一种基于多特征集成学习的恶意代码静态检测框架
2021-06-04高明哲
杨 望 高明哲 蒋 婷
(东南大学网络空间安全学院 南京 211189) (计算机网络和信息集成教育部重点实验室(东南大学) 南京 211189) (江苏省计算机网络技术重点实验室(东南大学) 南京 211189)
据不完全统计,现如今恶意代码已成为网络攻击的主要载体,恶意软件的样本总量已达到百亿级别,且每天新增百万级别的恶意样本.据国家互联网应急中心(CNCERT)发表的《2020年上半年我国互联网网络安全检测数据分析报告》[1]指出,仅2020年上半年,CNCERT就捕获计算机恶意程序样本数量约1 815万个,日均传播次数达483万余次,涉及计算机恶意程序家族约1.1万余个.而来自AV-Test[2]的数据则声称在2020年已统计到11.04亿的恶意软件样本.由此可见,爆炸性增长且种类繁杂的恶意样本如无法被快速高效地检测,极易对用户个人的财产安全、社会安全、乃至国家安全产生巨大威胁.
传统基于人工签名的检测方式[3]早已无法适应目前恶意软件数量指数型增长的趋势.同时为了抵抗检测,恶意软件的变种、加壳[4]、混淆[5]等技术也一直在迅猛发展中.随着对抗技术的不断成熟,单特征和单模型的检测能力持续不断的下降,因此,实现大规模样本数据的高效分析,并将之提取为机器可理解的数据,训练对恶意样本的加壳、混淆等技术有良好适应性的分类器已成为当前恶意代码检测的重中之重.
恶意代码分析方法有动态分析、静态分析2种类别.静态分析无需执行恶意软件即可对其进行分析.通常静态分析提供了对伪代码、散列、标头结构、字符串、元数据等数据的分析.静态分析恶意软件一般使用反汇编工具IDA Pro[6],OllyDbg[7],OllyDump[8]等对恶意软件进行逆向工程,以达到了解恶意软件的代码、逻辑结构等目的.动态分析则是指在受控环境中执行和分析恶意样本,受控环境往往因存在某些与真实环境之间固有的缺陷而容易被恶意样本所察觉,但使用真实环境的成本又过于昂贵.因此静态检测依然是恶意软件分析中的重要环节,一旦静态分析检测出恶意软件,就可以跳过下一步的动态分析,这在很大程度上节省了时间与人工等资源成本.
在近些年的研究中,一些学者不通过恶意软件的先验知识也能利用机器学习方法对恶意软件进行分类,如Nataraj等人[9]提出恶意软件转为图像的方法,将恶意软件转为灰度图表示,之后恶意软件图像就在学术界被广泛研究.Saxe等人[10]引入信息领域中熵的概念,将字节熵直方图应用在恶意代码检测中.Anderson等人[11]则在此基础上进一步挖掘其他相关特征以构建模型.当然另一主流研究方向则是利用恶意软件的先验知识,通过逆向工程的手段,提取字符串[12]、操作码[13]、可执行文件结构[14]和函数调用图[15]等特征以构建检测模型.不管是否基于先验知识,这些静态分析的研究方法均为恶意软件检测提供了更多落地的可能,但最近的研究[16]表明恶意软件加壳、混淆等对抗技术会极大的限制静态分析技术,使静态检测器的泛化能力急剧下降.因此如何缓解并突破对抗技术所带来的限制,该问题本身的研究价值是毋庸置疑的.
在近年的研究成果中,集成学习也成为常用的模型聚合方法:Zhang等人[17]提取恶意软件的n_gram字节序列,使用多个概率神经网络训练并聚合结果.Garg等人[18]则使用IDA-Pro提取API调用,创建多层次集成学习模型进行训练,以使模型对特征具有更好的表达能力.Guo等人[19]则通过提取恶意样本图像的GIST描述符,集成KNN和随机森林模型以聚合结果.上述研究表明:多模型集成方法均能进一步提高模型的表达能力,使特征的潜能进一步发挥出来.但众所周知,模型的检测能力不仅受限于模型的表达能力,也受限于特征的潜在能力.一般利用集成学习的研究成果均使用单特征作为输入,而加壳和混淆等对抗技术能够对静态检测中单特征检测造成不同程度的影响,而从不同测度提取特征,在多特征的基础上构建多模型集成能更好地抬高特征潜能的上限,使模型的表达能力不再局限于单特征,多种测度的特征互相补充,取长补短,能更好地缓解加壳、混淆等对抗技术带来的威胁,使恶意样本在静态检测阶段就能够被捕获.
本文提出一种基于多特征的策略投票方法的恶意代码静态检测框架,该框架可以有效缓解对抗技术发展带来的威胁,对恶意代码的变种、加壳、混淆都有较强的普适性,且能有效减少对全部样本直接进行动态分析的资源成本和人工分析的人力成本.
本文的主要贡献有2个方面:
1) 提出了一种基于多特征的静态检测方法,该方法从不同角度提取了恶意软件在字节、指令、调用3个不同层次的特征,并在每个特征的基础上进行基模型的集成,增强模型的泛化能力,使其更加不易过拟合,然后采取策略权重投票算法纠正单特征训练的初始分类错误,并且设定相应的策略阈值,在保证误报率较低的条件下提高检出率,达到最好的检测效果.该方法不仅能在未加壳的恶意样本检测中产生更好的效果,同时也能有效缓解变种、加壳、混淆等恶意样本对抗技术造成的干扰.
2) 论文使用的实验数据加入了多种加壳和混淆样本,包括使用了UPX壳、VMP壳、Themida壳以及Mpress壳等多种带有压缩壳或加密壳的样本,这些样本的使用可以更好地验证检测算法在恶意样本使用对抗手段时的效果.
1 特征与算法
我们选用了6种静态特征作为恶意软件检测的特征测度,其中包括:恶意软件图像的纹理特征、字节统计值和字节熵直方图特征、opcode序列特征、字符串序列特征、PE文件结构特征以及函数调用关系特征等,下面对每部分特征进行详细描述.
1.1 恶意样本图像与Gist描述符
恶意软件的二进制文件通过多个步骤可转化为灰度图像,如图1所示.首先我们将二进制文件按照8 b无符号整数依次读取并存入向量中.其次读取文件大小,根据文件大小与灰度图宽度映射表得到灰度图的width,而后根据文件大小和width计算灰度图的height,文件大小到width的映射如表1所述,将这些向量转为形状是[height,width]的2D数组,最后将2D数组可视化为[0,255](0:黑色,255:白色)范围内的灰度图像.二进制文件转化为灰度图算法流程如算法1所示.
