行颜色归一化,从而调节图像的对比度,降低图像局部阴影和光照变化对结果造成影响,消除一些噪声的干扰。
步骤二:梯度计算,通过梯度计算对图像进行边缘检测,计算出人脸表情图像中像素点(x,y)的水平和竖直方向的梯度,公式如下:
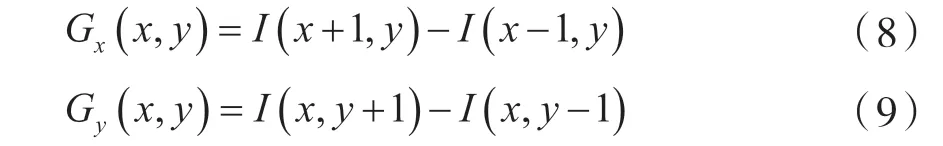
步骤三:梯度幅值和角度计算,使用前面梯度计算得到的梯度值G和G,通过公式(10)和(11)计算梯度幅值G(x,y)和梯度方向θ(x,y)。
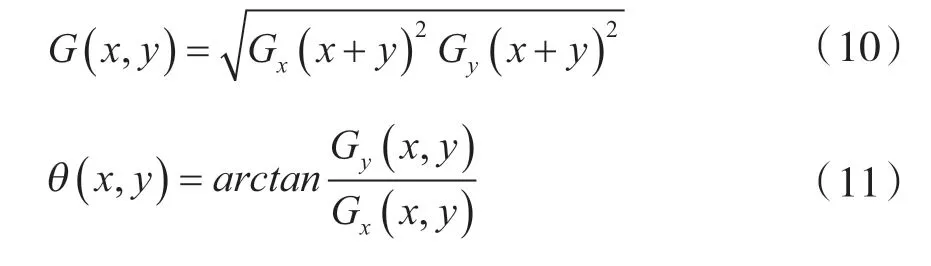
步骤四:C-HOG 计算[29],将人脸表情图像利用其维度信息平均分割成m×m 个像素大小的Cell,在获取Cell 之后统计以Cell 为单位的方向梯度直方图C-HOG,之后将梯度方向平均分为N 个方向角度区域(Bin),用λ(x,y)表示在(x,y)位置处对第n 个Bin 的权值,权值的取值计算如下:

步骤五:B-HOG 计算,由步骤三分割的Cell,利用其相邻的 m*m 个从而组成一个较大的单元块(Block),将块内所有Cell 的C-HOG 通过串联得到块的方向梯度直方图(B-HOG),然后,采用L模标准化的方式对每个B-HOG 进行标准化(如公式13)。

其中,ε 是一个无穷小量,为了避免分母为0。
步骤六:HOG 特征提取,将每个B-HOG 以串联的形式拼接在一起,顺序级联这些特征,进而得到人脸表情图像的HOG 特征。
在本文中,将所提取到的HOG 特征与通过人脸特征点定位获得的feature进行向量间串联拼接融合,形成融合后的LM_HOG 特征向量。
1.4 表情识别
表情识别是最后也是最重要的一步,使用基于分类的识别策略执行。创建LM_HOG 特征向量后与经过CNN 得到的特征进行融合输入到分类器中对面部表情进行分类识别。在本文中,分别使用SVM和Softmax 进行表情识别。
2 实验
实验采用的环境为:软件环境Windows10 下的TensorFlow 平台;硬件环境:处理器是Intel Core i7-7700 CPU,显卡是GTX-1070;
2.1 表情数据库介绍
FER2013 是Pierre 和Aaron 通过Google 图像搜索API 自动收集的无约束的大规模数据集,是Kaggle 面部表情识别挑战赛中的公开数据集,共包含35887 张人脸表情图像,28709 张图像作为训练集,3589 张图像作为验证集,3589 张图像作为测试集,每张人脸图片的像素大小为48×48,所有的图像都进行相同的预处理操作。该数据集反映了不同环境下人脸表情呈现的真实状态,每一类表情在年龄、光照、面部姿态、表情程度等方面都有着显著的差异,具有一定的挑战性。
CK+ 数据集是在人脸表情数据库Cohn-Kanade(CK)基础上扩增而来的,是目前评估人脸表情识别方法最广泛的实验室控制条件下的数据集。该数据集包含来自123 名受试者593 个视频序列,其中共有327 个样本,总共涵盖了七种基本表情。由于CK+数据量较少,故此在实验中采用了十折交叉验证的方式进行,即加载全部表情图像然后将人脸表情数据数据均分为10 份,每次训练时取其中9 份进行训练,然后另一份进行测试,共进行10 次实验,为了避免单次实验的影响,最后取实验的平均结果作为表情识别率。
2.2 实验结果与分析
在对CNN 网络模型的训练中,网络模型的详细训练参数见表1。