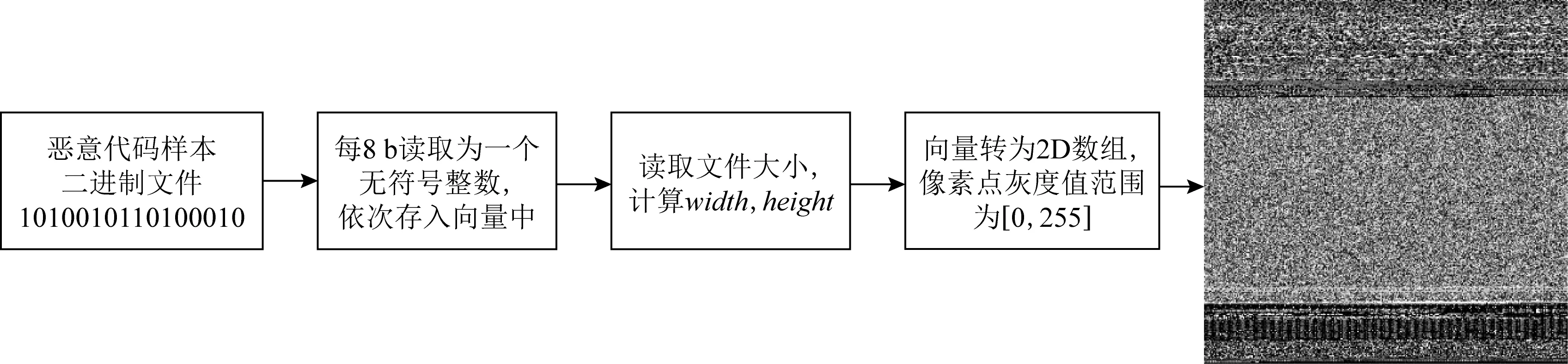
Fig. 1 Binary to malware image图1 二进制转恶意软件图像
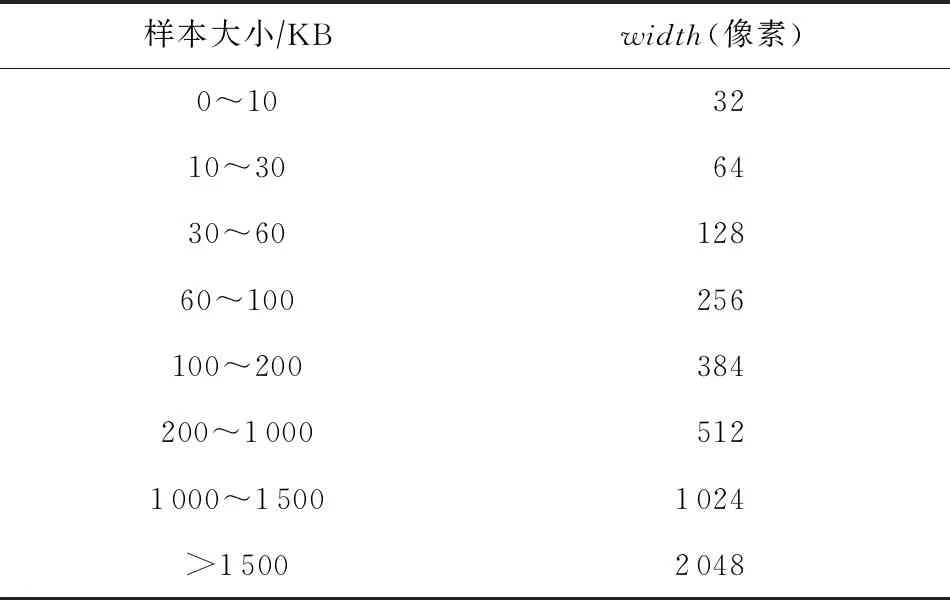
Table 1 Binary File and Grayscale Image width Mapping表1 二进制文件与灰度图width映射
算法1.二进制文件转恶意软件图像.
输入:二进制文件file;
输出:file的图像表示image.
① functionbin2image(file)
②f=open(file,“rb”);
/*以二进制读取文件*/
③image=np.fromfile(f);
④ /*将每8 b转为一个无符号数存入
image中*/
⑤filesize=image.shape[0];
/*获取二进制文件大小*/
⑥width=get_image_width(filesize);
⑦ /*根据映射表获取width*/
⑧height=filesize/width;
/*计算height*/
⑨image=image.reshape(height,width);
/*调整shape*/
⑩ returnimage;
我们在将恶意软件转为图像后,对图像做统一的标准化处理,即统一图像的shape至固定尺寸.我们使用(256,512)作为图像新的height和width,如果图像尺寸大于该尺寸,则使用像素面积相关重采样算法缩小图片至该尺寸,该算法可以有效避免图像缩小时波纹的产生.否则使用双三次插值法放大图片至该尺寸.
图像描述符通常用来描述图像中的视觉特征.我们使用GIST描述符[20]计算恶意软件图像之间的相似度.给定对应输入图像,计算GIST描述符:首先需要将1幅恶意样本图像f(x,y)划分为4×4的网格块,每个网格块代表一个子区域,按照行依次标记为p1,p2,…,p16.其次在每个网格块使用4个尺度,8个卷积方向的Gabor滤波器做卷积滤波计算,每个网格块再经过各通道的滤波后,将卷积结果级联,得到该网格块图像的局部GIST特征为
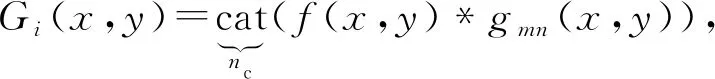
(1)
其中,i=1,2,…,16,(x,y)∈pi,nc为m×n个通道,gmn表示滤波函数,cat为级联运算符,*为卷积运算符.
最后计算局部GIST特征的均值,并将结果按行组合,得到全局GIST特征为
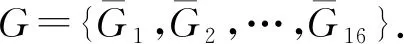
(2)
由于我们将图像划分为16个子区域,同时使用4个滤波尺度和8个方向的Gabor滤波器做卷积滤波计算,故因此会生成32个与输入图像大小相同的特征图,平均16个子区域内32个特征图的值排列组合得到的全局GIST特征为512维.GIST描述符总结了输入图像不同部分的梯度信息(比例和方向),因此可作为判断恶意软件图像之间的相似度依据.
1.2 字节统计值与字节熵直方图
字节统计值同样是一种无需解析PE文件格式就可直接提取特征的一种方式,它统计二进制文件中的全部数据,每8 b划分为一个单位,其值在[0,255]之间,统计每个值的出现次数.在生成特征时,由于文件大小也作为常规文件信息中的特征,故字节统计值需要归一化处理,即计算[0,255]范围内统计值的总和,每一个统计值除以总和得到归一化后的统计值.某样本的字节统计值如图2所示:
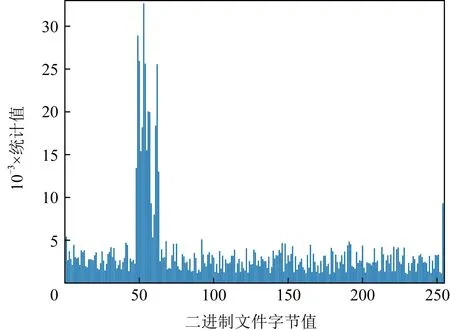
Fig. 2 Byte statistics图2 字节统计值
字节熵直方图则近似于熵H和字节值X的联合分布p(H,X).我们为二进制文件计算以字节分布建模的字节熵直方图的bin值.为了提取字节熵直方图,如文献[10]中所述,我们在二进制文件上滑动一个固定字节长度的窗口,步长也为固定字节长度,通过计算在该窗口中每个字节的出现次数,并计算每个窗口上的以2为底的熵,使用计算出的熵值作为下标,将窗口中每个字节的出现次数自增到特征矩阵相应下标所对应的向量上.随后滑动窗口继续计算对应字节窗口的熵值.在生成特征时,展开该特征矩阵为一维特征向量.计算字节熵时滑动窗口示意图如图3所示,在每个窗口内计算字节熵算法流程如算法2所示,遍历二进制文件所有字节算法流程如算法3所示.

Fig. 3 Schematic diagram of sliding window图3 滑动窗口示意图
算法2.每个窗口内计算字节熵算法流程.
输入:原始样本在每个窗口内的二进制数据data、窗口值window;
输出:熵值Hbin、窗口内所有值的出现次数c.
① functionCalc_window_entropy(data,window)
②c=np.bincount(data≫4,minlength=16);
③ /*将data右移4位,即范围从[0,255]缩小至[0,15],然后计算data中的值出现次数.
c为一个shape=(1,16)的数组*/
④p=c.astype(np.float32)/window;
⑤ /*将c转为浮点类型除以窗口值*/
她要嫁给他,他说,不行,你有丈夫。她说,我要跟你走,不管你到哪,我都跟着。他说,不行,我身边不能带着女人。他又说,其实,我们不是朋友,是敌人。
⑥wh=np.where(c)[0];
⑦ /*获取当前坐标对应值不为0的下标*/
⑧Hg=np.sum(-p[wh]×
np.lb(p[wh]))×2;
⑨ /*计算熵值*/
⑩Hbin=int(Hg×2);
算法3.遍历二进制文件字节熵算法流程.
输入:原始二进制样本文件file、窗口值window、步长step;
输出:(1,256)形状大小的特征向量entropy.
① functionCalc_file_entropy(file,
window,step)
②f=open(file,‘rb’);
③data=np.frombuffer(f);
④entropy=np.zeros((16,16));
⑤filesize=data.shape(0);
⑥ iffilesize≤window
⑦ /*如果文件大小小于窗口值*/
⑧Hb,c=Calc_window_entropy(data,window);
⑨entropy[Hb,:]+=c;
⑩ else
(data,windows,shape);
(block,window);
1.3 opcode序列特征
我们使用IDA Pro反汇编工具的批处理功能对PE可执行文件进行反汇编,获取二进制程序的opcode序列.可执行文件经过反汇编后一般分为3部分,包括text,data,bss段.data和bss段一般存储程序的数据变量和数据常量,因此我们只对text段的opcode序列进行分析.text段部分opcode序列如图4所示:
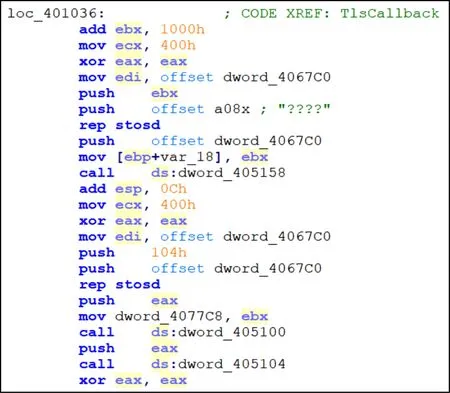
Fig. 4 Original opcode sequence图4 原始opcode序列
由图4可见,一条汇编指令由操作码和操作数构成,但操作数过于复杂,包含偏移量、内存地址、立即数等各种表示形式.由于操作数格式复杂、长短差距悬殊、含义丰富杂乱且数量庞大,无法直接作为后续特征处理的语料库.因此我们在获取text段的opcode序列之后,对opcode序列进行了预处理.制定一系列的规则对opcode序列进行替换,使其表现方式有限,清除汇编数据中的一些噪声干扰.
我们首先统计了所有x86指令集的操作码及其参考含义[21],因为在IDA Pro反汇编得到的asm反汇编文件内存在大量的注释、数据变量定义、交叉引用等方便提供给逆向工程分析师分析的内容.因此只有当asm反汇编文件的第一个分词为x86指令集中的分词时,我们才继续统计该行中的剩余分词.对操作数进行预处理时,我们参考文献[22]的汇编指令预处理过程,制定6项规则对操作数进行处理.
1) 寄存器.收集8 b,16 b,32 b这3种主要的寄存器列表,如eax,ebx,ecx,edx,esi,edi,ebp,esp,ax,bx,al,bl等.
2) 内存.表示形式为内存的全部标准化为mem,如[ebx],[esi+8]等.
3) 立即数.表示形式为立即数的全部标准化为val,如5A4Dh,0 h等.
4) 调用指令.调用内部函数后的操作数全部标准化为sub,如“call sub_102A02D”,标准化为“call sub”.
5) 跳转指令.跳转指令后的操作数全部标准化为loc,如“jnz loc_3025A8”,标准化为“jnz loc”.
6) 对于不符合上述5条的操作数,全部标准化为oth.
对opcode序列进行预处理后,图4的opcode序列处理为图5所示:

Fig. 5 Original opcode sequence图5 预处理后opcode序列
我们将预处理后的每个操作码设定为一个单 词,每条汇编指令设定为一个短语.随后采用 Word2Vec[19-20,23-24]模型对所有asm文件进行训练, 获取每个词对应的词向量表示.Word2Vec模型是 当前最流行的词向量转换方法之一,该模型是一个 简化的浅层神经网络,包括输入层、隐藏层和输出 层.其中,我们采用Word22Vec模型的CBOW 模型 来根据上下文信息预测一个词,该模型的输入是某 一个特定词上下文相关词对应的词向量,输出则是这 一特定词的词向量.汇编指令处理流程如图6所示:
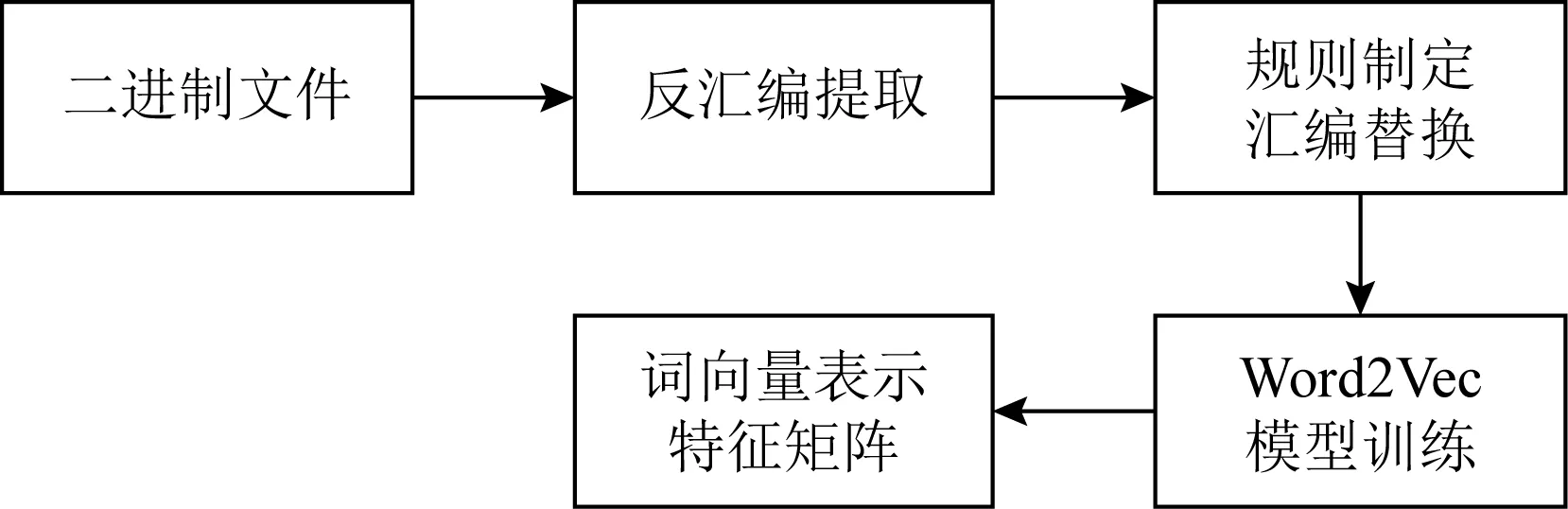
Fig. 6 opcode sequence processing flow图6 opcode序列处理流程
1.4 strings序列特征
我们使用Linux下的Strings工具来提取二进制文件中的可打印字符串,但在可打印字符串中存在较多的噪声与干扰,因此我们使用正则匹配有意义的字符串以减少噪声和干扰.正则匹配的模式为0x30~0x39,0x41~0x5A,0x61~0x7A分别对应阿拉伯数字0~9、大写字母A~Z和小写字母a~z.之后我们使用TF-IDF算法对string序列进行处理,用于统计恶意样本库和良性样本库中string重要程度的差异.TF-IDF算法具体为.