表1 网络模型训练参数
为了验证该方法融合特征的有效性,从人脸表情图像中提取了基于几何特征的facial landmark,HOG 特征,以及融合后的LM_HOG 特征,并且在人脸表情图像预处理中,分别采用是否加入sliding window 的操作进行实验效果对比,验证其有效性。表2 为基于CNN 融合模型结构在不同的特征组合下,分别在FER2013 和CK+两个数据集中进行实验得到的表情识别率。由表2 中的实验结果数据可以看出,将基于facial landmark 的几何特征与基于纹理的HOG 特征进行融合可以更为有效的提高表情识别率,验证了本文方法的有效性。
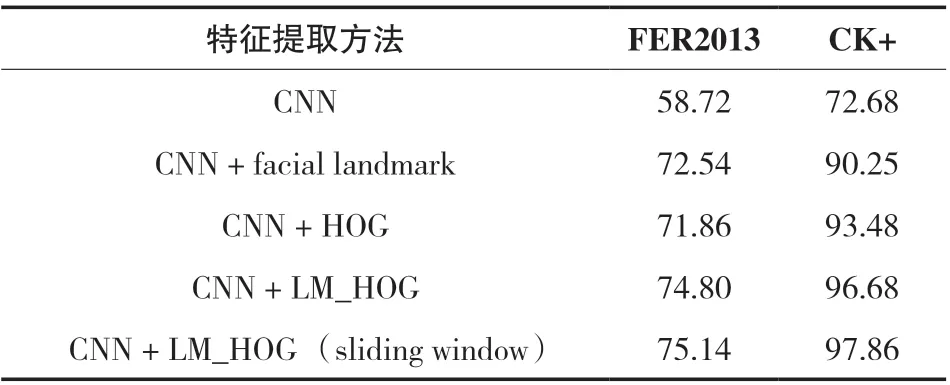
表2 不同特征组合方式识别率对比 (%)
表和表分别为在FER2013 和CK+上的表情识别混淆矩阵。从表3 的混淆矩阵可以看出,该方法对“高兴”情感的识别率最高,而对于“恐惧”的识别率相对较低。这种情况出现的原因主要有两个:一个是数据集中的情感类别数量不均衡,例如有7215 张“高兴”表情图像,而“恐惧”表情图像只有436 张,统计发现每种类别的平均数量大约为4101张,而“恐惧”数量不足从而导致学习不够;其次,“恐惧”、“厌恶”、“伤心”这几类情感在情绪表达时有一定的相似之处,这使得它们有时难以区分,并且在原数据集中同样存在很多错误分类的情况,这使得训练难度更大;第三是因为模型对于面部夸张、运动幅度大的表情,提取更加明显且更易提取,而对于运动幅度小、面部变化不明显的表情,识别率较低。从表4 的混淆矩阵可以看出,本文所采用的特征融合的方法对每种表情的识别率都能达到95%以上,表明本文多特征融合的方法可以对表情进行有效的区分。

表3 基于CNN + LM_HOG 的表情识别率混淆矩阵(FER2013)
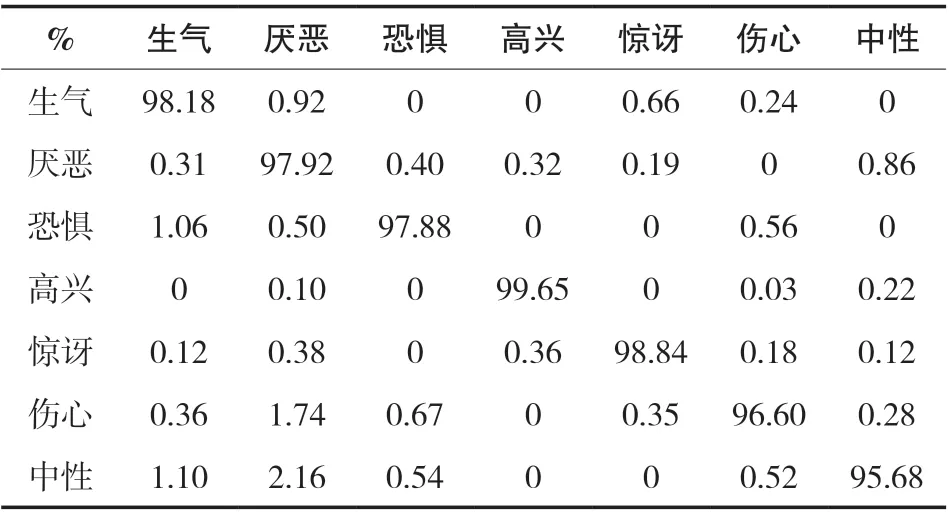
表4 基于CNN + LM_HOG 的表情识别率混淆矩阵(CK+)
在FER2013 和CK+数据集中,将本文方法与目前主流的人脸表情识别方法进行了比较,包括GLTP、Gabor、LDN、CNN、Geometric feature + LBP + SVM、HOG + DBN + Gabor +SAE、LBP + MTSL、Boosted DBN、DNNRL、T-DNN、CPC、RTCRelief-F等方法。实验结果如表5,6 所示,可以看出,本文所提出的方法对表情具有更好的识别效果,识别率明显高于其他几种方法。

表5 本文方法与目前主流的方法对比(FER2013)

表 6 本文方法与目前主流的方法对比(CK+)
3 结论
本文提出一种基于卷积神经网络融合特征的人脸表情识别方法,结合facial landmark 和HOG 特征对人脸表情图像进行几何特征、局部梯度特征、纹理特征的提取,然后将两种特征进行融合形成LM_HOG 特征,最后将融合后的特征与经过CNN提取的全局特征再次融合输入到分类器中进行表情识别。在FER2013 和CK+数据集均取得了较好的识别效果。特征融合的方式能够将单一特征的优缺点进行有效互补,可以更充分地提高面部表情信息,因此能够取得较好的表情识别效果。在接下来的工作中,对于含有较大遮挡的面部表情识别任务将成为研究的重点,提高识别网络模型对于遮挡情况的鲁棒性。