词频-逆文档频率(term frequency-inverse docu-ment frequency, TF-IDF)是一种常用的文本特征向量化方法之一,该方法可体现出文本中某个词语对整个文本的重要程度.一个特定词语的TF-IDF值为TF值与IDF值的乘积,而TF值表示某一个给定的词语在该文件中出现的频率:

(3)
IDF则表示一个词语普遍重要性的度量,某一特定词语的IDF,可以由总文件数目除以包含该词语的文件数目,再对商取以10为底的对数:

(4)
我们所使用字符串特征提取算法如算法4所述:
算法4.字符串特征提取算法.
输入:每个样本的原始字符串string;
输出:3000维的特征矩阵Feature_map.
① functiontf_idf_string(string)
②Reg_mode=“[a-zA-Z0-9]+”;
③ /*定义正则匹配模式*/
④new_s=re.findall(Reg_mode,string);
⑤ /*使用定义的匹配模式正则匹配*/
⑥n_gram_strings=n_gram(new_s,[1,3]);
⑦ /*使用n_gram算法对字符串做(1,3)范围内扩充*/
⑧Feature_map=tf_idf.fit(n_gram_strings);
⑨ /*tf_idf算法训练处理好的字符串*/
⑩ returnFeature_map;
1.5 PE文件结构特征
当前相当多的学者尝试利用PE文件结构检测恶意软件,例如文献[14]使用最少的领域知识,即MS-DOS,COFF,Optional标头信息进行恶意软件的检测并取得了较好的结果.
PE文件格式描述了Microsoft Windows操作系统的主要可执行文件格式,包括可执行文件,动态链接库等.而可执行文件结构又包含许多标准headers,每个header对应一个或多个部分,例如通用对象文件结构(common object file format, COFF)头则包含一些相当重要的信息,如文件所针对标识链接器版本、文件的性质、节数、可选标头标识连接器版本、代码大小、已初始化和未初始化的数据大小、入口地址等.由此可见,根据先验知识,PE文件头结构经过解析后的结果在识别文件是否异常可以发挥重要作用.我们借鉴文献[11]中所提到的思路,提取PE文件中的general,header,imports,exports,section这5部分结构信息,如表2所述,再分别做Feature-Hasher算法处理,将每部分向量拼接成形状为1 735维的向量表示,即可得到每个样本对应的PE文件结构特征.

Table 2 Corresponding Characteristics of Each Part of the PE File
1.6 函数调用关系特征
我们使用反汇编工具IDA Pro批量导出恶意样本的GDL文件,GDL文件通常由3部分组成:颜色、节点和边,如图7所示.其中颜色标识唯一的ID,后面跟的3个数字为RGB颜色每个通道所代表的颜色值;节点标识中title字段是唯一标识,label字段代表函数名,color,textcolor,bordercolor等字段代表颜色;边标识中有源节点和目的节点2个信息,这2个信息与节点标识中的title字段对应,用以标识一条有向边.
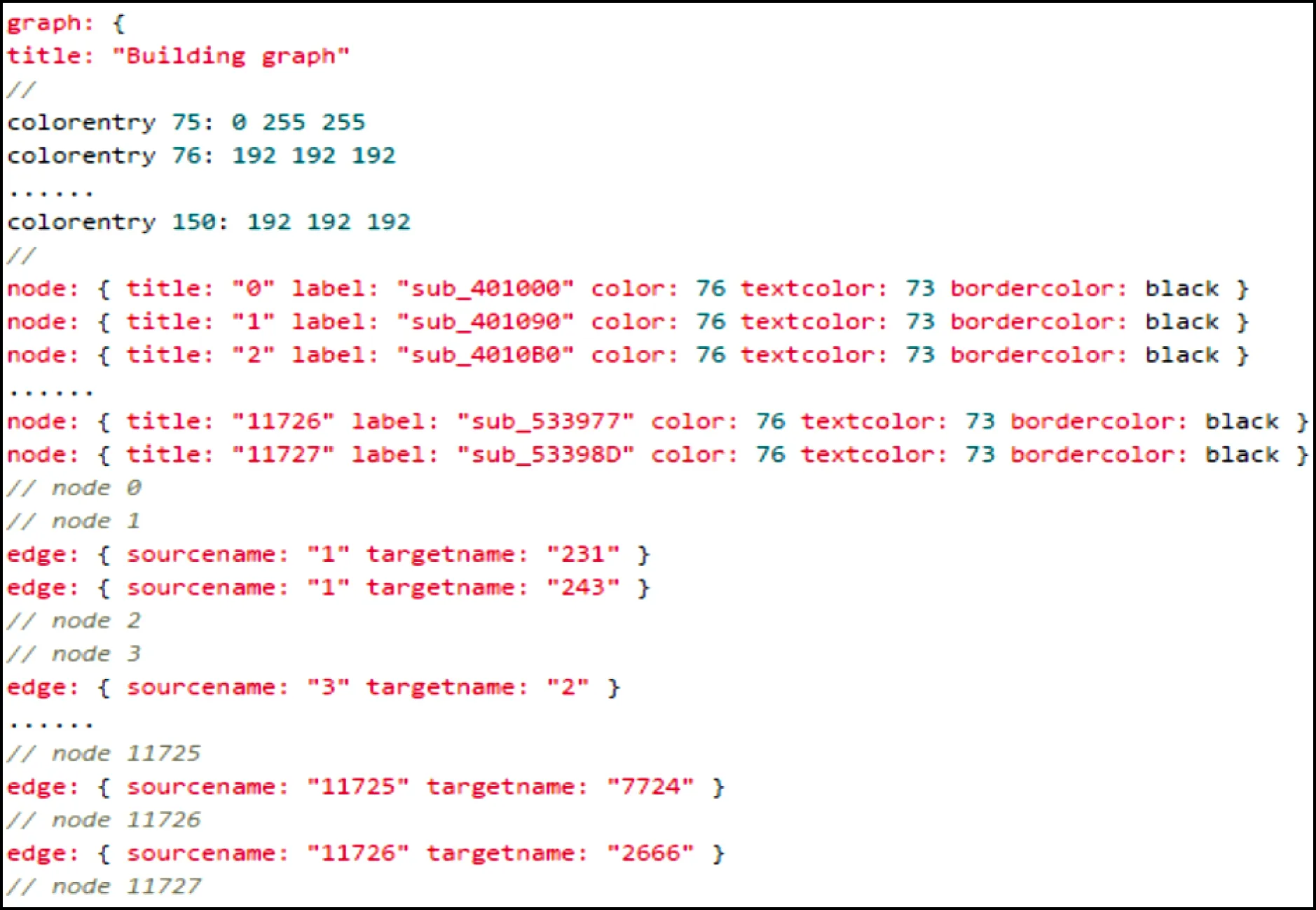
Fig. 7 The description of GDL file format图7 GDL文件格式说明
我们发现,在节点与节点之间的有向边反映了该二进制文件中函数的互相调用关系,函数之间的调用关系在一定程度上反映了该二进制文件本身的行为意图,因此,我们抽取每个样本文件的有向边关系矩阵.由于二进制文件可能存在函数较多的情况,在本文的实验中,sha256值为ec470aec5741cdbb45 d926e57cd5258104654cafa74771a4cf73cf33f23a1ef4的样本中函数的数量达到39 664个,可知其生成的调用关系矩阵的大小是无比庞大的,而我们需要在保证精确度下降程度不大的情况下尽可能减少后续模型训练的时间,因此我们采用核主成分分析算法对原始调用关系矩阵进行预处理,达到降维的目的.
核主成分分析算法(kernel principal component analysis, KPCA)是利用核技术对主成分分析的一种非线性推广,该方法通过非线性映射,将原始数据从输入控件映射到特征空间,使其具有更好的可分性,再对特征空间中的映射数据进行主成分分析,进一步得到该映射数据的主成分[25],并对生成的特征矩阵做规范化、归一化处理.
提取函数调用关系算法流程如算法5所述:
算法5.提取函数调用关系算法流程.
输入:GDL文件;
输出:(1,20 000)特征矩阵.
① functionExtract_func_call(file)
②data=open_and_read(file);
③ /*读取GDL文件内容至data中*/
④max_node_addr=re.findall(“//node 0”)[0]-1;
⑤ /*使用正则定位node的最大值位置*/
⑥max_node=data[max_node_addr].
node.title;
⑦ /*读取node的最大节点数*/
⑧func_call=np.zeros((max_node,max_node));
⑨ forlineindata
⑩ /*遍历有向边*/
2 算法模型
集成学习是一种范式,通过集成多种机器学习算法以进一步提高性能,这是一种基于委员会的方法,旨在获得每个成员的投票.近几年来,各个大数据驱动的机器学习赛事系统如Kaggle、天池、DataCon等频繁看到集成学习的身影,集成学习思想也在其中大放光芒.自1979年集成学习思想[26]被首次提出,集成学习便不断的蓬勃发展,由于集成模型具有更低的方差和更好的泛化能力,集成学习算法也越来越受到科研人员的关注.集成学习主要包含3种经典算法:Bagging,Boosting,Stacking.由于本文中只使用到了Bagging和Stacking,故本章节仅对这2种集成方法进行详细介绍,同时介绍本文所使用的多结果聚合算法:权重策略投票.
2.1 Bagging集成
Bagging算法[27]又称装袋算法,是最早的集成学习算法之一,Bagging的2个关键是自助和聚合.自助即使用自助采样法[28]随机改变训练集的分布并产生新的子集.同时对于Bagging的任一基分类器,训练时原始训练集中约有36.8%的样本会未被使用,此时该基分类器的好坏可以通过这些包外样本进行估算.而对于分类任务,聚合则是指Bagging将样本传给基分类器并收集输出,然后对输出标记进行投票,获胜的标记作为预测结果,平局则随机挑选一个作为预测结果.
由于Bagging聚合多个且独立的基分类器,故其可以显著降低方差,提高模型性能,避免过拟合的发生.如图8为Bagging算法流程:
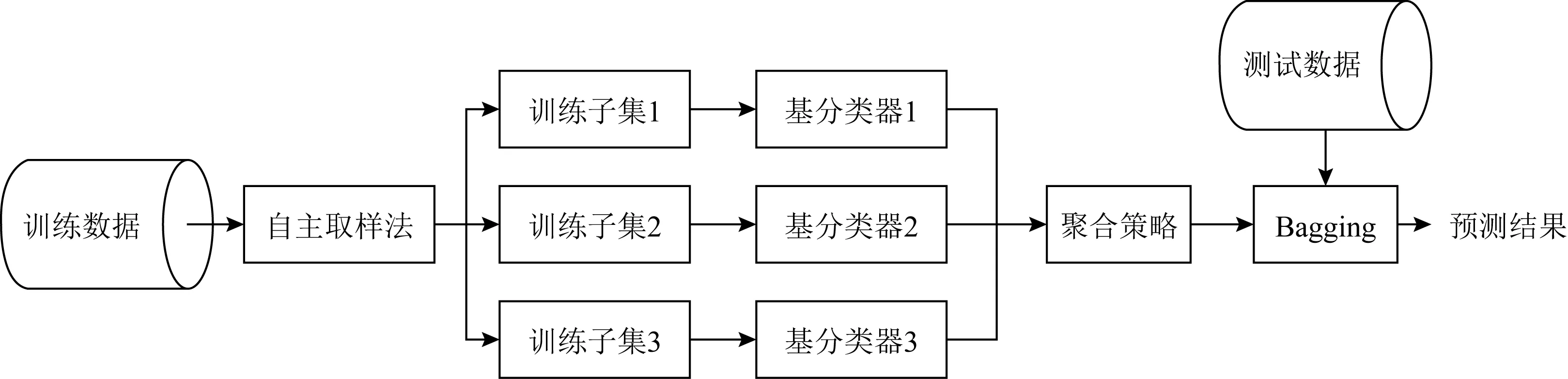
Fig. 8 Bagging algorithm flow图8 Bagging算法流程
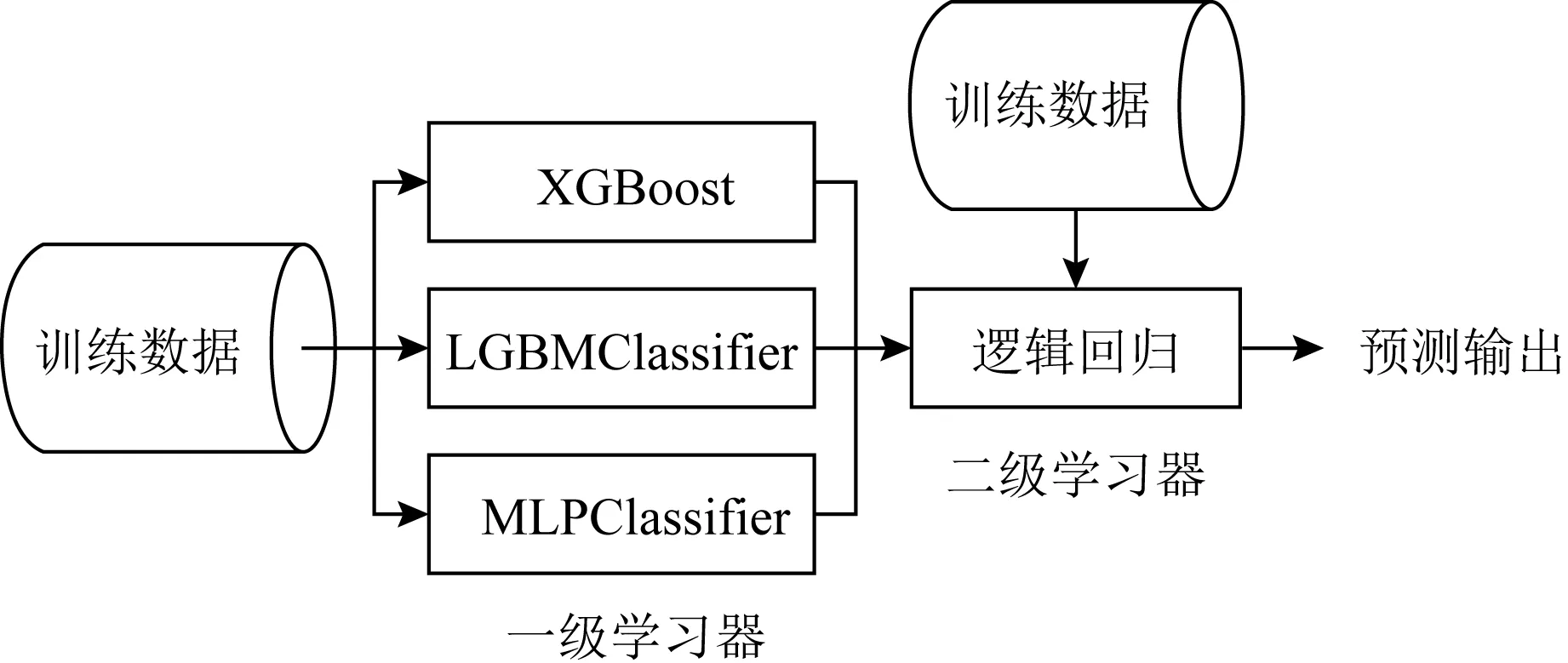
Fig. 9 Stacking algorithm flow图9 Stacking算法流程
2.2 Stacking集成
Stacking算法[29]其结构如图9所示,其中包括2层学习器,第1层有不定数目的基学习器,输入的特征矩阵经由第1层的基学习器来抽取有效的特征,第2层的输入来自于第1层的特征输出,故第2层的输入中不应包含原始特征.Stacking集成框架的存在即是为了降低单模型对训练数据过拟合的风险,故第2层分类器通常为较为简单的线性分类器,比如逻辑回归、SVM算法等.由于Stacking框架平滑的特性,故其能突显出性能最佳的基模型,且降低性能较差的基模型,使之泛化能力更加稳定.
2.3 权重策略投票
在使用每部分特征预测出结果后,我们利用权重策略投票算法集成5种特征生成的结果,即5种特征经过Bagging集成或Stacking集成后输出每个测试样本的2类概率proba0和proba1.同时我们为每个分类器设置相应的权重,首先我们选择唯一的评价标准,例如准确率、召回率、F1等,并计算该评价标准在每个模型训练集上5折交叉验证的分数,然后再把该分数相加得到总分数,将每个分类器的分数与总分数相比,得到单个分类器的权值λi(其中i表示分类器的个数):
(5)
然后使用计算得到的权值λi与各分类器所给出的对应测试样本的概率相乘,得到该测试样本的概率p0和p1,将各分类器的p0和p1累加得到聚合结果finalP0和finalP1,其中finalP0指被判断为正常样本的概率,finalP1则是指被判断为恶意样本的概率.
为了提高检出率,我们检查每个测试样本的finalP1是否大于我们所设置的策略阈值,如大于该阈值,则输出为恶意样本,否则输出为正常样本.
权重策略投票算法可以最大程度地纠正每部分特征训练出的分类器的初始分类错误,使聚合结果更加地可靠.
3 架构描述
3.1 特征提取架构
我们在第1节算法提取的基础上,对部分特征进行整合.由于熵描述了恶意样本混乱程度的大小,从本质上讲加壳后的恶意样本比未加壳的恶意样本混乱程度更大,即如果可执行文件使用了加密或者加壳程序则往往反应了较高的熵值[30],而我们以往的认知是:正常样本基本不会施以加壳等手段,故熵在恶意软件检测中发挥了很好的功效.但近期的一些研究[16,31]表明:正常软件为了保护版权等信息也越来越多地使用加壳等手段;低熵加壳方法逐渐成为一种流行的加壳方式.故单纯使用字节熵直方图特征会使得模型的泛化能力越来越差,不利于其健壮性.而且字节统计值和字节熵直方图特征的维数与GIST描述符的特征维数相同,均为512维,这2部分特征无需任何先验知识就能对恶意样本检测,因此我们将恶意样本图像的Gist描述符特征与字节统计值和字节熵直方图特征整合为非PE结构特征.
最终我们构成5组特征:非PE结构特征、字符串序列特征、汇编指令特征、PE结构特征以及函数调用关系特征.特征提取框架图如图10所示:

Fig.10 Feature extraction frame diagram图10 特征提取框架图
3.2 模型算法选择
我们针对不同的特征,利用5折交叉验证训练不同的预选模型,根据在验证集上的评价结果,选出合适数量的模型,而后分别使用Stacking框架或Bagging框架对基模型进行聚合,观测在验证集上评价结果的变化.每部分模型对应基模型列表如表3所示.而后我们使用网格搜索算法,对基模型所对应的参数加以调整,从而使基模型更加拟合数据分布.
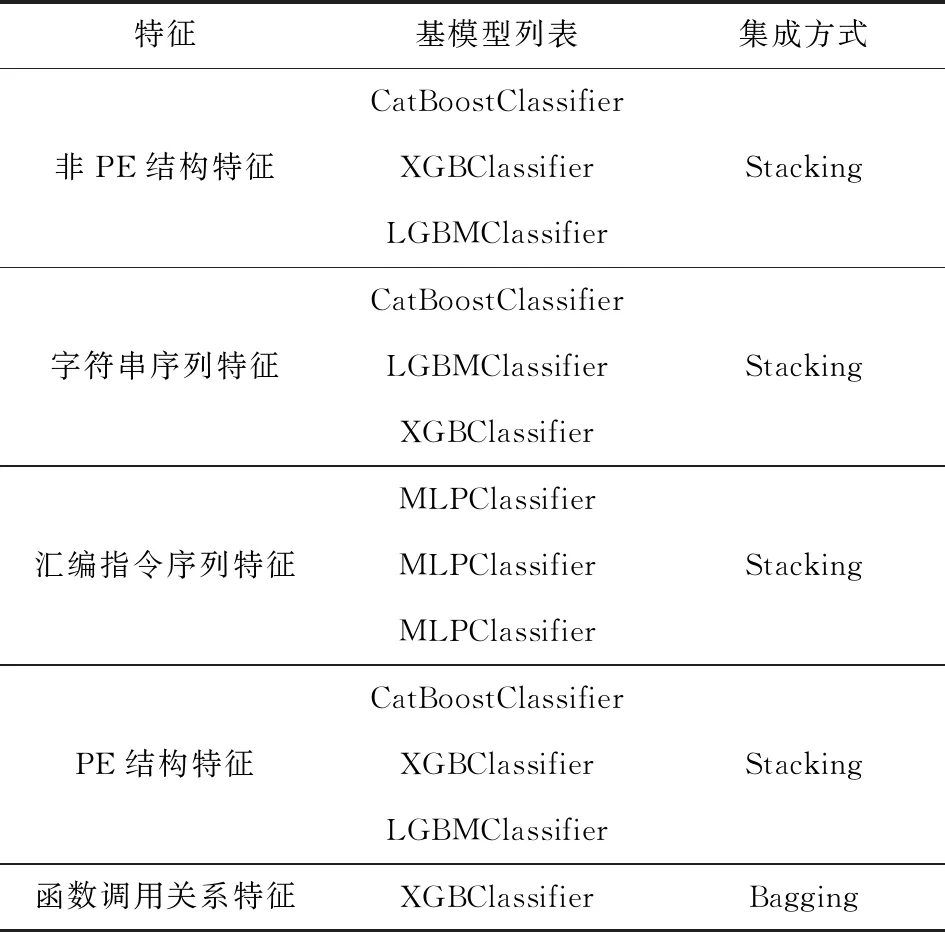
Table 3 Each Part of the Feature Corresponds to the Base Model List
3.3 整体架构
本文进行实验的恶意软件静态检测整体框架如图11所示:
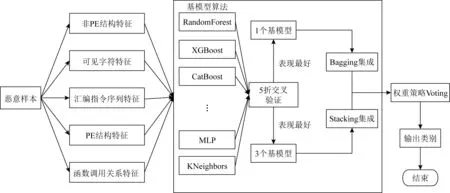
Fig. 11 Overall framwork of malware stastic detection图11 恶意软件静态检测整体框架图
4 实验过程
4.1 数据集
本文所使用数据集由2020年“DataCon开放数据计划”[32]提供,为23 655个标注好的PE样本,其中包含7 896个挖矿样本与15 759个非挖矿样本(其他家族恶意样本),所有样本均为现网中捕获的真实数据,并非仿真数据、陈旧数据,这就保证了该数据集中的样本存在加壳、混淆等大量对抗样本.经我们统计:该数据集中包含UPX壳、VMP壳、Themida壳以及Mpress壳等多种带有压缩壳或加密壳的样本.而且该数据集通过代码相似性等方法过滤了相似样本,保证所有样本具有一定的多样性.同时为了防止样本误运行,都抹去了MZ头、PE头以及导入导出表部分.故我们在进行实验部分的时候人工为其添加了MZ头和PE头部分,使之可以被当成PE文件进行解析.
为了更能彰显模型的泛化能力与抗加壳抗混淆的能力,我们舍弃正常情况下4∶1或7∶3的划分标准,按照1∶3的比例将样本随机划分为训练集与测试集,即训练集中的黑白样本为2 000和4 000;测试集中的黑白样本为5 896和11 759.
4.2 评价标准
混淆矩阵是监督学习中一种可视化表示形式,为了方便表示后续的评价标准,我们首先介绍恶意软件检测的混淆矩阵,如表4所示,其中,TP指将恶意软件正确分类为恶意软件;FP指将正常软件错误分类为恶意软件;FN指将恶意软件错误分类为正常软件;TN指将正常软件正确分类为正常软件.

Table 4 Confusion Matrix表4 混淆矩阵
本文选用恶意代码检测领域的通用评测标准的准确率(accuracy rate,AR)、召回率(recall rate,RR)、误报率(false positive rate,FPR)以及召回率和误报率的平衡标准Score对本文方法进行评测,每个评测标准的计算:
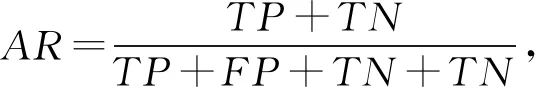
(6)
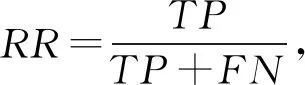
(7)
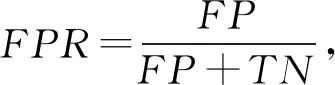
(8)
Score=RR-ε×FPR.
(9)
其中式(9)中的ε为惩罚因子,可以为任意数值,我们在实验中设为1.2.Score评价标准实际含义为召回率减去惩罚因子乘误报率,用于平衡召回率和误报率,即Score的大小与召回率呈正相关,与误报率呈负相关.
4.3 参数选择
根据特征提取方案及总体模型架构,我们对字节熵直方图特征中的window和step变量以及权重策略投票算法中的策略阈值做不同取值的对比实验.
在非PE结构特征中,字节熵直方图的窗口和步长2个变量的取值对该部分特征的影响较大,所以我们对2个变量进行分析:首先固定step的值为256,使用CatBoost算法、XGBoost算法以及多层感知机算法(multilayer perceptron, MLP)3种不同算法对不同值的window所表现的Score进行评价,如图12所示,显而易见,在window=1280时,CatBoost模型和XGBoost模型达到最优,MLP模型也呈上升趋势;而后我们取window=1280,利用上述3个算法对不同值的step进行Score评价,如图13所示,在step=128时,MLP模型达到最优,CatBoost模型和XGBoost模型的Score值也在中等偏上,故我们选取step=128.

Fig. 12 When step=256, the effect of windowsize on Score图12 step=256时window大小对Score的影响

Fig. 13 When window=1 280, the effect of stepsize on Score图13 window=1 280时step大小对Score的影响
当我们进行最后的5部分特征聚合时,权重策略投票算法中的策略阈值也对最后的结果起着至关重要的作用,故我们针对该阈值进行实验验证:设定不同的阈值,以此对照AR,RR,FPR,Score,找到召回率和误报率的最优平衡点.不同阈值对结果的影响如表5所示.
由表5及图14可知,召回率与策略阈值呈正相关,误报率随策略阈值呈负相关,当阈值为0.30时,AR与Score评价均达到最高为0.969 9和0.921 9.

Table 5 The Impact of Different Policy Thresholds on Voting Algorithms
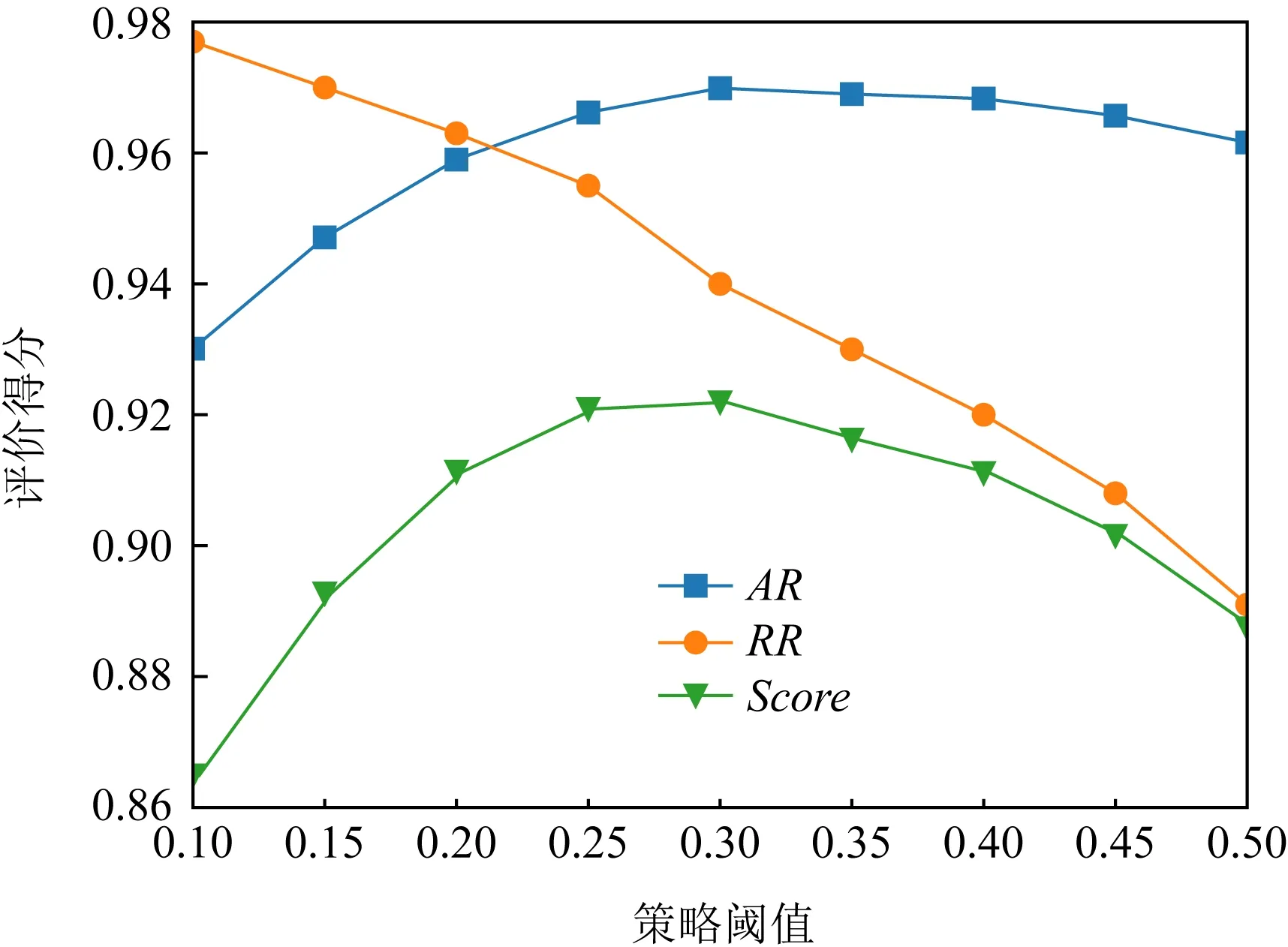
Fig. 14 Changes in AR, RR, and Score with policy thresholds图14 AR,RR,Score随策略阈值的变化情况
4.4 Stacking二级分类器算法选择
针对Stacking集成学习算法的二级分类器选择,我们选择Logistic Regression,KNN,SVM等算法进行评测,由于篇幅有限,我们仅对非PE文件结构特征进行描述,如表6所示.可以看出,在非PE结构特征中,当二级分类器为SVM算法时,Stacking算法在Score上的表现是最优的.但在字符串特征和PE结构特征中,二级分类器选择KNN算法效果会更好,因此我们根据最终模型的表现效果来确定二级分类器算法的选择.

Table 6 Stacking Algorithm Two-Level Classifier Comparison表6 Stacking算法二级分类器比较
4.5 5部分特征对比
我们提取上述5种特征,分别采用表现最好的单模型算法与集成学习算法输出每种特征的性能指标,对比结果如表7所示,集成学习模型在AR,RR,Score上均略高或持平于单模型算法,凸显了集成学习更加强大的潜力.并且使用权重策略投票算法聚合5部分特征的结果,通过调整策略阈值使得实验结果在AR,RR,Score等评价标准上均有进一步提升.
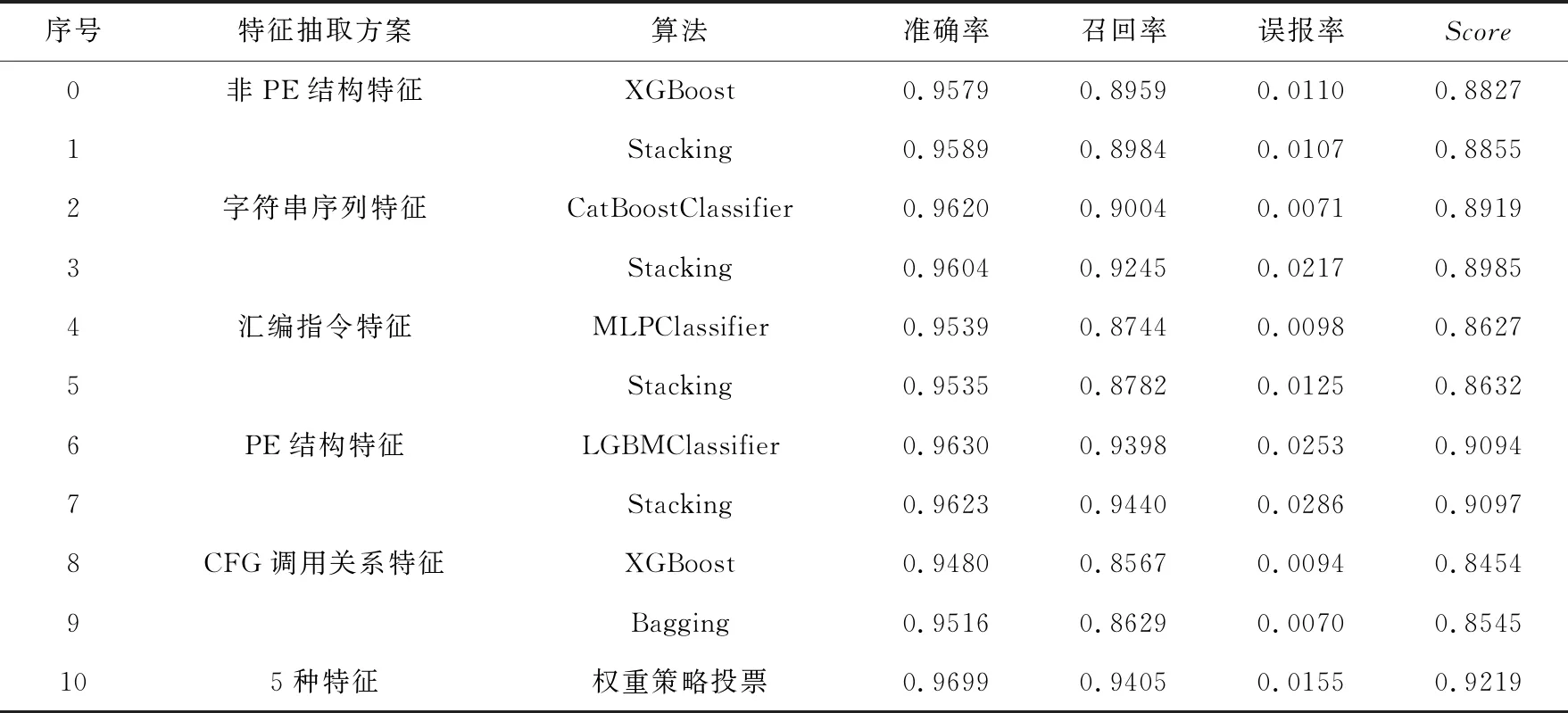
Table 7 Comparison of Feature Detection Results for Each Part
4.6 不同恶意软件检测方法对比
我们参考文献[15,19,22,33]分别做对比实验,4篇对比文献中,2篇关于深度学习,1篇关于集成学习,最后1篇则关于机器学习.文献[15]是提取恶意样本的函数调用图,通过归一化使函数调用图更加稳定,继而使用深度卷积神经网络进行训练得到分类结果.文献[19]则是提取恶意样本的灰度图,通过不同参数的GIST描述符提取特征,而后采取KNN算法和随机森林算法完成投票并达到分类效果.文献[33]则是对恶意样本的图像进行处理,首先训练一个成熟的卷积神经网络,而后使用Xgboost算法替代卷积神经网络的全连接层的最后一层以达到分类效果.文献[22]是提取恶意样本的汇编指令,经过预处理之后使用LDA算法降维,而后经LDA产生的数据由随机森林算法训练后得到结果.表8为对比实验结果,我们随后对文献[22]的分类器做了改进,使用随机森林、Catboost、Xgboost、lightGBM等算法进行集成学习,其结果如表8第4行所示,虽然相较文献[22]有一定的提升,但跟我们的方法相比,明显还存在一定差距.在AR评价标准下,我们所提出的基于多特征集成学习的静态检测框架在准确率上能达到96.99%,其余4篇文献的AR值均在96.99%之下;在召回率评价标准下,其余4篇文献所表现出的性能仍然明显低于我们的方法;在误报率评价标准下,虽然文献[22,33]略低于于我们的方法,但我们的方法所表现出的误报率仍在可接受范围内.并且在综合召回率和误报率的Score的评价标准下,我们所提出的基于多特征的检测方法表现最好,同时对混淆加壳等样本的普适性更高.

Table 8 Explanation of Comparative Experiment Results表8 对比实验结果说明
5 总结与展望
网络空间安全的威胁日益加剧,海量病毒的处理已经成为愈发紧要的问题,本文所提出的基于多特征集成学习的恶意代码静态检测框架具有检出率高、误报率低、抗加壳、混淆等一系列优点,可以很好地适应数据量级别较高的要求.但汇编指令特征与CFG调用关系特征所使用的模型仍为普通的机器学习模型,未将特征的性能全部发挥出来,在后续工作中将使用深度学习框架改进并搭建循环神经网络、图神经网络等模型,进一步挖掘2部分特征.同时我们将持续关注在恶意软件检测领域的对抗攻击技术,计划使用一些较新的对抗攻击技术攻击检测模型,核验该检测方法是否能抵抗更加高级的对抗攻击方法.
